Olá, Habr! Neste artigo, mostrarei como fazer uma análise de frequência da língua russa moderna da Internet e usá-la para decifrar o texto. Quem se importa, bem-vindo sob o corte!

Análise de frequência do idioma russo da Internet
A rede social Vkontakte foi tomada como fonte de onde se podem obter muitos textos com uma linguagem moderna da Internet ou, para ser mais preciso, são comentários sobre publicações em várias comunidades desta rede. Escolhi o futebol de verdade como comunidade . Para analisar comentários, usei a API Vkontakte :
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passO resultado foi cerca de 200 MB de texto. Agora contamos qual caractere aparece quantas vezes:
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequencyOs resultados obtidos podem ser comparados com os resultados da Wikipedia e exibidos como:
1) gráfico de comparação
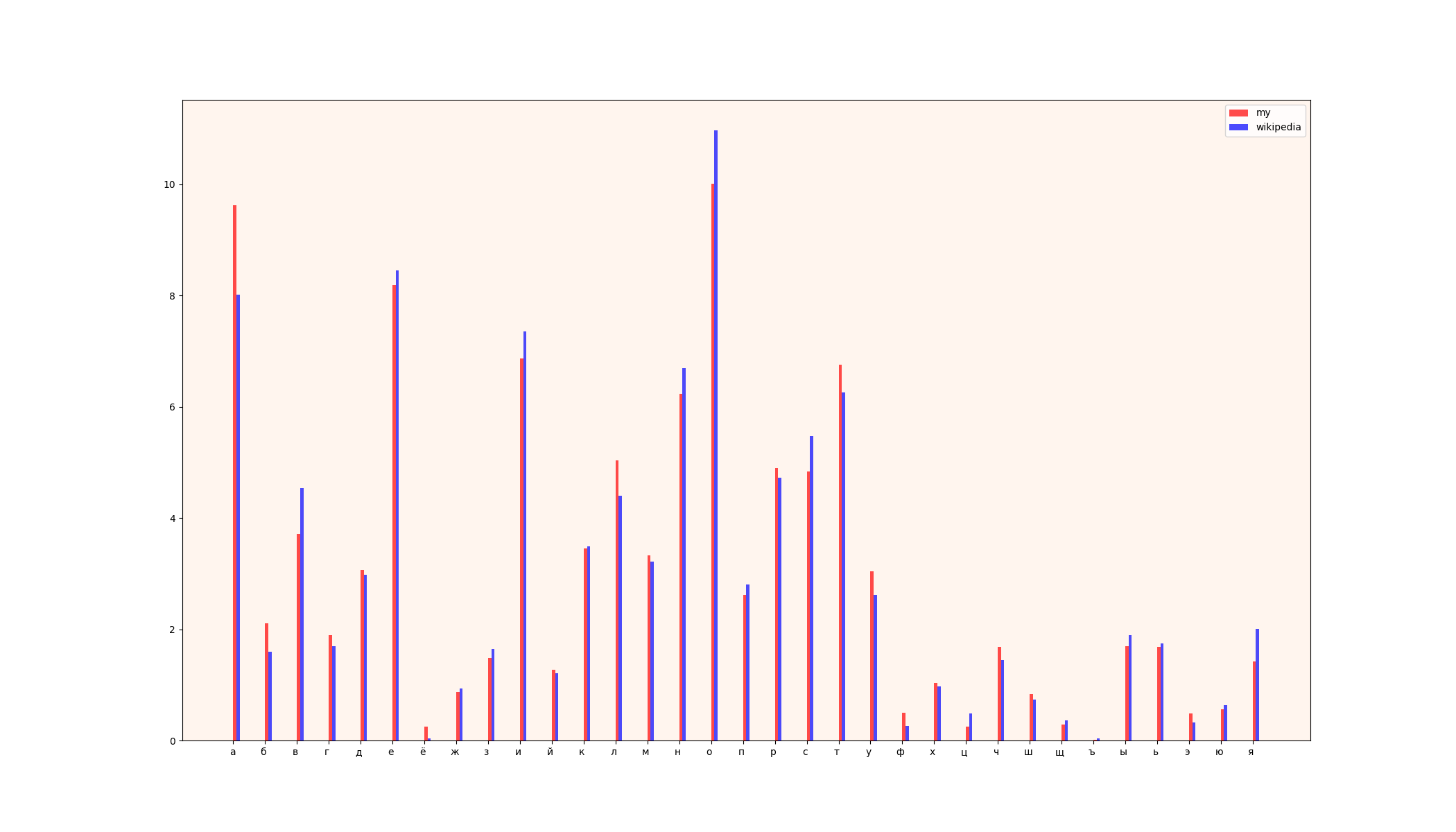
2) tabelas (esquerda - dados da wikipedia, direita - meus dados)
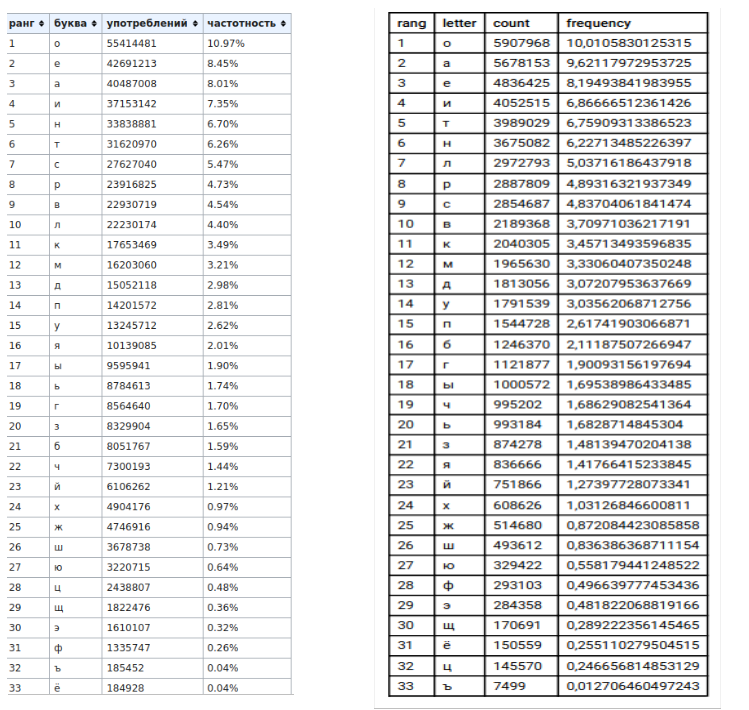
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
Se você olhar o texto descriptografado, poderá adivinhar onde nosso algoritmo deu errado: luta → faz, vadio → rádio, toho → adição, lidera → pessoas. Assim, é possível decifrar todo o texto, pelo menos para apreender o significado do texto. Também quero observar que esse método será eficaz para descriptografar apenas textos longos que foram criptografados com métodos de criptografia simétricos. O código completo está disponível no Github .