Os cientistas de dados descobrem no que as pessoas estão interessadas e em que gastam seu dinheiro
No decorrer da pesquisa de vários públicos, os cientistas de dados observam fatos naturais e surpreendentes que caracterizam vividamente a sociedade ao nosso redor. Neste artigo falarei sobre essas curiosidades e casos inusitados que percebi ao realizar tarefas relacionadas à análise de auditoria, pesquisando os interesses dos internautas e o comportamento de compra de diversos grupos sociais.
Quais características sociológicas foram identificadas por meio do uso de modelos de aprendizado de máquina? O que sabemos sobre os clientes?

Perfil do cliente de seu cheque? Fácil!
Eu trabalho como analista de dados na CleverDATA e normalmente enfrento as seguintes tarefas: classificação de dados brutos, análise de auditoria e construção de modelos semelhantes (LaL) quando o cliente tem seu próprio público e gostaria de encontrar um semelhante. É muito procurado por várias campanhas de publicidade online.
Temos 1DMC DATA Exchange onde os membros podem enriquecer e monetizar seus dados. Ele contém dados despersonalizados de dois tipos, agregados aos atributos de nossa taxonomia - compras online e clickstream, ou seja, a sequência de visitas à página que pudemos rastrear. O formato dos dados atende ao padrão europeu GDPR para proteção de dados pessoais.
Os atributos de nossa taxonomia são os fatos de propriedade de uma coisa ou a presença de certo interesse em uma pessoa. Esta é uma informação binária - lá ou não.
Aqui estão alguns exemplos de nossos atributos de taxonomia:

Uma das tarefas mais significativas é a agregação de dados brutos do fornecedor em atributos de taxonomia, ou seja, a tarefa de classificação.
Preciso tirar conclusões sobre as compras das pessoas sobre seu estilo de vida e se elas têm certas coisas (condicionalmente, um cheque para um modelo de haste de rua de marca provavelmente indica que o comprador é o proprietário de uma motocicleta Harley-Davidson) ou identificar potencial interesse em compras de através das páginas da Internet que visitam. Essas informações serão então usadas para publicidade direcionada.

No decorrer do meu trabalho, aparecem as seguintes cadeias:
- verificar - meus modelos de IA - perfil do comprador;
- clique em fluxo - meus modelos de IA - perfil do visitante do site.
A ferramenta que usamos no CleverDATA construirá automaticamente um classificador binário para qualquer atributo em nossa taxonomia. Pelo próprio nome do atributo de taxonomia (o proprietário do atributo da motocicleta chopper), terminamos com um classificador binário já avaliado automaticamente (se o modelo é bom ou a análise precisa ser aprimorada), que é capaz de determinar a presença ou ausência de tal item em uma pessoa por meio de cheque. Você pode ler mais sobre isso em nosso artigo sobre Habré .

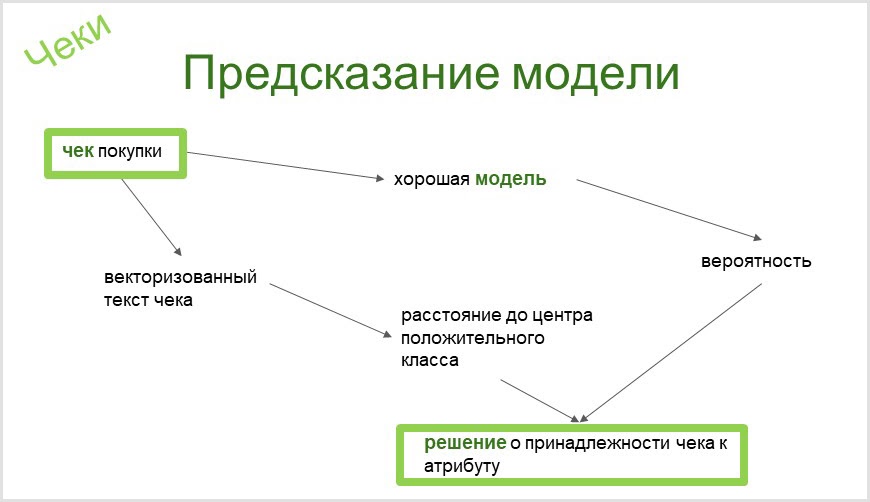
Ao classificar os cheques, você precisa de uma ferramenta que permita separar os cheques que têm palavras semelhantes de significados semelhantes. Então, de alguma forma, construí um modelo para captar o interesse por cursos de reciclagem profissional. E identificou o cheque para a compra do livro infantil de Paolo Cossi "Um Curso de Aulas de Magia para um Gato Comum" como um interesse no assunto. É claro que esse é um erro engraçado. A propósito, fiquei sabendo da existência do livro com esse cheque.

Para evitar essas curiosidades, usamos modelos de linguagem para avaliar os classificadores binários resultantes e cortar os exemplos que são semelhantes em palavras, mas não no significado.
De vez em quando, preciso olhar os recibos com os olhos para encontrar algumas correspondências falsas e, posteriormente, automatizar a busca por essas conexões construídas erroneamente. Pode ser útil chegar ao fundo disso, porque talvez um único caso incompreensível me permita melhorar todo o processo.
Ao longo da minha prática, acumulei todo um conjunto de cheques misteriosos que pude não apenas classificar, mas até mesmo decifrar o que exatamente o comprador comprou. Eu regularmente compartilho esses casos divertidos com colegas e até comecei a coluna "piadas sobre IA".
A dica mais comum é a indicação no cheque do título do livro sem o nome do produto. Isso é exatamente o que vemos no caso de "mágica para um gato comum". E quais compras são registradas no cheque "Fence Novosibirsk 1.029 rublos." e "caixa de contrato 5000 rublos." Eu ainda não entendo. Aceito suas versões nos comentários a este artigo.
A seguir, vamos passar para a classificação do fluxo de cliques.
Perfil do cliente por seus movimentos no site
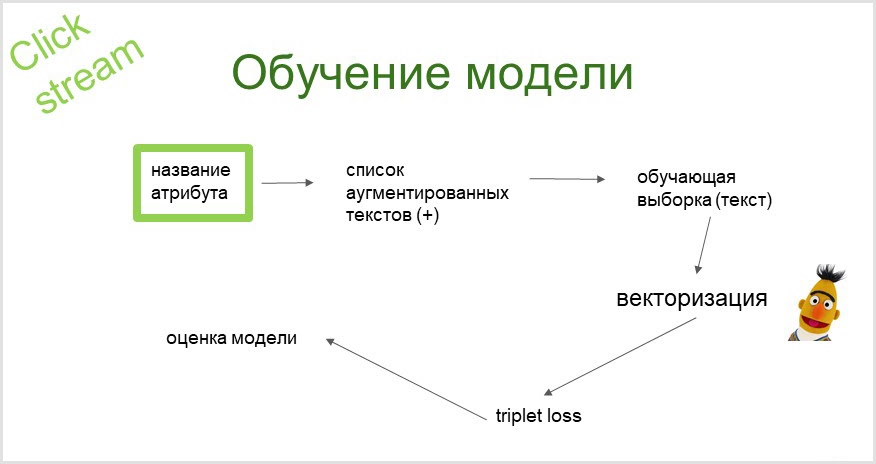
O sistema de classificação clickstream foi introduzido por nós em 2019, que foi rico em avanços no campo da PNL (Processamento de Linguagem Natural). Uma das invenções de maior destaque e sucesso nessa área é a rede BERT ( Bidirectional Encoder Representations from Transformers ). Portanto, haverá um pouco de Bertologia pela frente.

A partir do nome do atributo, usando um modelo de linguagem probabilístico, obtemos uma lista aumentada (estendida com sinônimos) de consultas que rastreamos (enviamos para um mecanismo de pesquisa e coletamos os resultados da pesquisa), portanto, nossa amostra de treinamento é obtida. Vamos vetorizá-lo usando o modelo de linguagem BERT pré-treinado. Usando os embeddings obtidos (vetores), treinamos o classificador (com a função de perda de tripleto).
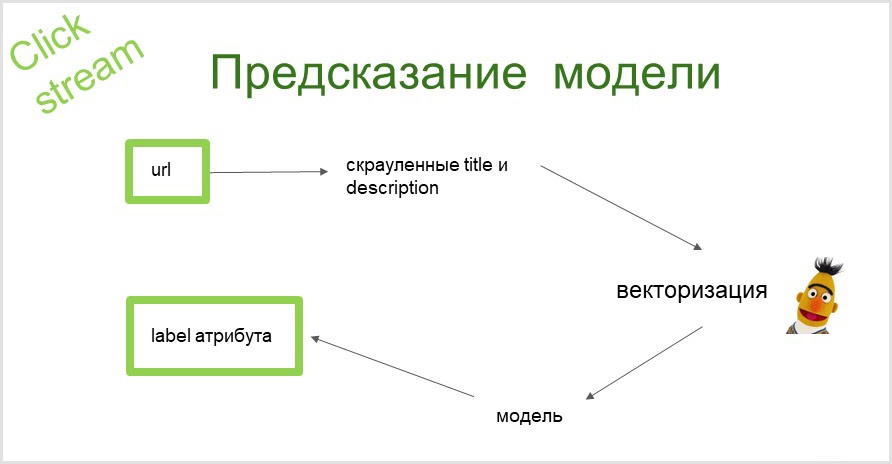
Como funciona a previsão?
Pegamos o url da página, coletamos informações de texto (título e descrição da página). Com a ajuda do BERT, obtemos uma representação vetorial desses textos. Em seguida, esses vetores são alimentados no modelo e, na saída, obtemos um atributo ao qual podemos consultar a página.
Em geral, este sistema é muito bem sucedido, todos os casos engraçados que encontrei são mais exceções do que regra. Mas procuro prestar muita atenção neles, pois um pequeno erro pode levar a grandes consequências desagradáveis, já que uma grande quantidade de dados passa pelo sistema.
Os dados online que pesquisei mostraram que as pessoas lêem mais na Internet. Acontece que este é um dos tópicos mais populares - astrologia, leitura da sorte, etc.

Essas páginas específicas (urls, não domínios) foram visitadas por mais de 5.000 mil pessoas (identificadores únicos) por dia. Fiquei especialmente impressionado com o site dedicado à astrologia de gatos e revelando a conexão entre o caráter do animal e seu signo do zodíaco.

Todos sabem sobre palavras de parada e geralmente conectam dicionários ou filtram por frequências sem se aprofundar nas especificidades dos textos. No início, também conectei meus dicionários. O resultado não foi agradável: o site de receitas sem o uso de assados foi classificado como atributo de interesse em panificação (panificação doméstica). E isso se deve ao fato de que todas as partículas negativas estavam presentes em meu dicionário de palavras irrelevantes.

Usando meu exemplo, exorto meus colegas a lerem cuidadosamente os dicionários com os quais você filtra seus dados.
Outro problema comum é que as pessoas costumam usar linguagem sarcástica, o que, durante a fase de rastreamento, leva a frases engraçadas no título e na descrição de páginas relacionadas a determinadas consultas na Internet. Por exemplo, o modelo pode vincular pastéis e interesse em uma dieta vegetariana. Parece-me que isso pode ser explicado pela abundância de comentários em artigos sobre o tema do vegetarianismo no espírito de "Como você vive sem pastéis?"

E agora um minuto de humor negro em nossa seção "piadas de IA": a modelo conectou a discussão da legalização da eutanásia com o interesse em comprar uma casa, e o rapper Timati com um circo. Tive que rastrear os dados e remarcar manualmente a classe.
Existem configurações que não podemos controlar, elas dependem da sociedade em que vivemos. E então o crime se mistura com comédias e relações familiares.

E também há casos polêmicos em que você nem sabe se vale a pena dar uma bronca no modelo e redesenhar alguma coisa, lutar com os erros ou deixar tudo como está.
É possível que o recebimento de pacotes represente um risco comercial.
Qualquer coisa pode ser encontrada no quadro de avisos.

Procure um público semelhante
O próximo bloco de tarefas que eu, como analista, tenho que resolver é Audiene Research / Look-alike model. O cliente, via de regra, deseja alguns novos conhecimentos sobre o público, o que deve ajudá-lo a estabelecer comunicação com ela. Mas mesmo que seu pedido não esteja claramente formulado, sempre tentamos ajudá-lo e, na maioria dos casos, conseguimos.
Aqui você tem a opção de se concentrar na Pesquisa de público, ou seja, em insights internos (análise de inteligência do público), ou em um modelo semelhante, que permitirá a você acelerar o público de nossa troca e encontrar clientes em potencial com base nos dados internos do cliente sobre o público-alvo. Um público é entendido como um conjunto de identificadores codificados (números de telefone, endereços de e-mail ou id online). Recordo que não trabalhamos com dados de forma aberta, cumprimos todas as regras da lei.
Assim, podemos cruzar muitos identificadores codificados com a troca e ver o comportamento de compra ou seu fluxo de cliques. Fazemos clustering para qualquer público-alvo e qualquer tarefa. Depois que o modelo agrupou as pessoas de acordo com seu comportamento de compra, de alguma forma vi um cluster formado apenas por pessoas que apostam em esportes e não compram mais nada online. Embora seja possível que eles tenham algum tipo de contas separadas para fins de apostas.
Aqui está uma captura de tela deste cluster.

Caso "maternidade feliz"
Para uma campanha publicitária de uma marca conhecida de fraldas, era necessário fazer uma pesquisa de público e encontrar mulheres no terceiro trimestre de gravidez - a cliente sugeriu que era a partir do terceiro trimestre que o produto deveria ser anunciado para que a maioria do público pudesse comprá-lo.
No início da análise, a descrição das circunstâncias de vida das gestantes assemelhava-se a um quadro idílico: uma jovem família com animais de estimação, na véspera do nascimento de um filho, equipa a habitação.

Mulheres de diferentes clusters possuem aparelhos de diferentes marcas, preferem diferentes marcas de produtos de higiene e, em geral, está tudo bem. Veja por si mesmo.
25,5% dos
compradores de IDs de Huggies Elite Soft têm três vezes menos probabilidade de comprar Pampers e 7 vezes menos probabilidade de comprar produtos Lovular. Eles usam produtos da marca Peligrin. Com alta probabilidade (0,6) são pais de meninas. Eles tendem a pagar pelos serviços públicos via Internet.
25,5% dos identificadores estão
inclinados a pagar por serviços de comunicação e seguros pela Internet. Com alta probabilidade (0,6) são donos de cães. Compre produtos Helen Harper. Entre os eletrônicos de consumo, a marca Xiaomi é expressa.
17,5% dos identificadores
Usuários do Ozon Premium. Eles compram equipamentos para bebês Philips Avent e estão interessados em passar roupas e instalações.
Atenção, conselho para o futuro: fique atento às promoções / marcas que geram ruído na quantidade total de dados.
O status de Ozon Premium em muitos de nossos clusters acabou sendo um dos atributos definidores. Mas atingir o público de potenciais compradores de fraldas apenas para o Ozon Premium está além do bom senso. Então, eu tive que retirar o status de todos os dados. Sim, eu baixei as métricas, mas ao mesmo tempo aumentei a adequação do modelo. O primeiro lugar foi ocupado pelos bens para recém-nascidos, e não pelo status popular promovido. Foi uma experiência que me ensinou a cortar produtos que fossem muito significativos para o modelo.
Para a modelagem sósia, a ideia de construir vários classificadores simples de público-alvo (classe 1) e generalizados (classe 0) está na superfície a fim de destacar o público-alvo.
Por exemplo, vamos pegar compras do público-alvo e dez vezes o volume de perfis aleatórios. Trazemos essas informações na seqüência, compras. Em seguida, trabalhamos com os textos resultantes (pré-processamento): removemos todas as palavras não informativas de alta frequência e colocamos o resto na forma inicial. Em seguida, construímos classificadores simples de várias famílias diferentes - linear (Linear SVC, Logistic Regression), "wood" (RandomForest), etc. - e medimos a importância do recurso, ou seja, a importância de quaisquer palavras de acordo com os modelos. Encontrei valores limiares, acima dos quais a importância desses sinais é inadequada, ou seja, o sinal é muito barulhento. Antes de construir algo automático, você deve aplicar o bom senso e o método de olhar cuidadoso muitas vezes para coletar estatísticas internas e entender quais métodos funcionam e quais não.
Examinamos aglomerados com uma imagem idílica na véspera do nascimento de uma criança, mas outras histórias de vida também foram rastreadas. Por exemplo, em um dos clusters, os compradores em potencial de fraldas para recém-nascidos têm alta probabilidade (0,65) de ter uma conta em um site de namoro. Esta não é uma afirmação infundada, eles pagam pelos serviços nesses sites.
Para que os insights “funcionem”, você sempre tem que interpretar novos conhecimentos, mas desta vez eu não quero olhar para a história por dentro - todos sabem sobre o mal-estar social e a desordem cotidiana da vida em nosso país.

Gostaria de lembrar que, como parte desse caso, pesquisamos todo o público interessado em comprar fraldas para recém-nascidos. E descobriu-se que não só as mulheres no terceiro trimestre de gravidez.
Chamei um grupo separado de "pais de domingo" - seus representantes são fãs de futebol, entusiastas de carros ávidos, compram componentes para carros Sparco e de vez em quando compram produtos Chupa Chups.
Agora, atenção, a questão: vale a pena deletar "papais dominicais" se eles não pertencem ao público-alvo originalmente designado? Costumo fazer essa pergunta aos meus gerentes de projeto e a tarefa é repensada. Talvez não precisemos realmente de um público-alvo específico, mas de todos que possam se tornar compradores do produto. No nosso caso, são pais e avós, irmãos e namoradas de uma parturiente, prontos para cuidar do bebê. A resposta a qual público deve ser considerado o alvo é para os representantes comerciais.
Caso "Empreendedores individuais"

O próximo caso, do qual falarei, é a Pesquisa de Público para o público-alvo “Empreendedores individuais” que abriram conta à ordem em um banco conhecido.
As principais diferenças entre essas pessoas e o público da troca podem ser percebidas claramente em suas compras. O mais óbvio é o pagamento de royalties (10-15% dos perfis), serviços de segurança e contas de serviços públicos para instalações não residenciais. Entre os sinais indiretos que apontam para os empresários está a compra de uma peça adicional de bagagem durante os voos (em 15-20% dos casos). Em todo o volume de cheques, uma parte significativa é composta por livros sobre psicologia, autoconhecimento e autodesenvolvimento, workshops de comunicação com subordinados e literatura de coaching.
Com a ajuda da importância do recurso LaL, obtivemos sinais indiretos de público-alvo: transporte aéreo, compra de aspirador robô, máquina de café, smartphone Honor, entrega de flores, pagamento de prêmios de seguros. Este é um daqueles casos maravilhosos em que as máquinas nos fornecem um resultado facilmente interpretável.
Pessoas ocupadas compram robôs domésticos. Nenhum escritório pode viver sem máquinas de café. Entrega de flores e voos frequentes também podem ser vinculados =).
Case "Proprietários de automóveis"
Uma conhecida marca de automóveis no segmento de preços “acima da média” estava absolutamente convencida de que seus clientes eram pessoas completamente excepcionais e desejavam conhecer seus hábitos e preferências.
Este público-alvo se sobrepõe significativamente ao caso anterior ("Empreendedores individuais"). Mas nem todos os empreendedores individuais compram essa marca de carro.

Descobriu-se que a percepção do cliente sobre a singularidade dos clientes é muito exagerada. Sim, o público não coincide com o da média, mas apenas em alguns detalhes, por exemplo, os motoristas preferem comprar o chá elite (300 rublos mais caro) e geralmente gastam mais em bonito e estético do que funcional e prático.
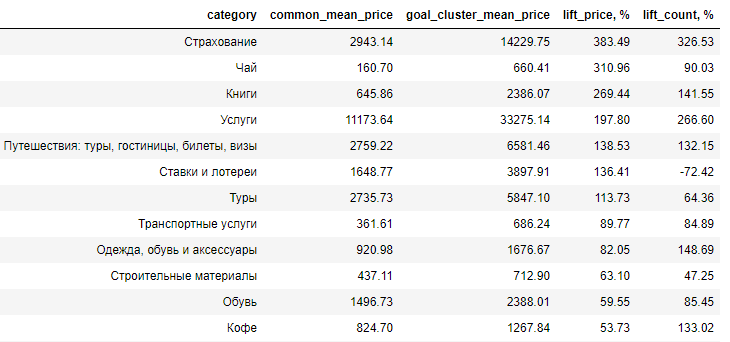
Aqui é apresentada a diferença entre o público-alvo e o público médio dos compradores em termos de aumento, ou seja, em que porcentagem o preço médio de um produto no público estudado ultrapassa o mesmo valor do público médio (lift_price). Como você pode ver, o gasto principal é com prazer.
Sempre testamos as hipóteses de maneira justa e imparcial. É de se esperar que às vezes a hipótese do cliente sobre a exclusividade de seu público não seja suportada pelos dados obtidos. Não há nada com que se preocupar, basta uma nova hipótese e novas pesquisas.

Concluindo, direi que no meu trabalho sou guiado pelo princípio "Rotina calma". E eu te aconselho.
Com tanta variedade de dados, é imprescindível ter muito cuidado e estar atento às pequenas coisas, pois qualquer exceção à primeira vista pode mais tarde se tornar a regra e podemos obter muitos resultados errôneos.
Então, se eu não tivesse visto o que meu modelo "sem assar" se refere como "assar", o sistema "com vazamento" teria entrado em produção. Portanto, não negligencie a rotina: se você passar meia hora checando com os olhos, pode dormir bem - a modelo não cometerá erros.
