
Foto do site Unsplash . Por Sasha • Histórias
Scikit-learn é uma das bibliotecas de aprendizado de máquina Python mais usadas. Sua interface simples e padrão permite o pré-processamento, treinamento, otimização e avaliação do modelo de dados.
Este projeto, desenhado por David Cournapeau, nasceu como parte do programa Google Summer of Code e foi lançado em 2010. Desde o seu início, a biblioteca evoluiu para uma infraestrutura rica para a construção de modelos de aprendizado de máquina. Novos recursos permitem que você resolva ainda mais tarefas e melhore a usabilidade. Neste artigo, apresentarei dez dos recursos mais interessantes que você talvez não conheça.
1. Conjuntos de dados integrados
Na API da biblioteca scikit-learn, você pode encontrar conjuntos de dados integrados contendo dados gerados e reais . Você pode usá-los com apenas uma linha de código. Esses dados são extremamente úteis se você está apenas aprendendo ou apenas deseja testar algo rapidamente.
Além disso, usando uma ferramenta especial, você mesmo pode gerar dados sintéticos para tarefas de regressão
make_regression(), agrupamento make_blobs()e classificação make_classification().
Cada método produz dados já divididos em X (recursos) e Y (variável de destino) para que possam ser usados diretamente para treinar o modelo.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. Acesso a conjuntos de dados públicos de terceiros
Se você deseja acessar uma variedade de conjuntos de dados públicos diretamente por meio do scikit-learn, verifique o recurso útil que permite importar dados diretamente de openml.org . Este site contém mais de 21.000 conjuntos de dados diferentes que podem ser usados em projetos de aprendizado de máquina.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. Classificadores prontos para modelos de linha de base de treinamento
Ao criar um modelo de aprendizado de máquina para um projeto, é aconselhável criar primeiro um modelo de linha de base. É um modelo fictício que sempre prevê a classe mais comum. Isso lhe dará benchmarks para avaliar seu modelo mais complexo. Além disso, você pode ter certeza da qualidade do seu trabalho, por exemplo, que ele produz mais do que apenas um conjunto de dados selecionados aleatoriamente.
A biblioteca scikit-learn tem uma
DummyClassifier()para problemas de classificação e DummyRegressor()para trabalhar com regressão.
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. Própria API para visualização
O Scikit-learn possui uma API de visualização integrada que permite que você visualize como seu modelo funciona sem importar quaisquer outras bibliotecas. Ele fornece as seguintes opções: gráficos de dependência, matriz de erro, curvas ROC e Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()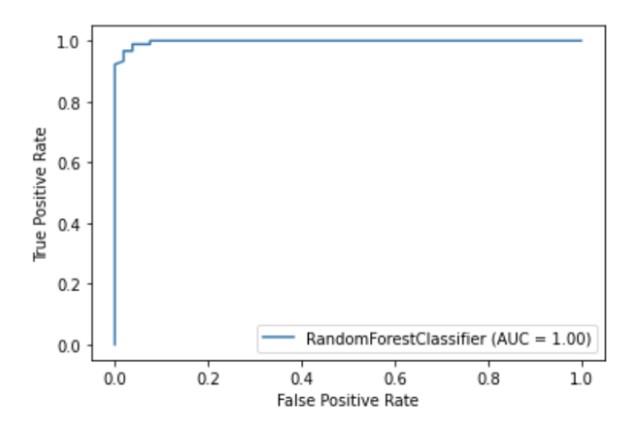
Ilustração do autor
5. Métodos integrados de seleção de recursos
Uma das maneiras de melhorar a qualidade do modelo é usar apenas os recursos mais úteis no treinamento ou remover os menos informativos. Este processo é chamado de seleção de recursos.
O Scikit-learn possui vários métodos para realizar a seleção de recursos , um dos quais é
SelectPercentile(). Este método seleciona o percentil X dos recursos mais informativos com base no método estatístico de estimativa especificado.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. Pipelines para conectar estágios no processo de aprendizado de máquina
Além de poder usar uma lista enorme de algoritmos de aprendizado de máquina, o scikit-learn também oferece várias funções para pré-processamento e transformação de dados. Para garantir reprodutibilidade e acessibilidade no processo de aprendizado de máquina no scikit-learn foram criados o Pipeline , que reúne as diferentes etapas e estágio de pré-processamento do modelo de treinamento.
O pipeline armazena todos os estágios do fluxo de trabalho como um único objeto que pode ser chamado pelos métodos de ajuste e previsão. Quando você executa o método de ajuste em um objeto de pipeline, as etapas de pré-processamento e treinamento do modelo são executadas automaticamente.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer para variar métodos de pré-processamento para diferentes recursos
Muitos conjuntos de dados contêm diferentes tipos de recursos, que requerem vários estágios diferentes para o pré-processamento. Por exemplo, você pode se deparar com uma mistura de dados categóricos e numéricos e pode desejar dimensionar colunas numéricas e converter recursos categóricos em numéricos usando codificação one-hot.
O pipeline scikit -learn é equipado com uma função ColumnTransformer , que permite indicar facilmente o método de pré-processamento mais apropriado para colunas específicas por meio da indexação ou especificando os nomes das colunas.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. Obtenha facilmente uma imagem HTML de seu pipeline
Os pipelines costumam ser bastante complexos, especialmente ao trabalhar com dados reais. Portanto, é muito conveniente que você possa usar o scikit-learn para exibir o diagrama HTML das etapas do pipeline.
from sklearn import set_config
set_config(display='diagram')
lr
Ilustração do autor
9. Função de plotagem para visualizar árvores de decisão
A função
plot_tree()permite criar um diagrama das etapas presentes no modelo de árvore de decisão.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. Muitas bibliotecas de terceiros que estendem as funções do scikit-learn
Existem muitas bibliotecas de terceiros que são compatíveis com o scikit-learn e estendem sua funcionalidade.
Por exemplo, a biblioteca Category Encoders , que oferece uma escolha mais ampla de métodos de pré-processamento para recursos categóricos, ou a biblioteca ELI5 , para uma interpretação mais detalhada do modelo.
Ambos os recursos também podem ser acessados diretamente por meio do pipeline scikit-learn.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))Obrigado pela atenção!