O objetivo deste artigo é falar sobre regressão linear, nomeadamente, recolher e mostrar as formulações e interpretações do problema de regressão em termos de análise matemática, estatística, álgebra linear e teoria da probabilidade. Embora os livros-texto estabeleçam esse tópico de maneira estrita e exaustiva, outro artigo de ciência popular não fará mal.
! Cuidado com o trânsito! O artigo contém um número notável de imagens para ilustrações, algumas em formato gif.
Conteúdo
- Introdução
- Método dos mínimos quadrados
- Regressão multilinear
- Base arbitrária
- Considerações finais
- Publicidade e conclusão
Introdução
Existem três conceitos semelhantes, três irmãs: interpolação, aproximação e regressão.
Eles têm um objetivo comum: de uma família de funções, escolha aquela que possui uma determinada propriedade.
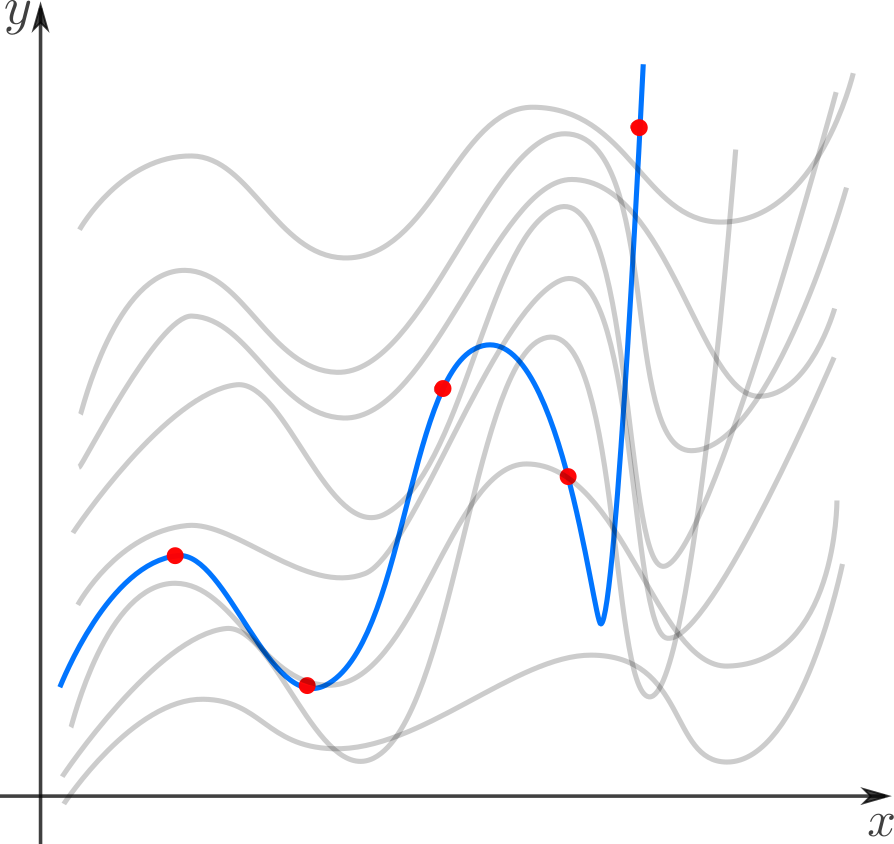
Interpolação- uma forma de selecionar de uma família de funções aquela que passa por determinados pontos A função é geralmente usada para calcular em pontos intermediários. Por exemplo, definimos manualmente a cor de vários pontos e queremos que as cores dos pontos restantes formem transições suaves entre os dados fornecidos. Ou definimos quadros-chave para a animação e queremos transições suaves entre eles. Exemplos clássicos: interpolação polinomial de Lagrange, interpolação spline, interpolação multidimensional (bilinear, trilinear, vizinho mais próximo, etc.). Existe também um conceito relacionado de extrapolação - prever o comportamento de uma função fora de um intervalo. Por exemplo, prever a taxa do dólar com base nas flutuações anteriores é uma extrapolação.
 Aproximação- uma forma de escolher de uma família de funções "simples" uma aproximação para uma função "complexa" em um segmento, enquanto o erro não deve exceder um certo limite. A aproximação é usada quando você precisa obter uma função semelhante a uma dada, mas mais conveniente para cálculos e manipulações (diferenciação, integração, etc.). Ao otimizar seções críticas do código, uma aproximação é frequentemente usada: se o valor de uma função é calculado muitas vezes por segundo e a precisão absoluta não é necessária, então um aproximador mais simples com um "custo" de cálculo menor pode ser dispensado. Exemplos clássicos incluem séries de Taylor em um segmento, aproximação polinomial ortogonal, aproximação de Padé, aproximação de seno de Bhaskar, etc.
Aproximação- uma forma de escolher de uma família de funções "simples" uma aproximação para uma função "complexa" em um segmento, enquanto o erro não deve exceder um certo limite. A aproximação é usada quando você precisa obter uma função semelhante a uma dada, mas mais conveniente para cálculos e manipulações (diferenciação, integração, etc.). Ao otimizar seções críticas do código, uma aproximação é frequentemente usada: se o valor de uma função é calculado muitas vezes por segundo e a precisão absoluta não é necessária, então um aproximador mais simples com um "custo" de cálculo menor pode ser dispensado. Exemplos clássicos incluem séries de Taylor em um segmento, aproximação polinomial ortogonal, aproximação de Padé, aproximação de seno de Bhaskar, etc.
 Regressão- uma forma de escolher de uma família de funções aquela que minimiza a função perda. Este último caracteriza o quanto a função de teste se desvia dos valores nos pontos dados. Se pontos são obtidos em um experimento, eles inevitavelmente contêm erro de medição, ruído, então é mais razoável exigir que a função transmita a tendência geral e não passe exatamente por todos os pontos. Em certo sentido, a regressão é um “ajuste de interpolação”: queremos desenhar a curva o mais próximo possível dos pontos e ainda mantê-la o mais simples possível para capturar a tendência geral. A função de perda (na literatura inglesa “função perda” ou “função custo”) é responsável pelo equilíbrio entre esses desejos conflitantes.
Regressão- uma forma de escolher de uma família de funções aquela que minimiza a função perda. Este último caracteriza o quanto a função de teste se desvia dos valores nos pontos dados. Se pontos são obtidos em um experimento, eles inevitavelmente contêm erro de medição, ruído, então é mais razoável exigir que a função transmita a tendência geral e não passe exatamente por todos os pontos. Em certo sentido, a regressão é um “ajuste de interpolação”: queremos desenhar a curva o mais próximo possível dos pontos e ainda mantê-la o mais simples possível para capturar a tendência geral. A função de perda (na literatura inglesa “função perda” ou “função custo”) é responsável pelo equilíbrio entre esses desejos conflitantes.
Neste artigo, veremos a regressão linear. Isso significa que a família de funções que escolhemos é uma combinação linear de funções de base predeterminadasf eu
f = ∑ i w i f i .
A regressão está conosco há muito tempo: o método foi publicado pela primeira vez por Legendre em 1805, embora Gauss o tenha abordado antes e usado com sucesso para prever a órbita do "cometa" (na verdade, um planeta anão) Ceres. Existem muitas variações e generalizações de regressão linear: LAD, Least Squares, Ridge Regression, Lasso Regression, ElasticNet e muitos outros.

Método dos mínimos quadrados
Vamos começar com o caso bidimensional mais simples. Vamos receber pontos no avião{ ( x 1 , y 1 ) , ⋯ , ( x N , y N ) } e estamos procurando por uma função afim
f ( x ) = a + b ⋅ x ,
 para que seu gráfico fique mais próximo dos pontos. Assim, nossa base consiste em uma função constante e uma linear( 1 , x ) .
para que seu gráfico fique mais próximo dos pontos. Assim, nossa base consiste em uma função constante e uma linear( 1 , x ) .
Como você pode ver na ilustração, a distância de um ponto a uma linha reta pode ser entendida de diferentes maneiras, por exemplo, geometricamente - é o comprimento de uma perpendicular. No entanto, no contexto da nossa tarefa, precisamos de uma distância funcional, não geométrica. Estamos interessados na diferença entre o valor experimental e a previsão do modelo para cadax i , então você precisa medir ao longo do eixoy .
A primeira coisa que vem à mente é tentar uma expressão que dependa dos valores absolutos das diferenças como uma função de perda| f ( x i ) - y i | ... A opção mais simples é a soma dos módulos de desvio∑ i | f ( x i ) - y i | resulta na regressão da Distância Mínima Absoluta (LAD).
No entanto, a função de perda mais popular é a soma dos quadrados dos desvios do regressante do modelo. Na literatura inglesa, é denominado Soma dos Erros Quadrados (SSE)
SSE(a,b)=SSres[iduals]=N∑i=1i2=N∑i=1(yi−f(xi))2=N∑i=1(yi−a−b⋅xi)2,

Essa escolha é principalmente conveniente: a derivada de uma função quadrática é uma função linear e as equações lineares são facilmente resolvidas. No entanto, indicarei ainda outras considerações em favor deSSE ( a , b ) .

Analise matemática
A maneira mais simples de encontrar argmin a , bSSE ( a , b ) - calcular derivadas parciais em relação aum eb , iguale-os a zero e resolva o sistema de equações lineares
∂∂ um SSE(a,b)= - 2 N ∑ i = 1 ( y i - a - b x i ) , ∂∂ b SSE(a,b)= - 2 N ∑ i = 1 ( y i - a - b x i ) x i .
0=-2N∑Eu=1(yEu-ˆuma-ˆbxEu),0=-2N∑Eu=1(yEu-ˆuma-ˆbxEu)xEu,
ˆuma=∑EuyEuN-ˆb∑EuxEuN,ˆb=∑EuxEuyEuN-∑EuxEu∑EuyEuN2∑Eux2EuN-(∑Eux2EuN)2...
Estatisticas
As fórmulas resultantes podem ser escritas de forma compacta usando estimadores estatísticos: média ⟨⋅⟩, variações σ⋅ (desvio padrão), covariância σ(⋅,⋅) e correlações ρ(⋅,⋅)
ˆuma=⟨y⟩-ˆb⟨x⟩,ˆb=⟨xy⟩-⟨x⟩⟨y⟩⟨x2⟩-⟨x⟩2...
ˆb=σ(x,y)σ2x,
ρ(x,y)=σ(x,y)σxσy
ˆb=ρ(x,y)σyσx...

y-⟨y⟩=ρ(x,y)σyσx(x-⟨x⟩)...
- a linha reta passa pelo centro de massa (⟨x⟩,⟨y⟩);
- se ao longo do eixo x por unidade de comprimento escolha σx, e ao longo do eixo y - σy, então o ângulo de inclinação da linha reta será de -45∘ antes 45∘... Isso se deve ao fato de que-1≤ρ(x,y)≤1...
Em segundo lugar, agora fica claro por que o método de regressão é chamado assim. Em unidades de desvio padrãoy desvia de sua média por menos de x, Porque |ρ(x,y)|≤1... Isso é chamado de regressão (do latim regressus - "retorno") em relação à média. Este fenômeno foi descrito por Sir Francis Galton no final do século 19 em seu artigo "Regressão à Mediocridade na Herança do Crescimento". O artigo mostra que as características (como altura) que se desviam muito da média raramente são herdadas. As características da prole parecem tender para a média - a natureza repousa sobre os filhos de gênios.
Ao elevar o coeficiente de correlação ao quadrado, obtemos o coeficiente de determinaçãoR=ρ2... O quadrado desta medida estatística mostra o quão bem o modelo de regressão se ajusta aos dados.R2igual a 1, significa que a função se ajusta perfeitamente a todos os pontos - os dados estão perfeitamente correlacionados. Pode ser provado queR2mostra quanto da variância nos dados é devido ao melhor modelo linear. Para entender o que isso significa, apresentamos as definições
Vardumatuma=1N∑Eu(yEu-⟨y⟩)2,Varres=1N∑Eu(yEu-modelo(xEu))2,Varreg=1N∑Eu(modelo(xEu)-⟨y⟩)2...
Varres - variação de resíduos, ou seja, variação de desvios do modelo de regressão - de yEu você precisa subtrair a previsão do modelo e encontrar a variação.
Varreg - variação da regressão, ou seja, variação das previsões do modelo de regressão em pontos xEu (observe que a média das previsões do modelo corresponde ⟨y⟩)

Vardumatuma=Varres+Varreg...
σ2dumatuma=σ2res+σ2reg...

Nós nos esforçamos para nos livrar da variabilidade associada ao ruído e deixar apenas a variabilidade que é explicada pelo modelo - queremos separar o joio do trigo. A extensão em que o melhor dos modelos lineares teve sucesso é evidenciada porR2igual a um menos a fração de variação do erro na variação total
R2=Vardumatuma-VarresVardumatuma=1-VarresVardumatuma
R2=VarregVardumatuma...
Teoria da probabilidade
Anteriormente, falamos da função de perda SSE(uma,b)por razões de conveniência, mas também pode ser alcançado usando a teoria da probabilidade e o método da máxima verossimilhança (MLM). Deixe-me relembrar brevemente sua essência. Suponha que temosNvariáveis aleatórias independentes distribuídas de forma idêntica (em nosso caso, resultados de medição). Conhecemos a forma da função de distribuição (por exemplo, a distribuição normal), mas queremos determinar os parâmetros que estão incluídos nela (por exemploµ e σ) Para fazer isso, você precisa calcular a probabilidade de obterNpontos de dados sob a suposição de parâmetros constantes, mas desconhecidos. Devido à independência das medidas, obtemos o produto das probabilidades de realização de cada dimensão. Se pensarmos no valor resultante como uma função de parâmetros (função de verossimilhança) e encontrarmos seu máximo, obteremos uma estimativa dos parâmetros. Freqüentemente, em vez da função de verossimilhança, eles usam seu logaritmo - é mais fácil diferenciá-lo, mas o resultado é o mesmo.
Voltemos ao problema de regressão simples. Digamos que os valoresx sabemos exatamente, mas em medição yhá ruído aleatório (propriedade exógena fraca ). Além disso, assumimos que todos os desvios da linha reta (propriedade de linearidade ) são causados por ruído com uma distribuição constante ( distribuição constante ). Então
y=uma+bx+ϵ,
ϵ∼N(0,σ2),p(ϵ)=1√2πσ2e-ϵ22σ2...

Com base nas premissas acima, escrevemos a função de probabilidade
eu(uma,b|y)=P(y|uma,b)=∏EuP(yEu|uma,b)=∏Eup(yEu-uma-bx|uma,b)==∏Eu1√2πσ2e-(yEu-uma-bx)22σ2=1√2πσ2e-∑Eu(yEu-uma-bx)22σ2==1√2πσ2e-SSE(uma,b)2σ2
eu(uma,b|y)=registroeu(uma,b|y)=-SSE(uma,b)+const...
(ˆuma,ˆb)=argmaxuma,beu(uma,b|y)=argminuma,bSSE(uma,b),
ϵ∼Laplace(0,α),peu(ϵ;µ,α)=α2e-α|ϵ-µ|
EeuUMAD(uma,b)=∑Eu|yEu-uma-bxEu|,
A abordagem que usamos nesta seção é possível. É possível obter o mesmo resultado usando propriedades mais gerais. Em particular, a propriedade de distribuição constante pode ser enfraquecida substituindo-a pelas propriedades de independência, constância de variação (homocedasticidade) e ausência de multicolinearidade. Além disso, em vez da estimativa MMP, você pode usar outros métodos, por exemplo, estimativa MMSE linear.
Regressão multilinear
Até agora, consideramos o problema de regressão para um recurso escalar x, no entanto geralmente o regressor é nvetor dimensional x... Em outras palavras, para cada dimensão, registramosnrecursos, combinando-os em um vetor. Neste caso, é lógico aceitar o modelo comn+1 funções de base independentes do argumento do vetor - n graus de liberdade correspondem n recursos e mais um - regressante y... A escolha mais simples são funções de base linear(1,x1,⋯,xn)... Quandon=1 nós temos a base já familiar (1,x)...
Então, queremos encontrar esse vetor (conjunto de coeficientes)W, o que
n∑j=0Wjx(Eu)j=W⊤x(Eu)≃yEu,Eu=1...N...
ˆW=argminWN∑Eu=1(yEu-W⊤x(Eu))2
X=(-x(1)⊤-⋯⋯⋯-x(N)⊤-)=(|||x0x1⋯xn|||)=(1x(1)1⋯x(1)n⋯⋯⋯⋯1x(N)1⋯x(N)n)...
XW≃y...
SSE(W)=‖y-XW‖2,W∈Rn+1;y∈RN,
ˆW=argminWSSE(W)=argminW(y-XW)⊤(y-XW)==argminW(y⊤y-2W⊤X⊤y+W⊤X⊤XW)...
∂SSE(W)∂W=-2X⊤y+2X⊤XW,
X⊤XˆW=X⊤y...
ˆW=(X⊤X)-1X⊤y=X+y,
X+=(X⊤X)-1X⊤
pseudo-inverso a X... O conceito de matriz pseudoinversa foi introduzido em 1903 por Fredholm e desempenhou um papel importante nas obras de Moore e Penrose.
Deixe-me lembrá-lo do que virarX⊤X e encontra X+ só é possível se as colunas Xsão linearmente independentes. No entanto, se as colunasX perto da dependência linear, cálculo (X⊤X)-1já está se tornando numericamente instável. O grau de dependência linear de recursos emXou, como se costuma dizer, a multicolinearidade da matrizX⊤X, pode ser medido pelo número de condicionalidade - a razão entre o valor próprio máximo e o mínimo. Quanto maior for, mais pertoX⊤X para degenerar e computação instável do pseudoinverso.
Álgebra Linear
A solução para o problema da regressão multilinear pode ser alcançada de forma bastante natural com o auxílio da álgebra linear e da geometria, pois mesmo o fato de a norma do vetor de erro aparecer na função de perda já sugere que o problema tem um lado geométrico. Vimos que uma tentativa de encontrar um modelo linear que descreva os pontos experimentais leva à equação
XW≃y...
(|||x0x1⋯xn|||)W=W0x0+W1x1+⋯Wnxn...
Se além de vetoresC(X) consideramos todos os vetores perpendiculares a eles, então obtemos mais um subespaço e podemos qualquer vetor de RNdecompõe-se em dois componentes, cada um dos quais vive em seu próprio subespaço. O segundo espaço perpendicular pode ser caracterizado como segue (precisaremos disso mais tarde). Deixe irv∈RNentão
X⊤v=(-x⊤0-⋯⋯⋯-x⊤n-)v=(x⊤0⋅v⋯x⊤n⋅v)

Onde ker(X⊤)={v|X⊤v=0}... Cada um dos subespaços pode ser alcançado usando o operador de projeção correspondente, mas mais sobre isso a seguir.

y=yproj+y⊥,yproj∈C(X),y⊥∈ker(X⊤)...

argminW||y-XW||=argminW||y⊥+yproj-XW||=argminW√||y⊥||2+||yproj-XW||2,
XˆW=yproj,

X⊤XW=X⊤yproj=X⊤yproj+X⊤y⊥=X⊤y,
W=(X⊤X)-1X⊤y=X+y,
yproj=XW=XX+y=ProjXy,
Vamos esclarecer o significado geométrico do coeficiente de determinação.

y-ˆy⋅1=y-ˉy+ˆy-ˉy⋅1...
‖y-ˆy⋅1‖2=‖y-ˉy‖2+‖ˆy-ˉy⋅1‖2...
Vardumatuma=Varres+Varreg...
R2=VarregVardumatuma,
R=cosθ...
Base arbitrária
Como sabemos, a regressão é realizada em funções básicas fEu e seu resultado é o modelo
f=∑EuWEufEu,
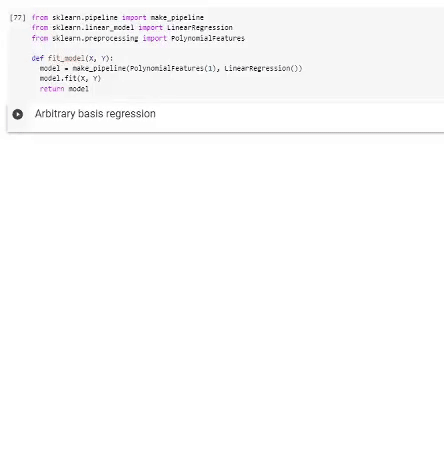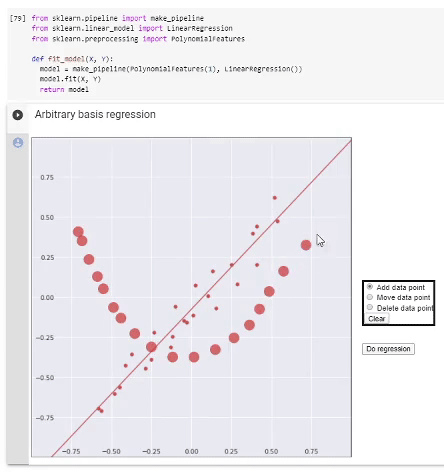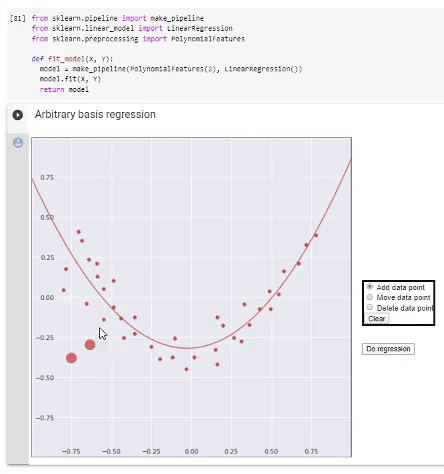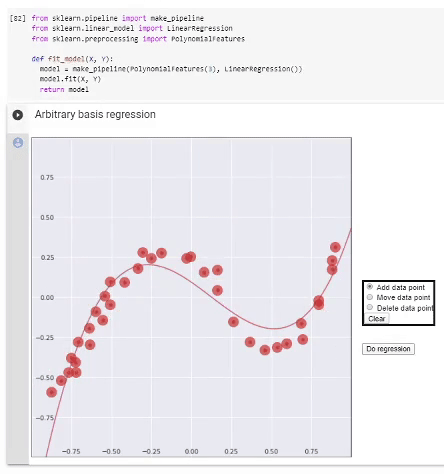
Se tivermos decidido com base, procederemos da seguinte forma. Formamos uma matriz de informações
Φ=(-f(1)⊤-⋯⋯⋯-f(N)⊤-)=(f0(x(1))f1(x(1))⋯fn(x(1))⋯⋯⋯⋯f0(x(N))f1(x(N))⋯fn(x(N))),
E(W)=‖ϵ(W)‖2=‖y-ΦW‖2
ˆW=argminWE(W)=(Φ⊤Φ)-1Φ⊤y=Φ+y
Considerações finais
Problema de seleção de dimensão
Na prática, muitas vezes é necessário construir de forma independente um modelo do fenômeno, ou seja, determinar quantas e quais funções básicas devem ser desempenhadas. O primeiro impulso de "conseguir mais" pode ser uma piada cruel: o modelo será muito sensível a ruídos nos dados (overfitting). Por outro lado, se você restringir excessivamente o modelo, ele ficará muito grosso (ajuste insuficiente).
Existem duas maneiras de sair dessa situação. A primeira é aumentar consistentemente o número de funções básicas, verificar a qualidade da regressão e parar a tempo. Ou a segunda: escolha uma função de perda que determinará o número de graus de liberdade automaticamente. Como critério para o sucesso da regressão, pode-se usar o coeficiente de determinação, que já foi mencionado acima, porém, o problema é queR2aumenta monotonicamente com o crescimento da dimensão da base. Portanto, o coeficiente ajustado é introduzido
ˉR2=1-(1-R2)[N-1N-(n+1)],
O segundo grupo de abordagens é a regularização, a mais famosa das quais é Ridge (eu2/ ridge / regularização Tikhonov), Lasso (eu1regularização) e Rede Elástica (Ridge + Lasso). A ideia principal desses métodos é modificar a função de perda com termos adicionais que não permitirão o vetor de coeficientesW crescer indefinidamente e, assim, evitar a reciclagem
ECume(W)=SSE(W)+α∑Eu|WEu|2=SSE(W)+α‖W‖2eu2,ELaço(W)=SSE(W)+β∑Eu|WEu|=SSE(W)+β‖W‖eu1,ERU(W)=SSE(W)+α‖W‖2eu2+β‖W‖eu1,
y=uma+bx+ϵ,ϵ∼N(0,σ2),{b∼N(0,τ2)←Cume,b∼Laplace(0,α)←Laço...

Métodos numéricos
Deixe-me dizer algumas palavras sobre como minimizar a função de perda na prática. SSE é uma função quadrática comum que é parametrizada pelos dados de entrada, portanto, em princípio, pode ser minimizada pelo método de descida mais íngreme ou outros métodos de otimização. Claro, os melhores resultados são mostrados por algoritmos que levam em consideração a forma da função SSE, por exemplo, o método de descida gradiente estocástico. A implementação de regressão do Lasso no scikit-learn usa o método de descida por coordenadas.
Você também pode resolver equações normais usando métodos de álgebra linear numérica. Um método eficiente que o scikit-learn usa para OLS é encontrar o pseudoinverso usando decomposição de valor singular. Os campos deste artigo são muito restritos para tocar neste tópico, para detalhes, eu o aconselho a consultar o curso de palestras de K.V. Vorontsov.
Publicidade e conclusão
Este artigo é uma releitura resumida de um dos capítulos de um curso sobre aprendizado de máquina clássico na Universidade Acadêmica de Kiev (sucessor da filial de Kiev do Instituto de Física e Tecnologia de Moscou, KO MIPT). O autor do artigo ajudou a criar este curso. O curso é feito tecnicamente na plataforma Google Colab, que permite combinar fórmulas formatadas em LaTeX, código executável Python e demonstrações interativas em Python + JavaScript, para que os alunos possam trabalhar com os materiais do curso e executar o código em qualquer computador que tenha um navegador. A página inicial contém links para resumos, pastas de trabalho práticas e recursos adicionais. O curso é baseado nos seguintes princípios:
- todos os materiais devem estar disponíveis para os alunos da primeira dupla;
- a aula é necessária para a compreensão, não para fazer anotações (as anotações já estão prontas, não adianta escrevê-las se não quiser);
- uma palestra é mais do que uma palestra (há mais material nas notas do que foi anunciado na palestra; na verdade, as notas são um livro-texto completo);
- visibilidade e interatividade (ilustrações, fotos, demos, gifs, código, vídeos do youtube).
Se você quiser ver o resultado, dê uma olhada na página do curso no GitHub .
Espero que esteja interessado, obrigado pela atenção.