
Uma das tarefas de um exame fonoscópico é estabelecer a autenticidade e autenticidade de uma gravação de áudio - em outras palavras, identificar sinais de edição, distorção e alteração da gravação. Tivemos a tarefa de conduzi-lo para estabelecer a autenticidade dos registros - para determinar que nenhuma influência foi exercida sobre os registros. Mas como analisar milhares e até centenas de milhares de gravações de áudio?
Os métodos de IA vêm em nosso socorro, bem como um utilitário para trabalhar com áudio, do qual falamos em um artigo no site da NewTechAudit "PROCESSANDO ÁUDIO COM FFMPEG" .
Como aparecem as mudanças no áudio? Como você distingue entre um arquivo modificado e um arquivo intocado?
Existem vários desses sinais, e o mais simples é identificar as informações sobre a edição de um arquivo e analisar a data de sua modificação. Esses métodos são facilmente implementados por meio do próprio sistema operacional, portanto, não vamos nos alongar sobre esses métodos. Mas as alterações podem ser feitas por um usuário mais qualificado, que pode ocultar ou alterar as informações sobre a edição, neste caso, métodos mais complexos são utilizados, por exemplo:
- mudança de contornos;
- alterar o perfil espectral do áudio gravado;
- o aparecimento de pausas;
- e muitos outros.
E todos esses métodos complicados de sonorização são executados por especialistas especialmente treinados - fonoscopistas que usam software especializado como Praat, Speech Analyzer SIL, ELAN, muitos dos quais são pagos e exigem qualificações suficientemente altas para usar e interpretar os resultados.
Os especialistas analisam o áudio usando um perfil espectral, nomeadamente analisando os seus coeficientes cepstrais. Utilizaremos a experiência de especialistas e ao mesmo tempo utilizaremos o código pronto, adaptando-o à nossa tarefa.
Portanto, há muitas mudanças que podem ser feitas, como podemos escolher?
Dos possíveis tipos de alterações que podem ser feitas nos arquivos de áudio, estamos interessados em cortar uma parte do áudio, ou cortar uma parte e, em seguida, substituir a parte original por uma parte da mesma duração - as chamadas alterações de cortar / copiar. editar arquivos em termos de redução de ruído, alteração da freqüência do tom e outros não trazem o risco de ocultar informações.
E como vamos identificar esses mesmos recortar / copiar? Eles devem ser comparados com algo?
É muito simples - com a ajuda do utilitário FFmpeg cortaremos uma parte de uma duração aleatória do arquivo e em um local aleatório, após o qual compararemos os espectrogramas cepstrais pequenos do arquivo original e o "cortado".
Código para exibi-los:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' Preparamos um conjunto de dados da fonte e cortamos os arquivos usando o comando do utilitário FFmpeg:
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav onde STARTTIME e ENDTIME são o início e o fim do fragmento cortado. E usando o comando:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavjunte a parte do arquivo para inserir part_1.wav com as partes originais (para agrupar comandos FFmpeg em python, consulte nosso artigo sobre FFmpeg).
Aqui estão os arquivos originais de espectrograma de giz que foram cortados do áudio de 0,2-2,5 segundos e espectrograma de giz dos arquivos que foram cortados do áudio de 0,2-2,5 segundos e, em seguida, inseridos nos fragmentos de áudio de uma duração semelhante a deste arquivo de áudio:
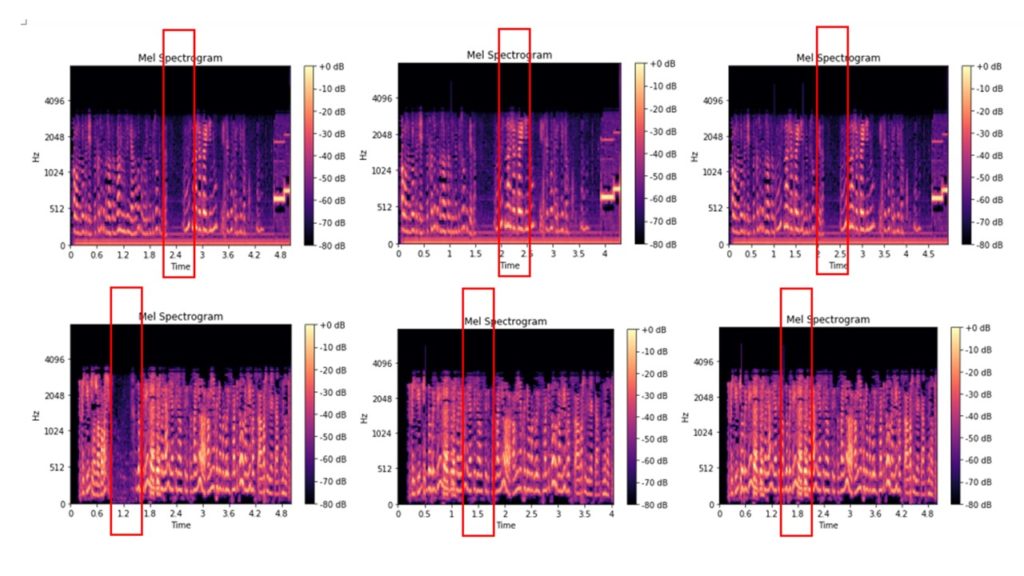
Alguns as imagens são distinguíveis até visualmente, outras parecem quase iguais. Distribuímos as imagens resultantes em pastas e as usamos como dados de entrada para treinar o modelo de classificação de imagens. Estrutura da pasta:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # Para nós, não faz diferença se o arquivo de áudio modificado foi adicionado ou encurtado - dividimos todos os resultados em bons, ou seja, arquivos sem alterações, e ruins. Assim, resolvemos o problema clássico de classificação binária. Vamos classificar usando redes neurais, pegaremos o código para trabalhar com uma rede neural pronta a partir de exemplos de trabalho com o pacote Keras.
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)Além disso, após o treinamento do modelo, realizamos a classificação com sua ajuda
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'Na saída, obtemos a classificação do arquivo de áudio - 'original' / 'corrompido', ou seja, o arquivo inalterado e os arquivos nos quais as alterações foram feitas.
Provamos mais uma vez que coisas de aparência complexa podem ser feitas de forma simples - não usamos o mecanismo mais difícil dos métodos de IA, soluções prontas e verificamos se há alterações no áudio. Bem, nós éramos os especialistas do detetive.