Gostaria de compartilhar minha experiência na implementação de redes neurais da moda em nossa empresa. Tudo começou quando decidimos construir nosso próprio Service Desk. Por que e por que o seu, você pode ler meu colega Alexei Volkov (cara) aqui .
Vou falar sobre uma inovação recente no sistema: uma rede neural para ajudar o despachante da primeira linha de suporte. Se estiver interessado, bem-vindo ao gato.

Esclarecimento da tarefa
Uma dor de cabeça para qualquer gerente de help desk é uma decisão rápida de atribuir a uma solicitação de cliente recebida. Aqui estão os pedidos:
Boa tarde.
Entendi bem: para compartilhar uma agenda com um usuário específico, você precisa abrir o acesso à sua agenda no PC do usuário que deseja compartilhar a agenda e inserir o e-mail do usuário a quem deseja dar acesso?
De acordo com o regulamento, o despachante deve responder em até dois minutos: registrar a solicitação, determinar a urgência e designar uma unidade responsável. Nesse caso, o despachante escolhe entre 44 divisões da empresa.
As instruções dos despachantes descrevem uma solução para as consultas mais comuns. Por exemplo, fornecer acesso a um data center é uma solicitação simples. Mas as solicitações de serviço incluem muitas tarefas: instalar software, analisar uma situação ou atividade de rede, descobrir detalhes sobre os preços de soluções, verificar todos os tipos de acesso. Às vezes é difícil entender a partir da solicitação para quem o responsável deve enviar a pergunta:
Hi Team,
The sites were down again for few minutes from 2020-07-15 14:59:53 to 2020-07-15 15:12:50 (UTC time zone), now they are working fine. Could you please check and let us know why the sites are fluctuating many times.
Thanks
Houve situações em que o aplicativo foi para o departamento errado. A solicitação foi levada para o trabalho e então reatribuída a outros executores ou enviada de volta ao despachante. Isso aumentou a velocidade da solução. O tempo para resolução das solicitações está escrito no contrato com o cliente (SLA), e somos responsáveis pelo cumprimento dos prazos.
Dentro do sistema, decidimos criar um assistente para despachantes. O objetivo principal era adicionar prompts que ajudassem o funcionário a tomar uma decisão sobre o aplicativo com mais rapidez.
Acima de tudo, eu não queria sucumbir à tendência moderna e colocar o chatbot na primeira linha de suporte. Se você já tentou escrever para esse suporte técnico (que já não peca com isso), você entende o que quero dizer.
Em primeiro lugar, ele entende você muito mal e não responde a pedidos atípicos e, em segundo lugar, é muito difícil chegar a uma pessoa viva.
Em geral, definitivamente não planejamos substituir despachantes por bots de bate-papo, pois queremos que os clientes ainda se comuniquem com uma pessoa ao vivo.
No início, pensei em sair barato e alegre e tentei a abordagem de palavra-chave. Compilamos um dicionário de palavras-chave manualmente, mas isso não foi suficiente. A solução lidava apenas com aplicativos simples, com os quais não havia problemas.
Durante o trabalho de nosso Service Desk, acumulamos um sólido histórico de solicitações, com base no qual podemos reconhecer solicitações semelhantes recebidas e atribuí-las imediatamente aos executores corretos. Armado com o Google e há algum tempo, decidi me aprofundar em minhas opções.
Teoria de aprendizagem
Acontece que minha tarefa é uma tarefa de classificação clássica. Na entrada, o algoritmo recebe o texto primário da aplicação, na saída o atribui a uma das classes previamente conhecidas - ou seja, as divisões da empresa.
Houve muitas soluções. Esta é uma "rede neural", e "classificador bayesiano ingênuo", "vizinhos mais próximos", "regressão logística", "árvore de decisão", "boosting" e muitas, muitas outras opções.
Não haveria tempo para experimentar todas as técnicas. Portanto, optei por redes neurais (há muito tempo queria tentar trabalhar com elas). Como ficou claro mais tarde, essa escolha foi totalmente justificada.
Então, comecei meu mergulho em redes neurais a partir daqui . Algoritmos de aprendizagem estudadosredes neurais: com um professor (aprendizagem supervisionada), sem professor (aprendizagem não supervisionada), com envolvimento parcial de um professor (aprendizagem semi-supervisionada) ou “aprendizagem por reforço”.
Como parte da minha tarefa, surgiu o método de ensino com um professor. Há dados mais do que suficientes para treinamento: mais de 100 mil de aplicativos resolvidos.
Escolha de implementação
Eu escolhi a biblioteca Encog Machine Learning Framework para implementação . Ele vem com documentação acessível e compreensível com exemplos . Além disso, implementação para Java, que está perto de mim.
Resumidamente, a mecânica de trabalho é assim:
- A estrutura da rede neural é pré-configurada: várias camadas de neurônios conectadas por conexões sinápticas.

- Um conjunto de dados de treinamento com um resultado predeterminado é carregado na memória.
- . «». «» .
- «» : , , .
- 3 4 . , . , - .
Eu tentei vários exemplos do framework, percebi que a biblioteca lida com números na entrada com um estrondo. Assim, o exemplo com a definição da classe de íris pelo tamanho da tigela e pétalas ( íris de Fisher ) funcionou bem .
Mas eu tenho algum texto. Isso significa que as letras devem de alguma forma ser transformadas em números. Então, passei para a primeira fase preparatória - "vetorização".
A primeira opção de vetorização: por carta
A maneira mais fácil de transformar texto em números é pegar o alfabeto da primeira camada da rede neural. Acontece 33 letras-neurônios: ABVGDEEZHZYKLMNOPRSTUFHTSCHSHSCHYEUYA.
Cada um recebe um número: a presença de uma letra em uma palavra é considerada como um, e a ausência é considerada zero.
Então, a palavra "olá" nesta codificação terá um vetor:

esse vetor já pode ser fornecido à rede neural para treinamento. Afinal, esse número é 001001000100000011010000000000000 = 1216454656 Depois de mergulhar
na teoria, percebi que não há um ponto específico em analisar letras. Eles não carregam nenhum significado semântico. Por exemplo, a letra "A" estará em todos os textos da proposta. Considere que esse neurônio está sempre ativado e não terá qualquer efeito no resultado. Como todas as outras vogais. E no texto do aplicativo, haverá a maioria das letras do alfabeto. Esta opção não é adequada.
A segunda variante de vetorização: por dicionário
E se você pegar não letras, mas palavras? Digamos o dicionário explicativo de Dahl. E para contar como 1 já a presença de uma palavra no texto, e a ausência - como 0.
Mas aqui me deparei com o número de palavras. O vetor será muito grande. Um neurônio com 200k de neurônios de entrada levará uma eternidade e exigirá muita memória e tempo de CPU. Você tem que fazer seu próprio dicionário. Além disso, há uma especificidade de TI nos textos que Vladimir Ivanovich Dal não conhecia.
Voltei-me para a teoria novamente. Para encurtar o vocabulário ao processar textos, use os mecanismos de N-gramas - uma sequência de N elementos.
A ideia é dividir o texto de entrada em alguns segmentos, compor um dicionário a partir deles e alimentar a rede neural com a presença ou ausência de uma frase no texto original como 1 ou 0. Ou seja, em vez de uma letra, como no caso do alfabeto, não apenas uma letra, mas uma frase inteira será considerada 0 ou 1.
Os mais populares são unigramas, bigramas e trigramas. Usando a frase "Bem-vindo ao DataLine" como exemplo, falarei sobre cada um dos métodos.
- Unigrama - o texto é dividido nas palavras: "bom", "bem-vindo", "v", "DataLine".
- Bigram - nós o dividimos em pares de palavras: "bem-vindo", "bem-vindo", "para DataLine".
- Trigrama - da mesma forma, 3 palavras cada: "bem-vindo ao", "bem-vindo ao DataLine".
- N-gramas - essa é a ideia. Quantos N, tantas palavras seguidas.
- N-. , . 4- N- : «»,« », «», «» . . .
Decidi me limitar ao unigrama. Mas não apenas um unigrama - as palavras ainda eram demais.
O algoritmo "Porter's Stemmer" veio em nosso auxílio , que foi usado para unificar palavras em 1980.
A essência do algoritmo: remover sufixos e terminações da palavra, deixando apenas a parte semântica básica. Por exemplo, as palavras “importante”, “importante”, “importante”, “importante”, “importante”, “importante” são trazidas para a base “importante”. Ou seja, em vez de 6 palavras, haverá uma no dicionário. E esta é uma redução significativa.
Além disso, retirei todos os números, sinais de pontuação, preposições e palavras raras do dicionário, para não criar "ruído". Como resultado, para 100 mil textos, temos um dicionário de 3 mil palavras. Você já pode trabalhar com isso.
Treinamento de rede neural
Então eu já tenho:
- Dicionário de 3k palavras.
- Representação de dicionário vetorizada.
- Os tamanhos das camadas de entrada e saída da rede neural. De acordo com a teoria, um dicionário é fornecido na primeira camada (entrada) e a camada final (saída) é o número de classes de solução. Tenho 44 deles - pelo número de divisões da empresa.
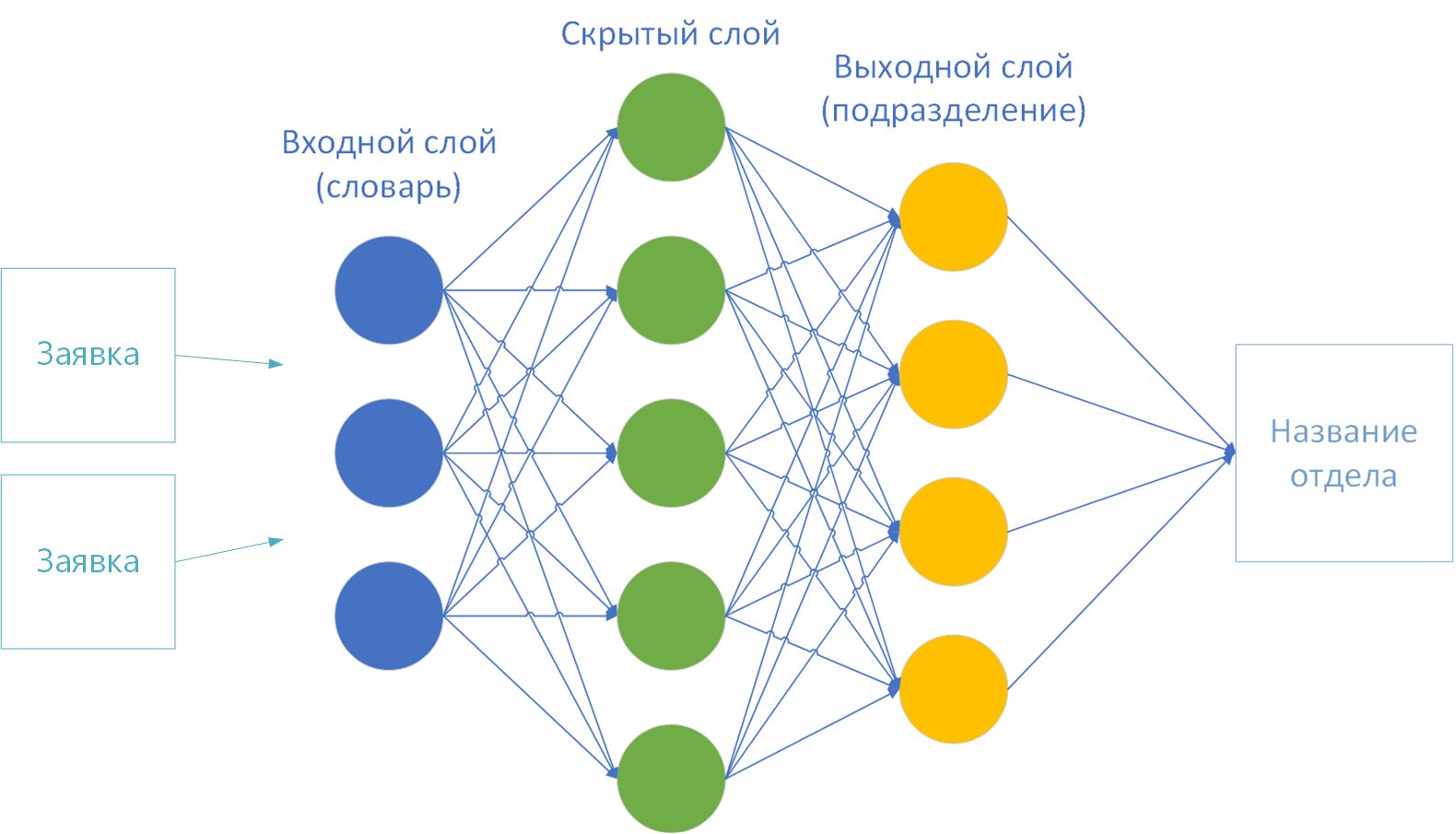
Para treinar uma rede neural, resta muito pouco a escolher:
- Método de ensino.
- Função de ativação.
- O número de camadas ocultas.
Como selecionei os parâmetros . Os parâmetros são sempre selecionados empiricamente para cada tarefa específica. Este é o processo mais longo e tedioso, pois requer muita experimentação.
Então, peguei uma amostra de referência de 11k aplicativos e fiz o cálculo de uma rede neural com vários parâmetros:
- Aos 10k eu treinei uma rede neural.
- Em 1k testei a rede já treinada.
Ou seja, aos 10k construímos um vocabulário e aprendemos. E então mostramos a rede neural treinada 1k textos desconhecidos. O resultado é a porcentagem de erro: a proporção de unidades adivinhadas em relação ao número total de textos.
Como resultado, consegui uma precisão de cerca de 70% em dados desconhecidos.
Empiricamente, descobri que o treinamento pode continuar indefinidamente se os parâmetros errados forem escolhidos. Algumas vezes, o neurônio entrou em um ciclo infinito de cálculos e desligou a máquina de trabalho durante a noite. Para evitar isso, para mim, aceitei o limite de 100 iterações ou até que o erro de rede pare de diminuir.
Aqui estão os parâmetros finais:
Método de ensino . Encog oferece várias opções para escolher: Backpropagation, ManhattanPropagation, QuickPropagation, ResilientPropagation, ScaledConjugateGradient.
Essas são maneiras diferentes de determinar os pesos nas sinapses. Alguns dos métodos funcionam mais rápido, alguns são mais precisos, é melhor ler mais na documentação. A propagação resiliente funcionou bem para mim .
Função de ativação . É necessário determinar o valor do neurônio na saída, dependendo do resultado da soma ponderada das entradas e do valor limite.
Eu escolhi entre 16 opções . Não tive tempo de verificar todas as funções. Portanto, considerei o mais popular: tangente sigmóide e hiperbólica em várias implementações.
No final, decidi pelo ActivationSigmoid .
Número de camadas ocultas... Em teoria, quanto mais camadas ocultas, mais longo e mais difícil é o cálculo. Comecei com uma camada: o cálculo era rápido, mas o resultado era impreciso. Eu me estabeleci em duas camadas ocultas. Com três camadas, foi considerado muito mais longo e o resultado não diferiu muito de um de duas camadas.
Com isso terminei os experimentos. Você pode preparar a ferramenta para produção.
Para a produção!
Mais uma questão de tecnologia.
- Eu estraguei o Spark para que eu pudesse me comunicar com o neurônio via REST.
- Ensinado a salvar os resultados do cálculo em um arquivo. Nem sempre é preciso recalcular ao reiniciar o serviço.
- Adicionada a capacidade de ler dados reais para treinamento diretamente do Service Desk. Anteriormente treinado em arquivos csv.
- Adicionada a capacidade de recalcular a rede neural para anexar o recálculo ao planejador.
- Coletei tudo em uma jarra grossa.
- Pedi aos meus colegas um servidor mais poderoso do que uma máquina de desenvolvimento.
- Zaploil e zadulil recontam uma vez por semana.
- Apertei o botão no lugar certo na Central de Serviços e escrevi aos meus colegas como usar esse milagre.
- Eu coletei estatísticas sobre o que o neurônio escolhe e o que a pessoa escolheu (estatísticas abaixo).
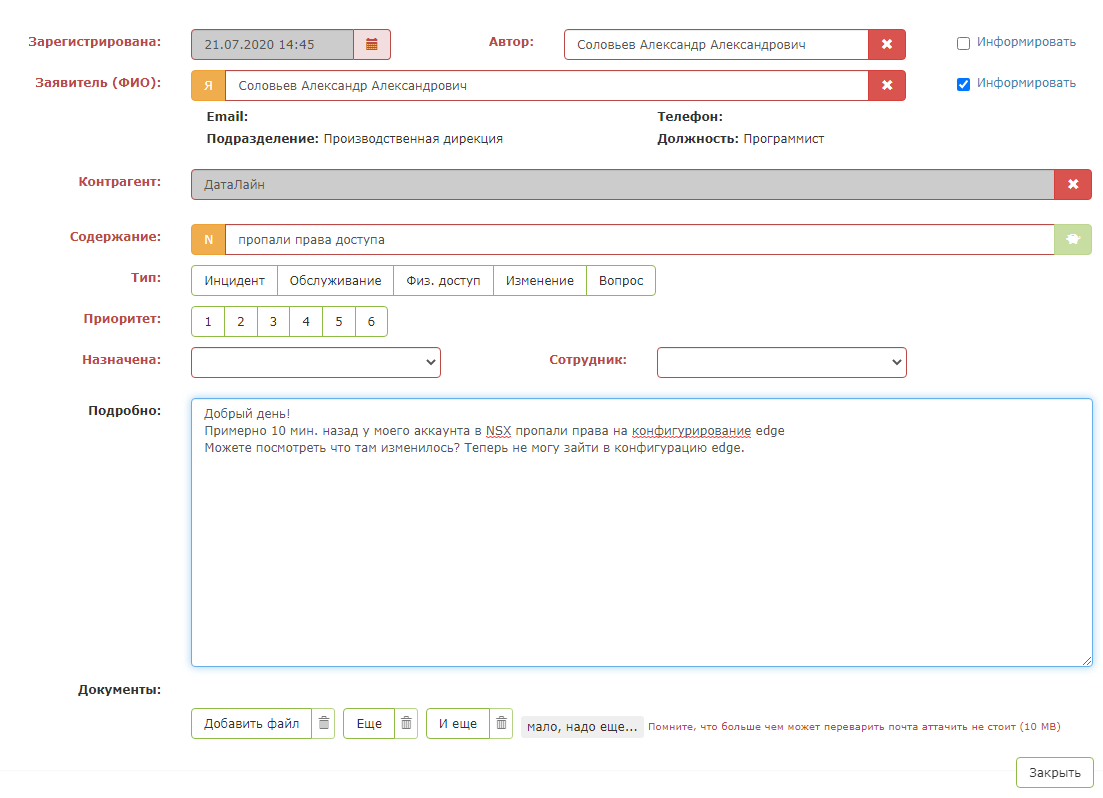
É assim que um aplicativo de teste se parece:
Mas assim que você pressiona o "botão verde mágico", a mágica acontece: os campos do cartão são preenchidos. Resta ao despachante certificar-se de que o sistema avisa corretamente e salvar a solicitação.
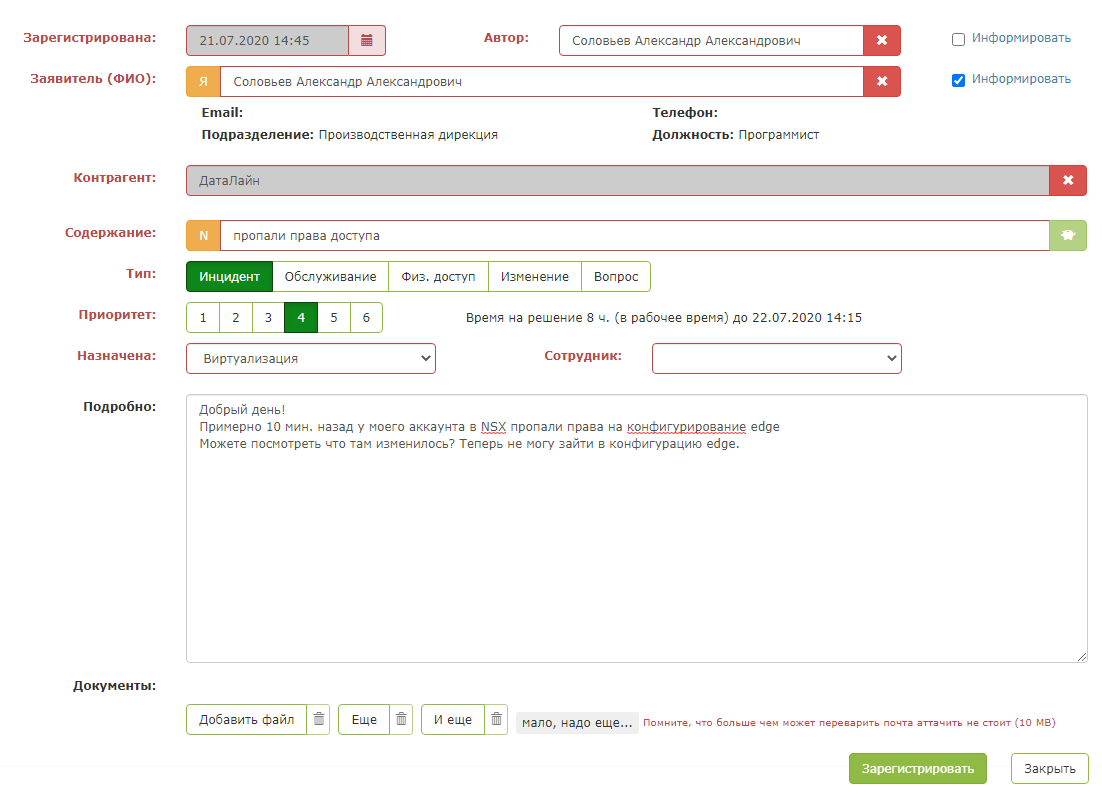
O resultado é um assistente inteligente para o despachante.
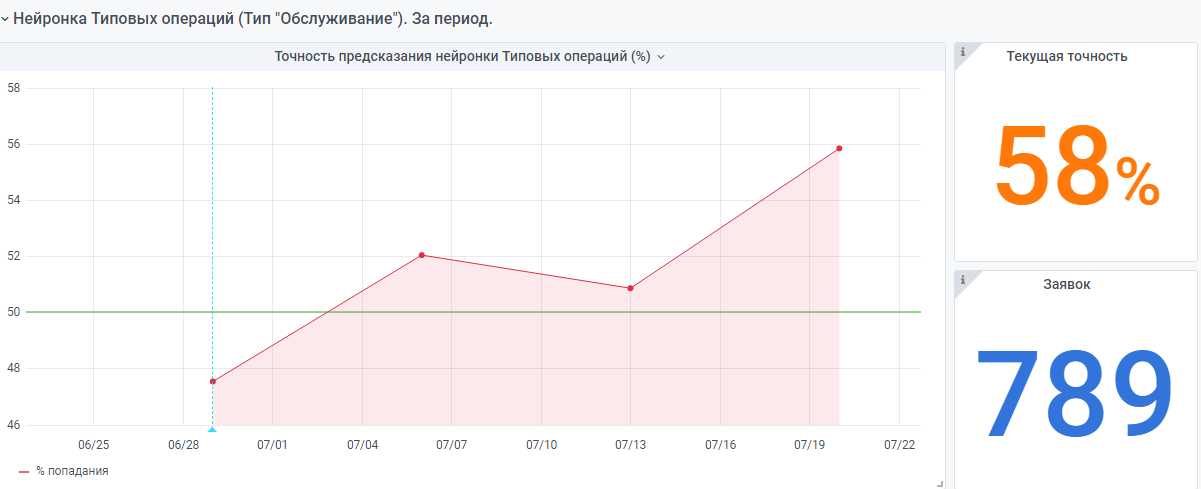
Por exemplo, estatísticas do início do ano.
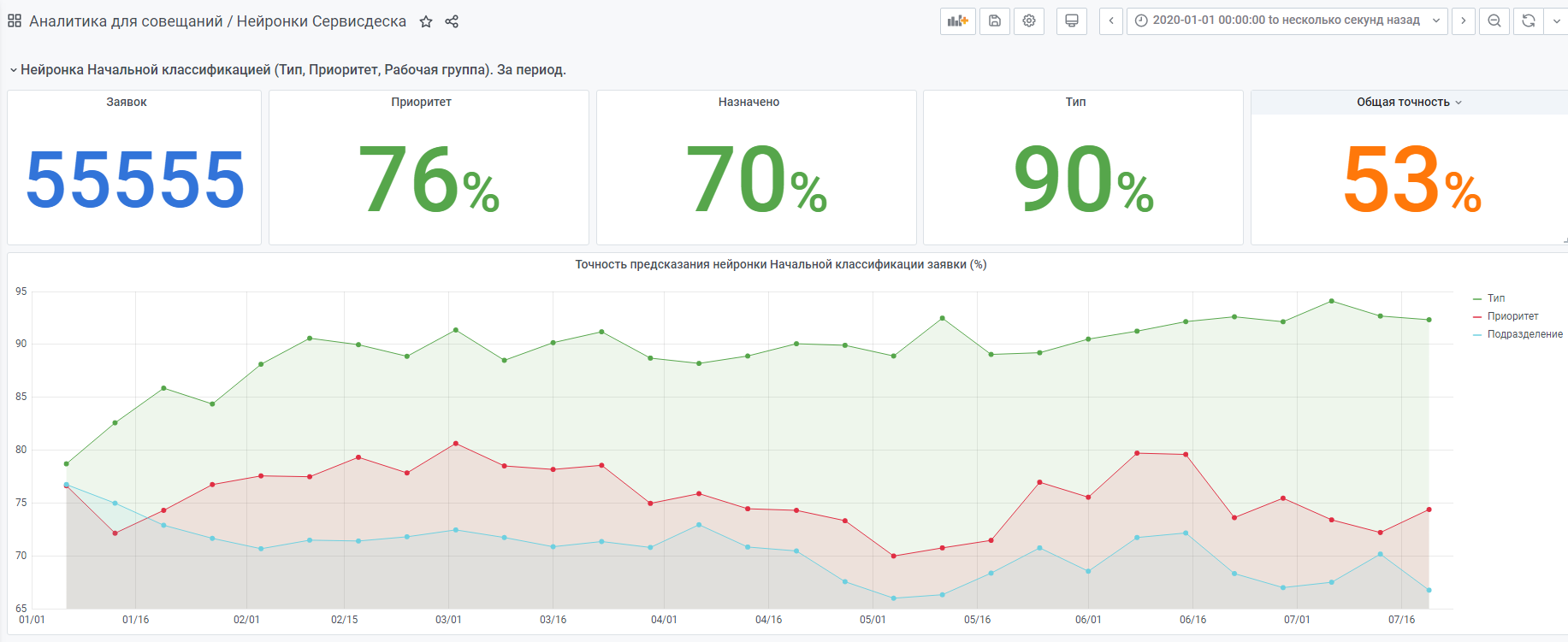
Há também uma rede neural "muito jovem" feita de acordo com o mesmo princípio. Mas ainda há poucos dados, ela ainda está ganhando experiência.
Ficarei feliz se minha experiência ajudará alguém a criar sua própria rede neural.
Se você tiver alguma dúvida, ficarei feliz em responder.