

Novo cenário de dados - novo armazenamento de dados
A intensidade da manipulação de dados está aumentando em todos os setores. E o setor bancário é uma ilustração clara disso. Nos últimos anos, o número de transações bancárias aumentou mais de dez vezes. Como mostra a pesquisa do BCG , só na Rússia, no período de 2010 a 2018, o número de transações que não em dinheiro usando cartões de plástico cresceu mais de trinta vezes - de 5,8 para 172 por pessoa por ano. A questão é, em primeiro lugar, o triunfo dos micropagamentos: a maioria de nós se tornou parecido com o banco online e o banco agora está à mão - pelo telefone.
A infraestrutura de TI de uma instituição de crédito deve estar preparada para esse desafio. E isso é realmente um desafio. Entre outras coisas, se antes o banco precisava garantir a disponibilidade dos dados apenas durante o horário de expediente, agora é 24/7. Até recentemente, 5ms era considerado uma norma aceitável para latência, e daí? Agora, até 1 ms é demais. Para um sistema de armazenamento moderno, a meta é 0,5 ms.
O mesmo acontece com a confiabilidade: na década de 2010, formou-se um entendimento empírico de que bastava trazer seu patamar para as “cinco dúzias” - 99,999%. É verdade que esse entendimento ficou desatualizado. Em 2020, é absolutamente normal que as empresas exijam 99,9999% para armazenamento e 99,99999% para arquitetura geral. E isso não é um capricho, mas uma necessidade urgente: ou não há janela de tempo para manutenção da infraestrutura, ou ela é minúscula.

Para maior clareza, é conveniente projetar esses indicadores no plano do dinheiro. A maneira mais fácil é por meio do exemplo de instituições financeiras. O diagrama acima mostra quanto cada um dos 10 principais bancos mundiais ganha em uma hora. Somente para o Banco Industrial e Comercial da China, isso é nada menos que US $ 5 milhões. Exatamente quanto custará uma hora de inatividade da infraestrutura de TI da maior instituição de crédito da China (e apenas os lucros cessantes são levados em consideração no cálculo!). Dessa perspectiva, é claro que reduzir o tempo de inatividade e aumentar a confiabilidade, não apenas em alguns por cento - mesmo em uma fração de um por cento, são totalmente justificados de forma racional. Não só para aumentar a competitividade, mas também simplesmente para manter as posições no mercado.
Mudanças comparáveis estão ocorrendo em outras indústrias. Por exemplo, nas viagens aéreas: antes da pandemia, o tráfego aéreo só ganhava impulso de ano para ano, e muitos passaram a usá-lo quase como um táxi. Quanto aos padrões de consumo, a sociedade tem um hábito profundamente arraigado de acessibilidade total dos serviços: ao chegar ao aeroporto, precisamos de uma conexão wi-fi, acesso a serviços de pagamento, mapa da área, etc. Conseqüentemente, a carga de infraestrutura e serviços em espaços públicos aumentou muitas vezes. E as abordagens para isso, infraestrutura, construção, que considerávamos aceitáveis até mesmo um ano atrás, estão rapidamente se tornando obsoletas.

É muito cedo para mudar para All-Flash?
Para resolver os problemas mencionados acima, do ponto de vista do desempenho do AFA, arrays totalmente em flash, ou seja, arrays totalmente construídos em flash, são os mais adequados. A menos que, até recentemente, persistissem dúvidas sobre se eles são comparáveis em confiabilidade com aqueles montados na base de HDD e com os híbridos. Afinal, o flash de estado sólido tem uma métrica como o tempo médio entre falhas ou MTBF. A degradação de células devido a operações de I / O, infelizmente, é um dado adquirido.
Portanto, a perspectiva do All-Flash foi ofuscada pela questão de como evitar a perda de dados no caso de SSDs precisarem durar muito. Fazer backup é uma opção comum, mas o tempo de recuperação seria inaceitavelmente longo com base nos requisitos modernos. Outra saída é estabelecer um segundo nível de armazenamento nas unidades de eixo, mas esse esquema perde algumas das vantagens de um sistema "estritamente flash".
No entanto, os números dizem o contrário: estatísticas dos gigantes da economia digital, incluindo o Google, mostraram nos últimos anos que o flash é várias vezes mais confiável do que os discos rígidos. Além disso, tanto por um curto período de tempo quanto por um longo período: em média, leva de quatro a seis anos antes que os flash drives falhem. Em termos de confiabilidade de armazenamento de dados, eles não são de forma alguma inferiores aos drives em discos magnéticos de eixo, ou mesmo os superam.
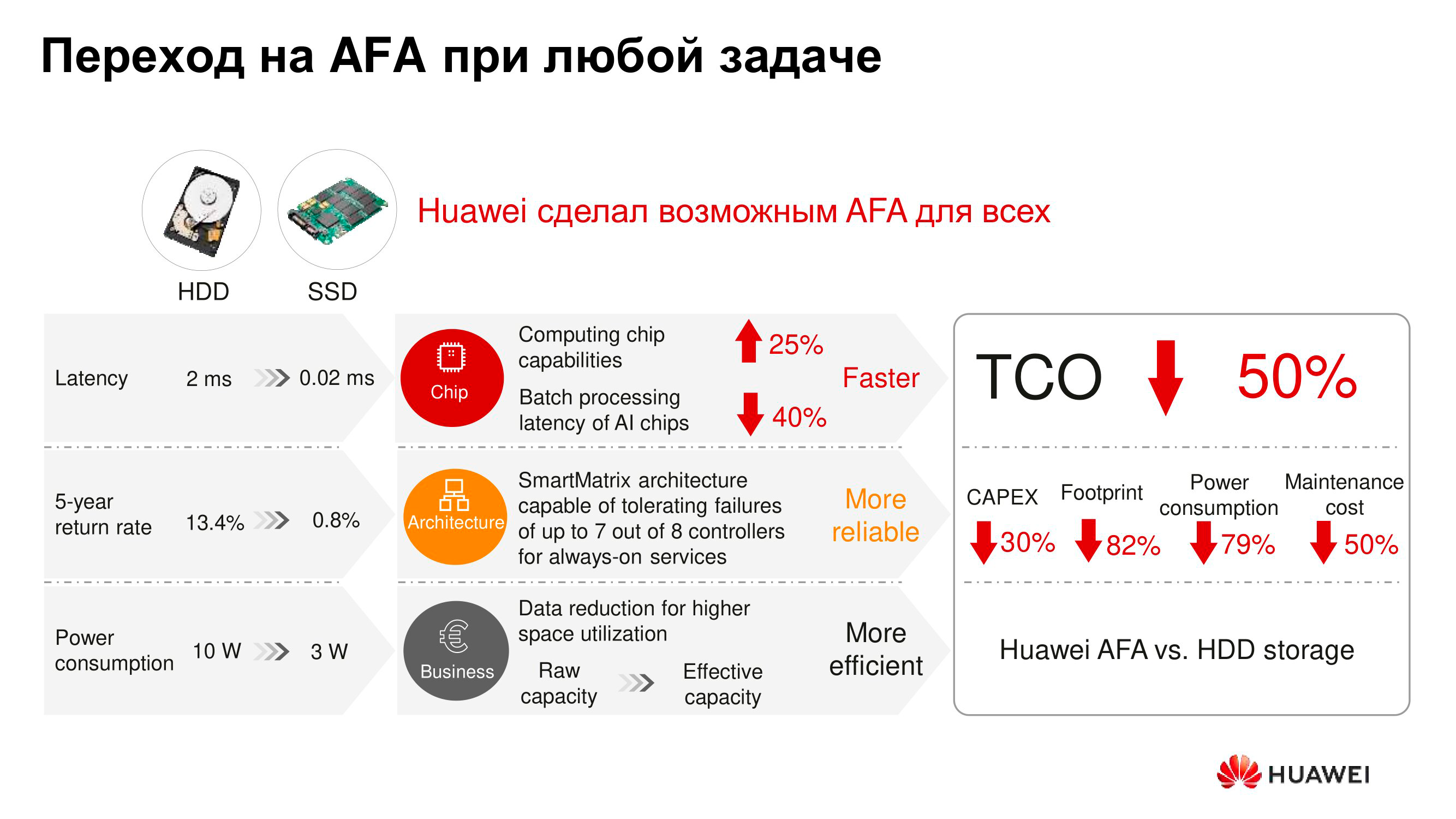
Outro argumento tradicional a favor dos acionamentos do fuso é sua acessibilidade. Não há dúvida de que o custo de armazenamento de um terabyte em um disco rígido ainda é relativamente baixo. E se você levar em conta apenas o custo do hardware, manter um terabyte em uma unidade de eixo é mais barato do que em uma unidade de estado sólido. No entanto, no contexto do planejamento financeiro, importa não apenas quanto um determinado dispositivo foi comprado, mas também qual é o custo total de possuí-lo por um longo tempo - de três a sete anos.
Deste ponto de vista, tudo é completamente diferente. Mesmo que deixemos de fora dos colchetes a desduplicação e a compressão, que, via de regra, são utilizadas em flash arrays e tornam sua operação mais rentável economicamente, características como espaço em rack ocupado por portadoras, dissipação de calor e consumo de energia permanecem. E, segundo eles, o flush vence seus predecessores. Como resultado, o TCO dos sistemas de armazenamento flash, levando em consideração todos os parâmetros, costuma ser quase a metade do que no caso de arrays em drives de fuso ou com híbridos.
De acordo com os relatórios do ESG, os sistemas de armazenamento Dorado V6 All-Flash podem realmente atingir uma redução de 78% no custo de propriedade em um intervalo de cinco anos - incluindo desduplicação e compactação eficientes e baixo consumo de energia e dissipação de calor. A empresa analítica alemã DCIG também os recomenda para uso como o TCO ideal disponível atualmente.
O uso de drives de estado sólido permite economizar espaço utilizável, reduzir o número de falhas, reduzir o tempo de manutenção da solução e reduzir o consumo de energia e a dissipação de calor do sistema de armazenamento. E acontece que o AFA em termos econômicos é pelo menos comparável aos arrays tradicionais em drives de fuso, mas freqüentemente os supera.

Royal Flush da Huawei
Entre nossos estoques All-Flash, o primeiro lugar pertence ao sistema hi-end OceanStor Dorado 18000 V6. E não só entre os nossos: na indústria como um todo, detém o recorde de velocidade - até 20 milhões de IPOS na configuração máxima. Além disso, é extremamente confiável: mesmo se dois controladores voarem ao mesmo tempo, ou até sete controladores um após o outro, ou um motor inteiro de uma vez, os dados sobreviverão. Uma grande vantagem do "dezoito milésimo" é dada pela IA conectada a ele, incluindo a flexibilidade no gerenciamento de processos internos. Vamos ver como tudo isso é feito.

Em grande medida, a Huawei está na frente porque é o único fabricante no mercado que faz os próprios sistemas de armazenamento de dados - completa e completamente. Temos nosso próprio circuito, nosso próprio microcódigo, nosso próprio serviço.
O controlador nos sistemas OceanStor Dorado é construído no Kunpeng 920, um processador Huawei proprietário e fabricado, que usa o Intelligent Baseboard Management Controller (iBMC), também nosso. Os chips AI, nomeadamente o Ascend 310, que otimizam as previsões de falhas e dão recomendações sobre as configurações, também são huavean, assim como as placas I / O - o módulo I / O Smart. Finalmente, os controladores em drives de estado sólido são projetados e fabricados por nós. Tudo isso forneceu a base para fazer uma solução integralmente equilibrada e de alto desempenho.

, . 40 OceanStor Dorado 18000 V6 metro- : IOPS, - .

NVMe
Os sistemas de armazenamento mais recentes da Huawei suportam NVMe ponta a ponta, no qual estamos nos concentrando por uma razão. Os protocolos de acesso ao armazenamento usados tradicionalmente foram desenvolvidos na antiguidade de TI: eles são baseados em comandos SCSI (olá, anos 1980!), Que trazem consigo várias funções para garantir compatibilidade com versões anteriores. Qualquer que seja o método de acesso que você use, a sobrecarga do protocolo é colossal neste caso. Como resultado, os armazenamentos que usam protocolos relacionados a SCSI têm latência de E / S que não pode ser inferior a 0,4–0,5 ms. Por sua vez, sendo um protocolo criado para trabalhar com memória flash e se livrar de muletas em prol da notória compatibilidade com versões anteriores, NVMe - Non-Volatile Memory Express - reduz a latência para 0,1 ms, além disso, não em sistemas de armazenamento, mas em toda a pilha, de hospedeiro para unidades. Não é surpreendente,que o NVMe está alinhado com as tendências de desenvolvimento de armazenamento de dados para um futuro previsível. Também apostamos no NVMe - e estamos gradualmente nos afastando do SCSI. Todos os sistemas de armazenamento Huawei produzidos hoje, incluindo a linha Dorado, suportam NVMe (embora, de ponta a ponta, seja implementado apenas nos modelos avançados da série Dorado V6).

FlashLink: um punhado de tecnologia
A tecnologia fundamental para toda a linha OceanStor Dorado é o FlashLink. Mais precisamente, é um termo que engloba um conjunto integral de tecnologias que servem para garantir alto desempenho e confiabilidade. Isso inclui tecnologias de desduplicação e compactação, o funcionamento do sistema de distribuição de dados RAID 2.0+, separação de dados "frios" e "quentes", gravação sequencial de dados completos (gravações aleatórias, com dados novos e modificados, são agregadas em uma grande pilha e gravadas sequencialmente, o que aumenta a velocidade ler escrever).
Entre outras coisas, FlashLink inclui dois componentes importantes - Nivelamento de desgaste e Coleta de lixo global. Vale a pena estudá-los separadamente.
Praticamente qualquer SSD é um sistema de armazenamento em miniatura com um grande número de blocos e um controlador que garante a disponibilidade dos dados. E é fornecido, entre outras coisas, devido ao fato de que os dados das células "mortas" são transferidos para as "não mortas". Isso garante que eles possam ser lidos. Existem vários algoritmos para esta transferência. Em geral, o controlador tenta equilibrar o desgaste de todas as células de armazenamento. Essa abordagem tem uma desvantagem. Quando os dados se movem dentro de um SSD, o número de operações de E / S que ele executa é drasticamente reduzido. No momento, este é um mal necessário.
Assim, se o sistema tiver muitos drives de estado sólido, uma "serra" aparecerá no gráfico de seu desempenho, com altos e baixos acentuados. O problema é que qualquer unidade do pool pode iniciar a migração de dados a qualquer momento e o desempenho geral é removido de todos os SSDs no array. Mas os engenheiros da Huawei descobriram como evitar a "serra".
Felizmente, os controladores nas unidades e o controlador de armazenamento e o microcódigo da Huawei são "nativos", esses processos no OceanStor Dorado 18000 V6 são iniciados centralmente, de forma síncrona em todas as unidades do array. Além disso, ao comando do controlador de armazenamento e precisamente quando não há carga pesada no I / O.
: , -, , , : Wear Leveling, .
Além disso, o controlador do sistema vê o que está acontecendo em cada célula da unidade, em contraste com os sistemas de armazenamento de fabricantes concorrentes: eles são forçados a comprar mídia de estado sólido de fornecedores terceirizados, razão pela qual o detalhamento em nível de célula não está disponível para os controladores de tais armazenamentos.
Como resultado, o OceanStor Dorado 18000 V6 tem um período muito curto de perda de desempenho durante o Nivelamento de Desgaste e é executado principalmente quando nenhum outro processo sofre interferência. Isso proporciona um desempenho alto e consistente em uma base consistente.

O que torna o OceanStor Dorado 18000 V6 confiável
Em sistemas modernos de armazenamento de dados, quatro níveis de confiabilidade são distinguidos:
- hardware, no nível do drive;
- arquitetônico, no nível do equipamento;
- arquitetura junto com a parte do software;
- cumulativo, referindo-se à decisão como um todo.
Já que, como lembramos, nossa empresa projeta e fabrica todos os componentes do próprio sistema de armazenamento, garantimos confiabilidade em cada um dos quatro níveis, com a capacidade de rastrear minuciosamente o que está acontecendo em cada um deles no momento.

A confiabilidade das unidades é garantida principalmente pelo Nivelamento de Desgaste e Coleta de Lixo Global descritos anteriormente. Quando um SSD parece uma caixa preta para o sistema, ele não tem ideia de como as células se desgastam nele. Para o OceanStor Dorado 18000 V6, as unidades são transparentes, o que torna possível equilibrar uniformemente todas as unidades no array. Assim, acaba estendendo significativamente a vida útil dos SSDs e garantindo um alto nível de confiabilidade de sua operação.

Além disso, células redundantes adicionais afetam a confiabilidade da unidade. E junto com uma reserva simples no sistema de armazenamento, são utilizadas as chamadas células DIF, que contêm somas de verificação, bem como códigos adicionais para salvar cada bloco de um único erro, além de proteção no nível do array RAID.

A solução SmartMatrix é a chave para a confiabilidade arquitetônica. Resumindo, são quatro controladores que ficam em um backplane passivo como parte de um motor. Dois desses motores - respectivamente, com oito controladores - são conectados a prateleiras comuns com drives. Graças ao SmartMatrix, mesmo que sete controladores de oito parem de funcionar, o acesso a todos os dados, tanto de leitura quanto de gravação, permanece. E se você perder seis dos oito controladores, pode até continuar com o cache.

As placas de E / S no mesmo backplane passivo estão disponíveis para todos os controladores, front-end e back-end. Com este esquema de conexão full-mesh, não importa o que falhe, o acesso às unidades é sempre preservado.

É mais apropriado falar sobre a confiabilidade da arquitetura no contexto de cenários de falha contra os quais o sistema de armazenamento pode se proteger.
O armazenamento sobreviverá à situação sem perdas caso dois controladores "caiam", inclusive simultaneamente. Tal estabilidade é alcançada devido ao fato de que qualquer bloco de cache certamente possui mais duas cópias em controladores diferentes, ou seja, no total existe em três cópias. E pelo menos um está em um motor diferente. Assim, mesmo que todo o motor pare de funcionar - com todos os seus quatro controladores - é garantido que todas as informações que estavam na memória cache serão guardadas, pois o cache ficará duplicado em pelo menos um controlador do motor restante. Finalmente, com uma conexão em cadeia, você pode perder até sete controladores e mesmo se eles forem eliminados em blocos de dois - e novamente, todas as E / S e todos os dados da memória cache serão salvos.

Quando comparado com armazenamentos de última geração de outros fabricantes, pode-se ver que apenas a Huawei fornece proteção completa de dados e disponibilidade total, mesmo após a morte de dois controladores ou do motor inteiro. A maioria dos fornecedores usa um circuito com os chamados pares de controladores aos quais as unidades são conectadas. Infelizmente, nesta configuração, se dois controladores falharem, há o risco de perder o acesso de E / S ao drive.

Infelizmente, a falha de um único componente não é objetivamente excluída. Nesse caso, o desempenho ficará lento por algum tempo: é necessário reconstruir os caminhos e retomar o acesso para operações de I / O relativos aos blocos que vieram para gravação, mas ainda não foram gravados, ou foram solicitados para leitura. O OceanStor Dorado 18000 V6 tem um tempo médio de reconstrução de aproximadamente um segundo - significativamente menos do que seu análogo mais próximo da indústria (4 segundos). Isso é conseguido graças ao mesmo backplane passivo: quando o controlador falha, os outros vêem imediatamente sua entrada-saída e, em particular, qual bloco de dados não foi adicionado; como resultado, o controlador mais próximo pega o processo. Daí a capacidade de restaurar o desempenho em apenas um segundo. Deve-se acrescentar que o intervalo é estável: um segundo por controlador,segundo para outro, etc.

No painel traseiro passivo OceanStor Dorado 18000 V6, todas as placas estão disponíveis para todos os controladores sem qualquer endereçamento adicional. Isso significa que qualquer controlador é capaz de captar E / S em qualquer porta. Qualquer que seja a porta de I / O de front-end, o controlador estará pronto para trabalhar. Conseqüentemente - o número mínimo de transferências internas e uma notável simplificação do equilíbrio.
O balanceamento de front-end é realizado usando o driver multipathing, e o balanceamento é adicionalmente realizado dentro do próprio sistema, uma vez que todos os controladores veem todas as portas de E / S.

Tradicionalmente, todos os arrays da Huawei são projetados de forma que não tenham um único ponto de falha. Todos os seus componentes podem ser substituídos "quentes" sem reiniciar o sistema: controladores, módulos de energia, módulos de refrigeração, placas de E / S, etc.

Uma tecnologia como RAID-TP também melhora a confiabilidade do sistema como um todo. Este é o nome de um grupo de RAID que permite que você se proteja contra a falha simultânea de até três unidades. Além disso , uma reconstrução de 1 TB leva consistentemente menos de 30 minutos. Melhores resultados registrados - oito vezes mais rápido do que com a mesma quantidade de dados em uma unidade de eixo. Assim, é possível usar drives extremamente amplos, digamos, 7,68 ou até 15 TB, e não se preocupar com a confiabilidade do sistema.
É importante que a reconstrução seja realizada não na unidade sobressalente, mas no espaço sobressalente - a capacidade de reserva. Cada unidade tem espaço de armazenamento dedicado usado para recuperação de desastres. Assim, a restauração é realizada não de acordo com o esquema "muitos para um", mas sim de acordo com o esquema "muitos para muitos", pelo qual é possível acelerar significativamente o processo. E enquanto houver capacidade livre, a recuperação pode continuar.

Separadamente, deve ser feita menção à confiabilidade de uma solução de vários storages - em um metro-cluster ou, na terminologia da Huawei, HyperMetro. Esses esquemas são suportados em toda a gama de modelos de nossos sistemas de armazenamento de dados e podem funcionar com acesso a arquivo e bloco. Além disso, no bloco ele funciona via Fibre Channel e Ethernet (incluindo iSCSI).
Basicamente, estamos falando sobre a replicação bidirecional de um sistema de armazenamento para outro, em que o LUN replicado é atribuído ao mesmo LUN-ID do principal. A tecnologia funciona principalmente devido à consistência dos caches de dois sistemas diferentes. Assim, para o host, é absolutamente tudo o mesmo de que lado está: aqui e ali, ele vê o mesmo disco lógico. Como resultado, nada impede que você implante um cluster de failover abrangendo dois sites.
Para quorum, uma máquina Linux física ou virtual é usada. Ele pode ser localizado no terceiro site e os requisitos para seus recursos são pequenos. Um cenário comum é alugar um site virtual exclusivamente para hospedar uma VM de quorum.
A tecnologia também permite a expansão: dois storages - em um metro-cluster, uma plataforma adicional - com replicação assíncrona.

Historicamente, muitos clientes formaram um "zoológico de armazenamento": um monte de sistemas de armazenamento de diferentes fabricantes, diferentes modelos, diferentes gerações, com diferentes funcionalidades. No entanto, o número de hosts pode ser impressionante e geralmente são virtualizados. Nessas condições, uma das tarefas prioritárias da administração é fornecer de forma rápida, uniforme e conveniente discos lógicos para hosts, de preferência de forma a não se aprofundar onde esses discos estão fisicamente localizados. É exatamente para isso que se destina a nossa solução de software OceanStor DJ, que pode unificar o gerenciamento de vários sistemas de armazenamento e fornecer serviços a partir deles sem estar vinculado a um modelo de armazenamento específico.

Mesmo e AI
Como já mencionado, o OceanStor Dorado 18000 V6 possui processadores integrados com algoritmos de inteligência artificial - Ascend. Eles são usados, em primeiro lugar, para prever falhas e, em segundo lugar, para formar recomendações de ajuste, o que também aumenta o desempenho e a confiabilidade do armazenamento.
O horizonte de previsão é de dois meses: o mecanismo de IA assume que provavelmente acontecerá durante este tempo, é hora de fazer uma extensão, alterar as políticas de acesso, etc. As recomendações são fornecidas com antecedência, o que permite janelas de planejamento para a manutenção do sistema com antecedência.
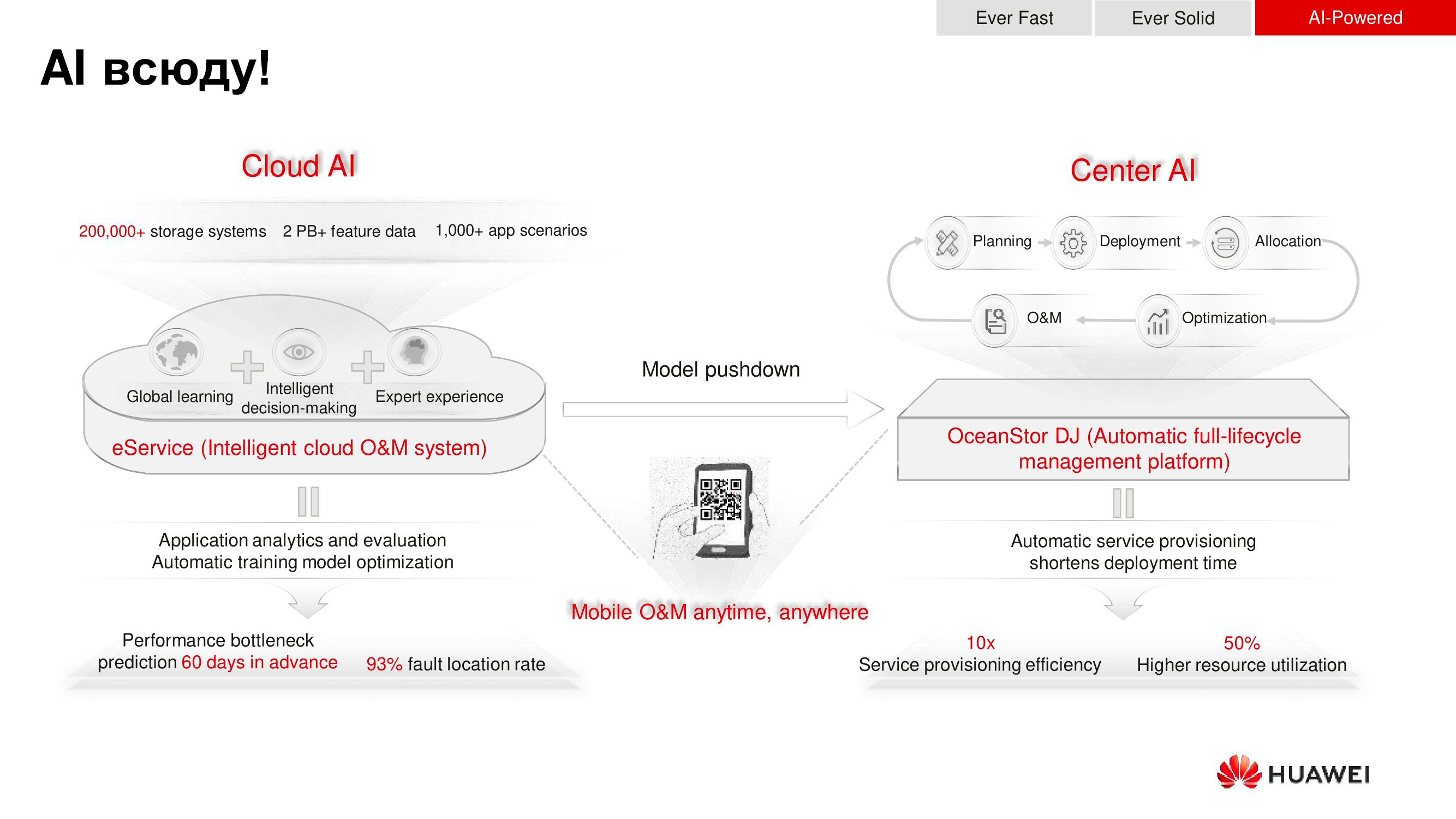
O próximo estágio no desenvolvimento de IA da Huawei envolve trazê-lo para o nível global. Durante o serviço - failover ou recomendação - a Huawei agrega informações dos sistemas de registro de todos os repositórios de nossos clientes. Com base nos dados coletados, uma análise das falhas ocorridas ou potenciais é realizada e recomendações globais são feitas - baseadas não no funcionamento de um sistema de armazenamento específico ou mesmo uma dúzia, mas no que está acontecendo e acontecendo com milhares de tais dispositivos. A amostra é enorme e, com base nela, os algoritmos de IA começam a aprender extremamente rápido, o que torna as previsões mais precisas.
Compatibilidade

Em 2019-2020, houve muitas insinuações sobre como nosso hardware interage com os produtos VMware. Para finalmente detê-los, declaramos com responsabilidade: A VMware é parceira da Huawei. Foram realizados todos os testes imagináveis de compatibilidade do nosso hardware com o seu software e, como resultado, no site da VMware na lista de compatibilidade de hardware, os sistemas de armazenamento atualmente disponíveis da nossa produção são indicados sem quaisquer reservas. Em outras palavras, com o ambiente de software VMware, você pode usar o armazenamento Huawei, incluindo Dorado V6, com suporte total.

O mesmo se aplica à nossa colaboração com a Brocade. Continuamos a interagir e a conduzir testes de interoperabilidade para nossos produtos para garantir que nossos sistemas de armazenamento sejam totalmente interoperáveis com os switches Brocade FC mais recentes.

Qual é o próximo?
Continuamos a desenvolver e melhorar nossos processadores: eles se tornam mais rápidos, mais confiáveis, seu desempenho está crescendo. Também estamos aprimorando os chips de IA - com base neles, entre outras coisas, são produzidos módulos que aceleram a desduplicação e a compactação. Quem tem acesso ao nosso configurador deve ter notado que nos modelos Dorado V6 essas placas já estão disponíveis para encomenda.
Também estamos avançando para o cache adicional na memória de classe de armazenamento - memória não volátil com latências especialmente baixas, cerca de dez microssegundos por leitura. Entre outras coisas, o SCM aumenta o desempenho, especialmente ao trabalhar com big data e ao resolver tarefas OLTP. Após a próxima atualização, os cartões SCM devem estar disponíveis para pedido.
E, claro, a funcionalidade de acesso a arquivos continuará a se expandir por toda a gama de armazenamento de dados da Huawei - fique atento às nossas atualizações.