
Nosso mundo está gerando cada vez mais informações. Alguma parte dele é passageira e se perde tão rapidamente quanto é coletada. O outro deve ser armazenado por mais tempo, enquanto o outro é projetado "por séculos" - pelo menos é assim que o vemos no presente. Os fluxos de informações estão se estabelecendo nos data centers a uma velocidade tal que qualquer nova abordagem, qualquer tecnologia projetada para satisfazer essa "demanda" infinita está rapidamente se tornando obsoleta.
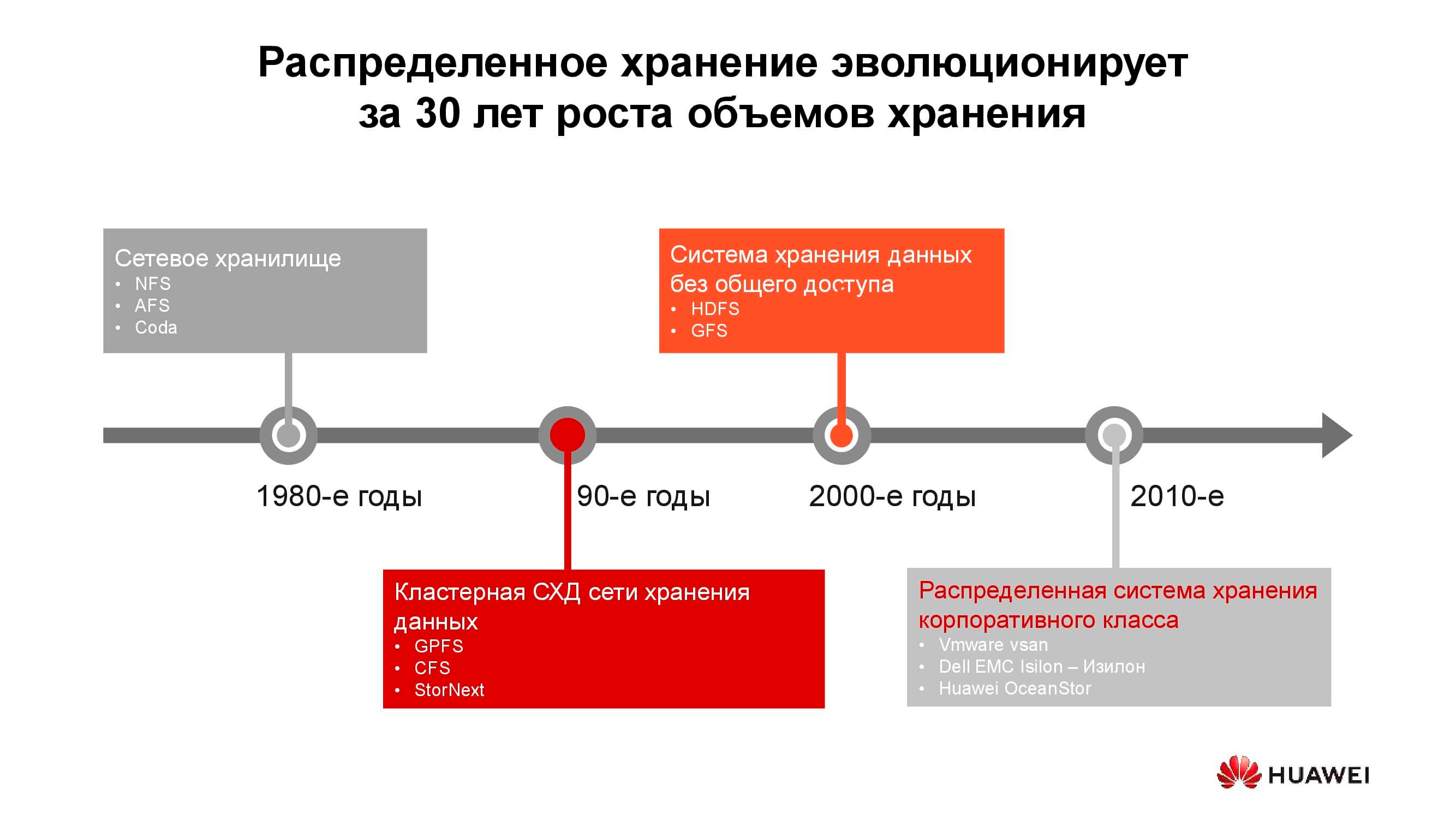
40 anos de desenvolvimento de sistemas de armazenamento distribuído
Os primeiros armazenamentos anexados à rede apareceram na forma usual na década de 1980. Muitos de vocês encontraram NFS (Network File System), AFS (Andrew File System) ou Coda. Uma década depois, a moda e a tecnologia mudaram e os sistemas de arquivos distribuídos deram lugar a sistemas de armazenamento em cluster baseados em GPFS (General Parallel File System), CFS (Clustered File Systems) e StorNext. Como base, foram usados storages de blocos de arquitetura clássica, sobre os quais um único sistema de arquivos foi criado usando uma camada de software. Essas e outras soluções semelhantes ainda estão em uso, ocupam um nicho próprio e são bastante procuradas.
Na virada do milênio, o paradigma de armazenamento distribuído mudou um pouco e os sistemas com a arquitetura SN (Shared-Nothing) assumiram a liderança. Houve uma transição do armazenamento em cluster para o armazenamento em nós separados, que, como regra, eram servidores clássicos com software que fornecem armazenamento confiável; em tais princípios são construídos, digamos, HDFS (Hadoop Distributed File System) e GFS (Global File System).
Mais perto dos anos 2010, os conceitos por trás do armazenamento distribuído estão cada vez mais refletidos em produtos comerciais completos, como VMware vSAN, Dell EMC Isilon e nosso Huawei OceanStor.... As plataformas mencionadas não são mais uma comunidade de entusiastas, mas fornecedores específicos que são responsáveis pela funcionalidade, suporte, serviço do produto e garantem seu futuro desenvolvimento. Essas soluções são mais procuradas em várias áreas.
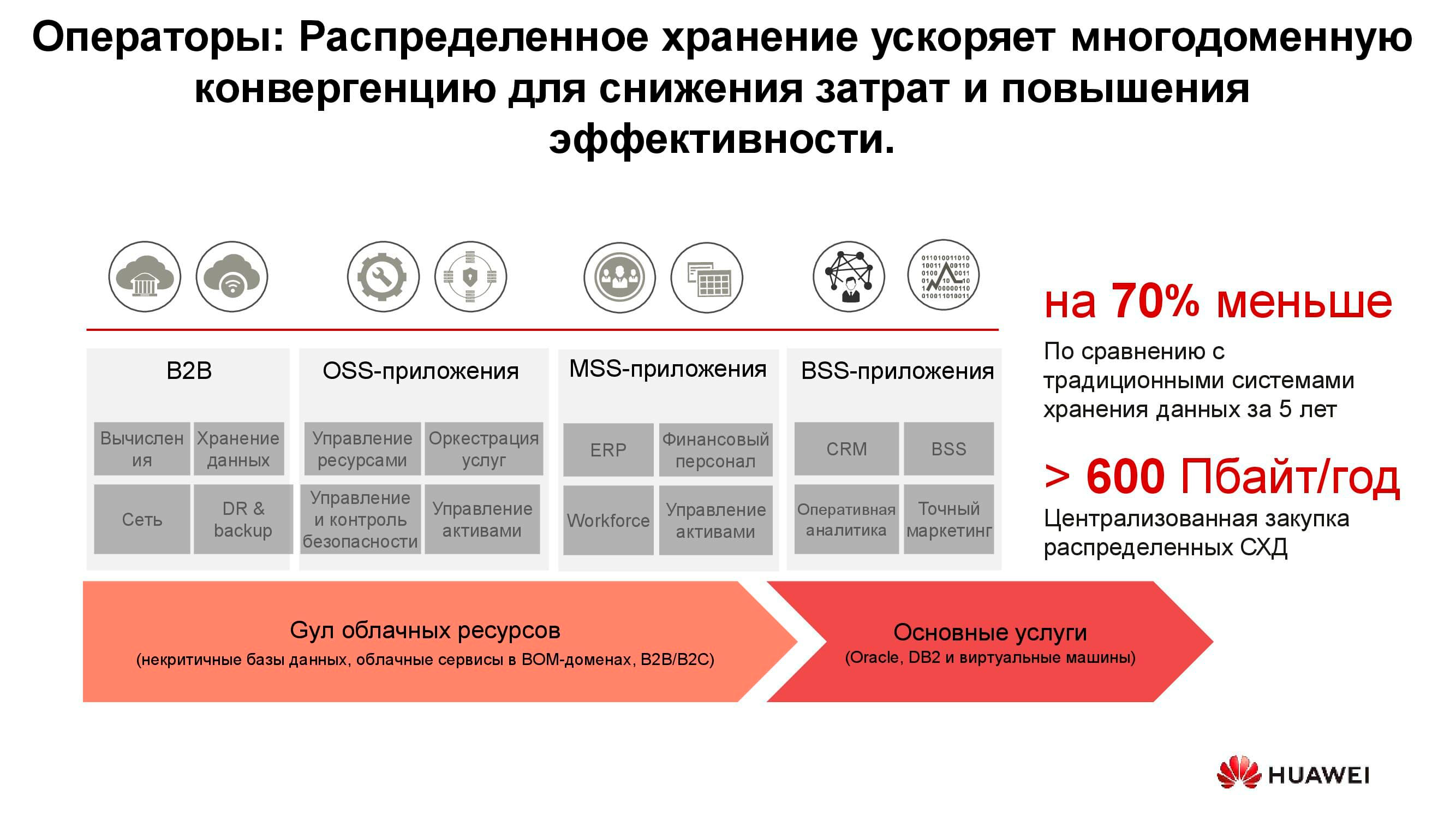
Operadoras de telecom
Talvez um dos consumidores mais antigos de sistemas de armazenamento distribuído sejam as operadoras de telecomunicações. O diagrama mostra quais grupos de aplicativos produzem a maior parte dos dados. OSS (Operations Support Systems), MSS (Management Support Services) e BSS (Business Support Systems) são três camadas de software complementares necessárias para fornecer serviços aos assinantes, relatórios financeiros para o provedor e suporte operacional para os engenheiros da operadora.
Freqüentemente, os dados dessas camadas são fortemente mesclados entre si e, para evitar o acúmulo de cópias desnecessárias, são utilizados armazenamentos distribuídos, que acumulam toda a quantidade de informação proveniente da rede de trabalho. Os armazenamentos são combinados em um pool comum, ao qual todos os serviços se referem.
Nossos cálculos mostram que a transição de sistemas de armazenamento clássicos para sistemas de armazenamento em bloco permite que você economize até 70% do orçamento apenas eliminando sistemas de armazenamento dedicados de alta tecnologia e usando servidores convencionais de arquitetura clássica (geralmente x86) trabalhando em conjunto com software especializado. As operadoras de celular há muito começaram a comprar essas soluções em grandes volumes. Em particular, as operadoras russas vêm usando esses produtos da Huawei há mais de seis anos.
Sim, várias tarefas não podem ser executadas em sistemas distribuídos. Por exemplo, com requisitos de desempenho aumentados ou compatibilidade com protocolos mais antigos. Mas pelo menos 70% dos dados que o operador processa podem estar localizados em um pool distribuído.
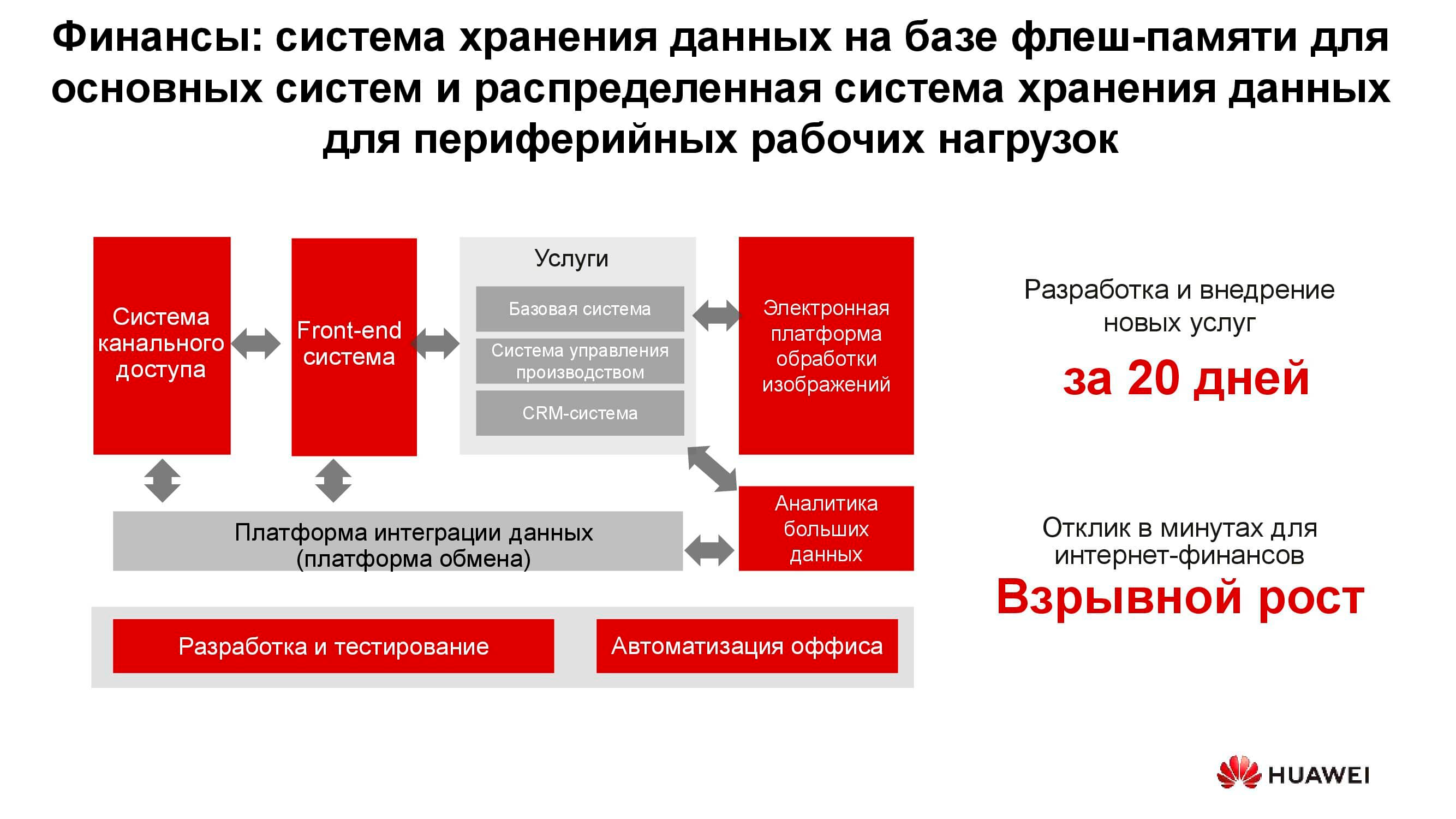
Setor bancário
Em qualquer banco, existem muitos sistemas de TI diferentes, desde processamento até um sistema bancário automatizado. Essa infraestrutura também trabalha com uma grande quantidade de informações, enquanto a maioria das tarefas não exige aumento de desempenho e confiabilidade dos sistemas de armazenamento, por exemplo, desenvolvimento, teste, automação de processos de escritório, etc. Aqui, o uso de sistemas de armazenamento clássicos é possível, mas a cada ano é cada vez menos lucrativo. Além disso, neste caso, não há flexibilidade no uso dos recursos de armazenamento, cujo desempenho é calculado a partir do pico de carga.
Ao usar sistemas de armazenamento distribuído, seus nós, que na verdade são servidores comuns, podem ser convertidos a qualquer momento, por exemplo, em um farm de servidores e usados como plataforma de computação.
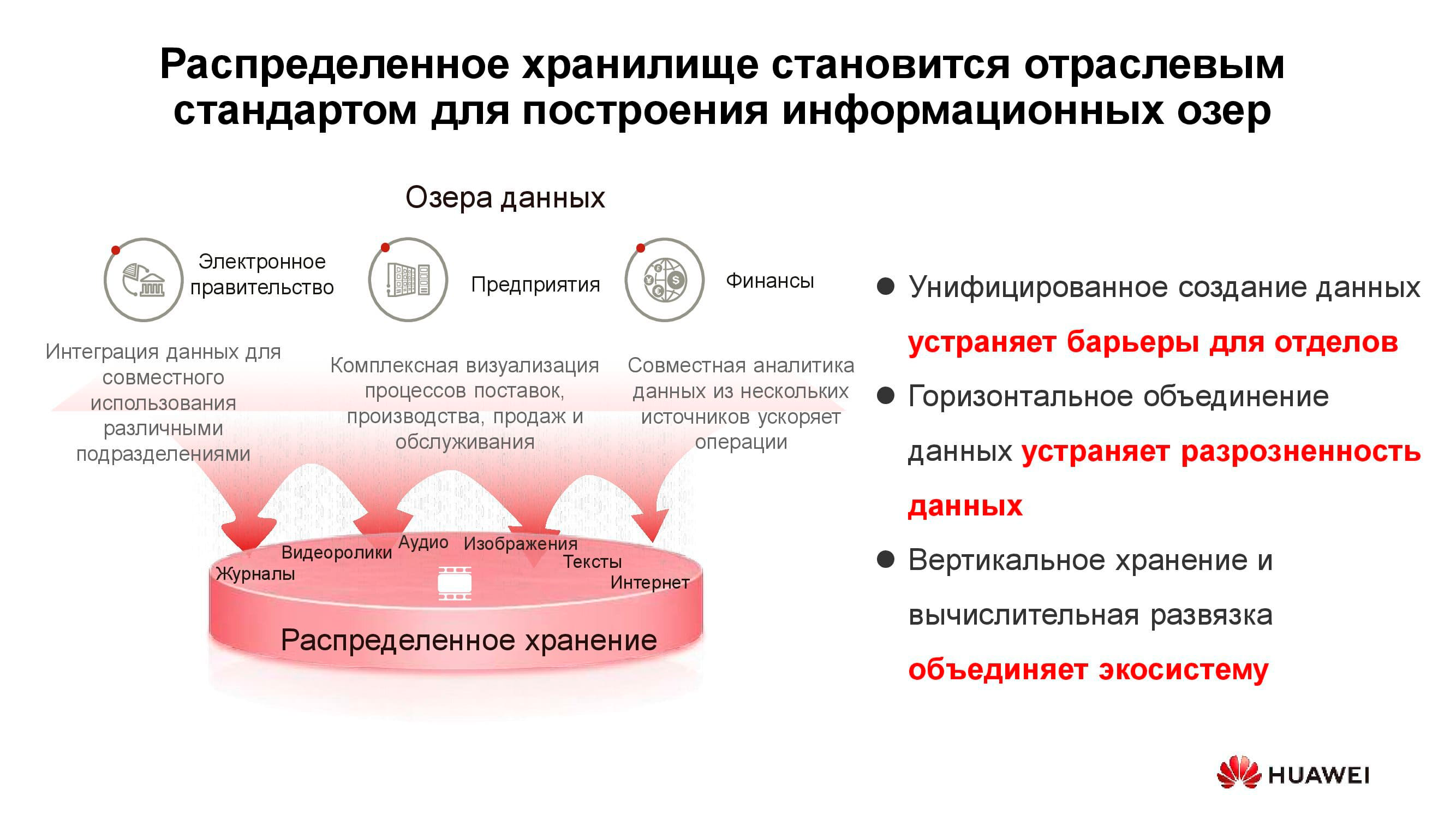
Data lagos
O diagrama acima mostra uma lista de consumidores típicos de serviços de data lake . Podem ser serviços de governo eletrônico (por exemplo, "Gosuslugi"), empresas digitalizadas, estruturas financeiras etc. Todos eles precisam trabalhar com grandes quantidades de informações heterogêneas.
A operação de sistemas de armazenamento clássicos para resolver tais problemas é ineficaz, uma vez que tanto o acesso de alto desempenho para bloquear bancos de dados quanto o acesso regular a bibliotecas de documentos digitalizados armazenados como objetos são necessários. Isso também pode ser vinculado, por exemplo, um sistema de pedidos por meio de um portal da web. Para implementar tudo isso em uma plataforma de armazenamento clássica, você precisará de um grande conjunto de equipamentos para diferentes tarefas. Um sistema de armazenamento horizontal universal pode muito bem cobrir todas as tarefas listadas anteriormente: você só precisa criar vários pools nele com diferentes características de armazenamento.

Geradores de novas informações
A quantidade de informações armazenadas no mundo cresce cerca de 30% ao ano. Essa é uma boa notícia para os fornecedores de armazenamento, mas qual é e será a principal fonte desses dados?
Há dez anos, as redes sociais tornaram-se tais geradores, o que exigiu a criação de um grande número de novos algoritmos, soluções de hardware, etc. Agora, existem três motores principais de crescimento nos volumes de armazenamento. O primeiro é a computação em nuvem. Atualmente, cerca de 70% das empresas usam serviços em nuvem de uma forma ou de outra. Podem ser sistemas de e-mail, backups e outras entidades virtualizadas.
O segundo driver são as redes de quinta geração. Essas são novas velocidades e novos volumes de transferência de dados. Prevemos que a ampla adoção do 5G levará a uma queda na demanda por cartões de memória flash. Não importa quanta memória haja no telefone, ele ainda acabará e, se houver um canal de 100 megabit no gadget, não há necessidade de armazenar fotos localmente.
O terceiro grupo de razões para a crescente demanda por sistemas de armazenamento inclui o rápido desenvolvimento da inteligência artificial, a transição para a análise de big data e a tendência para a automação universal de tudo o que é possível.
A peculiaridade do "novo tráfego" é sua desestruturação... Precisamos armazenar esses dados sem especificar seu formato. É necessário apenas para leituras subsequentes. Por exemplo, um sistema de pontuação bancária para determinar o valor do empréstimo disponível analisará as fotos que você postou nas redes sociais, determinando se você costuma visitar o mar e restaurantes, e ao mesmo tempo estudará os extratos de seus documentos médicos disponíveis para ele. Esses dados, por um lado, são abrangentes e, por outro, carecem de uniformidade.

Um oceano de dados não estruturados
Que problemas o surgimento de "novos dados" acarreta? O principal deles, é claro, é a quantidade de informações em si e o tempo estimado de armazenamento. Um carro autônomo moderno sem um motorista sozinho gera até 60 TB de dados todos os dias de todos os seus sensores e mecanismos. Para desenvolver novos algoritmos de movimento, essa informação deve ser processada no mesmo dia, caso contrário, começará a se acumular. Além disso, deve ser armazenado por muito tempo - dezenas de anos. Só então, no futuro, será possível tirar conclusões com base em grandes amostras analíticas.
Um único dispositivo de sequenciamento genético produz cerca de 6 TB por dia. E os dados coletados com sua ajuda não implicam em exclusão alguma, ou seja, hipoteticamente, deveriam ser armazenados para sempre.
Finalmente, todas as mesmas redes de quinta geração. Além das informações reais transmitidas, essa rede em si é um grande gerador de dados: logs de ações, registros de chamadas, resultados intermediários de interações máquina-a-máquina etc.
Tudo isso requer o desenvolvimento de novas abordagens e algoritmos para armazenar e processar informações. E essas abordagens aparecem.
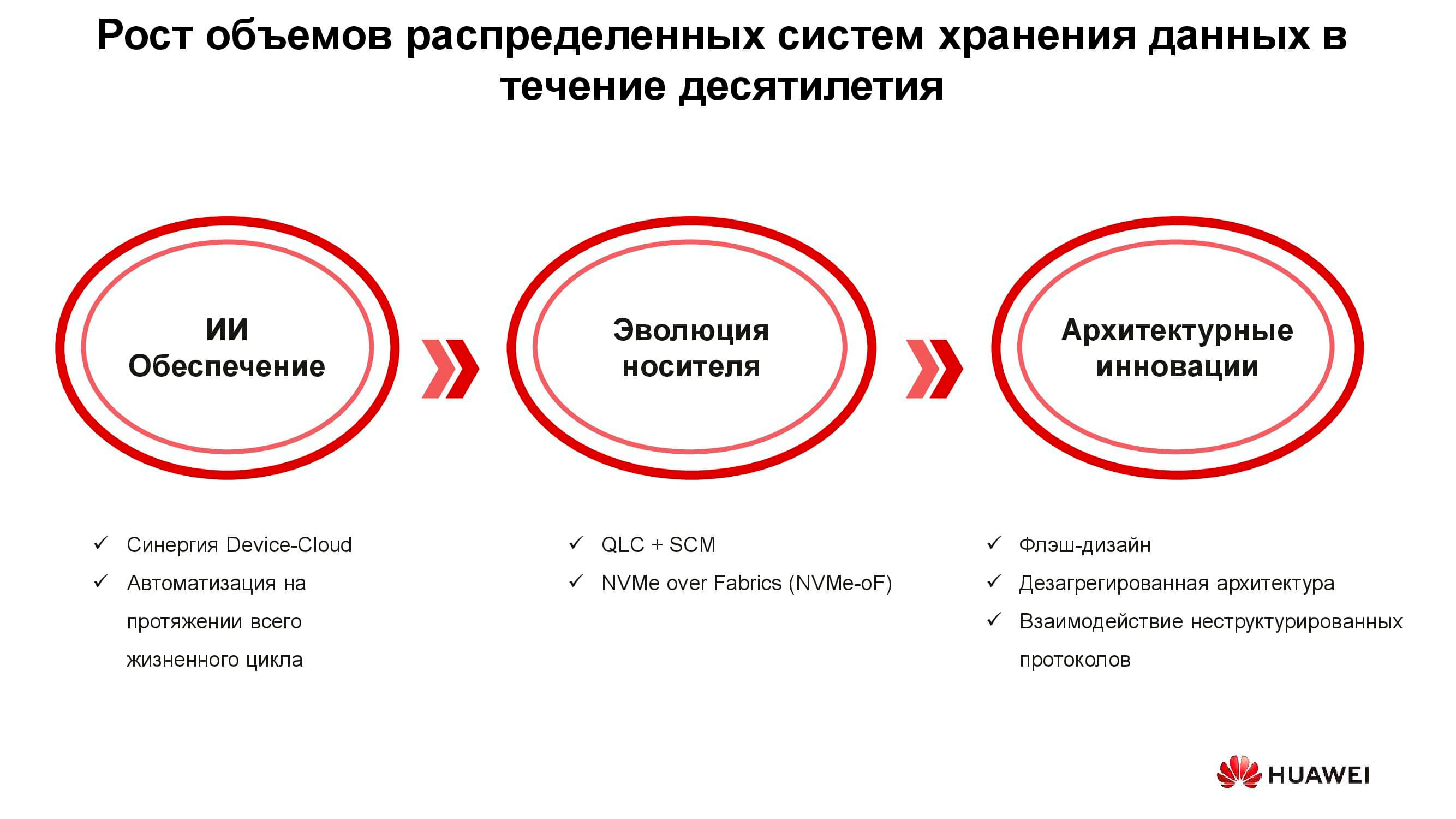
Tecnologias de uma nova era
Existem três grupos de soluções concebidas para fazer face aos novos requisitos dos sistemas de armazenamento de informação: a introdução da inteligência artificial, a evolução técnica dos suportes de armazenamento e as inovações no domínio da arquitectura de sistemas. Vamos começar com IA.

Nas novas soluções da Huawei, a inteligência artificial já é utilizada ao nível do próprio armazenamento, que é equipado com um processador AI que permite ao sistema analisar de forma independente o seu estado e prever falhas. Se o sistema de armazenamento estiver conectado a uma nuvem de serviço, que possui recursos computacionais significativos, a inteligência artificial pode processar mais informações e melhorar a precisão de suas hipóteses.
Além das falhas, tal AI é capaz de prever cargas de pico futuras e o tempo restante até que a capacidade se esgote. Isso permite que você otimize o desempenho e dimensione o sistema antes mesmo de qualquer evento indesejado ocorrer.

Agora, sobre a evolução dos suportes de dados. Os primeiros flash drives foram feitos com a tecnologia SLC (Single-Level Cell). Os dispositivos baseados nele eram rápidos, confiáveis, estáveis, mas tinham uma capacidade pequena e eram muito caros. O aumento de volume e a redução de preço foram alcançados por meio de certas concessões técnicas, devido às quais a velocidade, confiabilidade e vida útil das unidades foram reduzidas. No entanto, a tendência não afetou os próprios sistemas de armazenamento, que, devido a vários truques arquitetônicos, em geral, tornaram-se mais produtivos e confiáveis.
Mas por que você precisa de sistemas de armazenamento All-Flash? Não foi suficiente simplesmente substituir os antigos HDDs em um sistema já em uso por novos SSDs do mesmo formato? Isso foi necessário para usar com eficácia todos os recursos das novas unidades de estado sólido, o que era simplesmente impossível nos sistemas antigos.
A Huawei, por exemplo, desenvolveu uma gama de tecnologias para enfrentar esse desafio, uma das quais é o FlashLink , que maximiza as interações entre o controlador de disco.
A identificação inteligente tornou possível decompor os dados em vários fluxos e lidar com uma série de fenômenos indesejáveis, como WA (amplificação de gravação). Ao mesmo tempo, novos algoritmos de recuperação, em particular RAID 2.0+, aumentou a velocidade da reconstrução, reduzindo seu tempo a valores completamente insignificantes.
Falha, superlotação, "coleta de lixo" - esses fatores também não afetam mais o desempenho do sistema de armazenamento, graças a uma modificação especial dos controladores.
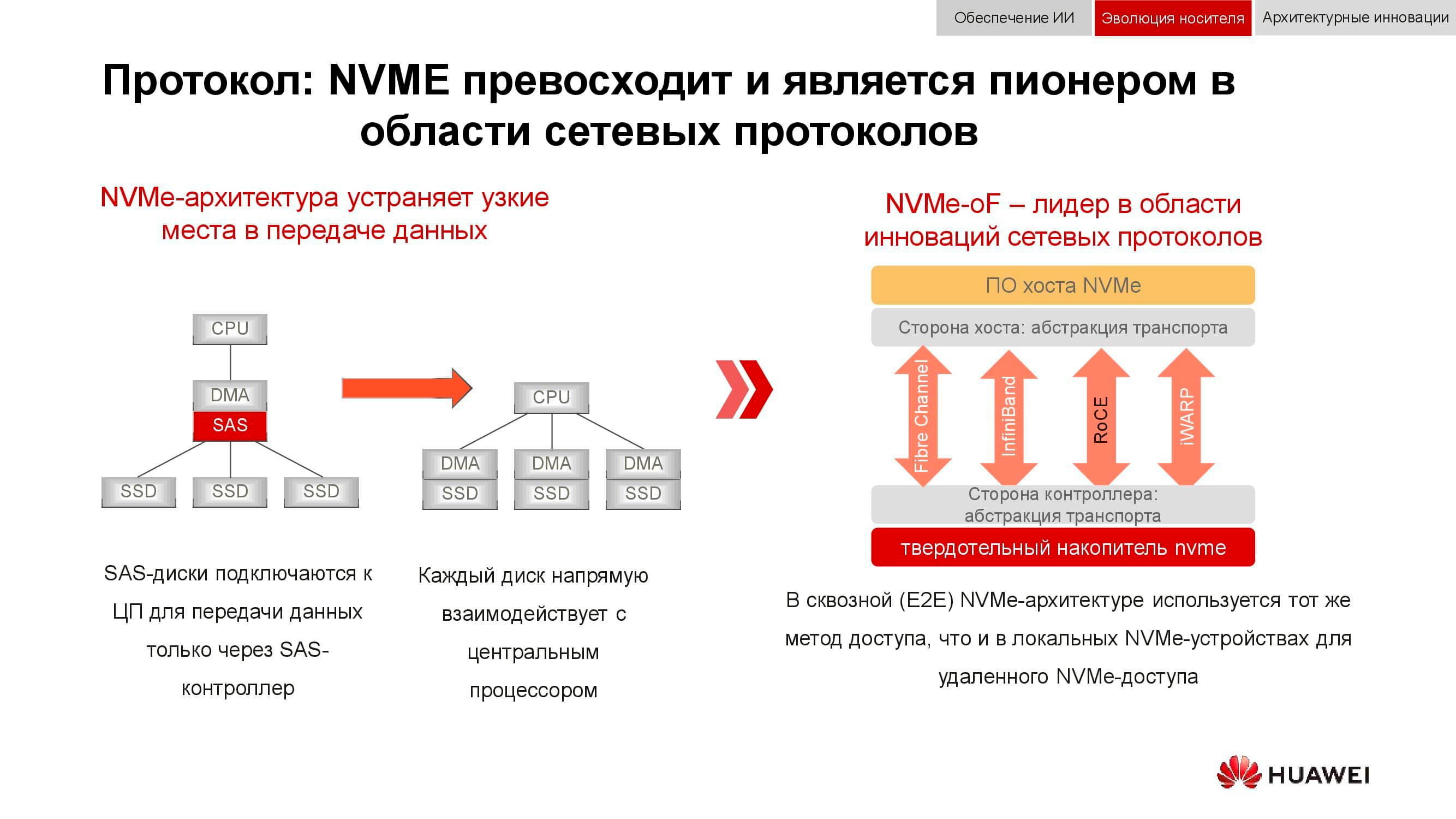
E o armazenamento de dados em bloco está se preparando para atender ao NVMe . Lembre-se de que o esquema clássico para organizar o acesso aos dados funcionava da seguinte maneira: o processador acessava o controlador RAID por meio do barramento PCI Express. Este, por sua vez, interagia com discos mecânicos via SCSI ou SAS. O uso de NVMe no backend acelerou significativamente todo o processo, mas tinha uma desvantagem: as unidades tinham que ser conectadas diretamente ao processador para fornecer acesso direto à memória.
A próxima fase de desenvolvimento de tecnologia que estamos vendo agora é o uso de NVMe-oF (NVMe sobre Tecidos). Quanto às tecnologias de bloco Huawei, elas já suportam FC-NVMe (NVMe sobre Fibre Channel) e na abordagem NVMe sobre RoCE (RDMA sobre Ethernet Convergente). Os modelos de teste são bastante funcionais, faltam vários meses para sua apresentação oficial. Observe que tudo isso também aparecerá em sistemas distribuídos, onde a "Ethernet sem perdas" terá grande demanda.
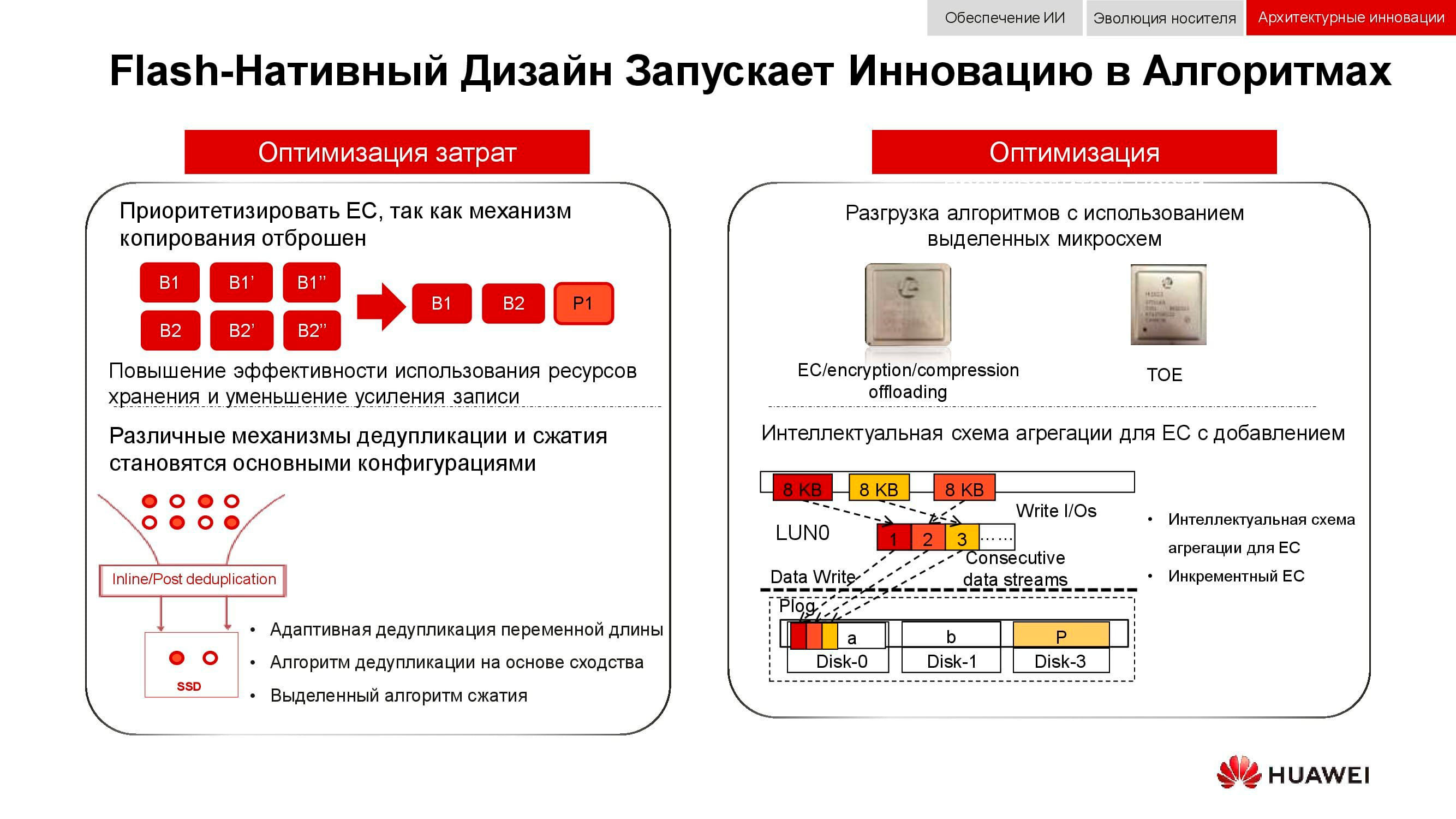
Uma forma adicional de otimizar o trabalho de armazenamento distribuído é rejeitar totalmente o espelhamento de dados. As soluções da Huawei não usam mais n cópias, como no RAID 1 normal, e mudam completamente para o mecanismo EC(Codificação de apagamento). Um pacote matemático especial com uma certa frequência calcula os blocos de controle que permitem restaurar os dados intermediários em caso de perda.
Os mecanismos de desduplicação e compactação estão se tornando obrigatórios. Se nos sistemas de armazenamento clássicos somos limitados pelo número de processadores instalados nos controladores, nos sistemas de armazenamento em expansão distribuída cada nó contém tudo o que você precisa: discos, memória, processadores e interconexão. Esses recursos são suficientes para desduplicação e compactação para ter um impacto mínimo no desempenho.
E sobre métodos de otimização de hardware. Aqui, foi possível reduzir a carga nos processadores centrais com a ajuda de microcircuitos dedicados adicionais (ou blocos dedicados no próprio processador), que desempenham o papel de TOE(TCP / IP Offload Engine) ou assumindo os problemas matemáticos de EC, desduplicação e compactação.
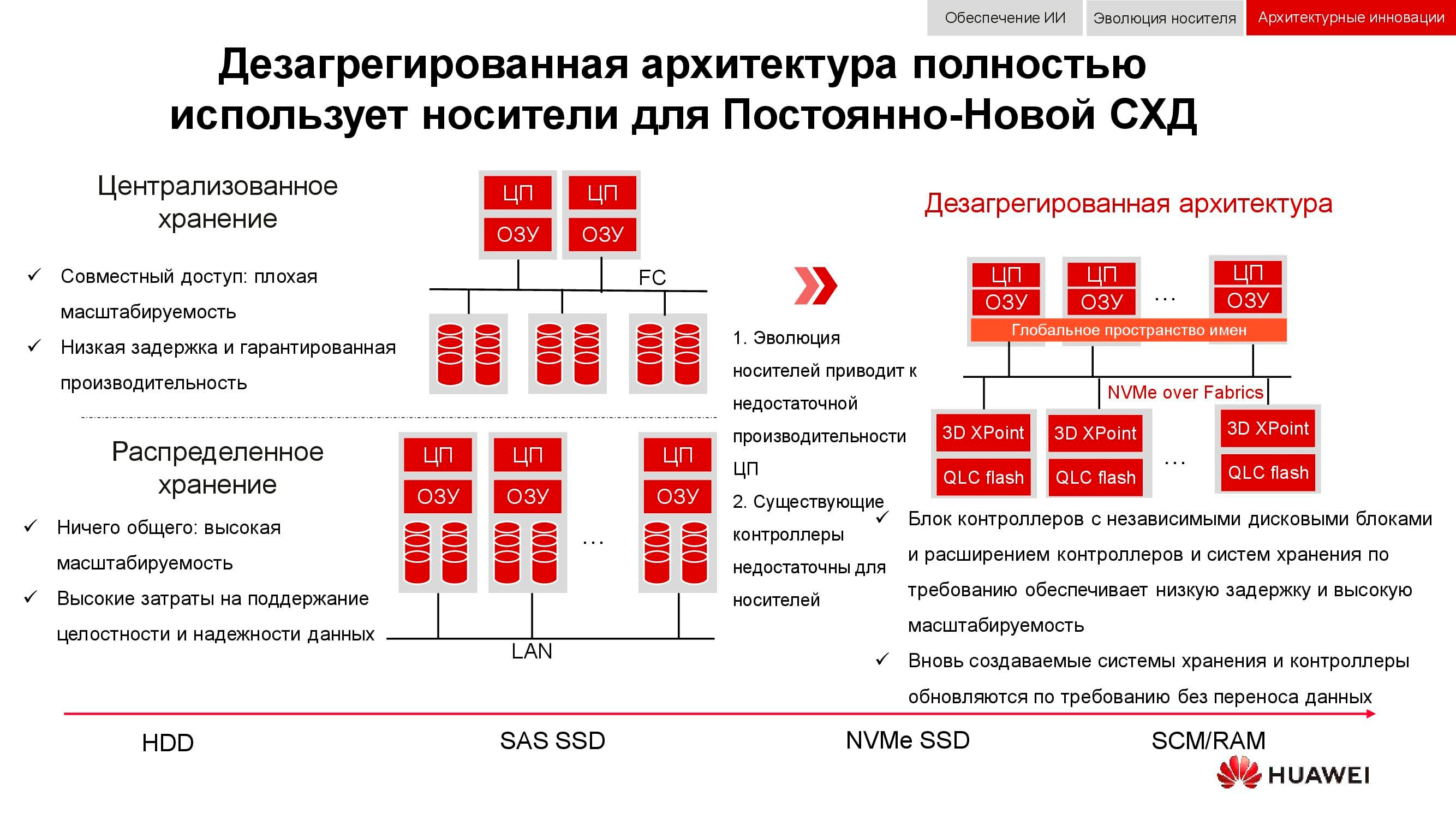
Novas abordagens para armazenamento de dados são incorporadas em uma arquitetura desagregada (distribuída). Em sistemas de armazenamento centralizado, há uma fábrica de servidores que é conectada via Fibre Channel a uma SAN com um grande número de arrays. As desvantagens dessa abordagem são a dificuldade em dimensionar e fornecer níveis de serviço garantidos (desempenho ou latência). Os sistemas hiperconvergentes usam os mesmos hosts para armazenar e processar informações. Isso fornece escalabilidade virtualmente ilimitada, mas acarreta altos custos para manter a integridade dos dados.
Em contraste com ambos os itens acima, a arquitetura desagregada implica na separação do sistema em uma malha de computação e sistema de armazenamento horizontal . Isso fornece os benefícios de ambas as arquiteturas e permite escalar quase indefinidamente apenas para o elemento que não tem desempenho.
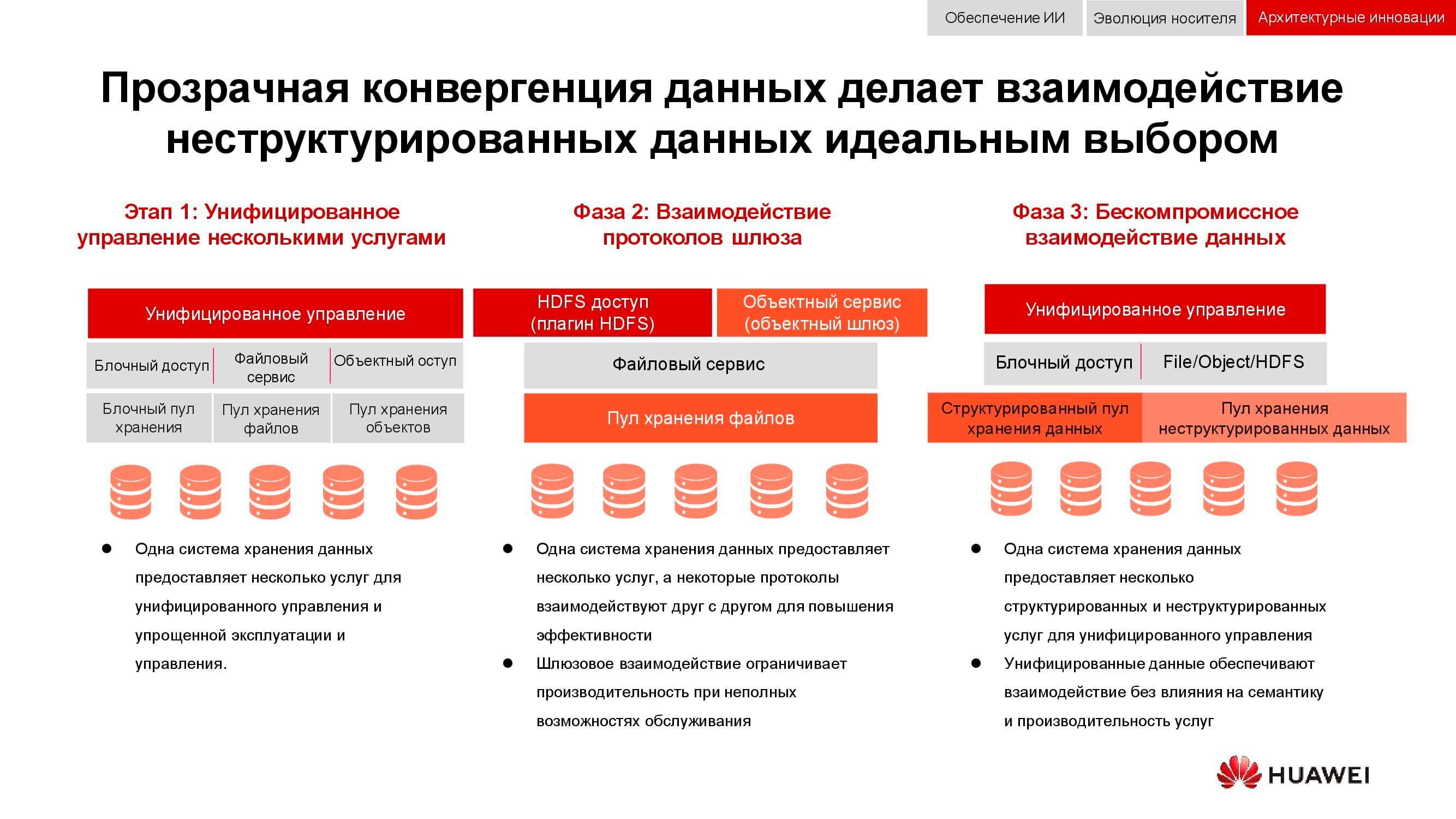
Da integração à convergência
Uma tarefa clássica, cuja relevância só cresceu nos últimos 15 anos, é a necessidade de fornecer simultaneamente armazenamento em bloco, acesso a arquivos, acesso a objetos, operação de farm para big data, etc. A cereja do bolo também pode ser, por exemplo, um sistema de backup para fita magnética.
Na primeira etapa, só foi possível unificar a gestão desses serviços. Os sistemas de armazenamento heterogêneos foram bloqueados em algum software especializado, por meio do qual o administrador alocou recursos dos pools disponíveis. Mas, como esses pools eram diferentes no hardware, a migração da carga entre eles era impossível. Em um nível superior de integração, a consolidação ocorreu no nível do gateway. Com o acesso a arquivos compartilhados, ele pode ser enviado por meio de diferentes protocolos.
O método de convergência mais avançado disponível para nós agora envolve a criação de um sistema híbrido universal. Exatamente o que nosso OceanStor 100D deveria ser . Acessibilidade usa os mesmos recursos de hardware, logicamente divididos em pools diferentes, mas permitindo a migração da carga de trabalho. Tudo isso pode ser feito por meio de um único console de gerenciamento. Desta forma, conseguimos implementar o conceito de "um centro de dados - um sistema de armazenamento".
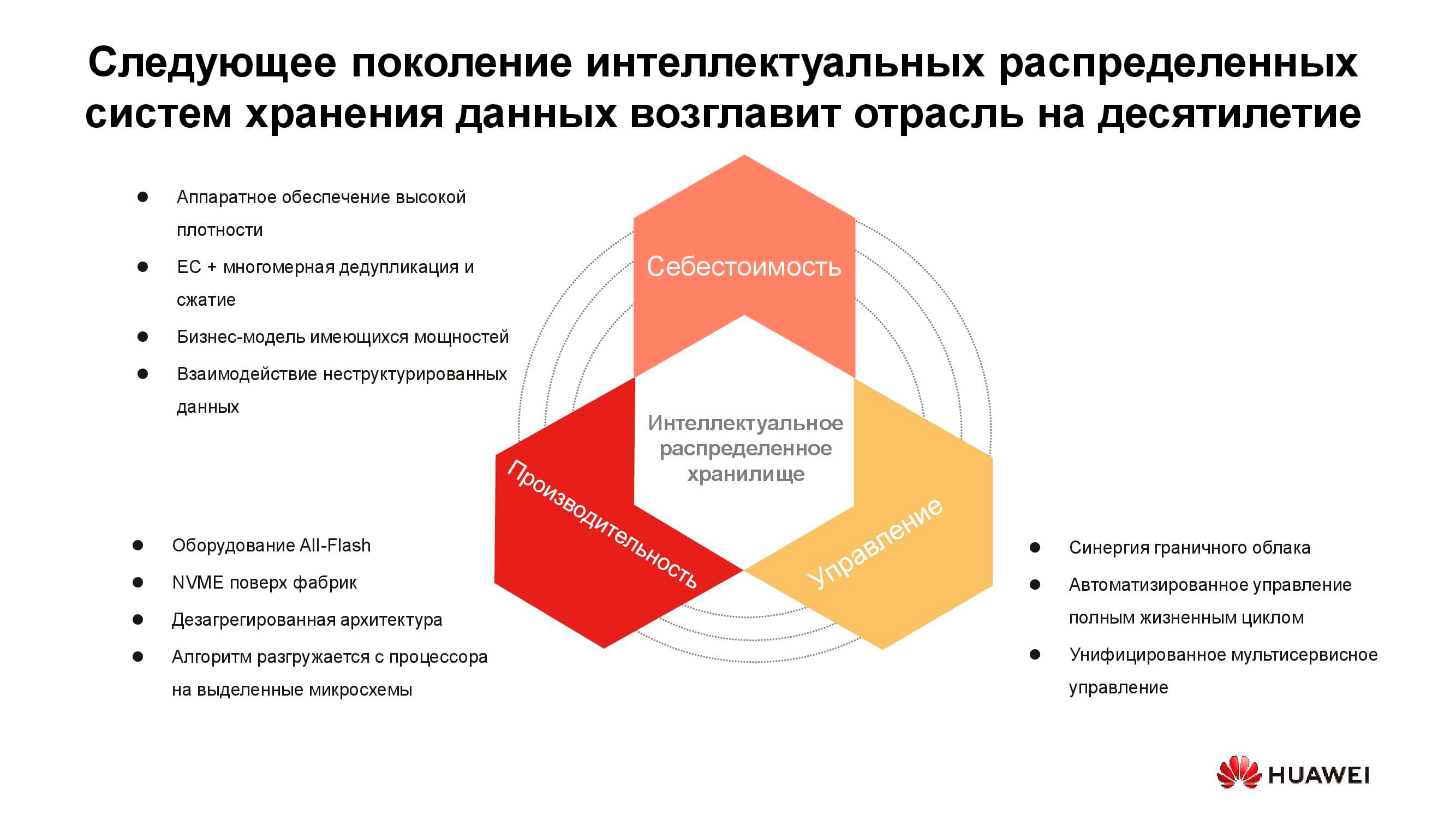
O custo de armazenamento de informações agora determina muitas decisões arquitetônicas. Embora possa ser colocado com segurança na vanguarda, estamos discutindo o armazenamento ao vivo com acesso ativo hoje, portanto, o desempenho também deve ser considerado. Outra propriedade importante dos sistemas distribuídos de próxima geração é a unificação. Afinal, ninguém quer ter vários sistemas distintos controlados em consoles diferentes. Todas essas qualidades estão incorporadas na nova série de produtos Huawei OceanStor Pacific .
Armazenamento em massa de uma nova geração
O OceanStor Pacific atende aos requisitos de confiabilidade no nível de "seis noves" (99,9999%) e pode ser usado para criar data centers da classe HyperMetro. Com uma distância de até 100 km entre dois datacenters, os sistemas apresentam um atraso adicional de 2 ms, o que permite construir sobre a base quaisquer soluções resistentes a desastres, incluindo aquelas com servidores quorum.
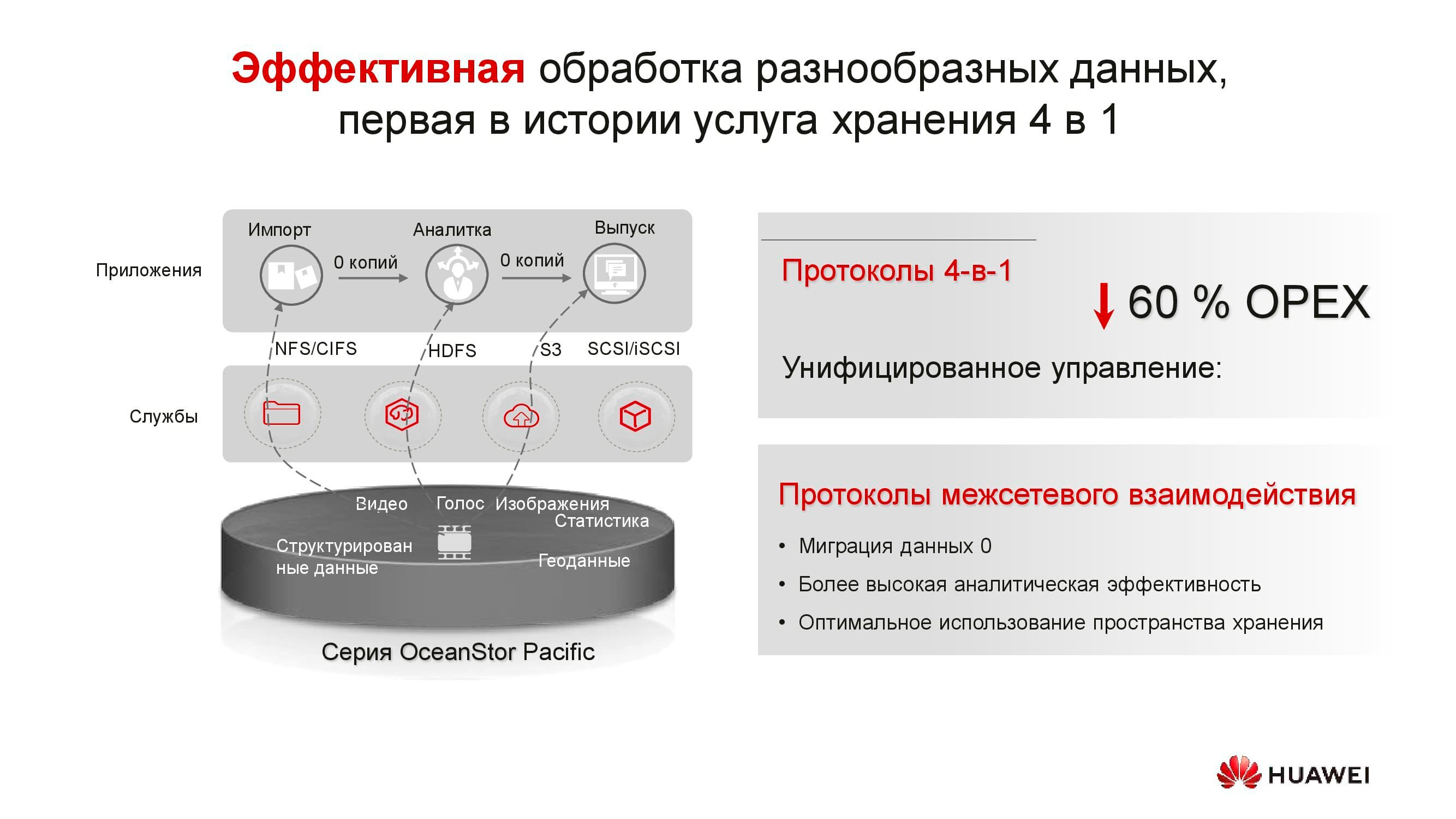
Os produtos da nova série demonstram versatilidade de protocolo. OceanStor 100D já oferece suporte a acesso de bloco, acesso a objeto e acesso Hadoop. O acesso a arquivos também será implementado em um futuro próximo. Não há necessidade de manter várias cópias dos dados se eles puderem ser fornecidos por meio de protocolos diferentes.
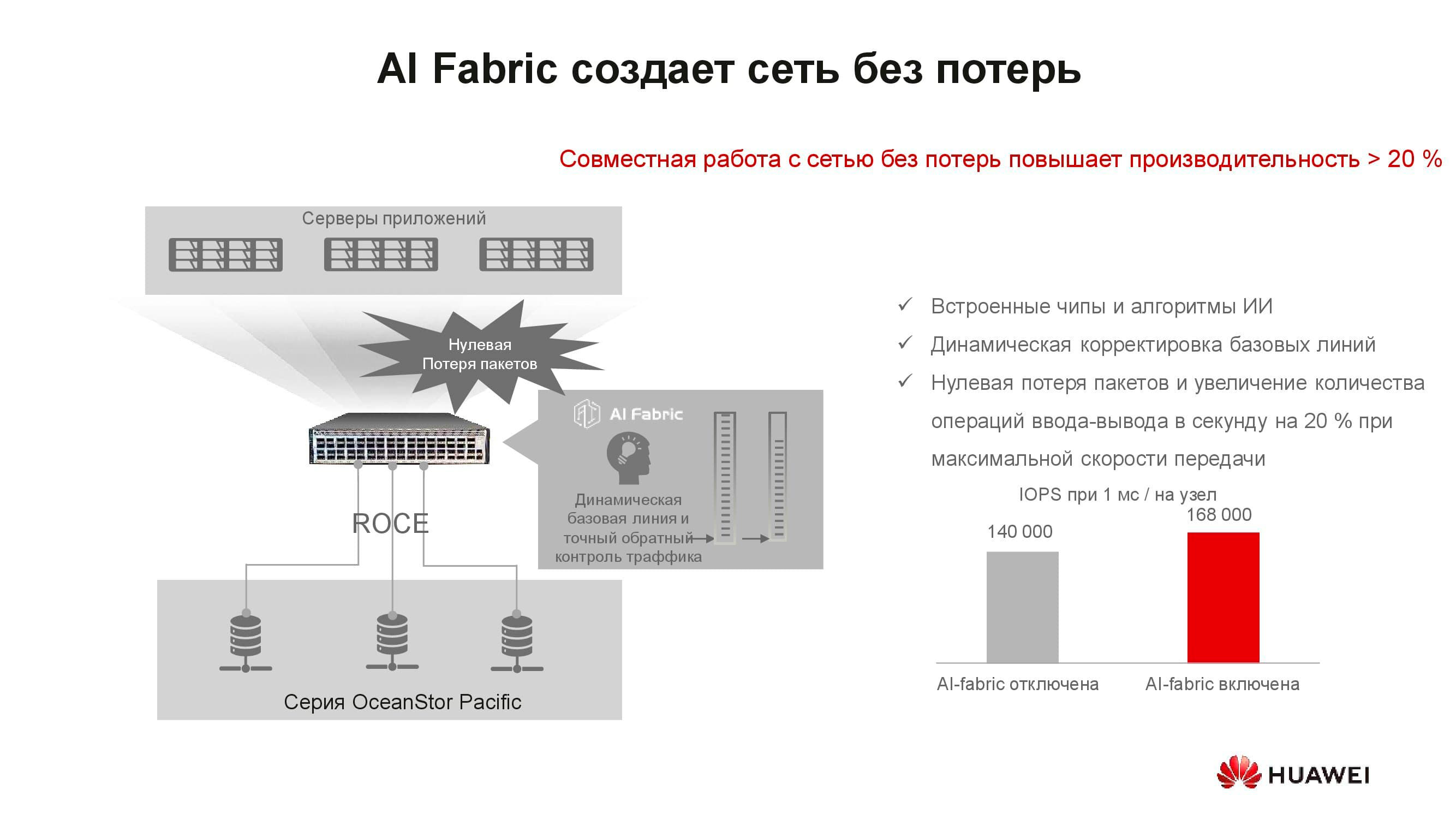
Ao que parece, o que o conceito de "rede sem perdas" tem a ver com armazenamento? O fato é que os sistemas de armazenamento distribuídos são construídos com base em uma rede rápida que suporta os algoritmos apropriados e o mecanismo RoCE. O AI Fabric com suporte em nossos switches ajuda a aumentar ainda mais a velocidade da rede e a reduzir a latência . Os ganhos de desempenho de armazenamento com a ativação do AI Fabric podem ser de até 20%.
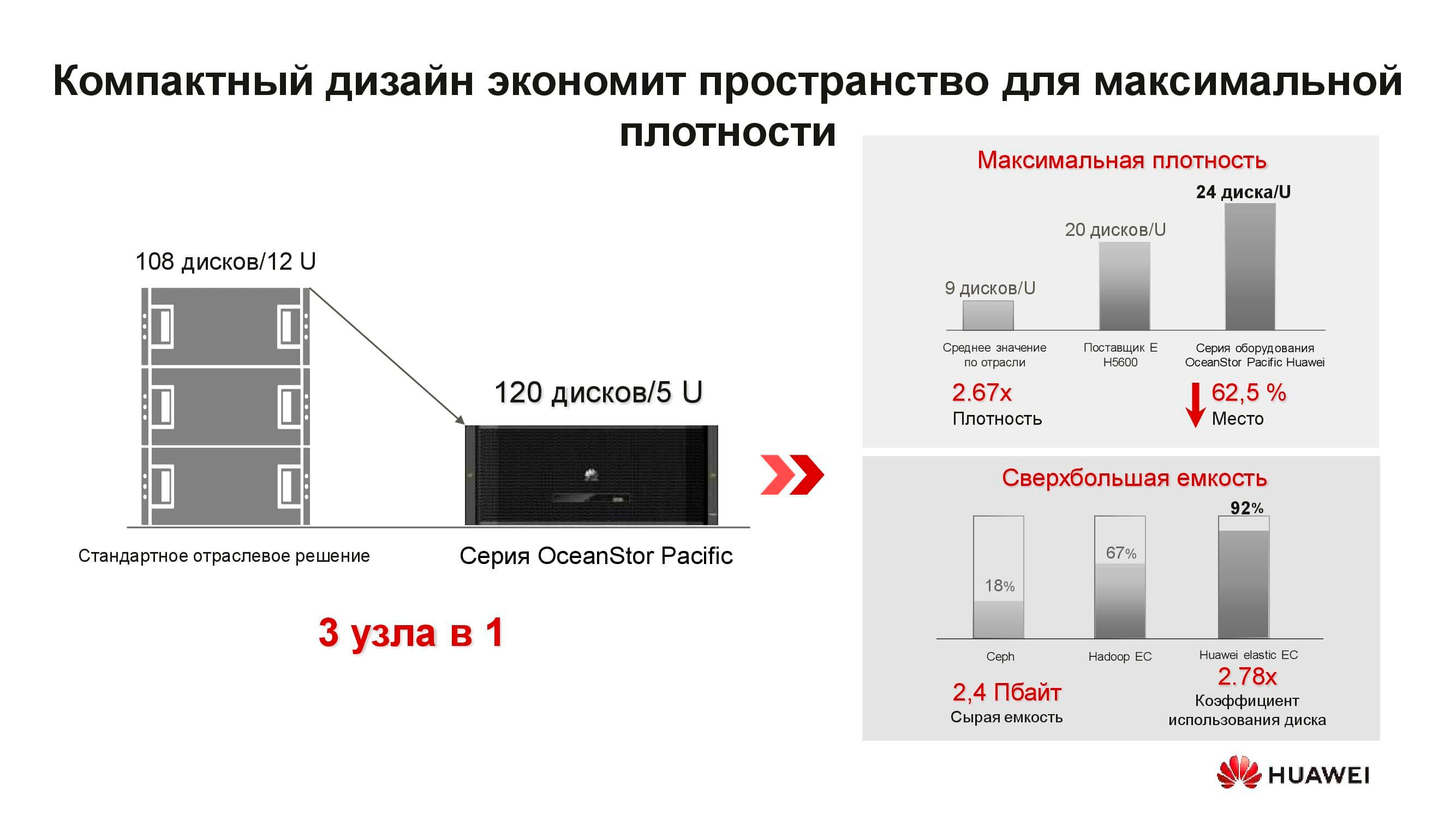
O que é o novo nó de armazenamento distribuído OceanStor Pacific? A solução 5U inclui 120 drives e pode substituir três nós clássicos, o que economiza mais de duas vezes o espaço do rack. Devido à recusa em armazenar cópias, a eficiência das unidades aumenta significativamente (até + 92%).
Estamos acostumados com o fato de que o armazenamento definido por software é um software especial instalado em um servidor clássico. Mas agora essa solução arquitetônica requer nós especiais para atingir os parâmetros ideais. Ele consiste em dois servidores baseados em processadores ARM, gerenciando uma série de unidades de 3 polegadas.
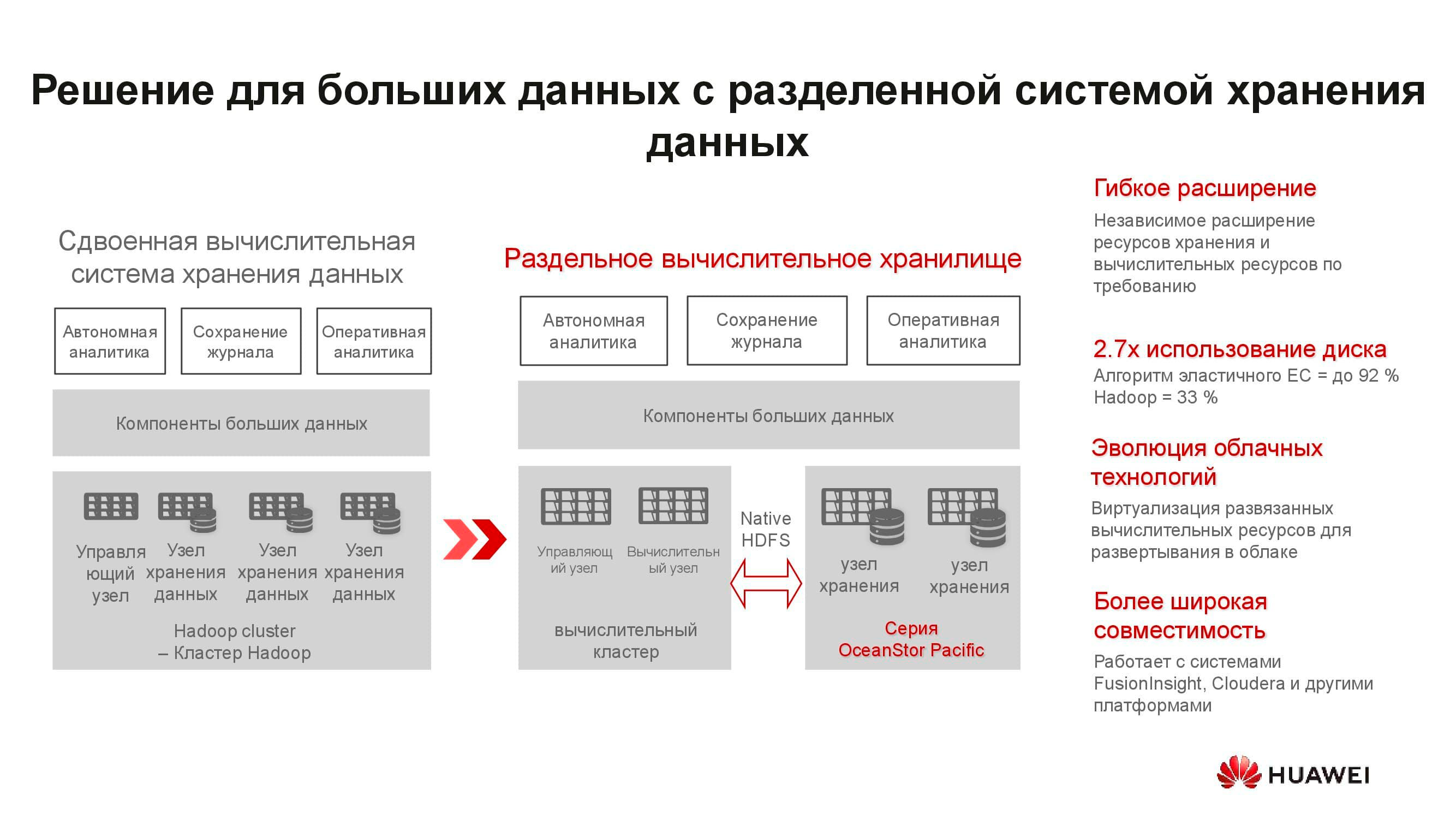
Esses servidores são inadequados para soluções hiperconvergentes. Em primeiro lugar, existem poucos aplicativos para ARM e, em segundo lugar, é difícil manter o equilíbrio da carga. Propomos mudar para armazenamento separado: um cluster computacional, representado por servidores clássicos ou em rack, opera separadamente, mas se conecta aos nós de armazenamento OceanStor Pacific, que também executam suas tarefas diretas. E isso se justifica.
Por exemplo, vamos pegar uma solução clássica de armazenamento de big data hiperconvergente que ocupa 15 racks de servidores. Ao separar a carga entre os servidores de computação individuais e os nós de armazenamento OceanStor Pacific, separando-os uns dos outros, o número de racks necessários é reduzido pela metade! Isso reduz o custo de operação do data center e reduz o custo total de propriedade. Em um mundo onde o volume de informações armazenadas cresce 30% ao ano, essas vantagens não estão espalhadas.
***
Você pode obter mais informações sobre as soluções e cenários da Huawei para seu uso em nosso site ou entrando em contato diretamente com os representantes da empresa.