Portanto, existem dois tipos de bots da web - legítimos e maliciosos. Os legítimos incluem motores de busca, leitores RSS. Exemplos de web bots mal-intencionados são scanners de vulnerabilidade, scrapers, spammers, bots de ataque DDoS e Trojans de fraude de cartão de pagamento. Assim que o tipo de bot da web for identificado, várias políticas podem ser aplicadas a ele. Se o bot for legítimo, você pode diminuir a prioridade de suas solicitações para o servidor ou diminuir o nível de acesso a certos recursos. Se um bot for identificado como malicioso, você pode bloqueá-lo ou enviá-lo para a sandbox para análise posterior. Detectar, analisar e classificar os bots da web é importante porque eles podem causar danos, por exemplo, vazar dados críticos para os negócios. E também vai reduzir a carga no servidor e reduzir o chamado ruído no tráfego, porque até 66% do tráfego de bot da web é exatamentetráfego malicioso .
Abordagens existentes
Existem diferentes técnicas para detectar bots da web no tráfego de rede, que vão desde limitar a frequência de solicitações a um host, adicionar endereços IP à lista negra, analisar o valor do cabeçalho HTTP do Agente do Usuário, imprimir um dispositivo - e terminar com a implementação de CAPTCHAs e análise comportamental da atividade de rede usando aprendizado de máquina.
Mas coletar informações de reputação sobre um site e manter listas negras atualizadas usando várias bases de conhecimento e inteligência de ameaças é um processo caro e trabalhoso e não é aconselhável ao usar servidores proxy.
A análise do campo User-Agent em uma primeira aproximação pode parecer útil, mas nada impede que o web bot ou o usuário altere os valores deste campo para um válido, disfarçando-se como um usuário regular e usando um User-Agent válido para o navegador, ou como um bot legítimo. Vamos chamar de imitadores de webbots. O uso de várias impressões digitais do dispositivo (rastreando o movimento do mouse ou verificando a capacidade do cliente de renderizar uma página HTML) nos permite destacar bots da web mais difíceis de detectar que imitam o comportamento humano, por exemplo, solicitando páginas adicionais (arquivos de estilo, ícones, etc.), analisando JavaScript. Essa abordagem é baseada na injeção de código do lado do cliente, o que geralmente é inaceitável, já que um erro ao inserir um script adicional pode quebrar o aplicativo da web.
Deve-se destacar que os web bots também podem ser detectados online: a sessão será avaliada em tempo real. Uma descrição dessa formulação do problema pode ser encontrada em Cabri et al. [1], bem como nos trabalhos de Zi Chu [2]. Outra abordagem é analisar somente após o término da sessão. O mais interessante, obviamente, é a primeira opção, que permite tomar decisões mais rapidamente.
A abordagem proposta
Usamos técnicas de aprendizado de máquina e a pilha de tecnologia ELK (Elasticsearch Logstash Kibana) para identificar e classificar bots da web. Os objetos de pesquisa foram sessões HTTP. Sessão é uma sequência de solicitações de um nó (valor único do endereço IP e do campo Agente do Usuário na solicitação HTTP) em um intervalo de tempo fixo. Derek e Gohale usam um intervalo de 30 minutos para definir os limites da sessão [3]. Iliu et al., Argumentam que esta abordagem não garante a exclusividade da sessão real, mas ainda é aceitável. Devido ao fato de que o campo User-Agent pode ser alterado, mais sessões podem aparecer do que realmente existem. Portanto, Nikiforakis e coautores propõem um ajuste mais preciso com base no suporte a ActiveX, se o Flash está habilitado, resolução da tela, versão do sistema operacional.
Consideraremos um erro aceitável na formação de uma sessão separada se o campo Usuário-Agente mudar dinamicamente. E para identificar as sessões de bot, construiremos um modelo de classificação binária claro e usaremos:
- atividade automática de rede gerada por um web bot (tag bot);
- atividade de rede gerada por humanos (tag humano).
Para classificar os bots da web por tipo de atividade, vamos construir um modelo multiclasse a partir da tabela abaixo.
| Nome | Descrição | Rótulo | Exemplos de |
|---|---|---|---|
| Crawlers | Web bots
coletando páginas da web |
rastejante | SemrushBot,
360Spider, Heritrix |
| Redes sociais | Web bots de várias
redes sociais |
rede social | LinkedInBot,
WhatsApp Bot, Facebook bot |
| Leitores rss | -,
RSS |
rss | Feedfetcher,
Feed Reader, SimplePie |
| -
|
search_engines | Googlebot, BingBot,
YandexBot |
|
| -,
|
libs_tools | Curl, Wget,
python-requests, scrapy |
|
| - | bots | ||
| ,
User-Agent |
unknown |
Também resolveremos o problema de treinamento online do modelo.
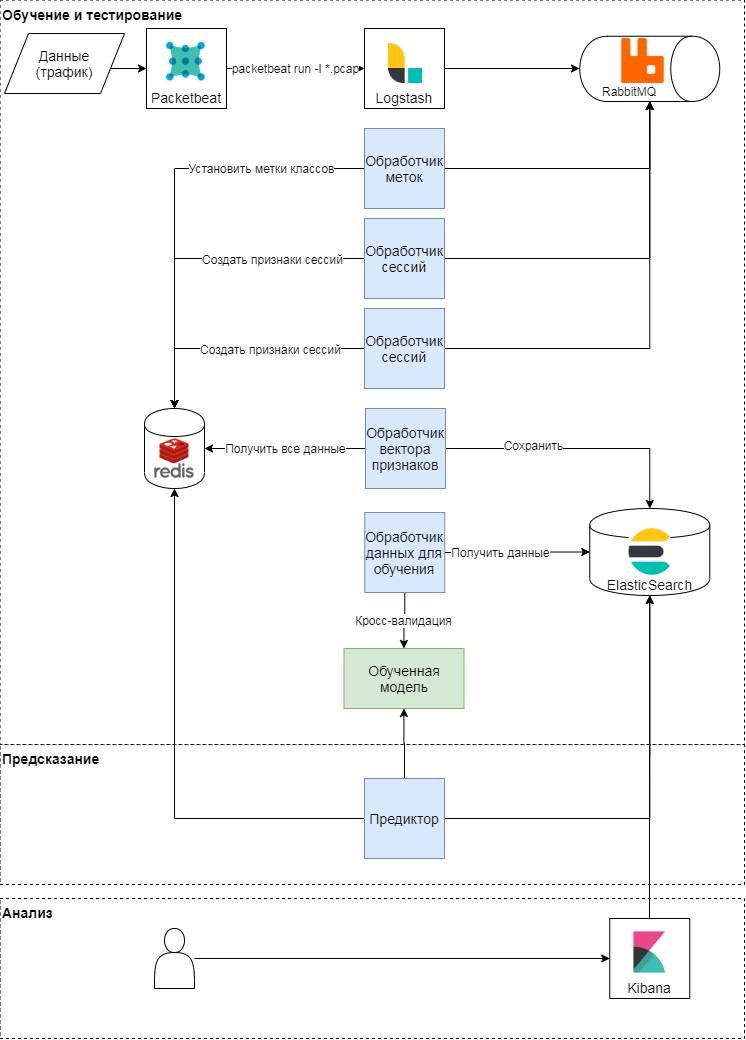
Esquema conceitual da abordagem proposta
Esta abordagem possui três etapas: treinamento e teste, previsão e análise dos resultados. Vamos considerar os dois primeiros com mais detalhes. Conceitualmente, a abordagem segue o padrão clássico de aprendizado e aplicação de modelos de aprendizado de máquina. Primeiro, as métricas de qualidade e atributos para classificação são determinados. Em seguida, um vetor de características é formado e uma série de experimentos (várias verificações cruzadas) são realizados para validar o modelo e selecionar hiperparâmetros. Na última etapa, o melhor modelo é selecionado e a qualidade do modelo é verificada em uma amostra diferida.
Treinamento e teste de modelo
O módulo packetbeat é usado para analisar o tráfego. Solicitações HTTP brutas são enviadas para logstash, onde as tarefas são geradas usando um script Ruby em termos de Celery. Cada um deles opera com um identificador de sessão, hora da solicitação, corpo da solicitação e cabeçalhos. Identificador de sessão (chave) - o valor da função hash da concatenação do endereço IP e do Agente do Usuário. Nesta fase, dois tipos de tarefas são criados:
- na formação de um vetor de recursos para a sessão,
- rotulando a classe com base no texto da solicitação e no Agente do Usuário.
Essas tarefas são enviadas para uma fila, onde os manipuladores de mensagens as executam. Assim, o manipulador do rotulador executa a tarefa de rotular a classe usando a opinião de especialistas e dados abertos do serviço browscap com base no User-Agent utilizado; o resultado é gravado no armazenamento de valor-chave. O processador de sessão gera um vetor de recurso (consulte a tabela abaixo) e grava o resultado para cada chave no armazenamento de valor-chave e também define o tempo de vida da chave (TTL).
| Placa | Descrição |
|---|---|
| len | Número de solicitações por sessão |
| len_pages | Número de solicitações por sessão em páginas
(URI termina com .htm, .html, .php, .asp, .aspx, .jsp) |
| len_static_request | Número de solicitações por sessão em
páginas estáticas |
| len_sec | Tempo da sessão em segundos |
| len_unique_uri | Número de solicitações por sessão
contendo um URI exclusivo |
| headers_cnt | Número de cabeçalhos por sessão |
| has_cookie | Existe um cabeçalho de cookie |
| has_referer | Existe um cabeçalho Referer |
| mean_time_page | Tempo médio por página por sessão |
| mean_time_request | Tempo médio por solicitação por sessão |
| mean_headers | Número médio de cabeçalhos por sessão |
É assim que a matriz de recursos é formada e o rótulo da classe de destino para cada sessão é definido. Com base nessa matriz, ocorre o treinamento periódico dos modelos e a posterior seleção dos hiperparâmetros. Para o treinamento, usamos: regressão logística, máquina de vetores de suporte, árvores de decisão, aumento de gradiente sobre árvores de decisão, algoritmo de floresta aleatório. Os resultados mais relevantes foram obtidos usando o algoritmo de floresta aleatória.
Predição
Durante a análise do tráfego, o vetor de atributos da sessão é atualizado no armazenamento de valores-chave: quando uma nova solicitação aparece na sessão, os atributos que a descrevem são recalculados. Por exemplo, o número médio de cabeçalhos em uma sessão (mean_headers) é calculado toda vez que uma nova solicitação é adicionada à sessão. O Predictor envia o vetor de recursos da sessão para o modelo e grava a resposta do modelo para o Elasticsearch para análise.
Experimentar
Testamos nossa solução no tráfego do portal SecurityLab.ru . Volume de dados - mais de 15 GB, mais de 130 horas. O número de sessões é superior a 10.000 e, pelo fato de o modelo proposto utilizar recursos estatísticos, as sessões com menos de 10 solicitações não foram envolvidas no treinamento e teste. Como métricas de qualidade, usamos as métricas de qualidade clássicas - precisão, integridade e medida F para cada classe.
Testando o modelo de descoberta do Web Bot
Construiremos e avaliaremos um modelo de classificação binária, ou seja, detectaremos os bots, e então os classificaremos por tipo de atividade. Com base nos resultados de uma validação cruzada estratificada quíntupla (isso é exatamente o que é necessário para os dados em consideração, uma vez que há um forte desequilíbrio de classes), podemos dizer que o modelo construído é muito bom (precisão e completude - mais de 98%) é capaz de separar as classes de usuários humanos e bots.
| Precisão média | Plenitude média | Medida F média | |
|---|---|---|---|
| robô | 0,86 | 0,90 | 0,88 |
| humano | 0,98 | 0,97 | 0,97 |
Os resultados do teste do modelo em uma amostra adiada são apresentados na tabela abaixo.
| Precisão | Integridade | Medida F | Número de
exemplos |
|
|---|---|---|---|---|
| robô | 0,88 | 0,90 | 0,89 | 1816 |
| humano | 0,98 | 0,98 | 0,98 | 9071 |
Os valores das métricas de qualidade na amostragem diferida coincidem aproximadamente com os valores das métricas de qualidade durante a validação do modelo, o que significa que o modelo nesses dados pode generalizar o conhecimento adquirido durante o treinamento.
Vamos considerar os erros do primeiro tipo. Se esses dados forem marcados habilmente, a matriz de erro mudará significativamente. Isso significa que alguns erros foram cometidos ao marcar os dados para o modelo, mas o modelo ainda foi capaz de reconhecer tais sessões corretamente.
| Precisão | Integridade | Medida F | Número de
exemplos |
|
|---|---|---|---|---|
| robô | 0,93 | 0,92 | 0,93 | 2446 |
| humano | 0,98 | 0,98 | 0,98 | 8441 |
Vejamos um exemplo de imitadores de sessão. Ele contém 12 consultas semelhantes. Uma das solicitações é mostrada na figura abaixo.
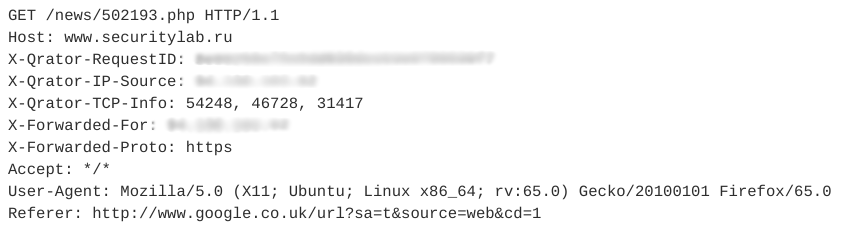
Todas as solicitações subsequentes nesta sessão têm a mesma estrutura e diferem apenas no URI.
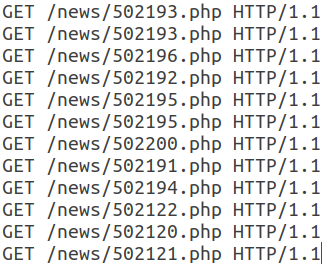
Observe que este webbot usa um User-Agent válido, adiciona um campo Referer, geralmente usado de forma não automática, e o número de cabeçalhos em uma sessão é pequeno. Além disso, as características temporais das solicitações - tempo da sessão, tempo médio por solicitação - permitem dizer que esta atividade é automática e pertence à classe dos leitores RSS. Nesse caso, o próprio bot está disfarçado como um usuário comum.
Testando o modelo de classificação de bot da web
Para classificar os bots da web por tipo de atividade, usaremos os mesmos dados e o mesmo algoritmo do experimento anterior. Os resultados do teste do modelo em uma amostra adiada são apresentados na tabela abaixo.
| Precisão | Integridade | Medida F | Número de
exemplos |
|
|---|---|---|---|---|
| robô | 0,82 | 0,81 | 0,82 | 194 |
| rastejante | 0,87 | 0,72 | 0,79 | 65 |
| libs_tools | 0,27 | 0,17 | 0,21 | dezoito |
| rss | 0,95 | 0,97 | 0,96 | 1823 |
| motores de busca | 0,84 | 0,76 | 0,80 | 228 |
| rede social | 0,80 | 0,79 | 0,84 | 73 |
| desconhecido | 0,65 | 0,62 | 0,64 | 45 |
A qualidade da categoria libs_tools é baixa, mas o volume insuficiente de exemplos para avaliação não nos permite falar sobre a correção dos resultados. Uma segunda série de experimentos deve ser realizada para classificar os bots da web em mais dados. Podemos dizer com segurança que o modelo atual com uma precisão e completude bastante alta é capaz de separar as classes de leitores RSS, motores de busca e bots em geral.
De acordo com esses experimentos sobre os dados em consideração, mais de 22% das sessões (com um volume total de mais de 15 GB) são criadas automaticamente, e entre elas 87% estão relacionadas à atividade de bots gerais, bots desconhecidos, leitores RSS, bots da web usando várias bibliotecas e utilitários ... Portanto, se você filtrar o tráfego de rede de bots da web pelo tipo de atividade, a abordagem proposta reduzirá a carga nos recursos de servidor usados em pelo menos 9 a 10%.
Testando o modelo de classificação de bot da web online
A essência desse experimento é a seguinte: em tempo real, após analisar o tráfego, os recursos são identificados e os vetores de recursos são formados para cada sessão. Periodicamente, cada sessão é enviada ao modelo para predição, cujos resultados são salvos.
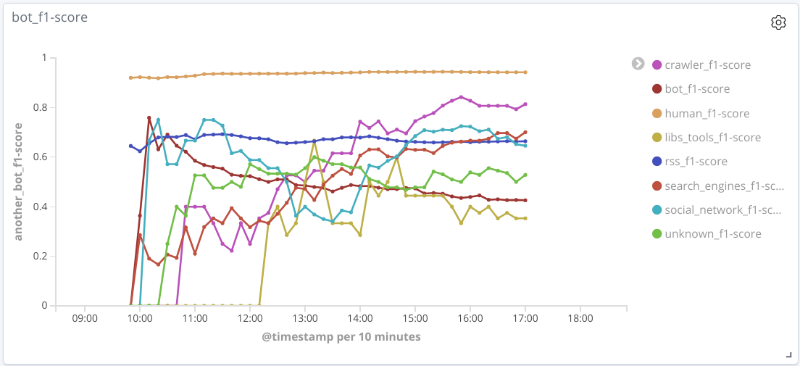
Medida F do modelo ao longo do tempo para cada classe Os
gráficos abaixo ilustram a mudança no valor das métricas de qualidade ao longo do tempo para as classes mais interessantes. O tamanho dos pontos sobre eles está relacionado ao número de sessões na amostra em um determinado momento.

Precisão, completude, medida F para a classe de motores de busca

Precisão, completude, medida F para a classe de ferramentas libs
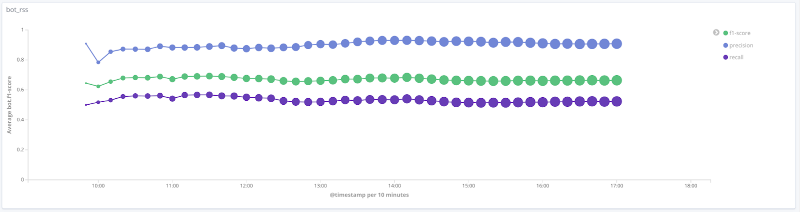
Precisão, completude, medida F para a classe rss

Precisão, completude, medida F para a classe de rastreador

Precisão, completude, medida F para classe humana
Para uma série de classes (humano, rss, search_engines) nos dados em consideração, a qualidade do modelo é aceitável (precisão e integridade acima de 80%). Para a classe crawler, com um aumento no número de sessões e uma mudança qualitativa no vetor de recursos para esta amostra, a qualidade do modelo aumenta: a completude aumentou de 33% para 80%. É impossível tirar conclusões razoáveis para a classe libs_tools, uma vez que o número de exemplos para esta classe é pequeno (menos de 50); portanto, resultados negativos (baixa qualidade) não podem ser confirmados.
Principais resultados e desenvolvimento futuro
Descrevemos uma abordagem para detectar e classificar bots da web usando algoritmos de aprendizado de máquina e recursos estatísticos. Nos dados em consideração, a acurácia e completude médias da solução proposta para classificação binária é superior a 95%, o que indica que a abordagem é promissora. Para certas classes de bots da web, a precisão e integridade médias é de cerca de 80%.
A validação dos modelos construídos exige uma avaliação real da sessão. Conforme mostrado anteriormente, o desempenho de um modelo é significativamente melhorado quando há marcação correta para a classe de destino. Infelizmente, agora é difícil construir essa marcação automaticamente e você precisa recorrer à marcação especializada, o que complica a construção de modelos de aprendizado de máquina, mas permite que você encontre padrões ocultos nos dados.
Para o desenvolvimento do problema de classificação e detecção de bots da web, é aconselhável:
- alocar classes adicionais de bots e treinar novamente, testar o modelo;
- adicione sinais adicionais para classificar os bots da web. Por exemplo, adicionar o atributo robots.txt, que é binário e é responsável pela presença ou ausência de acesso à página do robots.txt, permite aumentar a pontuação F média para uma classe de bots da web em 3% sem piorar outras métricas de qualidade para outras classes;
- faça uma marcação mais correta para a classe de destino, levando em consideração meta-recursos adicionais e opinião especializada.
Autor : Nikolay Lyfenko, Especialista Principal, Grupo de Tecnologias Avançadas, Tecnologias Positivas
Fontes
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.