
- O que exatamente está consumindo tanta memória?
- Existe alguma maneira de evitar isso?
Quero falar aqui sobre como estava procurando respostas para essas perguntas. Pretendo usar este material como referência sempre que precisar criar um perfil de código Python.
Comecei a analisar o Pylint, começando no ponto de entrada do programa (
pylint/__main__.py), e cheguei ao loop "fundamental" forque você esperaria em um programa que verifica vários arquivos:
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
Para começar, acabei de colocar uma instrução neste loop
print(«HI»)para ter certeza de que este é realmente o loop que começa quando eu executo o comando pylint my_code. Este experimento correu bem.
Em seguida, decidi descobrir o que exatamente está armazenado na memória durante o trabalho de Pylint. Então eu usei
heapye fiz um simples "despejo de pilha", na esperança de analisar esse despejo para algo incomum:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
O perfil de heap acabou consistindo quase inteiramente em quadros de pilha de chamadas (
types.FrameType). Eu, por algum motivo, esperava algo assim. A quantidade de objetos no depósito de lixo me fez pensar que parece haver mais deles do que deveria.
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
Foi neste momento que encontrei a ferramenta Profile Browser , que permite trabalhar comodamente com esses dados.
Eu configurei o mecanismo de dump para que os dados fossem gravados em um arquivo a cada 10 iterações de loop. Em seguida, construí um diagrama mostrando o comportamento do programa durante a operação.
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
Acabei com o que é mostrado abaixo. Este diagrama confirma que os objetos
type.FrameTypee type.TracebackType(informações de rastreamento) consumiram muita memória durante a execução do Pylint explorado.

Análise de dados
A próxima etapa do estudo foi a análise de objetos
types.FrameType. Como os mecanismos de gerenciamento de memória em Python são baseados na contagem do número de referências a objetos, os dados são mantidos na memória enquanto algo se refere a eles. Decidi descobrir o que exatamente "mantém" os dados na memória.
Aqui, usei uma excelente biblioteca
objgraphque, usando os recursos do gerenciador de memória Python, fornece informações sobre quais objetos estão na memória e permite que você descubra o que exatamente se refere a esses objetos.
Na verdade, é ótimo termos a capacidade de fazer esse tipo de pesquisa de software. Ou seja, se houver uma referência a um objeto, você pode encontrar tudo o que se refere a esse objeto (no caso das extensões C, nem tudo é tão suave, mas, em geral,
objgraphfornece informações razoavelmente precisas). Diante de nós está uma ótima ferramenta para depuração de código, dando acesso a muitas informações sobre os mecanismos internos do CPython. Para mim, esse é outro motivo para pensar no Python como uma linguagem agradável de se trabalhar.
No início, tropecei na busca de objetos, pois a equipe
objgraph.by_type('types.TracebackType')não encontrou nada. E isso apesar do fato de eu saber que existe um grande número de tais objetos. Descobriu-se que uma string deve ser usada como o nome do tipo traceback. A razão para isso não é totalmente clara para mim, mas o que é - isto é. O comando correto, no final, é assim:
random.choice(objgraph.by_type('traceback'))
Esta construção seleciona objetos aleatoriamente
traceback. E com a ajuda objgraph.show_backrefsvocê pode construir um diagrama do que se refere a esses objetos.
No final, em vez de apenas lançar uma exceção, decidi investigar o que acontece no loop
for( import pdb; pdb.set_trace()) após 100 iterações. Comecei a estudar objetos selecionados aleatoriamente traceback.
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
Inicialmente, eu vi apenas cadeias de objetos
traceback, então decidi escalar a uma profundidade de 100 objetos ...

Analisando objetos de rastreamento
Como se constatou, alguns objetos
tracebackreferem-se a outros objetos do mesmo tipo. Bem, ótimo. E havia muitas dessas cadeias.
Por algum tempo, sem muito sucesso para o negócio, estudei-os, e depois passei ao estudo de objetos do segundo tipo de interesse para mim -
FrameType(frame). Eles também pareciam suspeitos. Analisando-os, cheguei a diagramas que se assemelham ao seguinte.

Analisando objetos de quadro
Acontece que os objetos
tracebackcontêm objetosframe(portanto, há um número semelhante de tais objetos). Tudo isso, é claro, parece extremamente confuso, mas os objetosframepelo menos apontam para linhas específicas de código. Tudo isso me levou a perceber uma coisa ridiculamente simples: nunca me preocupei em olhar para dados usando uma quantidade tão grande de memória. Definitivamente, devo olhar para os próprios objetostraceback.
Caminhei em direção a esse objetivo, ao que parece, o mais tortuoso de todos os caminhos possíveis. Ou seja, ele reconheceu os endereços no dump criado por
objgraph, em seguida, olhou para os endereços na memória e procurou na Internet "como obter um objeto Python, sabendo seu endereço". Depois de todos esses experimentos, criei o seguinte esquema de ações:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
Na verdade, você pode simplesmente dizer ao Python: “Olhe para esta memória. Definitivamente, há pelo menos um objeto Python regular aqui. "
Mais tarde percebi que já tinha links para objetos de meu interesse graças aos
objgraph. Isto é - eu poderia simplesmente usá-los.
Parecia que a biblioteca
astroid, o analisador AST usado no Pylint, estava criando objetos em todos os lugares tracebackpor meio do código de tratamento de exceção. Suponho que quando algo é usado em algum lugar que pode ser chamado de "truque interessante", então, ao longo do caminho, eles se esquecem de como o mesmo pode ser feito mais facilmente. Então eu realmente não reclamo disso.
Os objetos
tracebacktêm muitos dados relacionados astroid. Houve algum progresso em minha pesquisa! Bibliotecaastroidé bastante semelhante a um programa que pode armazenar grandes quantidades de dados na memória, uma vez que analisa arquivos.
Eu vasculhei o código e encontrei as seguintes linhas no arquivo
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
“É isso”, pensei, “é exatamente isso que estou procurando!” É uma sequência de exceções que resulta nas cadeias mais longas de objetos
traceback. E aqui, entre outras coisas, os arquivos são analisados, então mecanismos recursivos também podem ser encontrados aqui. E algo que lembra uma construção raise thing from other_thingune tudo.
Eu removi
from exe ... nada aconteceu. A quantidade de memória consumida pelo programa permaneceu praticamente a mesma, os objetos tracebacktambém não foram a lugar nenhum.
Eu estava ciente de que as exceções armazenam suas ligações locais em objetos
traceback, para que você possa acessar ex. Como resultado, a memória deles não pode ser apagada.
Fiz uma refatoração massiva do código, tentando basicamente me livrar do bloco
except, ou pelo menos de um link para ex. Mas, novamente, não recebi nada. Mesmo
estourando, não consegui "incitar" o coletor de lixo nos objetos
traceback, mesmo considerando que não havia referências a esses objetos. Achei que a razão para isso era que havia algum outro link em algum lugar.
Na verdade, eu peguei uma pista falsa naquela época. Eu não sabia se essa era a causa do vazamento de memória, porque em um ponto comecei a perceber que não tinha nenhuma evidência para apoiar minha "teoria das cadeias de exceção". Eu só tinha um monte de suposições e milhões de objetos
traceback.
Então comecei a olhar para esses objetos ao acaso em busca de algumas pistas adicionais. Tentei “escalar” manualmente a cadeia de elos, mas no final só encontrei o vazio.
Então me ocorreu: todos esses objetos
tracebackestão localizados "um acima do outro", mas deve haver um objeto que está "acima" de todos os outros. Aquele que não é referenciado por nenhum dos outros objetos.
Os links foram feitos por meio de uma propriedade
tb_next, a sequência de tais links era uma cadeia simples. Então decidi dar uma olhada nos objetos tracebackno final das respectivas cadeias:
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
Há algo mágico em abrir caminho por meio de meio milhão de objetos com uma linha e encontrar o que você precisa.
Em geral, encontrei o que procurava. Encontrou a razão pela qual o Python teve que manter todos esses objetos na memória.

Encontrando a origem do problema
Tudo se resumia ao cache de arquivos!
A questão é que a biblioteca
astroidarmazena em cache os resultados dos módulos de carregamento. Se o código precisa de um módulo que já foi usado, a biblioteca simplesmente fornecerá o resultado do carregamento desse módulo que ele já possui. Isso também leva à reprodução de erros, armazenando as exceções lançadas.
Nesse ponto, tomei uma decisão ousada, raciocinando assim: “Faz sentido armazenar em cache algo que não contém erros. Mas, na minha opinião, não adianta armazenar objetos
tracebackgerados pelo nosso código. "
Decidi me livrar da exceção, manter minha própria classe
Errore apenas reconstruir as exceções quando necessário. Os detalhes podem ser encontrados nestePR, mas realmente acabou não sendo particularmente interessante.
Como resultado, consegui reduzir o consumo de memória ao trabalhar com nossa base de código de 500 MB para 100 MB.
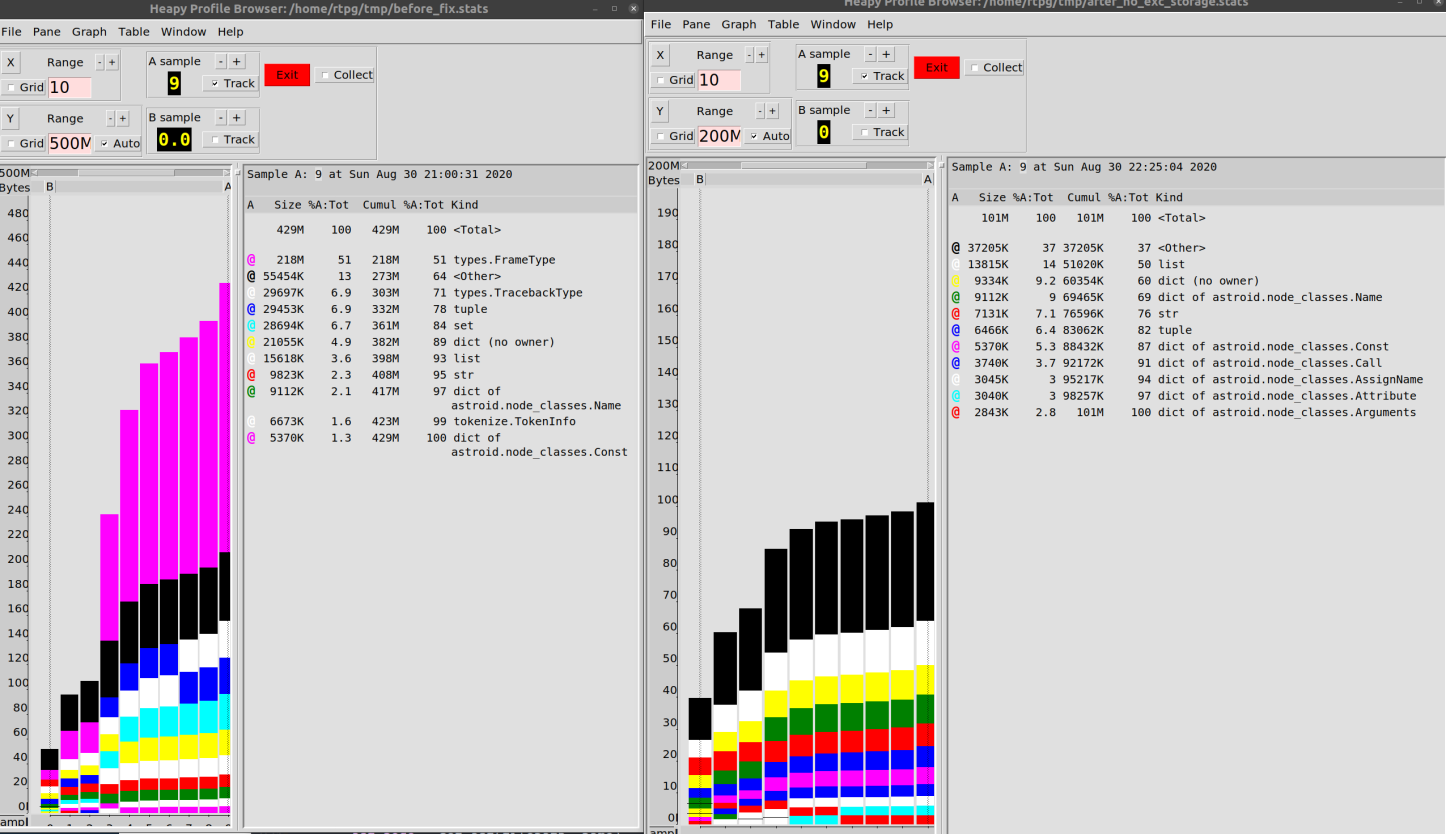
Eu diria que 80% de melhoria não é tão ruim, por
falar em RP, não tenho certeza se vai ser incluída no projeto. As mudanças que ele traz em si não estão apenas relacionadas ao desempenho. Acredito que o modo como funciona pode, em algumas situações, reduzir o valor dos dados de rastreamento de pilha. Considerando todos os detalhes, esta é uma mudança bastante grosseira, embora esta solução passe em todos os testes.
Como resultado, tirei as seguintes conclusões para mim:
- Python nos oferece excelentes recursos de análise de memória. Devo usar esses recursos com mais frequência ao depurar código.
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
Enquanto escrevia isso, percebi que já havia esquecido muito do que me permitiu chegar a certas conclusões. Então, acabei verificando alguns dos trechos de código novamente. Em seguida, executei as medições em uma base de código diferente e descobri que peculiaridades de memória são específicas para apenas um projeto. Passei muito tempo procurando e consertando esse incômodo, mas é muito provável que seja apenas uma característica do comportamento das ferramentas que usamos, que se manifesta apenas em um pequeno número de pessoas que usam essas ferramentas.
É muito difícil dizer algo definitivo sobre o desempenho, mesmo depois de fazer essas medições.
Tentarei transferir a experiência adquirida com os experimentos que descrevi para outros projetos. Acredito que haja muitos desses problemas de desempenho em projetos Python de código aberto que são fáceis de corrigir. O fato é que a comunidade de desenvolvedores Python geralmente dá relativamente pouca atenção a esse problema (isto é - se não falarmos sobre projetos que são extensões para Python, escritos em C).
Você já teve que otimizar o desempenho do seu código Python?

