Aprendizado de máquina. Redes neurais (parte 1): O processo de aprendizagem do perceptron
Neste artigo, usaremos uma rede neural para modelar a execução de operações lógicas OR; XOR, que é uma espécie de aplicativo "Hello World" para redes neurais.
Este artigo descreverá passo a passo o processo de modelagem usando TensorFlow.js.
Portanto, vamos construir uma rede neural para a operação lógica OR. Na entrada, sempre enviaremos dois sinais X 1 e X 2 e, na saída, receberemos um sinal de saída Y. Para treinar a rede neural, também precisamos de um conjunto de dados de treinamento (Figura 1).

Figura 1 - Um conjunto de dados de treinamento e um modelo para modelar uma operação lógica OR
Para entender qual estrutura de uma rede neural definir, vamos imaginar um conjunto de dados de treinamento em um plano de coordenadas com os eixos X 1 e X 2 (Figura 2, à esquerda).
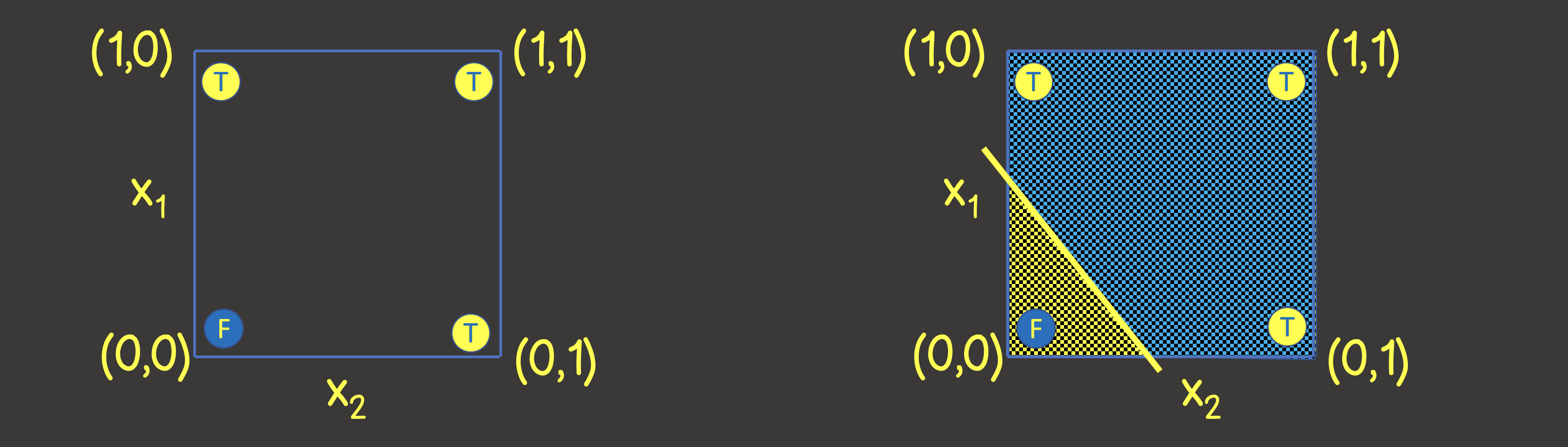
Figura 2 - Treinamento definido no plano de coordenadas para operação lógica OR
Observe que para resolver este problema, basta traçarmos uma linha que dividisse o plano de forma que de um lado da linha estivessem todos os valores VERDADEIROS , e do outro - todos os valores FALSOS (Figura 2, à direita). Também sabemos que um neurônio em uma rede neural (perceptron) pode perfeitamente lidar com esse propósito, o valor de saída do qual é calculado a partir dos sinais de entrada como:
que é uma representação matemática da equação de uma linha reta.
Visto que nossos valores estão na faixa de 0 a 1, então também aplicamos a função de ativação sigmóide. Assim, nossa rede neural se parece com a Figura 3.

Figura 3 - Rede neural para treinar a operação lógica de OR
Então, vamos resolver esse problema usando TensorFlow.js.
Primeiro, precisamos converter o conjunto de dados de treinamento em tensores. Um tensor é um contêiner de dados que pode tereixos e um número arbitrário de elementos ao longo de cada um dos eixos. A maioria com tensores está familiarizada com matemática - vetores (tensor com um eixo), matrizes (tensor com dois eixos - linhas, colunas).
Para definir o conjunto de dados de treinamento, o primeiro eixo (eixo 0) é sempre o eixo ao longo do qual todas as instâncias de amostra de dados disponíveis estão localizadas (Figura 4).
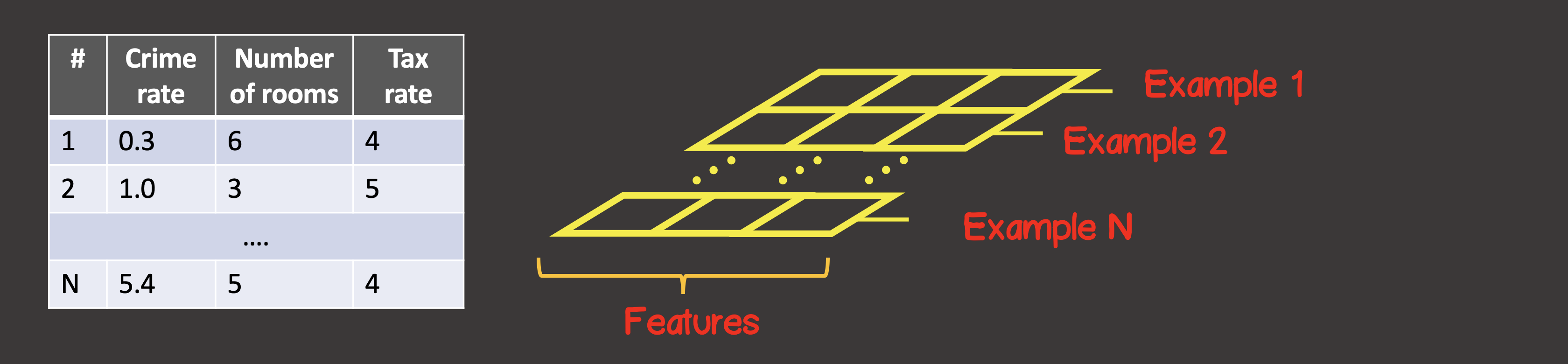
Figura 4 - Estrutura do tensor
Em nosso caso específico, temos 4 instâncias de amostras de dados (Figura 1), o que significa que o tensor de entrada ao longo do primeiro eixo terá 4 elementos. Cada elemento da amostra de treinamento é um vetor que consiste em dois elementos X 1 , X 2 . Assim, o tensor de entrada possui 2 eixos (matriz), ao longo do primeiro eixo existem 4 elementos, ao longo do segundo eixo - 2 elementos.
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
Da mesma forma, converta a saída em um tensor. Quanto aos sinais de entrada, ao longo do primeiro eixo temos 4 elementos, e cada elemento contém um vetor contendo um valor:
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
Vamos criar um modelo usando a API TensorFlow:
const model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 1, activation: 'sigmoid' })
);
A criação do modelo sempre começará com uma chamada para tf.sequential () . O principal bloco de construção de um modelo são as camadas. Podemos conectar quantas camadas à rede neural forem necessárias ao modelo. Aqui usamos uma camada densa , o que significa que cada neurônio na próxima camada tem uma conexão com cada neurônio na camada anterior. Por exemplo, se tivermos duas camadas densas, na primeira camada neurônios, e no segundo - , então o número total de conexões entre as camadas será ...
No nosso caso, como podemos ver, a rede neural consiste em uma camada, na qual existe um neurônio, portanto as unidades são definidas como um.
Além disso, para a primeira camada da rede neural, devemos definir o inputShape , uma vez que cada instância de entrada é representada por um vetor de dois valores X 1 e X 2 , portanto, inputShape = [2] . Observe que não há necessidade de definir inputShape para camadas intermediárias - o TensorFlow pode determinar esse valor a partir do valor de unidades da camada anterior.
Além disso, se necessário, cada camada pode ser atribuída a uma função de ativação, determinamos acima que esta será uma função sigmóide. As funções de ativação atualmente disponíveis no TensorFlow podem ser encontradas aqui .
Em seguida, precisamos compilar o modelo (consulte API aqui ), enquanto precisamos definir dois parâmetros obrigatórios - esta é a função de erro e o tipo de otimizador que procurará seu mínimo:
model.compile({
optimizer: tf.train.sgd(0.1),
loss: 'meanSquaredError'
});
Definimos a descida do gradiente estocástico como o otimizador com uma etapa de treinamento de 0,1.
A lista de otimizadores implementados na biblioteca: tf.train.sgd , tf.train.momentum , tf.train.adagrad , tf.train.adadelta , tf.train.adam , tf.train.adamax , tf.train.rmsprop .
Na prática, por padrão, você pode selecionar imediatamente o otimizador adam , que tem as melhores taxas de convergência do modelo, em contraste com o sgd - a taxa de aprendizagem em cada estágio do treinamento é definida dependendo do histórico das etapas anteriores e não é constante ao longo de todo o processo de aprendizagem.
Como uma função de erro, é dada pela função de erro quadrático médio:
O modelo está definido e a próxima etapa é o processo de treinamento do modelo, para isso o método de ajuste deve ser chamado no modelo :
async function initModel() {
// skip for brevity
await model.fit(trainingInputTensor, trainingOutputTensor, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
// any actions on during any epoch of training
await tf.nextFrame();
}
}
})
}
Definimos que o processo de aprendizagem deve consistir em 100 etapas de aprendizagem (número de épocas de aprendizagem); também em cada época sucessiva - os dados de entrada devem ser embaralhados em ordem aleatória ( shuffle = true ) - o que irá acelerar o processo de convergência do modelo, já que há poucas instâncias em nosso conjunto de dados de treinamento (4).
Após a conclusão do processo de treinamento, podemos usar o método de previsão , que, com base em novos sinais de entrada, calculará o valor de saída.
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
const output = model.predict(testInputTensor).arraySync();
O método generateInputs simplesmente gera um conjunto de dados de amostra de 10x10 que divide o plano de coordenadas em 100 quadrados:
O código completo é fornecido aqui
import React, { useEffect, useState } from 'react';
import LossPlot from './components/LossPlot';
import Canvas from './components/Canvas';
import * as tf from "@tensorflow/tfjs";
let model;
export default () => {
const [data, changeData] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
async function initModel() {
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape:[2], units:1, activation: 'sigmoid'})
);
model.compile({
optimizer: tf.train.adam(0.1),
loss: 'meanSquaredError'
});
await model.fit(inputTensor, outputTensor, {
epochs: 100,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
changeLossHistory((prevHistory) => [...prevHistory, {
epoch,
loss
}]);
const output = model.predict(testInputTensor)
.arraySync();
changeData(() => output.map(([out], i) => ({
out,
x1: testInput[i][0],
x2: testInput[i][1]
})));
await tf.nextFrame();
}
}
})
}
initModel();
}, []);
return (
<div>
<Canvas data={data} squareAmount={10}/>
<LossPlot loss={lossHistory}/>
</div>
);
}
function generateInputs(squareAmount) {
const step = 1 / squareAmount;
const input = [];
for (let i = 0; i < 1; i += step) {
for (let j = 0; j < 1; j += step) {
input.push([i, j]);
}
}
return input;
}
Na figura a seguir, você verá um processo de aprendizagem parcial:

Implementação do Planker:
Simulação da operação lógica XOR O
conjunto de treinamento para esta função é mostrado na Figura 6, e também colocaremos esses pontos como fizemos para a operação lógica OR no plano de coordenadas
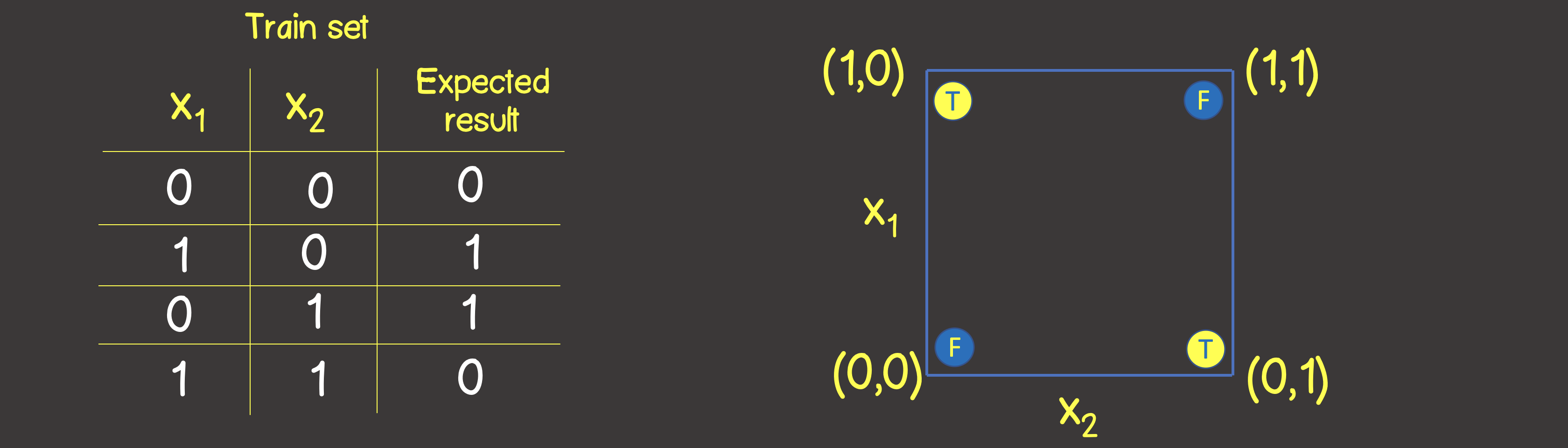
Figura 6 - Conjunto de dados de treinamento e modelo para modelar a operação lógica OU EXCLUSIVO (XOR)
Observe que ao contrário da operação OR lógica - você não pode dividir o plano com uma linha reta, de modo que de um lado haja todos os valores VERDADEIROS , e do outro lado - todos FALSO . No entanto, podemos fazer isso usando duas curvas (Figura 7).
Obviamente, neste caso, um neurônio em uma camada não é suficiente - você precisa de pelo menos mais uma camada com dois neurônios, cada um dos quais definiria uma das duas linhas no plano.
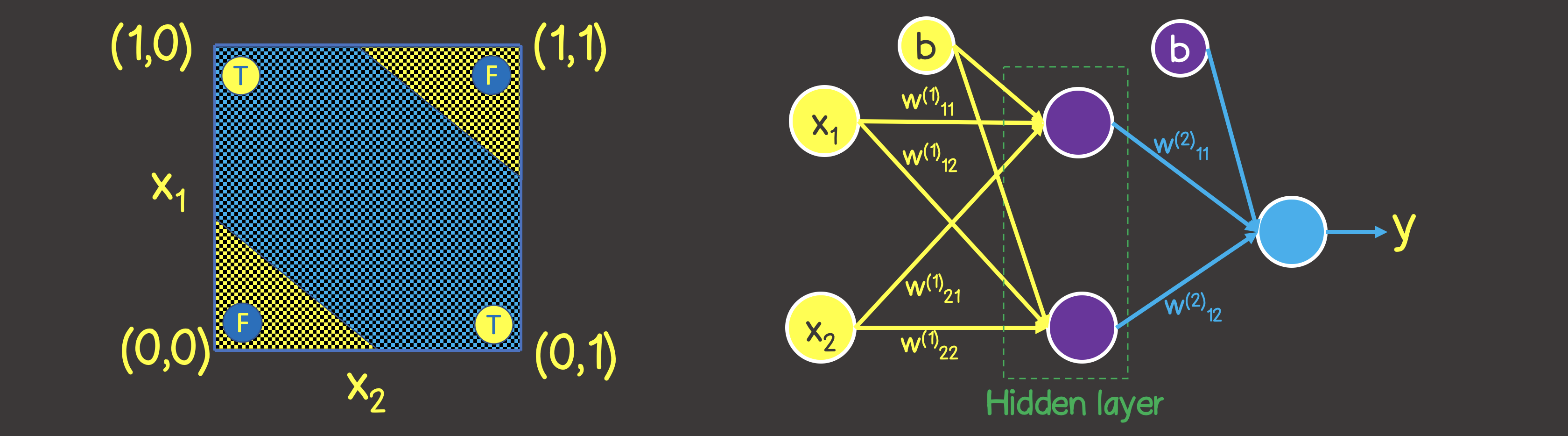
Figura 7 - Modelo de rede neural para a operação lógica EXCLUSIVE OR (XOR)
No código anterior, precisamos fazer alterações em vários locais, um dos quais é o próprio conjunto de dados de treinamento:
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [0]]
const outputTensor = tf.tensor(output, [output.length, 1]);
O segundo lugar é a alteração da estrutura do modelo, conforme Figura 7:
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 2, activation: 'sigmoid' })
);
model.add(
tf.layers.dense({ units: 1, activation: 'sigmoid' })
);
O processo de aprendizagem, neste caso, é assim:

Implementação do Planker:
Tópico do próximo artigo
No próximo artigo descreveremos como resolver problemas relacionados à classificação de objetos em categorias, com base em uma lista de alguns recursos.