
Editor de dados
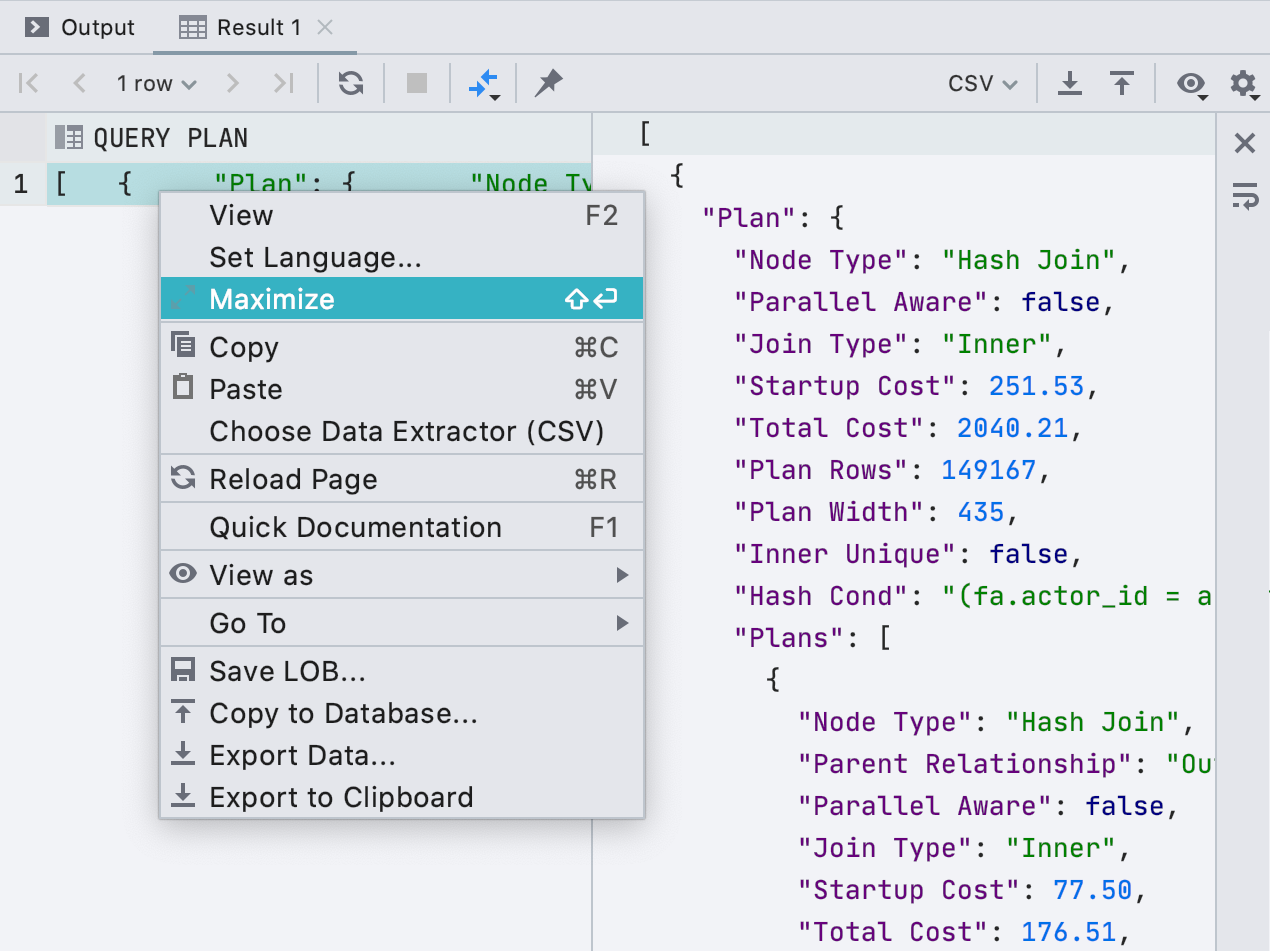
Editor de grande valor
Adicionamos um editor completo às células. Se uma célula contém um valor longo, como XML ou JSON, é conveniente abri-la em um painel separado. Para fazer isso, clique em
Maximizar no menu de contexto.
Visualizando uma consulta durante a edição
Agora, antes de escrever novos valores no editor de dados, você pode ver qual consulta será executada. Para fazer isso, clique no botão DML na barra de ferramentas.
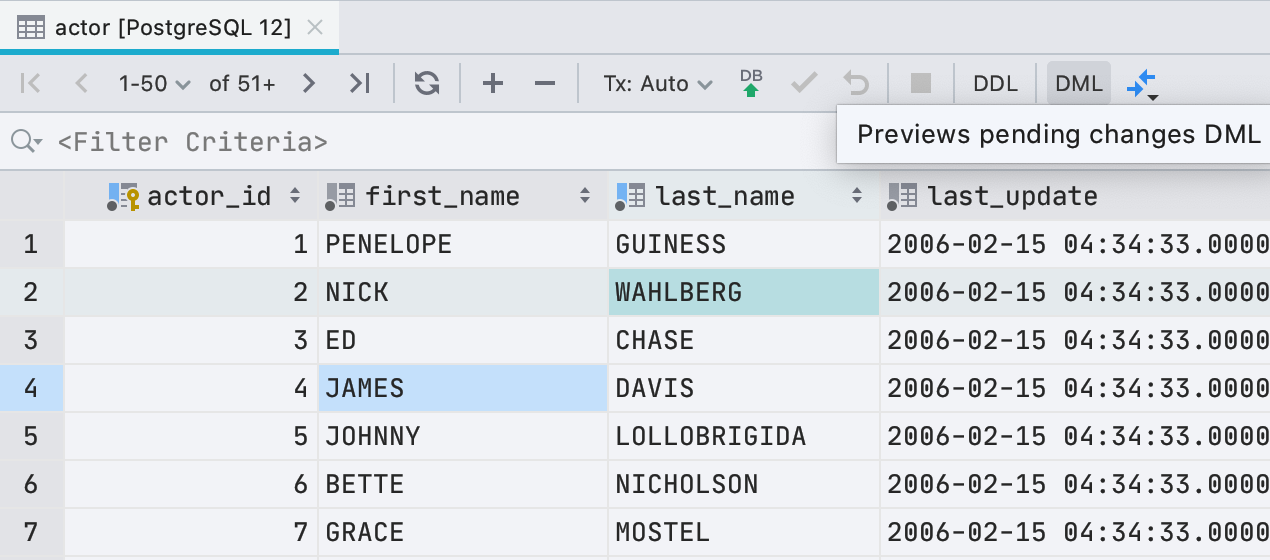
Para ser honesto, não é apenas a consulta que executamos porque, para editar dados, o DataGrip usa o driver JDBC. Mas, na maioria dos casos, o que mostramos coincidirá com o que realmente começa.
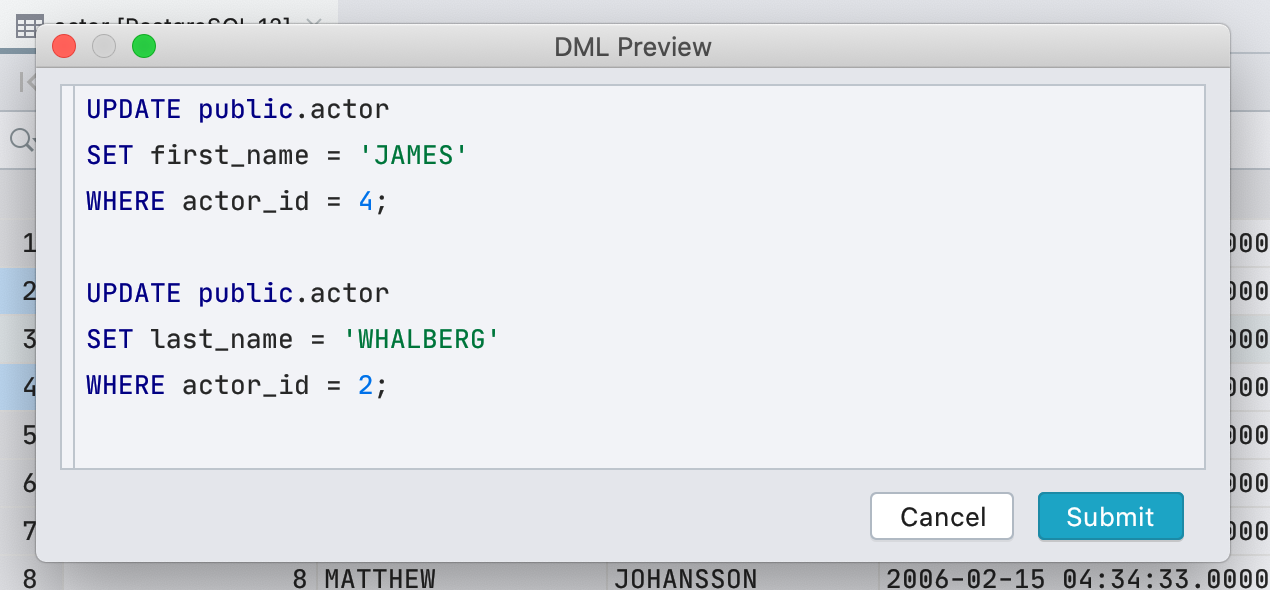
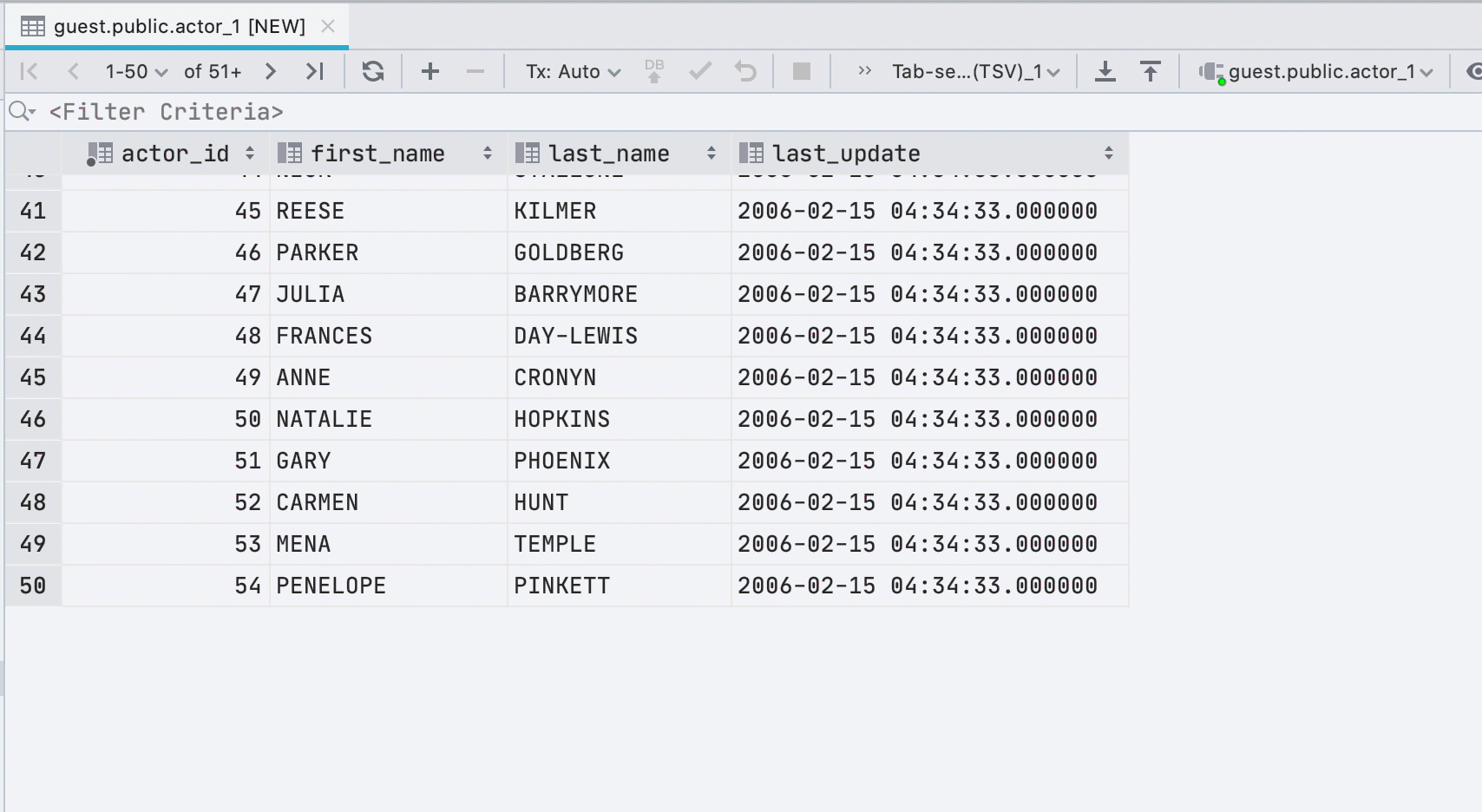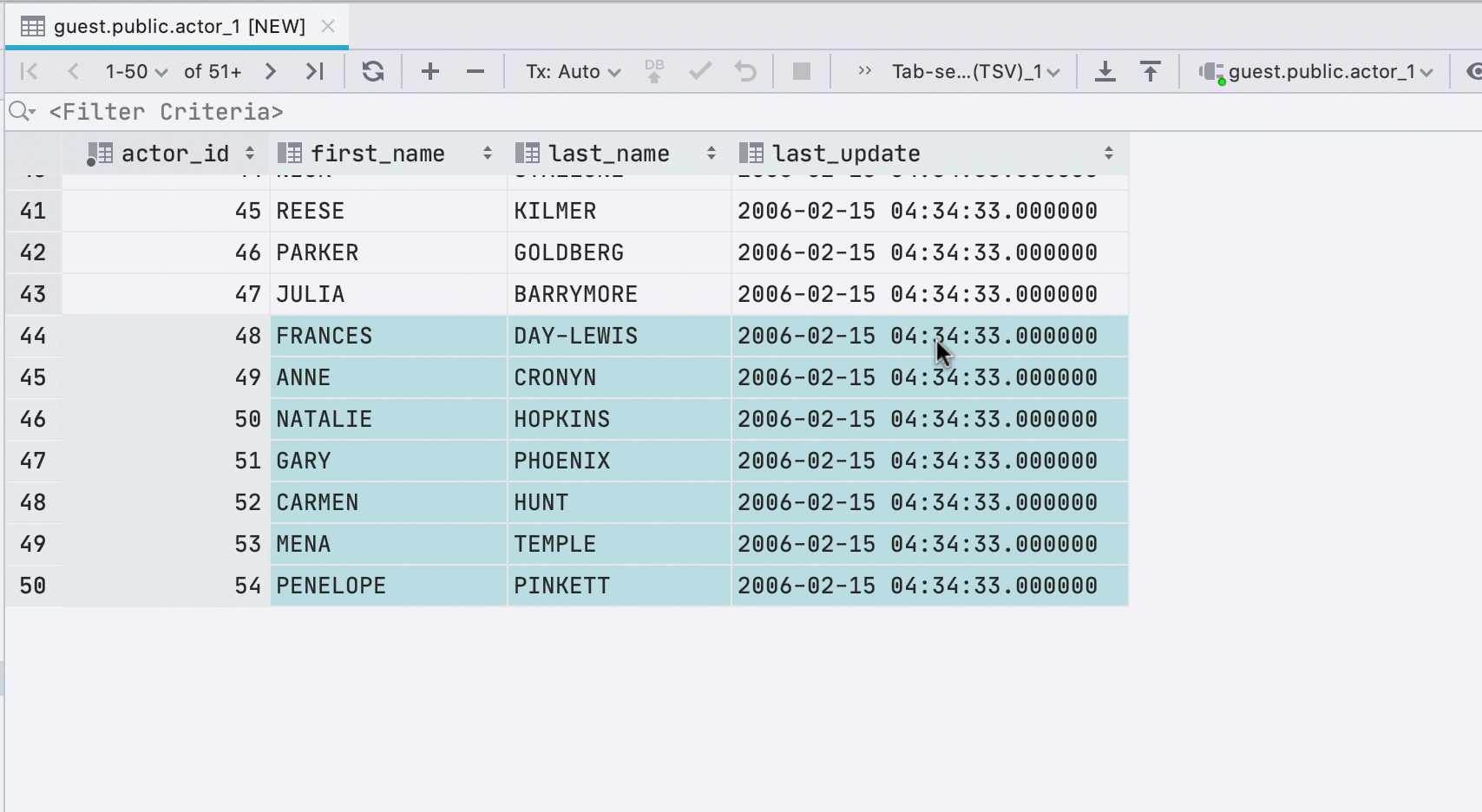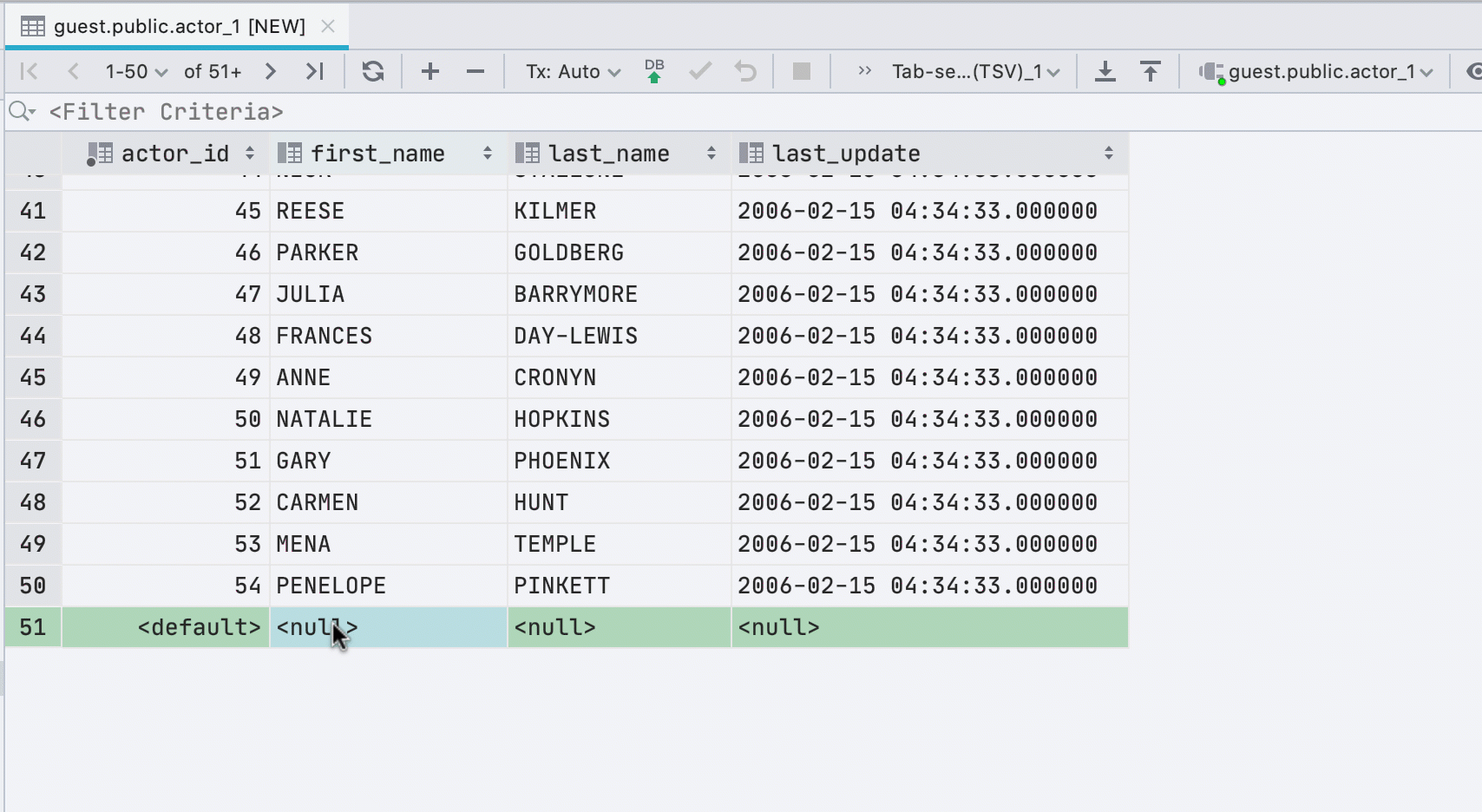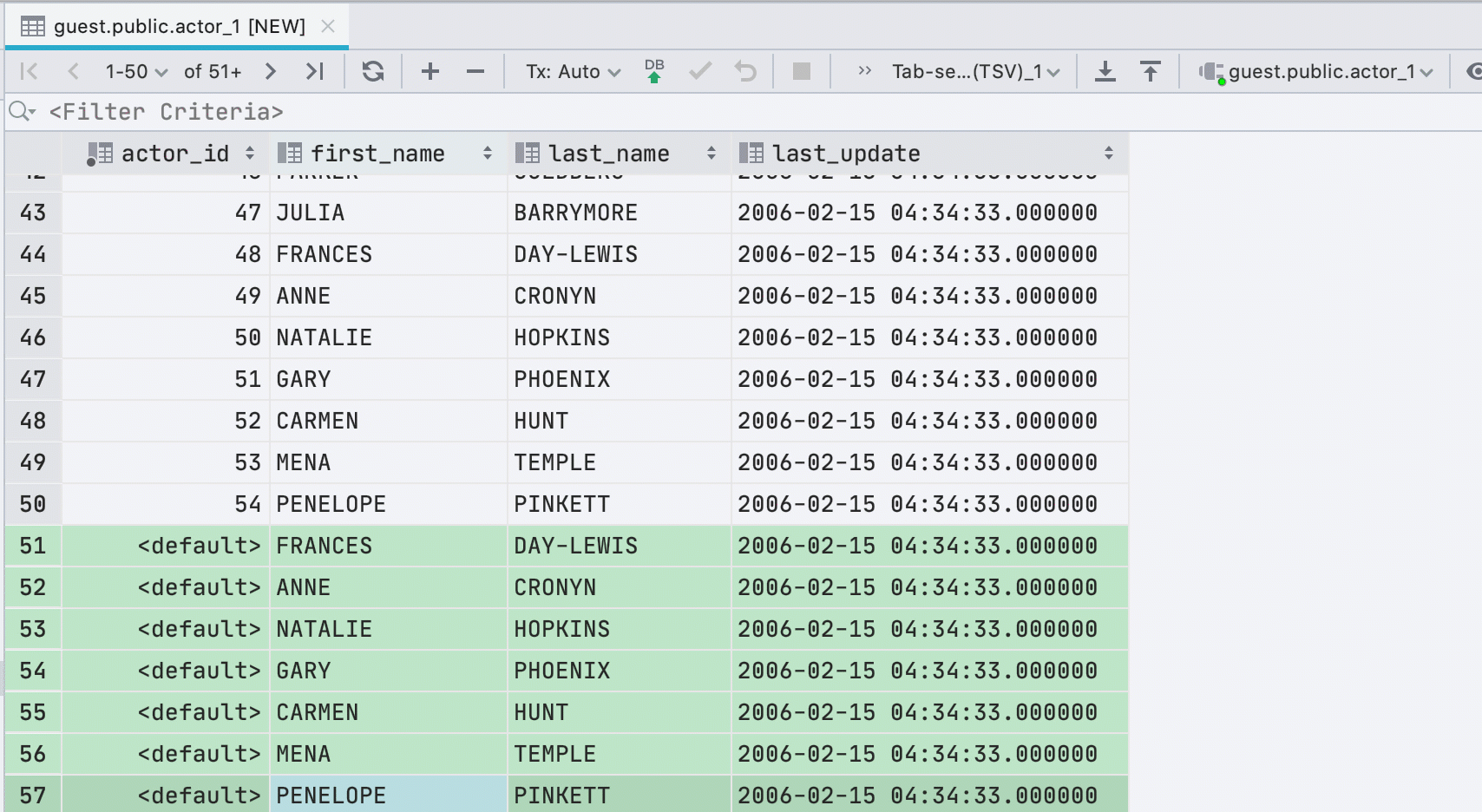
Nova exibição de células lógicas
Anteriormente, usávamos uma caixa de seleção para exibir células com o tipo booleano . Isso era inconveniente: nem todos sabiam como distinguir nulo de falso , e padrão, calculado e nulo eram exibidos da mesma forma. Decidimos não ser inteligentes e escrever o significado no texto.
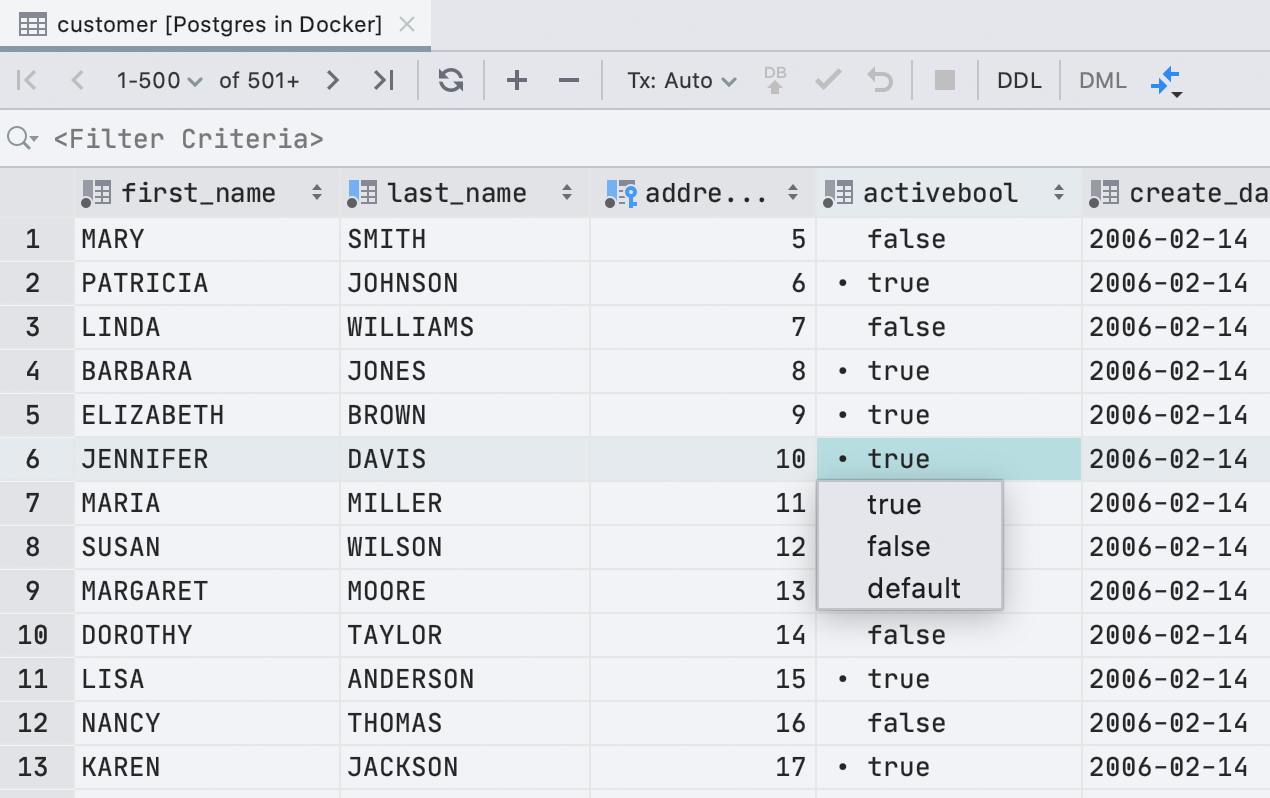
A caixa de seleção tinha uma vantagem: é fácil encontrar visualmente os valores verdadeiros . Na nova interface, o ponto executa essa tarefa.
Temos sorte: em inglês, todos os significados possíveis começam com letras diferentes. Portanto, para editar, basta pressionar a primeira letra do valor que você precisa: f, t, d, n, g ou c.Se imprimirmos outra coisa, mostraremos uma lista suspensa. E a barra de espaço alterna entre os valores disponíveis.
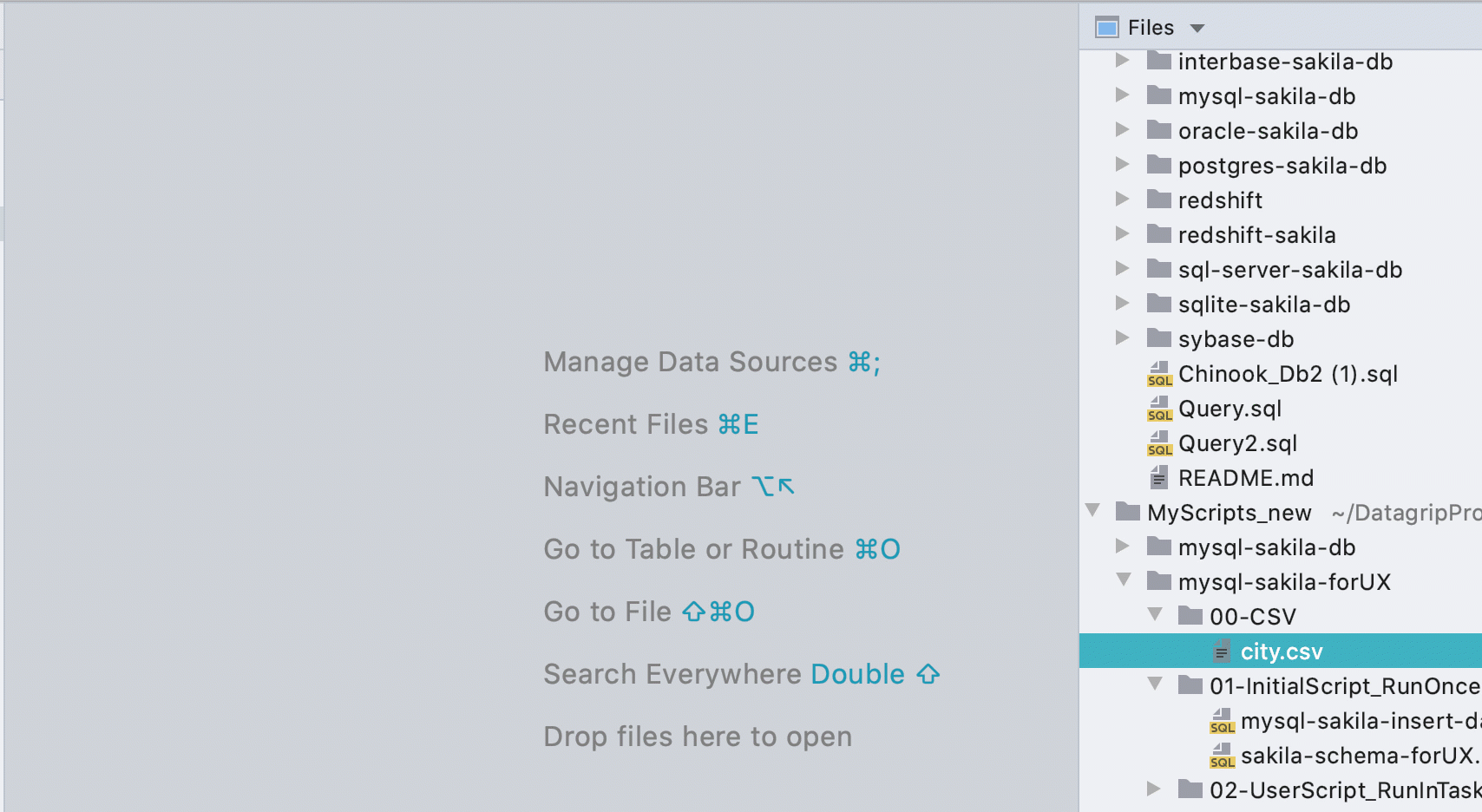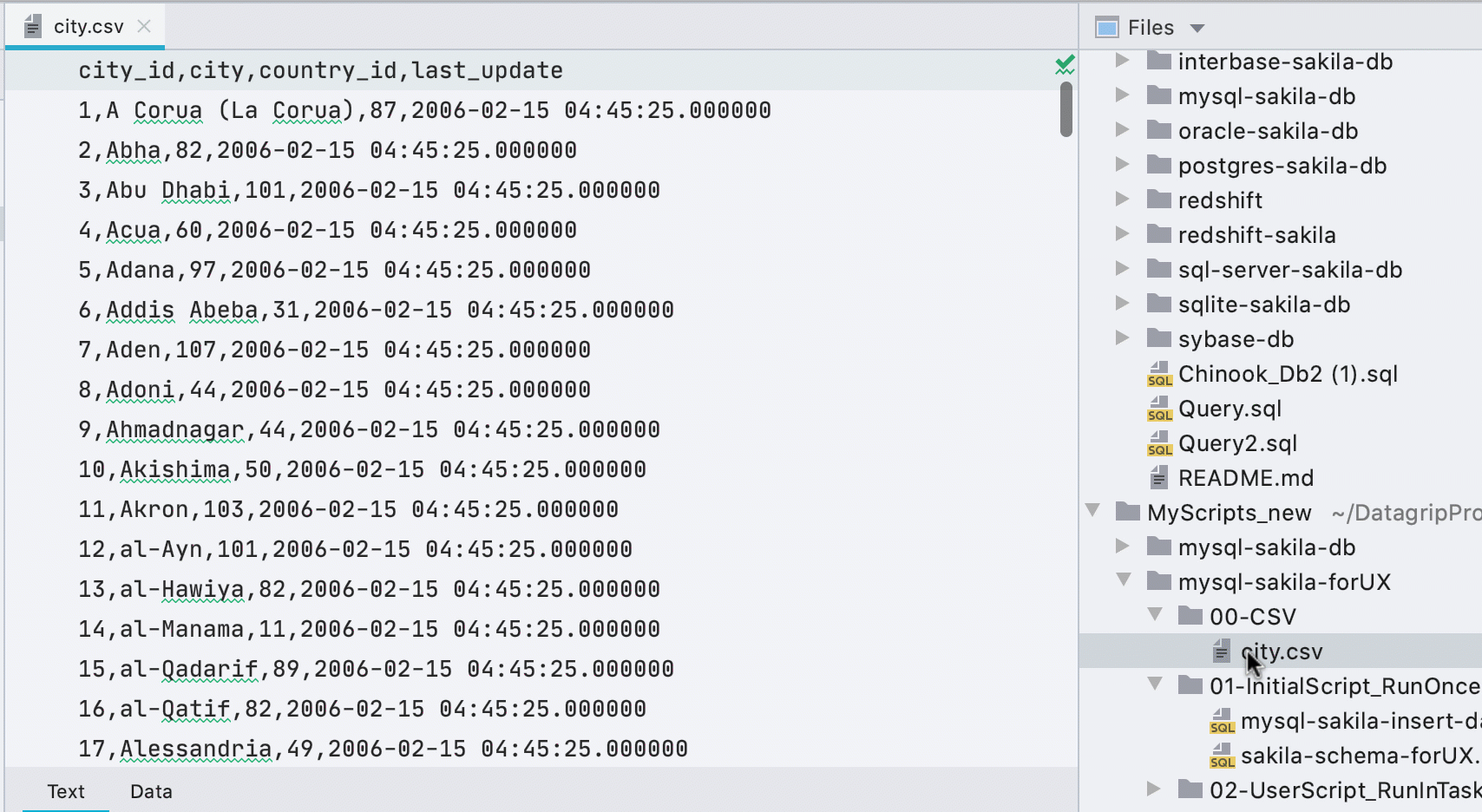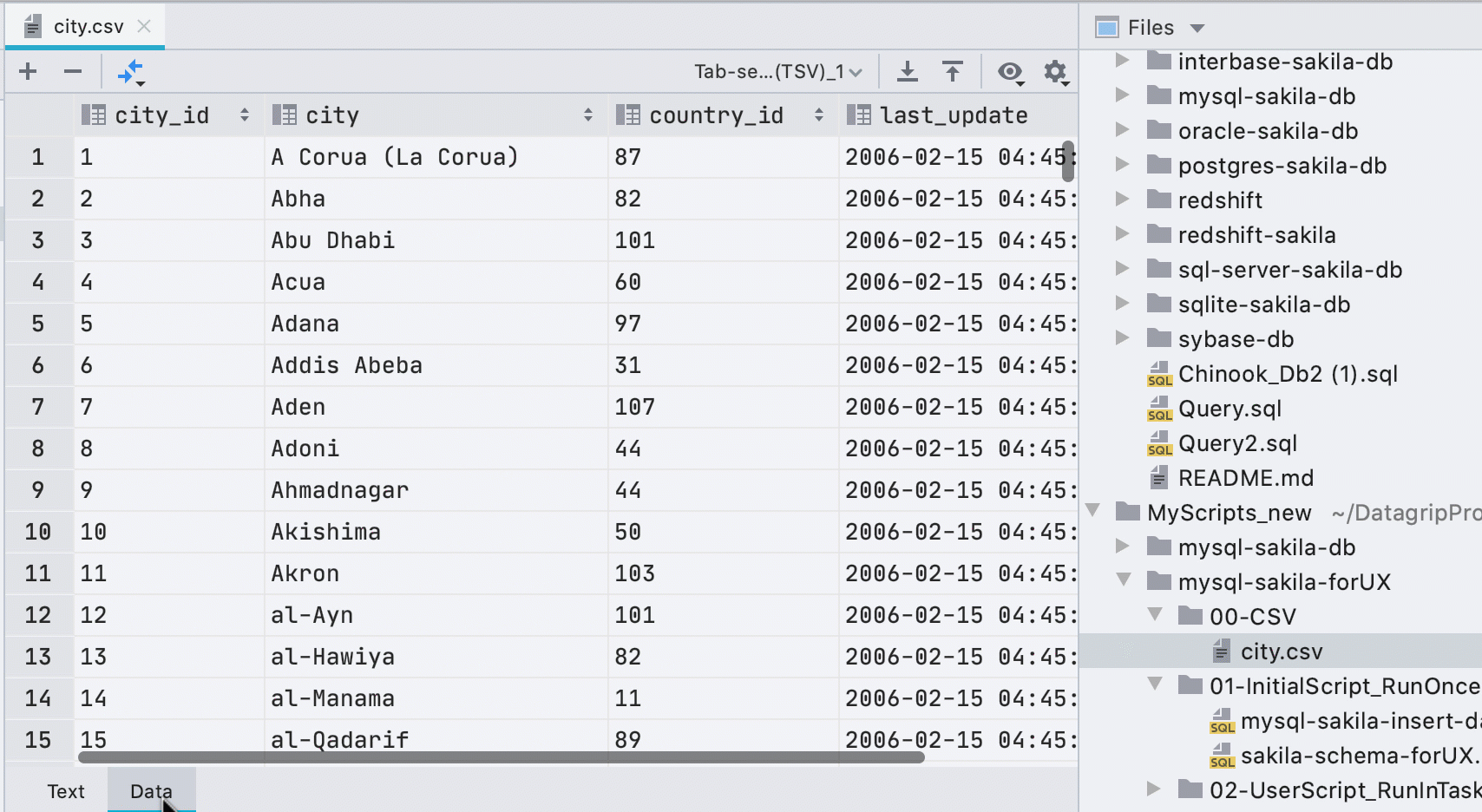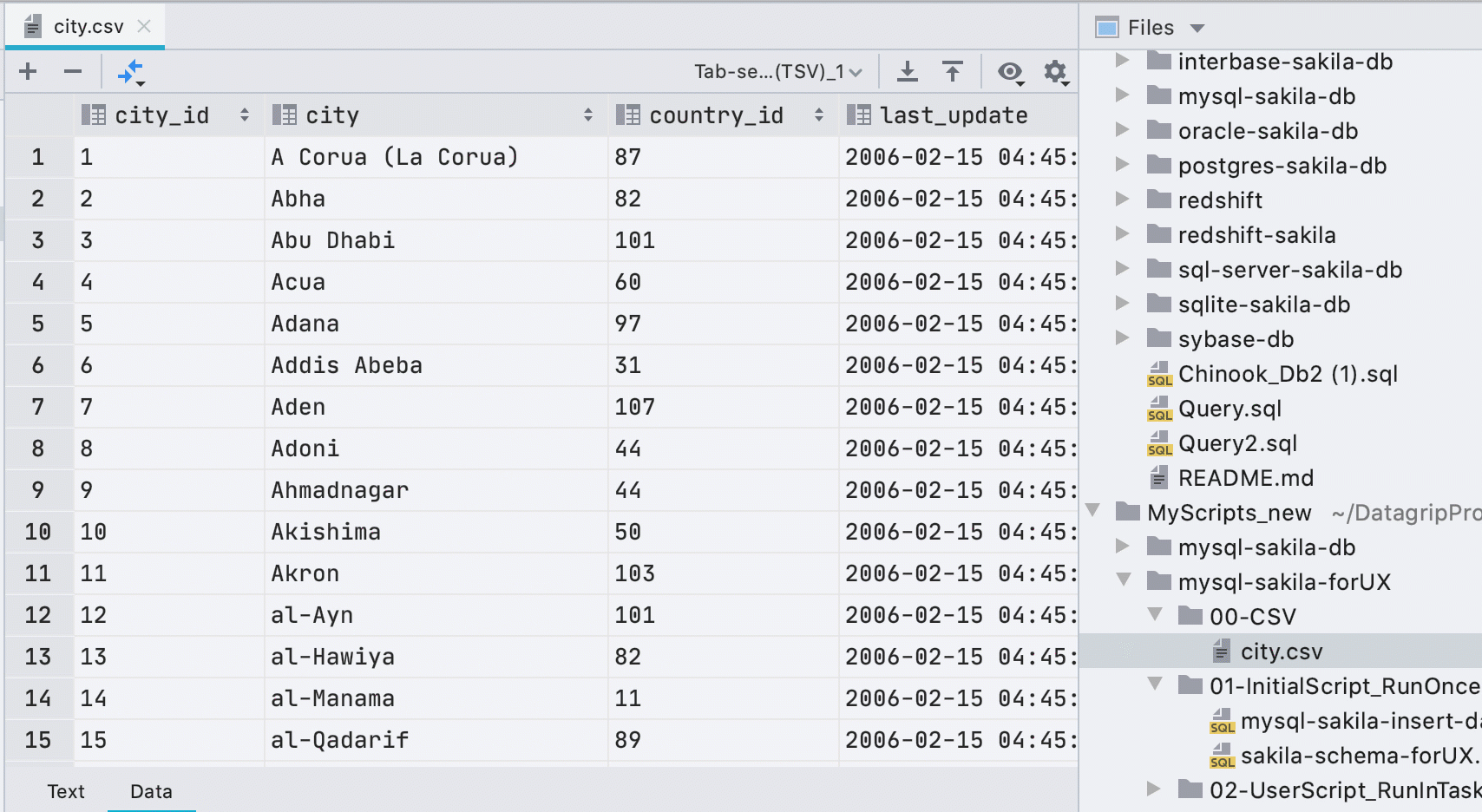
Editor de dados automático para arquivos CSV
Anteriormente, você tinha que chamar o editor de dados no menu de contexto e uma pequena barra amarela anunciava um plugin de terceiros ao abrir arquivos CSV. Agora descobrimos o que é o quê e mostramos a guia Dados para arquivos CSV.
Novas linhas ao colar valores
Se você colar dados da área de transferência em uma tabela, criaremos automaticamente o número necessário de novas linhas.
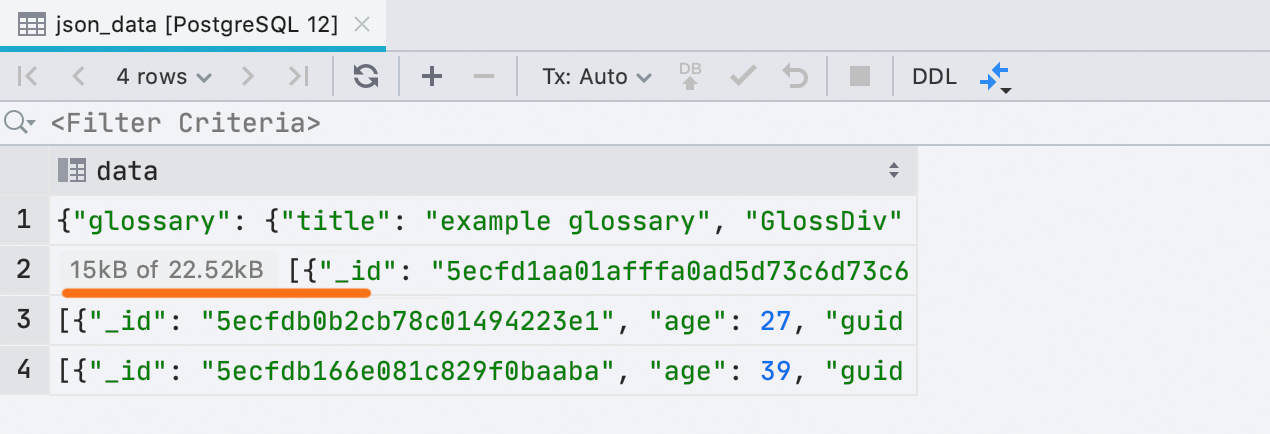
Nova interface para dados
subcarregados Às vezes, o DataGrip não pode carregar todos os dados em uma célula se ocupar muita memória. Isso é determinado pelo Banco de dados | Visualizações de dados | Comprimento máximo de LOB.Anteriormente, inseríamos texto sobre isso diretamente no valor da célula e isso é inconveniente. Agora é uma pequena placa separada:
Exportar para a área de transferência a partir do menu de contexto
Na última versão, criamos uma caixa de diálogo para exportação, deixando de fora um pequeno caso: ficou menos conveniente copiar todo o resultado para a área de transferência com o mouse. Agora, isso pode ser feito no menu de contexto.

Lembre-se de que esta ação copia todo o resultado ou tabela. E Ctrl / Cmd + C ou a ação
Copiar copia apenas a seleção.
Melhorias de filtragem para MongoDB
Além de ObjectId e ISODate , agora você pode filtrar por UUID , NumberDecimal , NumberLonge
BinData . Além disso, se você tiver um valor adequado para UUID / ObjectId / ISODate em sua área de transferência, o DataGrip se oferecerá para usá-lo para filtragem.
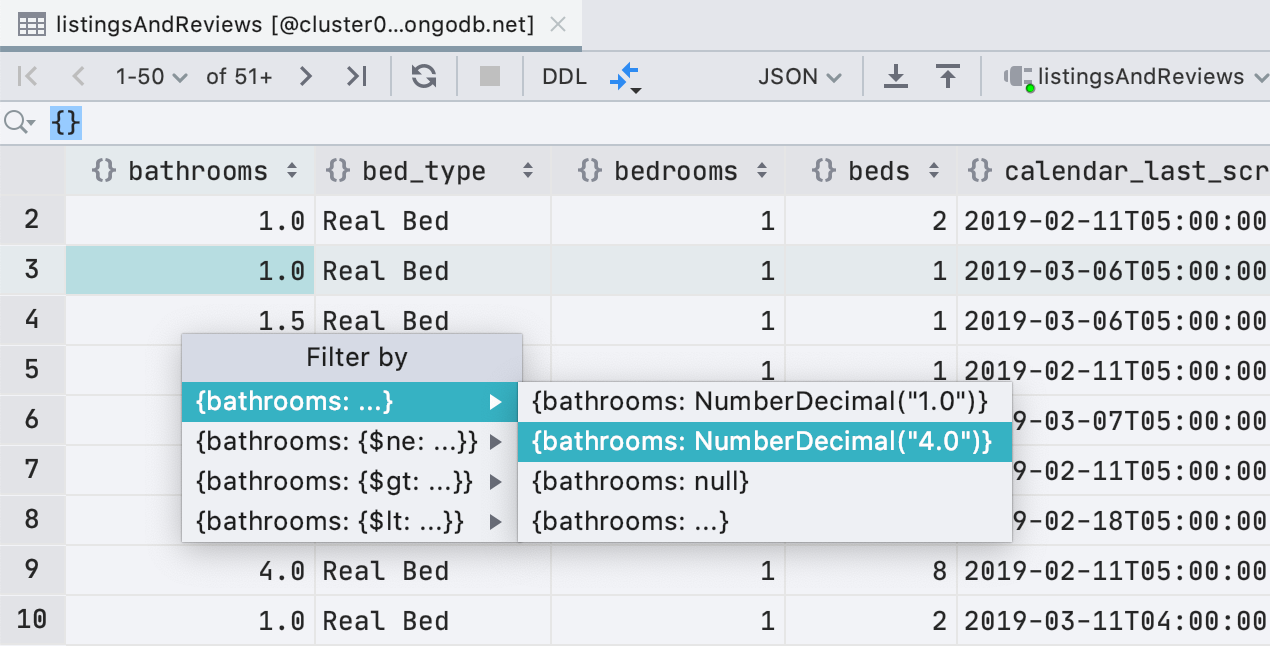
Também adicionamos expressões regulares às condições do filtro para que você não perca muito o filtro
LIKE em bancos de dados relacionais.

Editor de SQL
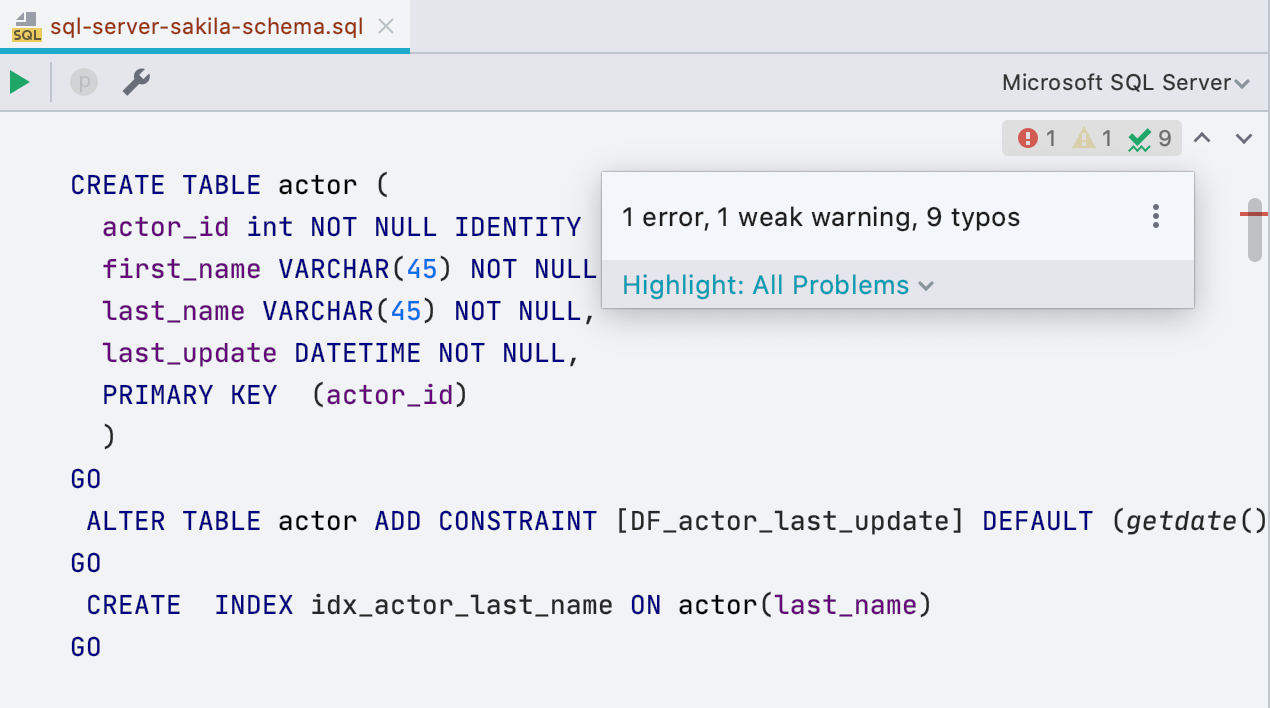
Novo widget com inspeções
Um pequeno painel apareceu à direita do editor - ele dirá quantos erros há no script e quantos lugares são suspeitos. A partir daí você pode navegar ou escolher o que destacar e o que não. O atalho de teclado F2 ainda funciona para o mesmo.
Sugestão para renomear
Isso apareceu em muitos de nossos IDEs: se você renomeou algo sem usar a refatoração embutida, mas mudou o nome no código, você será solicitado a refatorar e renomear e todos os usos. Por exemplo, é assim que funciona com aliases: A

conclusão de JOIN ficou ainda melhor
Anteriormente, para oferecermos uma condição JOIN completa, tínhamos que digitar esta palavra-chave. Agora entendemos o que é necessário assim que você digitou
'J'.

Também aprendemos a oferecer condições duplas se as chaves da tabela forem definidas dessa forma.

Atualizar as informações do banco de dados
Se o DataGrip não souber nada sobre os objetos de suas consultas, ele o informará sobre isso. Às vezes, isso acontece se você apenas selou. Também acontece que o arquivo estava associado à fonte de dados errada. Outra razão para tal evento é que o objeto já apareceu, mas o DataGrip não recebeu informações sobre ele do banco de dados. Para fazer isso, adicionamos a capacidade de iniciar a atualização da estrutura do banco de dados a partir do editor se o objeto for desconhecido.

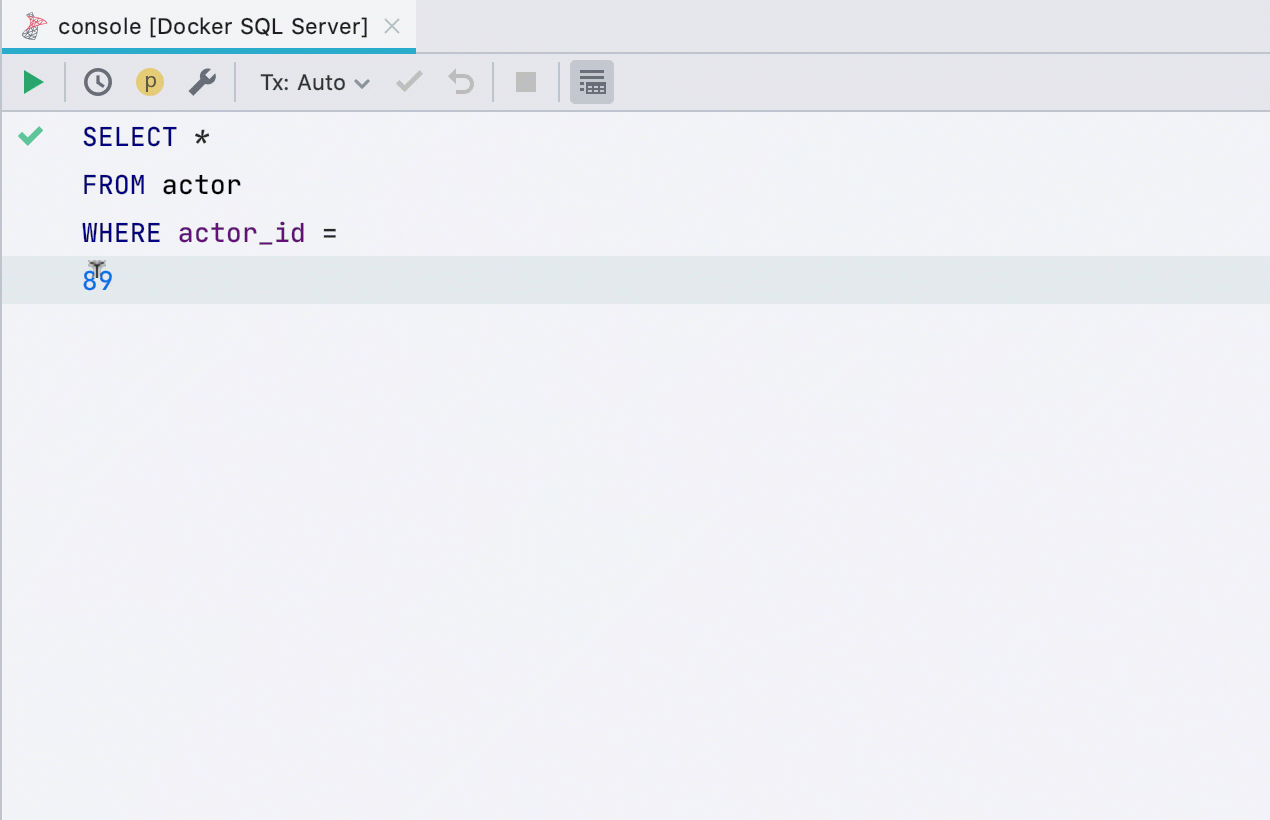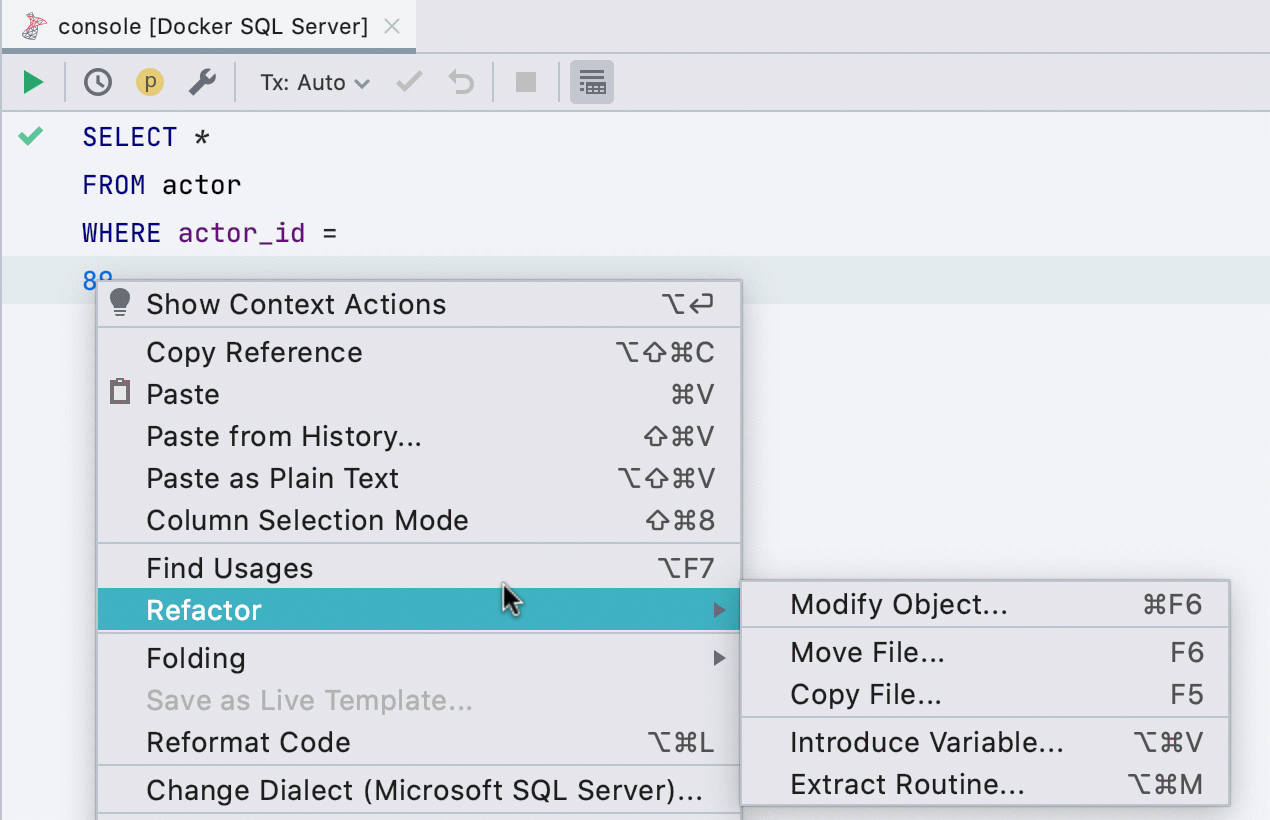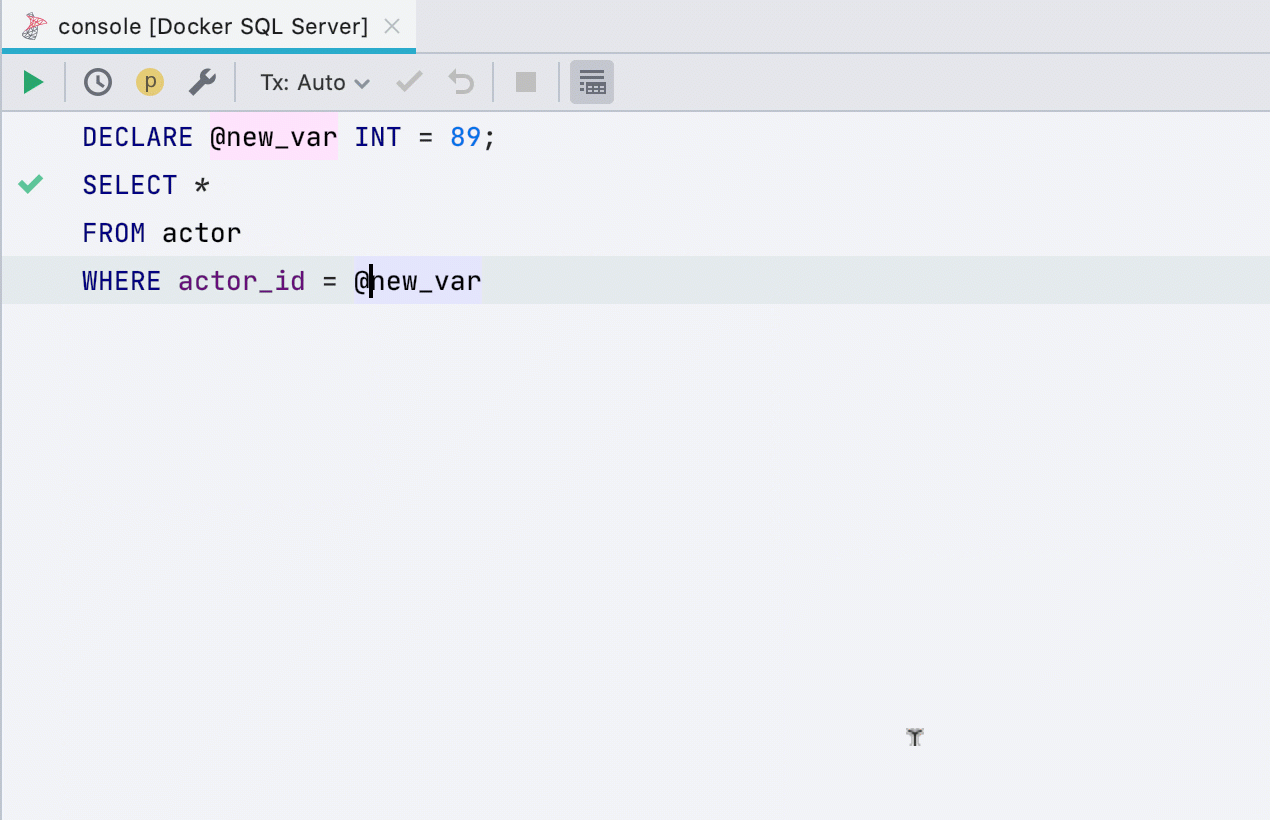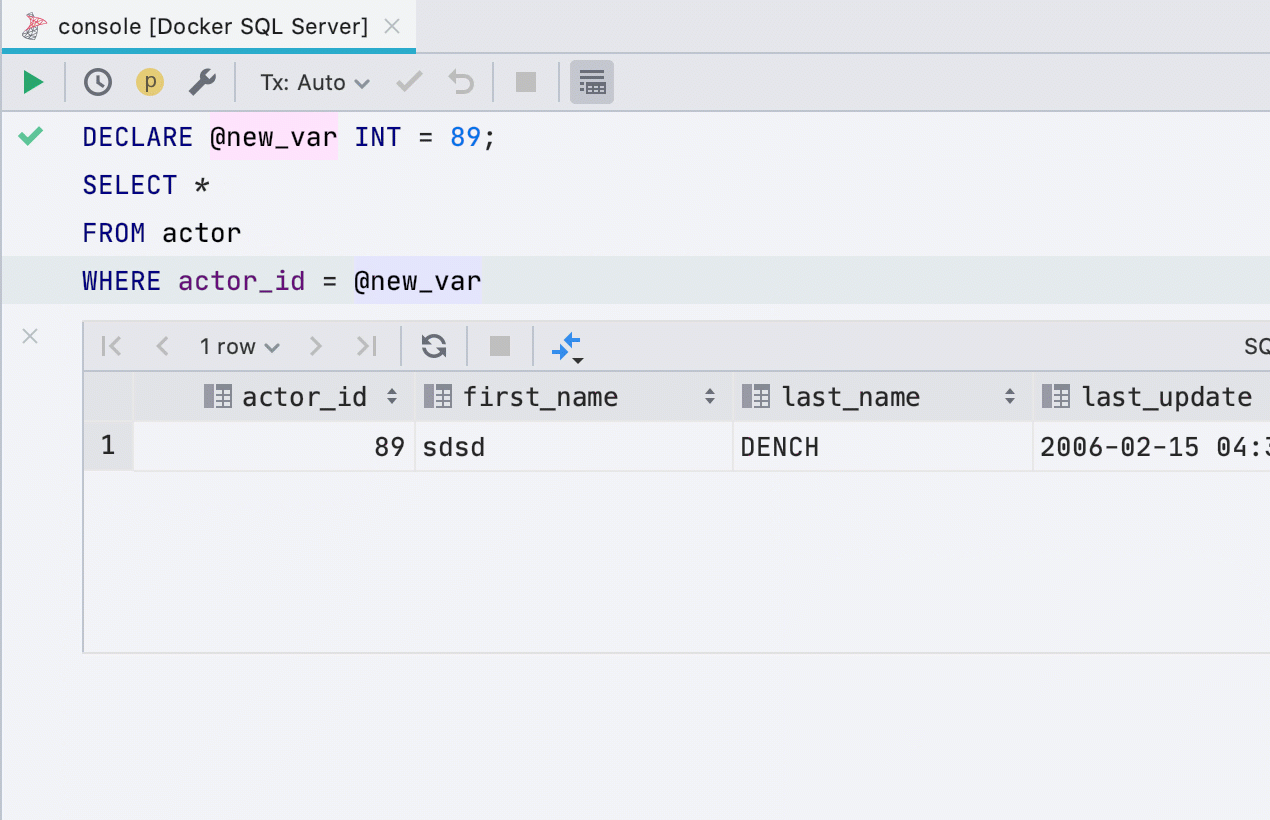
Alocar variável
Esta refatoração anteriormente não funcionava para todos os bancos de dados, agora funciona em SQL Server, Db2, Exasol, HSQL, Redshift e Sybase .
Destaque do Google BigQuery
Adicionados novos dialetos: Google BigQuery. Até agora, isso não é um suporte de banco de dados completo, mas apenas o realce de código correto. Conseqüentemente, você não precisa selecionar o código para executar consultas, nós mesmos determinaremos o que executar.

Destacando TextMate
Como nossos outros IDEs, DataGrip agora pode destacar o código usando o plugin TextMate. Pode ser útil se você tiver scripts em Python, lua, javascript. Uma lista completa de idiomas está disponível em Configurações / Preferências | Editor | Pacotes TextMate .

SQL 2016 como um dialeto <Generic>
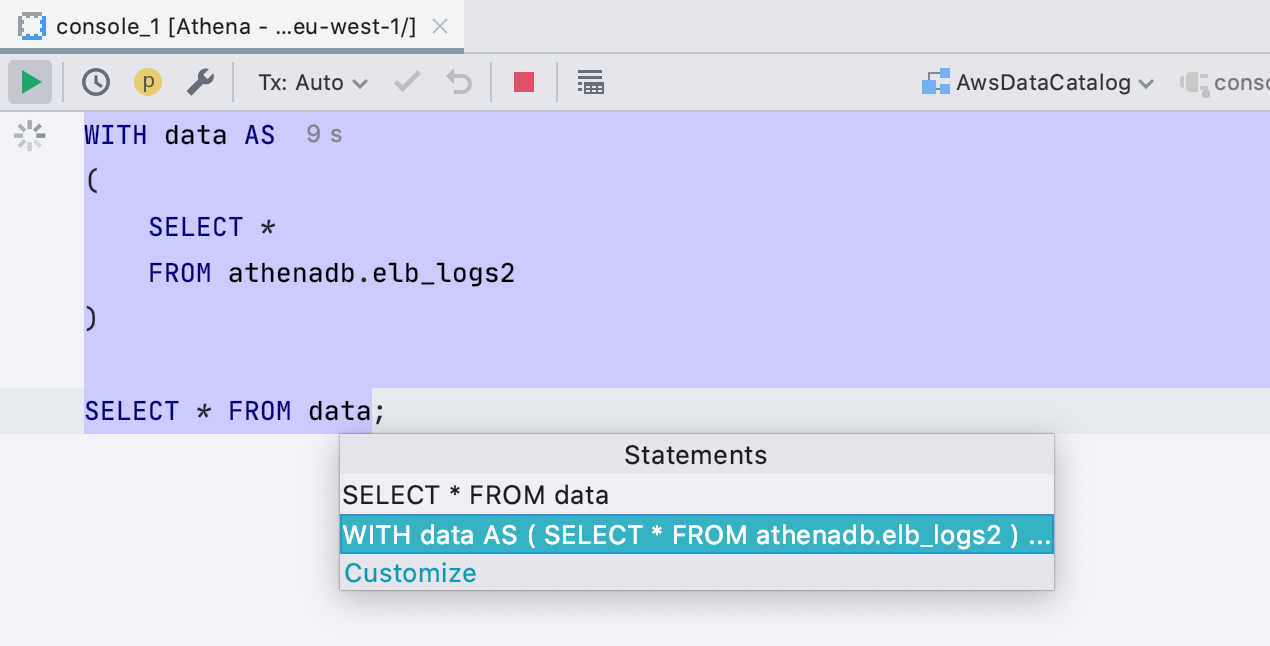
Se você trabalha com um banco de dados que não suportamos, as consultas são analisadas e destacadas com o dialeto < Genérico >. Anteriormente, era o SQL 92, agora SQL 2016. O mais importante é que agora processamos corretamente as consultas com um bloco WITH, respectivamente, eles não são apenas realçados corretamente, mas você também pode executá-los sem realçar o código.
Caso de nomes de objetos na formatação
Nas configurações de formatação, havia três configurações para os nomes de objetos de banco de dados - maiúsculas , minúsculas ou não alterar . Mas descobriu-se que há um quarto caso: os usuários querem usar o caso que foi usado ao criar o objeto no script. Nós apoiamos isso.

No exemplo, a tabela Ator é criada com a primeira letra maiúscula e, em uso, convertemos o nome da tabela para o mesmo caso.

Procuramos apenas os scripts de criação dentro do mesmo arquivo onde ocorre a formatação. Se você deseja que o formatador encontre a declaração do objeto em um arquivo vizinho, crie uma fonte de dados baseada em DDL a partir de seus arquivos .
Vários acentos circunflexos em uma seleção
Agora você pode selecionar um trecho de código e colocar um acento circunflexo em cada linha dele. Para isso, use a ação Adicionar circunflexos às extremidades das linhas selecionadas ou o atalho de teclado Shift + Alt + G

Database Explorer
Todas as bases e esquemas na árvore
Por padrão, mostramos na árvore apenas as bases e esquemas que você selecionou. A árvore não é preguiçosa e todas as metainformações sobre os objetos são usadas para o trabalho posterior do IDE. Portanto, baixamos apenas o necessário para não ficar pendurado acidentalmente em uma base gigante.
Porém, muitos estão acostumados com ferramentas que mostram sempre todos os objetos, e quem não conhece nosso conceito pode perder de vista as bases e os diagramas. Portanto, fizemos a configuração Mostrar Todos os Namespaces, e quando estiver habilitada, todos os bancos de dados e esquemas serão mostrados na árvore, mesmo que as informações sobre seus objetos não sejam carregadas. Esses esquemas e bases são marcados em cinza.

Interface para criar visualizações
Costumamos dizer que a função de geração de código no editor (Alt + Ins ou Cmd + N ) cobre muitas das necessidades de criação de objetos do desenvolvedor, mas às vezes é ainda menos conveniente. Portanto, começamos a adicionar interfaces para a criação de objetos: na nova versão, você pode criar visualizações.

Arquivos de script no painel Arquivos
Se você criou uma fonte de dados baseada em DDL, esses arquivos irão automaticamente para o painel
Arquivos . Portanto, será conveniente para você visualizá-los e editá-los. Vinculação de banco de dados

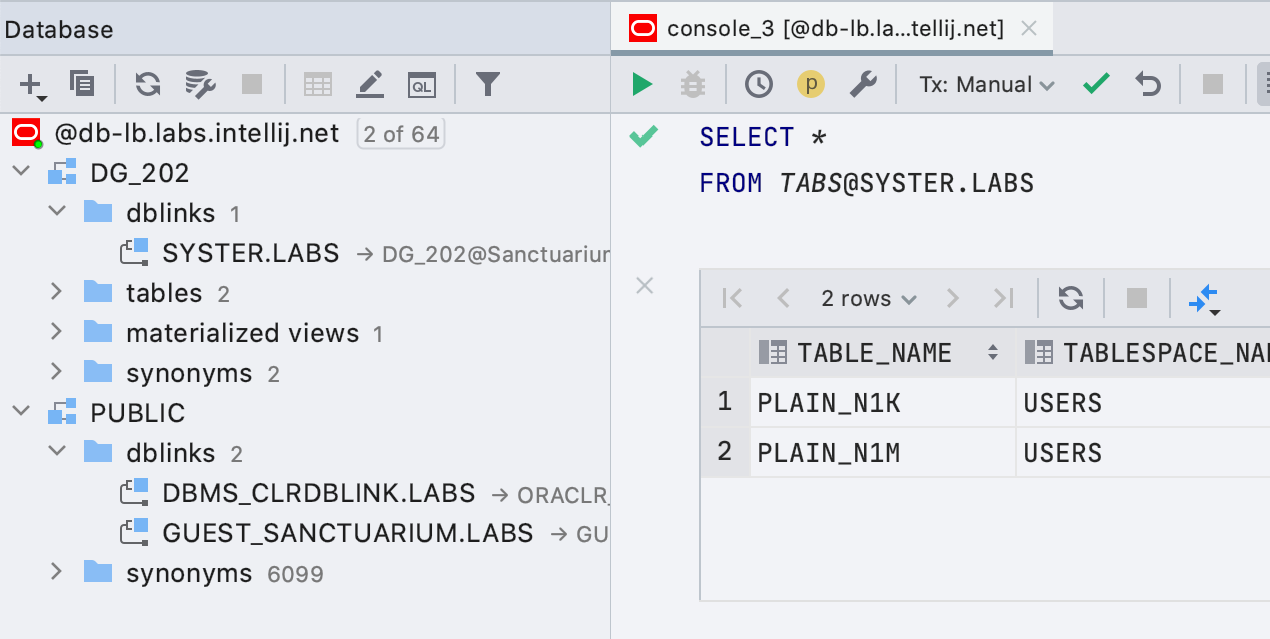
Oracle simples Os
links de banco de dados agora são mostrados no Explorer e as consultas que os utilizam são destacadas corretamente.
Geral
Chega de nomes de guia longos
Você sempre reclamou que as guias estão ficando fora de controle .

De agora em diante:
- Database | General | Always show qualified names for database objects , , .
- 20 , .
- , .
- — 36 , .
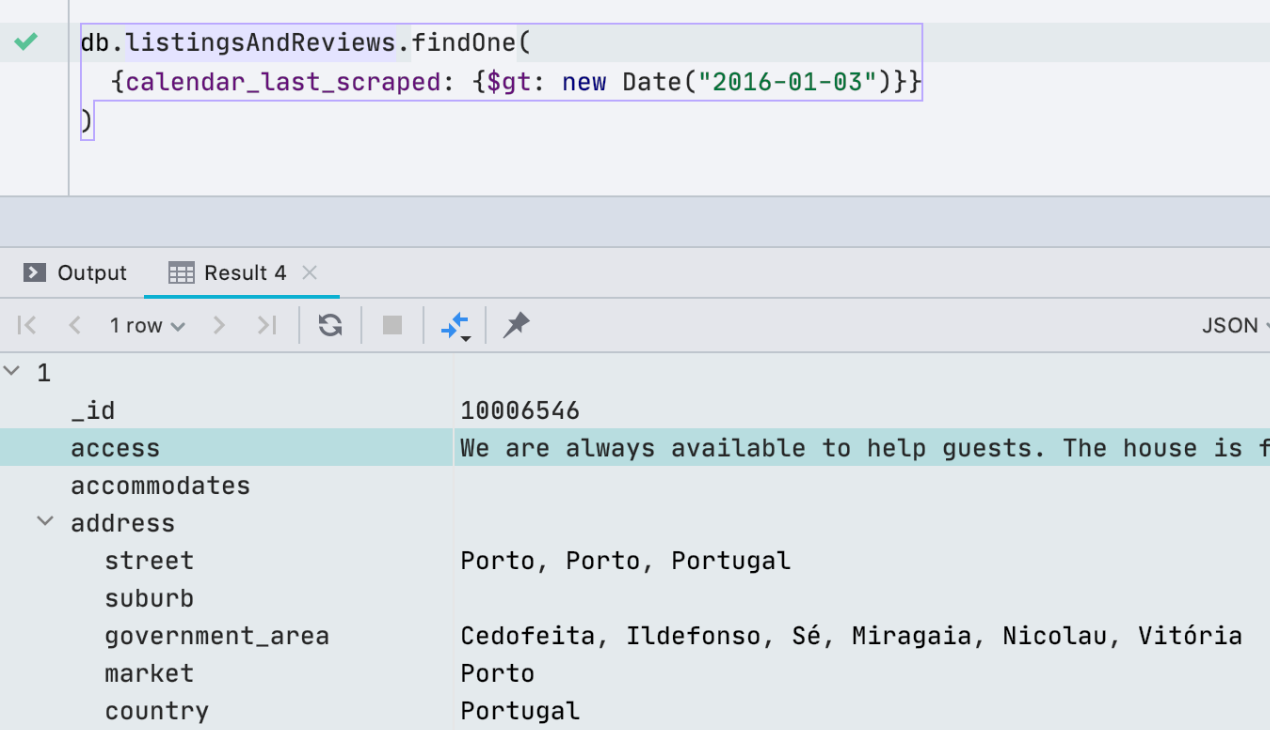
Suporte ao shell do MongoDB
Há um mês, atualizamos o driver que usamos para conectar ao MongoDB para oferecer suporte ao shell do MongoDB. Isso significa que novos comandos e métodos funcionaram, como help, db.getCollectionInfos (), db.getCollectionNames (), db.collection.remove () e outros. Artigo detalhado em inglês sobre o suporte ao shell do MongoDB aqui .
Bibliotecas nativas nas configurações do driver
Agora você pode especificar o caminho para a biblioteca nativa de que o driver precisa. Aqui estão algumas das vezes em que você pode precisar dele.

- SQL Server mssql-jdbc_auth-<version>-<arch>.dll SSO, . , SSO .
- Oracle ocijdbc, OCI .
- SQLite, ,
, , .
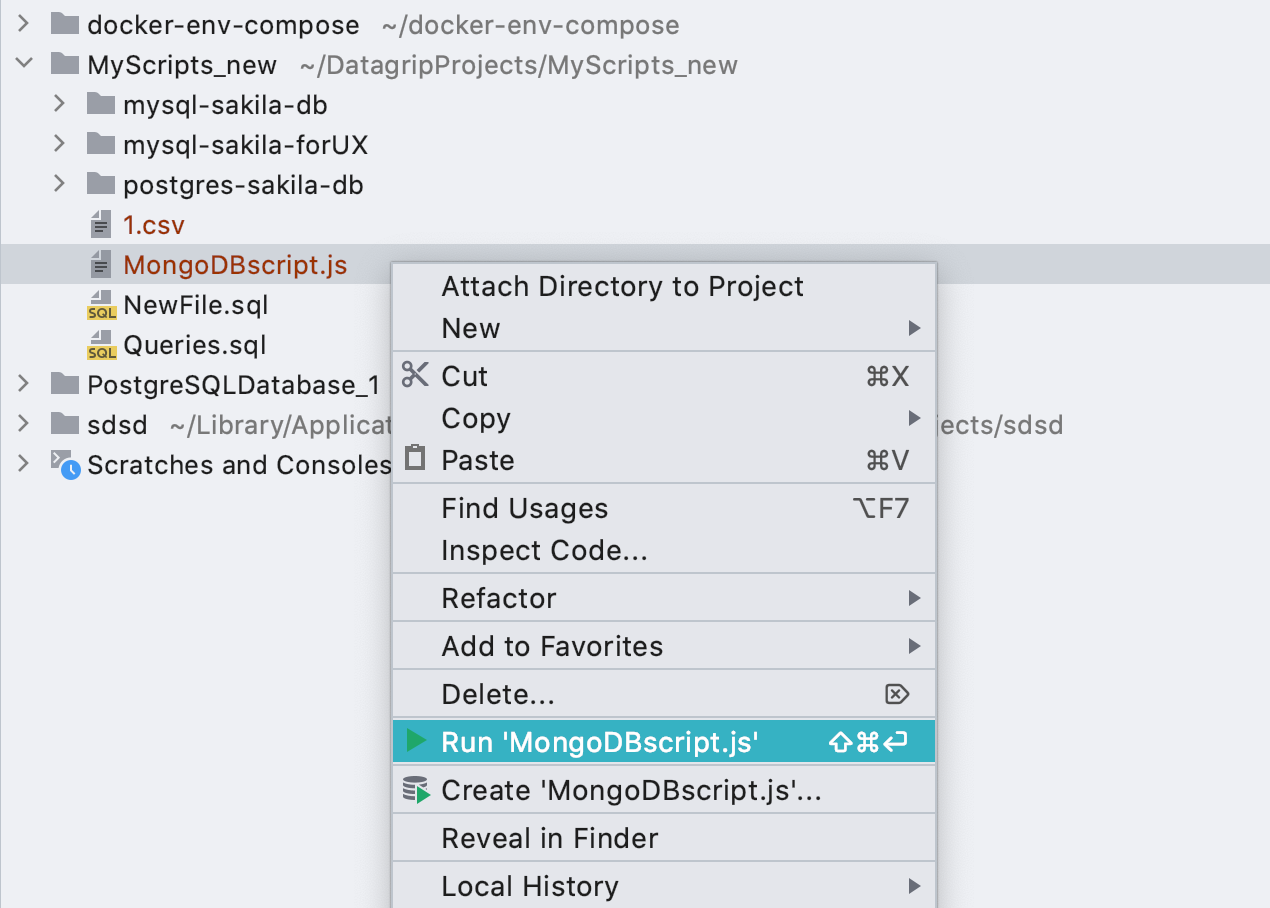
Configurações de inicialização para arquivos * .js
Agora as configurações de inicialização também funcionam para scripts MongoDB .
Integração com Git e Github funciona fora da caixa
Nossa pesquisa mostrou que algumas pessoas armazenam scripts em sistemas de controle de versão, então decidimos empacotar dois dos plug-ins mais populares nesta área.

Obrigado pela atenção! Lembramos que temos um canal próprio no Telegram , onde você pode tirar dúvidas e compartilhar experiências. Mas se você encontrar um bug, é melhor escrever imediatamente para o rastreador para que ele não se perca. Bem, aqui, claro, também escreva comentários :)
Isso é tudo!
Equipe DataGrip