Minha equipe e eu representamos a direção de desenvolvimento de negócios com os parceiros da Rosbank. Hoje gostaríamos de falar sobre a experiência de sucesso na automação de um processo de negócio bancário por meio de integrações diretas entre sistemas, inteligência artificial em termos de reconhecimento de imagem e texto com base em GreenOCR, legislação RF e preparação de amostras para treinamento.

Então, vamos começar. Rosbank tem um processo de negócios para abrir uma conta para um mutuário representado por um banco parceiro. O processo existente, seguindo todos os requisitos regulamentares e os requisitos do Grupo Societe Generale, antes da automação demorava até 20 minutos de tempo operacional por cliente. O processo inclui a recepção de digitalizações de documentos pelo back office, a verificação da correcção do preenchimento de cada documento e o lançamento dos campos do documento nos sistemas de informação do banco, vários outros cheques e apenas no final - abertura de conta. Este é exatamente o processo por trás do botão "Abrir uma conta".
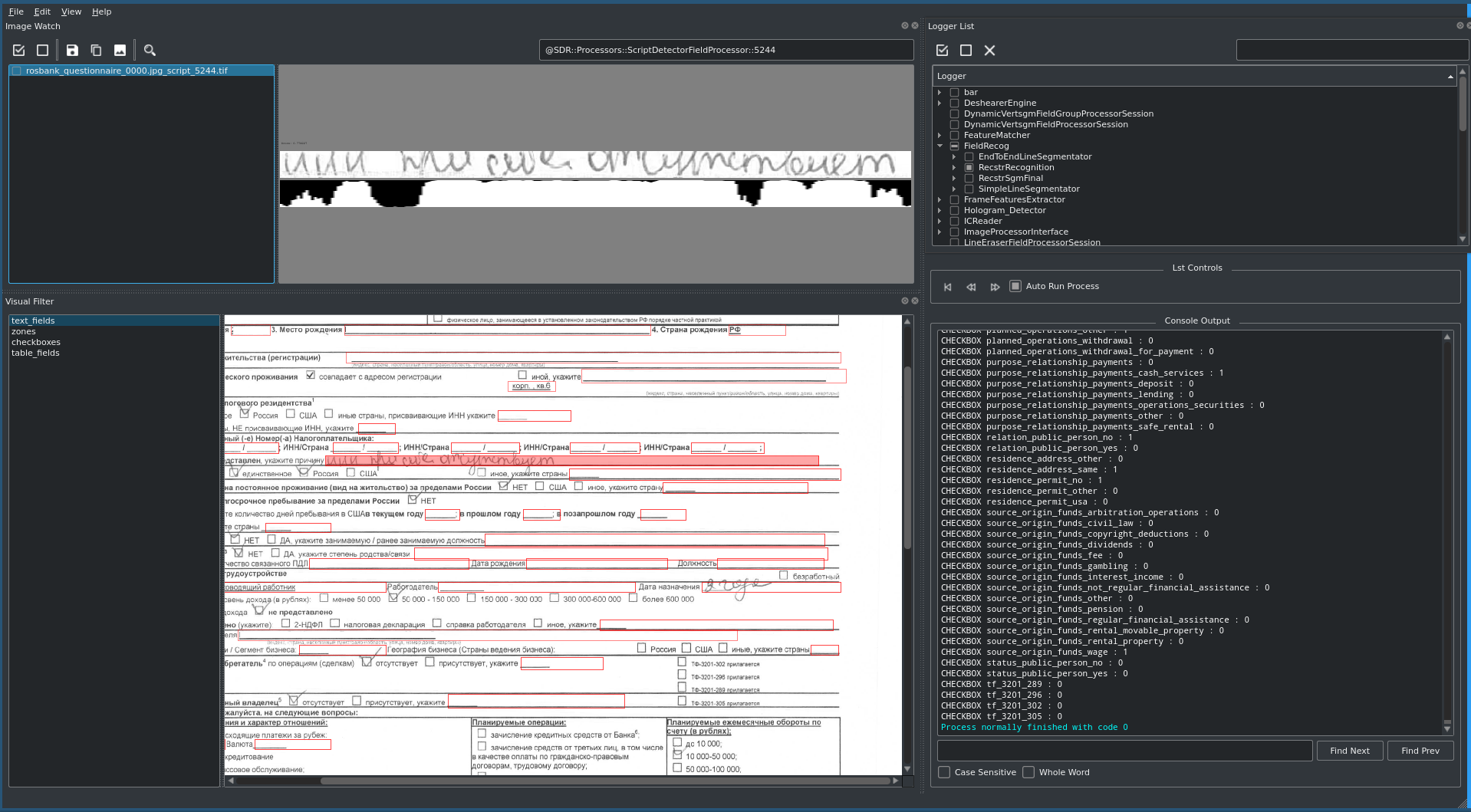
Os principais campos do documento - sobrenome, nome, patronímico, data de nascimento do cliente, etc. - estão contidos em praticamente todos os tipos de documentos recebidos e são duplicados quando inseridos nos diversos sistemas do Banco. O documento mais complexo - o questionário KYC (da Know Your Customer - conheça seu cliente) - é um formato A4 imprimível preenchido com fonte de 8 pontos e contém cerca de 170 campos de texto e caixas de seleção, bem como visualizações tabulares.
O que deveríamos fazer?
Nosso principal objetivo era reduzir ao mínimo o tempo de abertura de uma conta.
A análise do processo mostrou que é necessário:
- Reduzir o número de verificações manuais de cada documento;
- Automatize o preenchimento dos mesmos campos em diferentes sistemas bancários;
- Reduz a movimentação de digitalizações de documentos entre sistemas;
Para resolver os problemas (1) e (2), optou-se por usar a solução de reconhecimento de imagem e texto baseada em GreenOCR já implementada no banco (o nome de trabalho é "reconhecedor"). Os formatos de documentos utilizados no processo de negócio não são padronizados, por isso a equipe se deparou com a tarefa de desenvolver requisitos para o "reconhecedor" e preparar exemplos para treinamento da rede neural (amostras).
Para resolver os problemas (2) e (3), foi necessário refinar os sistemas e a integração intersistêmica.
Nossa equipe liderada por Julia Aleksashina
- Alexander Bashkov - desenvolvimento de sistemas internos (.Net)
- Valentina Sayfullina - análise de negócios, testes
- Grigory Proskurin - integração entre sistemas (.Net)
- Ekaterina Panteleeva - análise de negócios, testes
- Sergey Frolov - Gerenciamento de projetos, análise de qualidade de modelo
- Participantes de um fornecedor externo ( Smart Engines em conjunto com Philosophy.it )
Treinamento de reconhecimento
O conjunto de documentos do cliente usado no processo de negócios inclui:
- Passaporte;
- Consentimento - formulário impresso A4, 1 litro;
- Procuração - formulário impresso A4, 2 l;
- Questionário KYC - impresso A4, 1 litro;
Para começar, os documentos foram exaustivamente estudados e foram desenvolvidos requisitos, que incluíam não só o trabalho do reconhecedor com campos dinâmicos, mas também trabalho com texto estático, campos com dados manuscritos, em geral, reconhecimento de documentos ao longo do perímetro e outras melhorias.
O reconhecimento de passaporte foi incluído na funcionalidade de caixa do sistema GreenOCR e não exigiu modificações.
Para os demais tipos de documentos, como resultado da análise, foram determinados os atributos e sinais necessários que o "reconhecedor" deveria retornar. Ao mesmo tempo, os seguintes pontos tiveram que ser levados em consideração, o que complicou o processo de reconhecimento e exigiu uma complicação notável dos algoritmos usados:
- , . , «» ;
- 8- . , ;
- ( ) ;
- ;
- , , ;
- ;
Inicialmente, a tarefa nos parecia não muito complicada e parecia bastante normal:
Requisitos -> Fornecedor -> Modelo -> Testando o modelo -> Iniciando o processo
Em caso de testes malsucedidos, o modelo é devolvido ao fornecedor para reciclagem.
Todos os dias recebemos um grande número de digitalizações de documentos, e preparar uma amostra para treinar o modelo não deveria ser um problema. Todo o processamento de dados pessoais deve cumprir os requisitos da Lei Federal "Sobre Dados Pessoais" N152-FZ. O consentimento dos clientes para o processamento de dados pessoais de clientes está disponível apenas no Rosbank. Não podemos transferir os documentos do cliente para o fornecedor para treinamento do modelo.
Três maneiras de resolver o problema foram consideradas:
- , , , , ;
- . , – () , ;
- () . , , , , , ;
Tendo analisado as opções propostas com a equipe, quanto à rapidez de sua implementação e possíveis riscos, optamos pela terceira opção - a forma de imitar documentos para treinar o modelo. A principal vantagem deste processo é a capacidade de cobrir a mais ampla gama possível de dispositivos de digitalização para reduzir o número de iterações para calibração e refinamento do modelo.
Os modelos de documentos foram implementados em formato html. Uma matriz de dados de teste e uma macro foram preparadas de forma rápida e eficiente, preenchendo modelos com dados sintetizados e automatizando a impressão. A seguir, geramos formulários imprimíveis em formato pdf e atribuímos um identificador único a cada arquivo para verificar as respostas recebidas do "decodificador".
O treinamento da rede neural, a marcação das regiões e a configuração dos formulários ocorreram por parte do vendedor.
Devido ao tempo limitado, o treinamento do modelo foi dividido em 2 etapas.
Na primeira fase, o modelo foi treinado para reconhecer tipos de documentos e reconhecimento "aproximado" do conteúdo dos próprios documentos:
Requisitos -> Fornecedor -> Preparação de dados de teste -> Coleta de dados -> Treinamento do modelo no reconhecimento de formulário -> Formulários de teste -> Configurando o modelo
Na segunda etapa houve um treinamento detalhado do modelo para reconhecer o conteúdo de cada tipo de documento. O treinamento e a implementação do modelo na segunda etapa podem ser descritos pelo seguinte esquema, que é o mesmo para todos os tipos de documentos:
Preparando dados de teste em diferentes resoluções -> Coletando e transmitindo dados para o fornecedor -> Treinando o modelo -> Testando o modelo -> Calibrando o modelo -> Implementando o modelo -> Verificando os resultados na batalha -> Identificando casos de problemas -> Simulando casos de problemas e transferindo para o fornecedor -> Repetição de etapas de teste
Deve-se notar que, apesar da ampla cobertura da gama de scanners usados, uma série de dispositivos ainda não foram apresentados nos exemplos para treinamento do modelo. Portanto, a introdução do modelo na batalha ocorreu em modo piloto e os resultados não foram usados para automação. Os dados obtidos durante o trabalho no modo piloto foram apenas registrados no banco de dados para posterior análise e análise.
Testando
Como o loop de treinamento do modelo era do fornecedor e não estava conectado aos sistemas do banco, após cada ciclo de treinamento o modelo era transferido pelo fornecedor para o banco, onde era testado em ambiente de teste. Em caso de verificação bem-sucedida, o modelo era transferido para o ambiente de certificação, onde era feito o teste de regressão, e depois para o ambiente industrial, a fim de identificar casos especiais que não foram levados em consideração no treinamento do modelo.
No perímetro do banco, os dados eram submetidos ao modelo, os resultados eram registrados no banco de dados. A análise da qualidade dos dados foi realizada usando o todo-poderoso Excel - usando tabelas dinâmicas, lógica com fórmulas e suas combinações vlookup, hlookup, index, len, match e comparação de string caractere por caractere por meio da função if.
Testar usando documentos simulados nos permitiu executar o máximo de cenários de teste e automatizar o processo tanto quanto possível.
Primeiramente, no modo manual, verificamos o retorno de todos os campos quanto ao atendimento aos requisitos originais de cada tipo de documento. Em seguida, verificamos as respostas do modelo ao preencher dinamicamente blocos de texto de comprimentos diferentes. O objetivo era testar a qualidade das respostas quando o texto passa de linha em linha e de página em página. Ao final, verificamos a qualidade das respostas nos campos em função da qualidade do documento digitalizado. Para a calibração de qualidade mais alta do modelo, digitalizações de documentos de baixa resolução foram usadas.
Uma atenção especial deve ter sido dada ao documento mais complexo contendo o maior número de campos e caixas de seleção - o questionário KYC. Para ele, roteiros especiais para preenchimento do documento foram preparados com antecedência e macros automatizadas foram escritas, o que possibilitou agilizar o processo de testes, verificar todas as combinações de dados possíveis e dar prontamente feedback ao fornecedor para calibrar o modelo.
Integração e desenvolvimento interno
As revisões necessárias dos sistemas do banco e integração intersistêmica foram realizadas previamente e expostas nos ambientes de teste do banco.
O cenário realizado consiste nas seguintes etapas:
- Aceitação de digitalização de documentos recebidos;
- Enviando digitalizações recebidas para o "reconhecedor". O envio é possível no modo síncrono e assíncrono com até 10 threads;
- Receber uma resposta do “reconhecedor”, verificando e validando os dados recebidos;
- Salvar a digitalização original do documento na biblioteca eletrônica do banco;
- Iniciação nos sistemas do banco de processamento dos dados recebidos do “reconhecedor” e posterior verificação pelo funcionário;
Resultado
No momento, o treinamento do modelo foi concluído, os testes e a implementação do processo de negócio no ambiente de produção do banco foram realizados com sucesso. A automação realizada permitiu reduzir o tempo médio de abertura de conta de 20 minutos para 5 minutos. Uma fase de trabalho intensivo do processo empresarial para reconhecer e inserir dados de documentos, que antes era realizada manualmente, foi automatizada. Ao mesmo tempo, a probabilidade de erros causados pelo fator humano é drasticamente reduzida. Além disso, é garantida a identidade dos dados retirados de um mesmo documento em diferentes sistemas do banco.