
Olá, Khabrovites. Hoje vamos falar sobre RxJava. Sei que uma carroça e um carrinho foram escritos sobre ela, mas me parece que tenho alguns pontos interessantes que vale a pena compartilhar. Em primeiro lugar, vou contar como usamos o RxJava junto com a arquitetura VIPER para aplicativos Android e, ao mesmo tempo, dar uma olhada na maneira "clássica" de usá-lo. Depois disso, vamos examinar os principais recursos do RxJava e nos deter em mais detalhes sobre como os planejadores são organizados. Se você já tem um estoque de lanches, então seja bem-vindo em gato.
Uma arquitetura que agrada a todos
RxJava é uma implementação do conceito ReactiveX e foi criado pela Netflix. O blog deles tem uma série de artigos sobre por que eles fizeram isso e quais problemas resolveram. Os links (1, 2) podem ser encontrados no final do artigo. A Netflix usou RxJava no lado do servidor (backend) para paralelizar o processamento de uma grande solicitação. Embora eles tenham sugerido uma maneira de usar RxJava no backend, essa arquitetura é adequada para escrever diferentes tipos de aplicativos (móvel, desktop, backend e muitos outros). Os desenvolvedores da Netflix usaram RxJava na camada de serviço de forma que cada método da camada de serviço retorne um Observable. A questão é que os elementos em um Observable podem ser entregues de forma síncrona e assíncrona. Isso permite que o método decida por si mesmo se deve retornar o valor imediatamente de forma síncrona (por exemplo,se disponível no cache) ou primeiro obtenha esses valores (por exemplo, de um banco de dados ou serviço remoto) e retorne-os de forma assíncrona. Em qualquer caso, o controle retornará imediatamente após a chamada do método (com ou sem dados).
/**
* , ,
* , ,
* callback `onNext()`
*/
public Observable<T> getProduct(String name) {
if (productInCache(name)) {
// ,
return Observable.create(observer -> {
observer.onNext(getProductFromCache(name));
observer.onComplete();
});
} else {
//
return Observable.<T>create(observer -> {
try {
//
T product = getProductFromRemoteService(name);
//
observer.onNext(product);
observer.onComplete();
} catch (Exception e) {
observer.onError(e);
}
})
// Observable IO
// /
.subscribeOn(Schedulers.io());
}
}
Com essa abordagem, obtemos uma API imutável para o cliente (em nosso caso, o controlador) e diferentes implementações. O cliente sempre interage com o Observável da mesma maneira. Não importa se os valores são recebidos de forma síncrona ou não. Ao mesmo tempo, as implementações de API podem mudar de síncronas para assíncronas, sem afetar a interação com o cliente de forma alguma. Com essa abordagem, você não pode pensar completamente em como organizar multithreading e se concentrar na implementação de tarefas de negócios.
A abordagem é aplicável não apenas na camada de serviço no backend, mas também nas arquiteturas MVC, MVP, MVVM, etc. Por exemplo, para MVP, podemos fazer uma classe Interactor que será responsável por receber e salvar dados em várias fontes, e fazer tudo seus métodos retornaram Observable. Eles serão um contrato de interação com a Model. Isso também permitirá que o Presenter aproveite todo o poder das operadoras disponíveis no RxJava.
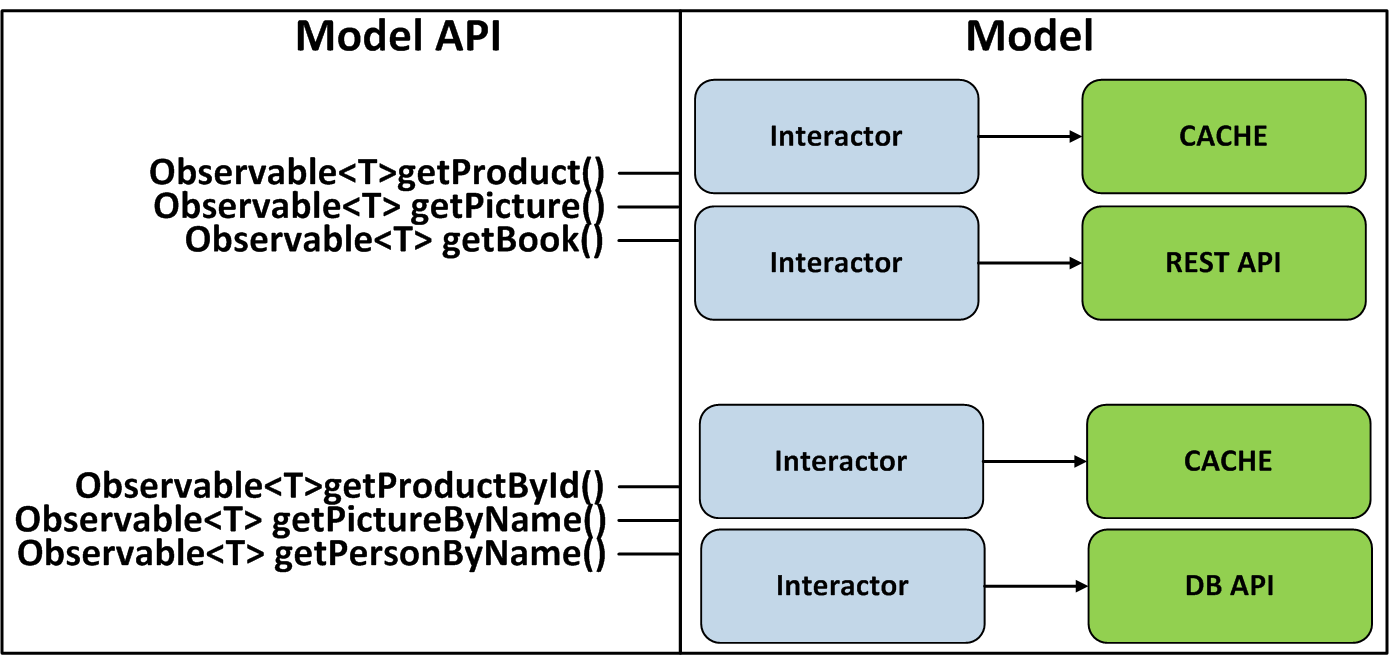
Podemos ir mais longe e tornar a API reativa do Presenter, mas para isso precisamos implementar corretamente o mecanismo de cancelamento de assinatura que permite que todas as visualizações cancelem simultaneamente a assinatura do Presenter.
A seguir, vamos ver um exemplo de uso dessa abordagem para a arquitetura VIPER, que é um MVP aprimorado. Também vale a pena lembrar que você não pode fazer objetos singleton Observable, porque as assinaturas de tais Observables irão gerar vazamentos de memória.
Experiência em Android e VIPER
Na maioria dos projetos Android atuais e novos, usamos a arquitetura VIPER. Eu a conheci quando entrei para um dos projetos em que ela já estava acostumada. Lembro-me de ficar surpreso quando me perguntaram se eu estava pensando em iOS. “IOS em um projeto Android?” Pensei. Enquanto isso, o VIPER veio do mundo iOS e, na verdade, é uma versão mais estruturada e modular do MVP. VIPER está muito bem escrito neste artigo (3).
No início, tudo parecia bem: corretamente dividido, camadas não sobrecarregadas, cada camada tem sua própria área de responsabilidade, lógica clara. Mas, depois de algum tempo, uma desvantagem começou a aparecer e, conforme o projeto crescia e mudava, até começou a interferir.
O fato é que usamos o Interactor da mesma forma que nossos colegas em nosso artigo. O Interactor implementa um pequeno caso de uso, por exemplo, "baixar produtos da rede" ou "pegar um produto do banco de dados por id" e executa ações no fluxo de trabalho. Internamente, o Interator executa operações usando o Observable. Para "executar" o Interator e obter o resultado, o usuário implementa a interface ObserverEntity junto com seus métodos onNext, onError e onComplete e a passa junto com os parâmetros para o método execute (params, ObserverEntity).
, , - . , . - . , default, default, , , . , , , , , , . , , executar (params, ObserverEntity), . , , , . , .
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
// ,
//
}
@Override
public void onError(Throwable throwable) {
//
// -
}
@Override
public void onComplete() {
//
// -
}
});
Além dos métodos vazios, existe um problema mais irritante. Usamos o Interactor para realizar uma ação, mas quase sempre essa ação não é a única. Por exemplo, podemos pegar um produto de um banco de dados, obter comentários e uma foto sobre ele, salvar tudo em outro lugar e finalmente ir para outra tela. Aqui, cada ação depende da anterior e, ao usar Interactors, obtemos uma enorme cadeia de retornos de chamada, que pode ser muito tedioso de rastrear.
private void checkProduct(int id, Locale locale) {
getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale), new ObserverEntity<Product>() {
@Override
public void onNext(Product product) {
getProductInfo(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void getProductInfo(Product product) {
getReviewsByProductIdInteractor.execute(product.getId(), new ObserverEntity<List<Review>>() {
@Override
public void onNext(List<Review> reviews) {
product.setReviews(reviews);
saveProduct(productInfo);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
// -
}
});
getImageForProductInteractor.execute(product.getId(), new ObserverEntity<Image>() {
@Override
public void onNext(Image image) {
product.setImage(image);
saveProduct(product);
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
}
});
}
private void saveProduct(Product product) {
saveProductInteractor.execute(product, new ObserverEntity<Void>() {
@Override
public void onNext(Void aVoid) {
}
@Override
public void onError(Throwable throwable) {
// -
}
@Override
public void onComplete() {
goToSomeScreen();
}
});
}
Bem, você gostou dessa massa? Ao mesmo tempo, temos uma lógica de negócios simples e aninhamento único, mas imagine o que aconteceria com um código mais complexo. Também dificulta a reutilização do método e a aplicação de diferentes agendadores para o Interator.
A solução é surpreendentemente simples. Você acha que essa abordagem está tentando imitar o comportamento de um Observável, mas isso é errado e cria restrições estranhas por si só? Como eu disse antes, pegamos esse código de um projeto existente. Ao consertar este código legado, usaremos a abordagem que os caras da Netflix nos legaram. Em vez de ter que implementar um ObserverEntity todas as vezes, vamos fazer o Interactor retornar apenas um Observable.
private Observable<Product> getProductById(int id, Locale locale) {
return getProductByIdInteractor.execute(new TypesUtil.Pair<>(id, locale));
}
private Observable<Product> getProductInfo(Product product) {
return getReviewsByProductIdInteractor.execute(product.getId())
.map(reviews -> {
product.set(reviews);
return product;
})
.flatMap(product -> {
getImageForProductInteractor.execute(product.getId())
.map(image -> {
product.set(image);
return product;
})
});
}
private Observable<Product> saveProduct(Product product) {
return saveProductInteractor.execute(product);
}
private doAll(int id, Locale locale) {
//
getProductById (id, locale)
//
.flatMap(product -> getProductInfo(product))
//
.flatMap(product -> saveProduct(product))
//
.ignoreElements()
//
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
//
.subscribe(() -> goToSomeScreen(), throwable -> handleError());
}
Voila! Portanto, não apenas nos livramos daquele horror incômodo e pesado, mas também trouxemos o poder do RxJava para o Presenter.
Conceitos básicos
Muitas vezes vi como eles tentaram explicar o conceito de RxJava usando programação reativa funcional (doravante FRP). Na verdade, não tem nada a ver com esta biblioteca. FRP é mais sobre valores contínuos em mudança dinâmica (comportamentos), tempo contínuo e semântica denotacional. No final do artigo, você pode encontrar alguns links interessantes (4, 5, 6, 7).
RxJava usa programação reativa e programação funcional como seus principais conceitos. A programação reativa pode ser descrita como uma transferência sequencial de informações do objeto observado para o objeto observador, de forma que o objeto observador as receba automaticamente (de forma assíncrona) conforme essas informações surgem.
A programação funcional utiliza o conceito de funções puras, ou seja, aquelas que não utilizam ou alteram o estado externo; eles são totalmente dependentes de suas entradas para obter seus resultados. A ausência de efeitos colaterais para funções puras torna possível usar os resultados de uma função como parâmetros de entrada para outra. Isso permite compor uma cadeia ilimitada de funções.
Juntar esses dois conceitos, junto com os padrões Observer e Iterator do GoF, permite criar fluxos de dados assíncronos e processá-los com um grande arsenal de funções muito úteis. Também torna possível usar multithreading de forma muito simples, e o mais importante com segurança, sem pensar em seus problemas, como sincronização, inconsistência de memória, sobreposição de thread, etc.
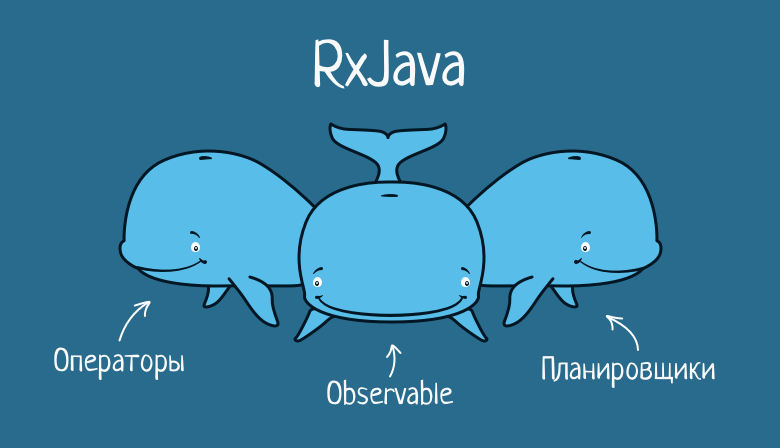
Três baleias de RxJava
Os três componentes principais sobre os quais o RxJava é construído são observáveis, operadores e planejadores.
Observable em RxJava é responsável por implementar o paradigma reativo. Os observáveis são freqüentemente chamados de fluxos porque implementam tanto o conceito de fluxos de dados quanto a propagação de mudanças. Observável é um tipo que atinge um paradigma reativo combinando dois padrões da Gangue dos Quatro: Observer e Iterator. Observable adiciona duas semânticas ausentes ao Observer, que estão em Iterable:
- A capacidade do produtor de sinalizar ao consumidor que não há mais dados disponíveis (o loop foreach no Iterable termina e apenas retorna; o Observable, neste caso, chama o método onCompleate).
- A capacidade do produtor de informar ao consumidor que ocorreu um erro e o Observable não pode mais emitir elementos (Iterable lança uma exceção se ocorrer um erro durante a iteração; Observable chama onError em seu observador e sai).
Se o Iterable usa a abordagem "pull", ou seja, o consumidor solicita um valor do produtor e o thread bloqueia até que esse valor chegue, o Observable é seu equivalente "push". Isso significa que o produtor envia valores ao consumidor apenas quando eles se tornam disponíveis.
Observável é apenas o começo do RxJava. Ele permite que você busque valores de forma assíncrona, mas o poder real vem com "extensões reativas" (portanto, ReactiveX) - operadoresque permitem transformar, combinar e criar sequências de elementos emitidos por um Observable. É aqui que o paradigma funcional vem à tona com suas funções puras. Os operadores fazem pleno uso deste conceito. Eles permitem que você trabalhe com segurança com as sequências de elementos que um Observável emite, sem medo de efeitos colaterais, a menos, é claro, que você mesmo os crie. Os operadores permitem multithreading sem se preocupar com questões como segurança de thread, controle de thread de baixo nível, sincronização, erros de inconsistência de memória, sobreposições de thread, etc. Tendo um grande arsenal de funções, você pode operar facilmente com vários dados. Isso nos dá uma ferramenta muito poderosa. O principal a ser lembrado é que os operadores modificam os itens emitidos pelo Observable, não o próprio Observable.Os observáveis nunca mudam desde que foram criados. Ao pensar em threads e operadores, é melhor pensar em gráficos. Se você não sabe como resolver o problema, pense, olhe para toda a lista de operadores disponíveis e pense novamente.
Embora o próprio conceito de programação reativa seja assíncrono (não deve ser confundido com multithreading), por padrão, todos os itens em um Observable são entregues ao assinante de forma síncrona, no mesmo thread em que o método subscribe () foi chamado. Para introduzir essa assincronia, você precisa chamar os métodos onNext (T), onError (Throwable), onComplete () por conta própria em outro thread de execução ou usar agendadores. Normalmente, todo mundo analisa seu comportamento, então vamos dar uma olhada em sua estrutura.
Planejadoresabstrair o usuário da fonte de paralelismo por trás de sua própria API. Eles garantem que fornecerão propriedades específicas, independentemente do mecanismo de simultaneidade subjacente (implementação), como Threads, loop de evento ou Executor. Os agendadores usam threads daemon. Isso significa que o programa terminará com o término da thread principal de execução, mesmo se algum cálculo ocorrer dentro do operador Observable.
RxJava possui vários planejadores padrão que são adequados para propósitos específicos. Todos eles estendem a classe abstrata Scheduler e implementam sua própria lógica para gerenciar trabalhadores. Por exemplo, o ComputationScheduler, no momento de sua criação, forma um pool de workers, cujo número é igual ao número de threads do processador. O ComputationScheduler então usa trabalhadores para realizar tarefas executáveis. Você pode passar o Runnable para o planejador usando os métodos scheduleDirect () e schedulePeriodicallyDirect (). Para ambos os métodos, o planejador pega o próximo trabalhador do pool e passa o Runnable para ele.
O trabalhador está dentro do planejador e é uma entidade que executa objetos executáveis (tarefas) usando um dos vários esquemas de simultaneidade. Em outras palavras, o planejador obtém o Runnable e o passa para o trabalhador para execução. Você também pode obter de forma independente um trabalhador do planejador e transferir um ou mais Runnable para ele, independentemente de outros trabalhadores e do próprio planejador. Quando um trabalhador recebe uma tarefa, ele a coloca na fila. O trabalhador garante que as tarefas sejam executadas sequencialmente na ordem em que foram enviadas, mas a ordem pode ser perturbada por tarefas pendentes. Por exemplo, no ComputationScheduler, o trabalhador é implementado usando um único thread ScheduledExecutorService.
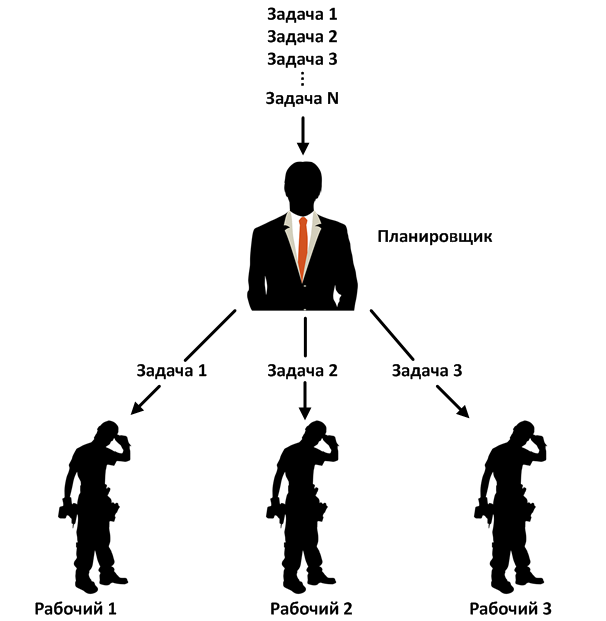
Portanto, temos trabalhadores abstratos que podem implementar qualquer esquema de paralelismo. Essa abordagem oferece muitas vantagens: modularidade, flexibilidade, uma API, diferentes implementações. Vimos uma abordagem semelhante no ExecutorService. Além disso, podemos usar agendadores separados do Observable.
Conclusão
RxJava é uma biblioteca muito poderosa que pode ser usada em uma ampla variedade de maneiras em muitas arquiteturas. As formas de utilizá-lo não se limitam às já existentes, por isso tente sempre adaptá-lo para si. No entanto, lembre-se sobre SOLID, DRY e outros princípios de design, e não se esqueça de compartilhar sua experiência com os colegas. Espero que você tenha aprendido algo novo e interessante com o artigo, até agora!