
Eu escrevo muito sobre pesquisar bugs complicados - bugs de CPU, bugs de kernel, alocação de memória intermediária de 4 GB, mas a maioria dos bugs não são tão exóticos. Às vezes, para encontrar um bug, você só precisa olhar o painel do servidor, passar alguns minutos no criador de perfil ou ler os avisos do compilador.
Neste artigo, irei cobrir os três principais bugs que encontrei e corrigi; todos eles não se esconderam e apenas esperaram que alguém os notasse.
Surpresa no processador do servidor

Vários anos atrás, passei várias semanas estudando o comportamento da memória em servidores de jogos ativos. Os servidores rodavam Linux em datacenters remotos, então a maior parte do tempo era gasto obtendo as permissões necessárias para que eu pudesse fazer um túnel para os servidores, bem como aprendendo como trabalhar efetivamente com perf e outras ferramentas de diagnóstico do Linux. Descobri uma série de bugs que faziam com que o consumo de memória fosse três vezes maior do que o necessário e os resolvi:
- Eu encontrei uma incompatibilidade no ID do mapa, o que fazia com que cada jogo não usasse a mesma cópia de aproximadamente 20 MB de dados, mas carregasse uma nova.
- Encontrei uma variável global de 50 MB não utilizada (!) (!!), que foi definida como zero memset (!!!), o que fez com que consumisse RAM física em todos os processos.
- Vários bugs menos graves.
Mas nossa história não será sobre isso.
Depois de aprender como criar o perfil de nossos servidores de jogo, percebi que poderia investigar isso um pouco mais a fundo. Portanto, executei o perf nos servidores de um de nossos jogos. O primeiro processo de servidor que criei foi ... estranho. Assistindo os dados do processador de amostra “ao vivo”, vi que uma única função consumia 100% do tempo da CPU. No entanto, apenas quatorze instruções foram executadas nesta função. Não fazia sentido.
No início, presumi que estava usando o perf incorretamenteou interpretando mal os dados. Observei alguns dos outros processos do servidor e descobri que cerca de metade deles estava em um estado estranho. A segunda metade teve um perfil de CPU mais normal.
A função de nosso interesse passou pela lista vinculada de nós de navegação. Perguntei a meus colegas e encontrei um programador que disse que problemas de precisão de ponto flutuante podem fazer com que o jogo gere listas de navegação em loop. Eles sempre quiseram limitar o número máximo de nós que podiam andar, mas nunca chegaram a fazer isso.
Então o quebra-cabeça está resolvido? A instabilidade dos cálculos de ponto flutuante causa loops nas listas de navegação, o que faz com que o jogo os contorne infinitamente - é isso, o comportamento é explicado.
Mas ... tal explicação significaria que, quando isso acontecer, o processo do servidor entrará em um loop infinito, todos os jogadores terão que se desconectar dele e o processo do servidor consumirá indefinidamente todo o núcleo do processador. Se fosse esse o caso, não ficaríamos sem recursos em nossos servidores? Alguém não teria notado isso?
Procurei dados de monitoramento de servidor e encontrei algo assim:
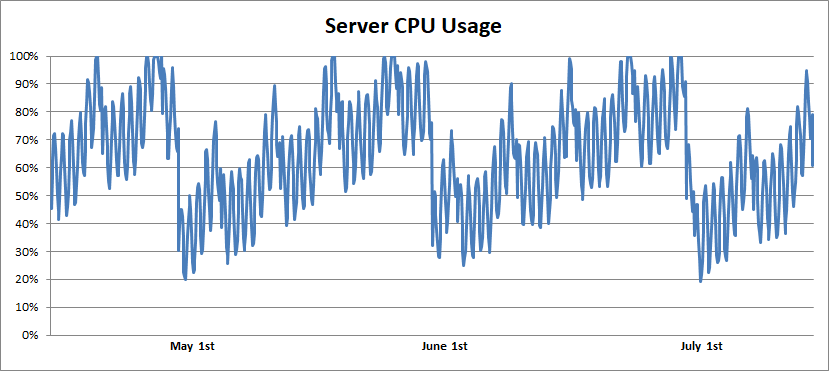
Durante toda a duração do monitoramento (um a dois anos), observei oscilações diárias e semanais na carga do servidor, às quais foi imposto um padrão mensal. O nível de utilização do processador aumentou gradualmente e depois caiu para zero. Depois de perguntar um pouco mais, descobri que os servidores eram reiniciados uma vez por mês. E, finalmente, a lógica apareceu em tudo isso:
- , .
- , , .
- CPU , 50%.
- .
O bug foi corrigido com a adição de algumas linhas de código que pararam de percorrer a lista após vinte nós de navegação, supostamente economizando vários milhões de dólares em custos de servidor e energia. Não encontrei esse bug olhando os gráficos de monitoramento, mas qualquer pessoa que os visse poderia fazer isso.
Adoro o fato de que a frequência do bug coincidiu perfeitamente com a maximização do custo dele; ao mesmo tempo, ele nunca causou problemas sérios o suficiente para serem encontrados. Isso é semelhante à ação de um vírus que evolui para fazer as pessoas espirrarem, não para matá-las.
Carregamento lento
A produtividade do desenvolvedor de software está intimamente relacionada à velocidade do ciclo de edição / compilação / link / depuração. Em outras palavras, depende de quanto tempo leva depois de fazer uma alteração no arquivo de origem para executar o novo binário com a alteração feita. Fiz um ótimo trabalho ao longo dos anos para reduzir os tempos de compilação / link, mas os tempos de carregamento também são importantes. Alguns jogos realizam uma grande quantidade de trabalho sempre que são iniciados. Estou impaciente e, portanto, frequentemente o primeiro a gastar horas ou dias fazendo o jogo carregar alguns segundos mais rápido.
Nesse caso, executei meu criador de perfil favorito e observei o gráfico de uso da CPU durante a fase de carregamento inicial do jogo. Um passo parecia o mais promissor: demorou cerca de dez segundos para inicializar alguns dados de iluminação. Eu esperava encontrar uma maneira de acelerar esses cálculos, economizando cinco segundos na fase de inicialização. Antes de mergulhar no estudo, consultei um especialista gráfico. Ele disse:
“Não usamos esses dados de iluminação no jogo. Basta remover este desafio. "
Oh ótimo. Foi fácil.
Gastando meia hora criando perfis e mudando uma linha, consegui reduzir pela metade o tempo de carregamento do menu principal e não foi preciso nenhum esforço extraordinário.
Partida prematura
Devido ao número arbitrário de argumentos na formatação, é
printfmuito fácil obter um erro de incompatibilidade de tipo. Na prática, os resultados podem variar muito:
- printf (“0x% 08lx”, p); // Imprime o ponteiro como int - truncar ou pior em 64 bits
- printf (“% d,% f”, f, i); // Alterar os lugares de float e int - pode exibir um disparate ou funcionar (!)
- printf (“% s% d”, i, s); // Alterar a ordem da string e do int - provavelmente levará a um travamento
O padrão diz que tais incompatibilidades de tipo são comportamento indefinido, e alguns compiladores geram código que falha deliberadamente com qualquer uma dessas incompatibilidades, mas o acima lista os resultados mais prováveis (nota: a questão de por que o segundo parágrafo freqüentemente produz os resultados desejados é boa Quebra-cabeça do conhecimento ABI ).
Esses erros são muito fáceis de cometer, portanto, todos os compiladores modernos têm a capacidade de avisar aos desenvolvedores que ocorreu uma incompatibilidade. Ambos gcc e clang têm anotações no estilo printf para funções e podem alertar sobre incompatibilidades (no entanto, infelizmente, as anotações não funcionam com funções no estilo wprintf). VC ++ tem anotações (infelizmente outras) que / analyse pode usar para avisar sobre incompatibilidades, mas se você não usar / analyse, ele só avisará sobre funções estilo CRT estilo printf / wprintf, não suas funções personalizadas ...
A empresa para a qual trabalhei anotou suas funções no estilo printf para que gcc / clang emitisse avisos, mas depois decidiu ignorar os avisos. Esta é uma decisão estranha, porque tais avisos são indicadores perfeitamente precisos de bugs - a relação sinal-ruído é infinita.
Decidi começar a limpar esses bugs com VC ++ e / analyse anotações para encontrar todos os bugs exatamente. Eu trabalhei na maioria dos bugs e fiz uma grande mudança esperando que o código fosse verificado antes de enviá-lo.

Houve uma queda de energia no data center naquele fim de semana e todos os nossos servidores caíram (provavelmente devido a erros na configuração de energia). O pessoal de emergência correu para reconstruir e consertar tudo antes que muito dinheiro fosse perdido.
O aspecto engraçado dos erros do printf é que eles se comportam mal 100% do tempo. Ou seja, se eles vão exibir dados incorretos ou causar o travamento do programa, isso acontecerá todas as vezes. Portanto, eles podem permanecer no programa apenas se estiverem no código de registro que nunca é lido ou no código de tratamento de erros que raramente é executado.
Descobriu-se que o evento "reinício simultâneo de todos os servidores" fazia com que o código se movesse por caminhos que normalmente não seriam executados. Os servidores iniciais começaram a procurar outros servidores, não conseguiram localizá-los e exibiram algo como esta mensagem:
fprintf (log, “Não é possível encontrar o servidor% s. Código de erro% d. \ n”, err, server_name);
Opa. Digite incompatibilidade para um número arbitrário de argumentos. E partida.
Os atendentes de emergência têm um problema adicional. Os servidores precisavam ser reinicializados, mas isso não podia ser feito antes que os despejos de memória fossem examinados, um bug fosse descoberto, os binários do servidor não fossem reconstruídos e uma nova construção fosse lançada. Foi um processo bastante rápido - ao que parece, não mais do que algumas horas, mas poderia muito bem ter sido evitado.
Achei que essa história demonstra perfeitamente por que devemos gastar tempo solucionando as causas desses avisos - por que ignorar os avisos que dizem que o código definitivamente travará ou se comportará mal quando executado? No entanto, ninguém se preocupou com o fato de que a eliminação dessa classe de avisos poderia nos poupar várias horas de inatividade. Na verdade, a cultura da empresa não parecia se importar com nenhuma dessas soluções. Mas foi esse último bug que me fez perceber que era hora de mudar para outra empresa.
Que lições podem ser aprendidas com isso?
Se todos os envolvidos estão trabalhando duro nos recursos do produto e corrigindo bugs conhecidos, provavelmente existem bugs muito simples que estão em exibição pública. Passe algum tempo estudando os logs, limpando os avisos do compilador (embora, na verdade, se você tiver avisos do compilador, provavelmente valha a pena repensar as decisões que você fez na vida), execute o criador de perfil por alguns minutos. Você ganha pontos extras se adicionar seu próprio sistema de registro, habilitar novos avisos ou usar um profiler que ninguém mais usa além de você.
Se você estiver fazendo correções excelentes que melhoram o uso ou a estabilidade da memória / CPU, e ninguém se importa com isso, encontre uma empresa que aprecie isso.
Discussão do Hacker News aqui , discussão do Reddit aqui , discussão do Twitter aqui .
Publicidade
Um servidor confiável para alugar e a escolha certa de um plano de tarifas permitirão que você se distraia menos com notificações de monitoramento desagradáveis - tudo funcionará perfeitamente e com um tempo de atividade muito alto!
