
O que são métricas curtas e longas?
Os modelos de classificação procuram estimar a probabilidade de o usuário interagir com a notícia (postagem): ele vai prestar atenção, colocar a marca “Gostei”, escrever um comentário. O modelo então distribui os registros em ordem decrescente dessa probabilidade. Portanto, ao melhorar a classificação, podemos obter um aumento na CTR (taxa de cliques) das ações do usuário: curtidas, comentários e outros. Essas métricas são muito sensíveis a mudanças no modelo de classificação. Vou chamá-los de curtos .
Mas existe outro tipo de métrica. Acredita-se, por exemplo, que o tempo despendido no aplicativo, ou o número de sessões do usuário refletem muito melhor sua atitude em relação ao serviço. Chamaremos essas métricas de longa .
Otimizar métricas longas diretamente por meio de algoritmos de classificação não é uma tarefa trivial. Com métricas curtas, isso é muito mais fácil: o CTR de curtidas, por exemplo, está diretamente relacionado a quão bem estimamos sua probabilidade. Mas se conhecermos as relações causais (ou causais) entre as métricas curtas e longas, podemos nos concentrar na otimização apenas das métricas curtas que devem afetar previsivelmente as longas. Tentei extrair tais conexões causais - e escrevi sobre isso em meu trabalho, que concluí como um diploma no Bachelor of Science (CT) da ITMO. Conduzimos a pesquisa no laboratório de Aprendizado de Máquina da ITMO em conjunto com a VKontakte.
Links para código, conjunto de dados e sandbox
Você pode encontrar todo o código aqui: AnverK .
Para analisar as relações entre as métricas, usamos um conjunto de dados que inclui os resultados de mais de 6.000 testes A / B reais que a equipe VK conduziu em vários momentos. O conjunto de dados também está disponível no repositório .
Na sandbox, você pode ver como usar o wrapper proposto: em dados sintéticos .
E aqui - como aplicar algoritmos a um conjunto de dados: no conjunto de dados proposto .
Lidando com falsas correlações
Pode parecer que para resolver nosso problema, basta calcular as correlações entre as métricas. Mas isso não é inteiramente verdade: a correlação nem sempre é causa. Digamos que medimos apenas quatro métricas e suas relações causais são assim:

Sem perda de generalidade, vamos supor que haja uma influência positiva na direção da seta: quanto mais curtidas, mais SPU. Nesse caso, será possível estabelecer que os comentários na foto têm um efeito positivo no SPU. E decida que se você "aumentar" essa métrica, o SPU aumentará. Este fenômeno é chamado de correlação falsa.: O coeficiente de correlação é bastante alto, mas não há relação causal. Correlações falsas não se limitam a dois efeitos da mesma causa. Da mesma coluna, pode-se chegar à conclusão errada de que curtidas têm um efeito positivo no número de aberturas de fotos.
Mesmo com um exemplo tão simples, torna-se óbvio que uma análise simples de correlações levará a muitas conclusões erradas. A inferência causal (métodos de inferência de relacionamentos) permite restaurar relacionamentos causais a partir dos dados. Para aplicá-los na tarefa, escolhemos os algoritmos de inferência causal mais adequados, implementamos interfaces python para eles e também adicionamos modificações de algoritmos conhecidos que funcionam melhor em nossas condições.
Algoritmos clássicos para links de inferência
Consideramos vários métodos de inferência causal: PC (Peter e Clark), FCI (Fast Causal Inference) e FCI + (semelhante ao FCI do ponto de vista teórico, mas muito mais rápido). Você pode ler sobre eles em detalhes nestas fontes:
- Causalidade (J. Pearl, 2009),
- Causation, Prediction and Search (P. Spirtes et al., 2000),
- Aprender Modelos Causais Esparsos não é NP-difícil (T. Claassen et al., 2013).
Mas é importante entender que o primeiro método (PC) assume que observamos todas as quantidades que afetam duas ou mais métricas - essa hipótese é chamada de Suficiência Causal. Os outros dois algoritmos levam em consideração que pode haver fatores não observáveis que afetam as métricas monitoradas. Ou seja, no segundo caso, a representação causal é considerada mais natural e permite a presença de fatores não observáveis. : Todas as implementações desses algoritmos são apresentadas na bibliotecapcalg. É bonito e flexível, mas com uma "desvantagem" - é escrito em R (ao desenvolver as funções mais pesadas computacionalmente, o pacote RCPP é usado). Portanto, para os métodos acima, escrevi wrappers na classe CausalGraphBuilder, adicionando exemplos de seu uso. Descreverei os contratos da função de inferência de links, ou seja, a interface e o resultado que pode ser obtido na saída. Você pode passar por uma função de teste para independência condicional. Este é um teste como este que retorna

sob a hipótese nula de que os valores e condicionalmente independentes para um conjunto conhecido de quantidades . O padrão éum teste de correlação parcial. Escolhi a função com este teste porque é o padrão em pcalg e é implementado em RCPP - isso o torna mais rápido na prática. Você também pode transferir , a partir da qual os vértices serão considerados dependentes. Para algoritmos de PC e FCI, você também pode definir o número de núcleos de CPU, se não precisar gravar um log da operação da biblioteca. Não existe essa opção para FCI +, mas eu recomendo usar este algoritmo específico - ele ganha em velocidade. Outra ressalva: o FCI + atualmente não suporta o algoritmo de orientação de aresta proposto - o ponto está nas limitações da biblioteca pcalg. Com base nos resultados do trabalho de todos os algoritmos, um PAG (grafo ancestral parcial) é construído na forma de uma lista de arestas. Com o algoritmo PC, ele deve ser interpretado como um grafo causal no sentido clássico (ou rede Bayesiana): uma aresta orientada a partir de
em significa influência em . Se uma aresta for não direcionada ou bidirecional, não podemos orientá-la exclusivamente, o que significa:
- ou os dados disponíveis são insuficientes para estabelecer uma direção,
- ou é impossível, porque o verdadeiro gráfico causal, usando apenas dados observáveis, só pode ser estabelecido até uma classe de equivalência.
Os algoritmos FCI também resultarão em PAG, mas um novo tipo de arestas aparecerá nele - com um "o" no final. Isso significa que a flecha pode ou não estar lá. Nesse caso, a diferença mais importante entre os algoritmos FCI e o PC é que uma borda bidirecional (com duas setas) deixa claro que os vértices conectados por ela são consequências de algum vértice não observável. Conseqüentemente, uma borda dupla no algoritmo do PC agora se parece com uma borda com duas extremidades "o". Uma ilustração para esse caso está na caixa de areia com exemplos sintéticos.
Modificando o algoritmo de orientação de borda
Os métodos clássicos têm uma desvantagem significativa. Eles admitem que pode haver fatores desconhecidos, mas ao mesmo tempo contam com outra suposição excessivamente séria. Sua essência é que a função de teste de independência condicional deve ser perfeita. Caso contrário, o algoritmo não é responsável por si mesmo e não garante a correção ou a completude do gráfico (o fato de que mais arestas não podem ser orientadas sem violar a correção). Quantos testes de independência condicional de amostra finita ideal você conhece? Eu não.
Apesar dessa desvantagem, os esqueletos gráficos são construídos de maneira bastante convincente, mas são orientados de forma muito agressiva. Então, sugeri uma modificação no algoritmo de orientação de aresta. Bônus: permite ajustar implicitamente o número de arestas orientadas. Para explicar claramente sua essência, seria necessário falar em detalhes aqui sobre os algoritmos para a derivação de ligações causais. Portanto, vou anexar a teoria desse algoritmo e a modificação proposta separadamente - um link para o material estará no final do post.
Compare modelos - 1: Gráfico de estimativa de probabilidade
Curiosamente, uma das sérias dificuldades em derivar relações causais é a comparação e avaliação de modelos. Como isso aconteceu? A questão é que geralmente a verdadeira representação causal de dados reais é desconhecida. Além disso, não podemos conhecê-lo em termos de distribuição com tanta precisão a ponto de gerar dados reais a partir dele. Ou seja, a verdade básica é desconhecida para a maioria dos conjuntos de dados. Portanto, surge um dilema: use dados (semi-) sintéticos com a verdade básica conhecida ou tente fazer sem a verdade básica, mas teste em dados reais. Em meu trabalho, tentei implementar duas abordagens de teste.
O primeiro é a estimativa de probabilidade do gráfico:

Aqui - conjunto de pais do vértice , - informações conjuntas de quantidades e , e é a entropia da quantidade . Na verdade, o segundo termo não depende da estrutura do gráfico, portanto, via de regra, apenas o primeiro é considerado. Mas você pode ver que a probabilidade não diminui com a adição de novas arestas - isso deve ser levado em consideração na comparação. É importante entender que tal avaliação só funciona para comparar redes Bayesianas (saída do algoritmo de PC), porque em PAGs reais (saída de algoritmos FCI, FCI +), as arestas duplas têm semânticas completamente diferentes. Portanto, comparei a orientação das arestas com meu algoritmo e o PC clássico: A orientação modificada das arestas permitiu um aumento significativo na verossimilhança em comparação com o algoritmo clássico. Mas agora é importante comparar o número de arestas:
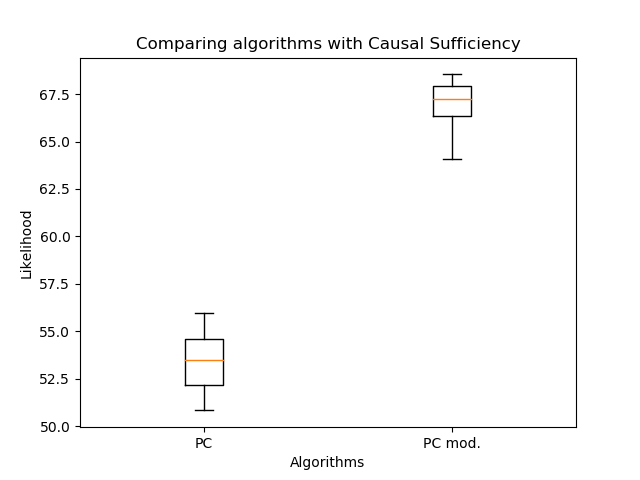
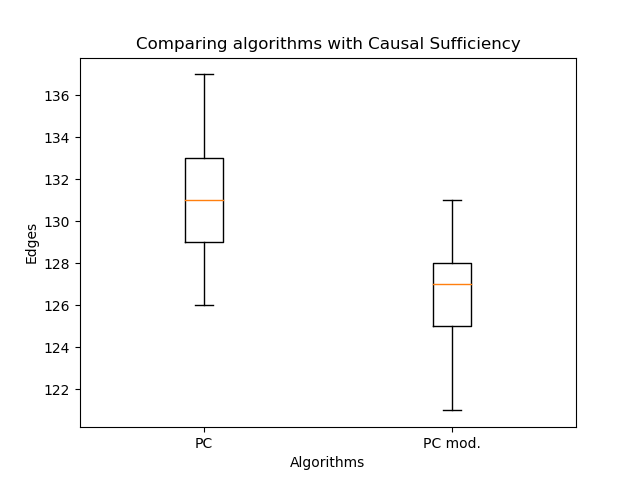
Há ainda menos deles - isso é esperado. Portanto, mesmo com menos arestas, é possível recuperar uma estrutura de gráfico mais plausível! Aqui você pode argumentar que a probabilidade não diminui com o número de arestas. A questão é que o gráfico resultante no caso geral não é um subgráfico do gráfico obtido pelo algoritmo de PC clássico. Arestas duplas podem aparecer em vez de arestas simples, e arestas simples podem mudar de direção. Portanto, sem limitações!
Comparando Modelos - 2: Usando uma Abordagem de Classificação
Vamos passar para a segunda forma de comparação. Usaremos o algoritmo PC para construir um gráfico causal e selecionar um gráfico acíclico aleatório a partir dele. Depois disso, iremos gerar os dados em cada vértice como uma combinação linear dos valores nos vértices pais com os coeficientes com ruído gaussiano adicionado. Aproveitei a ideia para essa geração do artigo "Rumo a uma descoberta causal robusta e versátil para aplicativos de negócios" (Borboudakis et al., 2016). Os vértices que não têm pais foram gerados a partir de uma distribuição normal - com parâmetros como no conjunto de dados para o vértice correspondente.
Quando os dados são recebidos, aplicamos os algoritmos que queremos avaliar a eles. Além disso, já temos um gráfico causal verdadeiro. Resta apenas entender como comparar os gráficos resultantes com o verdadeiro. Na reconstrução robusta de modelos gráficos causais baseados em informações condicionais de 2 e 3 pontos (Affeldt et al., 2015), o uso da terminologia de classificação foi proposto. Assumiremos que a aresta desenhada é uma classe Positiva e a não desenhada é Negativa. Então Verdadeiro Positivo ( ) é quando desenhamos a mesma aresta que no gráfico causal verdadeiro, e Falso Positivo ( ) - se uma aresta é desenhada, o que não está no gráfico causal verdadeiro. Avaliaremos esses valores do ponto de vista do esqueleto. Para levar em consideração as direções, apresentamos
para arestas que são exibidas corretamente, mas com a direção errada. Depois disso, vamos considerá-lo assim:
Então você pode ler medida tanto para o esqueleto quanto levando em consideração a orientação (obviamente, neste caso, não será maior do que para o esqueleto). No entanto, no caso do algoritmo de PC, uma borda dupla adiciona apenas , não , porque uma das arestas reais ainda é deduzida (sem Suficiência Causal, isso estaria errado). Finalmente, vamos comparar os algoritmos: Os primeiros dois gráficos são uma comparação dos esqueletos do algoritmo PC: o clássico e com a nova orientação da aresta. Eles são necessários para mostrar a borda superior

-medidas. Os dois segundos estão comparando esses algoritmos com relação à orientação. Como você pode ver, não há vitória.
Compare modelos - 3: desligue a suficiência causal
Agora vamos "fechar" algumas variáveis no gráfico verdadeiro e nos dados sintéticos após a geração. Isso desligará a suficiência causal. Mas será necessário comparar os resultados não com o gráfico verdadeiro, mas com o obtido da seguinte maneira:
- as arestas dos pais do vértice oculto serão desenhadas para seus filhos,
- conecte todos os filhos do vértice oculto com uma aresta dupla.
Já iremos comparar os algoritmos FCI + (com orientação de aresta modificada e com o clássico):

E agora, quando a Suficiência Causal não é atendida, o resultado da nova orientação fica muito melhor.
Outra observação importante apareceu - os algoritmos PC e FCI constroem esqueletos quase idênticos na prática. Portanto, comparei sua saída com a orientação das bordas, que propus em meu trabalho.
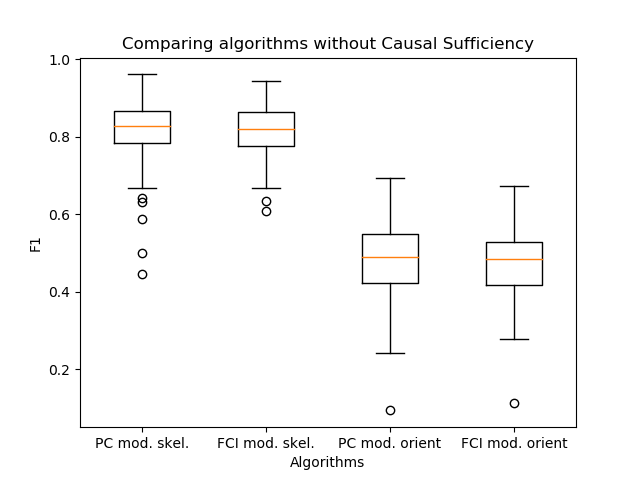
Descobriu-se que os algoritmos praticamente não diferem em qualidade. Nesse caso, o PC é uma etapa do algoritmo de construção do esqueleto dentro do FCI. Assim, usar o algoritmo PC de orientação, como no algoritmo FCI, é uma boa solução para aumentar a velocidade de inferência do enlace.
Resultado
Vou resumir brevemente o que falamos neste artigo:
- Como a tarefa de derivar ligações causais pode surgir em uma grande empresa de TI.
- O que são correlações espúrias e como elas podem interferir na seleção de recursos.
- Quais algoritmos para links de inferência existem e são usados com mais frequência.
- Que dificuldades podem surgir ao derivar gráficos causais?
- Qual é a comparação de gráficos causais e como lidar com isso.
Se você estiver interessado no tópico de inferência causal, verifique meu outro artigo - ele tem mais teoria. Lá escrevo em detalhes sobre os termos básicos que são usados na inferência de links, bem como como funcionam os algoritmos clássicos e a orientação das arestas por mim proposta.