
Muitas pessoas pensam que basta portar o aplicativo para o Kubernetes (usando o Helm ou manualmente) e haverá felicidade. Mas não é tão simples.
A equipe Mail.ru Cloud Solutions traduziu um artigo do engenheiro de DevOps Julian Guindi. Ele fala sobre as armadilhas que sua empresa enfrentou no processo de migração para que você não pise no mesmo rake.
Etapa um: configurar solicitações e limites de pod
Vamos começar configurando um ambiente limpo no qual nossos pods serão executados. O Kubernetes é excelente para programar pods e lidar com estados de falha. Mas descobriu-se que o planejador às vezes não consegue colocar um pod se for difícil estimar quantos recursos ele precisa para funcionar com sucesso. É aqui que entram as solicitações e limites de recursos. Há muita controvérsia sobre a melhor abordagem para definir solicitações e limites. Às vezes parece que realmente é mais arte do que ciência. Aqui está nossa abordagem.
As solicitações de pod são o valor principal usado pelo programador para o posicionamento ideal de pod.
Kubernetes: , . , PodFitsResources , .
Usamos solicitações de aplicativos para que possamos usá-los para estimar quantos recursos o aplicativo realmente precisa para funcionar corretamente. Isso permitirá que o planejador posicione os nós de forma realista. Inicialmente, queríamos configurar as solicitações com uma margem para garantir que houvesse recursos suficientes para cada pod, mas percebemos que o tempo de programação aumentou significativamente e alguns pods nunca foram totalmente programados, como se não houvesse solicitações de recursos para eles.
Nesse caso, o agendador frequentemente "comprimia" pods e não seria capaz de reprogramar porque o plano de controle não tinha ideia de quantos recursos o aplicativo precisaria, que é um componente-chave do algoritmo de agendamento.
Limites de podÉ uma limitação mais clara para o pod. Ele representa a quantidade máxima de recursos que o cluster alocará para o contêiner.
Mais uma vez, a partir da documentação oficial : se um limite de memória de 4 GiB for definido para um contêiner, o kubelet (e o tempo de execução do contêiner) o forçará. O tempo de execução evita que o contêiner use mais do que o limite de recursos especificado. Por exemplo, quando um processo em um contêiner tenta usar mais do que a quantidade de memória permitida, o kernel sai do processo com um erro de "falta de memória" (OOM).
Um contêiner sempre pode usar mais recursos do que o especificado em uma solicitação de recurso, mas nunca pode usar mais do que o especificado em um limite. Este valor é difícil de definir corretamente, mas é muito importante.
Idealmente, queremos que os requisitos de recursos do pod mudem ao longo do ciclo de vida do processo sem interferir em outros processos no sistema - esse é o objetivo de estabelecer limites.
Infelizmente, não posso fornecer instruções específicas sobre quais valores definir, mas nós mesmos aderimos às seguintes regras:
- Usando uma ferramenta de teste de carga, simulamos o tráfego de linha de base e monitoramos o uso de recursos do pod (memória e processador).
- ( 5 ) . , , Go.
Observe que as restrições de recursos maiores tornam o agendamento mais difícil porque o pod precisa de um nó de destino com recursos disponíveis suficientes.
Imagine uma situação em que você tenha um servidor da web leve com uma restrição de recursos muito alta, como 4 GB de memória. Este processo provavelmente precisará ser escalado horizontalmente e cada novo módulo terá que ser agendado em um nó com pelo menos 4 GB de memória disponível. Se tal nó não existir, o cluster deve introduzir um novo nó para processar este pod, o que pode levar algum tempo. É importante manter a diferença entre as solicitações e limites de recursos o menor possível para garantir um escalonamento rápido e suave.
Etapa dois: configurar os testes de vitalidade e prontidão
Este é outro tópico sutil que é frequentemente discutido na comunidade Kubernetes. É importante ter um bom entendimento dos testes de Liveness e Readiness, pois eles fornecem um mecanismo para o software funcionar sem problemas e minimizar o tempo de inatividade. No entanto, eles podem afetar seriamente o desempenho do seu aplicativo se não forem configurados corretamente. Abaixo está um resumo de quais são as duas amostras.
Liveness mostra se o contêiner está em execução. Se falhar, o kubelet elimina o contêiner e uma política de reinicialização é habilitada para ele. Se o contêiner não estiver equipado com uma sondagem de vivacidade, o estado padrão será bem-sucedido - conforme declarado na documentação do Kubernetes .
As sondagens de vivacidade devem ser baratas, ou seja, não consumir muitos recursos, porque são executadas com frequência e devem informar ao Kubernetes que o aplicativo está em execução.
Configurá-lo para ser executado a cada segundo adicionará 1 solicitação por segundo, portanto, esteja ciente de que recursos adicionais serão necessários para lidar com esse tráfego.
Em nossa empresa, os testes de Liveness validam os principais componentes de um aplicativo, mesmo que os dados (por exemplo, de um banco de dados remoto ou cache) não estejam totalmente disponíveis.
Configuramos um endpoint de "integridade" em aplicativos que simplesmente retorna um código de resposta de 200. Esta é uma indicação de que um processo está ativo e em execução e é capaz de lidar com solicitações (mas ainda não com tráfego).
Teste de prontidãoindica se o contêiner está pronto para atender às solicitações. Se a investigação de prontidão falhar, o controlador de endpoint remove o endereço IP do pod dos endpoints de todos os serviços que correspondem ao pod. Isso também é declarado na documentação do Kubernetes.
As análises de prontidão consomem mais recursos, pois devem ir para o back-end de forma a indicar que o aplicativo está pronto para aceitar solicitações.
Há muita controvérsia na comunidade quanto a ir diretamente para o banco de dados. Dada a sobrecarga (as verificações são realizadas com frequência, mas podem ser ajustadas), decidimos que, para alguns aplicativos, a disponibilidade para servir o tráfego é contada apenas após verificar se os registros são retornados do banco de dados. Sondas de disponibilidade bem projetadas garantiram maior disponibilidade e eliminaram o tempo de inatividade durante a implantação.
Se você decidir consultar o banco de dados para verificar se seu aplicativo está pronto, certifique-se de que seja o mais barato possível. Vamos fazer uma consulta como esta:
SELECT small_item FROM table LIMIT 1Aqui está um exemplo de como configuramos esses dois valores no Kubernetes:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
Algumas opções de configuração adicionais podem ser adicionadas:
initialDelaySeconds- quantos segundos decorrerão entre o início do recipiente e o início do início das amostras.periodSeconds— .timeoutSeconds— , . -.failureThreshold— , .successThreshold— , ( , ).
:
O Kubernetes tem uma topografia de rede "plana"; por padrão, todos os pods interagem diretamente uns com os outros. Em alguns casos, isso é indesejável.
Um possível problema de segurança é que um invasor pode usar um único aplicativo vulnerável para enviar tráfego a todos os pods da rede. Como em muitas áreas de segurança, o princípio do menor privilégio se aplica. Idealmente, as políticas de rede devem declarar explicitamente quais conexões entre pods são permitidas e quais não são.
Por exemplo, a seguir está uma política simples que nega todo o tráfego de entrada para um namespace específico:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Visualização desta configuração:
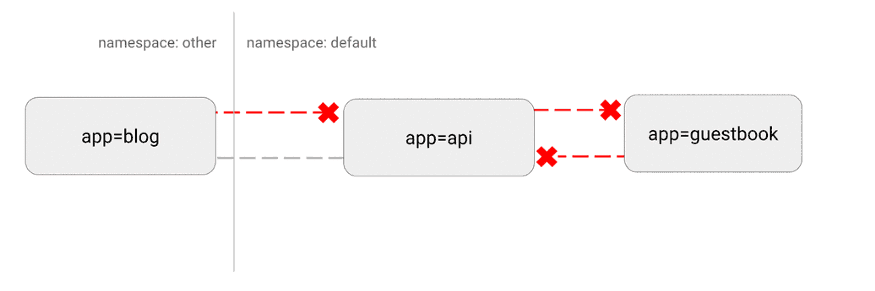
(https://miro.medium.com/max/875/1*-eiVw43azgzYzyN1th7cZg.gif)
Mais detalhes aqui .
Etapa quatro: comportamento personalizado com ganchos e containers init
Um dos nossos principais objetivos era fornecer implantações para o Kubernetes sem tempo de inatividade para os desenvolvedores. Isso é difícil porque há muitas opções para encerrar aplicativos e liberar recursos usados.
Dificuldades particulares surgiram com o Nginx . Percebemos que, quando esses pods foram implantados sequencialmente, as conexões ativas foram descartadas antes da conclusão bem-sucedida.
Após uma extensa pesquisa na Internet, descobriu-se que o Kubernetes não espera que as conexões do Nginx se esgotem antes de desligar o pod. Com a ajuda de um gancho de pré-parada, implementamos a seguinte funcionalidade e nos livramos completamente do tempo de inatividade:
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
E aqui
nginx-killer.sh:
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
Outro paradigma extremamente útil é o uso de containers init para lidar com o lançamento de aplicativos específicos. Isso é especialmente útil se você tiver um processo de migração de banco de dados com uso intensivo de recursos que precisa ser iniciado antes de executar o aplicativo. Você também pode especificar um limite de recursos mais alto para este processo sem definir esse limite para o aplicativo principal.
Outro esquema comum é acessar segredos no contêiner init, que fornece essas credenciais para o módulo principal, o que impede o acesso não autorizado a segredos do próprio módulo de aplicativo principal.
, : init- , . , .
:
Finalmente, vamos falar sobre uma técnica mais avançada.
O Kubernetes é uma plataforma extremamente flexível que permite executar cargas de trabalho da maneira que achar melhor. Temos vários aplicativos altamente eficientes e que consomem muitos recursos. Por meio de testes de carga extensivos, descobrimos que um dos aplicativos tem dificuldade em lidar com a carga de tráfego esperada quando os padrões do Kubernetes estão em vigor.
No entanto, o Kubernetes permite que você execute um contêiner privilegiado que altera os parâmetros do kernel apenas para um pod específico. Aqui está o que usamos para alterar o número máximo de conexões abertas:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
Esta é uma técnica mais avançada e frequentemente desnecessária. Mas se seu aplicativo está lutando para lidar com uma carga pesada, você pode tentar ajustar alguns desses parâmetros. Mais detalhes sobre este processo e configuração de vários valores - como sempre na documentação oficial .
Finalmente
Embora o Kubernetes possa parecer uma solução out-of-the-box, existem várias etapas importantes a serem seguidas para manter seus aplicativos funcionando sem problemas.
Em toda a sua migração para o Kubernetes, é importante seguir um "ciclo de teste de carga": execute o aplicativo, teste-o de carga, observe as métricas e o comportamento de dimensionamento, ajuste a configuração com base nesses dados e repita o ciclo novamente.
Faça uma estimativa realista do tráfego esperado e tente ir além para ver quais componentes quebram primeiro. Com essa abordagem iterativa, apenas algumas dessas recomendações podem ser suficientes para obter sucesso. Ou uma personalização mais aprofundada pode ser necessária.
Sempre pergunte a si mesmo estas perguntas:
- ?
- ? ? ?
- ? , ?
- ? ? ?
- ? - , ?
O Kubernetes oferece uma plataforma incrível que permite práticas recomendadas para implantar milhares de serviços em um cluster. No entanto, todos os aplicativos são diferentes. Às vezes, a implementação exige um pouco mais de trabalho.
Felizmente, o Kubernetes oferece a personalização necessária para atender a todos os objetivos técnicos. Usando uma combinação de solicitações e limites de recursos, probes de Liveness e Readiness, containers init, políticas de rede e ajuste de kernel personalizado, você pode obter alto desempenho junto com tolerância a falhas e escalabilidade rápida.
O que mais ler: