
Desde o início, gostaria de esclarecer que, neste caso, o Oracle é apresentado como uma linguagem SQL coletiva. Os agrupamentos e a forma como são aplicados aplicam-se a toda a família do SQL (que aqui é entendida como uma linguagem de consulta estruturada) e é aplicável a todas as consultas, com correções para a sintaxe de cada linguagem.
Tentarei explicar de maneira breve e fácil todas as informações necessárias em duas partes. A postagem provavelmente será útil para desenvolvedores novatos. Quem se importa - bem-vindo ao gato.
Parte 1: Ofertas por ordem, grupo por, tendo
Aqui vamos falar sobre classificação - Ordenar por, agrupar - Agrupar por, filtrar - Ter, e plano de consulta. Mas as primeiras coisas primeiro.
Ordenar por
O operador Order by classifica os valores de saída, ou seja, classifica o valor recuperado por uma coluna específica. A classificação também pode ser aplicada por um alias de coluna que é definido usando um operador.
A vantagem de Ordenar por é que ele pode ser aplicado a colunas numéricas e de string. As colunas de string são geralmente classificadas em ordem alfabética.
A classificação crescente é aplicada por padrão. Se você quiser classificar as colunas em ordem decrescente, use o operador DESC adicional.
Sintaxe:
SELECT coluna1, coluna2, … (indica o nome)
FROM nome_tabela
ORDER BY coluna1, coluna2 … ASC | DESC ;
Vejamos tudo com exemplos:
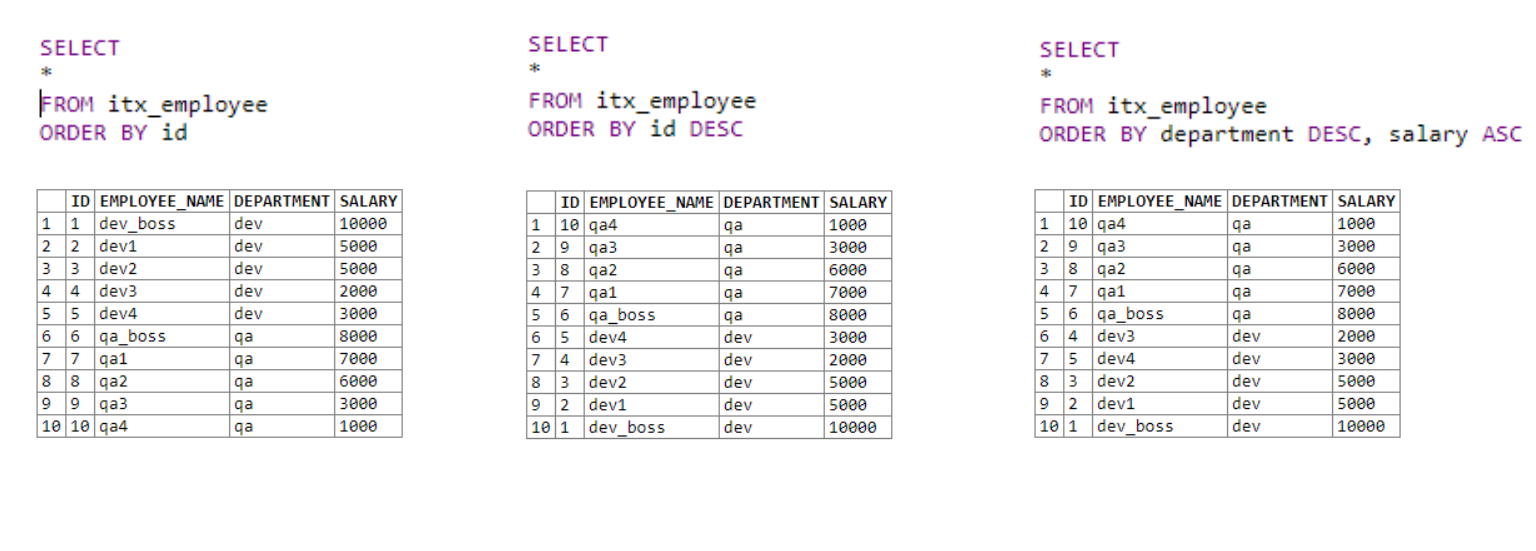
Na primeira tabela, obtemos todos os dados e os classificamos em ordem crescente pela coluna ID.
No segundo, também obtemos todos os dados. Classifique pela coluna ID em ordem decrescente usando a palavra-chave DESC .
A terceira tabela usa vários campos de classificação. Primeiro, vem a classificação por departamento. Se o primeiro operador for igual para campos com o mesmo departamento, a segunda condição de classificação é aplicada; no nosso caso, esse é o salário.
É muito simples. Podemos especificar mais de uma condição de classificação, o que nos permite classificar as listas de saída de forma mais inteligente.
Grupo por
No SQL, a instrução Group by reúne dados recuperados de um banco de dados em grupos específicos. O agrupamento divide todos os dados em conjuntos lógicos para que os cálculos estatísticos possam ser realizados separadamente em cada grupo.
Este operador é usado para combinar os resultados de uma seleção por uma ou mais colunas. Após o agrupamento, haverá apenas uma entrada para cada valor usado na coluna.
O uso do SQL Group por instrução está intimamente relacionado ao uso de funções agregadas e a instrução SQL Having. Uma função agregada em SQL é uma função que retorna um único valor sobre um conjunto de valores de coluna. Por exemplo: COUNT (), MIN (), MAX (), AVG (), SUM ()
Sintaxe:
SELECT nome_da_coluna (s)
FROM nome_da_tabela
WHERE condição
GROUP BY column_name (s)
ORDER BY column_name (s);
Agrupar por aparece após a cláusula WHERE condicional na consulta SELECT . Opcionalmente, você pode usar ORDER BY para classificar os valores de saída.
Portanto, com base na tabela do exemplo anterior, precisamos encontrar o salário máximo para os funcionários de cada departamento. A amostra final deve incluir o nome do departamento e o salário máximo.
Solução 1 (sem usar agrupamento):
SELECT DISTINCT
ie.department
ie.slary
FROM itx_employee ie
WHERE ie.salary = (
SELECT
max(ie1.salary)
FROM itx_employee ie1
WHERE ie.department = ie1.department
)
Solução 2 (usando agrupamento):
SELECT
department,
max(salary)
FROM itx_employee
GROUP BY department
No primeiro exemplo, resolvemos o problema sem usar agrupamento, mas usando uma subseleção, ou seja, coloque o segundo em um select. Na segunda solução, usamos agrupamento.
O segundo exemplo é mais curto e mais legível, embora execute as mesmas funções do primeiro.
Como o Group by funciona para nós: primeiro, ele divide dois departamentos em grupos qa e dev. Em seguida, ele procura o salário máximo para cada um deles.
Tendo
Ter é uma ferramenta de filtragem. Indica o resultado da execução de funções agregadas. Ter cláusula é usado em SQL onde WHERE não pode ser usado.
Se a cláusula WHERE definir um predicado para filtrar linhas, Tendo é usado após o agrupamento para definir um predicado lógico que filtra o grupo pelos valores das funções agregadas. A cláusula é necessária para testar os valores obtidos usando funções agregadas de grupos de linhas.
Sintaxe:
SELECT nome_da_coluna (s)
FROM nome_da_tabela
WHERE condição
GRUPO POR nome_da_coluna (s)
TENDO condição
Primeiro, exibimos os departamentos com um salário médio maior que 4000. Em seguida, exibimos o salário máximo usando a filtragem.
Solução 1 (sem usar GROUP BY e HAVING):
SELECT DISTINCT
ie.department AS "DEPARTMENT",
(
(SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department)
) AS "AVG SALARY"
FROM itx_employee ie
where (SELECT
AVG(ie1.salary)
FROM itx_employee ie1
WHERE ie1.department = ie.department) > 4000
Solução 2 (usando GROUP BY e HAVING):
SELECT
department,
AVG(salary)
FROM itx_employee
GROUP BY department
HAVING AVG(salary) > 4000
O primeiro exemplo usa duas subseleções, uma para encontrar o salário máximo e a outra para filtrar o salário médio. O segundo exemplo, novamente, saiu muito mais simples e conciso.
Solicitar plano
Muitas vezes, há situações em que uma solicitação leva muito tempo, consumindo recursos significativos de memória e discos. Para entender por que uma consulta está sendo executada de forma longa e ineficiente, podemos examinar o plano de consulta.
Um plano de consulta é o plano de execução pretendido para uma consulta, ou seja, como o DBMS irá executá-lo. O DBMS descreverá todas as operações que serão realizadas na subconsulta. Depois de analisar tudo, poderemos entender onde estão os pontos fracos da consulta e usando o plano de consulta podemos otimizá-los.
A execução de qualquer instrução SQL no Oracle recupera o chamado "plano de execução". Este plano de execução de consulta é uma descrição de como o Oracle buscará os dados de acordo com a instrução SQL que está sendo executada. Um plano é uma árvore que contém a ordem das etapas e a relação entre elas.
As ferramentas que permitem obter o plano de execução estimado de uma consulta incluem Toad, SQL Navigator, PL / SQL Developer , etc. Elas fornecem uma série de indicadores do consumo de recursos de uma consulta, entre os quais os principais são: custo - custo de execução e cardinalidade (ou linhas ) - cardinalidade (ou quantidade linhas).
Quanto maior o valor desses indicadores, menos eficiente é a consulta.
Abaixo você pode ver a análise do plano de consulta. A primeira solução usa uma sub-seleção, a segunda usa um agrupamento. Observe que a primeira solução processou 22 linhas, a segunda processou 15.
Análise do plano de consulta:
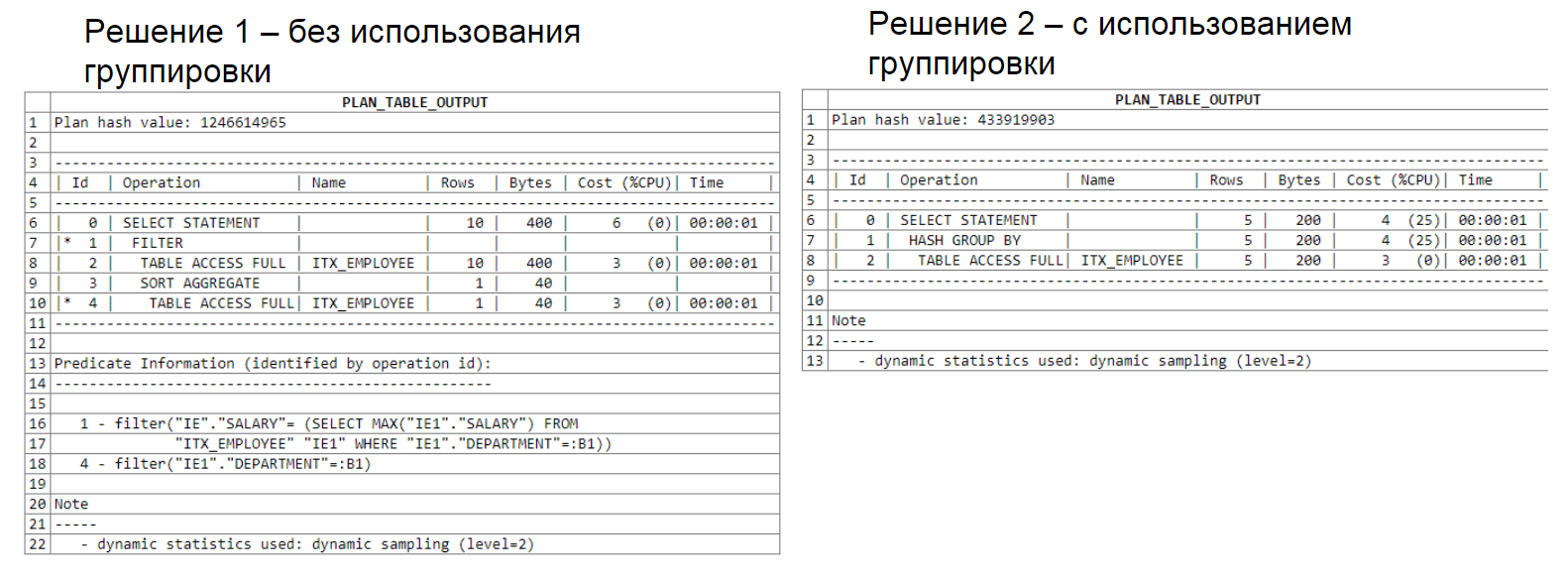
outra análise do plano de consulta que usa duas subseleções:
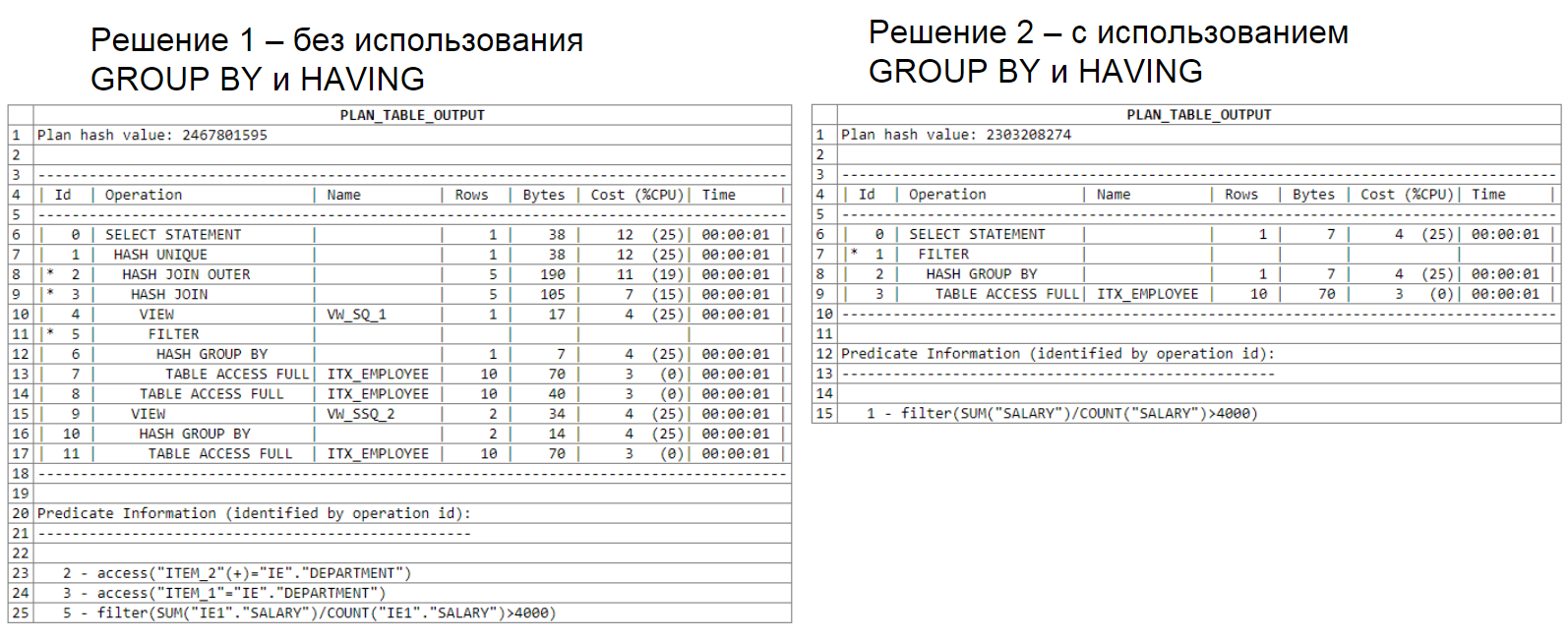
Este exemplo é apresentado como uma variante do uso ineficiente de ferramentas SQL e não recomendo que você o use em suas consultas.
Todos os recursos acima irão facilitar sua vida ao escrever consultas e aumentar a qualidade e legibilidade do seu código.
Parte 2: funções de janela
As funções de janela datam do Microsoft SQL Server 2005. Elas realizam cálculos em um determinado intervalo de linhas dentro de uma cláusula Select. Resumindo, uma "janela" é um conjunto de linhas dentro das quais ocorre um cálculo. "Janela" permite reduzir os dados e processá-los melhor. Este recurso permite que você divida todo o conjunto de dados em janelas.
O uso de janelas tem uma grande vantagem. Não há necessidade de formar um conjunto de dados para cálculos, o que permite salvar todas as linhas do conjunto com seu ID único. O resultado das funções da janela é adicionado à seleção resultante em mais um campo.
Sintaxe:
SELECT nome_da_coluna (s)
Função agregada (coluna a ser calculada)
OVER ([ PARTITION BYcoluna para grupo]
FROM nome_tabela
[ coluna ORDER BY para classificar]
[ expressão ROWS ou RANGE para restringir linhas dentro de um grupo])
OVER PARTITION BY é uma propriedade para definir o tamanho da janela. Aqui você pode especificar informações adicionais, fornecer comandos de serviço, por exemplo, adicionar um número de linha. A sintaxe da função de janela se ajusta perfeitamente à seleção da coluna.
Vejamos tudo com um exemplo: outro departamento foi adicionado à nossa tabela, agora existem 15 linhas na tabela. Tentaremos retirar funcionários, seu salário, bem como o salário máximo da organização.
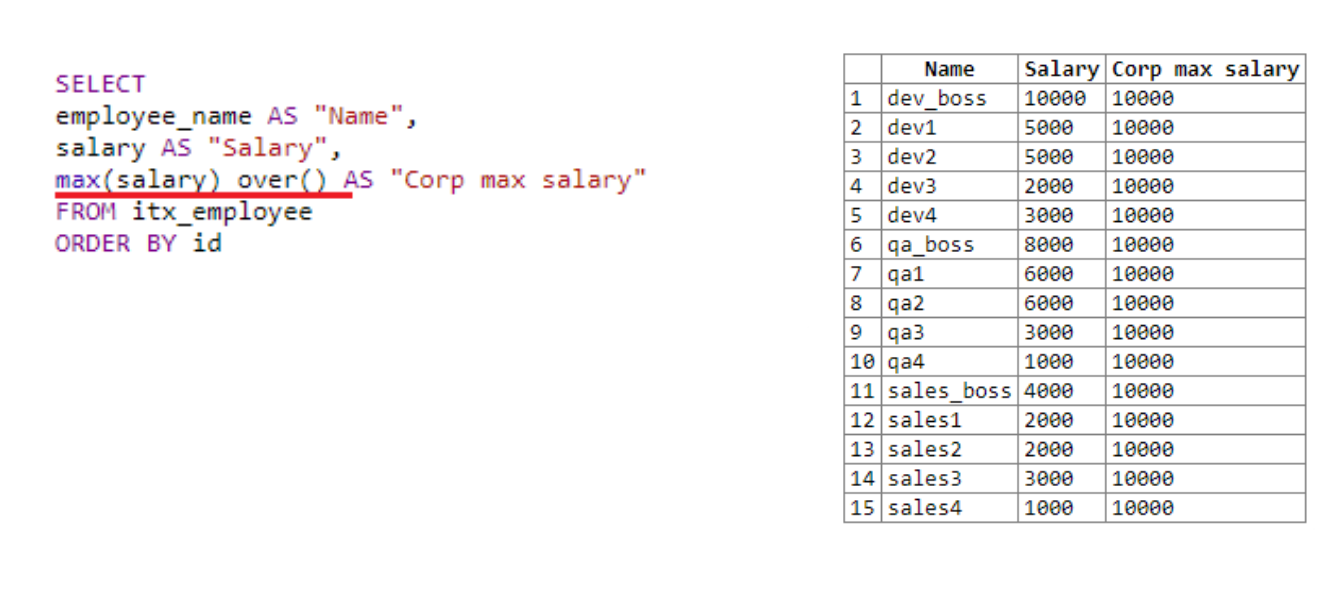
No primeiro campo, pegamos o nome, no segundo - o salário. Em seguida, usamos a função de janela em ()... Usamos para obter o máximo salário em toda a organização, já que o tamanho da "janela" não é indicado. Acima () com parênteses vazios se aplica a toda a seleção. Portanto, em todos os lugares, o salário máximo é de 10.000.O resultado da ação da função janela é adicionado a cada linha.
Se removermos a menção à função de janela da quarta linha da consulta, ou seja, apenas o máximo (salário) permanece , a solicitação não funcionará. O salário máximo simplesmente não podia ser calculado. Como os dados seriam processados linha por linha, e no momento da chamada de max (salário) , haveria apenas um número na linha atual, ou seja, funcionário atual. É aqui que você pode ver a vantagem da função de janela. No momento da chamada, funciona com toda a janela e com todos os dados disponíveis.
Vejamos outro exemplo onde você precisa mostrar o salário máximo de cada departamento:
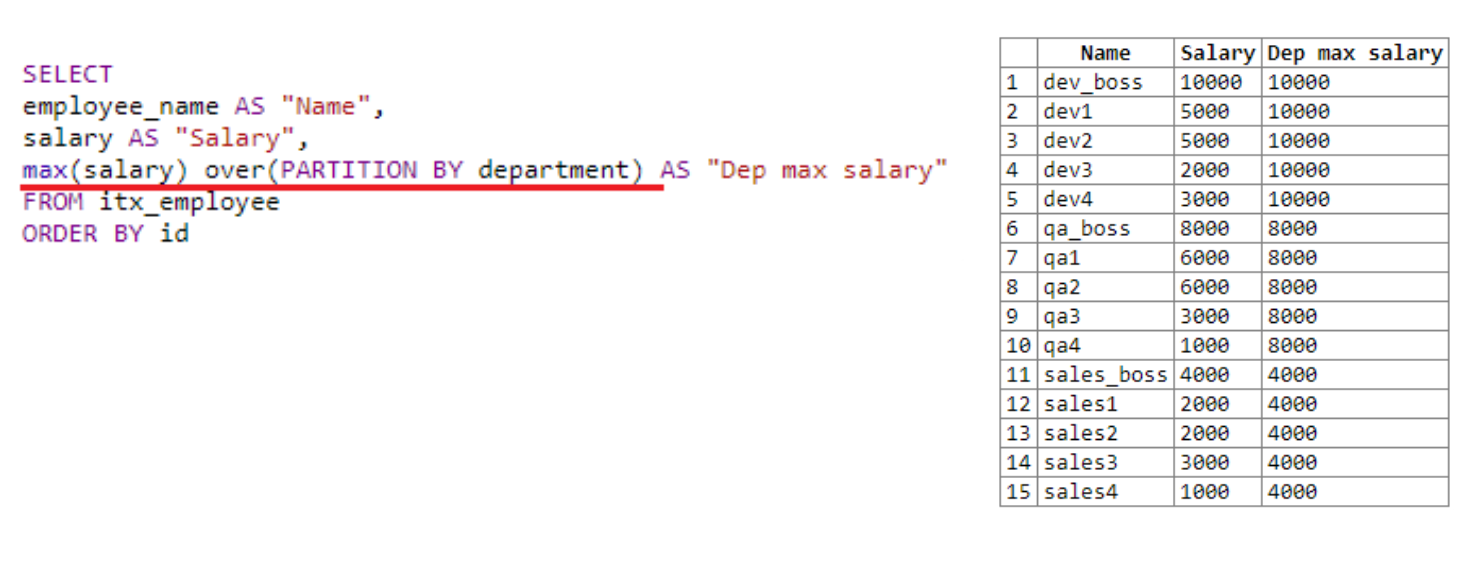
Na verdade, definimos a moldura da "janela", dividindo-a em departamentos. Usamos o departamento como exemplo de classificação. Temos três departamentos: dev, qa e vendas.
"Janela" encontra o salário máximo para cada departamento. Como resultado da seleção, vemos que ele encontrou o salário máximo primeiro para dev, depois para qa e, em seguida, para vendas. Conforme mencionado acima, o resultado da função de janela é escrito no resultado de busca de cada linha.
No exemplo anterior, os parênteses após terminados não foram especificados. Aqui usamos PARTITION BY, que nos permitiu definir o tamanho de nossa janela. Aqui você pode especificar algumas informações adicionais, enviar comandos de serviço, por exemplo, o número da linha.
Conclusão
SQL não é tão simples quanto parece à primeira vista. Tudo o que foi descrito acima é a funcionalidade básica das funções da janela. Com a ajuda deles, você pode “simplificar” nossas solicitações. Mas há muito mais potencial oculto neles: há operadores de serviços públicos (por exemplo ROWS ou RANGE) que podem ser combinados para adicionar mais funcionalidade às consultas.
Espero que o post tenha sido útil para todos os interessados neste tópico.