
Continuação da coleção de histórias da Internet sobre como os bugs às vezes têm manifestações completamente incríveis. A primeira parte está aqui .
Mais magia
Há alguns anos, vasculhei os armários que abrigavam o computador PDP-10 que pertencia ao laboratório de IA do MIT. Notei um pequeno interruptor colado na estrutura de um dos armários. Ficou claro que se tratava de um produto caseiro, acrescentado por um dos artesãos do laboratório (ninguém sabia quem exatamente).
Você não tocará em um botão desconhecido em seu computador sem saber o que ele faz, porque você pode quebrá-lo. O switch foi assinado de forma completamente ininteligível. Ele tinha duas posições, e as palavras "mágica" e "mais mágica" foram rabiscadas no corpo de metal a lápis. O interruptor estava na posição mais mágica. Liguei para um dos técnicos para dar uma olhada. Ele nunca tinha visto tal coisa antes. Após um exame mais detalhado, descobriu-se que apenas um fio vai para o switch! A outra extremidade do fio desapareceu na confusão de cabos dentro do computador, mas a natureza da eletricidade determina que um switch não fará nada até que você conecte dois fios nele.
Era óbvio que essa era a piada idiota de alguém. Depois de nos certificarmos de que a chave não faz nada, nós a alternamos. O computador desmaiou imediatamente.
Imagine nosso espanto. Achamos que era uma coincidência, mas ainda colocamos o botão de volta na posição "mais mágica" antes de iniciar o computador.
Um ano depois, contei essa história para outro técnico, David Moon, pelo que me lembro. Ele questionou minha adequação, ou suspeitou de acreditar na natureza sobrenatural daquela mudança, ou pensou que eu estava brincando com sua história falsa. Para provar meu ponto de vista, mostrei a ele esta chave, ainda colada na moldura e com um único fio, ainda na posição "mais mágica". Examinamos o interruptor e o fio de perto e descobrimos que ele estava aterrado. Parecia duplamente sem sentido: o interruptor não estava apenas eletricamente inoperante, mas também conectado a um local que não afetava nada. Nós o movemos para uma posição diferente.
O computador ficou em branco imediatamente.
Entramos em contato com Richard Greenblatt, um técnico de longa data do MIT, que estava por perto. Ele também nunca tinha visto a mudança. Eu examinei, cheguei à conclusão de que o interruptor era inútil, tirei o alicate e cortei o fio. Então ligamos o computador e ele começou a funcionar silenciosamente.
Ainda não sabemos como essa opção desligou o computador. Existe a hipótese de que ocorreu um pequeno curto-circuito próximo ao contato de aterramento e a translação das posições das chaves alterou a capacitância elétrica de modo que o circuito foi interrompido quando pulsos com duração de um milionésimo de segundo passaram por ele. Mas não saberemos com certeza. Só podemos dizer que a mudança foi mágica.
Ainda está no meu porão. Isso provavelmente é bobo, mas eu geralmente o mantenho na posição "mais mágica".
Em 1994, outra explicação para essa história foi proposta. Observe que o corpo do switch era de metal. Suponha que um contato sem um segundo fio foi conectado ao corpo (geralmente o corpo é aterrado, mas há exceções). O corpo do switch estava conectado ao gabinete do computador, que provavelmente estava aterrado. Então, o circuito de aterramento dentro da máquina pode ter um potencial diferente do circuito de aterramento da estrutura, e a mudança da posição da chave levou a uma queda ou surto de tensão e a máquina foi reinicializada. Esse efeito foi provavelmente descoberto por alguém que sabia da diferença de potencial e decidiu fazer uma troca de brincadeira.
OpenOffice não imprime às terças-feiras
Hoje no blog me deparei com uma menção a um bug interessante. Algumas pessoas estavam tendo problemas para imprimir documentos. Mais tarde, alguém notou que sua esposa reclamava de não conseguir imprimir às terças-feiras!
Nos relatórios de bug, alguns inicialmente reclamaram que deve ser um bug do OpenOffice, porque de todos os outros aplicativos ele imprimiu sem problemas. Outros notaram que o problema vai e vem. Um usuário encontrou uma solução: desinstale o OpenOffice e limpe o sistema, depois reinstale (qualquer tarefa simples no Ubuntu). O usuário relatou na terça-feira que seu problema de impressão foi resolvido.
Duas semanas depois, ele escreveu (na terça-feira) que sua solução ainda não funcionou. Cerca de quatro meses depois, a esposa do hacker do Ubuntu reclamou que o OpenOffice não imprimia às terças-feiras. Imagine esta situação:
Esposa: Steve, a impressora fecha às terças-feiras.
Steve: É um dia de folga na impressora, claro que não imprime às terças-feiras.
Esposa: Estou falando sério! Não consigo imprimir do OpenOffice às terças-feiras.
Steve: (incrédulo) Ok, me mostre.
Esposa: Não posso te mostrar.
Steve: (revirando os olhos) Por quê?
Esposa: Hoje é quarta-feira!
Steve: (acena com a cabeça, fala devagar) Certo.
O problema foi rastreado até um programa chamado
file. Este utilitário * NIX usa modelos para detectar tipos de arquivo. Por exemplo, se o arquivo começa com%!e então vai PS-Adobe-, então é PostScript. Parece que o OpenOffice está gravando dados nesse arquivo. Na terça-feira ele tira seu uniforme %%CreationDate: (Tue MMM D hh:mm:...). Um erro no modelo para arquivos Erlang JAM significa que Tueo arquivo PostScript foi reconhecido como um arquivo Erlang JAM e, portanto, presumivelmente, não estava sendo enviado para impressão.
O modelo para o arquivo Erlang JAM se parece com este:
4 string Tue Jan 22 14:32:44 MET 1991 Erlang JAM file - version 4.2
E deve ser assim:
4 string Tue\ Jan\ 22\ 14:32:44\ MET\ 1991 Erlang JAM file - version 4.2
Dada a variedade de tipos de arquivo que este programa tenta reconhecer (mais de 1600), os erros de modelo não são surpreendentes. Mas a ordem de comparação também leva a falsos positivos frequentes. Nesse caso, o tipo Erlang JAM foi mapeado para o tipo PostScript.
Pacotes de morte
Comecei a chamá-los assim porque eram exatamente pacotes de morte.
Star2Star fez parceria com um fabricante de hardware que criou as duas últimas versões de nosso sistema cliente local.
Cerca de um ano atrás, lançamos uma atualização para este hardware. Tudo começou bem simples, seguindo a lei usual de Moore. Maior, melhor, mais rápido, mais barato. O novo hardware era de 64 bits, tinha 8 vezes mais memória, mais drives e quatro portas Intel Gigabit Ethernet (meu fabricante favorito de controladores Ethernet). Tínhamos (e ainda temos) muitas ideias sobre como usar essas portas. Em geral, o pedaço de ferro era incrível.
A novidade passou por testes de desempenho e funcionalidade. A velocidade e a confiabilidade são altas. Idealmente. Em seguida, implantamos lentamente o equipamento em vários locais de teste. Claro, os problemas começaram a surgir.
Uma rápida pesquisa no Google sugere que a controladora Intel 82574L Ethernet teve pelo menos alguns problemas. Em particular, problemas com EEPROM, bugs no ASPM, truques com MSI-X, etc. Estamos resolvendo cada um deles há vários meses. E pensamos que tínhamos terminado.
Mas não. Só piorou.
Achei que projetei e implantei a imagem de software (e BIOS) perfeita. Porém, a realidade era diferente. Os módulos continuaram falhando. Às vezes, eles se recuperavam após uma reinicialização, às vezes não. No entanto, depois que o módulo foi restaurado, ele precisava ser testado.
Uau. A situação estava ficando estranha.
As esquisitices continuaram e, finalmente, decidi arregaçar as mangas. Tive a sorte de encontrar um revendedor muito paciente e prestativo que ficou comigo ao telefone por três horas enquanto eu colhia dados. Nesse ponto do cliente, por algum motivo, o controlador Ethernet pode cair durante a transmissão do tráfego de voz pela rede.
Vou me alongar sobre isso com mais detalhes. Quando digo que o controlador Ethernet “pode ter desligado”, significa que PODE ter desligado. O sistema e a interface Ethernet pareciam bem e, após enviar uma quantidade aleatória de tráfego, a interface poderia relatar um erro de hardware (perda de comunicação com o PHY) e perder a conexão. Os LEDs no switch e na interface literalmente apagaram. O controlador estava morto.
Foi possível trazê-lo de volta à vida apenas desligando e ligando novamente. A tentativa de reinicializar um módulo de kernel ou máquina resultou em um erro de varredura PCI. A interface permaneceu inativa até que a máquina fosse fisicamente desconectada e conectada novamente. Na maioria dos casos, para nossos clientes, isso significava retirar o equipamento.
Durante a depuração com este revendedor muito paciente, comecei a parar de receber pacotes quando a interface travou. No final, identifiquei um padrão: o último pacote da interface era sempre
100 Trying provisional response, e sempre tinha um determinado comprimento. Isso não é tudo, eu eventualmente rastreei esta resposta (do Asterisk) de volta ao pedido INVITE original específico para um dos telefones dos fabricantes.
Liguei para o revendedor, reuni as pessoas e mostrei as evidências. Embora fosse sexta-feira à noite, todos participaram dos trabalhos e montaram uma bancada de testes com nossos novos equipamentos e telefones deste fabricante.
Sentamos em uma sala de conferências e começamos a discar o mais rápido que nossos dedos podiam. Descobriu-se que podemos reproduzir o problema! Não em todas as chamadas e nem em todos os dispositivos, mas de vez em quando conseguíamos ligar o controlador Ethernet e de vez em quando não. Depois de desligar a energia, tentamos novamente e tivemos sucesso. Em todo caso, como sabe quem já tentou diagnosticar problemas técnicos, o primeiro passo é reproduzir o problema. Finalmente conseguimos.
Acredite em mim, demorou muito. Eu sei como funciona a pilha OSI. Eu sei como o software é segmentado. Eu sei que o conteúdo dos pacotes SIP não deve afetar o adaptador Ethernet. É tudo um absurdo.
Por fim, conseguimos isolar o problema dos pacotes no intervalo entre sua chegada ao nosso dispositivo e na porta de espelhamento do switch. Descobriu-se que o problema era com o pedido
INVITE, não com a resposta 100 Trying. Não 100 Tryinghouve resposta nos dados capturados na porta espelhada .
Era preciso lidar com isso
INVITE. O problema estava relacionado ao manuseio deste pacote pelo daemon do espaço do usuário? Talvez a transmissão fosse o problema 100 Trying? Um colega sugeriu fechar o aplicativo SIP e ver se o problema persistia. Sem este aplicativo, pacotes100 Tryingnão foram transmitidos.
Era necessário melhorar de alguma forma a transmissão dos pacotes problemáticos. Isolamos o pacote transmitido do telefone
INVITEe o reproduzimos usando tcpreplay. Funcionou. Pela primeira vez em meses, conseguimos descartar portas no comando com um único pacote. Foi um avanço significativo, e era hora de voltar para casa, ou seja, repetir a bancada de testes no laboratório doméstico!
Antes de continuar minha história, quero contar a vocês sobre um ótimo aplicativo de código aberto que encontrei. Ostinato transforma você em um mestre de pacotes. Suas possibilidades são literalmente infinitas. Sem esta aplicação, não teria conseguido progredir mais.
Armado com esta ferramenta de pacote versátil, comecei a experimentar. Fiquei surpreso com o que encontrei.
Tudo começou com uma peculiaridade SIP / SDP estranha. Dê uma olhada neste SDP:
v=0
o=- 20047 20047 IN IP4 10.41.22.248
s=SDP data
c=IN IP4 10.41.22.248
t=0 0
m=audio 11786 RTP/AVP 18 0 18 9 9 101
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:0 PCMU/8000
a=rtpmap:18 G729/8000
a=fmtp:18 annexb=no
a=rtpmap:9 G722/8000
a=rtpmap:9 G722/8000
a=fmtp:101 0-15
a=rtpmap:101 telephone-event/8000
a=ptime:20
a=sendrecv
Sim está certo. A proposta de transmissão de som está duplicada. Isso é um problema, mas, novamente, o que o controlador Ethernet tem a ver com isso? Bem, além do fato de que nada mais aumenta o tamanho do quadro Ethernet ... Mas espere, havia muitos quadros Ethernet bem-sucedidos nos pacotes transmitidos. Alguns deles eram menores, outros mais. Não houve problemas com eles. Eu tive que cavar mais longe. Depois de alguns truques de kung fu com Ostinato e um monte de reconexões elétricas, fui capaz de identificar a relação problemática (com o quadro do problema). Nota: estaremos olhando para valores hexadecimais.
Uma falha de interface foi iniciada por um valor de byte específico em um deslocamento específico. No nosso caso, foi o valor hexadecimal
32c 0x47f. Em ASCII, hexadecimal 32é2... Adivinhe de onde veio 2.
a=ptime:20
Todos os nossos SDPs eram idênticos (inclusive
ptime). Todos os URIs de origem e destino eram idênticos. As únicas diferenças eram o número do chamador, as tags e os IDs de sessão exclusivos. Os pacotes problemáticos tinham uma combinação de IDs de chamada, tags e ramificações, o que ptimeresultou em um valor 2com um deslocamento 0x47f.
Estrondo! Com os IDs, tags e ramos corretos (ou qualquer lixo aleatório), um "pacote bom" poderia se transformar em um pacote "matador" assim que a linha
ptimeterminasse em um determinado endereço. Foi muito estranho.
Ao gerar pacotes, experimentei diferentes valores hexadecimais. A situação ficou ainda mais complicada. Descobriu-se que o comportamento do controlador dependia inteiramente desse valor específico localizado no endereço especificado no primeiro pacote recebido. A foto era assim:
0x47f = 31 HEX (1 ASCII) -
0x47f = 32 HEX (2 ASCII) -
0x47f = 33 HEX (3 ASCII) -
0x47f = 34 HEX (4 ASCII) - (inoculation)
Quando eu disse "não afeta", quis dizer que não só não mata a interface, mas também não inocula (mais ou menos). E quando digo que "a interface está travando", bem, lembra da minha descrição? A interface está morrendo. Completamente.
Após novos testes, descobri que o problema persiste com todas as versões do Linux que pude encontrar, com o FreeBSD, e até mesmo ligando a máquina sem mídia inicializável! Era sobre o hardware, não o sistema operacional. Uau.
Além disso, com a ajuda de Ostinato, consegui criar diferentes versões do pacote killer: HTTP POST, ICMP echo request e outros. Quase tudo que eu queria. Com um servidor HTTP modificado que gerava dados em valores de byte (baseado em cabeçalhos, host, etc.), foi fácil criar a 200ª solicitação HTTP para conter o pacote de morte e matar as máquinas clientes atrás do firewall!
Já expliquei como era estranha toda a situação. Mas o mais estranho foi com a vacina. Descobriu-se que se o primeiro pacote recebido contiver algum valor (do testado por mim), com exceção
1, 2ou 3, se a interface se tornar invulnerável a morte de algum pacote (contendo o valor 2ou 3). Além disso, os códigos e os atributos ptimetêm sido múltiplos de 10: 10, 20, 30, 40. Dependendo da combinação de Call ID, Tag, Branch, IP, URI e mais (com este SDP com erros), esses atributos válidos ptimealinhados em uma sequência perfeita. Incrível!
De repente, ficou claro por que o problema estava ocorrendo esporadicamente. É incrível que eu tenha conseguido descobrir. Trabalho com redes há 15 anos e nunca vi nada parecido. E eu duvido que vou te ver novamente. Com sorte ...
Entrei em contato com dois engenheiros da Intel e enviei uma demonstração para que pudessem reproduzir o problema. Depois de experimentar por algumas semanas, eles descobriram que o problema era com a EEPROM nos controladores 82574L. Eles me enviaram uma nova EEPROM e uma ferramenta de escrita. Infelizmente, não conseguimos distribuí-lo e, além disso, foi necessário descarregar e recarregar o módulo do kernel e1000e, portanto a ferramenta não era adequada para nosso ambiente. Felizmente (com um pouco de conhecimento do esquema EEPROM), fui capaz de escrever um script bash e magicamente
ethtoolsalvou os valores "corrigidos" e registrou-os nos sistemas onde o bug se manifestou. Agora podemos identificar os dispositivos com problemas. Entramos em contato com nosso fornecedor para aplicar o patch a todos os dispositivos antes de enviá-lo para nós. Não se sabe quantos desses controladores Intel Ethernet já foram vendidos.
Mais uma palete
Em 2005, tive um problema inexplicável no trabalho. Um dia após o desligamento não planejado (devido ao furacão), comecei a receber ligações de usuários que reclamavam de tempo limite ao se conectar ao banco de dados. Como tínhamos uma rede muito simples de 32 nós e com largura de banda praticamente não utilizada, fiquei alarmado porque o servidor com o banco de dados executou ping normalmente por 15-20 minutos e, em seguida, as respostas de “solicitação expirou” chegaram em cerca de dois minutos. Este servidor estava executando monitoramento de desempenho e outras ferramentas e ping de vários locais. Com exceção do servidor, o resto das máquinas podem se comunicar com outros membros da rede o tempo todo. Procurei um switch ou conexão com falha, mas não consegui encontrar uma explicação para as falhas aleatórias e intermitentes.
Pedi a um colega para observar os LEDs no switch do warehouse enquanto eu fazia o roteamento e reconectava diferentes dispositivos. Demorou 45-50 minutos, um colega me disse no rádio "este está desligado, aquele levantou." Eu perguntei se ele notou algum padrão.
- Sim eu notei. Mas você vai pensar que estou louco. Cada vez que uma empilhadeira retira um palete da área de expedição, ocorre um tempo limite após dois segundos no servidor.
- O QUE???
- Sim. E o servidor é restaurado quando o carregador começa a enviar um novo pedido.
Corri para olhar a empilhadeira e tive certeza de que ele estava marcando a conclusão bem-sucedida do pedido ao ligar um magnetron gigante. Sem dúvida, as ondas eletromagnéticas do capacitor levam a uma ruptura no continuum espaço-tempo e interrompem temporariamente o funcionamento da placa de rede do servidor localizada em outra sala a 50 metros de distância. Não. A empilhadeira simplesmente empilhou caixas maiores no palete com caixas menores em cima, enquanto digitalizava cada caixa com um leitor de código de barras sem fio. Aha! Provavelmente é o scanner que está acessando o servidor de banco de dados, fazendo com que outras consultas falhem. Não. Eu verifiquei e descobri que o scanner não tinha nada a ver com isso. O roteador sem fio e seu no-break no saguão de embarque foram configurados corretamente e estão funcionando normalmente. O motivo foi outro, porque antes do fechamento por conta do furacão tudo funcionava bem.
Assim que o próximo tempo limite começou, corri para a área de embarque e observei o carregador encher o próximo palete. Assim que ele colocou quatro caixas grandes de shampoo em uma bandeja vazia, o servidor desligou novamente! Não acreditei no absurdo do que estava acontecendo, e por mais cinco minutos tirei e coloquei caixas de xampu, com o mesmo resultado. Eu estava prestes a cair de joelhos e orar pela misericórdia do Deus da Intranet quando percebi que o roteador no corredor de embarque estava pendurado cerca de 30 cm abaixo do nível das caixas no palete. Existe uma pista!
Quando grandes caixas foram colocadas em um palete, o roteador sem fio perdeu a linha de visão do armazém externo. Depois de dez minutos, resolvi o problema. Aqui está o que aconteceu. Durante o furacão, houve uma queda de energia que derrubou o único dispositivo não conectado ao UPS - um roteador sem fio de teste em meu escritório. As configurações padrão de alguma forma o transformaram em um repetidor para o único outro roteador sem fio pendurado na área de transporte. Ambos os dispositivos só podiam se comunicar quando não havia palete entre eles, mas mesmo assim o sinal não era muito forte. Quando os roteadores conversaram, eles criaram um loop em minha pequena rede e, em seguida, todos os outros pacotes para o servidor de banco de dados foram perdidos. O servidor tinha seu próprio switch do roteador principal, portanto, como um nó da rede, estava muito mais distante.A maioria dos outros computadores estavam no mesmo switch de 16 portas, então eu pude fazer ping entre eles sem problemas.
Em um segundo, resolvi um problema que vinha atormentando há quatro horas: desliguei o roteador de teste. Não houve mais tempos limite no servidor.
Como no filme Tron, apenas em um computador Apple IIgs
Um dos meus filmes favoritos quando criança foi Tron, que foi filmado no início dos anos 1980. Ele falava de um programador que foi “digitalizado” e absorvido no mundo da computação habitado por programas personalizados. O protagonista se juntou a um grupo de resistência na tentativa de derrubar o opressor Master Control Program (MCP), um programa rebelde que evoluiu, ganhou uma ânsia de poder e tentou assumir o sistema de computador do Pentágono.
Em uma das cenas mais impressionantes dos programas, os personagens correm em bicicletas leves - carros de duas rodas que parecem motocicletas que deixam paredes atrás de si. Um dos protagonistas forçou os pepelats inimigos a se chocarem contra a parede da arena, abrindo um buraco. Os heróis lidaram com seus oponentes e fugiram pelo buraco para a liberdade - o primeiro passo para a derrubada do MCP.
Quando assisti ao filme, não tinha ideia de que anos depois eu iria inadvertidamente recriar o mundo de Tron, programas rebeldes e tudo mais em um computador Apple IIgs.
Foi assim que aconteceu. Quando comecei a aprender a programar, decidi criar um jogo de ciclo leve da Tron. Junto com meu amigo Marco, escrevi um programa sobre Apple IIgs em ORCA / Pascal e assembler 65816. Durante o jogo, a tela foi pintada de preto com uma borda branca. Cada linha representa um dos jogadores. Exibimos os resultados dos jogos em uma linha na parte inferior da tela. Graficamente, não era o programa mais avançado, mas era simples e divertido. Ela parecia assim:

O jogo suportava até quatro jogadores se eles se sentassem em frente a um teclado. Foi inconveniente, mas funcionou. Raramente conseguimos obter o número certo de pessoas para usar os quatro ciclos de luz, então Marco adicionou jogadores controlados por computador que pudessem competir de maneira razoável.
Corrida armamentista
O jogo já era muito engraçado, mas queríamos experimentar. Adicionamos foguetes para dar aos jogadores a chance de escapar de um acidente iminente. Como Marco descreveu mais tarde:
Humanos e IA cada um tinha três mísseis que podiam ser usados durante o jogo. Quando o foguete atingiu a parede, houve uma "explosão", cujo fundo foi pintado de preto, removendo assim trechos da trilha deixados pelos ciclos de luz anteriores.
Em breve, jogadores e computadores poderiam abrir caminho para sair de situações difíceis com foguetes. Embora os puristas de Tron riam disso, os programas do filme não tinham o luxo dos foguetes.
A fuga
Como acontece com todos os eventos incomuns e bizarros, também foi inesperado.
Uma vez, quando Marco e eu estávamos jogando contra dois jogadores de computador, prendemos um dos loops de IA entre sua própria parede e a borda inferior da tela. Antecipando um acidente iminente, ele disparou um foguete, como sempre fazia antes. Mas desta vez, em vez de uma parede, ele atirou na borda da tela, que parecia o rastro de um dos ciclos de luz. O míssil atingiu a fronteira, deixou um buraco do tamanho de um ciclo de luz e o computador imediatamente saiu do campo de jogo por ele. Olhamos confusos para o ciclo de luz enquanto ele passava pela linha de pontuação. Ele facilmente evitou colidir com os símbolos e então deixou a tela completamente.
E imediatamente depois disso, o sistema travou.

Nossas mentes balançavam enquanto tentávamos entender o que havia acontecido. O computador encontrou uma maneira de sair do jogo. Quando o ciclo de luz saiu da tela, ele escapou para a memória do computador, assim como no filme. Nosso queixo caiu quando percebemos o que havia acontecido.
O que fizemos quando descobrimos um defeito em nosso programa que pode travar regularmente todo o sistema? Fizemos tudo de novo. Primeiro, tentamos nós mesmos sair dos limites. Então eles forçaram o computador a fugir novamente. Toda vez que éramos recompensados com travamentos de sistema encantadores. Às vezes, a luz do drive piscava enquanto o drive roncava sem parar. Outras vezes, a tela se enchia de caracteres sem sentido ou o alto-falante emitia um guincho ou zumbido baixo. E às vezes tudo acontecia ao mesmo tempo, e o computador ficava em um estado de completa desordem.
Por quê isso aconteceu? Para entender isso, vamos dar uma olhada na arquitetura do computador Apple IIgs.
Memória (des) protegida
O sistema operacional Apple IIgs não tinha memória protegida, que apareceu em sistemas operacionais posteriores, quando áreas de memória foram atribuídas a um programa e protegidas de acesso externo. Portanto, um programa para Apple IIgs podia ler e escrever qualquer coisa (exceto ROM). O IIgs usava E / S vinculada à memória para acessar dispositivos como a unidade de disquete, portanto, era possível ativar a unidade de disquete lendo de uma área específica da memória. Essa arquitetura permitiu que os programas gráficos leiam e gravem diretamente na memória da tela.
O jogo usava um dos modos gráficos do Apple IIgs - Super Hi-Res: uma incrível resolução de 320x200 pixels com uma paleta de 16 cores. Para selecionar uma paleta, o programador especificou 16 entradas (numeradas de 0 a 15 ou de $ 0 a F em formato hexadecimal) para valores de cor de 12 bits. Para desenhar na tela, você pode ler e escrever cores diretamente na memória de vídeo.
Algoritmo de detecção de colisão
Aproveitamos esse recurso e implementamos um detector de falhas lendo diretamente da memória de vídeo. O jogo calcula para cada ciclo de luz sua próxima posição com base na direção atual e lê esse pixel da memória de vídeo. Se a posição estava vazia, ou seja, representada por um pixel preto (entrada na paleta $ 0), o jogo continuava. Mas se a posição fosse tomada, o jogador colidia com o ciclo de luz ou o quadro branco da tela (entrada na paleta 15 ou $ F). Exemplo:
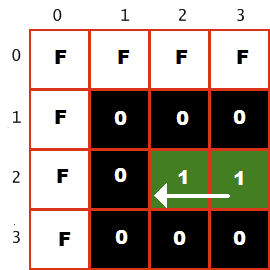
O canto superior esquerdo da tela é mostrado aqui. A cor $ F denota uma borda branca e a cor $ 1 denota o ciclo de luz verde do jogador. Ele se move para a esquerda conforme mostrado pela seta, ou seja, o próximo pixel está vazio, sua cor é $ 0. Se o jogador continuar a se mover nessa direção por mais de um turno, ele colidirá com uma parede (cor $ F) e quebrará.
Indo além
O algoritmo para determinar o próximo pixel usando matemática montadora calculou rapidamente o endereço de memória de um pixel acima, abaixo, à esquerda ou à direita do pixel atual. Como qualquer pixel na tela era um endereço na memória, o algoritmo simplesmente calculou um novo endereço para ler. E quando o ciclo de luz saiu da tela, o algoritmo determinou um local na memória do sistema para verificar a colisão com uma parede. Isso significava que o ciclo de luz agora estava atravessando a memória do sistema, ativando bits inutilmente e "quebrando" na memória.
Gravar em locais aleatórios na memória do sistema não é uma decisão arquitetônica inteligente. Sem surpresa, o jogo travou por causa disso. Um jogador humano não anda às cegas e normalmente cai de imediato, o que limita o âmbito dos problemas do sistema. E a IA não tem essa fraqueza. O computador verifica instantaneamente as posições ao seu redor para determinar se ele bate em uma parede e muda de direção. Ou seja, na visão do computador, a memória do sistema não era diferente da memória da tela. Como Marco descreveu:
, , . , , 0. «» , . «», - - , , — . , - , .
Como resultado, não apenas recriamos a corrida do ciclo de luz do filme, mas também a própria fuga. Como no filme, a fuga teve grandes consequências.
Isso é difícil de repetir hoje, uma vez que os sistemas operacionais adquiriram memória protegida. Mas ainda estou me perguntando se existem programas como o Tron que estão tentando escapar de seus "espaços protegidos" na tentativa de impedir que o código rebelde da IA assuma o controle do Pentágono.
Acho que, para descobrir, precisamos esperar pela invenção da digitalização da consciência.
Sente-se para fazer o login
Todo programador sabe que depurar é difícil. Embora, para depuradores excelentes, o trabalho pareça enganosamente simples. Programadores perturbados descrevem um bug que passam horas detectando, o mestre faz algumas perguntas e, depois de alguns minutos, os programadores veem o código defeituoso na frente deles. Um especialista em depuração não esquece que sempre há uma explicação lógica, não importa o quão misterioso o sistema pareça à primeira vista.
Essa atitude é ilustrada por uma história que aconteceu no IBM Yorktown Heights Research Center. O programador instalou recentemente uma nova estação de trabalho. Tudo estava bem quando ele estava sentado em frente ao computador, mas ele não conseguia fazer o login enquanto estava de pé. Esse comportamento sempre foi reproduzido: o programador sempre logava sentado, mas não conseguia nem uma vez em pé.
Muitos de nós apenas sentamos lá e se perguntaram. Como o computador poderia saber se eles estavam em frente a ele ou sentados? No entanto, bons depuradores sabem que deve haver um motivo. A primeira coisa que vem à mente é a eletricidade. Fio quebrado sob o tapete ou eletricidade estática? Mas os problemas elétricos raramente são reproduzidos 100% do tempo. Um dos colegas finalmente fez a pergunta certa: como o programador fez login enquanto estava sentado e em pé? Tente você mesmo.
O motivo era o teclado: os dois botões estavam invertidos. Quando o programador estava sentado, ele discou às cegas e o problema passou despercebido. E quando ele se levantou, ficou confuso, ele procurou por botões e os apertou. Armado com esta dica e uma chave de fenda, o especialista em depuração trocou os botões e tudo deu certo.
O sistema bancário implantado em Chicago funcionou bem por muitos meses. Mas ele parou inesperadamente quando foi usado pela primeira vez para processar dados internacionais. Os programadores vasculharam o código por dias, mas não conseguiram encontrar um único comando que levasse ao encerramento do programa. Quando examinaram mais de perto seu comportamento, descobriram que o programa seria encerrado se os dados do Equador fossem inseridos nele. A análise mostrou que quando o usuário digitou o nome da capital (Quito), o programa interpretou como um comando de saída!
Um dia Bob Martin encontrou um sistema que "funcionava uma vez, duas vezes". Ele tratou a primeira transação corretamente e houve pequenos problemas em todas as transações subsequentes. Quando o sistema foi reinicializado, ele novamente processou corretamente a primeira transação e falhou em todas as subsequentes. Quando Bob descreveu esse comportamento como "executando uma vez duas vezes", os desenvolvedores imediatamente perceberam que precisavam procurar uma variável que foi inicializada corretamente quando o programa foi carregado, mas não foi redefinida após a primeira transação. Em todos os casos, as perguntas certas permitiram que programadores sábios identificassem rapidamente erros desagradáveis: “O que você fazia de maneira diferente quando estava de pé e sentado? Mostre-me como você faz o login em ambos os casos "," O que exatamente você inseriu antes do final do programa? " “O programa funcionou corretamente antes do início dos travamentos? Quantas vezes?"
Rick Lemons disse que a melhor lição que aprendeu sobre depuração foi quando observou a atuação do mágico. Ele havia feito uma dúzia de truques impossíveis, e Lemons achava que ele acreditava nisso. Ele então lembrou a si mesmo que o impossível não é possível e testou todos os truques para provar sua óbvia inconsistência. Limões começou com o que era uma verdade inabalável - as leis da física, e a partir delas ele começou a buscar explicações simples para cada truque. Essa atitude faz do Lemons um dos melhores depuradores que conheci.
O melhor livro de depuração, na minha opinião, é The Medical Detectives, escrito por Berton Roueche e publicado pela Penguin em 1991. Os heróis do livro depuram sistemas complexos, de uma pessoa moderadamente doente a cidades muito doentes. Os métodos de solução de problemas usados ali podem ser usados diretamente na depuração de sistemas de computador. Essas histórias reais são tão fascinantes quanto qualquer ficção.
O Caso de Email 500 Milhas
Aqui está uma situação que parecia inconcebível ... Quase me recusei a falar sobre isso porque é uma ótima bicicleta para conferências. Ajustei ligeiramente a história para proteger o culpado, para descartar detalhes irrelevantes e chatos e, no geral, para tornar a história mais envolvente.
Vários anos atrás, eu mantinha um sistema de e-mail no campus. O chefe do departamento de estatística me ligou.
- Temos um problema com o envio de cartas.
- Qual é o problema?
“Não podemos enviar cartas a mais de 500 milhas.
Engasguei com meu café.
- Não entendi.
“Não podemos enviar cartas do departamento a mais de 500 milhas. Na verdade, um pouco mais longe. Aproximadamente 520 milhas. Mas esse é o limite.
“Hmm ... Na verdade, o e-mail não funciona assim”, respondi, tentando controlar o pânico em minha voz. Você não pode mostrar pânico em uma conversa com o chefe de um departamento, mesmo um como o de estatística. - Por que você decidiu que não pode enviar cartas a mais de 500 milhas?
“Eu não decidi ,” ele respondeu pesadamente. - Veja, quando percebemos o que estava acontecendo há poucos dias ...
- Você esperou alguns DIAS? Eu o interrompi com a voz trêmula. - E você não podia mandar cartas todo esse tempo?
- Podemos enviar. Só não mais ...
”“ Quinhentas milhas, sim, ”eu terminei por ele. - Claro. Mas por que você não ligou antes?
“Bem, até este ponto não tínhamos dados suficientes para ter certeza do que estava acontecendo.
Exatamente, este é o chefe das estatísticas .
- De qualquer forma, pedi a um dos geoestatísticos que trabalhasse com isso ...
- Geoestatísticos ...
- Sim, e ela fez um mapa mostrando o raio dentro do qual podemos enviar cartas, pouco mais de 500 milhas. Existem vários lugares nesta zona onde nossas cartas não chegam de forma alguma ou periodicamente, mas fora do raio não podemos enviar nada.
“Entendo,” eu disse, e coloquei minha cabeça em minhas mãos. - Quando isso começou? Você disse isso há alguns dias, mas não alteramos nada em seus sistemas.
- Um consultor veio, corrigiu e reinicializou nosso servidor. Mas liguei para ele e ele disse que não mexeu no sistema de correio.
“Ok, deixe-me dar uma olhada e ligar de volta”, respondi, mal acreditando que estava participando de tal coisa. Hoje não era primeiro de abril. Tentei me lembrar se alguém me devia uma pegadinha.
Entrei no servidor do departamento e enviei alguns e-mails de verificação. Isso aconteceu no Triângulo de Pesquisa da Carolina do Norte, e a carta chegou à minha caixa de correio sem problemas. O mesmo aconteceu com as cartas enviadas para Richmond, Atlanta e Washington. Também foi enviada uma carta a Princeton (400 milhas).
Mas então enviei uma carta para Memphis (600 milhas). Não veio. Em Boston, não aconteceu. Em Detroit, não aconteceu. Peguei minha agenda e comecei a enviar cartas por meio dela. Veio para Nova York (420 milhas), mas não veio para Providence (580 milhas).
Comecei a duvidar de minha sanidade. Escreveu para um amigo na Carolina do Norte cujo provedor estava em Seattle. Felizmente, a carta não chegou. Se o problema fosse com a localização dos destinatários, não com seus servidores de e-mail, provavelmente eu teria chorado.
Depois de descobrir que o problema existia (incrivelmente) e era reproduzível, comecei a analisar o arquivo sendmail.cf. Ele parecia bem. Como sempre. Eu comparei com sendmail.cf em meu diretório inicial. Não houve diferença - foi o arquivo que escrevi. E eu tinha certeza de que não incluí a opção
FAIL_MAIL_OVER_500_MILES. Confuso, enviei um telnet à porta SMTP. O servidor respondeu alegremente com um banner Sendmail da SunOS.
Espere ... o banner Sendmail do SunOS? Na época, a Sun ainda distribuía o Sendmail 5 com seu sistema operacional, embora o Sendmail 8 já estivesse totalmente dopado. Como eu era um bom administrador de sistema, introduzi o Sendmail 8 como o padrão. Além disso, como eu era um bom administrador de sistemas, escrevi sendmail.cf, que usava as opções longas e legais de autodocumentação e nomes de variáveis disponíveis no Sendmail 8, em vez dos códigos de pontuação criptografados usados no Sendmail 5.
Tudo se encaixou. e engasguei com meu café já resfriado novamente. Parece que quando o consultor "corrigiu o servidor", ele atualizou a versão SunOS a partir da qual lançou uma versão mais antiga do Sendmail. Felizmente, o arquivo sendmail.cf sobreviveu, mas agora não correspondia.
Descobriu-se que o Sendmail 5 - pelo menos a versão fornecida pela Sun que tinha uma série de melhorias - poderia funcionar com sendmail.cf para Sendmail 8, porque a maioria das regras eram as mesmas. Mas novas opções de configuração longas agora não foram reconhecidas e descartadas. E como não havia padrões no binário Sendmail para a maioria deles, o programa não encontrou nenhum valor adequado em sendmail.cf e os redefiniu para zero.
Um desses valores zerados era o tempo limite de conexão com um servidor SMTP remoto. Após alguma experimentação, descobriu-se que, nesta máquina em particular, sob carga normal, um tempo limite zero leva a uma desconexão em pouco mais de três milissegundos.
Na época, a rede do campus era totalmente baseada em switch. O pacote de saída não foi atrasado até chegar ao roteador do outro lado via POP. Ou seja, a duração de uma conexão com um host remoto com carga fraca em uma rede vizinha dependia principalmente da distância percorrida na velocidade da luz, e não de atrasos aleatórios pelos roteadores.
Sentindo-me um pouco tonto, entrei na linha de comando:
$ units
1311 units, 63 prefixes
You have: 3 millilightseconds
You want: miles
* 558.84719
/ 0.0017893979
"500 milhas ou mais."
Continua.