
Uma das primeiras advertências que um jovem Padawan recebe com acesso aos repositórios git é: "nunca
git push -f." Como esta é uma das centenas de máximas que um engenheiro de software novato precisa aprender, ninguém se preocupa em esclarecer por que isso não deve ser feito. É como bebês e fogo: “fósforos não são brinquedos para crianças” e pronto. Mas crescemos e nos desenvolvemos como pessoas e como profissionais, e um dia a pergunta "por que, na verdade?" sobe em pleno crescimento. Este artigo foi escrito com base em nosso encontro interno, sobre o tema: "Quando você pode e deve reescrever o histórico de commits."

Ouvi dizer que a capacidade de responder a essa pergunta em uma entrevista em algumas empresas é um critério para entrevistas para cargos seniores. Mas para entender melhor a resposta a ela, você precisa descobrir por que reescrever a história é ruim?
Para fazer isso, por sua vez, precisamos fazer uma excursão rápida na estrutura física do repositório git. Se você tem certeza de que sabe tudo sobre o dispositivo repo, pode pular esta parte, mas mesmo no processo de descoberta, aprendi muitas coisas novas por mim mesmo, e algumas antigas acabaram não sendo muito relevantes.
No nível mais baixo, um repo git é uma coleção de objetos e ponteiros para eles. Cada objeto tem seu próprio hash de 40 dígitos (20 bytes hexadecimais), que é calculado com base no conteúdo do objeto.
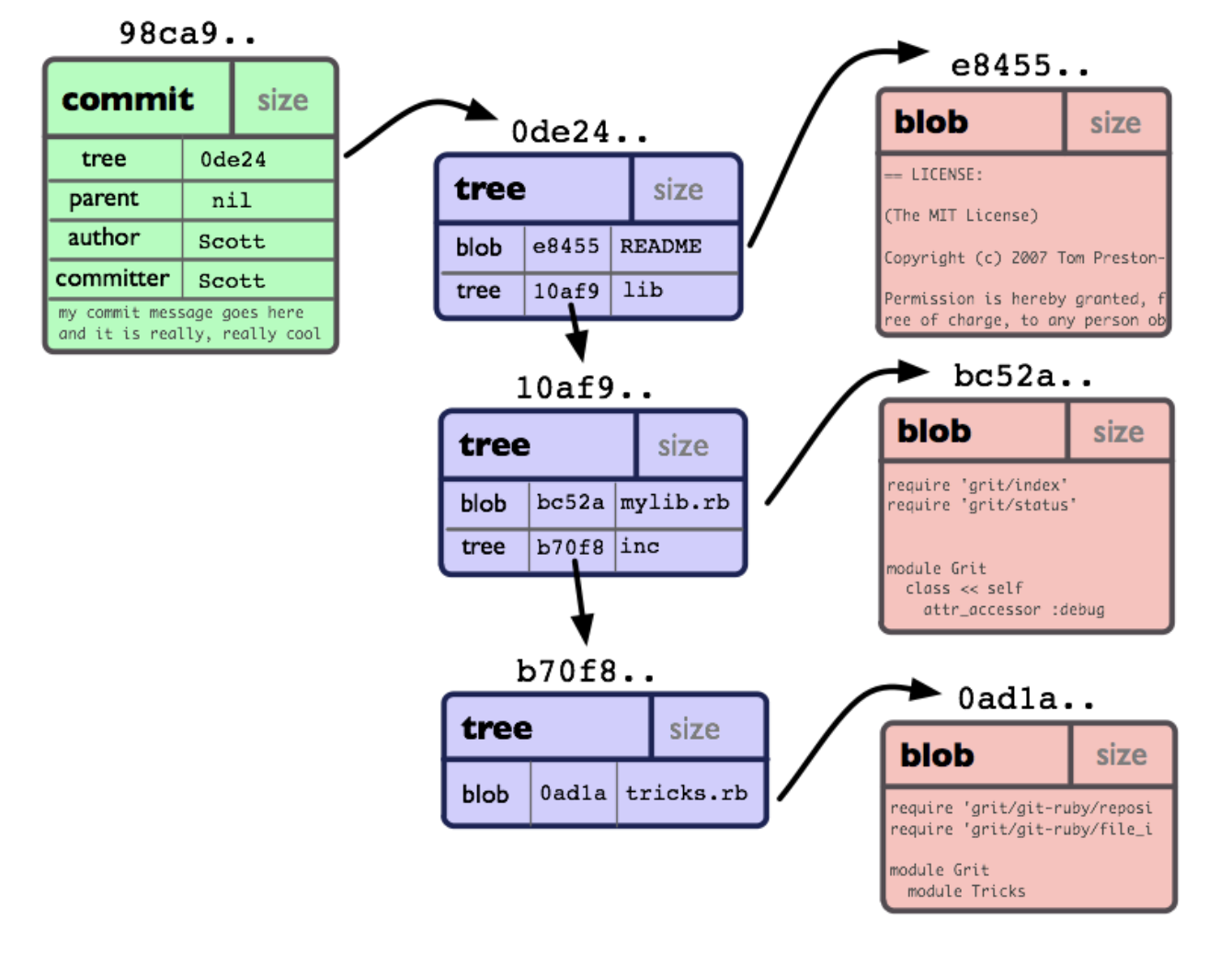
Ilustração tirada do livro da comunidade Git
Os principais tipos de objeto são blob (apenas o conteúdo de um arquivo), tree (uma coleção de ponteiros para blobs e outras árvores) e commit. Um objeto do tipo commit é apenas um ponteiro para a árvore, para o commit anterior e informações de serviço: data / hora, autor e comentário.
Onde estão os branches e tags com os quais costumávamos operar? E eles não são objetos, são apenas ponteiros: um branch aponta para o último commit nele, uma tag aponta para um commit arbitrário no repo. Ou seja, quando vemos ramos lindamente desenhados com círculos de commit neles no cliente IDE ou GUI, eles são construídos na hora, rodando ao longo das cadeias de commit desde o final dos ramos até a "raiz". O primeiro commit no repo não tem nenhum anterior, em vez de um ponteiro, é nulo.
Um ponto importante a entender: o mesmo commit pode aparecer em vários branches ao mesmo tempo. Os commits não são copiados quando um novo branch é criado, ele apenas começa a "crescer" de onde HEAD estava quando o comando foi emitido
git checkout -b <branch-name>.
Então, por que reescrever a história de um repositório é prejudicial?

Primeiro, e isso é óbvio, quando você faz upload de uma nova história para o repositório com o qual a equipe de engenharia está trabalhando, outras pessoas podem simplesmente perder suas alterações. O comando
git push -f remove da ramificação no servidor todos os commits que não estão na versão local e grava novos.
Por algum motivo, poucas pessoas sabem que há muito tempo a equipe
git pushtem uma chave "segura"--force-with-leaseo que faz com que o comando falhe se houver commits adicionados por outros usuários ao repositório remoto. Eu sempre recomendo usá-lo -f/--force.
A segunda razão pela qual o comando
git push -fé considerado prejudicial é que ao tentar mesclar um branch com um histórico reescrito com os branches onde ele foi preservado (mais precisamente, os commits removidos do histórico reescrito foram salvos), teremos um grande número de conflitos (pelo número confirma, na verdade). Há uma resposta simples para isso: se você seguir cuidadosamente o Gitflow ou o Gitlab Flow , é provável que essas situações nem mesmo ocorram.
E, finalmente, há um lado desagradável de reescrever a história: aqueles commits que são, por assim dizer, removidos do branch, na verdade, não desaparecem em lugar nenhum e simplesmente permanecem para sempre no repo. Uma ninharia, mas desagradável. Felizmente, os desenvolvedores git também resolveram esse problema, com o comando garbage collection
git gc --prune. A maioria dos hosts git, pelo menos GitHub e GitLab, fazem isso em segundo plano de vez em quando.
Assim, tendo dissipado os temores de mudar a história do repositório, podemos finalmente passar à questão principal: por que é necessário e quando se justifica?
Na verdade, tenho certeza de que quase todos os usuários git mais ou menos ativos mudaram de história pelo menos uma vez, quando de repente descobriu que algo deu errado no último commit: um erro de digitação irritante entrou no código, fez um commit não daquele usuário (do e-mail pessoal ao invés do trabalho ou vice-versa), esqueceu de adicionar um novo arquivo (se você, como eu, gosta de usar
git commit -a). Até mesmo alterar a descrição de um commit leva à necessidade de reescrevê-lo, porque o hash também é contado a partir da descrição!
Mas este é um caso trivial. Vejamos outros mais interessantes.
Digamos que você fez um grande recurso, que você viu por vários dias, enviando resultados diários do trabalho para o repositório no servidor (4-5 commits), e enviou suas alterações para revisão. Dois ou três revisores incansáveis cobriram de você grandes e pequenas recomendações para edições, ou mesmo encontraram jambs (mais 4-5 commits). Então, o QA encontrou vários casos extremos que também exigem correções (mais 2 ou 3 commits). E por fim, durante a integração, foram constatadas algumas incompatibilidades ou entrados autotestes, que também precisam ser corrigidos.
Se agora você pressionar o botão Mesclar sem olhar, uma dúzia e meia de commits como "Meu recurso, dia 1", "Dia 2", "Corrigir testes", "Corrigir revisão" serão adicionados ao branch principal (para muitos, é chamado de mestre à moda antiga) etc. Isso, é claro, ajuda o modo squash, que agora está no GitHub e no GitLab, mas você precisa ter cuidado com isso: em primeiro lugar, ele pode substituir a descrição do commit por algo imprevisível e, em segundo lugar, substituir o autor do recurso naquele que pressionou o botão Merge (em nosso país, geralmente é um robô ajudando o engenheiro de liberação a construir a implantação de hoje). Portanto, a coisa mais simples será, antes da integração final no lançamento, recolher todos os commits do branch em um usando
git rebase.
Mas também acontece que você já abordou a revisão do código com um histórico de repo que lembra a salada de Olivier. Isso acontece se um recurso foi serrado por várias semanas, porque estava mal decomposto, ou, embora equipes decentes tenham sido golpeadas com um candelabro para isso, os requisitos mudaram durante o processo de desenvolvimento. Por exemplo, aqui está uma solicitação real de mesclagem que me veio para uma revisão duas semanas atrás:
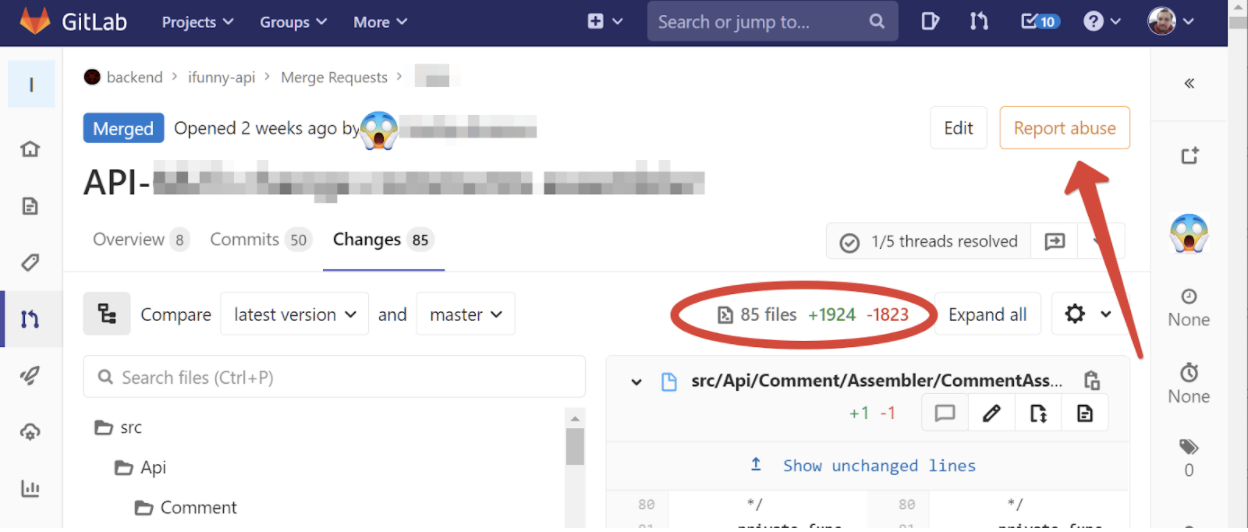
Minha mão automaticamente alcançou o botão "Denunciar abuso", porque de que outra forma você pode caracterizar uma solicitação com 50 commits com quase 2.000 linhas alteradas? E como, alguém se pergunta, revisá-lo?
Para ser honesto, levei dois dias apenas para me forçar a começar esta revisão. E esta é uma reação normal para um engenheiro; alguém em situação semelhante, apenas sem olhar, pressiona Aprovar, percebendo que em um tempo razoável ainda não será capaz de fazer o trabalho de revisar essa mudança com qualidade suficiente.
Mas existe uma maneira de tornar a vida mais fácil para um amigo. Além do trabalho preliminar para uma melhor decomposição do problema, após a conclusão da escrita do código principal, você pode trazer a história de sua escrita em uma forma mais lógica, dividindo-a em commits atômicos com testes verdes em cada um: "criou um novo serviço e uma camada de transporte para ele", "construiu modelos e escreveu verificação de invariantes "," validação adicionada e tratamento de exceção "," testes escritos "
Cada um desses commits pode ser revisado separadamente (tanto GitHub quanto GitLab podem fazer isso) e fazê-lo em raids ao alternar entre tarefas ou em intervalos.
O mesmo
git rebasecom a chave nos ajudará a fazer tudo isso --interactive. Como parâmetro, você precisa passar o hash do commit, a partir do qual você precisará reescrever o histórico. Se estamos falando sobre os últimos 50 commits, como no exemplo da imagem, você pode escrever git rebase --interactive HEAD~50(substitua seu número por “50”).
A propósito, se você adicionou o branch master a você mesmo no processo de trabalho em uma tarefa, então você primeiro precisará rebase este branch para que os commits e commits do master não se confundam sob seus pés.
Armado com o conhecimento interno de um repositório git, deve ser fácil entender como o rebase funciona no master. Este comando pega todos os commits em nosso branch e muda o pai do primeiro para o último commit no branch master. Veja o diagrama: As
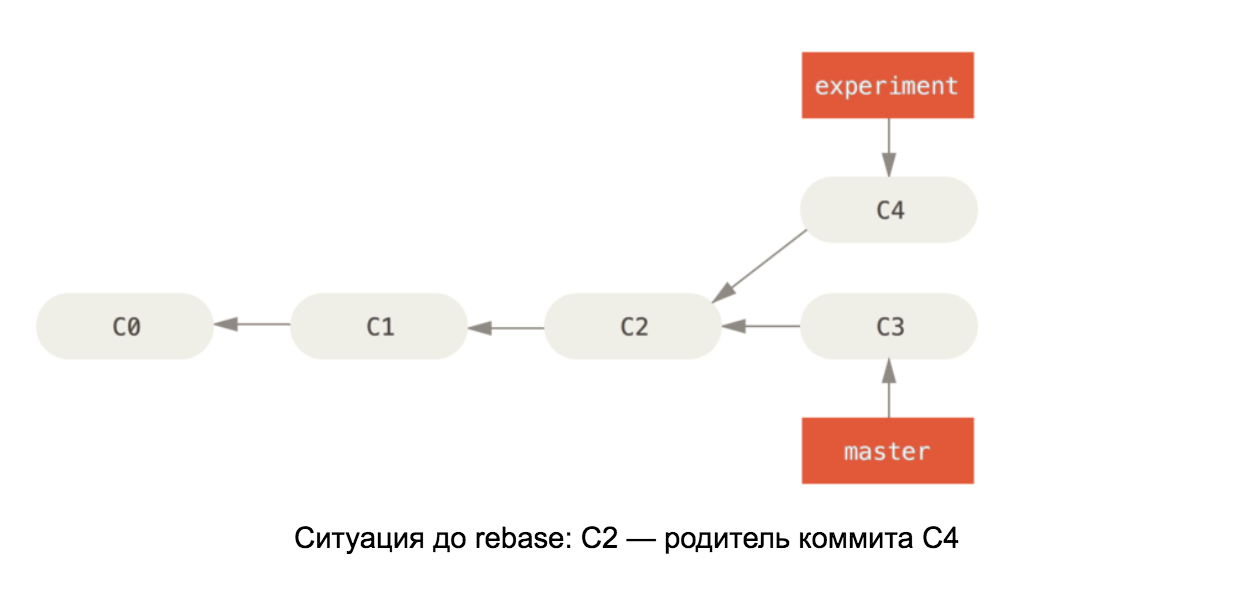
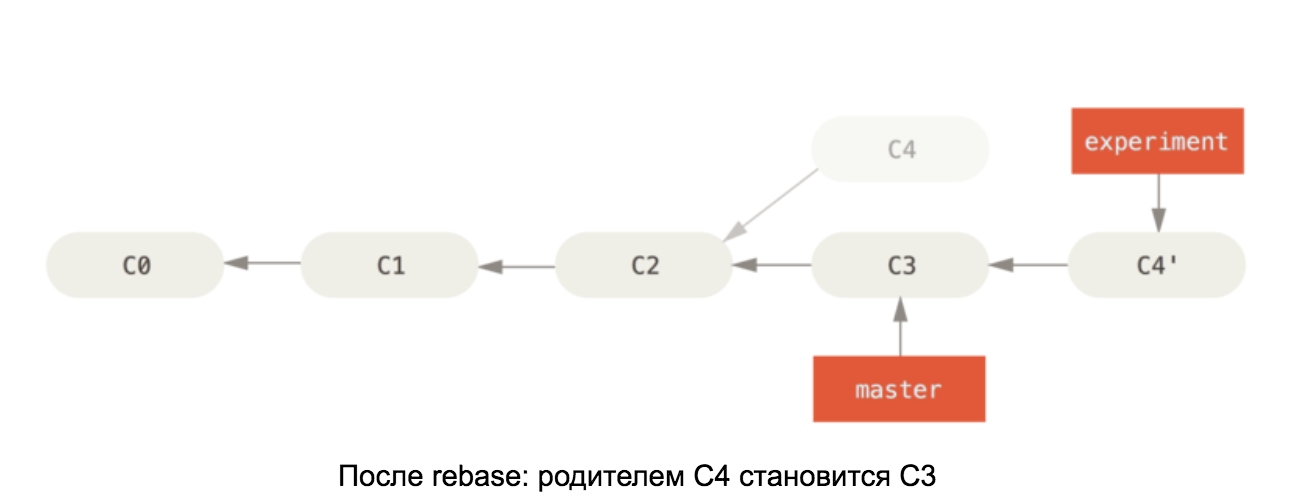
ilustrações foram tiradas do livro Pro Git.
Se houver mudanças no conflito C4 e C3, depois que o conflito for resolvido, o commit C4 mudará seu conteúdo, por isso é renomeado no segundo diagrama para C4 '.
Dessa forma, você acabará com um branch que consiste apenas em suas alterações e crescendo do topo do master. Claro, o mestre deve estar atualizado. Você pode apenas usar a versão do servidor:
git pull --rebase origin/master(como você sabe, é git pullequivalente git fetch && git merge, e a chave --rebaseforçará o git a rebase em vez de mesclar).
Vamos finalmente voltar para
git rebase --interactive... Ele foi feito por programadores para programadores, e percebendo o estresse que as pessoas sentirão no processo, tentamos preservar os nervos do usuário o máximo possível e salvá-lo da necessidade de se esforçar excessivamente. Isto é o que você verá na tela:
Este é o repositório do popular pacote Guzzle. Parece que ele poderia usar um rebase ...
O arquivo gerado é aberto em um editor de texto. Abaixo você encontrará informações detalhadas sobre o que fazer aqui. Em seguida, no modo de edição fácil, você decide o que fazer com os commits em seu branch. Tudo é tão simples quanto um stick: pick - deixe como está, reescreva - altere a descrição do commit, squash - mescle com o anterior (o processo funciona de baixo para cima, ou seja, o anterior é a linha abaixo), solte - exclua completamente, edite - e este é o interessante é parar e congelar. Depois que o git encontrar o comando edit, ele assumirá a posição onde as alterações no commit já foram adicionadas ao modo de teste. Você pode alterar qualquer coisa neste commit, adicionar mais alguns em cima dele e então comandar
git rebase --continuepara continuar o processo de rebase.
Ah, e por falar nisso, você pode trocar commits. Isso pode criar conflitos, mas, em geral, o processo de rebase raramente é totalmente livre de conflitos. Como se costuma dizer, tendo arrancado a cabeça, não choram pelos cabelos.
Se você ficar confuso e parecer que tudo se foi, você tem um botão de ejeção de emergência
git rebase --abortque irá retornar tudo imediatamente.
Você pode repetir o rebase várias vezes, tocando apenas partes da história e deixando o resto intocado com a picareta, dando à sua história uma aparência cada vez mais acabada, como uma jarra de oleiro. É uma boa prática, como escrevi acima, ter certeza de que os testes em cada commit serão verdes (para isso, editar ajuda perfeitamente e na próxima passagem - squash).
Outra acrobacia, útil no caso de você precisar decompor várias alterações no mesmo arquivo em commits diferentes -
git add --patch. Pode ser útil por si só, mas em combinação com a diretiva de edição, permitirá que você divida um commit em vários, e faça isso no nível de linhas individuais, o que, se não estou enganado, nenhum cliente GUI e nenhum IDE não permite.
Mais uma vez para garantir que tudo está em ordem, você pode finalmente com a paz de espírito para fazer alguma coisa, o que começou este tutorial:
git push --force. Oh, claro que sim --force-with-lease!

No início, você provavelmente gastará uma hora nesse processo (incluindo o rebase inicial no master), ou até duas se o recurso estiver realmente se espalhando. Mas mesmo isso é muito melhor do que esperar dois dias para que o revisor se force a finalmente aceitar seu pedido, e mais alguns dias até que ele o cumpra. No futuro, você provavelmente caberá em 30-40 minutos. Os produtos IntelliJ com ferramenta de resolução de conflitos integrada (divulgação completa: a FunCorp paga por esses produtos aos seus funcionários) são especialmente úteis nisso.
A última coisa que quero alertar é não reescrever o histórico do branch durante a revisão do código. Lembre-se de que um revisor cuidadoso pode clonar seu código localmente para poder examiná-lo por meio do IDE e executar testes.
Obrigado a todos que leram até o fim! Espero que este artigo seja útil não apenas para você, mas também para colegas que recebem seu código para revisão. Se você tem alguns hacks git legais - compartilhe-os nos comentários!