
Nos últimos três anos, a Nvidia tem criado chips gráficos nos quais, além dos núcleos usuais usados para shaders, outros adicionais são instalados. Esses núcleos, chamados de núcleos tensores, já são encontrados em milhares de PCs desktop, laptops, estações de trabalho e data centers em todo o mundo. Mas o que eles fazem e para que são usados? Eles são mesmo necessários em placas de vídeo?
Hoje vamos explicar o que é um tensor e como os kernels de tensor são usados no mundo gráfico e de aprendizado profundo.
Uma pequena aula de matemática
Para entender o que os kernels tensores estão fazendo e para que podem ser usados, primeiro descobrimos o que são tensores. Todos os microprocessadores, independentemente da tarefa que executem, realizam operações matemáticas em números (adição, multiplicação, etc.).
Às vezes, esses números precisam ser agrupados porque têm um certo significado um para o outro. Por exemplo, quando o chip processa dados para renderizar gráficos, ele pode lidar com valores inteiros únicos (digamos, +2 ou +115) como o fator de escala, ou com um grupo de flutuantes (+0,1, -0,5, +0,6) como o coordenadas de um ponto no espaço 3D. No segundo caso, todos os três itens de dados são necessários para a posição do ponto.
TensorÉ um objeto matemático que descreve as relações entre outros objetos matemáticos relacionados entre si. Eles geralmente são exibidos como uma matriz de números, cujas dimensões são mostradas abaixo.

O tipo de tensor mais simples tem dimensão zero e consiste em um único valor; caso contrário, é denominado escalar . À medida que o número de dimensões aumenta, encontramos outras estruturas matemáticas comuns:
- 1 dimensão = vetor
- 2 dimensões = matriz
Estritamente falando, um escalar é um tensor 0 x 0, um vetor é 1 x 0 e uma matriz é 1 x 1, mas por uma questão de simplicidade e referência aos núcleos tensores da GPU, consideraremos os tensores apenas na forma de matrizes.
Uma das operações matemáticas mais importantes realizadas em matrizes é a multiplicação (ou produto). Vamos dar uma olhada em como duas matrizes com quatro linhas e colunas de dados são multiplicadas uma pela outra:
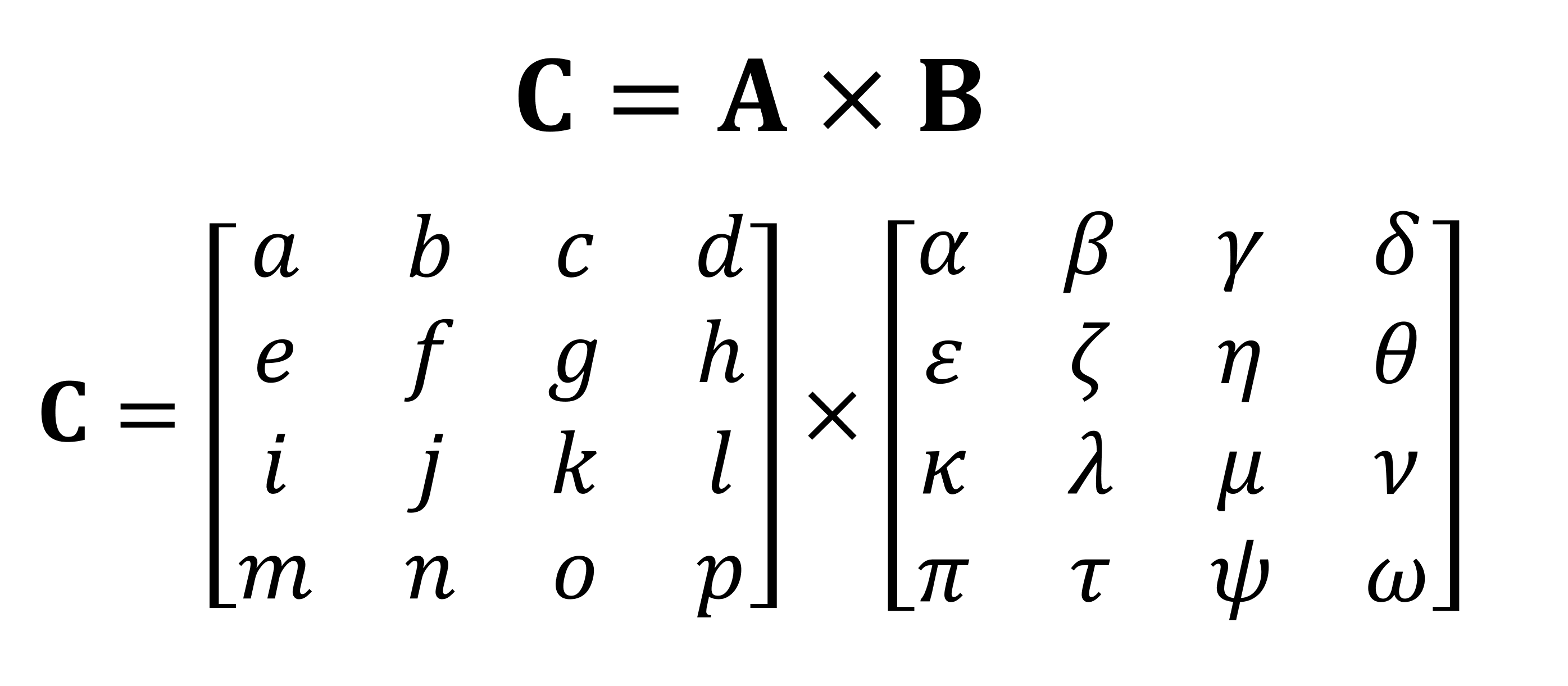
O resultado final da multiplicação será sempre o mesmo número de linhas da primeira matriz e o mesmo número de colunas da segunda. Como você multiplica essas duas matrizes? Como isso:
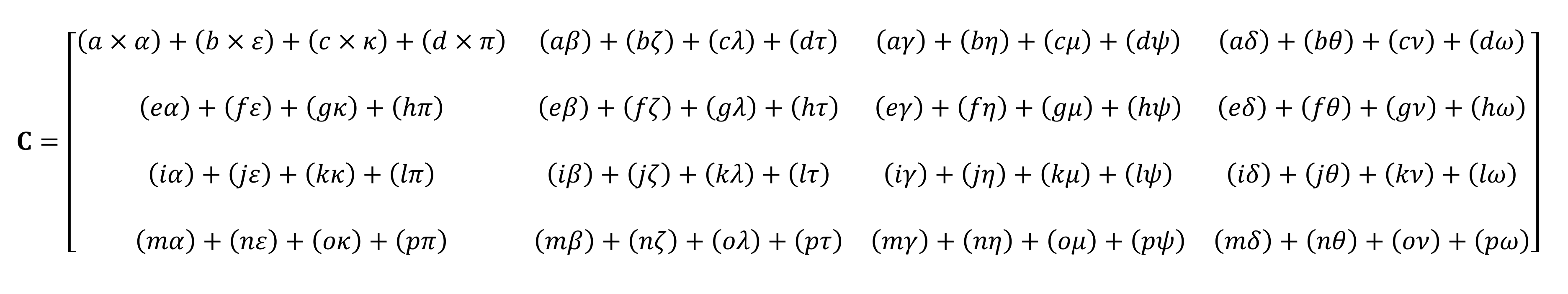
Não será possível contá-lo nos dedos.
Como você pode ver, o cálculo do produto "simples" das matrizes consiste em um monte de pequenas multiplicações e adições. Uma vez que qualquer unidade de processamento central moderna pode executar ambas as operações, os tensores mais simples podem ser executados por qualquer desktop, laptop ou tablet.
No entanto, o exemplo mostrado acima contém 64 multiplicações e 48 adições; cada pequeno produto fornece um valor que precisa ser armazenado em algum lugar antes que possa ser adicionado aos outros três pequenos produtos para que o valor do tensor final possa ser armazenado posteriormente. Portanto, apesar da simplicidade matemática das multiplicações de matrizes, elas são computacionalmente caras. - é necessário usar muitos registradores, e o cache deve ser capaz de lidar com um monte de leituras e gravações.

Arquitetura Intel Sandy Bridge, que introduziu as extensões AVX pela primeira vez
Ao longo dos anos, os processadores AMD e Intel tiveram várias extensões (MMX, SSE e agora AVX - todas elas são SIMD, instrução única , dados múltiplos ), permitindo que o processador processe simultaneamente muitos números ponto flutuante; isso é exatamente o que é necessário para a multiplicação da matriz.
Mas existe um tipo especial de processador que é projetado especificamente para lidar com operações SIMD: a unidade de processamento gráfico (GPU).
Mais inteligente do que uma calculadora normal?
No mundo dos gráficos, é necessário transmitir e processar simultaneamente grandes quantidades de informações na forma de vetores. Devido à sua capacidade de processamento paralelo, as GPUs são ideais para processamento de tensor; todas as GPUs modernas suportam uma funcionalidade chamada GEMM ( General Matrix Multiplication ).
Esta é uma operação "colada" em que duas matrizes são multiplicadas e o resultado é então acumulado com outra matriz. Existem restrições importantes no formato das matrizes e todas estão relacionadas ao número de linhas e colunas de cada matriz.

Requisitos de linha e coluna do GEMM: matriz A (mxk), matriz B (kxn), matriz C (mxn)
Os algoritmos usados para realizar operações em matrizes geralmente funcionam melhor quando as matrizes são quadradas (por exemplo, uma matriz 10 x 10 funcionará melhor do que 50 x 2) e bastante pequeno em tamanho. Mas eles ainda terão um desempenho melhor se processados em equipamentos exclusivamente projetados para essas operações.
Em dezembro de 2017, a Nvidia lançou uma placa de vídeo com GPU apresentando a nova arquitetura Volta . Ele era voltado para o mercado profissional, portanto este chip não era usado em modelos GeForce. Foi único porque se tornou a primeira GPU com núcleos apenas para realizar cálculos de tensores.

Placa de vídeo Nvidia Titan V com chip GV100 Volta. Sim, você pode executar o Crysis nele. Os
núcleos tensores da Nvidia foram projetados para executar 64 GEMMs por ciclo de clock com 4 x 4 matrizes contendo valores FP16 (números de ponto flutuante de 16 bits) ou multiplicação FP16 com adição FP32. Esses tensores são muito pequenos em tamanho, portanto, ao processar conjuntos de dados reais, os kernels processam pequenas partes de grandes matrizes, criando a resposta final.
Menos de um ano depois, a Nvidia lançou a arquitetura Turing . Desta vez, núcleos tensores também foram instalados no modelo GeForcenível do consumidor. O sistema foi melhorado para suportar outros formatos de dados, como INT8 (valor inteiro de 8 bits), mas fora isso eles funcionavam da mesma forma que em Volta.

No início deste ano, a arquitetura Ampere estreou na GPU de data center A100 e, desta vez, a Nvidia melhorou o desempenho (256 GEMM por ciclo em vez de 64), adicionou novos formatos de dados e a capacidade de processamento muito rápido de tensores esparsos (matrizes com muitos zeros).
Os programadores podem acessar os núcleos tensores dos chips Volta, Turing e Ampere muito facilmente: o código só precisa usar um sinalizador informando a API e os drivers para usar núcleos tensores, o tipo de dados deve ser suportado pelos núcleos e as dimensões da matriz devem ser múltiplos de 8. Quando executado Todas essas condições serão atendidas pelo equipamento.
Tudo isso é ótimo, mas quão melhores são os Tensor Cores no processamento de GEMM do que os núcleos GPU regulares?
Quando o Volta foi lançado, a Anandtech fez testes de matemática em três placas Nvidia: a nova Volta, a mais poderosa da linha Pascal, e a velha placa Maxwell.
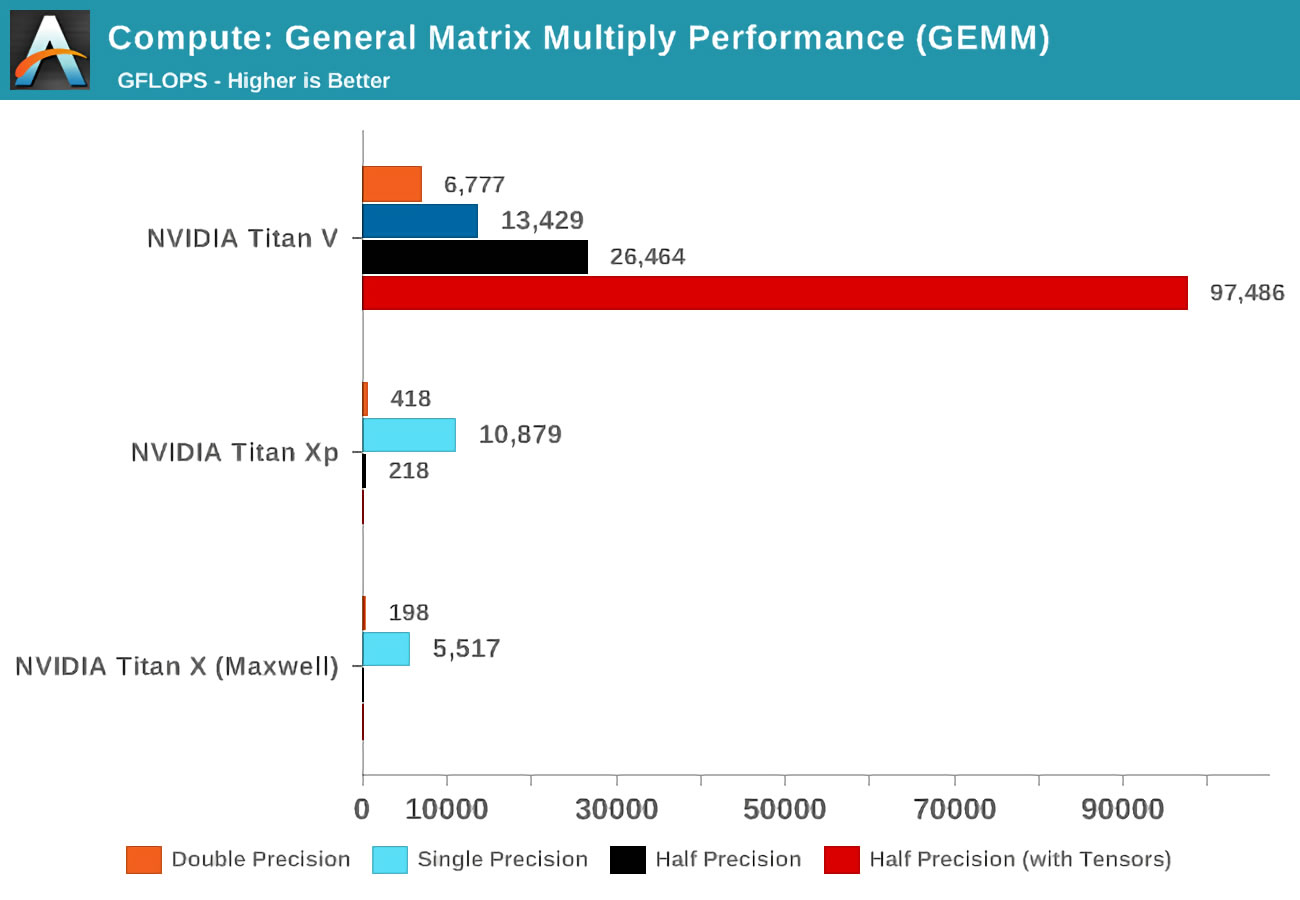
O conceito de exatidão (precisão) refere-se ao número de bits usados para números de ponto flutuante nas matrizes: duplo (duplo) denota 64, um único (único) - 32 e assim por diante. O eixo horizontal é o número máximo de operações de ponto flutuante realizadas por segundo, ou FLOPs para breve (lembre-se de que um GEMM é 3 FLOPs).
Dê uma olhada nos resultados ao usar kernels tensores em vez dos chamados kernels CUDA! Obviamente, eles são incríveis neste trabalho, mas o que podemos fazer com kernels tensores?
A matemática que torna tudo melhor
A computação de tensores é extremamente útil em física e engenharia, é usada para resolver todos os tipos de problemas complexos em mecânica dos fluidos , eletromagnetismo e astrofísica , no entanto, os computadores que foram usados para processar esses números geralmente executavam operações de matriz em grandes aglomerados de unidades de processamento central.
Outra área em que os tensores são populares é o aprendizado de máquina , especialmente sua subseção "aprendizado profundo". Seu significado se resume ao processamento de enormes conjuntos de dados em matrizes gigantes chamadas de redes neurais . As conexões entre diferentes valores de dados recebem um certo peso - um número que expressa a importância de uma determinada conexão.
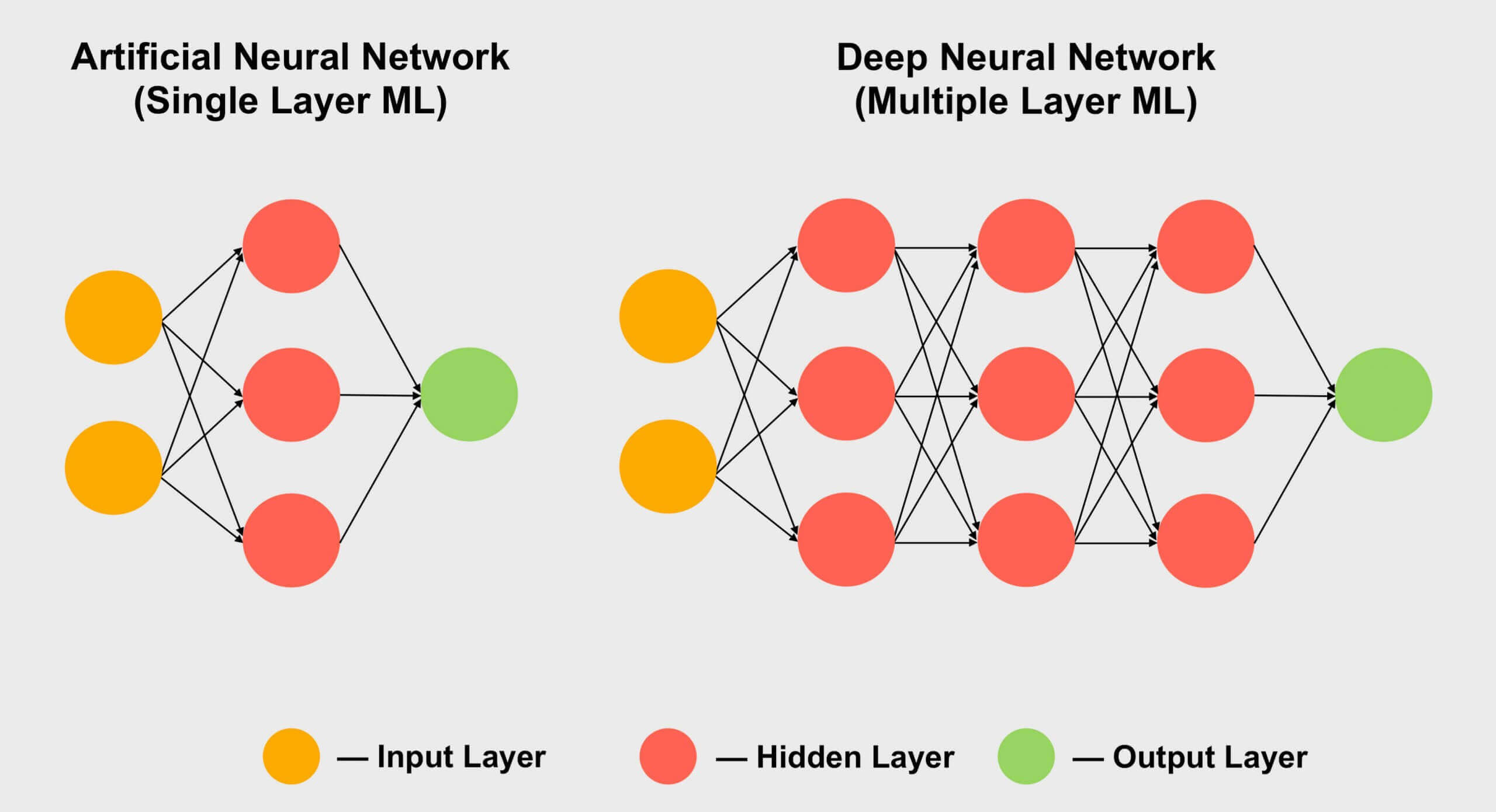
Portanto, quando precisamos descobrir como todas essas centenas, senão milhares de conexões interagem, precisamos multiplicar cada pedaço de dados na rede por todos os pesos de conexão possíveis. Em outras palavras, multiplique duas matrizes, que é a matemática tensorial clássica!

Chips Google TPU 3.0 resfriados a água
É por isso que todos os supercomputadores de aprendizado profundo usam GPUs, e quase sempre Nvidia. No entanto, algumas empresas até desenvolveram seus próprios processadores a partir de núcleos tensores. O Google, por exemplo, anunciou o desenvolvimento de sua primeira TPU ( unidade de processamento de tensores ) em 2016 , mas esses chips são tão especializados que não podem fazer nada além de operações com matrizes.
Tensor de núcleos em GPUs de consumidor (GeForce RTX)
Mas e se eu comprar uma placa de vídeo Nvidia GeForce RTX sem ser um astrofísico resolvendo problemas Riemannianos múltiplos, ou um especialista em experiências com profundidades de rede neural convolucional ...? Como posso usar kernels tensores?
Na maioria das vezes, eles não se aplicam à renderização, codificação ou decodificação regular de vídeo, então pode parecer que você desperdiçou dinheiro em um recurso inútil. No entanto, a Nvidia construiu núcleos tensores em seus produtos de consumo em 2018 (Turing GeForce RTX) enquanto implementava DLSS - Deep Learning Super Sampling .

O princípio é simples: renderize o quadro em uma resolução bastante baixa e, após a conclusão, aumente a resolução do resultado final para que corresponda às dimensões "nativas" da tela do monitor (por exemplo, renderize em 1080p e, em seguida, redimensione para 1400p). Isso melhora o desempenho porque menos pixels são processados e ainda produz uma bela imagem na tela.
Os consoles têm esse recurso há anos e muitos jogos de PC modernos também oferecem esse recurso. Em Assassin's Creed: Odyssey da Ubisoft, você pode reduzir a resolução de renderização para apenas 50% da resolução do monitor. Infelizmente, os resultados não parecem tão bonitos. É assim que o jogo se parece em 4K com configurações gráficas máximas:

As texturas ficam mais bonitas em altas resoluções porque retêm mais detalhes. No entanto, é preciso muito processamento para exibir esses pixels na tela. Agora dê uma olhada no que acontece quando a renderização é definida para 1080p (25% do número anterior de pixels), usando os shaders no final para esticar a imagem para 4K.

Devido à compressão jpeg, a diferença pode não ser imediatamente perceptível, mas você pode ver que a armadura do personagem e a rocha ao longe parecem borradas. Vamos ampliar parte da imagem para ver mais de perto:

A imagem à esquerda é renderizada em 4K; a imagem à direita é 1080p esticada para 4K. A diferença é muito mais perceptível em movimento, pois a suavização de todos os detalhes rapidamente se transforma em uma bagunça borrada. Parte da nitidez pode ser restaurada graças ao efeito de nitidez dos drivers da placa de vídeo, mas gostaríamos de não ter que fazer isso de forma alguma.
É aqui que o DLSS entra em jogo - na primeira versãoEsta tecnologia Nvidia analisou vários jogos selecionados; eles rodaram em alta resolução, baixa resolução, com e sem anti-aliasing. Em todos esses modos, um conjunto de imagens foi gerado e carregado nos supercomputadores da empresa, que usaram uma rede neural para determinar a melhor forma de transformar uma imagem 1080p em uma imagem perfeita em uma resolução mais alta.

Devo dizer que o DLSS 1.0 não era perfeito : muitas vezes os detalhes se perdiam e estranhas cintilações apareciam em alguns lugares. Além disso, ele não usava os próprios núcleos tensores da placa de vídeo (era executado na rede Nvidia) e cada jogo habilitado para DLSS exigia uma pesquisa separada da Nvidia para gerar o algoritmo de aumento de escala.

Quando a versão 2.0 foi lançada no início de 2020, grandes melhorias foram feitas nela. Mais importante ainda, os supercomputadores da Nvidia agora eram usados apenas para criar um algoritmo de upscaling geral - a nova versão do DLSS usa dados de um quadro renderizado para processar pixels usando um modelo neural (núcleos tensores de GPU).

Estamos impressionados com as capacidades do DLSS 2.0 , mas até agora poucos jogos o suportam - no momento em que este livro foi escrito, havia apenas 12. Mais e mais desenvolvedores desejam implementá-lo em seus jogos futuros, e por um bom motivo.
Qualquer aumento de escala pode alcançar ganhos de produtividade significativos, portanto, você pode ter certeza de que o DLSS continuará a evoluir.
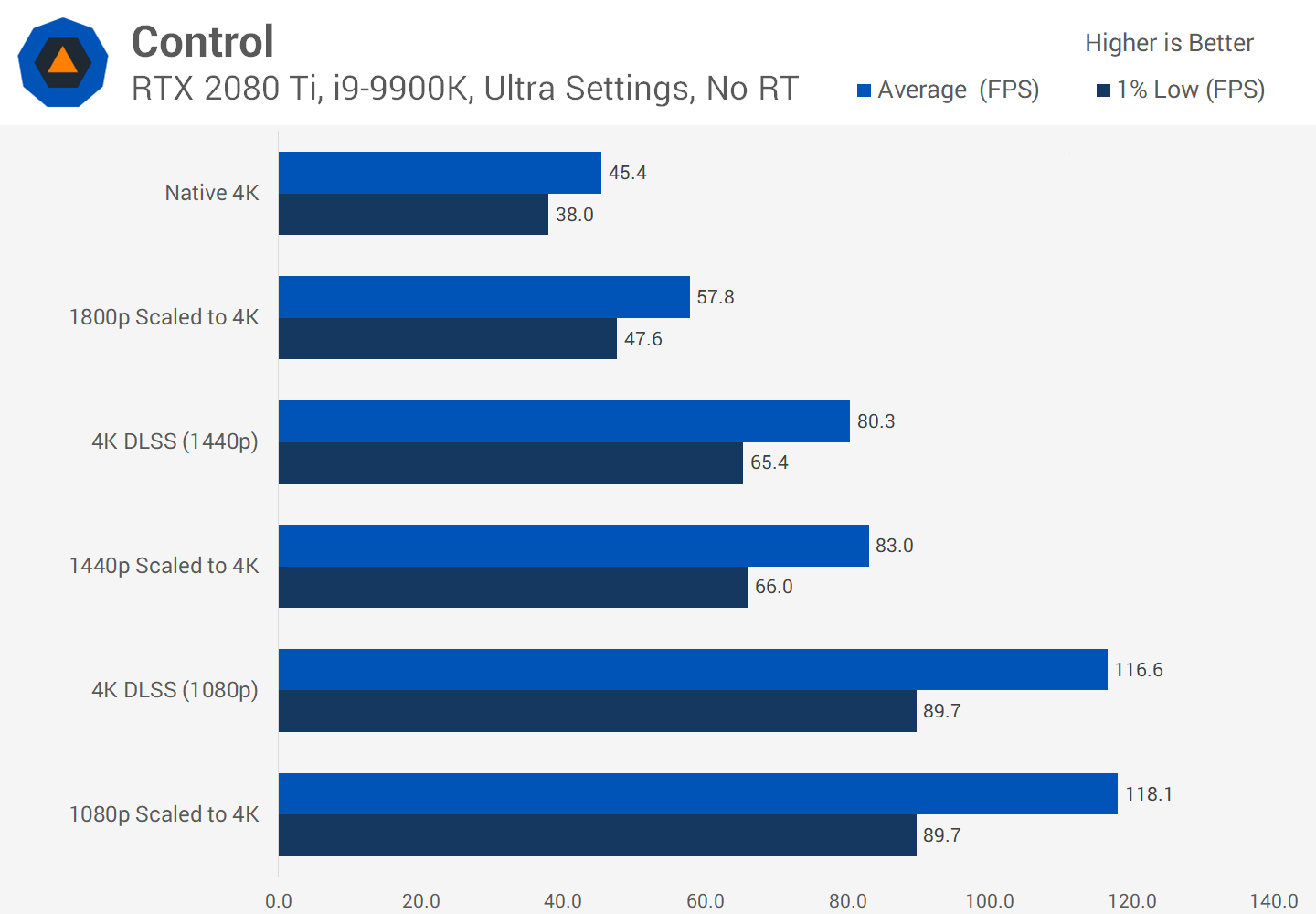
Embora os resultados visuais do DLSS nem sempre sejam perfeitos, ao liberar recursos de renderização, os desenvolvedores podem adicionar mais efeitos visuais ou fornecer um nível de gráfico em uma ampla gama de plataformas.
Por exemplo, o DLSS é frequentemente anunciado junto com o rastreamento de raios em jogos "habilitados para RTX". As placas GeForce RTX contêm blocos computacionais adicionais chamados núcleos RT, que são blocos lógicos especializados para acelerar as interseções de triângulo de raios e a travessia da hierarquia de volume delimitador (BVH). Esses dois processos são procedimentos muito demorados que determinam como a luz interage com outros objetos na cena.
Como descobrimos, o rastreamento de raiosÉ um processo muito demorado, portanto, para garantir um nível aceitável de taxa de quadros em jogos, os desenvolvedores devem limitar o número de raios e reflexos realizados na cena. Este processo pode criar imagens granuladas, portanto, um algoritmo de redução de ruído deve ser aplicado, o que aumenta a complexidade do processamento. Espera-se que os kernels tensores melhorem o desempenho desse processo eliminando o ruído usando IA, mas isso ainda não foi percebido: a maioria dos aplicativos modernos ainda usa kernels CUDA para essa tarefa. Por outro lado, uma vez que DLSS 2.0 está se tornando uma técnica de upsizing muito prática, Tensor Kernels pode ser usado efetivamente para aumentar as taxas de quadros após o traçado de raio em uma cena.
Existem outros planos para usar os núcleos tensores de placas GeForce RTX, como melhorar as animações de personagens ou simular tecidos . Mas, como acontece com o DLSS 1.0, levará muito tempo até que haja centenas de jogos que usam computação de matriz especializada na GPU.
Um começo promissor
Portanto, a situação é a seguinte - núcleos tensores, excelentes unidades de hardware, que, no entanto, são encontrados apenas em algumas placas de consumo. Alguma coisa mudará no futuro? Visto que a Nvidia já melhorou significativamente o desempenho de cada Tensor Core em sua arquitetura Ampere, há uma boa chance de que eles sejam instalados no modelo de gama baixa a média também.
Embora esses núcleos ainda não estejam nas GPUs da AMD e Intel, talvez os veremos no futuro. A AMD possui um sistema para afiar ou realçar detalhes em frames acabados ao custo de uma ligeira diminuição no desempenho, então a empresa pode se ater a este sistema, principalmente por não precisar ser integrado pelos desenvolvedores, basta habilitá-lo nos drivers.
Também há uma percepção de que o espaço nos cristais nos chips gráficos seria melhor gasto em núcleos de shader adicionais - isso é o que a Nvidia fez ao criar versões econômicas de seus chips Turing. Em produtos como a GeForce GTX 1650 , a empresa abandonou completamente os núcleos tensores e os substituiu por shaders FP16 adicionais.
Mas, por enquanto, se você deseja fornecer processamento GEMM ultrarrápido e tirar o máximo proveito dele, então você tem duas opções: comprar um monte de enormes CPUs multicore ou apenas uma GPU com núcleos tensores.
Veja também: