Há cerca de um ano, nossa divisão de infraestrutura está migrando todos os serviços executados no GitLab.com para o Kubernetes. Durante esse tempo, encontramos problemas não apenas com a transferência de serviços para o Kubernetes, mas também com o gerenciamento da implantação híbrida durante a transição. As valiosas lições que aprendemos serão discutidas neste artigo.
Desde o início do GitLab.com, seus servidores eram executados na nuvem em máquinas virtuais. Essas máquinas virtuais são gerenciadas pelo Chef e instaladas usando nosso pacote oficial do Linux . A estratégia de implantação no caso de um aplicativo precisar ser atualizado é simplesmente atualizar a frota de servidores de uma maneira sequencial coordenada usando o pipeline de CI. Este método - embora lento e um pouco enfadonho - garante que GitLab.com use os mesmos métodos de instalação e configuração que os usuários de instalações autogerenciadas do GitLab usando nossos pacotes Linux.
Usamos esse método porque é extremamente importante sentir toda a tristeza e alegria que os membros comuns da comunidade experimentam ao instalar e configurar suas cópias do GitLab. Essa abordagem funcionou bem por algum tempo, mas como o número de projetos no GitLab ultrapassou 10 milhões, percebemos que ele não atendia mais às nossas necessidades de dimensionamento e implantação.
Primeiras etapas para o Kubernetes e GitLab nativo da nuvem
Em 2017, o projeto GitLab Charts foi criado para preparar o GitLab para implantação na nuvem, bem como para permitir que os usuários instalem o GitLab em clusters Kubernetes. Sabíamos então que mover o GitLab para o Kubernetes aumentaria a escalabilidade da plataforma SaaS, simplificaria as implantações e aumentaria a eficiência da computação. Ao mesmo tempo, muitos recursos de nosso aplicativo dependiam de partições NFS montadas, o que retardava a transição das máquinas virtuais.
A busca pelo nativo da nuvem e pelo Kubernetes permitiu que nossos engenheiros planejassem uma transição gradual, durante a qual abandonamos algumas das dependências NAS do aplicativo enquanto continuamos a desenvolver novos recursos ao longo do caminho. Desde que começamos a planejar a migração no verão de 2019, muitas dessas restrições foram removidas e o processo de migração do GitLab.com para o Kubernetes está em pleno andamento!
Recursos do trabalho de GitLab.com no Kubernetes
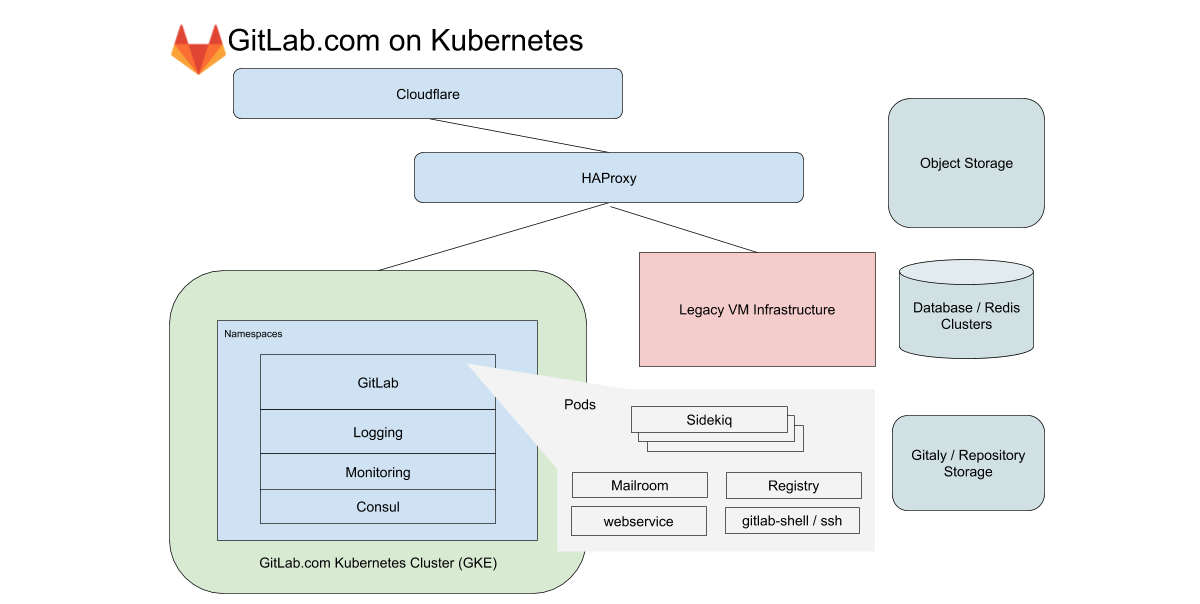
Para GitLab.com, usamos um único cluster GKE regional que lida com todo o tráfego de aplicativos. Para minimizar a complexidade da (já complicada) migração, nos concentramos em serviços que não dependem de armazenamento local ou NFS. GitLab.com usa uma base de código Rails predominantemente monolítica e roteamos o tráfego com base nas características da carga de trabalho para vários endpoints isolados em nossos próprios pools de nós.
No caso do front-end, esses tipos são divididos em solicitações para a web, API, Git SSH / HTTPS e Registro. No caso do back-end, enfileiramos os trabalhos de acordo com diferentes características, dependendo dos limites de recursos predefinidos que nos permitem definir objetivos de nível de serviço (SLOs) para diferentes cargas de trabalho.
Todos esses serviços GitLab.com são configurados usando um gráfico GitLab Helm não modificado. A configuração é feita em subcharts, que podem ser ativados seletivamente conforme migramos gradualmente os serviços para o cluster. Embora tenha sido decidido não incluir alguns de nossos serviços com monitoração de estado, como Redis, Postgres, GitLab Pages e Gitaly na migração, o Kubernetes reduz drasticamente o número de VMs que o Chef gerencia atualmente.
Transparência do Kubernetes e gerenciamento de configuração
Todas as configurações são controladas pelo próprio GitLab. Para isso, três projetos de configuração baseados em Terraform e Helm são usados. Tentamos usar o próprio GitLab sempre que possível para executar o GitLab, mas para tarefas operacionais temos uma instalação separada do GitLab. É necessário ser independente da disponibilidade do GitLab.com para implantações e atualizações do GitLab.com.
Embora nossos pipelines para o cluster Kubernetes sejam executados em uma instalação separada do GitLab, os repositórios de código têm espelhos disponíveis publicamente nos seguintes endereços:
- k8s-workloads / gitlab-com - vinculação de configuração GitLab.com para o gráfico GitLab Helm;
- k8s-workloads/gitlab-helmfiles — , GitLab . , PlantUML;
- Gitlab-com-infrastructure — Terraform Kubernetes (legacy) VM-. , , , , , IP-.

Quando são feitas alterações, um breve resumo disponível publicamente é mostrado com um link para uma comparação detalhada, que o SRE analisa antes de fazer alterações no cluster.
Para SREs, o link aponta para uma diferença detalhada na instalação do GitLab que está sendo usada para produção e o acesso é limitado. Isso permite que os funcionários e a comunidade sem acesso ao projeto operacional (é aberto apenas para o SRE) visualizem as alterações de configuração propostas. Ao combinar uma instância pública do GitLab para código com uma instância privada para pipelines de CI, mantemos um único fluxo de trabalho, garantindo a independência de GitLab.com para atualizações de configuração.
O que descobrimos durante a migração
Durante a mudança, ganhamos experiência que aplicamos a novas migrações e implantações no Kubernetes.
1. -

Estatísticas de saída diária (bytes por dia) para o parque de repositório Git em GitLab.com O
Google divide sua rede em regiões. Essas, por sua vez, são divididas em zonas de disponibilidade (AZ). A hospedagem Git está associada a grandes quantidades de dados, por isso é importante para nós controlar a saída da rede. Para tráfego interno, a saída é gratuita apenas se permanecer na mesma AZ. No momento da redação deste artigo, estamos distribuindo cerca de 100 TB de dados em um dia útil típico (e isso apenas para repositórios Git). Serviços que estavam nas mesmas VMs em nossa antiga topologia baseada em VM agora são executados em diferentes pods do Kubernetes. Isso significa que parte do tráfego que antes era local para a VM pode sair potencialmente das zonas de disponibilidade.
Os clusters regionais do GKE permitem que você abranja várias zonas de disponibilidade para redundância. Estamos considerando dividir o cluster regional do GKE em clusters de zona única para serviços que geram grandes volumes de tráfego. Isso reduzirá os custos de saída, mantendo a redundância do cluster.
2. Limites, solicitações de recursos e escala

O número de réplicas que processam o tráfego de produção em registry.gitlab.com. O tráfego atinge o pico às 15:00 UTC.
Nossa história de migração começou em agosto de 2019, quando portamos nosso primeiro serviço, o GitLab Container Registry, para o Kubernetes. Esse serviço de missão crítica de alto tráfego foi bem adequado para a primeira migração porque é um aplicativo sem estado com poucas dependências externas. O primeiro problema que encontramos foi o grande número de pods antecipados devido à memória insuficiente nos nós. Por causa disso, tivemos que alterar solicitações e limites.
Verificou-se que, no caso da aplicação em que o consumo de memória aumenta com o tempo, baixos valores para request'ov (para cada pod'a de memória redundante) juntamente com "generoso" rígido limit'om para usar levam a unidades de saturação (saturação) e um alto nível de deslocamento. Para lidar com esse problema, decidiu-se aumentar as solicitações e diminuir os limites . Isso tirou a pressão dos nós e garantiu um ciclo de vida do pod que não colocou muita pressão sobre o nó. Agora começamos as migrações com solicitações generosas (e quase idênticas) e valores de limite, ajustando-os conforme necessário.
3. Métricas e registros

A infraestrutura se concentra na latência, taxas de erro e saturação com objetivos de nível de serviço (SLOs) estabelecidos vinculados à disponibilidade geral de nosso sistema .
No ano passado, um dos principais desenvolvimentos na divisão de infraestrutura foram as melhorias no monitoramento e no trabalho com SLOs. Os SLOs nos permitiram definir metas para serviços individuais, que monitoramos de perto durante a migração. Mas, mesmo com essa capacidade de observação aprimorada, nem sempre é possível ver imediatamente os problemas usando métricas e alertas. Por exemplo, ao nos concentrarmos nas taxas de latência e erro, não cobrimos totalmente todos os casos de uso de um serviço em migração.
Esse problema foi descoberto quase imediatamente após mover algumas das cargas de trabalho para o cluster. Tornou-se especialmente agudo quando era necessário verificar funções, cujo número de requisições é pequeno, mas que têm dependências de configuração muito específicas. Uma das principais lições dos resultados da migração foi a necessidade de levar em consideração ao monitorar não apenas as métricas, mas também os logs e a "cauda longa" (estamos falando sobre sua distribuição no gráfico - transl. Aprox.) . Agora, para cada migração, incluímos uma lista detalhada de consultas de log e planejamos procedimentos de reversão claros que podem ser passados de um turno para outro em caso de problemas.
Atender as mesmas solicitações em paralelo na infraestrutura de VM antiga e na nova baseada no Kubernetes foi um desafio único. Ao contrário da migração lift-and-shift (transferência rápida de aplicativos "como estão" para uma nova infraestrutura; você pode ler mais detalhes, por exemplo, aqui - tradução aproximada) , o trabalho paralelo em VMs "antigas" e Kubernetes requer ferramentas para os sistemas de monitoramento eram compatíveis com os dois ambientes e podiam combinar métricas em uma visão. É importante que usemos os mesmos painéis e consultas de log para obter observabilidade consistente durante a transição.
4. Mudar o tráfego para um novo cluster
Para GitLab.com, alguns dos servidores são alocados para o estágio canário . O Canary Park atende aos nossos projetos internos e também pode ser ativado pelos usuários . Mas, antes de mais nada, ele se destina a validar as alterações feitas na infraestrutura e no aplicativo. O primeiro serviço migrado começou aceitando uma quantidade limitada de tráfego interno e continuamos a usar esse método para garantir que o SLO seja atendido antes de encaminhar todo o tráfego para o cluster.
No caso da migração, isso significa que primeiro as solicitações para projetos internos são enviadas para o Kubernetes e, em seguida, mudamos gradualmente o restante do tráfego para o cluster, alterando o peso do back-end por meio do HAProxy. No processo de mudança da VM para o Kubernetes, ficou claro que era muito benéfico ter uma maneira fácil de redirecionar o tráfego entre a infraestrutura antiga e a nova e, portanto, manter a infraestrutura antiga pronta para reversão nos primeiros dias após a migração.
5. Reserve energia dos frutos e seu uso
Quase imediatamente, o seguinte problema foi identificado: os pods do serviço de registro foram iniciados rapidamente, mas os pods do Sidekiq demoraram até dois minutos para iniciar . Os pods de longa execução para Sidekiq se tornaram um problema quando começamos a migrar cargas de trabalho para o Kubernetes para trabalhadores que precisam processar jobs rapidamente e escalar rapidamente.
Nesse caso, a lição foi que, embora o Autoescalador Horizontal de Pod (HPA) no Kubernetes lide bem com o crescimento do tráfego, é importante levar em consideração as características das cargas de trabalho e alocar capacidade de pod reserva (especialmente em um ambiente de distribuição de demanda desigual) Em nosso caso, houve um aumento repentino nas tarefas, acarretando em um escalonamento rápido, o que levou à saturação dos recursos da CPU antes que tivéssemos tempo de escalar o pool de nós.
Sempre há a tentação de extrair o máximo possível do cluster, no entanto, nós, inicialmente enfrentando problemas de desempenho, agora começamos com um orçamento de pod generoso e diminuímos mais tarde, mantendo um olho atento no SLO. O lançamento de pods para o serviço Sidekiq foi significativamente acelerado e agora leva cerca de 40 segundos em média.Tanto o GitLab.com quanto nossos usuários de instalações autogerenciadas que trabalham com o gráfico oficial do GitLab Helm se beneficiaram com a redução nos tempos de inicialização do pod .
Conclusão
Depois de migrar cada serviço, desfrutamos dos benefícios de usar o Kubernetes na produção: implantação de aplicativos mais rápida e segura, escalonamento e alocação de recursos mais eficiente. Além disso, as vantagens da migração vão além do serviço GitLab.com. Cada melhoria no gráfico oficial do Helm também beneficia seus usuários.
Espero que você tenha gostado da história de nossas aventuras de migração do Kubernetes. Continuamos migrando todos os novos serviços para o cluster. Informações adicionais podem ser obtidas nas seguintes publicações:
- « Por que estamos migrando para o Kubernetes <br> we? ";
- " GitLab.com no Kubernetes ";
- Épico na migração de GitLab.com para Kubernetes .
PS do tradutor
Leia também em nosso blog: