
Na verdade, esses lagos (lagos de dados ) se tornaram o padrão para empresas e corporações que estão tentando usar todas as informações disponíveis. Os componentes de código aberto costumam ser uma opção atraente ao desenvolver grandes data lakes. Veremos os padrões gerais de arquitetura necessários para criar um data lake para soluções em nuvem ou híbridas e destacaremos uma série de detalhes críticos a serem observados ao implementar componentes-chave.
Projeto de fluxo de dados
Um fluxo lógico de data lake típico inclui os seguintes blocos funcionais:
- Fontes de dados;
- Recebendo dados;
- Nó de armazenamento;
- Processamento e enriquecimento de dados;
- Análise de dados.
Neste contexto, as fontes de dados são normalmente fluxos ou coleções de dados de eventos brutos (por exemplo, logs, cliques, telemetria IoT, transações).
A principal característica dessas fontes é que os dados brutos são armazenados em sua forma original. O ruído nesses dados geralmente consiste em registros duplicados ou incompletos com campos redundantes ou errôneos.
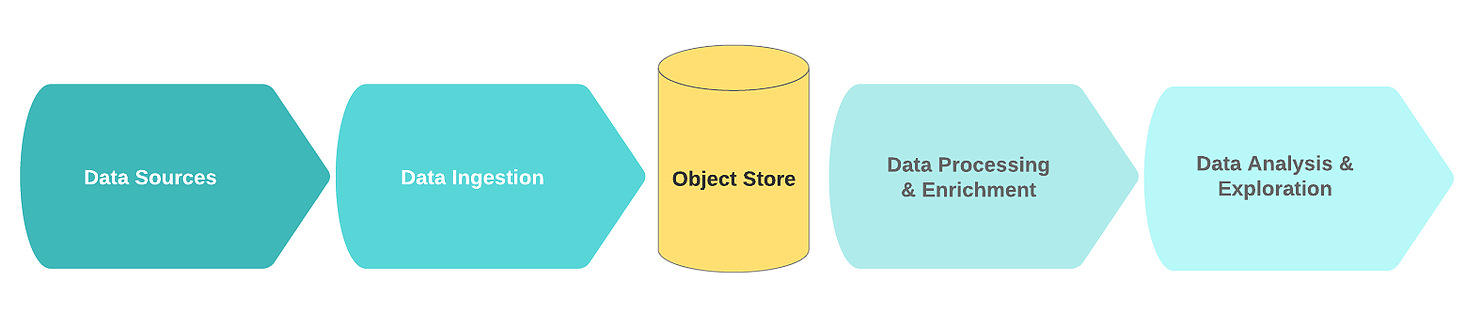
No estágio de ingestão, os dados brutos vêm de uma ou mais fontes de dados. O mecanismo de recepção é mais frequentemente implementado na forma de uma ou mais filas de mensagens com um componente simples voltado para a limpeza primária e salvamento de dados. Para construir um data lake eficiente, escalonável e consistente, é recomendável distinguir entre limpeza de dados simples e tarefas de enriquecimento de dados mais complexas. Uma boa regra prática é que as tarefas de limpeza requerem dados de uma única fonte em uma janela deslizante.
Texto oculto
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
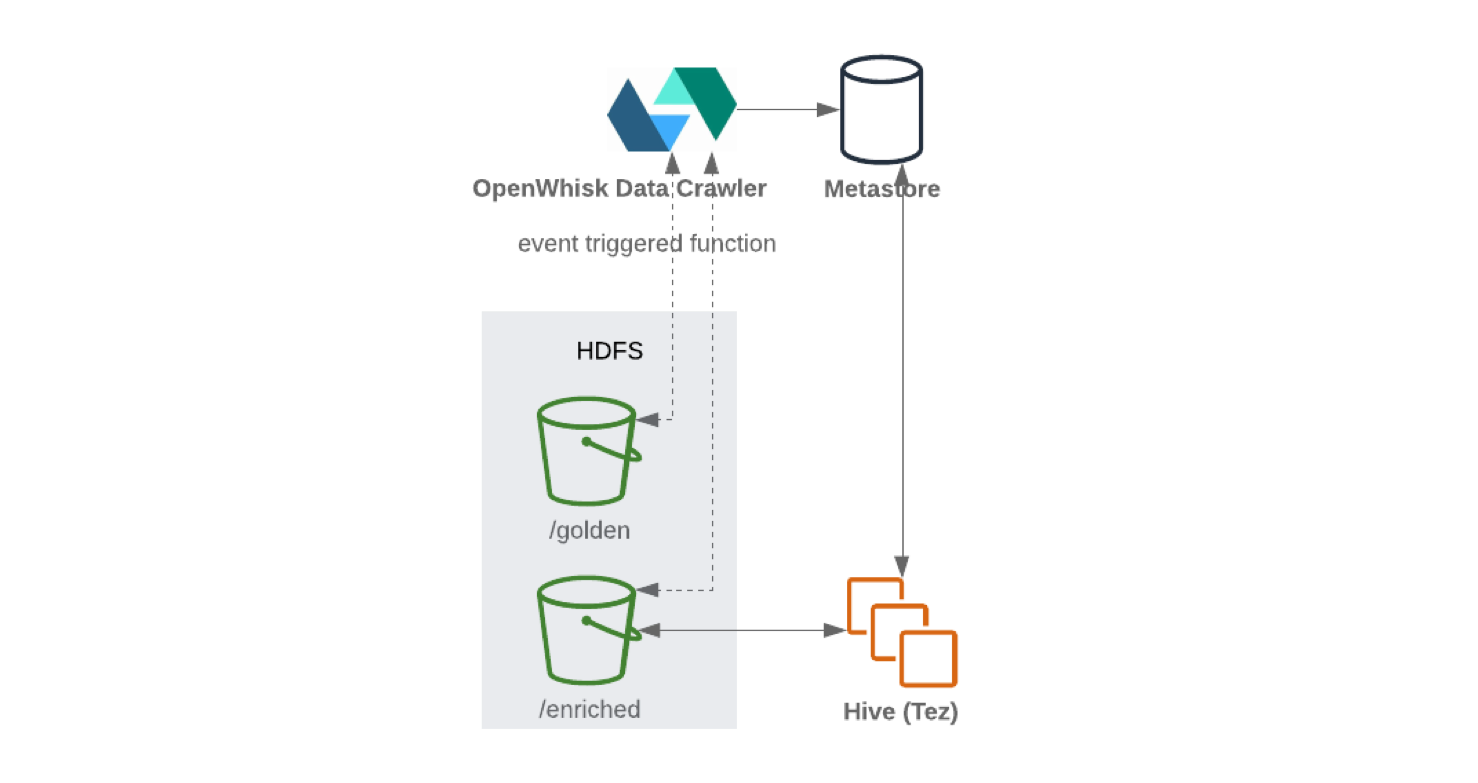
Depois que os dados são recebidos e limpos, eles são armazenados no sistema de arquivos distribuído (para melhorar a tolerância a falhas). Os dados geralmente são escritos em formato tabular. Quando novas informações são gravadas no nó de armazenamento, o catálogo de dados que contém o esquema e os metadados pode ser atualizado usando um rastreador offline. O lançamento do crawler geralmente é acionado por evento, por exemplo, quando um novo objeto chega ao armazenamento. Os repositórios são geralmente integrados aos seus catálogos. Eles descarregam o esquema subjacente para que os dados possam ser acessados.
Em seguida, os dados vão para uma área especial dedicada a "dados ouro". A partir deste ponto, os dados estão prontos para serem enriquecidos por outros processos.
Texto oculto
, , .
Durante o processo de enriquecimento, os dados são alterados e limpos adicionalmente de acordo com a lógica de negócios. Como resultado, eles são armazenados em um formato estruturado em um data warehouse ou banco de dados que é usado para recuperar rapidamente informações, análises ou um modelo de treinamento.
Finalmente, o uso de dados é análise e pesquisa. É aqui que as informações extraídas são transformadas em ideias de negócios por meio de visualizações, painéis e relatórios. Além disso, esses dados são uma fonte de previsão usando aprendizado de máquina, cujo resultado ajuda a tomar melhores decisões.
Componentes da plataforma
A infraestrutura de nuvem de lago de dados requer uma robusta e, no caso de sistemas de nuvem híbrida, uma camada de abstração unificada que pode ajudar a implantar, coordenar e executar tarefas computacionais sem as restrições de provedores de API.
O Kubernetes é uma ótima ferramenta para esse trabalho. Ele permite que você implante, organize e execute com eficiência vários serviços e tarefas computacionais de um data lake de maneira confiável e econômica. Ele oferece uma API unificada que funcionará localmente e em qualquer nuvem pública ou privada.
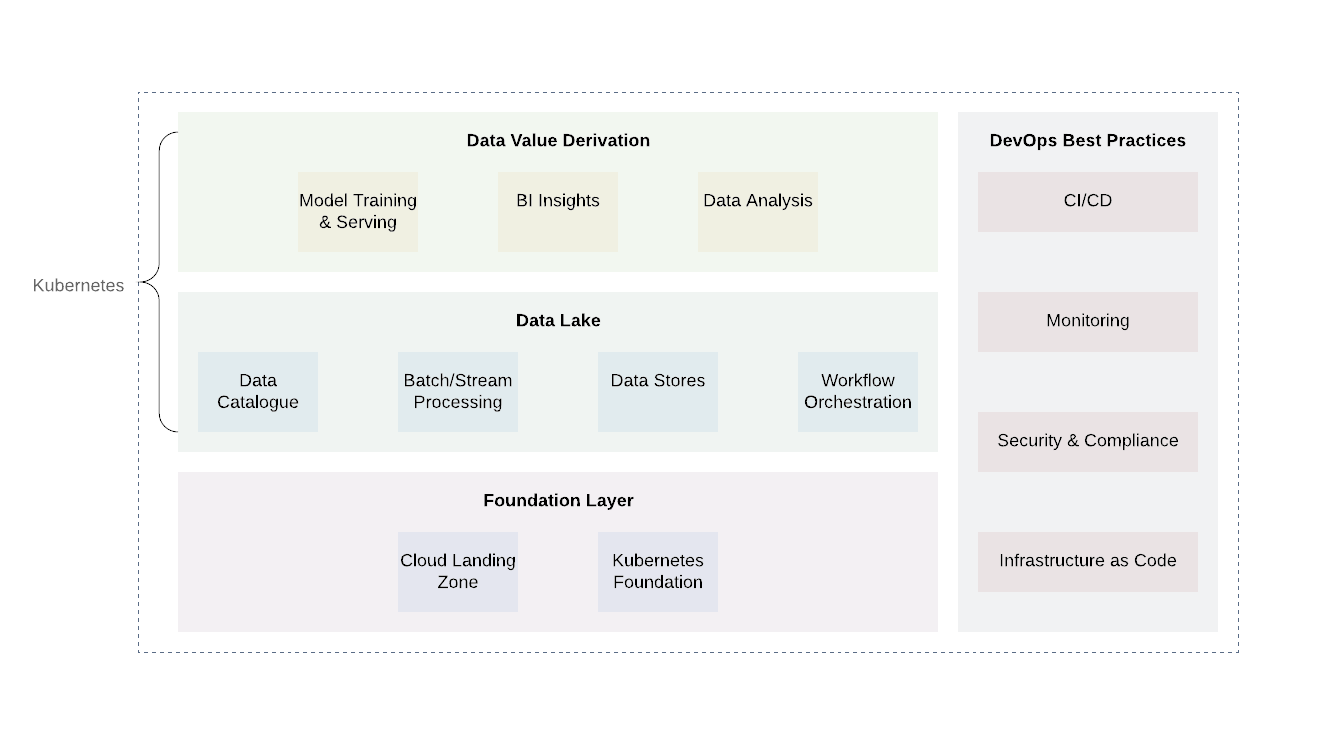
A plataforma pode ser dividida em várias camadas. A camada de base é onde implantamos o Kubernetes ou seu equivalente. A camada de base também pode ser usada para lidar com tarefas computacionais fora do domínio do data lake. Ao usar provedores de nuvem, seria promissor usar as práticas já estabelecidas de provedores de nuvem (registro e auditoria, design de acesso mínimo, varredura e relatórios de vulnerabilidade, arquitetura de rede, arquitetura IAM, etc.) Isso alcançará o nível necessário de segurança e conformidade com outros requisitos ...
Existem dois níveis adicionais acima do nível básico - o próprio data lake e o nível de saída de valor. Esses dois níveis são responsáveis pela base da lógica de negócios, bem como pelos processos de processamento de dados. Embora existam muitas tecnologias para essas duas camadas, o Kubernetes mais uma vez provará ser uma boa opção devido à sua flexibilidade para oferecer suporte a uma variedade de tarefas de computação.
A camada de data lake inclui todos os serviços necessários para recebimento ( Kafka , Kafka Connect ), filtragem, enriquecimento e processamento ( Flink e Spark ), gerenciamento de workflow ( Airflow ). Além disso, inclui armazenamento de dados e sistemas de arquivos distribuídos ( HDFS), bem como bancos de dados RDBMS e NoSQL .
O nível mais alto é obter valores de dados. Basicamente, esse é o nível de consumo. Inclui componentes como ferramentas de visualização para compreensão de business intelligence, ferramentas de mineração de dados ( Jupyter Notebooks ). Outro processo importante que ocorre nesse nível é o aprendizado de máquina usando amostras de treinamento de um data lake.
É importante observar que uma parte integrante de cada data lake é a implementação de práticas DevOps comuns: infraestrutura como código, capacidade de observação, auditoria e segurança. Eles desempenham um papel importante na solução de problemas do dia-a-dia e devem ser aplicados em todos os níveis para garantir a padronização, segurança e facilidade de uso.
, — , opensource-.
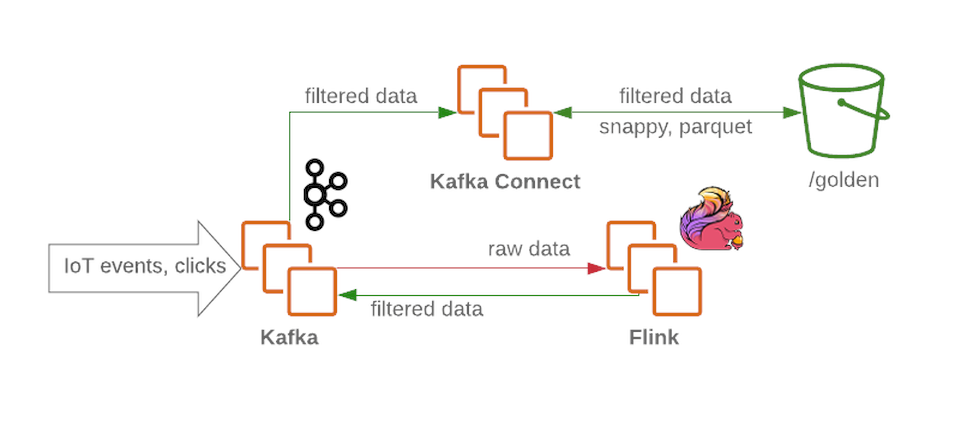
O cluster Kafka receberá mensagens não filtradas e não processadas e funcionará como um nó de recebimento no data lake. O Kafka fornece mensagens de alto rendimento de maneira confiável. Um cluster geralmente contém várias seções para dados brutos, processados (para streaming) e dados não entregues ou malformados.
Flink aceita uma mensagem de um nó de dados brutos de Kafka , filtra os dados e os pré-enriquece, se necessário. Os dados são então devolvidos ao Kafka (em uma seção separada para dados filtrados e ricos). Em caso de falha, ou quando a lógica de negócios muda, essas mensagens podem ser chamadas novamente, porque que eles são salvos emKafka . Esta é uma solução comum para processos de streaming. Enquanto isso, Flink grava todas as mensagens malformadas em outra seção para análise posterior.
Usando o Kafka Connect, conseguimos salvar dados nos back-ends de armazenamento de dados necessários (como a zona dourada no HDFS ). O Kafka Connect é facilmente escalável e o ajudará a aumentar rapidamente o número de processos simultâneos, aumentando o rendimento sob carga de trabalho pesada:
Ao gravar do Kafka Connect para HDFS, é recomendado realizar a divisão de conteúdo para eficiência do tratamento de dados (quanto menos dados para varrer, menos solicitações e respostas). Depois que os dados foram gravados no HDFS , a funcionalidade sem servidor (como OpenWhisk ou Knative ) atualizará periodicamente os metadados e o armazenamento de parâmetros de esquema. Como resultado, o esquema atualizado pode ser acessado por meio de uma interface semelhante a SQL (por exemplo, Hive ou Presto ).
O Apache Airflow pode ser usado para fluxos de dados subsequentes e controle de processo ETL . Ele permite que os usuários executem piplines de várias etapas usando objetos Python e Directed Acyclic Graph ( DAG ). O usuário pode definir dependências, programar processos complexos e rastrear tarefas por meio de uma interface gráfica. O Apache Airflow também pode lidar com todos os dados externos. Por exemplo, para receber dados por meio de uma API externa e armazená-los em armazenamento persistente. Faísca alimentado pela Apache Airflow
por meio de um plugin especial, ele pode enriquecer periodicamente os dados filtrados brutos de acordo com os objetivos de negócios e preparar os dados para pesquisa por cientistas de dados e analistas de negócios. Os cientistas de dados podem usar o JupyterHub para gerenciar vários Notebooks Jupyter . Portanto, vale a pena usar o Spark para configurar interfaces multiusuário para trabalhar com dados, coletá-los e analisá-los.

Para aprendizado de máquina, você pode usar estruturas como Kubeflow , aproveitando a escalabilidade do Kubernetes . Os modelos de treinamento resultantes podem ser devolvidos ao sistema.
Se juntarmos o quebra-cabeça, obteremos algo assim:

Excelência operacional
Dissemos que os princípios de DevOps e DevSecOps são componentes essenciais de qualquer data lake e nunca devem ser esquecidos. Com muito poder vem muita responsabilidade, especialmente quando todos os dados estruturados e não estruturados sobre sua empresa estão em um só lugar.
Os princípios básicos serão os seguintes:
- Restringir o acesso do usuário;
- Monitoramento;
- Criptografia de dados;
- Soluções sem servidor;
- Usando processos de CI / CD.
Os princípios de DevOps e DevSecOps são componentes essenciais de qualquer data lake e nunca devem ser esquecidos. Com muito poder vem muita responsabilidade, especialmente quando todos os dados estruturados e não estruturados sobre sua empresa estão em um só lugar.
Um dos métodos recomendados é permitir o acesso apenas para determinados serviços, distribuindo os direitos apropriados, e negar o acesso direto do usuário para que os usuários não possam alterar os dados (isso também se aplica aos comandos). O monitoramento completo por ações de registro também é importante para proteger os dados.
A criptografia de dados é outro mecanismo de proteção de dados. Os dados armazenados podem ser criptografados usando um sistema de gerenciamento de chaves ( KMS) Isso criptografará seu sistema de armazenamento e estado atual. Por sua vez, a criptografia de transmissão pode ser feita usando certificados para todas as interfaces e terminais de serviços como Kafka e ElasticSearch .
E no caso de motores de busca que não cumpram a política de segurança, é melhor dar preferência a soluções sem servidor . Também é necessário abandonar implantações manuais, mudanças situacionais em qualquer componente do data lake; cada mudança deve vir do controle de origem e passar por uma série de testes de CI antes de ser implantada em um lago de dados do produto ( teste de fumaça , regressão, etc.).
Epílogo
Cobrimos os princípios básicos de design de uma arquitetura de data lake de código aberto. Como costuma acontecer, a escolha da abordagem nem sempre é óbvia e pode ser ditada por diferentes requisitos de negócios, orçamento e tempo. Mas o aproveitamento da tecnologia de nuvem para criar data lakes, seja uma solução híbrida ou totalmente em nuvem, é uma tendência emergente no setor. Isso se deve ao grande número de benefícios que essa abordagem oferece. Possui alto grau de flexibilidade e não restringe o desenvolvimento. É importante entender que um modelo de trabalho flexível traz benefícios econômicos significativos, permitindo combinar, dimensionar e aprimorar os processos aplicados.