
A equipe Mail.ru Cloud Solutions traduziu um ensaio resumido de Kevin Wu , que discute o que a indústria farmacêutica e de saúde já alcançou usando inteligência artificial e aprendizado de máquina, e quando novas tecnologias ajudarão a encontrar drogas de todas as doenças.
Por que pode parecer que não há progresso
Algumas pessoas expressam sua frustração com a vida mais ou menos assim: "Se este é o futuro, onde está meu jetpack?" À primeira vista, esse desejo por um futuro retro parece estranho em uma era de computação onipresente, células programáveis e uma exploração espacial ressurgente . Mas, para alguns, esse futurismo nostálgico se mantém surpreendentemente bem. Eles se apegam a previsões que parecem estranhas em retrospecto, ignorando a realidade surpreendente que ninguém poderia ter previsto.
Quem teria pensado que graças ao aprendizado profundo seríamos capazes de prever as propriedades de drogas que ainda não existem? Isso é de extrema importância para a indústria farmacêutica.
No que diz respeito à inteligência artificial, as reclamações podem ser mais ou menos assim: “Quase oito anos se passaram desde a invenção da rede neural AlexNet [ aprox. tradutor : em 2012, Aleksey Krizhevsky publicou o projeto da rede neural convolucional AlexNet, que venceu a competição ImageNet por uma grande margem], bem, onde está meu carro autônomo? " Na verdade, pode parecer que as expectativas de meados da década de 2010 não foram atendidas. Entre os pessimistas, as previsões da próxima estagnação na pesquisa de IA estão ganhando impulso .
O objetivo deste ensaio é discutir o progresso significativo do aprendizado de máquina no desafio da descoberta de medicamentos no mundo real. Quero lembrá-lo de outro velho ditado, desta vez de pesquisadores de IA. Para reformular um pouco, soa assim: "IA é chamada de IA até que funcione, então é apenas software."
O que até alguns anos atrás era considerado pesquisa fundamental de ponta em aprendizado de máquina agora é frequentemente referido como “apenas ciência de dados ” (ou mesmo análise) - e está revolucionando a indústria farmacêutica. Há uma chance sólida de que o uso do aprendizado profundo para descobrir drogas mude radicalmente nossas vidas para melhor.
Visão computacional e aprendizado profundo em imagens biomédicas
Assim que os cientistas obtiveram acesso a computadores e a capacidade de fazer upload de imagens, eles imediatamente tentaram processá-los. Basicamente, estamos falando de imagens biomédicas: radiografias, ultrassom e resultados de ressonância magnética. Nos dias da boa e velha IA, o processamento geralmente significava inferir manualmente afirmações lógicas com base em características simples, como contornos e brilho.
A década de 1980 viu uma mudança para algoritmos de aprendizado de máquina supervisionado, mas eles ainda dependiam de tags configuradas manualmente. Modelos de aprendizagem supervisionada simples (como regressão linear ou aproximação polinomial) são treinados em recursos extraídos por algoritmos como SIFT (Scale Invariant Feature Transformation) e HOG (Directional Gradient Histogram). Não deve ser surpresa que os desenvolvimentos que levaram à aplicação prática do aprendizado profundo hoje começaram há décadas.
As redes neurais convolucionais foram usadas pela primeira vez para a análise de imagens biomédicas em 1995, quando Law e colegasapresentou um modelo para o reconhecimento de tumores cancerígenos nos pulmões em fluorogramas. O método deles era um pouco diferente do que estamos acostumados hoje, a derivação do resultado demorava cerca de 15 segundos, mas o conceito era essencialmente o mesmo - com aprendizagem por retropropagação até os núcleos convolucionais da rede neural. Seu modelo envolvia duas camadas ocultas, enquanto as arquiteturas de rede profunda populares de hoje geralmente têm uma centena ou mais camadas.
Avance para 2012. As redes neurais convolucionais causaram grande impacto com a chegada do sistema AlexNet, que levou a um salto no desempenho do agora famoso conjunto de dados ImageNet. O sucesso da AlexNet, uma rede com cinco camadas convolucionais e três fortemente acopladas treinadas em GPUs de jogos, tornou-se tão famoso no aprendizado de máquina que as pessoas agora estão falando sobre “Moments of ImageNet ”em diferentes nichos de aprendizado de máquina e IA.
Por exemplo, "o processamento de linguagem natural pode ter sobrevivido ao seu momento ImageNet com o desenvolvimento de grandes transformadores em 2018" ou "o aprendizado por reforço ainda está aguardando seu momento ImageNet."
Quase dez anos se passaram desde AlexNet. A visão computacional e os modelos de aprendizado profundo estão melhorando gradualmente. Os aplicativos foram além da classificação. Hoje eles aprenderam como segmentar imagens, estimar a profundidade e reconstruir automaticamente cenas 3D a partir de várias imagens 2D. E esta não é uma lista completa de suas capacidades.
O aprendizado profundo para análise de imagens biomédicas se tornou uma área quente de pesquisa. Um efeito colateral é um aumento inevitável do ruído. Publicado em 2019aproximadamente 17.000 artigos científicos sobre aprendizagem profunda . Claro, nem todos valem a pena ler. É provável que muitos pesquisadores ajustem demais os modelos em seus modestos conjuntos de dados.
A maioria deles não fez contribuições à ciência básica ou ao aprendizado de máquina. A paixão pelo aprendizado profundo apoderou-se de pesquisadores acadêmicos que anteriormente não demonstravam interesse nele, e por um bom motivo. Ele pode fazer o que os algoritmos clássicos de visão computacional fazem (veja o teorema da aproximação universal de Tsybenko e Hornik), e freqüentemente o faz mais rápido e melhor, poupando os engenheiros do tedioso projeto manual de cada nova aplicação.
Uma rara oportunidade de lutar contra doenças "negligenciadas"
Isso nos leva ao tópico da descoberta de medicamentos hoje, uma indústria que está prestes a sofrer uma grande sacudida. As empresas farmacêuticas e seus contratados adoram reiterar os enormes custos de colocar um novo medicamento no mercado. Esses custos são em grande parte devido ao fato de que muitos medicamentos levam muito tempo para serem estudados e testados antes de serem consumidos.
O custo de desenvolvimento de um novo medicamento pode chegar a US $ 2,5 bilhões ou mais . Às vezes, devido ao alto custo e à lucratividade relativamente baixa, vários trabalhos sobre certas classes de medicamentos são deixados para segundo plano .
Também está levando a um aumento na incidência na categoria apropriadamente chamada de "doenças negligenciadas", incluindo um número desproporcional de doenças tropicais.que afligem pessoas nos países mais pobres e são consideradas desvantajosas para o tratamento e doenças raras com baixas taxas de incidência. Relativamente poucas pessoas sofrem de cada um deles, mas o número total de pessoas com todas as doenças raras é bastante grande. Estima-se que cerca de 300 milhões de pessoas. E mesmo esse número pode estar subestimado devido à avaliação sombria de especialistas: cerca de 30% dos portadores de uma doença rara não vivem até cinco anos.
" Cauda longa»As doenças raras têm potencial significativo para melhorar a vida de um grande número de pessoas, e é aqui que o aprendizado de máquina e o big data vêm em seu auxílio. O ponto cego para doenças raras (órfãs) que não têm um tratamento oficialmente aprovado abre uma oportunidade para inovação de pequenas equipes de biólogos e desenvolvedores de aprendizado de máquina.
Uma dessas startups em Salt Lake City, Utah, está tentando fazer exatamente isso. Os fundadores da Recursion Pharmaceuticals veem a falta de medicamentos para doenças raras como uma lacuna na indústria farmacêutica. Eles recebem enormes quantidades de dados analisando os resultados de microscopia e testes de laboratório. Com o auxílio das redes neurais, é possível identificar as características das doenças e buscar métodos de tratamento.
No final de 2019, a empresa realizou milhares de experimentos e coletou mais de 4 petabytes de informações. Eles postaram um pequeno subconjunto desses dados (46 GB) para a competição NeurIps 2019, você pode baixá-lo do site do RxRx e experimentar por conta própria.
O fluxo de trabalho descrito neste artigo é amplamente baseado nas informações dos white papers [ pdf ] da Recursion Pharmaceuticals, mas essa abordagem pode servir de inspiração para outras áreas.
Outras startups no campo incluem Bioage Labs (doenças do envelhecimento), Notable Labs (oncologia) e TwoXAR.(várias doenças para as quais não existem opções de tratamento). Normalmente, as startups jovens estão envolvidas em técnicas inovadoras de processamento de dados e aplicam uma variedade de métodos de aprendizado de máquina, além ou em vez do aprendizado profundo com visão computacional.
A seguir, descreverei o processo de análise de imagens e como o aprendizado profundo se encaixa no fluxo de trabalho de descoberta de medicamentos para doenças raras. Veremos um processo de alto nível aplicável a uma variedade de outras áreas da descoberta de medicamentos.
Por exemplo, pode ser facilmente usado para rastrear drogas contra o câncer quanto aos seus efeitos na morfologia das células tumorais. Talvez até para analisar a resposta de células de pacientes específicos a diferentes opções de medicamentos. Esta abordagem usa conceitos da análise de componente principal não linear, hashing semântico [ pdf ] e a boa e velha classificação de imagens de redes neurais convolucionais.
Classificação em ruído morfológico
A biologia é uma bagunça. Portanto, a microscopia multiparâmetros de alto rendimento é uma fonte de frustração constante para os biólogos celulares. As imagens resultantes diferem muito de um experimento para o outro. Flutuações de temperatura, tempo de exposição, quantidade de reagentes, entre outros, levam a alterações que não estão relacionadas ao fenótipo estudado ou à ação do medicamento e, portanto, a erros nos resultados obtidos.
Talvez o controle do clima em um laboratório funcione de maneira diferente no verão e no inverno? Talvez alguém tenha almoçado ao lado das lâminas antes de inseri-las no microscópio? Talvez o fornecedor de um dos ingredientes do meio de cultura tenha mudado? Ou o fornecedor mudou de fornecedor? Um grande número de variáveis afeta o resultado de um experimento. Rastrear e destacar ruído não intencional é um dos principais desafios na descoberta de medicamentos baseada em dados.
As imagens microscópicas podem ser muito diferentes nos mesmos experimentos. O brilho da imagem, a forma das células, a forma das organelas e muitas outras características mudam devido aos efeitos fisiológicos correspondentes ou erros aleatórios.
Portanto, as imagens na figura abaixo são obtidas a partir do mesmoum conjunto disponível publicamente de micrografias de células cancerosas metastáticas compiladas por Scott Wilkinson e Adam Marcus. Variações na saturação e morfologia devem refletir a incerteza dos dados experimentais. Eles são criados pela introdução de distorções no processamento. É uma espécie de análogo de aumento, que os pesquisadores usam para regularizar redes neurais profundas em problemas de classificação. Portanto, não deve ser surpresa que a capacidade de generalizar grandes modelos para grandes conjuntos de dados seja uma escolha lógica para procurar características fisiologicamente significativas em um mar de ruído.
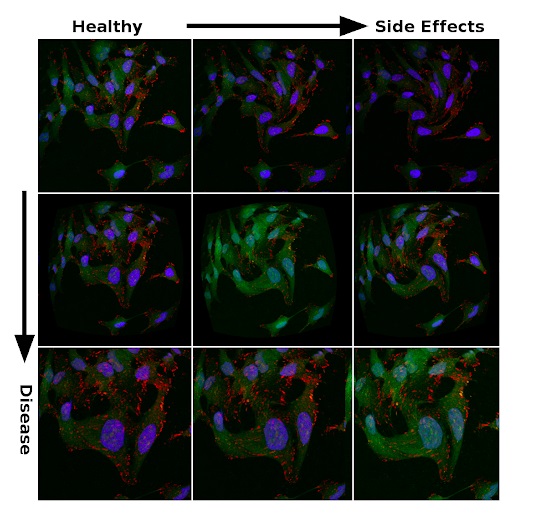
Sinais de eficácia do tratamento e efeitos colaterais entre dados ruidosos
A principal causa de doenças raras é geralmente uma mutação genética. Para construir modelos de cura para essas doenças, é necessário entender os efeitos de uma ampla gama de mutações e sua relação com os diferentes fenótipos. Para comparar com eficácia os possíveis tratamentos para uma doença rara específica, as redes neurais são treinadas com base em milhares de mutações diferentes.
Essas mutações podem ser imitadas pela supressão da expressão gênica usando pequenos RNAs de interferência(siRNA). É um pouco como os bebês agarram seus tornozelos: mesmo se você puder correr rápido, sua velocidade diminuirá drasticamente com sua sobrinha ou sobrinho pendurado em cada perna. O siRNA funciona de maneira semelhante: uma pequena sequência de RNAs interferentes adere às partes correspondentes do RNA mensageiro de genes específicos, impedindo sua expressão total.
Ao aprender com milhares de mutações em vez de um modelo celular singular de uma doença específica, a rede neural aprende a codificar fenótipos em um espaço oculto multidimensional. O código resultante permite avaliar medicamentos por sua capacidade de aproximar o fenótipo da doença de um fenótipo saudável, cada um representado por um conjunto multidimensional de coordenadas. Da mesma forma, os efeitos colaterais dos medicamentos podem ser embutidos na representação codificada do fenótipo, e os medicamentos são avaliados não apenas quanto ao desaparecimento dos sintomas da doença, mas também para minimizar os efeitos colaterais prejudiciais.

O diagrama reflete o efeito do tratamento no modelo celular da doença (representado por um ponto vermelho). O tratamento é o movimento do fenótipo codificado para mais perto do fenótipo saudável (ponto azul). Esta é uma representação 3D simplificada da codificação fenotípica em um espaço oculto multidimensional
Os modelos de aprendizagem profunda usados para este fluxo de trabalho são muito semelhantes a outros problemas de classificação com um grande conjunto de dados, embora se você estiver acostumado a trabalhar com um pequeno número de categorias, como em conjuntos de dados CIFAR-10 e CIFAR-100, você não se acostumará imediatamente às milhares de marcas de classificação diferentes.
Além disso, este método de descoberta de medicamentos baseado em imagem funciona bem com a mesma arquitetura DenseNet ou ResNet com centenas de camadas, o que fornece desempenho ideal em conjuntos de dados como ImageNet.
Os valores de ativação da camada codificados em um espaço multidimensional refletem o fenótipo, a patogênese da doença, as relações entre os tratamentos, os efeitos colaterais e outras doenças. Portanto, todos esses fatores podem ser analisados por deslocamento no espaço codificado. Este código fenotípico pode ser sujeito a regularização especial (por exemplo, minimizando a covariância entre diferentes ativações de camadas) para reduzir as correlações de codificação ou para outros fins.
A figura abaixo mostra um modelo simplificado. As setas pretas representam as operações de convolução + pooling. As linhas azuis representam conexões estreitas. Para simplificar, o número de camadas é reduzido e as conexões residuais não são mostradas.
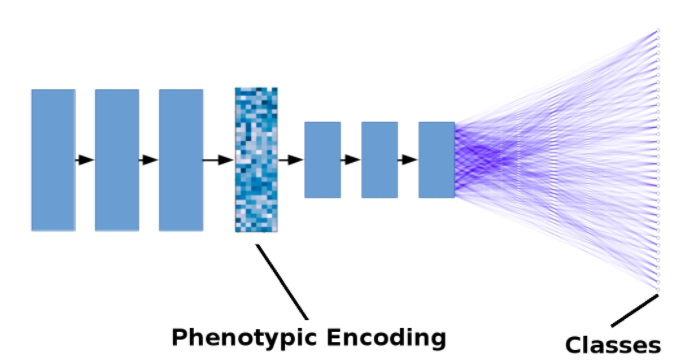
Ilustração simplificada de um modelo de aprendizado profundo para descoberta de drogas
O futuro da aprendizagem profunda na descoberta de medicamentos e na indústria farmacêutica
O alto custo de trazer novos medicamentos ao mercado tem levado as empresas farmacêuticas a frequentemente optarem por resultados de mercado em vez de pesquisar medicamentos para doenças graves. Equipes menores de analistas de dados em startups estão mais bem equipadas para inovar nessa área, enquanto doenças negligenciadas e raras fornecem uma oportunidade de entrar no mercado e demonstrar o valor do aprendizado de máquina.
A eficácia desta abordagem foi comprovada. Estamos vendo um progresso significativo na pesquisa e vários medicamentos já estão na primeira fase de testes clínicos. Por exemplo, equipes de apenas algumas centenas de cientistas e engenheiros em empresas como a Recursion Pharmaceuticals conseguem isso. Outras startups estão por perto: TwoXAR tem vários candidatos a medicamentos em testes pré-clínicos em outras categorias de doenças.
Pode-se esperar que a abordagem de aprendizado profundo e visão computacional para o desenvolvimento de medicamentos tenha um impacto significativo nas grandes empresas farmacêuticas e na área de saúde em geral. Em breve veremos como isso afetará o desenvolvimento de novos tratamentos para doenças comuns (incluindo doenças cardíacas e diabetes), bem como doenças raras que permaneceram fora de vista até hoje.
O que mais ler sobre o assunto: