Iniciando um exemplo
A seguir, escreveremos um aplicativo simples em java (o autor usou java 14, mas java 8 também serve), mediremos seu desempenho usando contadores dentro do aplicativo e tentaremos melhorar o resultado executando o código em vários threads. Tudo o que é necessário para reproduzir o exemplo é qualquer ambiente de desenvolvimento java ou apenas jdk e um utilitário visualvm que nos ajudará a diagnosticar os problemas que surgiram. O exemplo intencionalmente não usa vários benchmarks para medir o desempenho e outras ferramentas avançadas - neste caso, eles são supérfluos. O caso de teste foi executado no Windows em um processador Intel Core i7 com 4 núcleos físicos e 8 lógicos.
Então, vamos criar uma aplicação simples que, em loop, irá realizar uma tarefa computacional que onera o processador, ou seja, o cálculo do fatorial. Além disso, cada tarefa no loop também calculará o fatorial de um número no intervalo de 1 a 25. O intervalo flutuante é usado para trazer o exemplo mais perto da realidade. Abaixo está o código para a função work ():
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(RandomUtils.nextInt(1, 25));
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
A função recebe como entrada o número de ciclos para cálculo do fatorial, especificado por uma constante:
private static final int POWER_BASE = 1000000;Depois de completar um certo número de tarefas especificadas na variável
private static final int LOG_STEP = 10;O número de tarefas concluídas e o tempo total de sua execução são registrados
. A função work () também usa:
//
private long startTime;
//
private AtomicLong counter = new AtomicLong();
//
private long factorial(int power) {
if (power == 1) return power;
else return power * factorial(power - 1);
}
Deve-se notar que uma execução única da função work () em um thread leva cerca de 20 ms, portanto, uma chamada sincronizada para a variável de contador compartilhada no final, o que poderia ser um gargalo, não cria problemas, uma vez que acontece para cada thread não mais do que 20 vezes ms, que excede significativamente o tempo de execução de counter.incrementAndGet (). Em outras palavras, a contenção entre threads associados ao acesso a um contador sincronizado não deve afetar significativamente os resultados do experimento e pode ser negligenciada.
Vamos executar o seguinte código em um thread e ver o resultado:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
work(POWER_BASE);
}
No console, vemos a seguinte saída:
10 tarefas concluídas em 0 segundos
...
100 tarefas concluídas em 2 segundos
...
500 tarefas concluídas em 10 segundos
Então, em um thread, obtivemos um desempenho igual a 50 tarefas por segundo ou 20 ms por tarefa.
Paralelizando código
Se obtivermos o desempenho X em um thread, então em 4 processadores, na ausência de carga adicional, podemos esperar que o desempenho será de cerca de 4 * X, ou seja, aumentará 4 vezes. Parece bastante lógico. Bem, vamos tentar!
Vamos apresentar um pool simples com um número fixo de threads:
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
Constante:
private static final int POOL_SIZE = 1;Vamos mudar no intervalo de 1 a 16 e corrigir o resultado.
Redesenhando o código de lançamento:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Por padrão, o tamanho da fila de tarefas no pool de threads é Integer.MAX_VALUE, não adicionamos mais do que tarefas Integer.MAX_VALUE ao pool de threads, portanto, a fila de tarefas não deve estourar.
Ir!
Primeiro, vamos definir a constante POOL_SIZE para 8 threads:
private static final int POOL_SIZE = 8;execute o aplicativo e veja o console:
10 Tarefas concluídas em 3 segundos
20 Tarefas concluídas em 6 segundos
30 Tarefas concluídas em 8 segundos
40 Tarefas concluídas em 10 segundos
50 Tarefas concluídas em 14 segundos
60 Tarefas concluídas em 16 segundos
70 Tarefas concluídas em 19 segundos
80 Tarefas concluídas em 20 segundos
90 Tarefas concluídas em 23 segundos
100 Tarefas concluídas em 24 segundos
110 Tarefas concluídas em 26 segundos
120 Tarefas concluídas em 28 segundos
130 Tarefas concluídas em 29 segundos
140 Tarefas concluídas em 31 segundos
150 Tarefas concluídas em 33 segundos
160 Tarefas concluídas em 36 segundos
170 tarefas concluídas em 46 segundos
O que nós vemos? Em vez do aumento de desempenho esperado, caiu mais de 10 vezes de 20 ms por tarefa para 270 ms. Mas isso não é tudo! A mensagem sobre 170 tarefas concluídas é a última do log. Em seguida, o aplicativo parecia ter parado completamente.
Antes de lidar com as razões desse comportamento estranho do programa, vamos entender a dinâmica e remover o log sequencialmente para 4 e 16 threads, definindo a constante POOL_SIZE com os valores apropriados.
Log para 4 threads:
10 Tarefas concluídas em 2 segundos
20 Tarefas concluídas em 4 segundos
30 Tarefas concluídas em 6 segundos
40 Tarefas concluídas em 8 segundos
50 Tarefas concluídas em 10 segundos
60 Tarefas concluídas em 13 segundos
70 Tarefas concluídas em 15 segundos
80 tarefas concluídas em 18 segundos
90 tarefas concluídas em 21 segundos
100 tarefas concluídas em 33 segundos
As primeiras 90 tarefas concluídas aproximadamente no mesmo tempo que para 8 threads, depois outros 12 segundos foram necessários para concluir outras 10 tarefas e o aplicativo travou.
Log para 16 threads:
10 Tarefas concluídas em 2 segundos
20 Tarefas concluídas em 3 segundos
30 Tarefas concluídas em 6 segundos
40 Tarefas concluídas em 8 segundos
...
290 Tarefas concluídas em 51 segundos
300 Tarefas concluídas em 52 segundos
310 Tarefas concluídas em 63 segundos
Após a conclusão Para 310 tarefas, o aplicativo foi congelado e, como nos casos anteriores, as últimas 10 tarefas levaram mais de 10 segundos para serem concluídas.
Vamos resumir:
Paralelizar a execução de tarefas leva à degradação do desempenho em 10 ou mais vezes.
Em todos os casos, o aplicativo trava e quanto menos threads mais rápido ele trava (voltaremos a esse fato)
Procure por problemas
Obviamente, algo está errado com nosso código. Mas como você encontra o motivo? Para fazer isso, usaremos o utilitário visualvm. E vamos lançá-lo antes da execução de nosso aplicativo, e depois de lançar o aplicativo, mudaremos para o processo Java necessário na interface visualvm. O aplicativo pode ser iniciado diretamente do ambiente de desenvolvimento. Claro, isso geralmente está errado, mas em nosso exemplo não afetará o resultado.
Em primeiro lugar, olhamos para a guia Monitor e vemos que algo está errado com a memória.
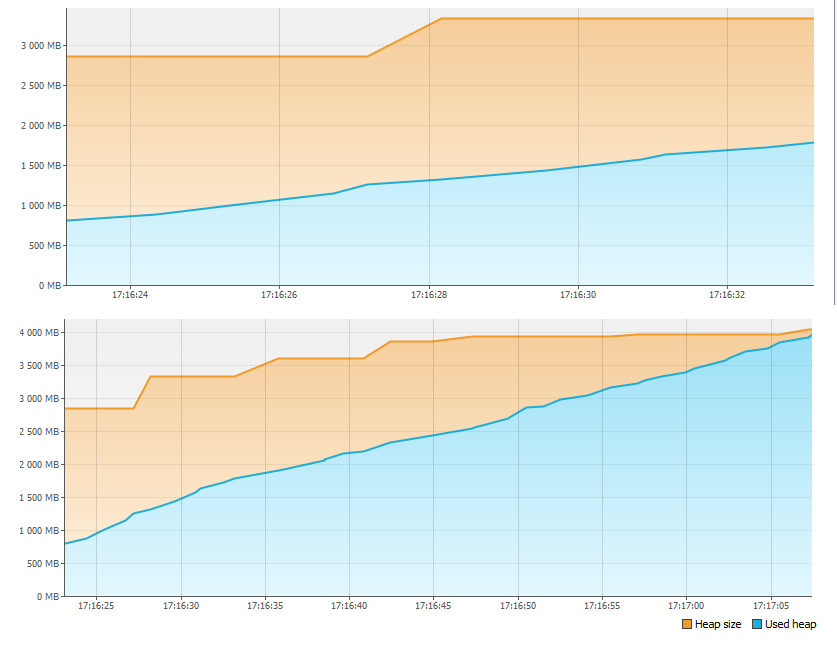
Em menos de um minuto, 4 GB de memória simplesmente acabaram! Portanto, o aplicativo foi interrompido. Mas para onde foi a memória?
Reinicie o aplicativo e pressione o botão Heap Dump na guia Monitor. Depois de remover e abrir o despejo de memória, vemos:

Na seção Classes por tamanho de instâncias, mais de 1 GB é ocupado pela classe LinkedBlockingQueue $ Node. Não é nada mais do que um topo da fila de tarefas do pool de threads. A segunda maior classe é a própria tarefa que está sendo adicionada ao pool de threads. Em apoio a isso, na seção Classes por número de instâncias, vemos a correspondência entre o número de instâncias da primeira e da segunda classes (a correspondência não é totalmente precisa, aparentemente devido ao fato de que primeiro é criada uma tarefa e, em seguida, apenas um novo topo da fila, e devido à diferença de tempo multiplicado pelo número de threads, temos uma pequena discrepância no número de instâncias).
Agora vamos contar. Criamos cerca de 2 bilhões de tarefas em loop (Integer.MAX_VALUE), ou seja, cerca de 2 GB de tarefas. As tarefas são executadas mais lentamente do que são criadas, portanto, o tamanho da fila continua crescendo. Mesmo que cada tarefa exigisse apenas 8 bytes de memória, o tamanho máximo da fila seria:
8 * 2 GB = 16 GB
Com um tamanho total de heap de 4 GB, não é surpreendente que não houvesse memória suficiente. Na verdade, se não interrompêssemos a execução da aplicação cujo log parou, depois de um tempo veríamos o famoso OutOfMemoryError e mesmo sem visualvm, apenas olhando o código, poderíamos adivinhar para onde vai a memória.
Vamos lembrar que quanto menor o número de threads executando as tarefas, mais rápido o aplicativo é interrompido. Agora podemos tentar explicar isso. Quanto menor o número de threads, mais rápido o aplicativo é executado (por quê - ainda precisamos descobrir) e mais rápido a fila de tarefas se enche e a memória fica cheia.
Bem, consertar o problema de estouro de memória é muito simples. Vamos criar uma constante em vez de Integer.MaxValue:
final estático privado int MAX_TASKS = 1024 * 1024;
E vamos mudar o código da seguinte maneira:
startTime = System.currentTimeMillis();
for (int i = 0; i < MAX_TASKS; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Agora resta executar o aplicativo e certificar-se de que tudo está em ordem com a memória:

Continuamos a análise
Lançamos nosso aplicativo novamente, aumentando sequencialmente o número de threads e corrigindo o resultado.
1 thread - 500 tarefas em 10 segundos
2 threads - 500 tarefas em 21 segundos
4 threads - 500 tarefas em 37 segundos
8 threads - 500 tarefas em 49 segundos
16 threads - 500 tarefas em 57 segundos
Como podemos ver, o tempo de execução de 500 tarefas aumenta o número de threads não diminui, mas aumenta; ao mesmo tempo, a velocidade de execução de cada porção de 10 tarefas é uniforme e as threads não congelam agora.
Vamos usar o utilitário visualvm novamente e fazer um despejo de thread enquanto o aplicativo está em execução. Para obter uma imagem mais precisa, é melhor fazer um despejo ao trabalhar em 16 threads. Existem diferentes utilitários para analisar despejos de thread, mas em nosso caso, você pode simplesmente rolar por todos os threads com os nomes "pool-1-thread-1", "pool-1-thread-2", etc. na interface visualvm e ver o seguinte:

No momento do despejo, a maioria dos threads gera o próximo número aleatório para calcular o fatorial. Acontece que esta é a função mais demorada. Porquê então? Para descobrir isso, vamos entrar no código-fonte de Random.next () e ver o seguinte:
private final AtomicLong seed;
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
Todos os encadeamentos compartilham uma única instância da variável inicial, cujo acesso é sincronizado usando a classe AtomicLong. Isso significa que, quando cada número aleatório é gerado, os threads são enfileirados para acessar essa variável, em vez de serem executados em paralelo. Portanto, a produtividade não cresce. Mas por que ela cai? A resposta é simples. Ao paralelizar a execução, recursos adicionais são gastos no suporte ao processamento paralelo, em particular, alternando o contexto do processador entre os threads. Acontece que surgiram custos adicionais e os threads ainda não funcionam em paralelo, uma vez que competem pelo acesso ao valor da variável seed e são enfileirados quando seed.compareAndSet () é chamado. Competição entre threads por um recurso limitado, talveza causa mais comum de degradação de desempenho ao paralelizar cálculos.
Vamos alterar o código da função work () da seguinte maneira:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(20);
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
e novamente verifique o desempenho em um número diferente de threads:
1 thread - 1000 tarefas em 17 segundos
2 threads - 1000 tarefas em 10 segundos
4 threads - 1000 tarefas em 5 segundos
8 threads - 1000 tarefas em 4 segundos
16 threads - 1000 tarefas em 4 segundos
Agora o resultado está próximo de nossas expectativas. O desempenho em 4 threads aumentou cerca de 4 vezes. Além disso, o aumento no desempenho praticamente parou porque a paralelização é limitada pelos recursos do processador. Vamos dar uma olhada nos gráficos de carga do processador, capturados por meio do visualvm ao trabalhar em 4 e 8 threads.

Como pode ser visto nos gráficos, com 4 threads, mais de 50% dos recursos do processador são gratuitos, e com 8 threads, o processador é usado quase 100%. Isso significa que, neste exemplo, 8 threads é o limite, o desempenho adicional apenas diminuirá. Em nosso exemplo, o crescimento do desempenho já parou em 4 threads, mas se os threads, em vez de calcular o fatorial, executassem E / S síncrona, então, provavelmente, o limite de paralelização no qual dá um ganho de desempenho poderia ser significativamente aumentado. Os leitores podem verificar isso por conta própria e escrever o resultado nos comentários do artigo.
Se falarmos sobre a prática, dois pontos importantes podem ser observados:
A paralelização é geralmente eficaz quando o número de threads é até 2 vezes o número de núcleos do processador (é claro, na ausência de outra carga do processador). A
utilização da CPU na prática não deve exceder 80% para garantir tolerância a falhas
Reduzindo a contenção entre threads
Nos empolgando com a conversa sobre performance, esquecemos uma coisa essencial. Alterando a chamada de RandomUtils.nextInt () no código para uma constante, alteramos a lógica de negócios de nosso aplicativo. Vamos voltar ao algoritmo antigo, evitando problemas de desempenho. Descobrimos que chamar RandomUtils.nextInt () faz com que cada um dos threads use a mesma variável de semente para gerar um número aleatório e, enquanto isso, isso é completamente opcional. Usando em nosso exemplo em vez de
RandomUtils.nextInt(1, 25)a classe ThreadLocalRandom:
ThreadLocalRandom.current().nextInt(1, 25)vai resolver o problema com a competição. Agora, cada thread usará sua própria instância da variável interna necessária para gerar o próximo número aleatório.
Usar uma variável separada para cada encadeamento, em vez de acesso sincronizado a uma única instância de uma classe compartilhada entre encadeamentos, é uma técnica comum para melhorar o desempenho reduzindo a contenção entre os encadeamentos. A classe java.lang.ThreadLocal pode ser usada para armazenar os valores das variáveis no contexto de um encadeamento, embora existam ferramentas mais avançadas, por exemplo, Mapped Diagnostic Context.
Concluindo, gostaria de observar que reduzir a competição entre threads não é apenas uma tarefa técnica, mas também lógica. Em nosso exemplo, cada thread pode usar sua própria instância de variável sem problemas, mas e se precisarmos de uma instância para todas, por exemplo, um contador compartilhado? Nesse caso, você teria que refatorar o próprio algoritmo. Por exemplo, armazene um contador no contexto de cada fluxo e, periodicamente ou mediante solicitação, calcule o valor do contador total com base nos valores dos contadores para cada fluxo.
Conclusão
Portanto, existem 3 pontos que afetam o desempenho do processamento paralelo:
- Recursos da CPU
- Competição entre tópicos
- Outros fatores que afetam indiretamente o resultado geral