
Meu nome é Alexander Deulin, trabalho no departamento de desenvolvimento de nossa própria "Fábrica de Microsserviços" de desenvolvimento na MegaFon. E quero contar a vocês sobre o caminho espinhoso do surgimento de caches Tarantool no cenário de nossa empresa, bem como implementamos a replicação do Oracle. E vou explicar imediatamente que, neste caso, o cache significa um aplicativo com um banco de dados.
Caches de Tarantool
Já falamos muito sobre como implementamos o Faturamento Unificado na MegaFon , não vamos nos alongar sobre isso, mas agora o projeto está em fase de conclusão. Portanto, apenas algumas estatísticas:
Com o que abordamos nossa tarefa:
- 80 milhões de assinantes;
- 300 milhões de perfis de assinantes;
- 2 bilhões de eventos transacionais para alterar o saldo por dia;
- 250 TB de dados ativos;
- > 8 PB de arquivos;
- e tudo isso está localizado em 5000 servidores em diferentes data centers.
Ou seja, estamos falando de um sistema altamente carregado, em que cada subsistema passou a atender 80 milhões de assinantes. Se antes tínhamos 7 instâncias e escala horizontal condicional, agora mudamos para o domínio. Costumava haver um monólito, mas agora temos DDD. O sistema é bem coberto pela API, dividido em subsistemas, mas nem em todos os lugares há um cache. Agora somos confrontados com o fato de que os subsistemas criam uma carga cada vez maior. Além disso, surgem novos canais que exigem que eles forneçam 5.000 solicitações por segundo por operação com uma latência de 50 ms em 95% dos casos e garantam disponibilidade em 99,99%.
Paralelamente, começamos a criar uma arquitetura de microsserviço.

Temos uma camada separada de caches, na qual os dados de cada subsistema são gerados. Isso torna os compostos fáceis de montar e isola os sistemas principais de cargas de trabalho pesadas de leitura.
Como construir um cache para subsistemas fechados?
Decidimos que precisamos criar caches nós mesmos, sem depender do fornecedor. O faturamento unificado é um ecossistema fechado. Ele contém muitos padrões de microsserviço, que têm várias APIs e seus próprios bancos de dados. No entanto, devido à natureza fechada, é impossível modificar nada.
Começamos a pensar em como podemos abordar nossos sistemas principais. Uma abordagem muito popular é o design orientado a eventos, quando recebemos dados de algum tipo de barramento: ou este é um tópico Kafka ou trocamos RabbitMQ. Você também pode obter dados do Oracle: por triggers, usando CQN (uma ferramenta gratuita da Oracle) ou Golden Gate. Como não podemos integrar ao aplicativo, as opções write-through e write-behind não estavam disponíveis para nós.
Recebendo dados do barramento despachante de mensagens
Gostamos muito da opção com filas e gerenciadores de mensagens. RabbitMQ e Kafka já são usados em "Faturamento unificado". Nós pilotamos um dos sistemas e obtivemos um excelente resultado. Recebemos todos os eventos do RabbitMQ e fazemos cold loading, a quantidade de dados não é muito grande.
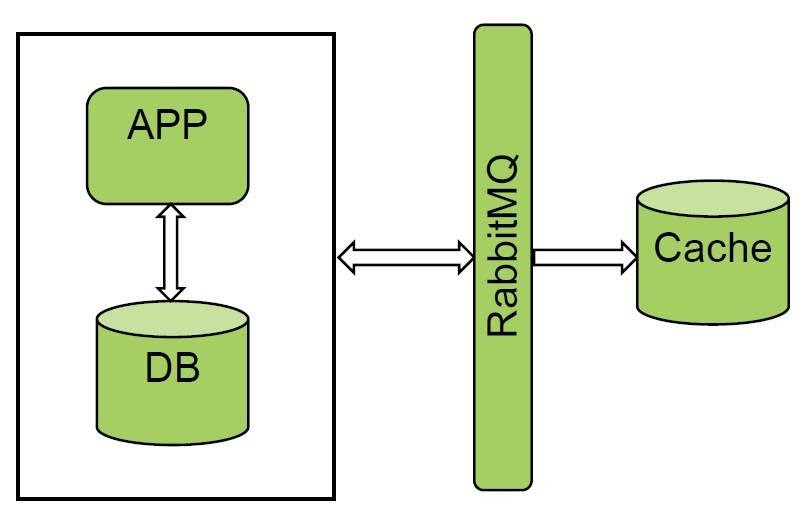
A solução funciona muito bem, mas nem todos os sistemas podem notificar os ônibus, então essa opção não funcionou para nós.
Recuperando dados do banco de dados: triggers
Ainda havia uma maneira de obter dados do banco de dados para preencher o cache.
A opção mais simples são os gatilhos. Mas não são adequados para aplicações de alta carga, porque, em primeiro lugar, modificamos o próprio sistema mestre e, em segundo lugar, este é um ponto adicional de falha. Se o gatilho repentinamente não conseguir gravar em algum tipo de placa temporária, obteremos degradação completa, incluindo o sistema mestre.

Recuperando dados do banco de dados: CQN
A segunda opção para obter dados do banco de dados. Usamos Oracle, e o fornecedor atualmente oferece suporte a apenas uma ferramenta gratuita para recuperar dados do banco de dados - CQN.
Este mecanismo permite que você assine notificações de mudança de operação DDL ou DML. Tudo é muito simples aí. Existem notificações de estilo JDBC e PL / SQL.
JDBC significa que notificamos a fila avançada e este evento é enviado ao sistema externo. Na verdade, é necessário um conector OSI externo. Não gostamos dessa opção, porque se perdermos nossa conexão com a Oracle, não poderemos ler nossa mensagem.
Escolhemos o PL / SQL porque nos permite interceptar a notificação e armazená-la em uma tabela temporária no mesmo banco de dados Oracle. Ou seja, desta forma você pode fornecer alguma integridade transacional.
Tudo funcionou bem no início, até que pilotamos uma base bastante carregada. As seguintes deficiências apareceram:
- Carga transacional na base. Quando interceptamos uma mensagem da fila de notificação, precisamos colocá-la na base. Ou seja, a carga de gravação dobra.
- Ele também usa uma fila avançada interna. E se o seu sistema mestre também o usar, pode surgir a competição pela fila.
- Encontramos um erro interessante nas tabelas particionadas. Se um commit fecha mais de 100 mudanças, então o CQN não captura tais mudanças. Abrimos um tíquete no Oracle, alteramos os parâmetros do sistema - não ajudou.
Para aplicações pesadas, o CQN definitivamente não é adequado. É bom para pequenas instalações, para trabalhar com algum tipo de dicionário, dados de referência.
Recuperando dados do banco de dados: Golden Gate
A boa e velha Golden Gate permanece. Inicialmente, não queríamos utilizá-lo, por se tratar de uma solução antiquada, ficamos intimidados com a complexidade do próprio sistema.

No próprio GG, havia duas instâncias adicionais que precisavam ser mantidas e não temos muito conhecimento de Oracle. Inicialmente foi bastante difícil, embora gostássemos muito das possibilidades da solução.
A combinação SCN + XID nos permitiu controlar a integridade transacional. A solução acabou por ser universal, tem um baixo impacto no sistema mestre de onde podemos receber todos os eventos. Embora a solução exija a compra de uma licença, isso não foi um problema para nós, pois a licença já estava disponível. Além disso, as desvantagens da solução incluem uma implementação complexa e o fato de que GG é um subsistema adicional.
conclusões
Que conclusões podem ser tiradas do acima?
Se você tiver um sistema fechado, será necessário pesquisar a natureza de sua carga e as formas de uso e selecionar a solução adequada. O ideal, em nossa opinião, é o design orientado a eventos, quando notificamos um tópico no Kafka e o agente de mensagens se torna o sistema mestre. Um tópico é um registro de ouro, o restante dos dados é obtido pelo sistema. Para sistemas fechados em nosso cenário, GG acabou sendo a solução de maior sucesso.
PIM - vitrine de comida
E agora, usando o exemplo de um dos produtos, vou contar como aplicamos essa solução. PIM é uma vitrine de produto baseada em SID. Ou seja, são todos os produtos do assinante que atualmente estão conectados a ele. Com base neles, as despesas são calculadas e a lógica do trabalho construída.
Arquitetura
Deixe-me lembrá-lo que neste artigo, "cache" significa uma combinação de um aplicativo e um banco de dados, este é o principal padrão de uso do Tarantool.
A peculiaridade do projeto PIM é que o sistema mestre Oracle original é "pequeno", apenas 10 bilhões de registros. Deve ser lido. E o maior problema que resolvemos foi o aquecimento do cache.
Por onde começamos?

As 10 tabelas principais fornecem 10 bilhões de registros. Queríamos lê-los de frente. Já que levantamos apenas dados quentes para o cache, e o Oracle armazena, entre outras coisas, dados históricos, tivemos que definir uma cláusula where e retirar esses 10 bilhões. Uma tarefa não trivial. A Oracle nos disse que isso não deveria ser feito: aumentou a carga do processador para 100%. Decidimos ir por outro caminho.
Mas, primeiro, algumas palavras sobre a arquitetura do cluster.
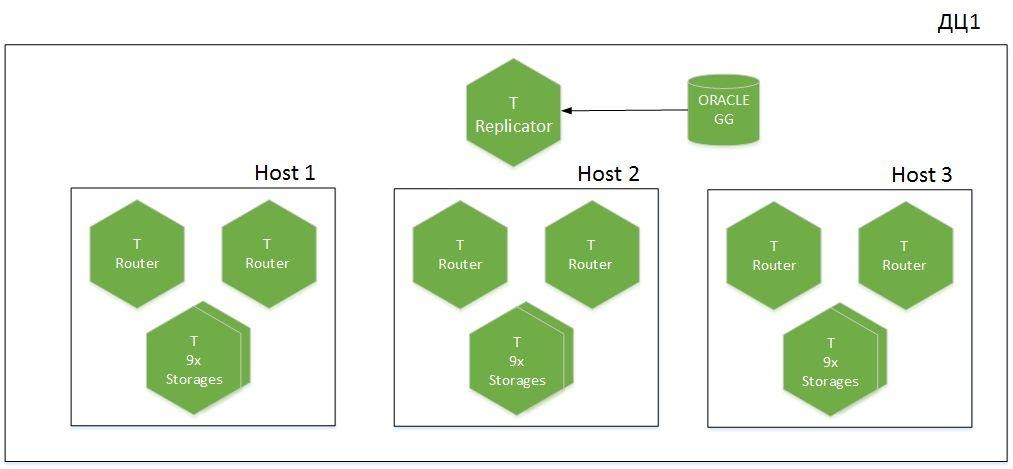
Este é um aplicativo fragmentado, 9 fragmentos em 6 hosts, distribuídos em dois datacenters. Temos o Tarantool com a função de Replicador, que recebe dados do Oracle, e outra instância chamada Importer é usada para inicialização a frio. Um total de 1,1 TB de dados ativos é gerado no cache.
Bota fria
Como resolvemos o problema da inicialização a frio? Tudo acabou sendo bastante trivial.

Como funciona todo o mecanismo? Removemos a cláusula where e lemos tudo. Primeiro, iniciamos o fluxo de redo-log para realmente receber as alterações online do banco de dados. Por meio da varredura completa, passamos por subseções, obtendo dados em lotes com normalização e filtragem. Nós salvamos as alterações, simultaneamente iniciamos o aquecimento a frio do cache e carregamos tudo em arquivos CSV. Existem 10 instâncias do importador em execução no cache, que, após serem lidas do Oracle, enviam dados para as instâncias do Tarantool. Para fazer isso, cada importador calcula o fragmento necessário e coloca os dados no próprio armazenamento necessário, sem carregar os roteadores.
Depois de carregar todos os dados do Oracle, reproduzimos o fluxo de trilhas do GG que se acumularam durante esse tempo. Quando SCN + XID atinge valores aceitáveis com o sistema mestre, consideramos que o cache está aquecido e incluímos a carga na leitura de sistemas externos.
Algumas estatísticas. Na Oracle, temos cerca de 2,5 TB de dados brutos. Nós os lemos por 5 horas, importamos para CSV. O carregamento no Tarantool com filtragem e normalização leva 8 horas. E por seis horas jogamos as toras acumuladas que chegam da trilha. Velocidade de pico de 600 mil registros / s. até 1 milhão em picos. Tarantool insere 1,1 TB de dados a 200 mil registros / s.
Agora, o aquecimento frio do cache em grandes volumes se tornou comum para nós, porque não temos muito impacto no Oracle.

Em vez da base, carregamos o I / O e a rede, por isso devemos primeiro nos certificar de que temos uma margem suficiente de largura de banda da rede, em nossos picos chega a 400 Mbit / s.
Como funciona a cadeia de replicação do Oracle para o Tarantool
Ao projetar o cache, decidimos economizar memória. Removemos toda a redundância, combinamos cinco tabelas em uma e obtivemos um esquema de armazenamento muito compacto, mas perdemos o controle sobre a consistência. Concluímos que é necessário repetir o DDL do Oracle. Isso nos permitiu controlar SCN + XIDs, armazenando-os em um espaço tecnológico separado para cada placa. Ao verificá-los periodicamente, podemos entender onde a replicação quebrou e, em caso de problemas, relemos os logs de arquivamento.
Sharding
Um pouco sobre armazenamento lógico de dados. Para eliminar o Map Reduce, tivemos que introduzir redundância de dados adicional e decompor dicionários em nossos próprios armazenamentos. Fizemos isso deliberadamente, porque nosso cache funciona principalmente para leitura. Não podemos integrá-lo ao sistema mestre, pois este aplicativo isola a carga de canais externos do sistema mestre. Lemos todos os dados sobre assinantes de um armazenamento. Nesse caso, perdemos desempenho de escrita, mas não é tão importante para nós, dicionários são atualizados com pouca frequência.
O que aconteceu no final?
Criamos um cache para nosso sistema fechado. Ocorreram alguns erros de filtragem, mas já os corrigimos. Estamos preparados para o surgimento de novos consumidores de alta carga. No verão passado, apareceu um novo sistema, que adicionava 5 a 10 mil solicitações por segundo, e não deixamos isso carregar no "Faturamento unificado". Também aprendemos como preparar a replicação do Oracle para o Tarantool, trabalhamos na transferência de grandes quantidades de dados sem carregar o sistema mestre.
O que ainda temos que fazer?
Estes são principalmente cenários operacionais:
- Controle automático de consistência de dados.
- Elabore o cenário de switch Oracle Active-Standby, tanto switchover quanto failover.
- Reproduzindo logs de arquivo de GG.
- — DDL- -. , DDL , .
- «»: ? https://habr.com/ru/article/470842/
- : Tarantool https://habr.com/ru/company/mailru/blog/455694/
- Telegram Tarantool https://t.me/tarantool_news
- Tarantool - https://t.me/tarantoolru