Desde a capacidade de processar grandes quantidades de informações e usar algoritmos de aprendizado de máquina com muito mais eficiência, até algoritmos de modelagem quântica que podem melhorar os cálculos (qualitativa e quantitativamente) para o projeto de novas drogas, previsão da estrutura da proteína, análise de vários processos em um organismo biológico e etc. Essas perspectivas incompreensíveis estão sujeitas a um grande entusiasmo da informação hoje, o que significa que é importante destacar as advertências e os desafios dessa nova tecnologia.
Aviso: A revisão é baseada em um artigo de um grupo de pesquisadores europeus do Reino Unido e da Suíça (Carlos Outeiral, Martin Strahm, Jiye Shi, Garrett M. Morris, Simon C. Benjamin, Charlotte M. Deane. "As perspectivas da computação quântica em biologia molecular computacional", WIREs Computational Molecular Science publicado por Wiley Periodicals LLC, 2020). As partes mais difíceis do artigo relacionadas a modelos matemáticos sofisticados não serão incluídas na revisão. Mas o material é inicialmente complexo e o leitor deve ter conhecimento de matemática e física quântica.
Mas se você pretende começar a estudar a aplicação de tecnologias quânticas em bioinformática, então, para entrar primeiro no assunto, sugere-se ouvir uma breve palestra de Viktor Sokolov, Pesquisador Sênior da M&S Decisions, que descreve alguns problemas modernos de modelagem de medicamentos:
Introdução
Desde o advento da computação de alto desempenho, algoritmos e modelos matemáticos têm sido usados para resolver problemas nas ciências biológicas - desde o estudo da complexidade do genoma humano até a modelagem do comportamento de biomoléculas. Métodos computacionais são regularmente usados hoje para analisar e extrair informações importantes de experimentos biológicos, bem como para prever o comportamento de objetos e sistemas biológicos. Na verdade, 10 dos 25 artigos científicos mais citados lidam com algoritmos computacionais usados em biologia [cf. aqui ], incluindo modelagem quântica [ aqui , aqui , aqui e aqui ], alinhamento de sequência [ aqui , aqui eaqui ], genética computacional [ver. aqui ] e difração de raios-X no processamento de dados [cf. aqui e aqui ].
Apesar desse progresso, muitos problemas em biologia permanecem insolúveis do ponto de vista de sua solução usando tecnologias computacionais existentes. Os melhores algoritmos para tarefas como prever o dobramento de proteínas, calcular a afinidade de ligação de um ligante a uma macromolécula ou encontrar o alinhamento genômico em grande escala ideal requer recursos computacionais que vão além até mesmo dos supercomputadores mais poderosos disponíveis hoje.
A solução para esses problemas pode estar em uma mudança de paradigma na tecnologia de computação. Na década de 1980, de forma independente, Richard Feynman [ver aqui ] e Yuri Manin [ver. aqui ] sugeriu o uso de efeitos da mecânica quântica para criar uma nova geração de computadores mais poderosa.
A teoria quântica provou ser uma descrição altamente bem-sucedida da realidade física e levou, desde seu início no início do século 20, a avanços como lasers, transistores e microprocessadores semicondutores. O computador quântico usa os algoritmos mais eficientes, usando operações que não são possíveis nas máquinas clássicas. Os processadores quânticos não funcionam mais rápido do que os computadores clássicos, mas funcionam de uma maneira completamente diferente, alcançando acelerações sem precedentes, evitando cálculos desnecessários. Por exemplo, o cálculo da função de onda eletrônica total da molécula de droga média em qualquer supercomputador moderno usando algoritmos convencionais deve levar mais tempo do que a idade total de nosso universo [ver Ref. aqui], embora até mesmo um pequeno computador quântico possa resolver esse problema em alguns dias. Encorajados por tal promessa de vantagem quântica, engenheiros e cientistas continuam sua busca por um processador quântico. No entanto, as dificuldades técnicas na fabricação, gerenciamento e proteção de sistemas quânticos são incrivelmente complexas e os primeiros protótipos surgiram apenas na última década.
É importante notar que os problemas técnicos de construção de computadores quânticos não impediram o desenvolvimento de algoritmos de computação quântica. Mesmo na ausência de hardware, os algoritmos podem ser analisados matematicamente, e o advento de simuladores de computador quântico de alto desempenho, bem como dos primeiros protótipos nos últimos anos, permitiu o avanço de pesquisas adicionais.
Vários desses algoritmos já mostraram aplicações potenciais promissoras em biologia. Por exemplo, um algoritmo para estimar a fase quântica torna possível calcular os valores próprios exponencialmente mais rápido [ver. aqui ], que pode ser usado para entender a correlação em grande escala entre partes de uma proteína ou para determinar a centralidade de um gráfico em uma rede biológica. O algoritmo quântico Harrow-Hasidim-Lloyd (HHL) [cf. aqui ] pode resolver alguns sistemas lineares exponencialmente mais rápido do que qualquer algoritmo clássico conhecido e também pode aplicar métodos de aprendizagem estatísticos com um processo de adaptação muito mais rápido e a capacidade de gerenciar grandes quantidades de dados.
Os algoritmos de otimização quântica têm um amplo campo de aplicação no campo do dobramento de proteínas e seleção de conformadores, bem como em problemas associados com a localização de mínimos ou máximos [ver aqui ]. Finalmente, a tecnologia foi recentemente desenvolvida para simular sistemas quânticos que prometem, por exemplo, produzir previsões precisas de interações droga-receptor [ver Ref. aqui ] ou para participar no estudo e compreensão de processos complexos e mecanismos químicos como a fotossíntese [ver. aqui ]. A computação quântica pode mudar significativamente os métodos da própria biologia, como a computação clássica fazia em sua época.
Recentes afirmações de supremacia quântica do Google [cf. aqui], embora contestado pela IBM [cf. aqui ], indicam que a era da computação quântica não está distante. Os primeiros processadores a usar efeitos quânticos para realizar cálculos impossíveis para a tecnologia de computador clássica são esperados na próxima década [cf. aqui ].
Nesta revisão, analisaremos os pontos-chave onde a computação quântica é uma promessa para a biologia computacional. Essas revisões analisam o impacto potencial da computação quântica em vários campos, incluindo aprendizado de máquina [veja. aqui , aqui e aqui ], química quântica [cf. aqui , aqui e aqui ] e síntese de drogas [ver.aqui ]. Também foi publicado recentemente um relatório do NIMH Workshop on Quantum Computing in Life Sciences [ver aqui ].
Nesta revisão, primeiro damos uma breve descrição do que se entende por computação quântica e uma breve introdução aos princípios do processamento de informação quântica. Em seguida, discutimos três áreas principais da biologia computacional, onde a computação quântica já mostrou desenvolvimentos algorítmicos promissores: métodos estatísticos, cálculos de estrutura eletrônica e otimização. Alguns tópicos importantes serão deixados de lado, por exemplo, algoritmos de string que podem afetar a análise de sequência [consulte aqui ], algoritmos de imagens médicas [ver. aqui ], algoritmos numéricos para equações diferenciais [aqui ] e outros problemas matemáticos ou métodos para analisar redes biológicas [ aqui ]. Finalmente, discutimos o impacto potencial da computação quântica na biologia computacional a médio e longo prazo.
1. Processamento de informação quântica
Os computadores quânticos prometem resolver problemas nas ciências biológicas, como prever as interações proteína-ligante ou compreender a coevolução dos aminoácidos nas proteínas. E não é fácil de resolver, mas sim exponencialmente mais rápido do que você pode imaginar com qualquer computador moderno. No entanto, essa mudança de paradigma requer uma mudança fundamental em nosso pensamento: os computadores quânticos são muito diferentes de seus predecessores clássicos. Os fenômenos físicos que fundamentam a vantagem quântica são freqüentemente ilógicos e contra-intuitivos, e usar um processador quântico requer uma mudança fundamental em nossa compreensão da programação. Nesta seção, apresentamos os princípios da informação quântica e como ela é processada para realizar cálculos.
Explicamos como as informações funcionam de maneira diferente em um sistema quântico, onde são armazenadas em qubits e como essas informações podem ser manipuladas usando portas quânticas. Como variáveis e funções em uma linguagem de programação, qubits e portas quânticas definem os elementos básicos de qualquer algoritmo. Também examinaremos por que a criação de um computador quântico é tecnicamente extremamente difícil e o que pode ser alcançado com a ajuda dos primeiros protótipos que são esperados nos próximos anos. Esta introdução cobrirá apenas os pontos principais; para um estudo abrangente, leia o livro de Nielsen e Chuang [ aqui ].
1.1. Elementos de algoritmos quânticos
1.1.1. Informações quânticas: uma introdução ao qubit
O primeiro problema em representar a computação quântica é entender como ela processa as informações. Em um processador quântico, as informações geralmente são armazenadas em qubits, que são os análogos quânticos dos bits clássicos. Um qubit é um sistema físico, como um íon, limitado por um campo magnético [ver. aqui ] ou um fóton polarizado [ver. aqui ], mas muitas vezes é falado de forma abstrata. Como o gato de Schrödinger, um qubit pode assumir não apenas os estados 0 ou 1, mas também qualquer combinação possível de ambos os estados. Quando um qubit é observado diretamente, ele não estará mais em uma superposição que colapsa em um dos estados possíveis, assim como o gato de Schrödinger está morto ou vivo após abrir a caixa [veja. aqui] Mais importante, quando vários qubits são combinados, eles podem se tornar correlacionados e as interações com qualquer um deles têm consequências para todo o estado coletivo. O fenômeno de correlação entre múltiplos qubits, conhecido como emaranhamento quântico, é um recurso fundamental na computação quântica.
Na informação clássica, a unidade fundamental de informação é o bit, um sistema com dois estados identificáveis, freqüentemente denotados 0 e 1. O análogo quântico, um qubit, é um sistema de dois estados, os estados dos quais são rotulados | 0⟩ e | 1⟩. Usamos a notação de Dirac, onde | *⟩ identifica um estado quântico. A principal diferença entre as informações clássicas e quânticas é que um qubit pode estar em qualquer superposição de estados | 0⟩ e | 1⟩:
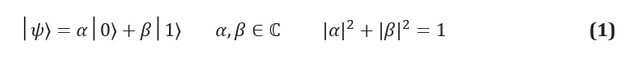
Os coeficientes complexos α e β são conhecidos como amplitudes de estados e estão relacionados a outro conceito-chave na mecânica quântica: o efeito da medição física. Como os qubits são sistemas físicos, você sempre pode criar um protocolo para medir seu estado. Se, por exemplo, os estados | 0⟩ e | 1⟩ correspondem aos estados do spin de um elétron em um campo magnético, então medir o estado de um qubit é simplesmente medir a energia do sistema. Os postulados da mecânica quântica ditam que, se o sistema está em uma superposição de resultados de medição possíveis, o próprio ato de medição deve mudar o estado. O sistema de superposição desmoronará no estágio de medição; a medição, portanto, destrói a informação transportada pelas amplitudes no qubit.
Implicações computacionais importantes surgem quando consideramos sistemas de múltiplos qubits que podem experimentar emaranhamento quântico. O entrelaçamento é um fenômeno no qual um grupo de qubits está correlacionado e qualquer operação em um desses qubits afetará o estado geral de todos eles. Um exemplo canônico de emaranhamento quântico é o paradoxo de Einstein-Podolsky-Rosen, apresentado em 1935 [cf. aqui ]. Considere um sistema de dois qubits, onde, uma vez que cada um dos qubits individuais pode assumir qualquer superposição de estados {| 0⟩ e | 1⟩}, o sistema composto pode assumir qualquer superposição de estados {| 00⟩, | 01⟩, | 10⟩, | 11 ⟩} (E, consequentemente, o sistema de N-qubits pode levar qualquer um doscadeias binárias, de {| 0 ... 0⟩ a | 1 ... 1⟩}. Uma das possíveis superposições do sistema são os chamados estados de Bell, um dos quais tem a seguinte forma: Se fizermos uma medição no primeiro qubit, podemos observar apenas | 0⟩ ou | 1⟩, cada um dos quais terá uma probabilidade de 1/2. Isso não faz nenhuma alteração para o caso de qubit único. Se o resultado para o primeiro qubit foi | 0⟩, o sistema entrará em colapso para o sistema | 01⟩ e, portanto, qualquer medição no segundo qubit dará | 1⟩ com probabilidade 1; da mesma forma, se a primeira medição fosse | 1⟩, a medição no segundo qubit daria | 0⟩. Uma operação (neste caso, uma medição com o resultado "0") aplicada ao primeiro qubit afeta os resultados que podem ser vistos quando o segundo qubit é medido subsequentemente.

A existência de emaranhamento é fundamental para a computação quântica útil. Foi provado que qualquer algoritmo quântico que não use emaranhamento pode ser aplicado a um computador clássico sem uma diferença significativa na velocidade [cf. aqui e aqui ]. Intuitivamente, a razão é a quantidade de informações que um computador quântico pode manipular. Se o sistema N qubit não estiver emaranhado, entãoas amplitudes de seu estado podem ser descritas pelas amplitudes de cada estado de um bit, ou seja, 2N amplitudes. No entanto, se o sistema estiver emaranhado, todas as amplitudes serão independentes, e o registrador qubit formarávetor dimensional. A capacidade dos computadores quânticos de manipular grandes quantidades de informações com múltiplas operações é uma das principais vantagens dos algoritmos quânticos e sustenta sua capacidade de resolver problemas exponencialmente mais rápido do que a tecnologia de computador clássica.
1.1.2. Portões quânticos
As informações armazenadas em qubits são processadas usando operações especiais conhecidas como portas quânticas. Portas quânticas são operações físicas, como um pulso de laser direcionado a um qubit de íon ou um conjunto de espelhos e divisores de feixe através dos quais um qubit de fóton deve viajar. No entanto, as portas são frequentemente vistas como operações abstratas. Os postulados da mecânica quântica impõem algumas condições estritas à natureza das portas quânticas em sistemas fechados, o que permite que sejam representadas como matrizes unitárias, que são operações lineares que preservam a normalização do sistema quântico.
Em particular, uma porta quântica aplicada a um registrador emaranhado de N qubits é equivalente a multiplicar a matriz × no vetor de entrada ... A capacidade de um computador quântico de armazenar e realizar cálculos de grandes quantidades de informações é da ordem de- ao manipular vários elementos - de ordem N - forma a base de sua capacidade de fornecer uma vantagem potencialmente exponencial sobre os computadores clássicos.
Essencialmente, portas quânticas são qualquer operação permitida em um sistema qubit. Os postulados da mecânica quântica impõem duas restrições estritas à forma das portas quânticas. Os operadores quânticos são lineares. Linearidade é uma condição matemática que, no entanto, tem profundas implicações para a física dos sistemas quânticos e, portanto, como eles podem ser usados para computação. Se o operador linear é aplicado à superposição de estados, então o resultado é uma superposição dos estados individuais afetados pelo operador. Em um qubit, isso significa: Os operadores lineares podem ser representados na forma de matrizes, que são simplesmente tabelas que indicam o efeito de um operador linear em cada estado básico. A Figura 1 (c, d) mostra uma representação matricial de uma de duas portas de qubit e duas portas de um bit. No entanto, nem toda matriz representa portas quânticas reais. Esperamos que as portas quânticas aplicadas a um conjunto de qubits forneçam um conjunto real diferente de qubits, em particular, um normalizado (por exemplo, na equação (3), esperamos que
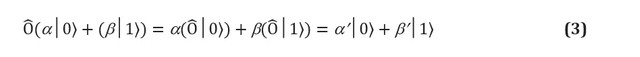
) Esta condição é satisfeita apenas se a matriz que representa as portas quânticas for unitária, ou seja, U † U = UU † = I, onde U † é a matriz U na qual as linhas e colunas foram reorganizadas, e cada número complexo foi conjugado (ou seja, cada elemento imaginário adquire um fator negativo). Matriz unitária arbitrária × é uma porta quântica N-qubit totalmente válida.
Na computação clássica, há apenas uma porta não trivial para um bit: a porta NOT, que converte 0 em 1 e vice-versa. Na computação quântica, há um número infinito de matrizes unitárias 2 × 2, e qualquer uma delas é uma possível porta quântica de um qubit. Um dos primeiros sucessos da computação quântica foi a descoberta de que esta vasta gama de possibilidades poderia ser realizada com um conjunto de portas universais afetando um e dois qubits [ver Ref. aqui] Em outras palavras, dadas portas quânticas arbitrárias, há um circuito de portas de um e dois qubit que pode acioná-lo com precisão arbitrária. Infelizmente, isso não significa que a aproximação seja eficaz. A maioria das portas quânticas só pode ser aproximada por um número exponencial de portas de nosso conjunto universal. Mesmo que essas portas possam ser usadas para resolver problemas úteis, sua implementação levará uma quantidade de tempo exponencialmente grande e pode negar qualquer vantagem quântica. FIGURA 1 (a) Comparação de um bit clássico com um bit quântico ou "qubit". Enquanto um bit clássico só pode assumir um de dois estados, 0 ou 1, um bit quântico pode assumir qualquer estado da forma

... Qubits simples são frequentemente descritos usando a representação da esfera de Bloch, onde θ e ϕ são entendidos como ângulos azimutais e polares em uma esfera de raio unitário. (b) Um esquema de um qubit íon trap, uma das abordagens mais comuns para a computação quântica experimental. Ion (frequentemente) é mantido em alto vácuo por campos eletromagnéticos e exposto a um forte campo magnético. Os níveis hiperfinos são separados de acordo com o efeito Zeeman e os dois níveis selecionados são selecionados como estados | 0⟩ e | 1⟩. Portas quânticas são implementadas por pulsos de laser apropriados, geralmente envolvendo outros níveis eletrônicos. Este diagrama foi adaptado de [ver. aqui ]. (c) Diagrama de um circuito quântico que implementa X ou o quantum de negação controlada (CNOT).
A representação e mudança na esfera de Bloch são mostradas. (d) Circuito quântico para gerar o estado Bellusando uma porta Hadamard e uma porta CNOT (negação controlada). A linha pontilhada no meio do contorno indica o estado após a válvula Hadamard ser aplicada.
1.2. Hardware quântico
Algoritmos quânticos só podem resolver problemas interessantes se forem executados no hardware quântico correto. Existem muitas propostas concorrentes para a criação de um processador quântico baseado em íons aprisionados [ver. aqui ], circuitos supercondutores [ver. aqui ] e dispositivos fotônicos [ver. aqui] No entanto, todos eles enfrentam um problema comum: erros computacionais que podem literalmente arruinar o processo computacional. Um dos pilares da computação quântica é a descoberta de que esses erros podem ser eliminados com códigos de correção de erros quânticos. Infelizmente, esses códigos também requerem um grande aumento no número de qubits, portanto, melhorias técnicas significativas são necessárias para atingir a tolerância a falhas.
Existem muitas fontes de erro que podem afetar um processador quântico. Por exemplo, a conexão de um qubit com seu ambiente pode levar ao colapso do sistema em um de seus estados clássicos - um processo conhecido como decoerência.... Pequenas flutuações podem transformar portas quânticas, o que acabará por levar a resultados diferentes do esperado. As portas menos sujeitas a erros até o momento foram registradas em um processador de íons aprisionados, com uma frequência de um erro porportas de um qubit e com taxa de erro de 0,1% para portas de dois qubit [ aqui e aqui ]. Para fins de comparação, um trabalho recente do Google relatou fidelidade de 0,1% para portas de um qubit e 0,3% para portas de dois qubit em um processador supercondutor [ver Ref. aqui ]. Dado que a falha de um gateway pode arruinar o cálculo, é fácil ver que a propagação do erro pode tornar o cálculo sem sentido após uma pequena sequência de elementos.
Uma das principais direções da computação quântica é o desenvolvimento de códigos de correção de erros quânticos. Na década de 1990, vários grupos de pesquisa provaram que esses códigos podem alcançar cálculos tolerantes a falhas, desde que as taxas de erro de porta estejam abaixo de um certo limite, que depende do código [ver. aqui , aqui , aqui e aqui ]. Uma das abordagens mais populares, o código de superfície, pode operar com taxas de erro próximas de 1% [consulte a Ref. aqui ].
Infelizmente, os códigos de correção de erros quânticos requerem um grande número de qubits físicos reais para codificar o qubit lógico abstrato que é usado para computação, e essa sobrecarga aumenta com a taxa de erro. Por exemplo, um algoritmo quântico para fatorar números primos [ver. aqui ] poderia decompor silenciosamente um número de 2.000 bits usando cerca de 4.000 qubits e, a 16 GHz, esse processo levaria cerca de um dia de trabalho. Supondo que a taxa de erro seja de 0,1%, o mesmo algoritmo, usando o código de superfície para corrigir os erros do ambiente, levaria vários milhões de qubits e a mesma quantidade de tempo [ver. aqui] Considerando que o registro atual para um processador quântico programável e controlado é de 53 qubits [ver. aqui ], ainda há um longo caminho a percorrer nessa direção de pesquisa.
Muitos grupos têm feito esforços para desenvolver algoritmos que podem ser executados nos chamados processadores quânticos de ruído de média escala [ver Ref. aqui ]. Por exemplo, algoritmos variacionais combinam um computador clássico com um pequeno processador quântico, realizando uma grande quantidade de cálculos quânticos curtos que podem ser realizados antes que o ruído se torne significativo.
Esses algoritmos geralmente usam um circuito quântico parametrizado, que executa uma tarefa particularmente difícil, e usam um computador clássico para otimizar os parâmetros. O método de resolução é uma região de redução de erros na qual, em vez de atingir tolerância a falhas, foi feita uma tentativa de minimizar os erros com o mínimo de esforço para acionar circuitos de portas maiores. Há várias abordagens que incluem o uso de operações adicionais para descartar execuções com erros [consulte. aqui ] ou manipulação da taxa de erro para extrapolar para o resultado correto [cf. aqui e aqui] Embora as principais aplicações exijam computadores quânticos tolerantes a falhas muito grandes; espera-se que os dispositivos disponíveis na próxima década resolvam esses problemas [ver aqui ].
2. Métodos estatísticos e aprendizado de máquina
Em biologia computacional, onde o objetivo é frequentemente coletar grandes quantidades de dados, métodos estatísticos e aprendizado de máquina são técnicas essenciais. Por exemplo, em genômica, modelos ocultos de Markov (HMM) são amplamente usados para anotar informações sobre genes [consulte aqui ]; na descoberta de drogas, uma ampla gama de modelos estatísticos foi desenvolvida para avaliar as propriedades moleculares ou para prever a ligação ligante-proteína [ver. aqui ]; e na biologia estrutural, redes neurais profundas têm sido usadas para prever conexões de proteínas [ver. aqui ] e estrutura secundária [ver. aqui ], e mais recentemente também estruturas tridimensionais de proteínas [ver. aqui ].
O treinamento e o desenvolvimento de tais modelos costumam exigir muito do computador. Um grande catalisador para os avanços recentes no aprendizado de máquina foi a compreensão de que as unidades de processamento gráfico de uso geral (GPUs) podem acelerar drasticamente o aprendizado. Ao fornecer algoritmos exponencialmente mais rápidos para aprendizado de máquina, os modelos de computação quântica podem fornecer interesse semelhante no foco de aplicação para problemas científicos.
Nesta seção, explicaremos como a computação quântica pode acelerar vários métodos de aprendizado estatístico.
2.1. Vantagens e desvantagens do Quantum Machine Learning
Primeiro, examinamos os benefícios que um computador quântico oferece para o aprendizado de máquina. Exceto por exemplos idealizados, os computadores quânticos não podem aprender mais informações do que um computador clássico [cf. aqui ]. No entanto, em princípio, eles podem ser muito mais rápidos e capazes de processar muito mais dados do que seus equivalentes clássicos. Por exemplo, o genoma humano contém 3 bilhões de pares de bases, que podem ser armazenados em 1,2 ×bits clássicos - aproximadamente 1,5 gigabytes. Um registro de N qubits incluiamplitudes, cada uma das quais pode representar um bit clássico, definindo a amplitude k-th para 0 ou 1 com um fator de normalização apropriado. Portanto, o genoma humano pode ser armazenado em ~ 34 qubits. Embora essas informações não possam ser extraídas de um computador quântico, até que um determinado estado seja preparado, será possível executar nele certos algoritmos de aprendizado de máquina. Mais importante, dobrar o tamanho do registro para 68 qubits deixa espaço suficiente para armazenar o genoma completo de cada pessoa viva no mundo. A apresentação e análise de tais grandes quantidades de dados seriam bastante consistentes com as capacidades até mesmo de um pequeno computador quântico tolerante a falhas.
As operações para processar essas informações também podem ser exponencialmente mais rápidas. Por exemplo, vários algoritmos de aprendizado de máquina são limitados à inversão de longo prazo da matriz de covariância com uma penalidadenas dimensões da matriz. No entanto, o algoritmo proposto por Harrow, Hassidim e Lloyd [cf. aqui ], permite que você inverta a matriz emsob algumas condições. O principal insight é que, ao contrário das GPUs, que aceleram os cálculos por meio do paralelismo maciço, os algoritmos quânticos têm a vantagem da complexidade dos algoritmos computacionais usados diretamente. Em alguns casos, especialmente com a aceleração exponencial atual, os computadores quânticos de médio porte podem resolver problemas de aprendizagem que estão disponíveis apenas para os maiores supercomputadores clássicos disponíveis atualmente.
O armazenamento e processamento de dados aprimorados têm benefícios secundários. Um dos pontos fortes das redes neurais é sua capacidade de encontrar representações concisas de dados [ver. aqui] Como as informações quânticas são mais gerais do que as clássicas (afinal, os estados de um bit clássico são subdivididos em autoestados | 0⟩ e | 1⟩, ou um qubit), é inteiramente possível que os modelos quânticos de aprendizado de máquina possam assimilar melhor as informações do que os modelos clássicos ... Por outro lado, algoritmos quânticos com complexidade logarítmica de tempo também melhoram a confidencialidade dos dados [ver. aqui ]. Como o treinamento do modelo requere requer a reconstrução da matriz, pois para um conjunto de dados grande o suficiente é impossível recuperar uma parte significativa das informações, embora o treinamento efetivo do modelo ainda seja possível. No contexto da pesquisa biomédica, isso pode facilitar a troca de dados, garantindo a confidencialidade.
Infelizmente, embora os algoritmos de aprendizado de máquina quântica no papel possam superar as contrapartes clássicas, ainda existem dificuldades práticas. Os algoritmos quânticos são freqüentemente sub-rotinas que transformam a entrada em saída. Os problemas surgem precisamente nestes dois estágios: como preparar entradas adequadas e como extrair informações das saídas [ver. aqui ]. Suponha, por exemplo, que estejamos usando o algoritmo HHL [ver. aqui ] para resolver um sistema linear da forma... No final da sub-rotina, o algoritmo produzirá o registrador qubit no seguinte estado: Aqui
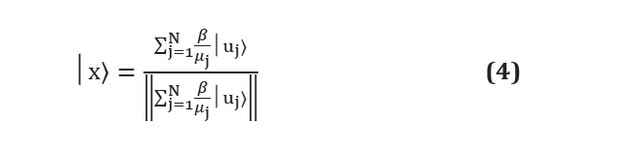
e São os autovetores e autovalores de A, e - coeficiente j-ésimo é expresso em termos dos autovetores de A, e o denominador é simplesmente uma constante de normalização. Pode-se ver que isso corresponde aos coeficientes, que são armazenados nas amplitudes de vários estados como e não são diretamente acessíveis. A medição do registro qubit levará ao seu colapso em um dos estados do autovetor e a reestimar as amplitudes de cada medidas necessárias , que em primeiro lugar supera qualquer vantagem do algoritmo quântico.
HHL e muitos outros algoritmos são úteis apenas para calcular a propriedade global de uma solução, como o valor esperado. Em outras palavras, o HHL não pode fornecer uma solução para um sistema de equações ou inverter uma matriz em tempo logarítmico, a menos que estejamos interessados apenas nas propriedades globais da solução, que podem ser obtidas usando várias medições fisicamente observáveis. Isso limita o uso de algumas rotinas, mas tem havido muitas sugestões para contornar esse problema.
Inserir informações em um computador quântico é um problema muito maior. A maioria dos algoritmos de aprendizado de máquina quântica assume que o computador quântico tem acesso ao conjunto de dados na forma de um estado de superposição; por exemplo, há um registrador qubit que está no estado da forma: Aqui - | bin (j) é um estado que atua como um índice, e

É a amplitude correspondente. Isso pode ser usado, por exemplo, para armazenar os elementos de um vetor ou matriz. Em princípio, existe um circuito quântico que pode preparar esse estado agindo, digamos, no estado | 0 ... 0⟩. No entanto, sua implementação pode ser muito difícil, pois esperamos que a aproximação de um estado quântico aleatório seja exponencialmente difícil e destrua qualquer vantagem quântica possível.
A maioria dos algoritmos quânticos assume acesso à memória quântica de acesso aleatório (QRAM) [ver. aqui ], que é um dispositivo de caixa preta capaz de construir essa superposição. Embora alguns desenhos tenham sido propostos [ver. aqui e aqui], até onde sabemos, não há nenhum dispositivo funcionando ainda. Além disso, mesmo que tal dispositivo estivesse disponível, não há garantia de que ele não criará gargalos que superem os benefícios do algoritmo quântico. Por exemplo, uma proposta recente baseada em esquema para QRAM [cf. aqui ] mostra o custo linear inevitável do número de estados que supera qualquer algoritmo de tempo de log. Finalmente, mesmo que o QRAM não introduza nenhum custo adicional, o pré-processamento clássico ainda precisará ser feito - para o exemplo do genoma, seria necessário o acesso a 12 exabytes de armazenamento clássico.
Finalmente, devemos enfatizar que os algoritmos de aprendizado de máquina quântica não estão isentos de um dos problemas mais comuns em aplicações práticas: a falta de dados relevantes. A disponibilidade de grandes quantidades de dados é crítica para o sucesso de muitas aplicações práticas da IA em ciência molecular, como o desenvolvimento molecular de novo [ver Ref. aqui ]. No entanto, o poder dos algoritmos quânticos pode ser útil como desenvolvimento científico e tecnológico, como o surgimento de laboratórios autogerenciados [ver. aqui ] fornecem mais e mais dados.
O aprendizado de máquina quântico tem o potencial de transformar a maneira como processamos e analisamos dados biológicos. No entanto, os atuais desafios práticos de implementação de tecnologias quânticas ainda são significativos.
2.2. Algoritmos de aprendizado de máquina quântica
2.2.1. Aprendendo sem professor
O aprendizado não supervisionado inclui várias técnicas para extrair informações de conjuntos de dados não marcados. Em biologia, onde o sequenciamento de última geração e a grande colaboração internacional estimularam a coleta de dados, esses métodos encontraram uso generalizado, por exemplo, para identificar ligações entre famílias de biomoléculas [ver. aqui ] ou genomas anotados [ver. aqui ].
Um dos algoritmos de aprendizagem não supervisionados mais populares é a análise de componentes principais (PCA), que tenta reduzir a dimensionalidade dos dados encontrando combinações lineares de recursos que maximizam a variância [cf. aqui] Este método é amplamente utilizado em todos os tipos de conjuntos de dados de alta dimensão, incluindo microarray de RNA e dados de espectrometria de massa [ver aqui ]. Um algoritmo quântico para PCA foi proposto por um grupo de pesquisadores [ver. aqui ]. Essencialmente, este algoritmo constrói uma matriz de covariância de dados em um computador quântico e usa uma sub-rotina conhecida como estimativa de fase quântica para calcular os vetores próprios em tempo logarítmico. A saída do algoritmo é um estado de superposição da forma: Aqui

É o j-ésimo componente principal, e - o autovalor correspondente. Uma vez que o PCA está interessado em grandes valores próprios, que são os principais componentes da variância, a medição do estado final fornecerá um componente principal adequado com alta probabilidade. A repetição do algoritmo várias vezes fornecerá um conjunto de componentes principais. Esse procedimento é capaz de reduzir a dimensão da vasta quantidade de informações que pode ser armazenada em um computador quântico.
Um algoritmo quântico também foi proposto para um método específico para analisar dados topológicos, nomeadamente para homologia estável [ver. aqui ]. A análise de dados topológicos tenta extrair informações usando propriedades topológicas na geometria dos conjuntos de dados; foi usado, por exemplo, no estudo de agregação de dados [ver.aqui ] e análise de rede [ver. aqui ]. Infelizmente, os melhores algoritmos clássicos possuem uma dependência exponencial na dimensão do problema, o que limita sua aplicação. Algoritmo Lloyd et al. também usa uma rotina de estimativa de fase quântica para acelerar exponencialmente a diagonalização da matriz, atingindo a complexidade... A presença de um algoritmo eficiente para a realização de análises topológicas pode estimular sua aplicação na análise de problemas em ciências biológicas.
2.2.2. Aprendizagem supervisionada
Aprendizagem supervisionada refere-se a um conjunto de métodos que podem ser usados para fazer previsões com base em dados rotulados. O objetivo é construir um modelo que possa classificar ou prever as propriedades de exemplos invisíveis. O aprendizado supervisionado é amplamente utilizado em biologia para resolver problemas tão diversos quanto prever a afinidade de ligação de um ligante para uma proteína [ver aqui ] e diagnóstico de doenças por computador [ver. aqui ]. Vejamos três abordagens de aprendizagem supervisionada.
Máquina de vetores de suporte(English support vector machine - SVM) é um algoritmo de aprendizagem de máquina que encontra o hiperplano ideal para separar as classes de dados. O SVM tem sido amplamente utilizado na indústria farmacêutica para classificar dados de moléculas pequenas [cf. aqui ]. Dependendo do kernel, o treinamento SVM geralmente parte de antes ... Rebentrost [ver. aqui ] apresentou um algoritmo quântico que pode treinar um SVM com um kernel polinomial eme, mais tarde, foi estendido ao núcleo da função de base radial (RBF) [ver. aqui ]. Infelizmente, não está claro como implementar as operações não lineares que são amplamente utilizadas no SVM, visto que as operações quânticas são limitadas a ser lineares. Por outro lado, um computador quântico permite outros tipos de kernels que não podem ser implementados em um computador clássico [ver. aqui ].
A regressão de processo gaussiana (GP) é uma técnica comumente usada para construir modelos substitutos, por exemplo, na otimização Bayesiana [ver aqui ]. Os GPs também são amplamente usados para criar modelos quantitativos de relação estrutura-atividade (QSAR) de propriedades de medicamentos.aqui ], e recentemente também para modelar a dinâmica molecular [ver. aqui ]. Uma das desvantagens da regressão GP é o alto valorinversão da matriz de covariância. Zhao e colegas [ver. aqui ] sugeriu usar o algoritmo HHL para sistemas lineares para inverter esta matriz, alcançando aceleração exponencial (desde que a matriz seja esparsa e bem condicionada) - uma propriedade que é frequentemente alcançada por matrizes de covariância. Mais importante, este algoritmo foi estendido para calcular o logaritmo da probabilidade limite [cf. aqui ], que é uma etapa importante para a otimização de hiperparâmetros.
Um dos métodos mais comuns em biologia computacional é o modelo de Markov oculto (HMM), que é amplamente usado na anotação de genes computacionais e alinhamento de sequência [cf. aqui] Este método contém vários estados ocultos, cada um dos quais associado a uma cadeia de Markov; as transições entre estados ocultos levam a mudanças na distribuição subjacente. Basicamente, o HMM não pode ser implementado diretamente em um computador quântico: a amostragem requer algum tipo de medição que interromperá o sistema. Porém, existe uma formulação em termos de sistemas quânticos abertos, ou seja, um sistema quântico que está em contato com o meio ambiente, que admite um sistema de Markov [ver. aqui ]. Embora nenhuma melhoria tenha sido proposta para o algoritmo Baum-Welch clássico para treinar HMMs, os HMMs quânticos foram considerados mais expressivos: eles podem reproduzir uma distribuição com menos estados ocultos [cf. aqui] Isso poderia levar a uma aplicação mais ampla do método em biologia computacional.
2.2.3. Redes neurais e aprendizado profundo
Desenvolvimentos recentes em aprendizado de máquina foram estimulados pela descoberta de que várias camadas de redes neurais artificiais podem detectar estruturas complexas em dados brutos [ver pág. aqui ]. O aprendizado profundo começou a permear todas as disciplinas científicas e, na biologia computacional, seus avanços incluem a previsão precisa de ligações de proteínas. aqui ], diagnóstico aprimorado de algumas doenças [ver. aqui ], design molecular [cf. aqui ] e modelagem [ver. aqui e aqui ].
Dados os avanços significativos no estudo de redes neurais, um trabalho significativo foi feito para desenvolver análogos quânticos que podem conduzir a melhorias adicionais na tecnologia.
O nome rede neural artificial geralmente se refere a um perceptron multicamadas de uma rede neural, onde cada neurônio pega uma combinação linear ponderada de suas entradas e retorna o resultado por meio de uma função de ativação não linear. O principal desafio no desenvolvimento de um análogo quântico é como implementar uma função de ativação não linear usando portas quânticas lineares. Ultimamente, tem havido muitas propostas e algumas idéias incluem medições [ver p. aqui , aqui e aqui ], portões quânticos dissipativos [ aqui], computação quântica com uma variável contínua [ aqui ] e a introdução de qubits adicionais para a construção de portas lineares que simulam a não linearidade [ver. aqui ]. Essas abordagens visam implementar uma rede neural quântica que deve ser mais expressiva do que uma rede neural clássica devido ao maior poder da informação quântica. As vantagens ou desvantagens de escalar o treinamento de um perceptron multicamadas em um computador quântico não são claras, embora o foco esteja na possível expressividade aprimorada desses modelos.
Uma grande quantidade de esforços recentes se concentrou nas máquinas de Boltzmann, redes neurais recorrentes capazes de atuar como modelos generativos. Uma vez treinados, eles podem gerar novos padrões semelhantes ao conjunto de treinamento.
Os modelos gerativos têm aplicações importantes, por exemplo, no projeto molecular de novo [cf. aqui e aqui ]. Embora as máquinas de Boltzmann sejam muito potentes, é necessário resolver o complexo problema de amostragem da distribuição de Boltzmann para calcular gradientes e realizar treinamentos, o que limita sua aplicação prática. Algoritmos quânticos foram propostos usando a máquina D-Wave [ver. aqui , aqui e aqui ] ou um algoritmo de circuito [ver.aqui ]; esta amostra da distribuição de Boltzmann é quadraticamente mais rápida do que é possível na versão clássica [ver. aqui ].
Recentemente, uma heurística para o treinamento eficiente de máquinas quânticas de Boltzmann foi proposta, baseada na termalização do sistema [ver. aqui ]. Além disso, em alguns artigos, implementações quânticas de redes adversárias geradoras (GANs) foram propostas [ver. aqui , aqui e aqui ]. Esses desenvolvimentos envolvem o aprimoramento de modelos generativos conforme o hardware de computação quântica se desenvolve.
3. Simulação eficaz de sistemas quânticos
De acordo com os modelos, a química é regulada pela transferência de elétrons. As reações químicas, assim como as interações entre entidades químicas, também são controladas pela distribuição dos elétrons e pela paisagem de energia livre que eles formam. Problemas como prever a ligação do ligante a uma proteína ou compreender a via catalítica de uma enzima se resumem a compreender o ambiente eletrônico. Infelizmente, modelar esses processos é extremamente difícil. O algoritmo mais eficiente para calcular a energia de um sistema de elétrons, a interação de configuração total (FCI), que escala exponencialmente conforme o número de elétrons aumenta, e mesmo moléculas com vários átomos de carbono mal estão disponíveis para pesquisa computacional [ver. aqui] Embora existam muitos métodos aproximados, profundamente e extensivamente descritos em publicações sobre a teoria do funcional da densidade [ver. aqui e aqui ], eles podem ser imprecisos e até mesmo falhar abruptamente em muitas situações de interesse, como a simulação do estado de resposta transiente [cf. aqui ]. Um algoritmo preciso e eficiente para estudar a estrutura eletrônica forneceria uma melhor compreensão dos processos biológicos e também abriria oportunidades para o desenvolvimento de interações biológicas de próxima geração.
Computadores quânticos foram originalmente propostos como um método para modelagem mais eficiente de sistemas quânticos. Em 1996, Seth Lloyd demonstrou que isso é possível para certos tipos de sistemas quânticos [ aqui], e uma década depois, Alan Aspuru-Guzik e colegas mostraram que os sistemas químicos são um desses casos [ aqui ]. Nas últimas duas décadas, houve uma pesquisa significativa em métodos de modelagem de ajuste fino para sistemas químicos que podem calcular propriedades de interesse de pesquisa.
3.1. Vantagens e desvantagens da simulação quântica
Em princípio, um computador quântico é capaz de resolver com eficiência um problema de estrutura eletrônica totalmente correlacionado (equações FCI), que será o primeiro passo para estimar com precisão as energias de ligação, bem como para simular a dinâmica de sistemas químicos. A química computacional clássica se concentrou quase exclusivamente em métodos aproximados, que têm sido úteis, por exemplo, para estimar as quantidades termoquímicas de pequenas moléculas [ aqui], mas isso pode não ser suficiente para processos associados à quebra ou formação de ligações. Em contraste, os processadores quânticos podem potencialmente resolver um problema eletrônico ao diagonalizar diretamente a matriz FCI, dando um resultado preciso dentro de um determinado conjunto de bases e, assim, resolvendo muitos dos problemas decorrentes de descrições incorretas da física de processos moleculares (por exemplo, polarização de ligantes) ... Além disso, ao contrário das abordagens clássicas, eles não requerem necessariamente um processo iterativo, embora a suposição inicial ainda seja importante.
Embora os computadores quânticos não sejam tão profundamente estudados, eles também superam as aproximações limitantes que eram necessárias na computação clássica. Por exemplo, a formulação da simulação quântica no espaço real leva automaticamente em consideração a função de onda nuclear na ausência da aproximação de Born-Oppenheimer [ aqui ]. Isso torna possível estudar os efeitos não adiabáticos de alguns sistemas que são conhecidos por serem importantes para a mutação do DNA [ver. aqui ] e o mecanismo de ação de muitas enzimas [ aqui ]. Aplicações de computação quântica para modelagem de sistemas relativísticos também foram propostas [ver. aqui ], que são úteis para estudar metais de transição que aparecem nos centros ativos de muitas enzimas.
Em um artigo de Reicher e colegas [ver aqui ] o conceito da escala de tempo para calcular estruturas eletrônicas em um computador quântico é revelado. Os autores consideraram o cofator FeMo da enzima nitrogenase, cujo mecanismo de fixação de nitrogênio ainda não foi estudado e é muito complexo para ser estudado por meio de abordagens computacionais modernas. O cálculo mínimo do FCI da linha de base para FeMoCo levará vários meses e cerca de 200 milhões de qubits da classe mais alta disponível hoje. No entanto, essas estimativas devem mudar com o rápido desenvolvimento da tecnologia. Ao longo dos 3 anos desde a publicação, os avanços algorítmicos já reduziram os requisitos de tempo em várias ordens de magnitude [ver. aqui] Além dos métodos mais poderosos de estrutura eletrônica, versões rápidas de métodos aproximados modernos que foram investigados recentemente [cf. aqui e aqui ], pode acelerar significativamente a prototipagem, o que pode ser útil, por exemplo, no estudo das coordenadas de reações de reações enzimáticas, cuja área é um problema para enzimologia computacional [ aqui ]. Além disso, com uma melhor compreensão das interações intermoleculares catalisadas pelo acesso a computação totalmente correlacionada ou acesso a largura de banda mais rápida que melhora a parametrização, a modelagem quântica pode melhorar significativamente as técnicas de modelagem não quântica, como campos de força.
Um último ponto a ser observado é que, ao contrário de outras áreas de pesquisa de algoritmos, como o aprendizado com máquinas quânticas, há uma série de algoritmos de simulação quântica de curto prazo que podem ser executados em hardware pré-existente pouco exigente. Numerosos grupos experimentais em todo o mundo relataram demonstrações bem-sucedidas desses algoritmos [ aqui , aqui , aqui e aqui ].
Infelizmente, também existem algumas desvantagens na modelagem de sistemas quânticos. Conforme discutido acima, é muito difícil extrair informações de um computador quântico. Reconstruir toda a função de onda é mais difícil do que calculá-la da maneira clássica. Esta é uma desvantagem importante para problemas químicos, onde argumentos baseados em estrutura eletrônica são a principal fonte de entendimento. No entanto, em comparação com o aprendizado de máquina, as vantagens superam as desvantagens, e a simulação quântica deve ser uma das primeiras aplicações úteis da computação quântica prática [ver Ref. aqui ].
3.2. Computação quântica tolerante a falhas
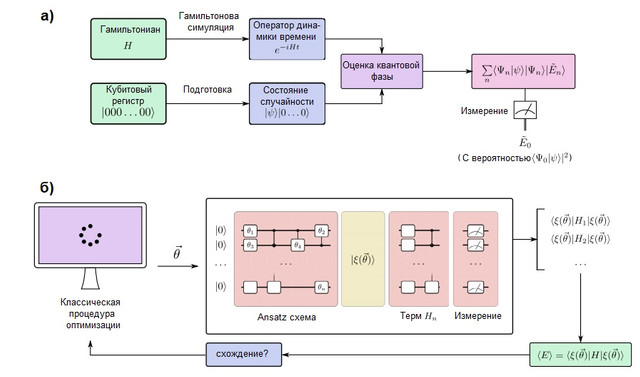
FIGURA 2. (a) Um algoritmo de simulação quântica em um computador quântico tolerante a falhas. Os qubits são divididos em dois registradores: um é preparado no estado, que se assemelha à função de onda alvo, enquanto a outra permanece no estado ... O algoritmo de estimativa de fase quântica (QPE) é usado para encontrar os valores próprios do operador de evolução no tempo, que é preparado usando os métodos de modelagem hamiltoniana. Após o QPE, a medição de um computador quântico fornece a energia do estado fundamental com probabilidadepor isso é importante preparar o estado da suposição com sobreposição diferente de zero com a função de onda verdadeira. (b) Um algoritmo de simulação quântica variacional em um computador quântico de curto prazo. Este algoritmo combina um processador quântico com uma rotina de otimização clássica para realizar várias execuções curtas que são rápidas o suficiente para evitar erros. Um computador quântico prepara um estado de suposiçãocom uma cadeia ansatz quântica dependendo de vários parâmetros... Os termos individuais do hamiltoniano são medidos um a um (ou em grupos de deslocamento usando estratégias mais avançadas), dando uma estimativa da energia esperada para um determinado vetor de parâmetros. Em seguida, os parâmetros são otimizados pelo procedimento de otimização clássico até a convergência. A abordagem variacional foi estendida a muitos problemas algorítmicos além da simulação quântica.
Os computadores quânticos que podem simular grandes sistemas químicos devem ser tolerantes a falhas para executar algoritmos arbitrariamente profundos sem erros. Esse computador quântico é capaz de simular um sistema químico mapeando o comportamento de seus elétrons com o comportamento de seus qubits e portas quânticas. O processo de modelagem quântica é conceitualmente muito simples e está representado na Figura 2 (a). Vamos preparar um registro de qubits que pode armazenar a função de onda e implementar a evolução unitária do Hamiltoniano.usando os métodos de modelagem hamiltoniana, que são discutidos abaixo. Com esses elementos, uma sub-rotina quântica conhecida como estimativa de fase quântica é capaz de encontrar os vetores e valores próprios do sistema. Ou seja, se o registrador qubit está inicialmente no estado | 0⟩, o estado final será: Em outras palavras, o estado final é uma superposição de autovalores

e autovetores sistemas. O estado fundamental é então medido com probabilidade... Para maximizar essa probabilidade, uma linha de base é estabelecida como um estado fácil de preparar, mas também motivado fisicamente, que deve ser semelhante ao estado fundamental exato. Um exemplo típico é o estado Hartree-Fock, embora outras idéias tenham sido exploradas para sistemas fortemente correlacionados [ver Ref. aqui ].
Existem duas maneiras comuns de representar elétrons em uma molécula: baseado em grade e orbital ou métodos básicos (veja McArdle e colegas para uma análise completa [ aqui ]). Nos métodos de conjunto de base, a função de onda do elétron é representada como uma soma dos determinantes de Slater dos orbitais do elétron, que podem ser comparados diretamente com o registrador de qubit [ aqui eaqui ]. Isso requer a escolha de uma base e o cálculo preliminar de integrais eletrônicos. Por outro lado, nos métodos de grade, o problema é formulado como uma solução para uma equação diferencial ordinária em uma grade. A vantagem da modelagem baseada em malha é que nenhuma aproximação de Bourne-Oppenheimer ou conjunto de base é necessária. No entanto, eles não são naturalmente antissimétricos, o que é exigido pelo princípio de Pauli da mecânica quântica, por isso é necessário garantir a antissimetria usando o procedimento de classificação [ aqui ]. Métodos baseados em grade foram discutidos no contexto de simulações de dinâmica química [cf. aqui ] e calculando a constante de taxa térmica [ver. aqui] Apesar das diferenças, o fluxo de trabalho da modelagem quântica é idêntico, conforme mostrado na Figura 2.
Existem também várias maneiras de construir o operador... Apresentaremos a técnica mais simples, Trotterização, também conhecida como formulação de produto [ver pág. aqui ]; para uma visão geral completa, consulte [ aqui e aqui ]. A trotterização é baseada na premissa de que o hamiltoniano molecular pode ser dividido como a soma dos termos que descrevem as interações de um e dois elétrons. Se sim, então o operadorpode ser implementado em termos dos operadores correspondentes para cada termo no Hamiltoniano usando a fórmula Trotter - Suzuki [ aqui ]: Por exemplo, na segunda quantização, cada termo nesta expressão terá a forma ou , onde estão os operadores de aniquilação e criação, respectivamente. As construções explícitas e detalhadas do esquema que representam esses termos foram fornecidas por Whitfield e colegas [cf. aqui ]. Depois de calcular os membros
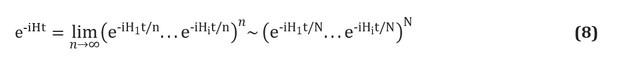

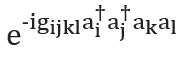
 e conhecido como integrais eletrônicos, a quantidadecompletamente determinado. Você também pode usar fórmulas Trotter - Suzuki de ordem superior para reduzir o erro. Existem muitas outras técnicas de modelagem hamiltoniana. Exemplos de técnicas poderosas e sofisticadas são cubitização [ aqui ] e processamento de sinal quântico [ver Ref. aqui ], que têm escala assintótica provavelmente ideal, embora não esteja claro se isso levará a melhores aplicações práticas.
e conhecido como integrais eletrônicos, a quantidadecompletamente determinado. Você também pode usar fórmulas Trotter - Suzuki de ordem superior para reduzir o erro. Existem muitas outras técnicas de modelagem hamiltoniana. Exemplos de técnicas poderosas e sofisticadas são cubitização [ aqui ] e processamento de sinal quântico [ver Ref. aqui ], que têm escala assintótica provavelmente ideal, embora não esteja claro se isso levará a melhores aplicações práticas.
4. Problemas de otimização
Muitos problemas em biologia computacional e outras disciplinas podem ser formulados como encontrar o mínimo ou máximo global de uma função multidimensional complexa. Por exemplo, acredita-se que a estrutura nativa de uma proteína é o mínimo global de sua hipersuperfície de energia livre [ver. aqui ]. Em outra área, identificar grupos em uma rede de proteínas ou objetos biológicos que interagem é equivalente a encontrar um subconjunto ideal de nós [ver aqui] Infelizmente, com exceção de alguns sistemas simples, os problemas de otimização costumam ser muito complexos. Embora existam heurísticas para encontrar soluções aproximadas, geralmente fornecem apenas mínimos locais e, em muitos casos, até mesmo a heurística é indecidível. A capacidade dos computadores quânticos de acelerar soluções para esses problemas de otimização ou de encontrar soluções melhores foi investigada em detalhes.
O tópico de otimização em um computador quântico é complexo porque geralmente não é óbvio se um computador quântico pode fornecer algum tipo de aceleração. Nesta seção, forneceremos uma visão geral de algumas das idéias de otimização quântica. No entanto, as garantias de melhoria não são tão claras quando comparadas, por exemplo, à simulação quântica, que se espera seja benéfica no longo prazo.
4.1. Otimização em um processador quântico
A otimização adiabática quântica é uma das abordagens de otimização mais populares devido à presença de máquinas D-Wave [ver. aqui ] que inicialmente implementam essa abordagem. A computação quântica adiabática [ aqui ] é baseada no teorema adiabático da mecânica quântica [cf. aqui] De acordo com esse teorema, se um sistema é preparado no estado fundamental do hamiltoniano e esse hamiltoniano muda lentamente, o sistema sempre permanecerá em seu estado fundamental instantâneo. Isso pode ser usado para realizar cálculos codificando um problema (como uma função de pontuação que esperamos minimizar) como um hamiltoniano e evoluindo gradualmente em direção a esse hamiltoniano a partir de algum sistema original que pode ser preparado trivialmente em seu estado fundamental. Em geral, a evolução adiabática é expressa da seguinte forma: Aqui

e - funções tais que e por um certo tempo T. Por exemplo, podemos considerar um programa de recozimento linear com e ... Muitos artigos têm se dedicado a discutir o tempo de execução do algoritmo adiabático, mas a heurística geral é que o tempo de execução é maximamente proporcional ao quadrado inverso da lacuna espectral mínima (a menor diferença de energia entre o solo e os primeiros estados excitados) durante a evolução adiabática... Acredita-se que a computação quântica adiabática (e a computação quântica em geral) não seja capaz de resolver efetivamente a classe de problemas NP-completos, ou pelo menos nenhum desses métodos passou por testes rigorosos [ver Ref. aqui ].
Em princípio, a computação quântica adiabática é equivalente à computação quântica universal [cf. aqui ]. Essa universalidade ocorre apenas se a evolução permitir a não estocasticidade, o que significa que o hamiltoniano tem elementos fora da diagonal não negativos em algum ponto da evolução. A implementação experimental mais popular de computação quântica adiabática, comercializada pela D-Wave Systems Inc., usa hamiltonianos estocásticos e, portanto, não é universal. Há alguma preocupação na literatura profissional de que esta variedade de computação quântica possa ser simulada classicamente [ aqui ], o que significa que a aceleração exponencial pode não ser possível. Apesar dessas preocupações, esta técnica tem sido amplamente usada como uma técnica de otimização metaheurística e recentemente foi mostrado para superar o recozimento simulado [ver Ref. aqui ].
A otimização quântica foi estudada fora do modelo adiabático. O algoritmo de otimização quântica aproximada (QAOA) [cf. aqui , aqui e aqui] É um algoritmo de otimização variacional em um computador quântico que tem gerado considerável interesse na literatura. Houve várias implementações experimentais de QAOA em processadores quânticos, por exemplo, [ver. aqui ] Figura 3. FIGURA 3. (a) Simulação de um computador quântico adiabático implementando o problema simplificado de dobramento de proteínas descrito [ aqui ]. A cor codifica a probabilidade logarítmica decimal de uma string binária específica. No final do cálculo, as duas soluções de menor energia têm uma probabilidade de medição próxima a 0,5. A evolução nunca é completamente adiabática em um tempo finito, e outras cadeias binárias têm probabilidades de medição residuais. (b)

Descrição do processo adiabático de computação quântica. O potencial de direcionamento dos qubits muda lentamente, fazendo com que eles girem. Observe que a representação da esfera de Bloch está incompleta, pois não exibe as correlações entre diferentes qubits que são necessários para a vantagem quântica. No final da evolução, o sistema qubit está em um estado clássico (ou superposição de estados clássicos), representando a solução com a menor energia. (c) Níveis de energia durante a evolução quântica adiabática. A quantidade de tempo necessária para garantir a evolução quase adiabática é determinada pela diferença de energia mínima entre os níveis, que é indicada pela linha tracejada
4.2. Previsão da estrutura da proteína
A previsão da estrutura da proteína sem uma matriz continua sendo um grande problema aberto e não resolvido em biologia computacional. A solução para este problema terá ampla aplicação em engenharia molecular e design de drogas. De acordo com a hipótese de dobramento de proteínas, a estrutura nativa de uma proteína é considerada um mínimo global de sua energia livre [ver. aqui ], embora haja muitos contra-exemplos. Dado o vasto espaço conformacional disponível mesmo para pequenos peptídeos, simulações clássicas exaustivas não são viáveis. No entanto, muitos estão se perguntando se a computação quântica pode ajudar a resolver esse problema.
A literatura de computação quântica se concentra no modelo de rede de proteínas, onde um peptídeo é modelado como uma estrutura de rede autopropelida, embora vários outros modelos também tenham começado a ser aplicados recentemente na prática computacional [cf. aqui ]. Cada sítio da rede corresponde a um resíduo e as interações entre sítios espaciais vizinhos contribuem para a função de energia. Existem vários esquemas de contato de energia, mas apenas dois foram usados em aplicações quânticas: o modelo hidrofóbico-polar [ver. aqui ], que considera apenas duas classes de aminoácidos, e o modelo Miyazawa-Jernigan [cf. aqui], contendo interações para cada par de resíduos. Embora esses modelos sejam uma simplificação marcante, eles forneceram uma visão substancial sobre o enovelamento de proteínas [ver Ref. aqui ] e foram propostas como uma ferramenta bruta para estudar o espaço conformacional antes de um refinamento mais detalhado [ver. aqui e aqui ].
Quase todo o trabalho se concentrou na computação quântica adiabática, uma vez que até mesmo os peptídeos modelo requerem um grande número de qubits, e as máquinas quânticas D-Wave são os maiores dispositivos quânticos disponíveis atualmente.
No entanto, em um artigo publicado recentemente por Fingerhat e colegas [ver aqui] foi feita uma tentativa de descrever o uso do algoritmo QAOA. Ambos os métodos têm características semelhantes se o problema da rede de proteínas for codificado como o operador de Hamilton. Este método foi considerado pela primeira vez por Perdomo [ver. aqui ], que sugeriu o uso de um registro qubitpara codificar coordenadas cartesianas de N aminoácidos em uma rede cúbica D-dimensional com lados N. A função de energia é expressa em um hamiltoniano contendo termos para recompensar contatos com proteínas: preservar a estrutura primária e evitar combinações de aminoácidos. Logo após este artigo marcante, outro artigo apareceu discutindo a construção de modelos mais eficientes de bits para uma rede bidimensional [ver. aqui ].
Essas codificações foram testadas em hardware real em 2012 quando Perdomo e seus colegas [ver. aqui] calculou a conformação de energia mais baixa do peptídeo PSVKMA em uma máquina quântica D-Wave. Recentemente, a equipe de pesquisa de Babay estendeu as codificações de rotação e diamante para modelos 3D e introduziu melhorias algorítmicas que reduzem a complexidade e a velocidade de movimento da codificação de Hamilton [ver Ref. aqui ]. Eles usaram um processador D-Wave 2000Q para determinar o estado fundamental de Higoline (10 resíduos) em uma rede quadrada e triptofano (8 resíduos) em uma rede cúbica, que são os maiores peptídeos investigados até agora. Essas implementações experimentais usam um método no qual uma porção do peptídeo é fixada. Isso permite que grandes problemas sejam introduzidos em um computador quântico devido à possibilidade de pesquisao número de parâmetros problemáticos estudados.
Encontrar a conformação de menor energia no modelo de rede é um problema NP difícil [ver. aqui e aqui ], o que significa que sob as hipóteses padrão não há algoritmo clássico para resolver. Além disso, acredita-se atualmente que os computadores quânticos não podem oferecer aceleração exponencial para problemas NP-completos e mais complexos [cf. aqui ], embora possam oferecer os benefícios da escala, que são conhecidos na literatura como "aceleração quântica limitada" [cf. aqui] Recentemente, o grupo de pesquisa de Outerel aplicou simulações numéricas para investigar esse fato, concluindo que há evidências de aceleração quântica limitada, embora esse resultado possa exigir máquinas adiabáticas usando correção de erros ou simulações quânticas em máquinas de uso geral tolerantes a falhas [cf. aqui ].
Embora a maior parte da literatura tenha se concentrado no modelo de rede de proteínas, um artigo recente [ aqui ] tentou usar o recozimento quântico para amostrar rotâmeros na função de energia de Rosetta [ver Ref. aqui ]. Os autores usaram o processador D-Wave 2000Qpara encontrar uma escala que parecia quase constante em comparação com o recozimento simulado clássico. Uma abordagem muito semelhante foi apresentada pelo grupo Marchand [ver. aqui ] para uma seleção de conformadores.
conclusões
Um computador quântico pode armazenar e manipular grandes quantidades de informações e executar algoritmos em uma taxa exponencialmente mais rápida do que qualquer tecnologia de computação clássica. O potencial de até mesmo pequenos computadores quânticos pode facilmente superar os melhores supercomputadores existentes hoje, que no final, no âmbito de certas tarefas, podem ter um efeito transformador para a biologia computacional, prometendo transferir problemas da categoria de insolúveis para difíceis e complexos para rotineiros. Os primeiros processadores quânticos que podem resolver problemas úteis devem aparecer na próxima década. Portanto, entender o que os computadores quânticos podem e não podem fazer é uma prioridade para todo cientista computacional.
Embora estejamos apenas entrando na era da computação quântica prática, já podemos ver os contornos de uma nova biologia computacional quântica para as próximas décadas. Esperamos que esta revisão gere interesse entre os biólogos computacionais por tecnologias que podem em breve mudar seu campo de experimentação e pesquisa. E especialistas em computação quântica, por sua vez, poderão ajudar os biólogos a desenvolver significativamente o nível de biologia computacional e bioinformática, a partir da qual muitos resultados significativos são esperados para toda a humanidade.