
Olá! Nossa empresa lida com o problema de proteção contra ataques DDoS há muito tempo, e no processo deste trabalho pude me familiarizar com áreas relacionadas com detalhes suficientes - estudar os princípios de criação de bots e como usá-los. Em particular, web scraping, ou seja, coleta em massa de dados públicos de recursos da web usando bots.
Em algum ponto, este tópico me fascinou com a variedade de problemas aplicados nos quais a raspagem é usada com sucesso. Deve-se notar aqui que o “lado negro” do web scraping é de grande interesse para mim, ou seja, cenários nocivos e ruins para seu uso e os efeitos negativos que pode ter nos recursos da web e nos negócios a eles associados.
Ao mesmo tempo, devido às especificidades do nosso trabalho, na maioria das vezes era nesses casos (ruins) que tínhamos que nos aprofundar nos detalhes, estudando detalhes interessantes. E o resultado desses mergulhos foi que meu entusiasmo foi passado aos meus colegas - implementamos nossa solução para capturar bots indesejados, mas acumulei histórias e observações suficientes que, espero, sejam um material interessante para vocês.

Vou falar sobre o seguinte:
- Por que as pessoas se arranham?
- Quais são os tipos e sinais de tal raspagem;
- Qual o impacto que isso tem nos sites direcionados;
- Quais ferramentas e capacidades técnicas os criadores de bots usam para fazer scraping;
- Como diferentes categorias de bots podem ser detectadas e reconhecidas;
- O que fazer e o que fazer se o raspador vier visitar seu site (e se você precisa fazer alguma coisa).
Vamos começar com um cenário hipotético inofensivo - vamos imaginar que você seja um estudante, amanhã de manhã você tem uma defesa de seu trabalho de conclusão de curso, você não tem nenhum cavalo por aí baseado em materiais, não há números, nem extratos, nem citações - e você entenderá isso pelo resto da noite Você não tem tempo, nem energia, nem desejo de vasculhar toda essa base de conhecimento manualmente.
Portanto, a conselho de camaradas mais velhos, você descobre a linha de comando do Python e escreve um script simples que aceita URLs como entrada, vai lá, carrega a página, analisa o conteúdo, encontra palavras-chave, blocos ou números de interesse nela, adiciona-os a um arquivo ou no prato e continua.
Carregue neste script o número necessário de endereços de publicações científicas, publicações online, recursos de notícias - ele passa rapidamente por tudo, somando os resultados. Basta desenhar gráficos e diagramas, tabelas sobre eles - e na manhã seguinte, com a aparência de um vencedor, você recebe o seu merecido ponto.
Vamos pensar sobre isso - você prejudicou alguém no processo? Bem, a menos que você tenha analisado HTML com uma expressão regular, provavelmente você não fez mal a ninguém, e ainda mais aos sites que visitou dessa forma. Esta é uma atividade única, pode ser chamada de modesta e imperceptível, e quase ninguém sofreu com o fato de você ter vindo e agarrado rapidamente e silenciosamente os dados de que precisava.
Por outro lado, você fará de novo se tudo der certo da primeira vez? Vamos enfrentá-lo - provavelmente você vai, porque você acabou de economizar muito tempo e recursos, tendo recebido, provavelmente, ainda mais dados do que você pensava originalmente. E isso não se limita à pesquisa científica, acadêmica ou em educação geral.

Porque as informações custam dinheiro, e as informações obtidas no prazo custam ainda mais dinheiro. É por isso que a sucata é uma importante fonte de renda para um grande número de pessoas. Este é um tópico popular para freelancers: entre e veja um monte de pedidos pedindo que você colete alguns dados ou escreva um software de raspagem. Existem também organizações comerciais que fazem scraping por encomenda ou fornecem plataformas para essa atividade, o chamado scraping as a service. Essa variedade e disseminação são possíveis, até porque a própria raspagem é algo ilegal, condenável, e não é. Do ponto de vista jurídico, é muito difícil encontrar uma falha nele - especialmente no momento, logo descobriremos o porquê.

Para mim, é de particular interesse também o fato de que, em termos técnicos, ninguém pode proibir você de lutar contra a raspagem - isso cria uma situação interessante em que os participantes do processo em ambos os lados das barricadas têm a oportunidade em um espaço público para discutir os aspectos técnicos e organizacionais deste assunto. Para avançar, até certo ponto, a engenharia pensou e envolver mais e mais pessoas neste processo.

Do ponto de vista jurídico, a situação que agora estamos considerando - com a permissibilidade de raspagem, nem sempre foi a mesma antes. Se olharmos um pouco para a cronologia de processos bastante conhecidos relacionados a raspagem, veremos que, mesmo no início do seu amanhecer, a primeira reclamação do eBay foi contra um raspador que coletou dados de leilões, e o tribunal o proibiu de se envolver nessa atividade. Nos 15 anos seguintes, o status quo foi mais ou menos mantido - grandes empresas venceram processos contra scrapers quando descobriram seu impacto. O Facebook e o Craigslist, assim como várias outras empresas, relataram reivindicações que acabaram em seu favor.
No entanto, há um ano, tudo mudou repentinamente. O tribunal concluiu que a ação do LinkedIn contra a empresa que coletou perfis públicos de usuários e currículos era infundada e ignorou cartas e ameaças exigindo o fim da atividade. O tribunal decidiu que a coleta de dados públicos, independentemente de ser um bot ou humano, não pode ser a base para uma reclamação da empresa exibindo esses dados públicos. Este poderoso precedente legal mudou o equilíbrio em favor dos scrapers e permitiu que mais pessoas mostrassem, demonstrassem e experimentassem seu próprio interesse no campo.
No entanto, olhando para todas essas coisas geralmente inofensivas, não se esqueça de que a raspagem tem muitos usos negativos - quando os dados são coletados não apenas para uso posterior, mas no processo, a ideia de causar qualquer dano ao site ou à empresa por trás deles é realizada. ou tentativas de enriquecimento de alguma forma às custas dos usuários do recurso de destino.
Vejamos alguns exemplos icônicos.

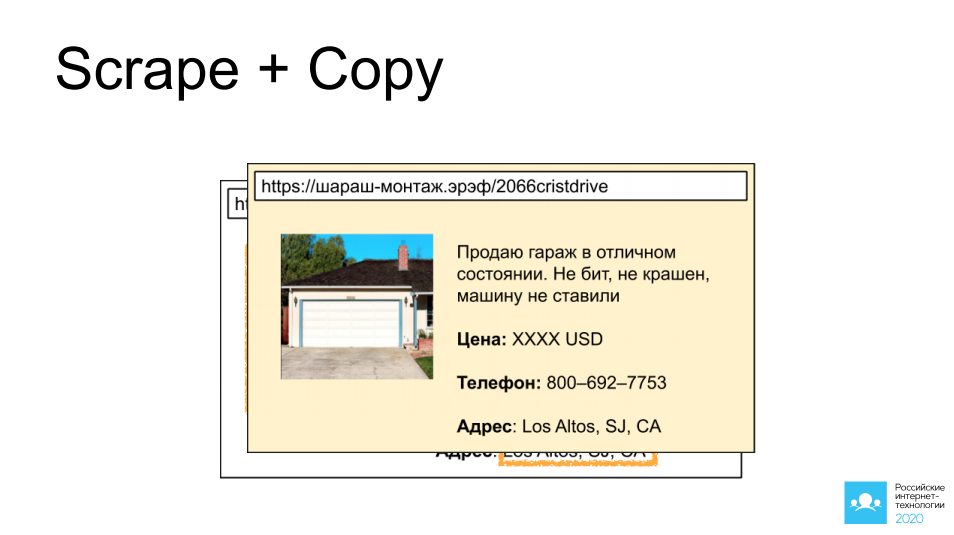
A primeira delas é raspar e copiar anúncios de outras pessoas de sites que fornecem acesso a esses anúncios: carros, imóveis, itens pessoais. Escolhi uma garagem maravilhosa na Califórnia como exemplo. Imagine que colocamos um bot lá, coletamos uma foto, coletamos uma descrição, pegamos todas as informações de contato e, após 5 minutos, o mesmo anúncio está pendurado em outro site de foco semelhante, e é bem possível que um negócio lucrativo aconteça por meio dele.
Se ligarmos um pouco a nossa imaginação aqui e pensarmos no outro lado - e se não for nosso concorrente quem está fazendo isso, mas um atacante? Essa cópia do site pode ser muito útil para, por exemplo, solicitar um adiantamento ao visitante ou simplesmente oferecer a inserção dos dados do cartão de pagamento. Você pode imaginar o desenvolvimento posterior dos eventos por si mesmo.
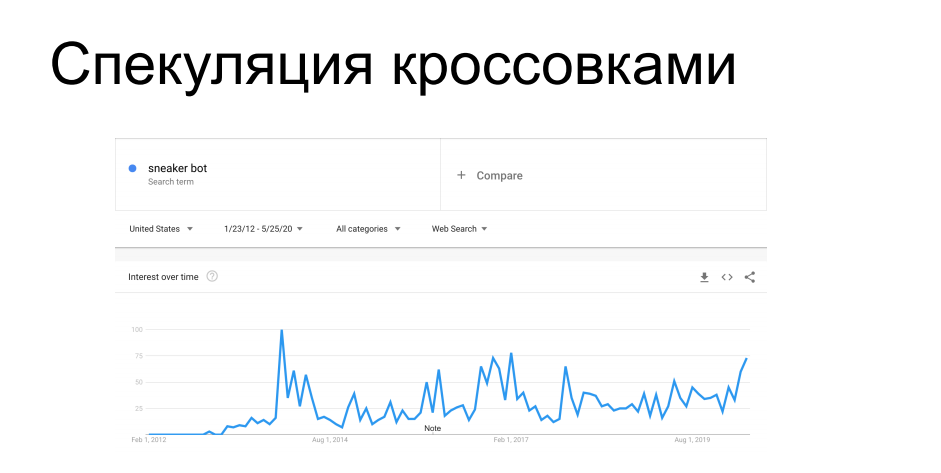
Outro caso interessante de raspagem é a compra de itens de disponibilidade limitada. Fabricantes de calçados esportivos, como Nike, Puma e Reebok lançam periodicamente tênis de edição limitada, etc. série de assinaturas - são caçados por colecionadores, ficam à venda por tempo limitado. À frente dos compradores, os bots correm para os sites das lojas de sapatos e aumentam toda a circulação, após o que esses tênis chegam ao mercado cinza com um preço completamente diferente. Ao mesmo tempo, enfureceu vendedores e varejistas que os distribuíam. Há 7 anos eles lutam contra raspadores, etc. bots de tênis com sucesso variável, tanto métodos técnicos quanto administrativos.

Você provavelmente já ouviu histórias quando, ao fazer compras online, teve que ir pessoalmente a uma loja de tênis, ou sobre honeypots com tênis por US $ 100 mil, que o bot comprou sem olhar, depois do qual seu dono agarrou sua cabeça - todas essas histórias seguem essa tendência.
E outro caso semelhante é o esgotamento de estoque nas lojas online. É semelhante ao anterior, mas na verdade nenhuma compra é feita nele. Há uma loja online e certos itens de mercadorias que os bots que chegam colocam na cesta na quantidade que é exibida como disponível no armazém. Como resultado, um usuário legítimo que tenta comprar um produto recebe uma mensagem de que o artigo está esgotado, coça a nuca de frustração e sai para outra loja. Os próprios bots então largam as cestas coletadas, os produtos são devolvidos ao pool - e aquele que precisava vem e faz o pedido. Ou não vem e não manda, se este for um cenário de travessuras mesquinhas e hooliganismo. A partir disso, fica claro que, mesmo que essas atividades não causem danos financeiros diretos a um negócio online, pelo menos podem perturbar seriamente as métricas de negócios,em que os analistas se concentrarão. Parâmetros como conversão, atendimento, demanda de produto, verificação média do carrinho - todos eles serão fortemente manchados pelas ações dos bots em relação a esses itens. E antes que essas métricas sejam postas em prática, elas terão que ser cuidadosa e meticulosamente limpas dos efeitos dos raspadores.
Além desse foco de negócios, existem efeitos técnicos bastante perceptíveis decorrentes do trabalho dos raspadores - mais frequentemente quando a raspagem é feita de forma ativa e intensiva.
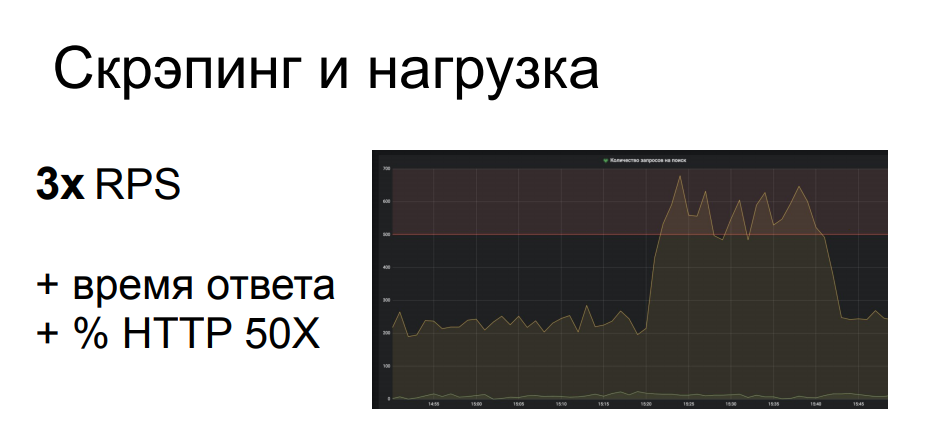
Um de nossos exemplos de um de nossos clientes. O raspador chegou a um local com uma busca parametrizada, que é uma das operações mais difíceis no backend da estrutura em questão. O raspador teve que resolver um monte de consultas de pesquisa e dos 200 RPS para este local ele fez quase 700. Esta parte seriamente carregada da infraestrutura, o que levou a uma degradação da qualidade do serviço para o resto dos usuários legítimos, o tempo de resposta disparou, os 502s e 503s caíram. e erros. Em geral, o raspador não se importou nem um pouco e sentou-se e fez seu trabalho enquanto todos os outros atualizavam freneticamente a página do navegador.
A partir disso, fica claro que tal atividade pode muito bem ser classificada como um ataque DDoS aplicado - e freqüentemente é. Principalmente se a loja online não for tão grande, ela não possui uma infraestrutura que é repetidamente reservada em termos de desempenho e localização. Tal atividade pode muito bem, se você não colocar totalmente o recurso - não é muito lucrativo para o raspador, já que neste caso ele não receberá seus dados - então irritar seriamente todos os outros usuários.
Mas, além do DDoS, o scraping também tem vizinhos interessantes para o crime cibernético. Por exemplo, logins e senhas de força bruta usam uma base técnica semelhante, ou seja, usando os mesmos scripts, isso pode ser feito com ênfase na velocidade e desempenho. Para preenchimento de credenciais, são usados dados do usuário descartados de algum lugar, que são colocados nos campos do formulário. Bem, aquele exemplo de cópia de conteúdo e postagem em sites semelhantes é um trabalho preparatório sério para escapar de links de phishing e atrair compradores desavisados.

Para entender como diferentes variantes de raspagem podem, do ponto de vista técnico, afetar o recurso, vamos tentar calcular a contribuição de fatores individuais para essa tarefa. Vamos fazer alguma aritmética.

Digamos que temos um monte de dados à direita que precisamos coletar. Temos uma tarefa ou pedido para recuperar 10.000.000 de linhas de itens de commodities, por exemplo, etiquetas de preços ou cotações. E do lado esquerdo temos um orçamento de tempo, porque amanhã ou em uma semana esses dados não serão mais necessários ao cliente - ficarão desatualizados e terão que ser coletados novamente. Portanto, você precisa se manter dentro de um determinado prazo e, usando seus próprios recursos, fazê-lo da maneira ideal. Temos vários servidores - máquinas e endereços IP atrás dos quais estão localizados, a partir dos quais iremos para o recurso de nosso interesse. Temos várias instâncias de usuário que fingimos ser - há uma tarefa de convencer uma loja online ou alguma base pública de que são pessoas diferentes ou computadores diferentes procuram algum tipo de dados para que aqueles quequem vai analisar os logs, não houve suspeita. E temos algum desempenho, taxa de solicitação, de uma dessas instâncias.
É claro que em um caso simples - uma máquina host, um aluno com um laptop, passando pelo Washington Post, um grande número de solicitações com os mesmos sinais e parâmetros será feito. Isso ficará muito perceptível nos logs, se houver muitos desses pedidos - o que significa que é fácil encontrar e banir, neste caso, pelo endereço IP.
Conforme a infraestrutura de scraping se torna mais complexa, um número maior de endereços IP aparece, os proxies estão começando a ser usados, incluindo os proxies internos - mais sobre eles posteriormente. E começamos a multi-instanciar em cada máquina - para substituir os parâmetros de consulta, os sinais que nos caracterizam, a fim de fazer com que a coisa toda manche nos logs e não seja tão visível.
Se continuarmos na mesma direção, teremos a oportunidade, no âmbito da mesma equação, de reduzir a intensidade das solicitações de cada uma dessas instâncias - tornando-as mais raras, girando-as com mais eficiência para que as solicitações dos mesmos usuários não acabem nos logs próximos. sem levantar suspeitas e ser semelhante aos usuários finais (legítimos).
Bem, há um caso extremo - já tivemos um caso na prática, quando um raspador chegou a um cliente de um grande número de endereços IP com atributos de usuário completamente diferentes por trás desses endereços, e cada instância fez exatamente uma solicitação de conteúdo. Fiz um GET para a página do produto desejado, analisei e saí - e nunca mais apareceu. Esses casos são bastante raros, pois requerem mais recursos (que custam dinheiro) para serem envolvidos no mesmo período de tempo. Mas, ao mesmo tempo, fica muito mais difícil rastreá-los e entender que alguém veio aqui e os raspou. Ferramentas de pesquisa de tráfego, como análise comportamental - construindo um padrão de comportamento de um usuário específico - tornam-se muito complicadas. Afinal, como você pode fazer análise comportamental se não houver comportamento? Não há histórico de ações do usuário,ele nunca tinha aparecido antes e, curiosamente, nunca mais voltou desde então. Nessas condições, se não tentarmos fazer algo na primeira solicitação, ele receberá seus dados e sairá, e não ficaremos sem nada - não resolvemos aqui o problema de combater a raspagem. Portanto, a única oportunidade é adivinhar logo no primeiro pedido que veio a pessoa errada, quem queremos ver no site, e dar-lhe um erro ou certificar-se de que não receberá os seus dados.quem queremos ver no site, e dar-lhe um erro ou de outra forma garantir que ele não receba seus dados.quem queremos ver no site, e dar-lhe um erro ou de outra forma garantir que ele não receba seus dados.
Para entender como você pode mover-se ao longo dessa escala de complexidade na construção de um scraper, vamos dar uma olhada no arsenal que os criadores de bots têm e que são usados com mais frequência - e em quais categorias ele pode ser dividido.

A categoria principal e mais simples com a qual a maioria dos leitores está familiarizada é a extração de scripts, o uso de scripts simples o suficiente para resolver problemas relativamente complexos.

E esta categoria é talvez a mais popular e bem documentada. É até difícil recomendar o que exatamente ler, porque, na verdade, há muito material. Muitos livros foram escritos usando esse método, são muitos artigos e publicações - em princípio, é suficiente gastar 5/4/3/2 minutos (dependendo da impudência do autor do material) para analisar seu primeiro site. Este é um primeiro passo lógico para muitos que estão começando na web scraping. O "pacote inicial" de tal atividade geralmente é o Python, além de uma biblioteca que pode fazer solicitações de maneira flexível e alterar seus parâmetros, como solicitações ou urllib2. E algum tipo de analisador de HTML, geralmente Beautiful Soup. Também existe uma opção para usar libs que são projetadas especificamente para scrapy, como scrapy, que inclui todas essas funcionalidades com uma interface amigável.
Com a ajuda de truques simples, você pode fingir ser diferentes dispositivos, diferentes usuários, mesmo sem poder escalar de alguma forma suas atividades por máquinas, por endereços IP e por diferentes plataformas de hardware.

Para tirar o cheiro de quem inspeciona os logs do lado do servidor de onde os dados são coletados, basta alterar os parâmetros de interesse - e isso não é difícil e nem demorado. Vejamos um exemplo de formato de log personalizado para nginx - registramos um endereço IP, informações TLS, cabeçalhos de nosso interesse. Aqui, é claro, nem tudo o que normalmente é coletado, mas precisamos dessa restrição como exemplo - para olhar um subconjunto, simplesmente porque todo o resto é ainda mais fácil de "jogar".
Para não sermos banidos por endereços, usaremos proxies residenciais, como são chamados no exterior - ou seja, proxies de máquinas alugadas (ou hackeadas) nas redes domésticas de provedores. É claro que, ao banir tal endereço IP, há uma chance de banir um certo número de usuários que moram nessas casas - e pode haver visitantes em seu site, então às vezes é mais caro para você fazer isso.
As informações TLS também não são difíceis de alterar - pegue os conjuntos de criptografia de navegadores populares e escolha o que você gosta - o mais comum, ou gire-os periodicamente para se apresentarem como dispositivos diferentes.
Quanto aos cabeçalhos, com a ajuda de um pequeno estudo, você pode definir o referenciador para o que o site copiado gosta, e pegamos o agente de usuário do Chrome, ou Firefox, para que não difira de forma alguma de dezenas de milhares de outros usuários.
Então, fazendo malabarismos com esses parâmetros, você pode fingir ser dispositivos diferentes e continuar raspando sem ter medo de ser notado a olho nu caminhando pelas toras. Para o olho armado, isso ainda é um pouco mais difícil, porque esses truques simples são neutralizados pelas mesmas contra-medidas bastante simples.

Comparar parâmetros de solicitação, cabeçalhos e endereços IP entre si e com os conhecidos publicamente permite que você pegue os scrapers mais arrogantes. Um exemplo simples - um bot de busca veio até nós, mas por algum motivo seu IP não é da rede do mecanismo de busca, mas de algum provedor de nuvem. Até o próprio Google na página que descreve o Googlebot recomenda fazer uma pesquisa reversa de registros DNS para garantir que esse bot realmente veio de google.com ou de outros recursos válidos do Google.
Existem muitas dessas verificações, na maioria das vezes elas são projetadas para aqueles raspadores que não se preocupam com a penugem, algum tipo de substituição. Para casos mais complexos, existem métodos mais confiáveis e complicados, por exemplo, inserir Javascript neste bot. É claro que em tais condições a luta já é desigual - seu script Python não será capaz de executar e interpretar o código JS. Mas isso pode ser feito pelo autor do script - se o autor do bot tiver tempo, desejo, recursos e habilidade suficientes para ir e ver o que seu Javascript está fazendo no navegador.
A essência das verificações é que você integre o script em sua página e é importante para você não apenas que seja executado, mas também que demonstre algum tipo de resultado, que geralmente é o POST enviado de volta ao servidor antes que o cliente durma o suficiente conteúdo, e a própria página será carregada. Portanto, se o autor do bot resolveu seu enigma e codifica as respostas corretas em seu script Python, ou, por exemplo, entende onde ele precisa analisar as próprias linhas do script em busca dos parâmetros necessários e métodos chamados e vai calcular a resposta por conta própria, ele será capaz de circular você em torno de seu dedo. Aqui está um exemplo.

Acho que alguns ouvintes vão reconhecer esse pedaço de javascript - esse é um cheque que um dos maiores provedores de nuvem do mundo costumava ter antes de acessar a página solicitada, compacta e muito simples, e ao mesmo tempo, sem aprender, é tão fácil o site não abre. Ao mesmo tempo, com um pouco de esforço, podemos pedir à página em busca dos métodos JS de nosso interesse que serão chamados, a partir deles, contando, encontre os valores de nosso interesse que devem ser calculados, e cole os cálculos no código. Depois disso, não se esqueça de dormir alguns segundos devido ao atraso e pronto.

Chegamos à página e então podemos analisar o que precisamos, gastando não mais recursos do que criando nosso próprio raspador. Ou seja, do ponto de vista do uso de recursos, não precisamos de mais nada para resolver tais problemas. É claro que a corrida armamentista nesse sentido - escrever desafios JS e analisá-los e contorná-los com ferramentas de terceiros - é limitada apenas pelo tempo, desejo e habilidades do autor dos bots e do autor dos cheques. Esta corrida pode durar bastante tempo, mas em algum momento a maioria dos scrapers se torna desinteressante, porque há opções mais interessantes para lidar com ela. Por que sentar e analisar o código JS em Python quando você pode simplesmente pegar e executar um navegador?

Sim, estou falando principalmente de navegadores sem cabeça, porque essa ferramenta, originalmente criada para testes e perguntas e respostas, acabou se revelando ideal para tarefas de web scraping no momento.
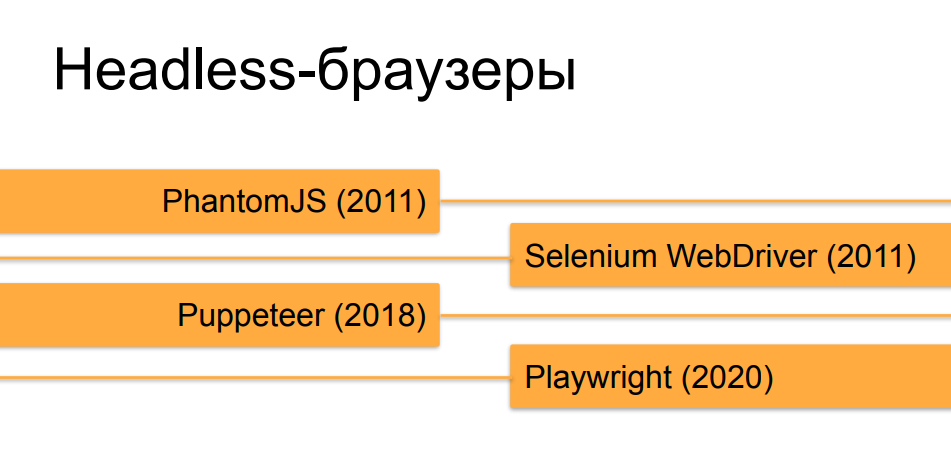
Não entraremos em detalhes sobre os navegadores headless, acho que a maioria dos ouvintes já os conhece. Os orquestradores, que automatizam navegadores sem cabeça, passaram por uma evolução bastante rápida nos últimos 10 anos. No início, na época do PhantomJS e das primeiras versões do Selenium 2.0 e Selenium WebDriver, um navegador sem cabeça rodando sob um autômato não era nada difícil de distinguir de um usuário real. Mas, com o tempo e o surgimento de ferramentas como Puppeteer para headless Chrome e, agora, a criação de cavalheiros da Microsoft - Playwright, que faz a mesma coisa que Puppeteer, mas não apenas para o Chrome, mas para todas as versões de navegadores populares, eles são cada vez mais e aproximar os navegadores sem cabeça dos reais em termos decomo podem ser feitas com a ajuda de uma orquestração semelhante em comportamento e em diferentes signos e propriedades ao navegador de uma pessoa saudável.

Para lidar com o reconhecimento sem cabeça no contexto de navegadores comuns que as pessoas usam, como regra, as mesmas verificações de javascript são usadas, mas mais profundas e detalhadas, coletando uma nuvem de parâmetros. O resultado dessa coleta é enviado de volta para a ferramenta de proteção ou para o site do qual o raspador deseja coletar os dados. Essa tecnologia é chamada de impressão digital, porque coleta uma impressão digital real do navegador e do dispositivo em que está sendo executado.
Existem algumas coisas que as verificações de JS examinam ao fazer a impressão digital - elas podem ser divididas em alguns blocos condicionais, em cada um dos quais a escavação pode continuar e continuar. Na verdade, existem muitas propriedades, algumas delas são fáceis de esconder, outras menos fáceis. E aqui, como no exemplo anterior, muito depende de quão meticulosamente o raspador abordou a tarefa de esconder as "caudas" salientes da decapitação. Existem propriedades de objetos no navegador, que o orquestrador substitui por padrão, existe a própria propriedade (navigator.webdriver), que está configurada em headless, mas ao mesmo tempo não está em navegadores regulares. Ele pode ser escondido, uma tentativa de esconder pode ser detectada verificando certos métodos - o que verifica essas verificações também pode ser escondido e deslizado saída falsa para funções que imprimem métodos, por exemploe pode durar indefinidamente.
Outro bloco de checagens, via de regra, é responsável por estudar os parâmetros da janela e da tela, que por definição não existem em navegadores headless: checando coordenadas, checando tamanhos, qual é o tamanho de uma imagem quebrada que não foi desenhada. São muitas as nuances que uma pessoa que conhece bem o dispositivo dos navegadores pode prever e tirar uma conclusão plausível (mas não real) sobre cada uma delas, que irá fugir nas verificações de impressões digitais para o servidor, que as analisará. Por exemplo, no caso de renderizar algumas imagens, 2D e 3D, por meio de WebGL e Canvas, você pode pegar toda a saída pronta, forjá-la, colocá-la em um método e fazer alguém acreditar que algo está realmente desenhado.
Existem verificações mais complicadas que não ocorrem simultaneamente, mas digamos que o código JS gire por um determinado número de segundos na página ou pare constantemente e transfira algumas informações do navegador para o servidor. Por exemplo, rastrear a posição e a velocidade do movimento do cursor - se o bot clicar apenas nos lugares de que precisa e seguir os links na velocidade da luz, isso pode ser rastreado pelo movimento do cursor, se o autor do bot não pensar em escrever algum tipo de suavidade humana , Deslocamento.
E há uma grande selva - esses são parâmetros específicos de versão e propriedades do modelo de objeto, que são específicos de navegador para navegador, de versão para versão. E para que essas verificações funcionem corretamente e não falsifiquem, por exemplo, em usuários ativos com alguns navegadores antigos, você precisa levar em consideração um monte de coisas. Primeiro, você precisa acompanhar o lançamento de novas versões, modificar suas verificações para que levem em consideração o estado das coisas nas frentes. É necessário manter a compatibilidade com versões anteriores para que alguém possa entrar em um site protegido por tais verificações em um navegador atípico e ao mesmo tempo não ser pego como um bot, e muitos outros.
Este é um trabalho meticuloso e bastante complicado - essas coisas geralmente são feitas por empresas que fornecem detecção de bots como um serviço, e fazer isso por conta própria não é um investimento muito lucrativo de tempo e dinheiro.
Mas o que fazer - nós realmente precisamos raspar o site, pendurado em uma nuvem de tais verificações de falta de cabeça e calculando nosso cromo sem cabeça com titereiro, apesar de tudo, não importa o quanto tentemos.
Uma pequena digressão lírica - para quem está interessado em ler mais detalhadamente sobre a história e evolução dos cheques, por exemplo, para a decapitação do Chrome, há um engraçado duelo epistolar entre dois autores. Não sei muito sobre um autor, e o outro se chama Antoine Vastel, um jovem francês que mantém um blog sobre bots e sua detecção, ofuscação de cheques e muitas outras coisas interessantes. E assim eles e sua contraparte vêm discutindo há dois anos sobre se é possível detectar o Chrome sem cabeça.
E seguiremos em frente e entenderemos o que fazer se não conseguirmos passar pelos cheques com um decapitado.

Isso significa que não usaremos headless, mas usaremos grandes navegadores reais que nos desenham janelas e todos os tipos de elementos visuais. Ferramentas como Puppeteer e Playwright permitem, em vez de headless, iniciar navegadores com uma tela renderizada, ler a entrada do usuário a partir dela, fazer capturas de tela e muito mais que não está disponível para navegadores sem um componente visual.

Além de contornar as verificações de ausência de cabeça, neste caso, você também pode lidar com o seguinte problema - quando temos alguns criadores de sites astutos, esconda-se do texto em imagens, torne-os invisíveis sem fazer cliques adicionais ou algumas outras ações e movimentos. Eles escondem alguns elementos que deveriam ser escondidos, e que aparecem sem cabeça: eles não sabem que este elemento não deve ser mostrado na tela agora, e o encontram. Podemos simplesmente desenhar esta imagem no navegador, alimentar a captura de tela para o OCR, obter o texto na saída e usá-lo. Sim, é mais difícil, mais caro em termos de desenvolvimento, leva mais tempo e consome mais recursos. Mas existem scrapers que funcionam dessa maneira e, às custas da velocidade e do desempenho, eles coletam dados dessa maneira.

"E quanto ao CAPTCHA?" - você pergunta. Afinal, o captcha OCR (avançado) não pode ser resolvido sem algumas coisas mais complicadas. Há uma resposta simples para isso - se não podemos resolver o captcha automaticamente, por que não usar trabalho humano? Por que separar um bot e um humano quando você pode combinar o trabalho deles para atingir um objetivo?
Existem serviços que permitem enviar um captcha para eles, onde é resolvido pelas mãos de pessoas sentadas em frente às telas, e através da API você pode obter uma resposta ao seu captcha, inserir um cookie na solicitação, por exemplo, que será emitido, e então processar automaticamente as informações deste site ... Cada vez que um captcha aparece, retiramos o apishka, obtemos uma resposta para o captcha - passamos para a próxima pergunta e seguimos em frente.
É claro que isso também custa um bom dinheiro - a solução de captcha é adquirida a granel. Mas se nossos dados são mais caros do que o custo de todos esses truques, então, afinal, por que não?
Agora que vimos a evolução em direção à complexidade de todas essas ferramentas, vamos pensar sobre o que fazer se ocorrer um scraping em nosso recurso online - uma loja online, uma base de conhecimento pública ou qualquer outra coisa.

A primeira coisa a fazer é encontrar o raspador. Vou te dizer uma coisa: nem todos os casos de reunião pública geralmente trazem efeitos negativos, como já consideramos no início do relatório. Como regra, métodos mais primitivos, os mesmos scripts sem limitação de taxa, sem limitar a velocidade da solicitação, podem causar muito mais danos (se não forem evitados por meio de proteção) do que qualquer raspagem de navegador complexa e sofisticada com uma solicitação na hora, que a princípio ainda precisa ser encontrada de alguma forma nos logs.

Portanto, primeiro você precisa entender que estamos sendo prejudicados - para ver os significados que geralmente são afetados por essa atividade. Agora estamos falando sobre parâmetros técnicos e métricas de negócios. Aquelas coisas que você pode ver no seu Grafana, ao longo do tempo observando a carga e o tráfego, todo tipo de estouro e anomalias. Você também pode fazer isso manualmente se não usar uma ferramenta de segurança, mas é feito de forma mais confiável por quem sabe como filtrar o tráfego, detectar todos os tipos de incidentes e combiná-los com alguns eventos. Pois além de analisar logs após o fato e além de analisar cada solicitação individual, pode funcionar aqui o uso de algum meio de proteção acumulado da base de conhecimento, que já viu as ações dos scrapers neste recurso ou em recursos semelhantes, e você pode de alguma forma comparar um com o outro - fala sobre a análise de correlação.
Quanto às métricas de negócios, já nos lembramos de usar o exemplo de scripts que causam danos financeiros diretos ou indiretos. Se for possível rastrear rapidamente a dinâmica desses parâmetros, então novamente o scraping pode ser notado - e então, se você resolver o problema sozinho, seja bem-vindo aos logs do seu backend.
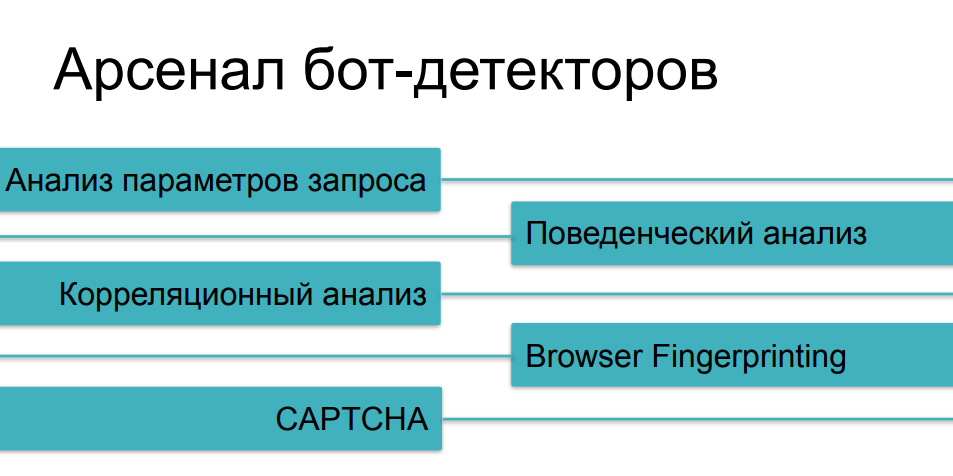
Quanto aos meios de proteção que são usados contra raspagem agressiva, já consideramos a maioria dos métodos, falando sobre diferentes categorias de bots. A análise de tráfego nos ajudará nos casos mais simples, a análise comportamental nos ajudará a rastrear coisas como fuzzing (substituição de identidade) e scripts de várias instâncias. Contra coisas mais complexas, coletaremos impressões digitais. E, claro, temos um CAPTCHA como o último argumento dos reis - se não conseguirmos de alguma forma pegar um bot astuto nas questões anteriores, então, provavelmente, ele tropeçará em um CAPTCHA, certo?
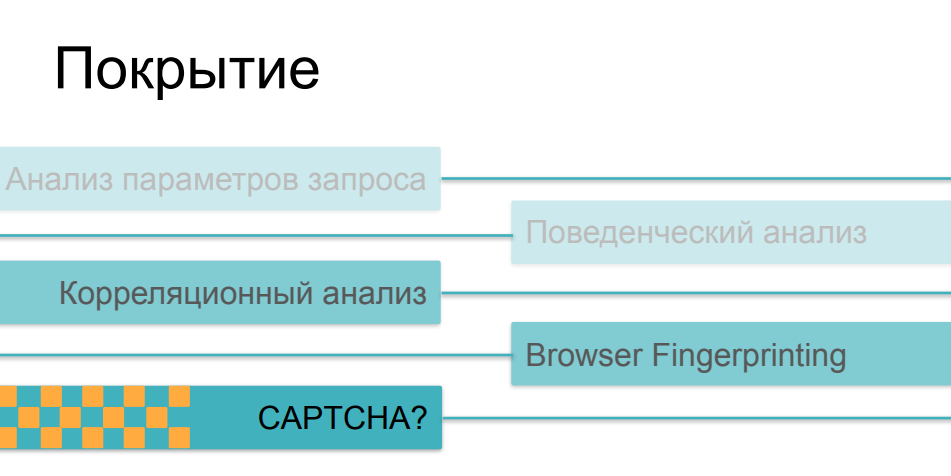
Bem, é um pouco mais complicado aqui. O fato é que conforme a complexidade e a astúcia dos cheques aumentam, eles se tornam cada vez mais caros, principalmente para o lado do cliente. Se a análise de tráfego e subsequente comparação de parâmetros com alguns valores históricos puderem ser feitas de forma absolutamente não invasiva, sem afetar o tempo de carregamento da página e a velocidade do recurso online em princípio, então a impressão digital, se for grande o suficiente e fizer centenas de verificações diferentes no navegador, pode afetar seriamente a velocidade de download. E poucas pessoas gostam de assistir às páginas com cheques no processo de seguir os links.
Quando se trata de CAPTCHAs, esse é o método mais rudimentar e invasivo. Isso é algo que pode realmente afastar os usuários ou compradores do recurso. Ninguém gosta de captcha e eles não recorrem a ele por causa de uma vida boa - eles recorrem a ele quando todas as outras opções não funcionaram. Há mais um paradoxo engraçado aqui, algum problema com a aplicação desses métodos. O fato é que a maioria dos meios de proteção em uma ou outra sobreposição utiliza todas essas possibilidades, dependendo de quão difícil o cenário de atividade do bot que eles encontraram. Se nosso usuário conseguiu passar nos analisadores de tráfego, se seu comportamento não difere do comportamento dos usuários, se sua impressão digital se parece com um navegador válido, ele superou todas essas verificações e, no final, mostramos a ele o captcha - e acaba por ser uma pessoa ... pode ser muito triste ...Como resultado, o captcha começa a ser mostrado não para bots malvados que queremos eliminar, mas para uma parcela bastante séria de usuários - pessoas que podem ficar bravas com isso e não vir na próxima vez, não comprar algo no recurso, não participar de seu desenvolvimento posterior.

Considerando todos esses fatores - o que deveríamos fazer no final, se houvesse um desperdício, olhássemos e pudéssemos avaliar de alguma forma seu impacto em nossos indicadores técnicos e de negócios? Por outro lado, não faz sentido lutar contra a coleta de dados por definição como coleta de dados públicos, máquinas ou pessoas - você mesmo concordou que esses dados estão disponíveis para qualquer usuário que venha da Internet. E para resolver o problema de limitar a eliminação "por princípio" - isto é, devido ao fato de que bots avançados e talentosos vêm até você, você tenta banir todos eles - isso significa gastar muitos recursos em proteção, seja você mesmo, ou usar uma solução cara e muito complexa , auto-hospedado ou baseado na nuvem no "modo de segurança máxima" e, em busca de cada bot individual, arrisca assustar a parcela de usuários válidos com tais coisas,como verificações pesadas de javascript, como captcha que aparece a cada terceira transição. Tudo isso pode mudar seu site irreconhecível em favor de seus visitantes.
Se você quiser usar uma ferramenta de proteção, então você precisa procurar por aquelas que lhe permitirão mudar e de alguma forma encontrar um equilíbrio entre a proporção de raspadores (do simples ao complexo) que você tentará cortar no uso do seu recurso e, de fato, a velocidade da sua web -recurso. Porque, como já vimos, algumas verificações são feitas de forma simples e rápida, enquanto outras são difíceis e demoradas - e ao mesmo tempo muito perceptíveis para os próprios visitantes. Portanto, as soluções que podem aplicar e variar essas contramedidas dentro de uma plataforma comum permitirão que você alcance esse equilíbrio mais rápido e melhor.
Bem, também é muito importante usar o que é chamado de "mentalidade correta" no estudo de todos esses problemas isoladamente ou nos exemplos de outros. É preciso lembrar que os dados públicos em si não precisam de proteção - mais cedo ou mais tarde serão vistos por todas as pessoas que os desejarem. A experiência do usuário precisa de proteção: a experiência do usuário de seus clientes, clientes e usuários, que, ao contrário dos scrapers, geram receita para você. Você pode mantê-lo e aumentá-lo se tiver mais experiência nesta área tão interessante.
Muito obrigado pela atenção!
