
Hoje vou falar um pouco sobre o que penso sobre o failover de tarantool / cartucho. Primeiro, algumas palavras sobre o que é cartucho: este é um pedaço de código lua que funciona dentro do tarantool e combina tarântulas entre si em um "cluster" condicional. Isso se deve a duas coisas:
- cada tarântula conhece os endereços de rede de todas as outras tarântulas;
- tarântulas regularmente "ping" entre si via UDP para entender quem está vivo e quem não está. Aqui, eu simplifico um pouco deliberadamente, o algoritmo de ping é mais complicado do que apenas solicitação-resposta, mas isso não é muito importante para a análise. Se estiver interessado - pesquise no algoritmo SWIM.
Em um cluster, tudo geralmente é dividido em tarântulas com estado (mestre / réplica) e sem estado (roteador). As tarântulas sem estado são responsáveis pelo armazenamento de dados e as tarântulas sem estado são responsáveis pelo roteamento de solicitações.
É assim que fica na foto:
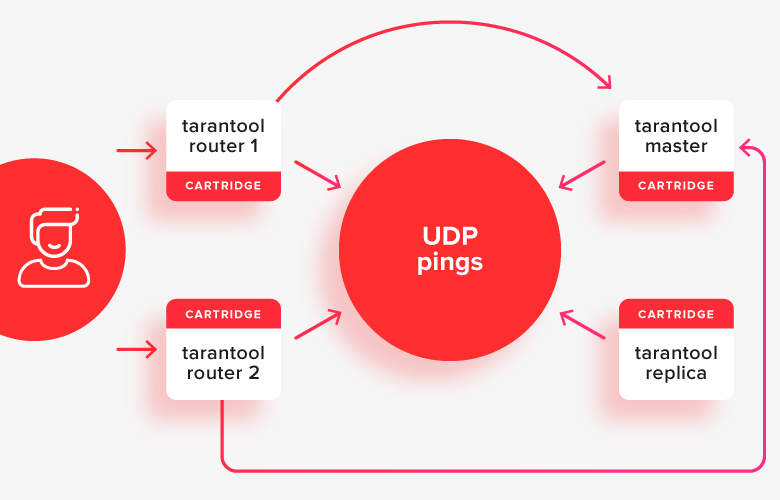
O cliente faz solicitações a qualquer um dos roteadores ativos, e eles redirecionam as solicitações para aquele das lojas, que agora é o mestre ativo. Na foto, esses caminhos são mostrados com setas.
Agora, não quero complicar e introduzir fragmentação na conversa sobre a escolha de um líder, mas a situação com ele será um pouco diferente. A única diferença é que o roteador ainda precisa tomar uma decisão sobre qual conjunto de réplicas irá do armazenamento.
Primeiro, vamos falar sobre como os nós aprendem os endereços uns dos outros. Para isso, cada um deles possui um arquivo yaml no disco com a topologia de cluster, ou seja, com informações sobre os endereços de rede de todos os membros, e quem deles é quem (com ou sem estado). Além de personalização potencialmente adicional, mas por enquanto, vamos deixar isso de lado. Os arquivos de configuração contêm as configurações para todo o cluster como um todo e são iguais para cada tarântula. Se forem feitas alterações nelas, elas serão feitas de forma síncrona para todas as tarântulas.
Agora as mudanças de configuração podem ser feitas através da API de qualquer uma das tarântulas do cluster: ela se conectará a todos os outros, enviará uma nova versão da configuração, todos a aplicarão e em todos os lugares haverá uma nova versão, a mesma novamente.
Cenário - falha de nó, switchover
Numa situação de falha de um roteador, tudo fica mais ou menos simples: basta o cliente ir a qualquer outro roteador ativo e entregar a solicitação na loja desejada. Mas e se, por exemplo, o mestre de um dos Storaja caísse?
No momento, implementamos um algoritmo "ingênuo" para esse caso, que se baseia no ping UDP. Se a réplica não “vê” respostas do mestre ao ping por um curto período de tempo, ela considera que o mestre caiu e se torna o próprio mestre, mudando para o modo de leitura e gravação de somente leitura. Os roteadores agem da mesma maneira: se eles não veem algum tempo de resposta de ping do mestre, eles mudam o tráfego para a réplica.
Isso funciona relativamente bem em casos simples, exceto para uma situação de cérebro dividido, quando metade dos nós são separados de outro por algum tipo de problema de rede:
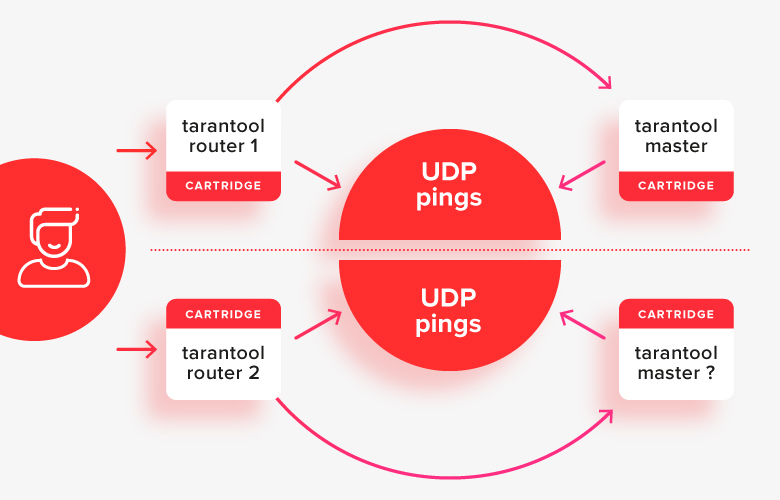
Nesta situação, os roteadores verão que a “outra metade” do cluster está indisponível e a considerarão como a principal, e acontece que há dois mestres no sistema ao mesmo tempo. Este é o primeiro caso importante a ser resolvido.
Cenário - Editar configuração em caso de falhas
Outro cenário importante é substituir uma tarântula com falha em um cluster por uma nova ou adicionar nós ao cluster quando uma das réplicas ou roteadores não estiver disponível.
Durante a operação normal, quando tudo no cluster está disponível, podemos nos conectar via API a qualquer nó, pedir a ele para editar a configuração e, como eu disse acima, o nó "distribuirá" a nova configuração para todo o cluster.
Mas quando alguém está indisponível, você não pode aplicar a nova configuração, porque quando esses nós ficarem disponíveis novamente, não ficará claro qual deles no cluster tem a configuração correta e qual não. Ainda assim, a inacessibilidade dos nós entre si pode significar que existe uma divisão do cérebro entre eles. E editar a configuração é simplesmente inseguro, porque você pode editá-la por engano de maneiras diferentes em metades diferentes.
Por esses motivos, agora proibimos a edição da configuração por meio da API quando alguém não está disponível. Só pode ser corrigido em disco, por meio de arquivos de texto (manualmente). Aqui você deve entender bem o que está fazendo e ter muito cuidado: a automação não o ajudará em nada.
Isso torna a operação inconveniente, e este é o segundo caso a ser resolvido.
Cenário - failover estável
Outro problema com o modelo de failover ingênuo é que a troca de mestre para réplica em caso de falha do mestre não é registrada em lugar nenhum. Todos os nós tomam a decisão de alternar por conta própria e, quando o mestre ganha vida, o tráfego muda para ele novamente.
Isso pode ou não ser um problema. Antes de ligar o mestre, o mestre "alcançará" os logs transacionais da réplica, portanto, provavelmente não haverá um grande atraso de dados. O problema estará apenas no caso de haver problemas de rede e perda de pacotes: então, muito provavelmente, haverá "flashes" periódicos do mestre (oscilação).
A solução é um coordenador "forte" (etcd / consul / tarantool)
Para evitar problemas com um cérebro dividido e para possibilitar a edição da configuração quando o cluster estiver parcialmente indisponível, precisamos de um coordenador forte que seja resistente à segmentação de rede. O coordenador deve ser distribuído em 3 data centers para que, se algum deles falhar, ele permaneça operacional.
Existem agora 2 coordenadores baseados em RAFT populares que usam etcd e consul para isso. Quando a replicação síncrona aparece no tarantool, ela também pode ser usada para isso.
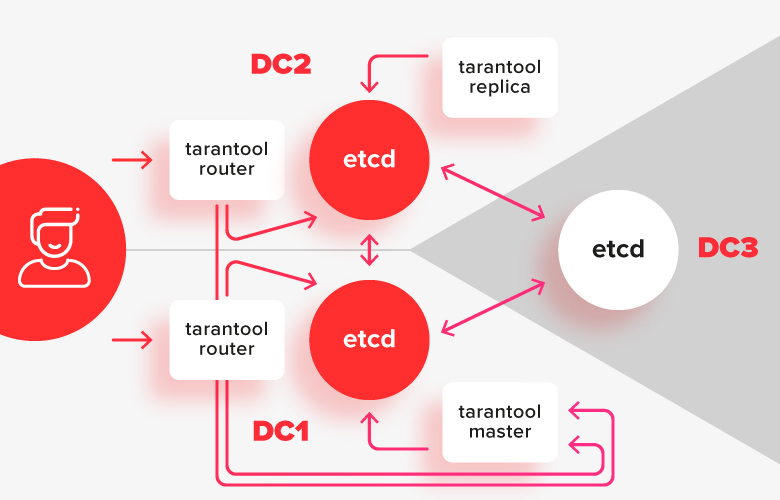
Neste esquema, as instalações de tarântula são divididas em dois datacenters e são conectadas à instalação local etcd. Uma instância de etcd no terceiro datacenter serve como árbitro para que, em caso de falha de um dos datacenters, diga exatamente qual deles permanece a maioria.
Gerenciamento de configuração com um coordenador forte
Como eu disse acima, na ausência de um coordenador e na falha de uma das tarântulas, não poderíamos editar a configuração centralmente, pois então é impossível dizer qual configuração em qual dos nós está correta.
No caso de um coordenador forte, tudo é mais simples: podemos armazenar a configuração no coordenador, e cada instância da tarântula conterá um cache dessa configuração em seu sistema de arquivos. Após a conexão bem-sucedida com o coordenador, ele atualizará sua cópia da configuração para a do coordenador.
Editar a configuração também fica mais fácil: pode ser feito através da API de qualquer tarântula. Ele irá pegar o bloqueio no coordenador, substituir os valores desejados na configuração, aguardar até que todos os nós o apliquem e liberar o bloqueio. Bem, ou como último recurso, você pode editar a configuração no etcd manualmente e ela se aplicará a todo o cluster.
Será possível editar a configuração mesmo que algumas tarântulas não estejam disponíveis. O principal é que a maioria dos nós coordenadores está disponível.
Failover com um coordenador forte
A comutação confiável de nós com um coordenador é resolvida devido ao fato de que além da configuração, armazenaremos no coordenador informações sobre quem é o mestre atual na réplica e onde as mudanças foram feitas.
O algoritmo de failover muda da seguinte maneira:
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
Com um coordenador, a proteção contra oscilações também é possível. No coordenador, é possível registrar todo o histórico de comutação, e se durante os últimos X minutos o mestre trocou para uma réplica, então a comutação reversa é feita apenas explicitamente pelo administrador.
Outro ponto importante é a chamada "Esgrima". As tarântulas que se encontram isoladas de outros datacenters (ou conectadas a um coordenador que perdeu a maioria) devem presumir que muito provavelmente o resto do cluster, ao qual o acesso foi perdido, tem a maioria. E isso significa que, dentro de um certo tempo, todos os nós cortados da maioria devem passar para somente leitura.
Problema de indisponibilidade do coordenador
Enquanto discutíamos abordagens para trabalhar com o coordenador, recebemos uma solicitação para garantir que, se o coordenador cair, mas todas as tarântulas estiverem intactas, não traduza todo o cluster em somente leitura.
A princípio parecia que não era muito realista fazer isso, mas depois lembramos que o próprio cluster monitora a disponibilidade de outros nós por meio de pings UDP. Isso significa que podemos direcioná-los e não acionar a reeleição do mestre dentro do conjunto de réplicas, se ficar claro por meio de pings UDP que todo o conjunto de réplicas está ativo.
Esta abordagem o ajudará a se preocupar menos com a disponibilidade do coordenador, especialmente se você precisar reiniciá-lo, por exemplo, para atualizar.
Planos de implementação
Agora estamos coletando feedback e iniciando a implementação. Se você tem algo a dizer - escreva nos comentários ou em um pessoal.
O plano é mais ou menos assim:
- Faça o suporte etcd no tarantool [pronto]
- Failover usando etcd como coordenador, stateful [feito]
- Failover usando tarântula como coordenador, travamento [concluído]
- Armazenando configuração no etcd [em andamento]
- Escrevendo ferramentas CLI para reparo de cluster [em andamento]
- Armazenando a configuração na tarântula
- Gerenciamento de cluster quando parte do cluster não está disponível
- Esgrima
- Proteção contra oscilações
- Failover usando cônsul como coordenador
- Armazenando configuração no cônsul
No futuro, quase certamente abandonaremos o cluster inteiramente sem um coordenador forte. Isso provavelmente coincidirá com a implementação baseada em RAFT de replicação síncrona na tarântula.
Agradecimentos
Obrigado aos desenvolvedores do Mail.ru Mail e administradores pelo feedback, críticas e testes fornecidos.