
Este artigo coleta alguns padrões comuns para ajudar os engenheiros a trabalhar com serviços de grande escala que estão sendo solicitados por milhões de usuários.
Na experiência do autor, esta não é uma lista exaustiva, masdicasrealmente eficazes . Então, vamos começar.
Traduzido com o apoio da Mail.ru Cloud Solutions .
Primeiro nível
As medidas listadas abaixo são relativamente fáceis de implementar, mas geram retornos elevados. Se você não os experimentou antes, ficará surpreso com as melhorias significativas.
Infraestrutura como código
O primeiro conselho é implementar a infraestrutura como código. Isso significa que você deve ter uma maneira programática de implantar toda a sua infraestrutura. Parece complicado, mas na verdade estamos falando sobre o seguinte código:
Implante 100 máquinas virtuais
- com Ubuntu
- 2 GB de RAM cada
- eles terão o seguinte código
- com tais parâmetros
Você pode rastrear e reverter para alterações de infraestrutura rapidamente usando o controle de origem.
O modernista em mim diz que você pode usar o Kubernetes / Docker para fazer todas as opções acima, e ele está certo.
Você também pode fornecer automação com Chef, Puppet ou Terraform.
Integração e entrega contínuas
Para criar um serviço escalonável, é importante ter um pipeline de compilação e teste para cada solicitação pull. Mesmo que o teste seja o mais simples, ele pelo menos garantirá que o código que você implanta seja compilado.
Cada vez neste estágio você está respondendo à pergunta: meu assembly compilará e passará nos testes, é válido? Isso pode soar como uma barra baixa, mas resolve muitos problemas.
Não há nada mais bonito do que ver essas caixas de seleção.
Para esta tecnologia, você pode verificar Github, CircleCI ou Jenkins.
Balanceadores de carga
Portanto, queremos iniciar um balanceador de carga para redirecionar o tráfego e garantir que a carga em todos os nós seja igual ou que o serviço funcione em caso de falha:
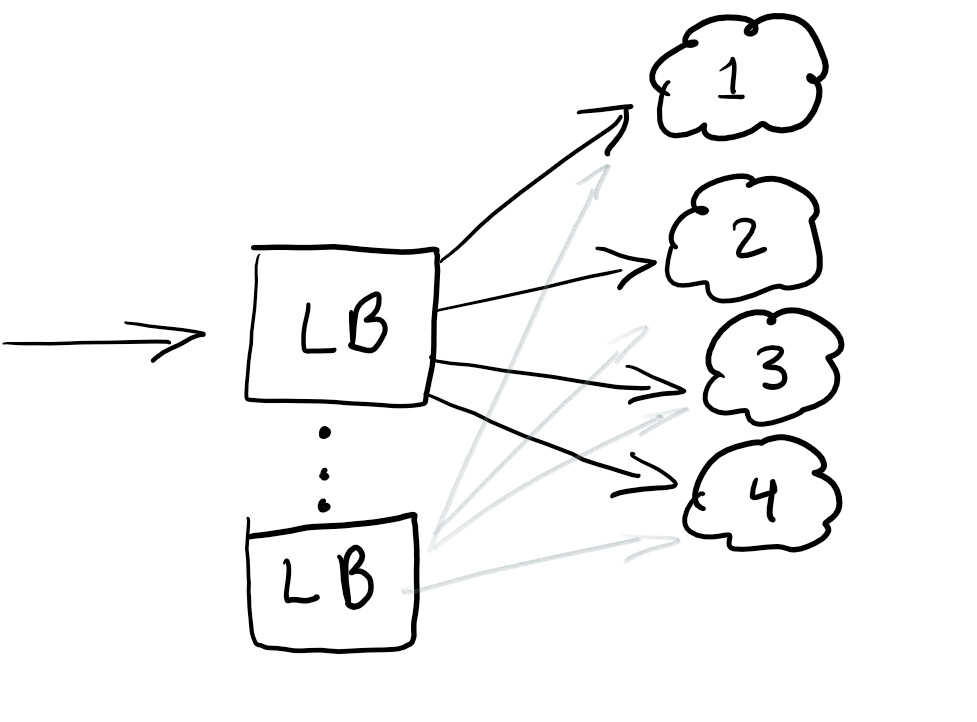
Um balanceador de carga geralmente é bom para ajudar a distribuir o tráfego. A melhor prática é desequilibrar para que você não tenha um único ponto de falha.
Normalmente, os balanceadores de carga são configurados na nuvem que você está usando.
RayID, ID de correlação ou UUID para solicitações
Você já encontrou um erro em um aplicativo com uma mensagem como esta: “Algo deu errado. Salve esta id e envie para nossa equipe de suporte ” ?
Identificador exclusivo, ID de correlação, RayID ou qualquer uma das variações é um identificador exclusivo que permite rastrear uma solicitação ao longo de seu ciclo de vida. Isso permite que você rastreie todo o caminho da solicitação nos logs.
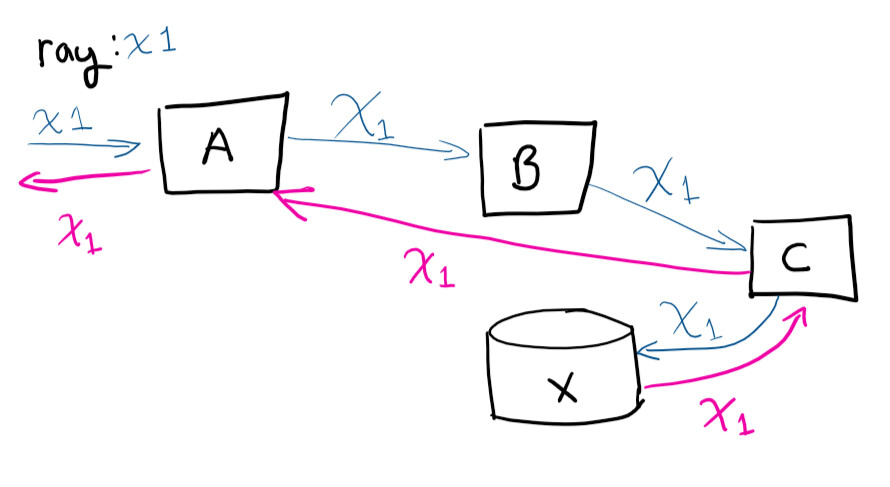
O usuário faz uma solicitação ao sistema A, em seguida, A contata B, que contata C, salva em X e, em seguida, a solicitação retorna a A
Se você fosse se conectar remotamente a máquinas virtuais e tentar rastrear o caminho da solicitação (e correlacionar manualmente quais chamadas estão ocorrendo), você ficaria louco. Ter um identificador exclusivo torna a vida muito mais fácil. Esta é uma das coisas mais fáceis de fazer para economizar tempo à medida que seu serviço cresce.
Nível médio
O conselho aqui é mais complexo do que o anterior, mas as ferramentas certas facilitam a tarefa, proporcionando um retorno do investimento, mesmo para pequenas e médias empresas.
Registro centralizado
Parabéns! Você implantou 100 máquinas virtuais. No dia seguinte, o CEO vem reclamar de um erro que recebeu ao testar o serviço. Ele relata o ID correspondente de que falamos acima, mas você terá que examinar os registros de 100 máquinas para encontrar aquele que causou o travamento. E ela precisa ser encontrada antes da apresentação de amanhã.
Embora pareça uma aventura divertida, é melhor garantir que você possa pesquisar todas as revistas em um só lugar. Resolvi o problema de centralizar os logs com a funcionalidade interna da pilha ELK: a coleta de logs pesquisáveis é suportada aqui. Isso realmente ajudará a resolver o problema de localização de um log específico. Como bônus, você pode criar diagramas e outras coisas divertidas como essas.
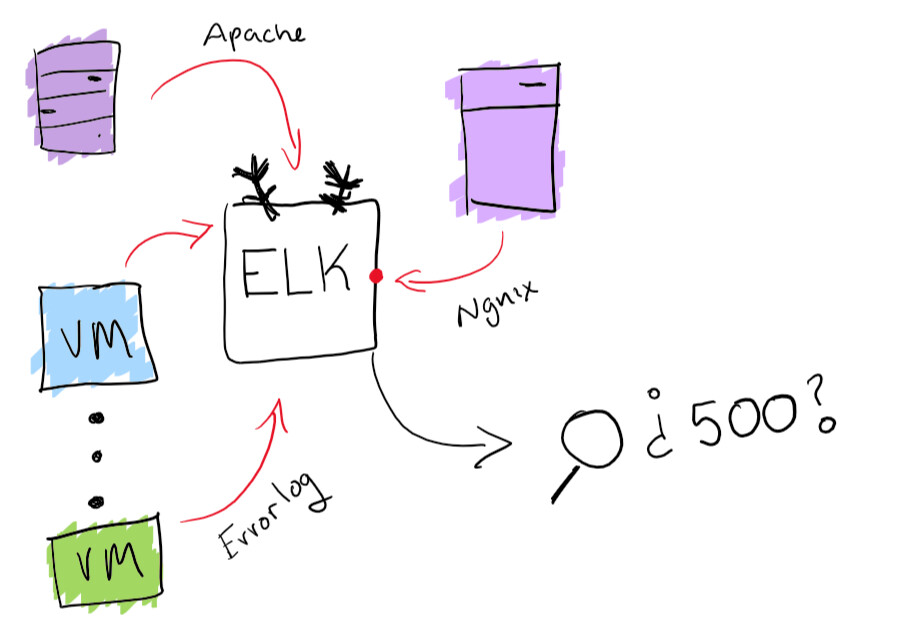
Funcionalidade de pilha ELK
Agentes de monitoramento
Agora que seu serviço está instalado e funcionando, você precisa verificar se ele está funcionando perfeitamente. A melhor maneira de fazer isso é executar vários agentes em paralelo e verificar se estão em execução e se as operações básicas são realizadas.
Neste ponto, você verifica se a montagem em execução está funcionando bem e funcionando bem .
Para projetos de pequeno a médio porte, recomendo o Postman para monitorar e documentar APIs. Mas, em geral, você só precisa ter certeza de que tem uma maneira de saber quando a falha ocorreu e receber alertas oportunos.
Escalonamento automático com base na carga
É muito simples. Se você tiver uma máquina virtual atendendo a solicitações e estiver se aproximando de 80% do uso de memória, poderá aumentar seus recursos ou adicionar mais máquinas virtuais ao cluster. A execução automática dessas operações é excelente para mudanças elásticas de potência sob carga. Mas você deve sempre ter cuidado com quanto dinheiro gasta e definir limites razoáveis.
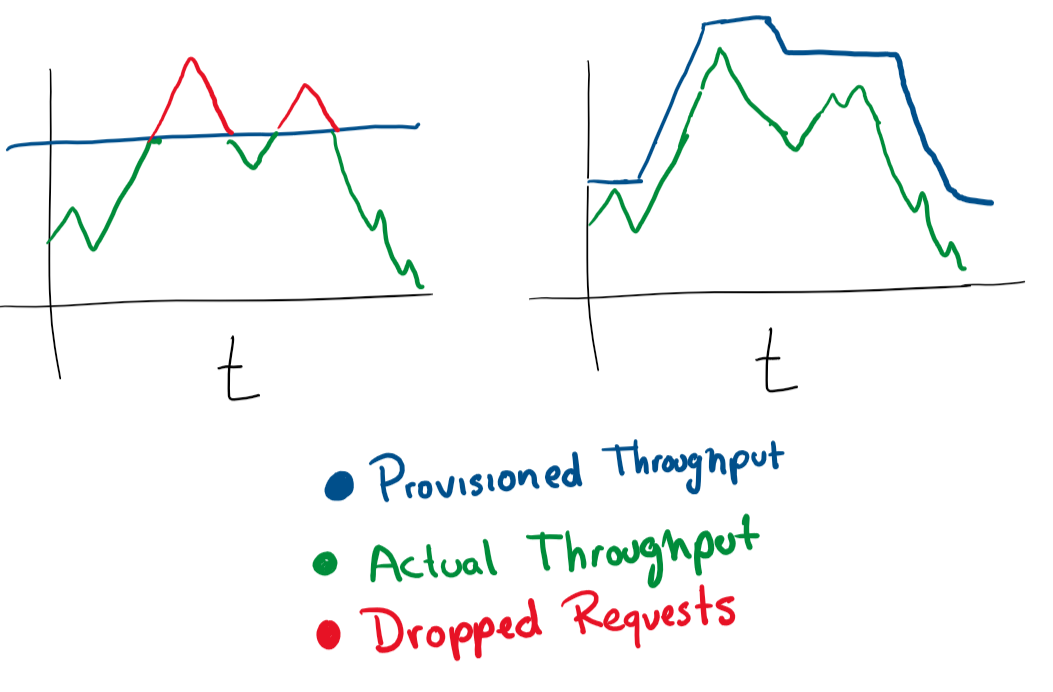
Na maioria dos serviços de nuvem, você pode configurar o escalonamento automático com mais servidores ou servidores mais poderosos.
Sistema de experimento
Uma boa maneira de implantar atualizações com segurança é poder testar algo para 1% dos usuários em uma hora. Certamente você já viu tais mecanismos em ação. Por exemplo, o Facebook mostra a partes do público uma cor diferente ou altera o tamanho da fonte para ver como os usuários percebem a mudança. Isso é chamado de teste A / B.
Até mesmo o lançamento de um novo recurso pode ser executado como um experimento e então descobrir como liberá-lo. Você também obtém a capacidade de "lembrar" ou alterar a configuração na hora, levando em consideração a função que causa a degradação do seu serviço.
Nível avançado
Aqui estão algumas dicas que são bastante difíceis de implementar. Provavelmente, você precisará de um pouco mais de recursos, por isso será difícil para uma pequena ou média empresa lidar com isso.
Implantações azul esverdeado
Isso é o que chamo de método de implantação "Erlang". Erlang foi amplamente usado quando as companhias telefônicas surgiram. Soft switches foram usados para rotear chamadas telefônicas. O foco principal do software nesses switches não era desligar chamadas durante uma atualização do sistema. Erlang tem uma ótima maneira de carregar um novo módulo sem travar o anterior.
Esta etapa depende da presença de um balanceador de carga. Digamos que você tenha a versão N do seu software e deseja implantar a versão N + 1.
Você pode simplesmente interromper o serviço e implantar a próxima versão em um momento que seja conveniente para seus usuários e obter algum tempo de inatividade. Mas suponha que você tenhatermos de SLA realmente estritos. Portanto, SLA de 99,99% significa que você pode ficar off-line apenas 52 minutos por ano.
Se você realmente deseja alcançar isso, precisa de duas implantações ao mesmo tempo:
- o que está agora (N);
- próxima versão (N + 1).
Você diz ao balanceador de carga para redirecionar uma porcentagem de seu tráfego para a nova versão (N + 1) enquanto você rastreia ativamente as regressões.
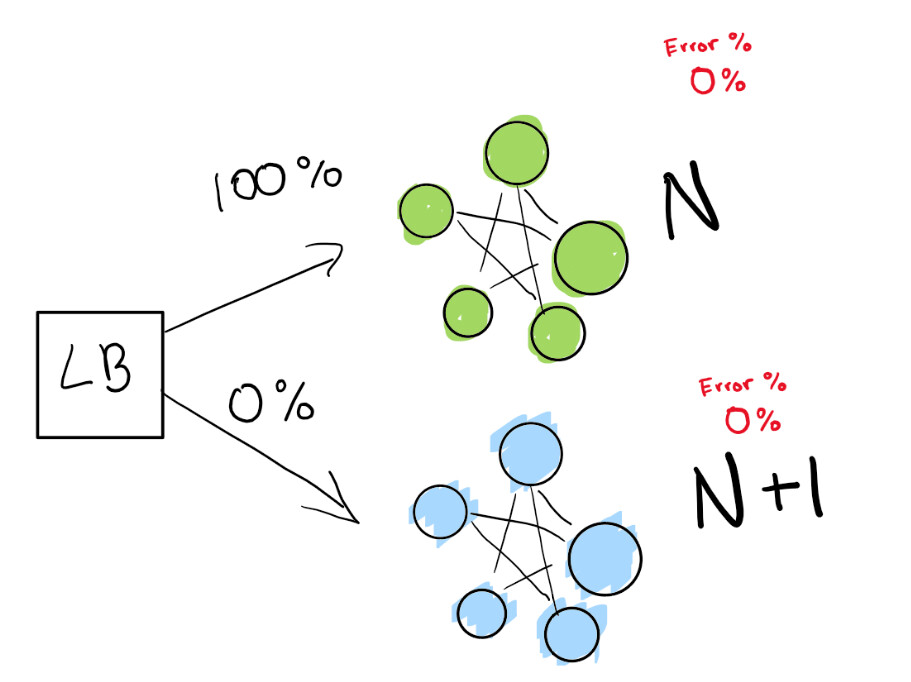
Aqui temos uma implantação verde N que funciona bem. Estamos tentando passar para a próxima versão desta implantação.
Primeiro, enviamos um teste bem pequeno para ver se nossa implantação N + 1 funciona com pouco tráfego:
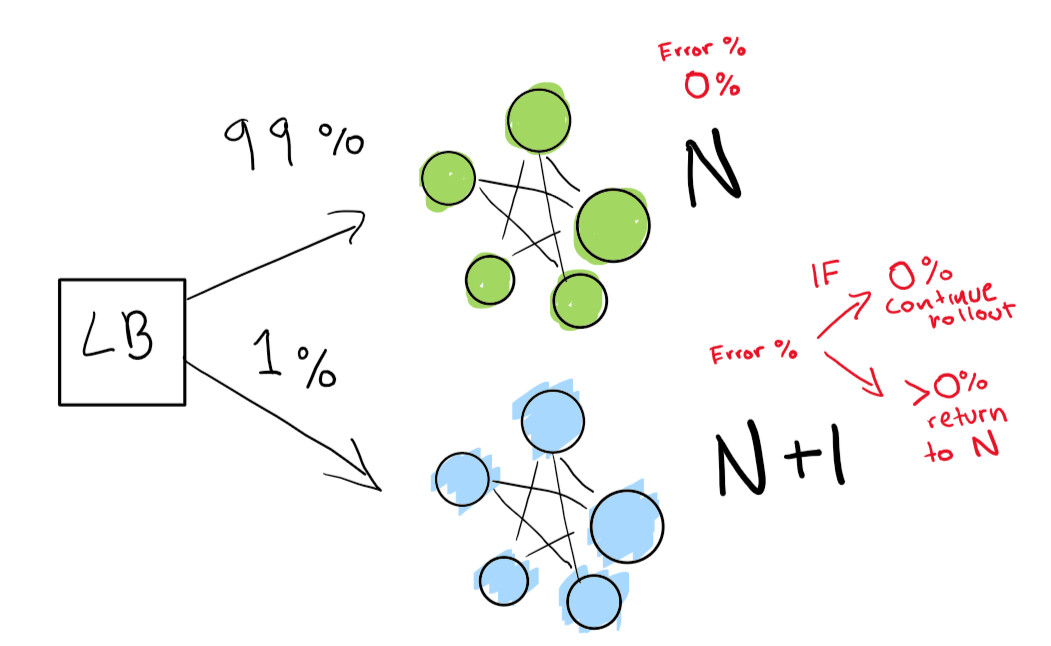
Finalmente, temos um conjunto de verificações automatizadas que acabamos executando até que nossa implantação seja concluída. Se você for muito, muito cuidadoso, também pode manter sua implantação N para sempre para uma reversão rápida em caso de regressão ruim:
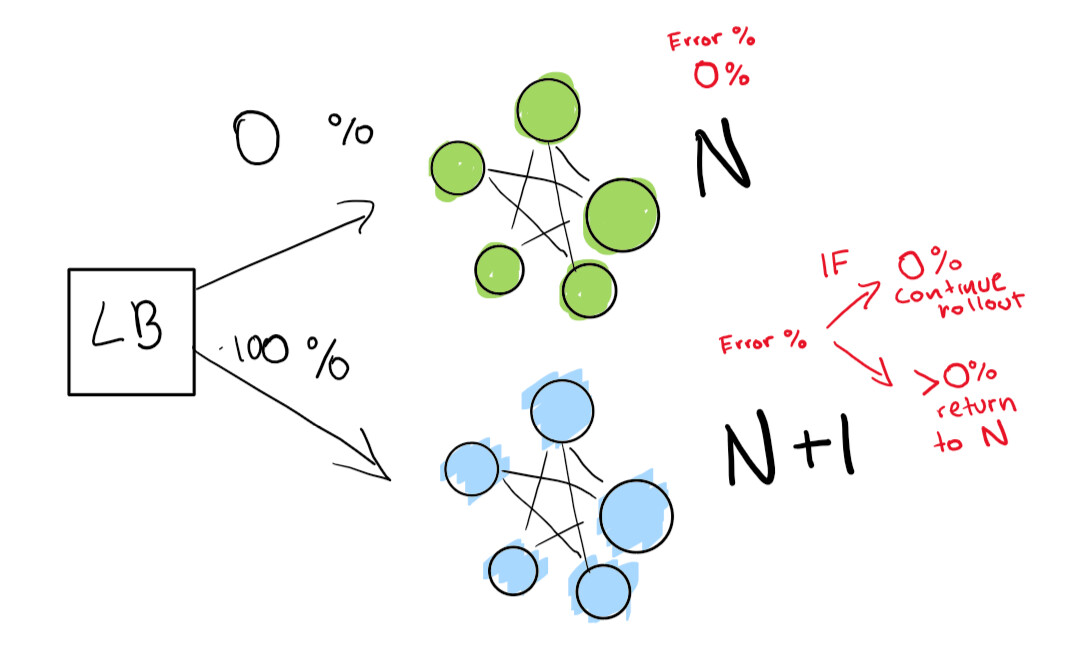
Se você quiser ir para um nível ainda mais avançado, deixe que tudo na implantação azul-verde seja feito automaticamente.
Detecção de anomalias e mitigação automática
Dado que você tem um registro centralizado e uma boa coleta de registros, você já pode definir metas mais altas. Por exemplo, prever falhas proativamente. Em monitores e registros, as funções são rastreadas e vários diagramas são construídos - e você pode prever com antecedência o que vai dar errado:
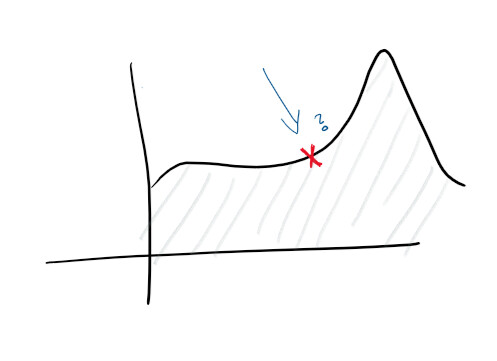
Com a descoberta de anomalias, você começa a estudar algumas das pistas que o serviço emite. Por exemplo, um pico no uso da CPU pode sugerir que um disco rígido está falhando, enquanto um pico nas solicitações significa que você precisa escalar. Este tipo de estatística permite-nos tornar o serviço pró-ativo.
Com esse insight, você pode escalar em qualquer dimensão, alterar de forma proativa e reativa as características das máquinas, bancos de dados, conexões e outros recursos.
Isso é tudo!
Essa lista de prioridades evitará muitos problemas se você estiver criando um serviço em nuvem.
O autor do artigo original convida os leitores a deixarem seus comentários e fazerem alterações. O artigo é distribuído como código aberto, o autor aceita solicitações pull no Github .
O que mais ler sobre o assunto: