Introdução
Olá, Habr!
Muitas pessoas gostaram da parte anterior, então eu novamente peguei metade da documentação do boost e encontrei algo sobre o que escrever. É muito estranho que não haja tanta empolgação em torno de boost.compute quanto em torno de boost.asio. Afinal, o suficiente, esta biblioteca é multiplataforma e também fornece uma interface conveniente (dentro da estrutura de c ++) para interagir com a computação paralela na GPU e CPU.
Todas as partes
- Parte 1
- Parte 2
Conteúdo
- Operações assíncronas
- Funções personalizadas
- Comparação da velocidade de diferentes dispositivos em diferentes modos
- Conclusão
Operações assíncronas
Parece muito mais rápido? Uma maneira de acelerar seu trabalho com contêineres no namespace de computação é usar funções assíncronas. Boost.compute nos fornece várias ferramentas. Destas, a classe compute :: future para controlar o uso de funções e as funções copy_async (), fill_async () para copiar ou preencher o array. Claro, também existem ferramentas para trabalhar com eventos, mas não há necessidade de considerá-las. O seguinte será um exemplo de como usar todos os itens acima:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
Não há nada de especial para explicar aqui. As três primeiras linhas são a inicialização padrão das classes requeridas, depois dois vetores para cópia, um vetor para preenchimento, a variável do qual preencherá o vetor anterior e diretamente as funções para preenchimento e cópia, respectivamente. Em seguida, esperamos sua execução.
Para quem trabalhou com std :: future da STL, tudo é igual aqui, só que em um namespace diferente e não há analogia com std :: async ().
Funções personalizadas para cálculos
Na parte anterior, eu disse que explicarei como usar meus próprios métodos para processar um conjunto de dados. Eu contei 3 maneiras de fazer isso: usar uma macro, usar make_function_from_source <> () e usar uma estrutura especial para expressões lambda.
Vou começar com a primeira opção - uma macro. Primeiro, anexarei um código de amostra e depois explicarei como funciona.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
O primeiro argumento é o tipo do valor de retorno, depois o nome da função, seus argumentos e o corpo da função. Ainda sob o nome add, esta função pode ser usada, por exemplo, na função compute :: transform (). O uso dessa macro é muito semelhante a uma expressão lambda regular, mas verifiquei que não funcionam.
O segundo método e provavelmente o mais difícil é muito semelhante ao primeiro. Eu olhei para o código da macro anterior e descobri que ela usa o segundo método.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Aqui tudo é mais óbvio do que pode parecer à primeira vista, a função make_function_from_source () usa apenas dois argumentos, um dos quais é o nome da função e o segundo é sua implementação. Depois que uma função é declarada, ela pode ser usada da mesma maneira que após uma implementação de macro.
Bem, a última opção é uma estrutura de expressão lambda. Exemplo de uso:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
Como quarto argumento, indicamos que queremos multiplicar cada elemento do primeiro vetor por 2, tudo é bastante simples e é feito no lugar.
As expressões booleanas podem ser especificadas da mesma maneira. Por exemplo, no método compute :: count_if ():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Assim, contamos todos os números pares no array, counter será igual a um.
Comparação da velocidade de diferentes dispositivos em diferentes modos
Bem, a última coisa que eu gostaria de escrever neste artigo é uma comparação da velocidade de processamento de dados em diferentes dispositivos e em diferentes modos (apenas para a CPU). esta comparação provará quando faz sentido usar GPUs para computação e computação paralela em geral.
Vou testar assim: usando compute para todos os dispositivos, chamarei a função compute :: sort () para classificar um array de 100 milhões de valores float. Para testar o modo de thread único, chame std :: sort em uma matriz do mesmo tamanho. Para cada dispositivo, anotarei o tempo em milissegundos usando a biblioteca padrão chrono e emitirei tudo para o console.
O resultado é o seguinte:

Agora farei o mesmo apenas para mil valores. Desta vez, o tempo será em microssegundos.

Desta vez, o processador no modo de thread único estava à frente de todos. A partir disso, concluímos que esse tipo de operação só vale a pena quando se trata de realmente big data.
Eu gostaria de fazer mais alguns testes, então vamos fazer um teste para calcular o cosseno, a raiz quadrada e o quadrado.
No cálculo do cosseno, a diferença é muito grande (a GPU roda 60 vezes mais rápido do que a CPU em um thread).
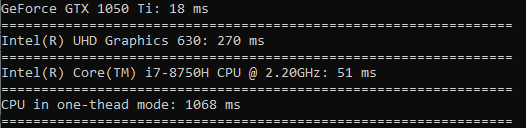
A raiz quadrada é calculada quase com a mesma velocidade da classificação.
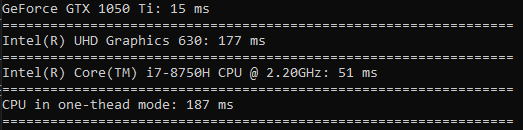
O tempo gasto na quadratura é ainda menos diferente do que na classificação (a GPU é apenas 3,5 vezes mais rápida).

Conclusão
Então, depois de ler este artigo, você aprendeu como usar funções assíncronas para copiar arrays e preenchê-los. Aprendemos como você pode usar suas próprias funções para realizar cálculos nos dados. E também viu claramente quando vale a pena usar uma GPU ou CPU para computação paralela e quando você pode sobreviver com um thread.
Eu ficaria feliz em receber um feedback positivo, obrigado pelo seu tempo!
Boa sorte a todos!