
Recentemente, as grandes empresas russas estão cada vez mais buscando soluções de armazenamento acessíveis. SGBDs de código aberto tornam-se concorrentes de Oracle, SAP HANA, Sybase, Informix: PostgreSQL, MySQL, MariaDB, etc. Gigantes ocidentais - Alibaba, Instagram, Skype - os usam há muito tempo em seus ambientes de TI.
No projeto para a União Russa de Seguradoras de Automóveis (RSA), onde a Jet Infosystems estava construindo a infraestrutura de TI para o novo AIS OSAGO, os desenvolvedores usaram DBMS PostgreSQL. E pensamos em como garantir a disponibilidade máxima do banco de dados e perda mínima de dados no caso de falhas de hardware. E essa descrição "no papel" da solução parece tão simples quanto 2 + 2; na verdade, nossa equipe teve que trabalhar muito para alcançar a tolerância a falhas.
Existem várias ferramentas de clustering de failover para PostgreSQL. Estes são Stolon, Patroni, Repmgr, Pacemaker + Corosync, etc.
Escolhemos o Patroni porque este projeto está em desenvolvimento ativo, ao contrário de projetos semelhantes, tem uma documentação clara e está se tornando cada vez mais a escolha dos administradores de banco de dados.
A composição do "conjunto de sopa"
Patroni é um conjunto de scripts python para automatizar a troca da função principal de um servidor de banco de dados PostgreSQL para uma réplica. Ele também pode armazenar, modificar e aplicar parâmetros do próprio DBMS PostgreSQL. Acontece que não há necessidade de manter os arquivos de configuração do PostgreSQL atualizados em cada servidor separadamente.
PostgreSQL é um banco de dados relacional de código aberto. Ele provou sua capacidade de lidar com processos analíticos grandes e complexos.
Keepalived - em uma configuração de vários nós, é usado para habilitar um endereço IP dedicado no próprio nó do cluster onde a função do nó PostgreSQL primário é usada atualmente. O endereço IP serve como ponto de entrada para aplicativos e usuários.
DCS é um armazenamento de configuração distribuída. O Patroni o usa para armazenar informações sobre a composição do cluster, as funções dos servidores do cluster, bem como armazenar seus próprios parâmetros de configuração do PostgreSQL. Este artigo se concentrará no etcd.
Experimentos com nuances
Em busca da solução ótima de tolerância a falhas e para testar nossas hipóteses sobre o funcionamento de diferentes opções, criamos vários bancos de teste. Inicialmente, consideramos soluções diferentes da arquitetura de destino: por exemplo, usamos Haproxy porque o nó principal do PostgreSQL ou DCS estava localizado nos mesmos servidores do PostgreSQL. Organizamos hackathons internos, estudamos como Patroni se comportaria em caso de falha de componente do servidor, indisponibilidade da rede, estouro do sistema de arquivos, etc. Ou seja, eles elaboraram vários cenários de falha. Como resultado desses "estudos científicos", a arquitetura final da solução tolerante a falhas foi formada.
Prato de alta cozinha de TI
Existem funções de servidor no PostgreSQL: primário - uma instância com a capacidade de escrever / ler dados; réplica - uma instância somente leitura, constantemente sincronizada com o primário. Essas funções são estáticas quando o PostgreSQL está em execução e, se um servidor com a função primária falhar, o DBA deve elevar manualmente a função de réplica para primária.
Patroni cria clusters de failover, ou seja, combina servidores com as funções primária e de réplica. Há uma mudança automática de função entre eles em caso de falha.

A ilustração acima mostra como os servidores de aplicativos se conectam a um dos servidores no cluster Patroni. Essa configuração usa um nó primário e duas réplicas, uma das quais é síncrona. Com a replicação síncrona, o PostgreSQL funciona de forma que o primário sempre aguarda que as alterações sejam gravadas na réplica. Se a réplica síncrona não estiver disponível, o primário não gravará as alterações em si mesmo, será somente leitura. Esta é a arquitetura do PostgreSQL. Para "mudar sua natureza", a segunda réplica é usada - assíncrona (se a replicação síncrona não for necessária, você pode se limitar a uma réplica).
Ao usar duas ou mais réplicas e habilitar a replicação síncrona, o Patroni sempre faz apenas uma réplica síncrona. Se o nó primário falhar, o Patroni aumenta o nível da réplica síncrona.
A ilustração a seguir mostra a funcionalidade adicional do Patroni que é vital em soluções empresariais industriais - replicação de dados para um site de backup.
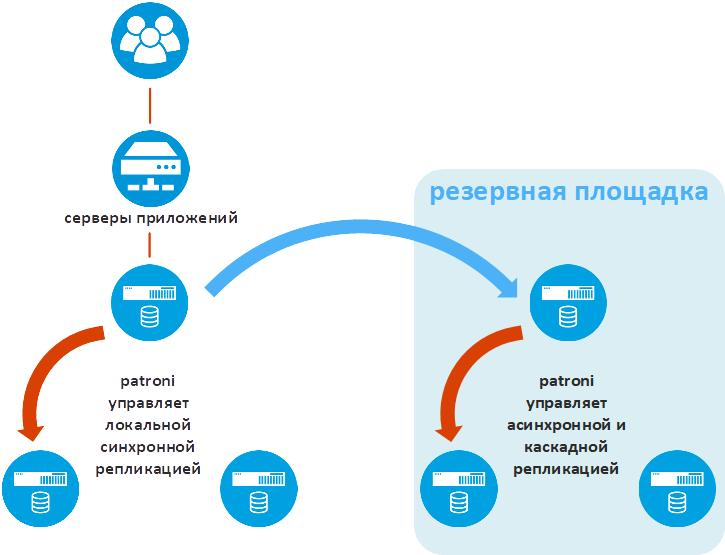
Patroni chama essa funcionalidade de standby_cluster. Ele permite que um cluster Ratroni seja usado em um site remoto como uma réplica assíncrona. Se o site principal for perdido, o cluster Patroni começará a funcionar como se fosse o site principal.
Um dos nós do cluster do site de backup é chamado Standby Leader. É uma réplica assíncrona do nó primário do site principal. Os dois nós restantes do cluster do site de backup recebem dados do Standby Leader. É assim que a replicação em cascata é implementada, o que reduz o volume de tráfego entre sites tecnológicos.
Composição de aplicativos de cluster Patroni
Uma vez iniciado, o Patroni cria uma porta TCP separada. Tendo feito uma solicitação HTTP para esta porta, você pode entender qual nó do cluster é primário e qual é réplica.

Em keepalived, especificamos um pequeno script feito pelo próprio como um objeto de monitoramento que controla a porta TCP Patroni. O script espera uma resposta HTTP GET 200. O nó do cluster que está respondendo é o nó Primário, no qual o keepalived inicia o endereço IP dedicado à conexão com o cluster.
Se você configurar a segunda instância de keepalived para aguardar uma resposta HTTP GET 200 de uma réplica síncrona, o keepalived no mesmo nó de cluster iniciará outro endereço IP dedicado. Este endereço pode ser usado pelo aplicativo para ler dados do banco de dados. Esta opção é útil, por exemplo, para preparar relatórios.
Como Patroni é um conjunto de scripts, suas instâncias em cada nó não "se comunicam" diretamente entre si, mas usam o armazenamento de configuração para isso. Usamos o etcd como ele, que é um quorum para o próprio Patroni - o nó primário atual atualiza constantemente a chave no repositório etcd, indicando que é o principal. O restante dos nós do cluster lêem constantemente essa chave e "entendem" que são réplicas. O serviço etcd está localizado em servidores dedicados no valor de 3 ou 5. A sincronização de dados no armazenamento etcd entre esses servidores é realizada por meio do próprio serviço etcd.
No decorrer de nossos experimentos, descobrimos que o serviço etcd precisa ser movido para servidores separados. Em primeiro lugar, o etcd é extremamente sensível à latência da rede e à capacidade de resposta do subsistema de disco, e os servidores dedicados não serão carregados. Em segundo lugar, com uma possível separação de rede dos nós do cluster Patroni, uma "divisão cerebral" pode ocorrer - dois nós primários aparecerão, que não saberão nada um sobre o outro, já que o cluster etcd também se "desintegrará".
Teste prático
Na escala de um projeto para construir uma infraestrutura de TI para AIS OSAGO, atingir a tolerância a falhas do PostgreSQL é uma das tarefas de "implantar" um SGBD aberto no cenário de TI corporativo. Ao lado dele estão questões relacionadas à integração do cluster PostgreSQL com sistemas de backup, monitoramento de infraestrutura e ferramentas de segurança da informação e segurança de dados confiável no site de backup. Cada uma dessas direções tem suas próprias armadilhas e maneiras de contorná-las. Já escrevemos sobre um deles - falamos sobre o backup PostgreSQL usando soluções corporativas .

A arquitetura de tolerância a falhas do PostgreSQL, pensada e testada por nós nos estandes, provou sua eficácia na prática. A solução está pronta para "transferir" vários sistemas e falhas lógicas. Agora, ele roda em 10 clusters Patroni altamente carregados e suporta cargas de processamento PostgreSQL de centenas de gigabytes de dados por hora.
Autor: Dmitry Erykin, e engenheiro-projetista de sistemas de computação da Jet Infosystems