
Bancos de dados gráficos são uma tecnologia importante para profissionais de banco de dados. Tento acompanhar as inovações e novas tecnologias nessa área e, depois de trabalhar com bancos de dados relacionais e NoSQL, vejo que o papel dos bancos de dados gráficos está crescendo. Ao trabalhar com dados hierárquicos complexos, não apenas os bancos de dados tradicionais, mas também o NoSQL são ineficazes. Freqüentemente, com um aumento no número de níveis de links e no tamanho da base, o desempenho diminui. E à medida que os relacionamentos se tornam mais complexos, o número de JOINs também aumenta.
Claro, existem soluções no modelo relacional para trabalhar com hierarquias (por exemplo, usando CTEs recursivos), mas essas ainda são soluções alternativas. Ao mesmo tempo, a funcionalidade dos bancos de dados gráficos do SQL Server permite que você processe facilmente vários níveis da hierarquia. Tanto o modelo de dados quanto as consultas são simplificados e, portanto, mais eficientes. A quantidade de código é reduzida significativamente.
Os bancos de dados gráficos são uma linguagem expressiva para representar sistemas complexos. Essa tecnologia já é amplamente utilizada na indústria de TI em áreas como mídia social, sistemas antifraude, análise de rede de TI, recomendações sociais, recomendações de produtos e conteúdo.
A funcionalidade de banco de dados gráfico no SQL Server é adequada para cenários nos quais os dados estão fortemente acoplados e têm relacionamentos bem definidos.
Modelo de dados gráficos
Um gráfico é um conjunto de vértices (nós) e arestas (relacionamentos). Os vértices representam entidades e as arestas representam links, cujos atributos podem conter informações.
Um banco de dados de gráficos modela entidades na forma de um gráfico, conforme definido na teoria dos grafos. Estruturas de dados são vértices e arestas. Atributos são propriedades de vértices e arestas. Um link é uma conexão de vértices.
Ao contrário de outros modelos de dados, em bancos de dados gráficos, os relacionamentos entre entidades têm precedência. Portanto, não há necessidade de calcular relacionamentos usando chaves estrangeiras ou qualquer outro meio. Você pode criar modelos de dados complexos usando apenas abstrações de vértices e arestas.
No mundo moderno, modelar relacionamentos exige técnicas cada vez mais sofisticadas. Para modelar relacionamentos, o SQL Server 2017 oferece recursos de banco de dados gráfico. Os vértices e arestas do gráfico são representados como novos tipos de tabelas: NODE e EDGE. Uma nova função T-SQL chamada MATCH () é usada para consultar o gráfico. Como essa funcionalidade é integrada ao SQL Server 2017, ela pode ser usada em seus bancos de dados existentes sem a necessidade de qualquer conversão.
Benefícios do modelo gráfico
Hoje em dia, empresas e usuários estão exigindo aplicativos que manipulem cada vez mais dados, enquanto esperam alto desempenho e confiabilidade. A apresentação de dados na forma de um gráfico oferece uma ferramenta conveniente para lidar com relacionamentos complexos. Essa abordagem resolve muitos problemas e ajuda a obter resultados dentro de um determinado contexto.
Parece que, no futuro, muitos aplicativos se beneficiarão com o uso de bancos de dados de gráficos.
Modelagem de dados: do modelo relacional ao gráfico
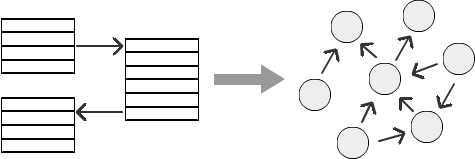
Exemplo
Vejamos um exemplo de estrutura organizacional com uma hierarquia de funcionários: um funcionário se reporta a um gerente, um gerente se reporta a um gerente sênior e assim por diante. Essa hierarquia pode ter qualquer número de níveis, dependendo de uma empresa específica. Mas à medida que o número de camadas aumenta, os relacionamentos de computação em um banco de dados relacional se tornam cada vez mais difíceis. É bastante difícil representar a hierarquia de funcionários, a hierarquia em marketing ou conexões de mídia social. Vamos ver como o SQL Graph pode resolver o problema de lidar com diferentes níveis da hierarquia.
Para este exemplo, vamos fazer um modelo de dados simples. Vamos criar uma tabela de funcionários EMP com um identificador EMPNO e uma coluna MGR, indicando o identificador do gerente (gerente) do funcionário. Todas as informações sobre a hierarquia são armazenadas nesta tabela e podem ser consultadas por meio das colunas EMPNO e MGR .
O diagrama a seguir mostra o mesmo modelo de organograma com quatro níveis de aninhamento em uma forma mais familiar. Funcionários são os vértices do gráfico da tabela EMP . A entidade "funcionário" está vinculada a si mesma pelo link "enviar" (ReportsTo). Em termos de gráfico, um link é uma borda (EDGE) que conecta os nós (NODE) dos funcionários.
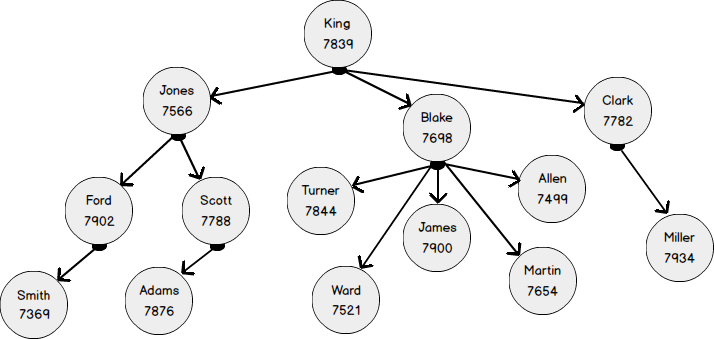
Vamos criar uma tabela EMP regular e adicionar os valores de acordo com o diagrama acima.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
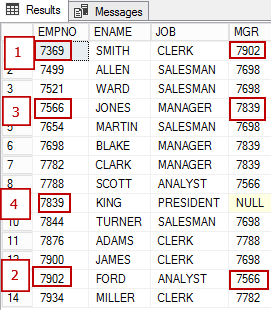
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)A figura abaixo mostra os funcionários:
- funcionário com EMPNO 7369 se reporta a 7902;
- funcionário com EMPNO 7902 obedece 7566
- funcionário com EMPNO 7566 obedece 7839
Agora, vamos ver uma representação gráfica dos mesmos dados. O nó EMPLOYEE possui vários atributos e está associado a si mesmo pelo relacionamento "obedecer" (EmplReportsTo). EmplReportsTo é o nome do relacionamento.
A mesa de borda (EDGE) também pode conter atributos.
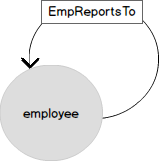
Criar a tabela de nó EmpNode
A sintaxe para criar um nó é bastante simples: a instrução CREATE TABLE é anexada com "AS NODE" no final .
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;Agora vamos transformar os dados de uma tabela regular em uma tabela gráfica. O próximo INSERT insere dados da tabela relacional EMP .
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp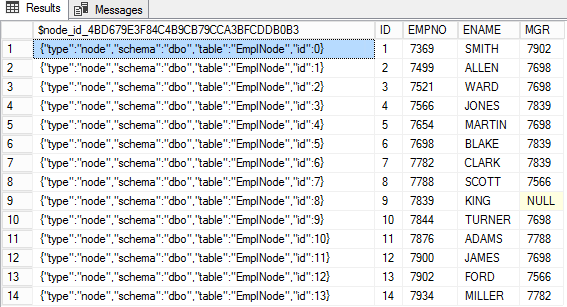
O
$node_id_*ID do nó é armazenado em uma coluna especial na tabela de nós na forma de JSON. As colunas restantes desta tabela contêm os atributos do nó.
Criar Bordas (EDGE)
Criar uma tabela de bordas é muito semelhante a criar uma tabela de nós, exceto que a palavra-chave "AS EDGE" é usada .
CREATE TABLE empReportsTo(Deptno int) AS EDGE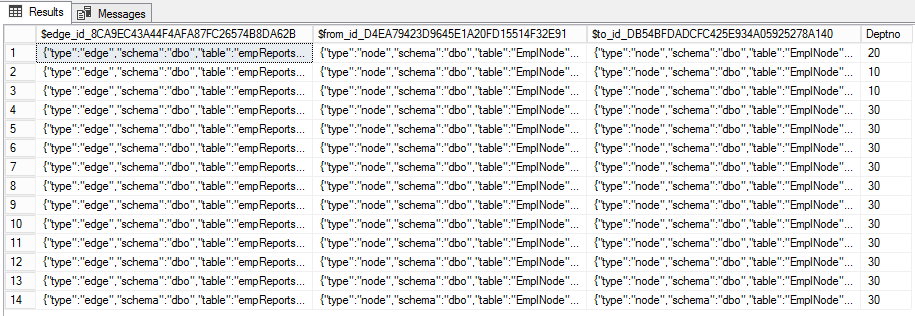
Agora vamos definir as relações entre os funcionários usando as colunas EMPNO e MGR . O organograma mostra como escrever INSERT .
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10)
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30);A tabela de borda padrão tem três colunas. O primeiro
$edge_idé o identificador JSON da borda. Os outros dois ( $from_ide $to_id) representam as comunicações entre os nós. Além disso, as costelas podem ter propriedades adicionais. No nosso caso, é o Deptno .
Visualizações do sistema
Existem
sys.tablesduas novas colunas na visualização do sistema :
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%'
SSMS
Objetos relacionados a gráficos estão localizados na pasta Tabelas de gráficos. O ícone da mesa de nó é marcado com um ponto, e o ícone da mesa de borda é marcado com dois círculos vinculados (que se parecem um pouco com óculos).

Expressão MATCH
A expressão MATCH é retirada do CQL (Cypher Query Language). Esta é uma maneira eficiente de consultar as propriedades do gráfico. CQL começa com uma expressão MATCH .
Sintaxe
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
<node_alias> ::=
node_table_name | node_alias
<edge_alias> ::=
edge_table_name | edge_aliasExemplos
Vamos dar uma olhada em alguns exemplos.
A consulta abaixo exibe os funcionários aos quais Smith e seu gerente se reportam.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH'
A próxima consulta é para encontrar funcionários e gerentes de segundo nível para Smith. Se você remover a cláusula WHERE , o resultado exibirá todos os funcionários.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.ENAME='SMITH'
E, finalmente, um pedido de funcionários e gerentes de terceiro nível.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.ENAME='SMITH'
Agora vamos mudar de direção para pegar os chefes Smith.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3)
Conclusão
O SQL Server 2017 se estabeleceu como uma solução corporativa completa para vários desafios de negócios de TI. A primeira versão do SQL Graph é muito promissora. Mesmo apesar de algumas limitações, já existe funcionalidade suficiente para explorar as capacidades dos gráficos.
A funcionalidade do SQL Graph é totalmente integrada ao SQL Engine. No entanto, conforme mencionado, o SQL Server 2017 tem as seguintes limitações:
Sem suporte para polimorfismo.
- .
- $from_id $to_id UPDATE.
- (transitive closure), CTE.
- In-Memory OLTP.
- (System-Versioned Temporal Table), .
- NODE EDGE.
- (cross-database queries).
- - (wizard) .
- GUI, Power BI.

: