Para gerar o relatório necessário com uma frequência especificada, basta escrever um recurso de Relatório personalizado correspondente.
Cenários de uso
Relatórios de medição personalizados são necessários, por exemplo, nos seguintes casos:
- OpenShift, , (worker nodes) . . CPU , , -, , .
- OpenShift. Metering, , , , . , , , .
- Além disso, em uma situação com clusters públicos, o departamento de operações seria útil para ser capaz de manter registros no contexto de equipes e departamentos pelo tempo operacional total de seus pods (ou por quanto recursos de CPU ou memória foram gastos nele). Em outras palavras, estamos novamente interessados em informações sobre quem é o proprietário deste ou daquele sub.
Para resolver esses problemas no cluster, basta criar alguns recursos personalizados, o que faremos a seguir. A instalação do operador de medição está além do escopo deste artigo, portanto, consulte a documentação de instalação, se necessário . Você pode aprender mais sobre como usar os relatórios de medição padrão na documentação relacionada .
Como funciona a medição
Antes de criar ativos personalizados, vamos dar uma olhada em Medição um pouco. Depois de instalado, ele cria seis tipos de recursos personalizados, dos quais nos concentraremos no seguinte:
- ReportDataSources (RDS) - Este mecanismo permite que você especifique quais dados estarão disponíveis e podem ser usados em ReportQuery ou recursos de Relatório personalizados. O RDS também permite que você extraia dados de várias fontes. No OpenShift, os dados são extraídos do Prometheus, bem como de recursos ReportQuery (RQ) personalizados.
- ReportQuery (rq) – SQL- , RDS. RQ- Report, RQ- , . RQ- RDS-, RQ- Metering view Presto ( Metering) .
- Report – , , ReportQuery. , , , Metering. Report .
Muitos RDS e RQ estão disponíveis fora da caixa. Como estamos principalmente interessados em relatórios de nível de nó, consideraremos aqueles que o ajudarão a escrever suas consultas personalizadas. Execute o seguinte comando durante o projeto "openshift-metering":
$ oc project openshift-metering
$ oc get reportdatasources | grep node
node-allocatable-cpu-cores
node-allocatable-memory-bytes
node-capacity-cpu-cores
node-capacity-memory-bytes
node-cpu-allocatable-raw
node-cpu-capacity-raw
node-memory-allocatable-raw
node-memory-capacity-raw
Aqui, estamos interessados em dois RDS: node-capacity-cpu-core e node-capput-capacity - capacity-raw, uma vez que queremos obter um relatório sobre o consumo de CPU. Vamos começar com node-capacity-cpu-core e executar o seguinte comando para ver como ele coleta dados do Prometheus:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml
<showing only relevant snippet below>
spec:
prometheusMetricsImporter:
query: |
kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)
Aqui, vemos uma solicitação do Prometheus que busca dados do Prometheus e os armazena no Presto. Vamos executar a mesma solicitação no console de métricas do OpenShift e ver o resultado. Temos um cluster OpenShift com dois nós de trabalho (cada um com 16 núcleos) e três nós mestres (cada um com 8 núcleos). A última coluna, Valor, contém o número de núcleos atribuídos ao nó.

Assim, os dados são recebidos e armazenados nas tabelas do Presto. Agora vamos ver os recursos personalizados do reportquery (RQ):
$ oc project openshift-metering
$ oc get reportqueries | grep node-cpu
node-cpu-allocatable
node-cpu-allocatable-raw
node-cpu-capacity
node-cpu-capacity-raw
node-cpu-utilization
Aqui, estamos interessados no seguinte RQS: node-cpu-capacity e node-cpu-capacity-raw. Como o nome sugere, essas métricas contêm dados descritivos (por quanto tempo um nó está em execução, quantos processadores ele alocou, etc.) e dados agregados.
Os dois RDS e dois RQS nos quais estamos interessados estão interconectados pela seguinte cadeia:
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
Relatórios Customizáveis
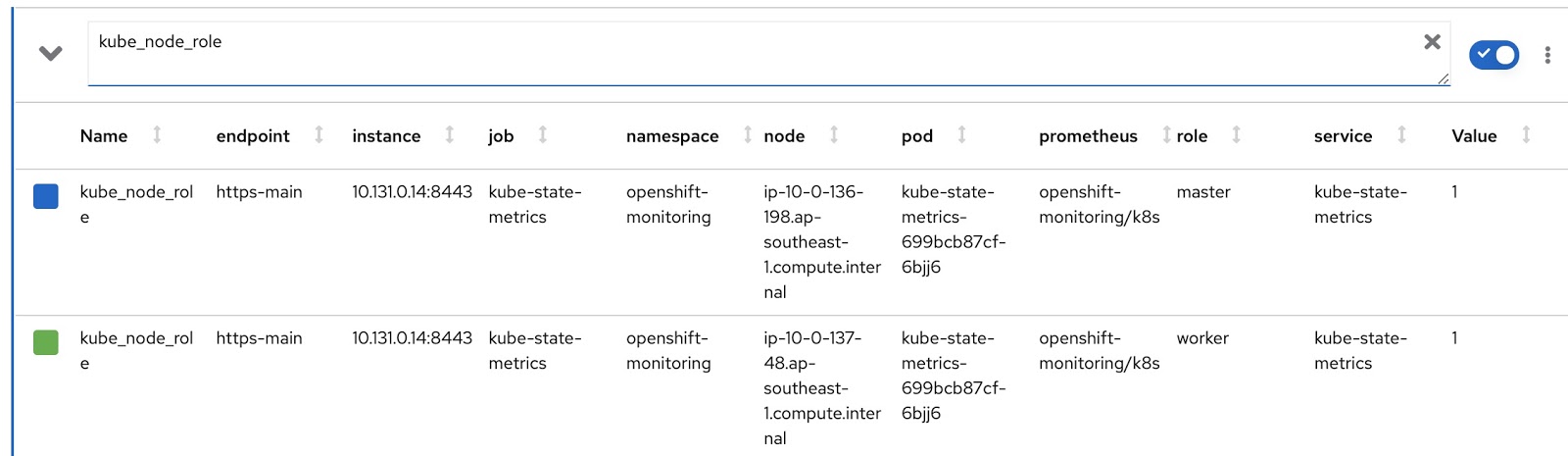
Agora vamos escrever nossas próprias versões personalizadas de RDS e RQ. Precisamos alterar a solicitação do Prometheus para que exiba o modo do nó (mestre / trabalhador) e o rótulo do nó correspondente, que indica a qual equipe este nó pertence. O modo de operação do nó está contido na métrica kube_node_role Prometheus, consulte a coluna de função:
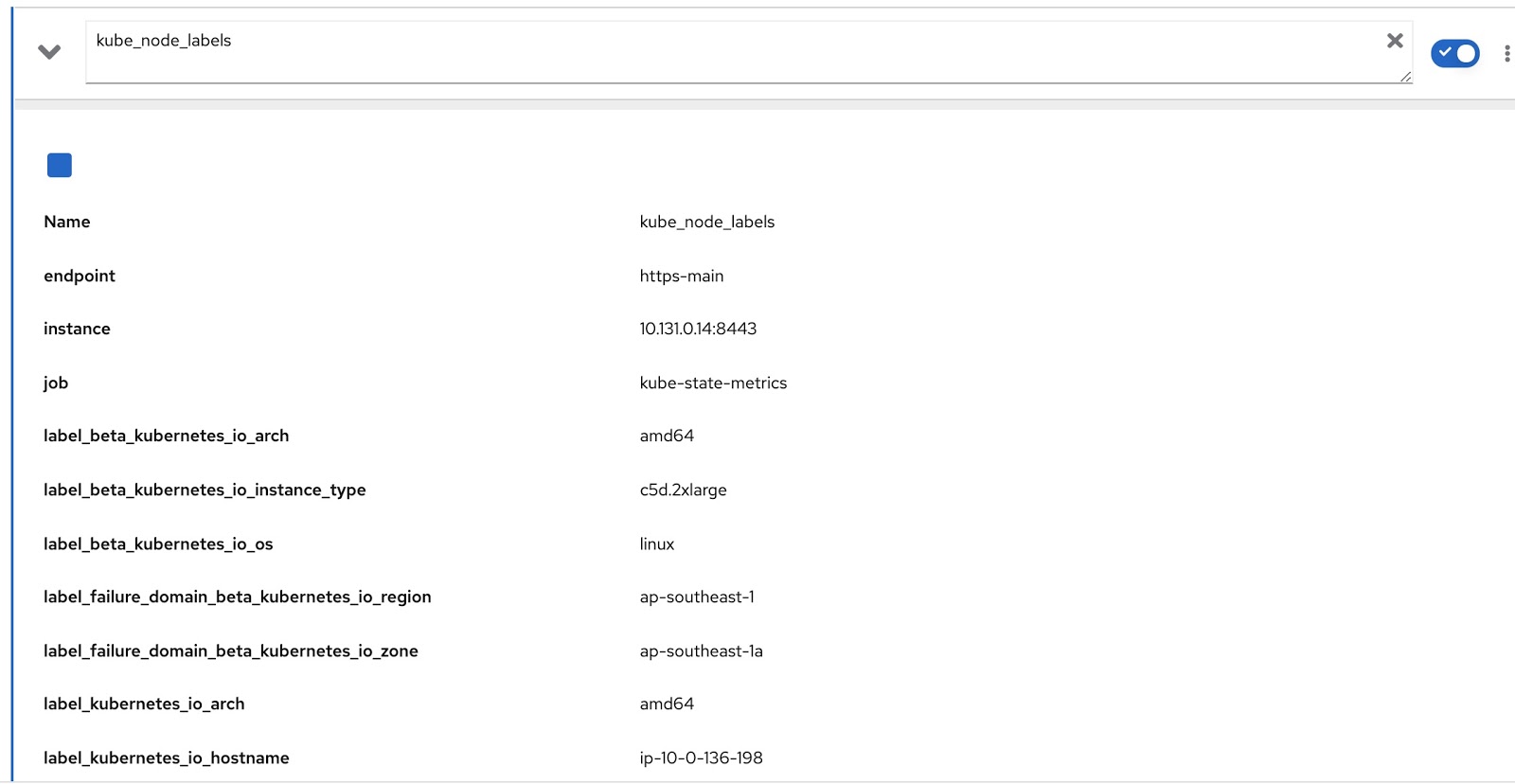
E todos os rótulos atribuídos ao nó estão contidos na métrica kube_node_labels do Prometheus, onde são formados usando o modelo label_. por exemplo, se um nó tiver um rótulo node_lob, na métrica do Prometheus ele será exibido como label_node_lob.
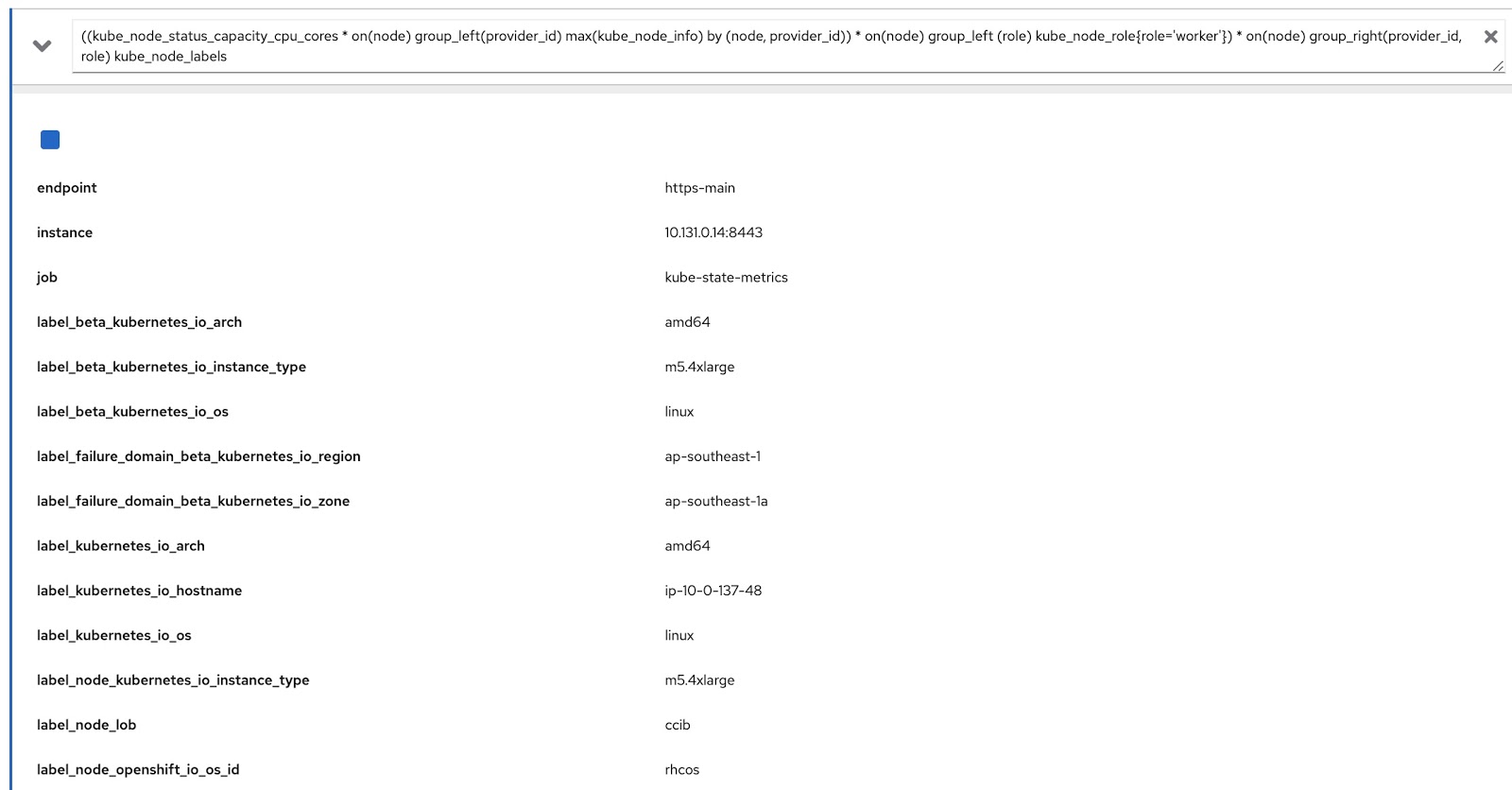
Agora só temos que modificar a consulta original usando essas duas consultas do Prometheus para obter os dados de que precisamos, como este:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
Agora vamos executar esta consulta no console de métricas OpenShift e garantir que ela retorne dados por rótulos (node_lob) e por funções. Na figura abaixo, este é, primeiramente, label_node_lob, assim como a função (está lá, só não apareceu na captura de tela):
Portanto, precisamos escrever quatro recursos personalizados (você pode baixá-los na lista abaixo):
- rds-custom-node-capacity-cpu-cores.yaml - Especifica uma solicitação Prometheus.
- rq-custom-node-cpu-capacity-raw.yaml - refere-se à solicitação da etapa 1 e dá saída aos dados brutos.
- rds-custom-node-cpu-capacity-raw.yaml - refere-se ao RQ da etapa 2 e cria um objeto de exibição no Presto.
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml - refere-se ao RDS da cláusula 3 e dados de saída levando em consideração as datas de início e término inseridas do relatório. Além disso, as colunas de função e rótulo são extraídas para o mesmo arquivo.
Depois de criar esses quatro arquivos yaml, vá para o projeto openshift-metering e execute os seguintes comandos:
$ oc project openshift-metering
$ oc create -f rds-custom-node-capacity-cpu-cores.yaml
$ oc create -f rq-custom-node-cpu-capacity-raw.yaml
$ oc create -f rds-custom-node-cpu-capacity-raw.yaml
$ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml
Agora resta apenas escrever um objeto Relatório personalizado que fará referência ao objeto RQ da etapa 4. Por exemplo, você pode fazer isso conforme mostrado abaixo para que o relatório seja executado imediatamente e retorne dados de 15 a 30 de setembro.
$ cat report_immediate.yaml
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: custom-role-node-cpu-capacity-lables-immediate
namespace: openshift-metering
spec:
query: custom-role-node-cpu-capacity-labels
reportingStart: "2020-09-15T00:00:00Z"
reportingEnd: "2020-09-30T00:00:00Z"
runImmediately: true
$ oc create -f report-immediate.yaml
Depois de executar este relatório, o arquivo de resultado (csv ou json) pode ser baixado do seguinte URL (basta substituir DOMAIN_NAME pelo seu próprio):
metering-openshift-metering.DOMAIN_NAME / api / v1 / reports / get? Name = custom-role-node-cpu- capacity-hourly & namespace = openshift-metering & format = csv
Como você pode ver na captura de tela do arquivo CSV, ele contém role e node_lob. Para obter o tempo de atividade do nó em segundos, divida node_capacity_cpu_core_seconds por node_capacity_cpu_cores:

Conclusão
O operador de medição é uma coisa legal para clusters OpenShift implantados em qualquer lugar. Ao fornecer uma estrutura extensível, permite criar recursos personalizados para gerar os relatórios desejados. Todos os códigos-fonte usados neste artigo podem ser baixados aqui .