Limites e estrangulamento da CPU
Como muitos outros usuários do Kubernetes, o Google recomenda ajustar os limites da CPU . Sem essa configuração, os contêineres no nó podem consumir toda a energia do processador, o que, por sua vez, fará com que processos importantes do Kubernetes (por exemplo
kubelet) parem de responder às solicitações. Portanto, definir limites de CPU é uma boa maneira de proteger seus nós.
Os limites do processador definem o tempo máximo do processador que pode ser usado por um período específico (100 ms por padrão), e o contêiner nunca excederá esse limite. O Kubernetes usa uma ferramenta especial CFS Quota para controlar o contêiner e evitar que ele exceda o limite., no entanto, no final, esse processador artificial limita o desempenho inferior e aumenta o tempo de resposta de seus contêineres.
O que pode acontecer se não definirmos os limites da CPU?
Infelizmente, nós mesmos tivemos que lidar com esse problema. Cada nó tem um processo responsável pelo gerenciamento de contêineres
kubelete parou de responder às solicitações. O nó, quando isso acontecer, entrará no estado NotReady, e os containers dele serão redirecionados para outro lugar e criarão os mesmos problemas já nos novos nós. Não é um cenário ideal, para dizer o mínimo.
Manifestando problemas de aceleração e capacidade de resposta
A principal métrica para rastrear contêineres é
trottlingquantas vezes seu contêiner foi estrangulado. Notamos com interesse a presença de afogamento em alguns containers, independentemente de a carga no processador ser máxima ou não. Por exemplo, vamos dar uma olhada em uma de nossas principais APIs:
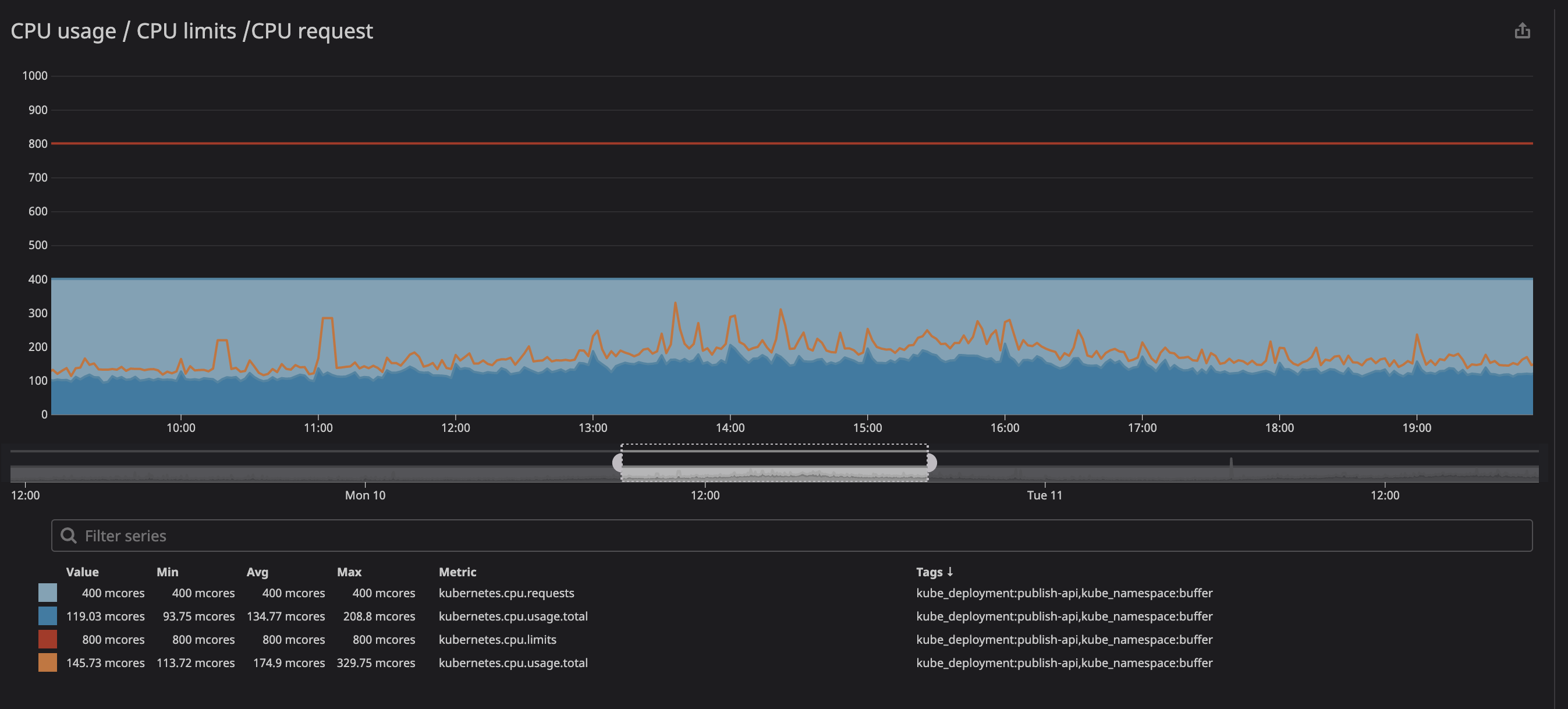
Como você pode ver abaixo, definimos o limite em
800m(0,8 ou 80% do núcleo), e os valores de pico são os melhores 200m(20% do núcleo). Parece que ainda temos muito poder de processamento antes de limitar o serviço, no entanto ...
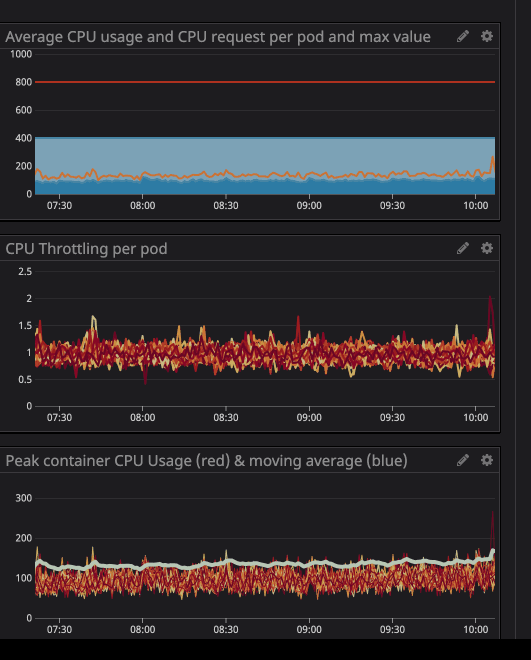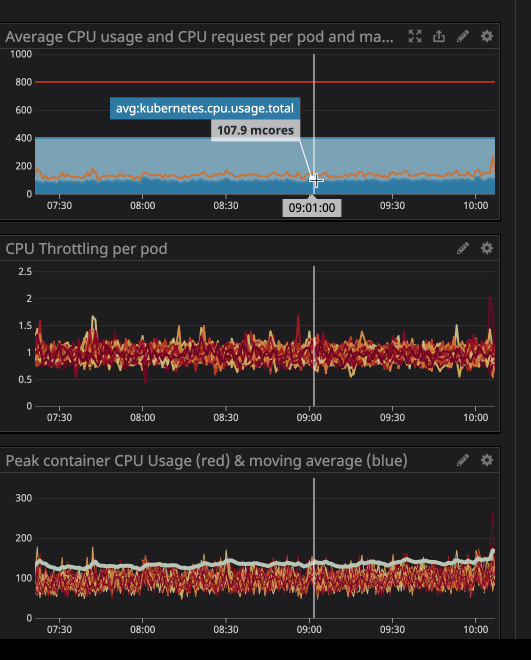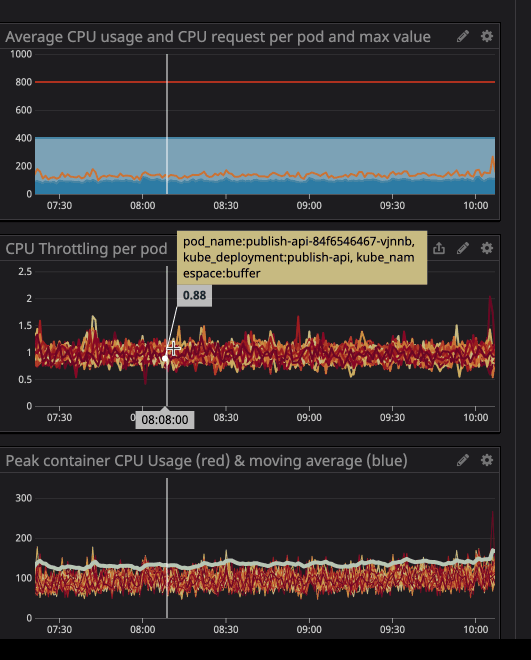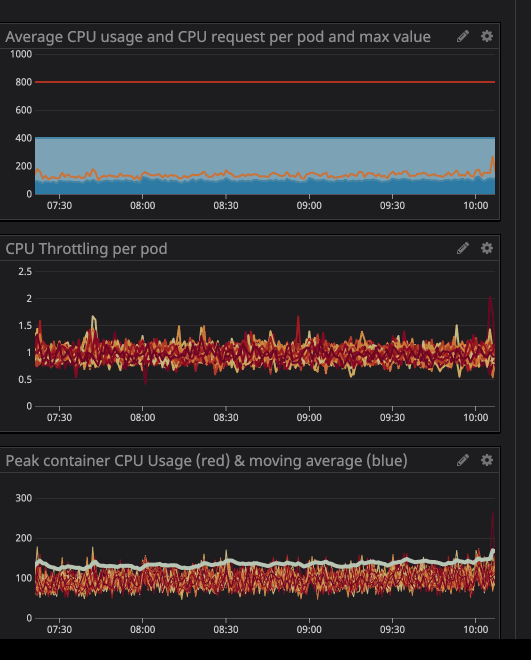
Você deve ter notado que, mesmo quando a carga no processador está abaixo dos limites especificados - muito mais baixo - o afogamento ainda funciona.
Diante disso, logo descobrimos vários recursos (um problema no github , uma apresentação no zadano , um post no omio ) sobre a queda no desempenho e no tempo de resposta dos serviços devido ao throttling.
Por que vemos aceleração sob baixo uso da CPU? A versão resumida diz assim: "Há um bug no kernel do Linux que dispara o controle desnecessário de contêineres com limites de processador especificados." Se você estiver interessado na natureza do problema, você pode ler a apresentação ( vídeo e texto variantes) por Dave Chiluk.
Removendo os limites do processador (com extremo cuidado)
Após longas discussões, decidimos remover as restrições do processador de todos os serviços que afetam direta ou indiretamente a funcionalidade crítica para nossos usuários.
A decisão acabou sendo difícil, pois valorizamos muito a estabilidade do nosso cluster. No passado, já experimentamos a instabilidade de nosso cluster e, em seguida, os serviços consumiram muitos recursos e retardaram o trabalho de todo o nosso nó. Agora tudo ficou um pouco diferente: tínhamos um entendimento claro do que esperávamos dos nossos clusters, bem como uma boa estratégia para implementar as mudanças planejadas.

Correspondência comercial sobre um assunto urgente.
Como proteger seus nós ao remover restrições?
Isolar serviços "ilimitados":
no passado, vimos alguns nós entrarem em um estado
notReady, principalmente devido a serviços que consumiam muitos recursos.
Decidimos colocar esses serviços em nós separados ("marcados") para que não interferissem nos serviços "vinculados". Como resultado, marcando alguns dos nós e adicionando um parâmetro de tolerância aos serviços “não relacionados”, ganhamos mais controle sobre o cluster e ficou mais fácil para nós identificar problemas com os nós. Para realizar processos semelhantes por conta própria, familiarize-se com a documentação .
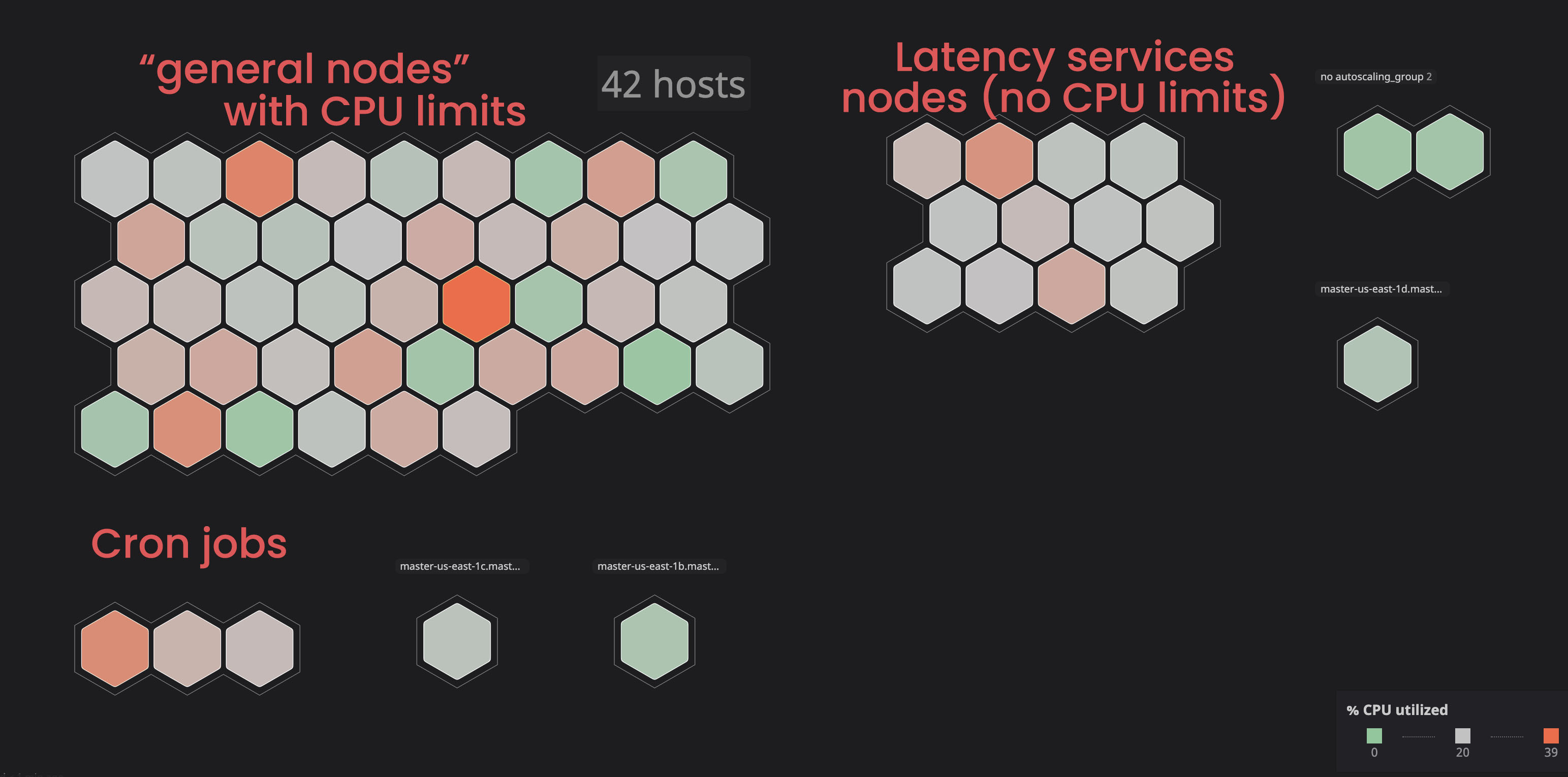
Atribuição do processador correto e solicitação de memória:
Acima de tudo, temíamos que o processo consumisse muitos recursos e o nó parasse de responder às solicitações. Desde agora (graças ao Datadog) pudemos observar claramente todos os serviços em nosso cluster, analisei vários meses de operação daqueles que planejamos designar como "não relacionados". Eu simplesmente defino a utilização máxima da CPU com uma margem de 20% e, portanto, aloco espaço no nó, caso o k8s tente atribuir outros serviços ao nó.
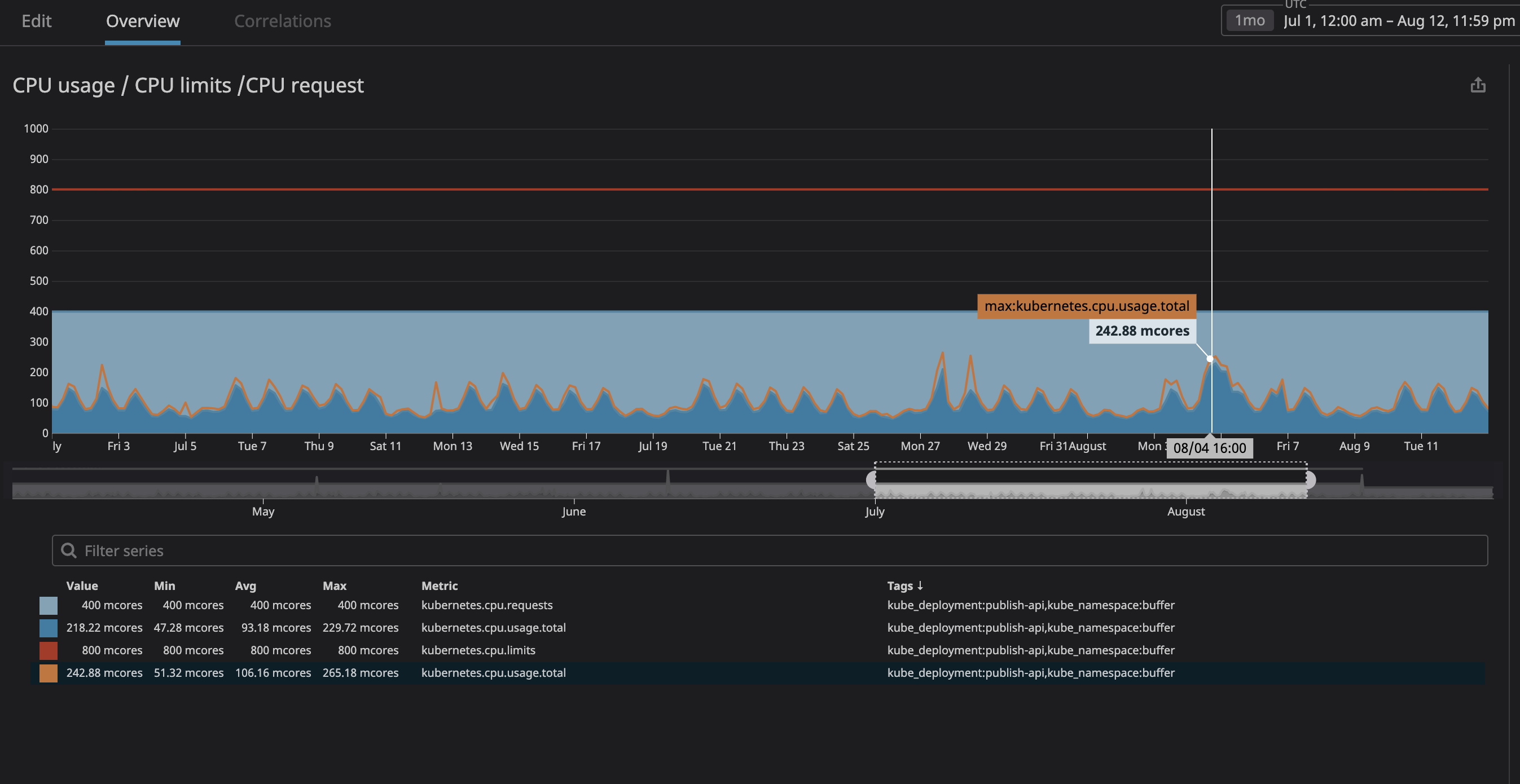
Como você pode ver no gráfico, a carga máxima do processador atingiu
242mos núcleos da CPU (0,242 núcleos do processador). Para uma solicitação do processador, é suficiente obter um número um pouco maior do que esse valor. Observe que, como os serviços são centrados no usuário, os picos de carga coincidem com o tráfego.
Faça o mesmo com o uso de memória e consultas, e pronto - está tudo pronto! Para maior segurança, você pode adicionar escalonamento automático horizontal de pods. Portanto, sempre que a carga nos recursos for alta, o escalonamento automático criará novos pods e o kubernetes os distribuirá para nós com espaço livre. Caso não haja espaço no próprio cluster, você pode definir um alerta ou configurar a adição de novos nós por meio de seu escalonamento automático.
Dos pontos negativos, é importante notar que perdemos na " densidade de contêineres ", ou seja, o número de contêineres trabalhando em um nó. Também podemos ter muitas "indulgências" com baixa densidade de tráfego e também há uma chance de que você alcance uma alta carga de processador, mas o escalonamento automático do nó deve ajudar com o último.
resultados
Tenho o prazer de publicar estes excelentes resultados de experiências nas últimas semanas, já notamos melhorias significativas na resposta entre todos os serviços modificados:
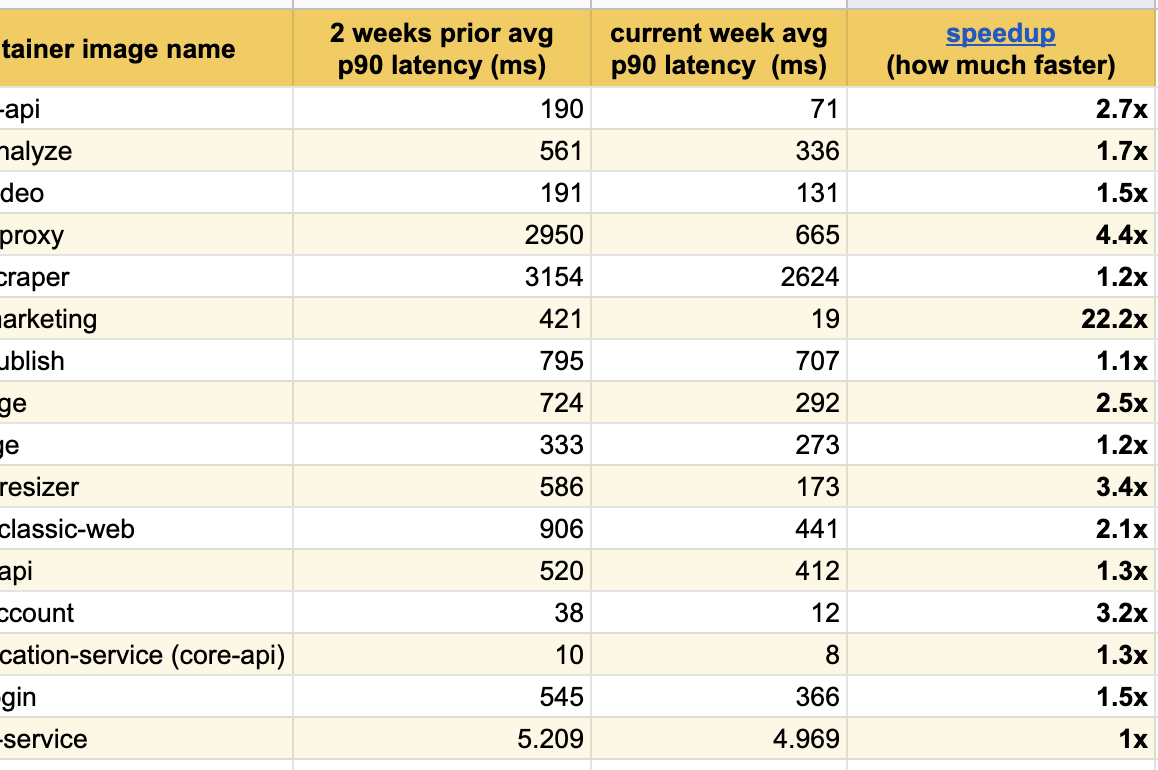
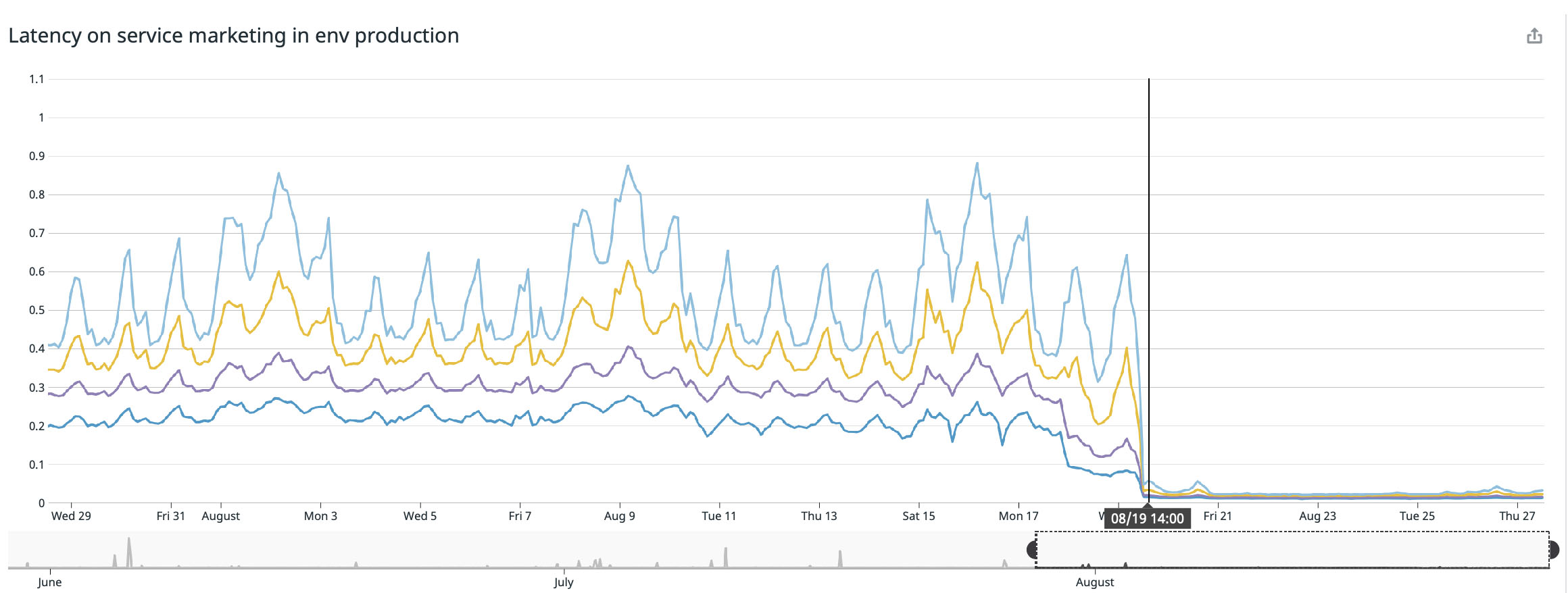
Alcançamos o melhor resultado na nossa página principal ( buffer.com ), aí o serviço foi vinte e duas vezes mais rápido !
O bug do kernel do Linux foi corrigido?
Sim, o bug já foi corrigido e a correção foi adicionada ao kernel das distribuições da versão 4.19 e superior.
No entanto, ao ler o problema do kubernetes no github em 2 de setembro de 2020, ainda encontramos menções de alguns projetos Linux com um bug semelhante. Eu acredito que algumas distribuições Linux ainda têm esse bug e estão trabalhando em uma correção.
Se sua versão da distribuição for inferior a 4.19, eu recomendaria atualizar para a mais recente, mas você deve tentar remover os limites do processador de qualquer maneira e ver se o afogamento persiste. Abaixo, você encontra uma lista incompleta de serviços de gerenciamento do Kubernetes e distribuições do Linux:
- Debian: , buster, ( 2020 ). .
- Ubuntu: Ubuntu Focal Fossa 20.04
- EKS 2019 . , AMI.
- kops: 2020
kops 1.18+Ubuntu 20.04. kops , , , . . - GKE (Google Cloud): 2020 , .
E se a correção corrigisse o problema de limitação?
Não tenho certeza se o problema foi completamente resolvido. Quando chegarmos à versão corrigida do kernel, testarei o cluster e atualizarei a postagem. Se alguém já atualizou, gostaria de revisar seus resultados com interesse.
Conclusão
- Se você trabalha com contêineres Docker no Linux (não importa Kubernetes, Mesos, Swarm ou qualquer outro), seus contêineres podem perder desempenho devido à limitação;
- Tente atualizar para a versão mais recente de sua distribuição na esperança de que o bug já tenha sido corrigido;
- Remover os limites do processador resolverá o problema, mas esta é uma técnica perigosa que deve ser usada com extremo cuidado (é melhor atualizar o kernel primeiro e comparar os resultados);
- Se você removeu os limites do processador, monitore cuidadosamente o uso do processador e da memória e certifique-se de que os recursos do processador excedam o consumo;
- Uma opção segura seria escalonar automaticamente os pods para criar novos pods em caso de alta carga de hardware para que os kubernetes os atribuam a nós livres.
Espero que esta postagem ajude você a melhorar o desempenho de seus sistemas de contêiner.
PS Aqui, o autor está em correspondência com leitores e comentaristas (em inglês).