
Este texto é uma tradução da postagem do blog Multi-Target in Albumentations datada de 27 de julho de 2020. O autor está no Habré , mas eu estava com preguiça de traduzir o texto para o russo. E esta tradução foi feita a seu pedido.
Traduzi tudo o que posso para o russo, mas alguns termos técnicos em inglês parecem mais naturais. Eles são deixados neste formulário. Se uma tradução adequada vier à sua mente - comente e corrija.
O aumento da imagem é uma técnica de regularização interpretada. Você converte dados marcados existentes em novos dados, aumentando assim o tamanho do conjunto de dados.

Você pode usar Albumentations em PyTorch , Keras , Tensorflow ou qualquer outra estrutura que possa processar uma imagem como um array numpy.
A biblioteca funciona melhor com tarefas padrão de classificação, segmentação, detecção de objetos e pontos-chave. Um pouco menos comuns são os problemas quando cada elemento do exemplo de treinamento contém não um, mas muitos objetos diferentes.
Para este tipo de situação, foi adicionada a funcionalidade multi-alvo.
Situações em que isso pode ser útil:
- Redes siamesas
- Processando frames em vídeo
- Image2image Tarefas
- Multilabel semantic segmentation
- Instance segmentation
- Panoptic segmentation
- Kaggle . Kaggle Grandmaster, Kaggle Masters, Kaggle Expert.
- , Deepfake Challenge , Albumentations .
- PyTorch ecosystem
- 5700 GitHub.
- 80 . .
Nos últimos três anos, temos trabalhado na otimização de funcionalidade e desempenho.
Por enquanto, estamos nos concentrando em documentação e tutoriais.
Pelo menos uma vez por semana, os usuários pedem para adicionar suporte de transformação para várias máscaras de segmentação.
Já a temos há muito tempo.
Neste artigo, vamos compartilhar exemplos de como trabalhar com vários alvos em albumentações.
Cenário 1: uma imagem, uma máscara
O caso de uso mais comum é a segmentação de imagens. Você tem uma imagem e uma máscara. Você deseja aplicar um conjunto de transformações espaciais a eles e eles devem ser o mesmo conjunto.
Neste código, estamos usando HorizontalFlip e ShiftScaleRotate .
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT,
scale_limit=0.3,
rotate_limit=(10, 30),
p=0.5)
], p=1)
transformed = transform(image=image, mask=mask)
image_transformed = transformed['image']
mask_transformed = transformed['mask']-> Link para gistfile1.py

Cenário 2: uma imagem e várias máscaras

Para algumas tarefas, você pode ter vários rótulos correspondentes ao mesmo pixel.
Vamos aplicar HorizontalFlip , GridDistortion , RandomCrop .
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.GridDistortion(p=0.5),
A.RandomCrop(height=1024, width=1024, p=0.5),
], p=1)
transformed = transform(image=image, masks=[mask, mask2])
image_transformed = transformed['image']
mask_transformed = transformed['masks'][0]
mask2_transformed = transformed['masks'][1]-> Link para gistfile1.py
Cenário 3: várias imagens, máscaras, pontos-chave e caixas

Você pode aplicar transformações espaciais a vários destinos.
Neste exemplo, temos duas imagens, duas máscaras, duas caixas e dois conjuntos de pontos-chave.
Vamos aplicar uma sequência de HorizontalFlip e ShiftScaleRotate .
import albumentations as A
transform = A.Compose([A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(border_mode=cv2.BORDER_CONSTANT, scale_limit=0.3, p=0.5)],
bbox_params=albu.BboxParams(format='pascal_voc', label_fields=['category_ids']),
keypoint_params=albu.KeypointParams(format='xy'),
additional_targets={
"image1": "image",
"bboxes1": "bboxes",
"mask1": "mask",
'keypoints1': "keypoints"},
p=1)
transformed = transform(image=image,
image1=image1,
mask=mask,
mask1=mask1,
bboxes=bboxes,
bboxes1=bboxes1,
keypoints=keypoints,
keypoints1=keypoints1,
category_ids=["face"]
)
image_transformed = transformed['image']
image1_transformed = transformed['image1']
mask_transformed = transformed['mask']
mask1_transformed = transformed['mask1']
bboxes_transformed = transformed['bboxes']
bboxes1_transformed = transformed['bboxes1']
keypoints_transformed = transformed['keypoints']
keypoints1_transformed = transformed['keypoints1']
→ Link para gistfile1.py

P: É possível trabalhar com mais de duas imagens?
R: Você pode tirar quantas imagens quiser.
P: O número de imagens, máscaras, caixas e pontos-chave deve ser o mesmo?
R: Você pode ter N imagens, M máscaras, K pontos-chave e B caixas. N, M, K e B podem ser diferentes.
P: Existem situações em que a funcionalidade de múltiplos destinos não funciona ou não funciona conforme o esperado?
R: Em geral, você pode usar alvos múltiplos para um conjunto de imagens de tamanhos diferentes. Algumas transformações dependem da entrada. Por exemplo, você não pode cortar um recorte maior do que a própria imagem. Outro exemplo: MaskDropout , que pode depender da máscara original. Como ele se comportará quando tivermos um conjunto de máscaras não está claro. Na prática, eles são extremamente raros.
P: Quantas transformações você pode combinar?
R : Você pode combinar transformações em um pipeline complexo de várias maneiras diferentes.
A biblioteca contém mais de 30 transformações espaciais . Todos eles suportam imagens e máscaras, a maioria das caixas de suporte e pontos-chave.
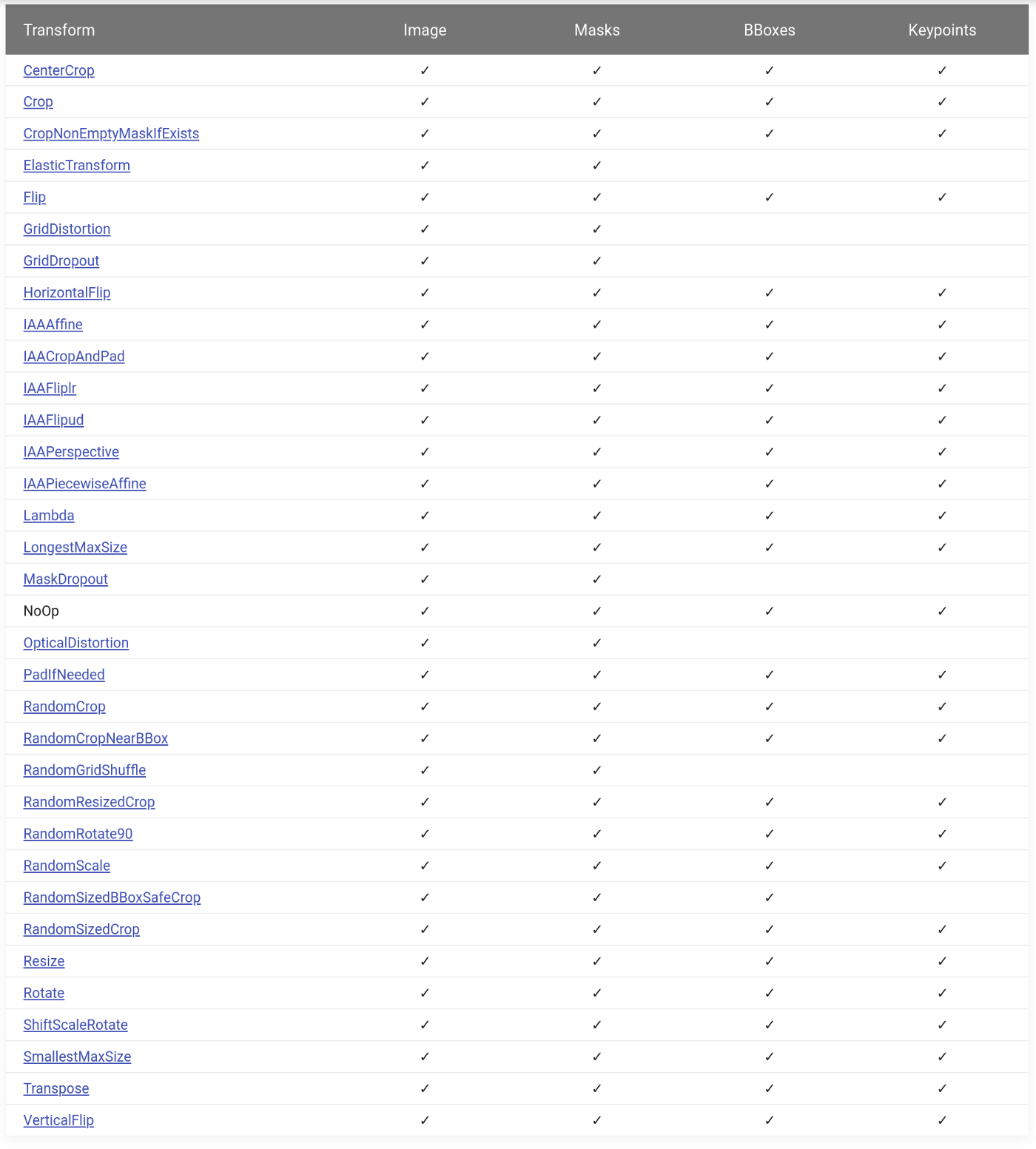
→ Link para a fonte
Eles podem ser combinados com mais de 40 transformações que alteram os valores de pixel de uma imagem. Por exemplo: RandomBrightnessContrast , Blur, ou algo mais exótico como RandomRain .
Documentação adicional
- Folha de conversão completa
- Transformações de máscara para tarefas de segmentação
- Aumento da detecção de objetos de caixas delimitadoras
- Transformações de pontos-chave
- Conversão síncrona de máscaras, caixas e pontos-chave
- Com que probabilidade as transformações são aplicadas no pipeline?
Conclusão
Trabalhar em um projeto de código aberto é difícil, mas muito emocionante. Gostaria de agradecer à equipe de desenvolvimento:
e todos os colaboradores que ajudaram a criar a biblioteca e trazê-la ao nível atual.