Segundo a crença popular, extrair texto de PDFs não deveria ser tão difícil. Afinal, aqui está o texto, bem diante dos nossos olhos, e as pessoas constantemente e com grande sucesso percebem o conteúdo do PDF. De onde vem a dificuldade na extração automática de texto?
Acontece que, assim como trabalhar com nomes de pessoas é difícil para algoritmos devido a muitos casos extremos e suposições incorretas, trabalhar com PDF é difícil devido à extrema flexibilidade do formato PDF.
O principal problema é que o PDF não foi concebido como um formato para entrada de dados - foi desenvolvido como um canal de saída, permitindo o ajuste fino da aparência do documento final.
Basicamente, o formato PDF consiste em um fluxo de instruções que descrevem como uma imagem é criada em uma página. Em particular, os dados de texto não são armazenados como parágrafos - ou mesmo palavras - mas como caracteres desenhados em locais específicos da página. Como resultado, ao converter texto ou documento do Word em PDF, a maior parte da semântica do conteúdo é perdida. Toda a estrutura interna do texto se transforma em uma sopa amorfa de personagens flutuando na página.
Ao preencher FilingDB, extraímos dados de texto de dezenas de milhares de documentos PDF. No processo, observamos como todas as nossas suposições sobre a estrutura dos arquivos PDF se revelaram erradas. Nossa missão foi especialmente difícil porque tivemos que processar documentos PDF vindos de fontes diferentes com estilos, fontes e aparências completamente diferentes.
A seguir está uma descrição dos recursos dos arquivos PDF que tornam difícil ou até mesmo impossível extrair texto deles.
Proteção de leitura de PDF
Você pode ter encontrado arquivos PDF que proíbem a cópia de conteúdo de texto deles. Por exemplo, isso é o que o programa SumatraPDF produz ao tentar copiar texto de um documento protegido contra cópia:

É interessante que o texto esteja visível, mas o visualizador se recusa a transferir o texto selecionado para a área de transferência.
Isso é realizado com vários sinalizadores de "permissões de acesso", um dos quais controla a permissão de cópia. É importante entender que o arquivo PDF em si não força isso - seu conteúdo não muda a partir disso, e a tarefa de sua implementação é inteiramente do visualizador.
Naturalmente, isso realmente não protege contra a extração de texto de PDF, uma vez que qualquer biblioteca suficientemente avançada para trabalhar com PDF permitirá ao usuário alterar esses sinalizadores ou ignorá-los.
Personagens fora das páginas
Muitas vezes, um PDF contém mais dados textuais do que os mostrados na página. Veja esta página do Relatório Anual de 2010 da Nestlé.
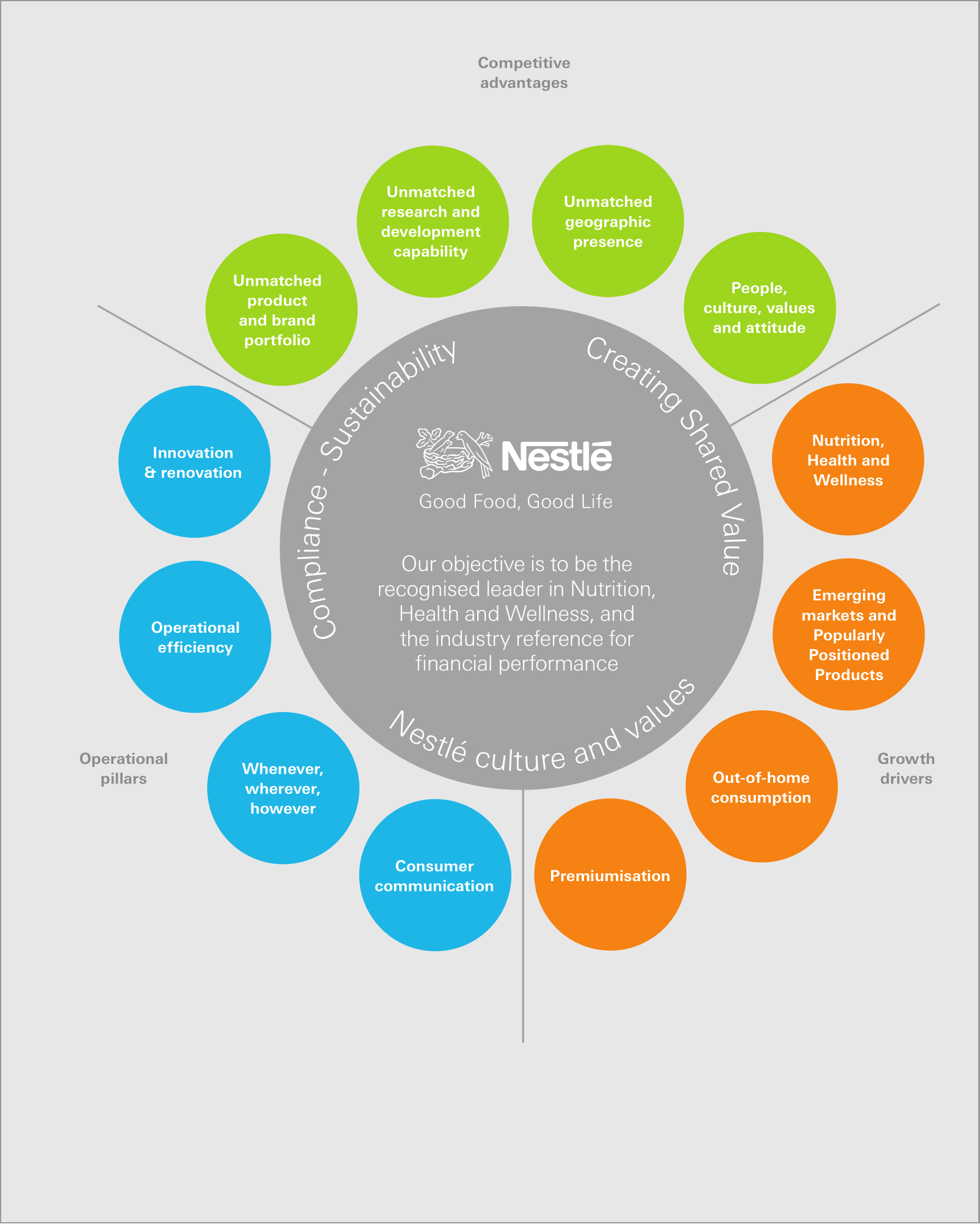
Há mais texto anexado a esta página do que o visível. Em particular, o seguinte pode ser encontrado no conteúdo associado a ele:
KitKat comemorou seu 75º aniversário em 2010, mas continua jovem e moderno, com mais de 2,5 milhões de fãs no Facebook. Seus produtos são vendidos em mais de 70 países, e as vendas estão crescendo bem em países desenvolvidos e mercados emergentes, como Oriente Médio, Índia e Rússia. O Japão é o segundo maior mercado da empresa.
Este texto está fora da página, então a maioria dos visualizadores de PDF não o mostra. No entanto, os dados estão lá e podem ser recuperados programaticamente.
Isso às vezes acontece devido a decisões de última hora para substituir ou remover texto durante o processo de aprovação.
Personagens pequenos ou invisíveis
Às vezes, caracteres muito pequenos ou até invisíveis podem ser encontrados na página do PDF. Por exemplo, aqui está uma página do relatório de 2012 da Nestlé.

A página tem um pequeno texto branco em um fundo branco que diz:
Logotipo da Wyeth Nutrition Orientação de identidade para os mercados
Vevey Octobre 2012 RCC / CI & D
Isso às vezes é feito para melhorar a acessibilidade, com o mesmo propósito que a tag alt em HTML.
Muitos espaços
Às vezes, espaços adicionais são inseridos entre letras de palavras em PDF. Isso provavelmente é feito para fins de kerning (alterando o espaçamento entre os caracteres).
Por exemplo, o relatório Hikma Pharma 2013 contém o seguinte texto:

Se você copiá-lo, obteremos:
ch a i r m a n ' s s tat em en tEm geral, é difícil resolver o problema da reconstrução do texto original. Nossa abordagem de maior sucesso é usar o reconhecimento óptico de caracteres, OCR.
Espaços insuficientes
Às vezes, o PDF está sem espaços ou foi substituído por um caractere diferente.
Exemplo 1: O seguinte extrato é do SEB Relatório Anual 2017.

Texto extraído:
TenyearsafterthefinancialcrisisstartedExemplo 2: O relatório Eurobank 2013 contém o seguinte:

Texto extraído:
On_April_7,_2013,_the_competent_authoritiesNovamente, OCR é a melhor escolha para essas páginas.
Fontes integradas
O PDF trabalha com fontes de uma forma complexa, para dizer o mínimo. Para entender como os dados de texto são armazenados em PDF, primeiro precisamos entender glifos, nomes de glifos e fontes.
- Um glifo é um conjunto de instruções que descreve como desenhar um caractere ou uma letra.
- – , . , « » ™ «» «».
- – . , , , «», .
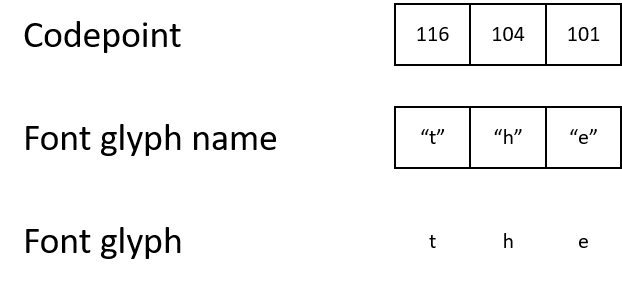
No PDF, os caracteres são armazenados como números, códigos de caracteres [pontos de código]. Para entender o que precisa ser exibido na tela, o renderizador deve seguir a cadeia do código do caractere até o nome do glifo e, em seguida, até o próprio glifo.
Por exemplo, um PDF pode conter um código de caractere 116, que mapeia para o nome do glifo "t", que por sua vez mapeia para um glifo que descreve como exibir o caractere "t".
A maioria dos PDFs usa a codificação de caracteres padrão. A codificação de caracteres é um conjunto de regras que atribuem significado aos próprios códigos de caracteres. Por exemplo:
- ASCII e Unicode usam o código de caractere 116 para representar a letra "t".
- O Unicode mapeia o código de caractere 9786 para o glifo "sorriso branco", que é exibido como ☺, mas o ASCII não define esse código.
No entanto, às vezes um documento PDF usa sua própria codificação de caracteres e fontes especiais. Pode parecer estranho, mas o documento pode denotar a letra "t" com o código de caractere 1. Ele mapeará o código de caractere 1 para o nome do glifo "c1", que será mapeado para um glifo que descreve como exibir a letra "t".
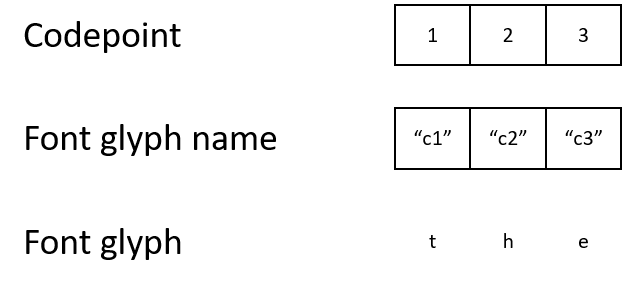
Embora o resultado final não seja diferente para um humano, a máquina ficará confusa com esses códigos de caracteres. Se os códigos de caracteres não corresponderem à codificação padrão, é quase impossível entender programaticamente o que significam os códigos 1, 2 ou 3.
Por que um PDF incluiria fontes e codificação não padrão?
- Um dos motivos é dificultar a extração de texto.
- – . , PDF . PDF , .
Uma maneira de contornar isso é extrair glifos de fonte do documento, executá-los por meio de OCR e mapear a fonte para Unicode. Isso permitirá que você traduza a codificação relacionada à fonte para Unicode, por exemplo: o código de caractere 1 corresponde ao nome "c1", que, de acordo com o glifo, deve significar "t", que corresponde ao código Unicode 116.
O mapa de codificação que você acabou de done - aquele que corresponde aos números 1 e 116 - é chamado de cartão ToUnicode no padrão PDF. Os documentos PDF podem conter seus próprios cartões ToUnicode, mas isso não é obrigatório.
Reconhecimento de palavras e parágrafos
Reconstruir parágrafos e até palavras da sopa simbólica amorfa de PDFs é uma tarefa assustadora.
Um documento PDF contém uma lista de caracteres em uma página e cabe ao consumidor reconhecer palavras e parágrafos. Os humanos são naturalmente eficazes nisso porque a leitura é uma habilidade comum.
O algoritmo de agrupamento mais comumente usado é comparar o tamanho, a posição e o alinhamento dos caracteres para determinar o que é uma palavra ou parágrafo.
As implementações mais simples de tais algoritmos podem facilmente atingir a complexidade O (n²), que pode levar muito tempo para processar páginas densamente compactadas.
Ordem do texto e parágrafos
Reconhecer a ordem do texto e do parágrafo é um desafio por dois motivos.
Primeiro, às vezes simplesmente não há uma resposta certa. Enquanto os documentos com conjunto tipográfico regular com uma coluna têm uma sequência de leitura natural, os documentos com uma organização de elementos mais ousada são mais difíceis de determinar. Por exemplo, não está totalmente claro se a próxima inserção deve vir antes, depois ou no meio do artigo ao lado do qual está localizada:

Em segundo lugar, mesmo quando a resposta é clara para uma pessoa, os computadores podem ser muito difíceis de determinar a ordem exata dos parágrafos - mesmo usando IA. Você pode achar esta afirmação um pouco ousada, mas em alguns casos a seqüência correta de parágrafos só pode ser determinada pela compreensão do conteúdo do texto.
Considere este arranjo de componentes em duas colunas, que descreve o preparo de uma salada de legumes.

No mundo ocidental, é razoável supor que a leitura seja da esquerda para a direita e de cima para baixo. Portanto, sem estudar o conteúdo do texto, podemos reduzir todas as opções a duas: ABCD e ACB D.
Depois de examinar o conteúdo, entender o que ele diz e saber que os vegetais são lavados antes de fatiar, podemos entender que a ordem correta seria ACB D. É extremamente difícil determinar isso algoritmicamente.
Nesse caso, "na maioria dos casos" funciona uma abordagem que depende da ordem em que o texto é armazenado no documento PDF. Geralmente segue a ordem em que o texto é inserido no momento da criação. Quando grandes pedaços de texto contêm muitos parágrafos, eles geralmente seguem a ordem que o autor pretendia.
Imagens incorporadas
Freqüentemente, parte do conteúdo do documento (ou o documento inteiro) acaba sendo uma imagem digitalizada. Nesses casos, não há dados textuais nele e você deve recorrer ao OCR.
Por exemplo, o Relatório Anual Yell de 2011 está disponível apenas como uma digitalização:

Por que não apenas reconhecer tudo?
Embora o OCR possa ajudar com alguns dos problemas descritos, ele também tem suas desvantagens.
- Tempo de processamento longo. A execução de OCR em uma digitalização de PDF geralmente leva uma ordem de magnitude mais longa (ou até mais longa) do que extrair texto diretamente de PDF.
- Dificuldades com caracteres e glifos não padrão. É difícil para os algoritmos de OCR trabalharem com novos caracteres - emoticons, asteriscos, círculos, quadrados (em listas), sobrescritos, símbolos matemáticos complexos, etc.
- . , PDF-, , . .
Até agora não mencionamos como é difícil confirmar se o texto foi extraído corretamente ou conforme o esperado. Descobrimos que é melhor executar um amplo conjunto de testes que estudam métricas básicas (comprimento do texto, comprimento da página, proporção de palavras por espaços) e mais complexos (porcentagem de palavras em inglês, porcentagem de palavras não reconhecidas, porcentagem de números), bem como monitor avisos como caracteres suspeitos ou inesperados.
O que podemos recomendar para extrair texto de PDF? Em primeiro lugar, certifique-se de que o texto não possui uma fonte mais conveniente.
Se os dados em que você está interessado estão apenas no formato PDF, então é importante entender que este problema parece simples à primeira vista, e pode não ser possível resolvê-lo com 100% de precisão.