- Resumindo, que plano vamos ter? Primeiro, vamos falar sobre por que vamos aprender Python. Então vamos ver como o interpretador CPython funciona com mais profundidade, como ele gerencia a memória, como funciona o sistema de tipos em Python, dicionários, geradores e exceções. Acho que vai demorar cerca de uma hora.
- Por que Python?
- Dispositivo de intérprete
- Digitando
- Dicionários
- Gerenciamento de memória
- Geradores
- Exceções
Por que Python?
* Insights.stackoverflow.com/survey/2019
** muito subjetivo
*** estudo
interpretação **** estudo interpretação
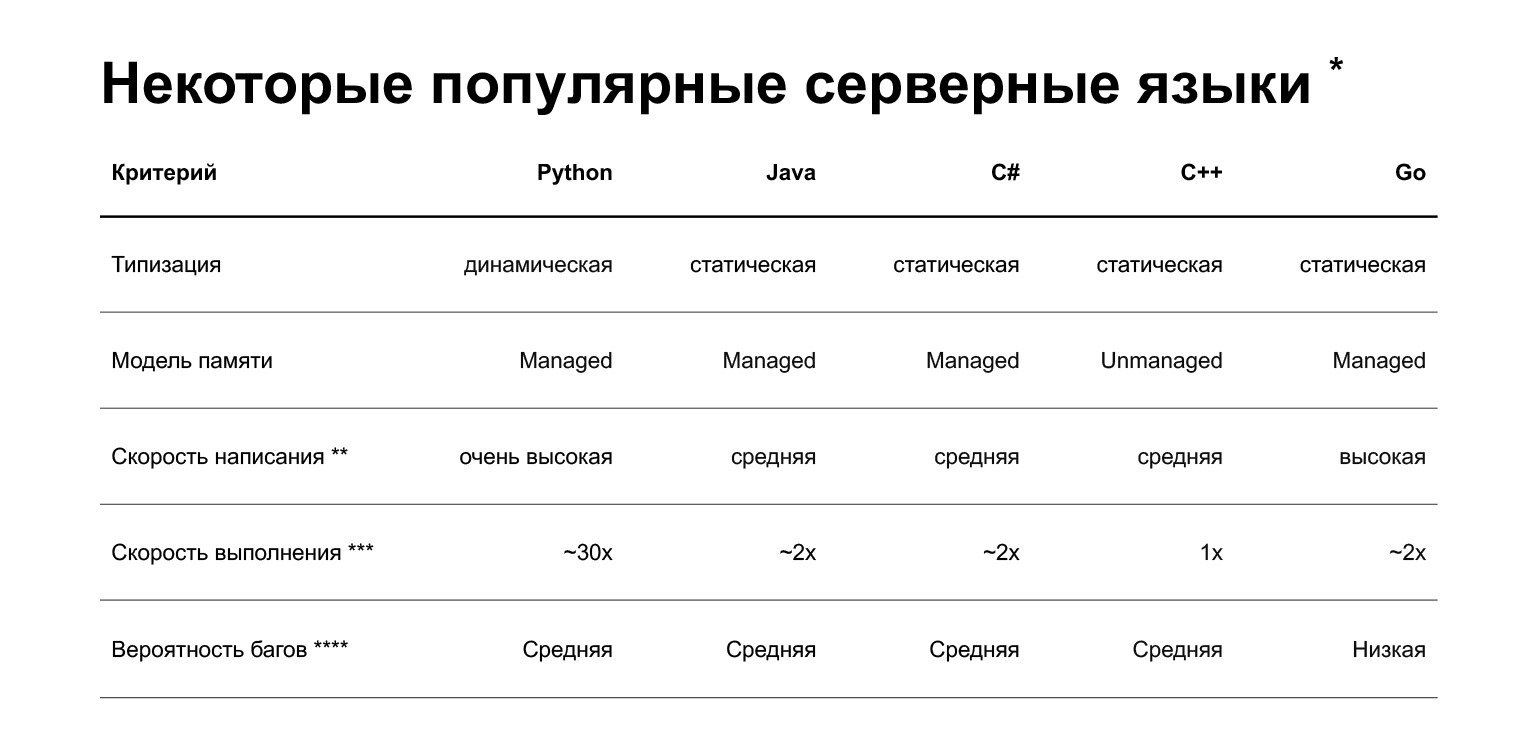
Vamos começar. Por que Python? O slide mostra uma comparação de várias linguagens que são usadas atualmente no desenvolvimento de back-end. Mas, em resumo, qual é a vantagem do Python? Você pode escrever código rapidamente nele. Isso, é claro, é muito subjetivo - pessoas que escrevem C ++ ou Go legais podem argumentar contra isso. Mas, em média, escrever em Python é mais rápido.
Quais são as desvantagens? A primeira e provavelmente a principal desvantagem é que o Python é mais lento. Pode ser 30 vezes mais lento do que outros idiomas, aqui está umestudosobre o assunto. Mas sua velocidade depende da tarefa. Existem duas classes de tarefas:
- Limite da CPU, tarefas ligadas à CPU, limite da CPU.
- I / O bound, tarefas limitadas por input-output: seja na rede ou em bancos de dados.
Se você está resolvendo o problema de limite da CPU, sim, o Python será mais lento. Se a E / S está limitada, e esta é uma grande classe de tarefas, para entender a velocidade de execução, você precisa executar benchmarks. E talvez comparando Python a outras linguagens você nem notará a diferença de desempenho.
Além disso, o Python é tipado dinamicamente: o interpretador não verifica os tipos em tempo de compilação. Na versão 3.5, apareceram dicas de tipo, permitindo especificar tipos estaticamente, mas eles não são muito restritos. Ou seja, você detectará alguns erros já na produção, e não na fase de compilação. Outras linguagens populares para o backend - Java, C #, C ++, Go - possuem tipagem estática: se você passar o objeto errado no código, o compilador irá informá-lo sobre isso.
Mais realista, como o Python é usado no desenvolvimento de produtos de táxi? Estamos caminhando para uma arquitetura de microsserviço. Já temos 160 microsserviços, nomeadamente mercearia - 35, 15 deles em Python, 20 - em vantagens. Ou seja, agora estamos escrevendo apenas em Python ou em vantagens.
Como escolhemos o idioma? O primeiro são os requisitos de carga, ou seja, vemos se o Python pode lidar com isso ou não. Se ele puxar, olharemos para a competência dos desenvolvedores da equipe.
Agora quero falar sobre o intérprete. Como funciona o CPython?
Dispositivo de intérprete
Pode surgir a pergunta: por que precisamos saber como funciona o intérprete. A pergunta é válida. Você pode escrever serviços facilmente sem saber o que está por trás disso. As respostas podem ser as seguintes:
1. Otimização para alta carga. Imagine que você tem um serviço Python. Funciona, a carga está baixa. Mas um dia a tarefa chega até você - escrever uma caneta, pronto para uma carga pesada. Você não pode fugir disso, você não pode reescrever todo o serviço em C ++. Então, você precisa otimizar o serviço para alta carga. Compreender como o intérprete funciona pode ajudar nisso.
2. Depuração de casos complexos. Digamos que o serviço esteja em execução, mas a memória comece a "vazar" nele. Na Yandex.Taxi, tivemos um caso assim recentemente. O serviço consumia 8 GB de memória a cada hora e travava. Precisamos descobrir isso. É sobre a linguagem, Python. É necessário conhecimento de como funciona o gerenciamento de memória em Python.
3. Isso é útil se você for escrever bibliotecas complexas ou código complexo.
4. E em geral - é considerado uma boa forma de conhecer mais profundamente a ferramenta com a qual você está trabalhando, e não apenas como um usuário. Isso é apreciado no Yandex.
5. Eles fazem perguntas sobre isso em entrevistas, mas esse não é o ponto, mas sua visão geral de TI.

Vamos relembrar brevemente quais são os tipos de tradutores. Temos compiladores e intérpretes. O compilador, como você provavelmente sabe, é o que traduz seu código-fonte diretamente em código de máquina. Em vez disso, o interpretador traduz primeiro em bytecode e, em seguida, o executa. Python é uma linguagem interpretada.
Bytecode é um tipo de código intermediário obtido do original. Ele não está vinculado à plataforma e é executado em uma máquina virtual. Por que virtual? Este não é um carro real, mas algum tipo de abstração.

Que tipos de máquinas virtuais existem? Registre e empilhe. Mas aqui devemos nos lembrar não disso, mas do fato de que Python é uma máquina de pilha. A seguir, veremos como a pilha funciona.
E mais uma ressalva: aqui vamos falar apenas sobre CPython. CPython é uma implementação de Python de referência, escrita, como você pode imaginar, em C. Usada como sinônimo: quando falamos sobre Python, normalmente falamos sobre CPython.
Mas também existem outros intérpretes. Existe o PyPy, que usa compilação JIT e acelera cerca de cinco vezes. Raramente é usado. Sinceramente, não conheci. Existe o JPython, existe o IronPython, que traduz bytecode para a máquina virtual Java e para a máquina Dotnet. Isso está fora do escopo da palestra de hoje - para ser honesto, ainda não descobri. Então, vamos dar uma olhada no CPython.

Vamos ver o que acontece. Você tem uma fonte, uma linha, e deseja executá-la. O que o intérprete faz? Uma string é apenas uma coleção de caracteres. Para fazer algo significativo com ele, primeiro você traduz o código em tokens. Um token é um conjunto agrupado de caracteres, um identificador, um número ou algum tipo de iteração. Na verdade, o intérprete traduz o código em tokens.

Além disso, a Árvore Sintaxe Abstrata, AST, é construída a partir desses tokens. Além disso, não se preocupe ainda, essas são apenas algumas árvores, nos nós dos quais você opera. Digamos que em nosso caso haja BinOp, uma operação binária. Operação - exponenciação, operandos: o número a aumentar e a potência a aumentar.
Além disso, você já pode construir algum código usando essas árvores. Perco muitas etapas, há uma etapa de otimização, outras etapas. Então, essas árvores de sintaxe são traduzidas em bytecode.
Vamos ver com mais detalhes aqui. Um bytecode é, como o nome nos diz, um código feito de bytes. E em Python, a partir de 3.6, o bytecode tem dois bytes.

O primeiro byte é o próprio operador, denominado opcode. O segundo byte é o argumento oparg. Parece que vimos de cima. Ou seja, uma sequência de bytes. Mas Python tem um módulo chamado dis, do Disassembler, com o qual podemos ver uma representação mais legível.
Com o que se parece? Há um número de linha da fonte - o mais à esquerda. A segunda coluna é o endereço. Como eu disse, o bytecode em Python 3.6 leva dois bytes, então todos os endereços são pares e vemos 0, 2, 4 ...
Load.name, Load.const já são as próprias opções de código, ou seja, os códigos daquelas operações que Python deve ser executado. 0, 0, 1, 1 são oparg, ou seja, os argumentos dessas operações. Vamos ver como eles são feitos a seguir.
(...) Vamos ver como o bytecode é executado em Python, quais estruturas existem para isso.

Se você não conhece C, tudo bem. As notas de rodapé são para compreensão geral.
Python tem duas estruturas que nos ajudam a executar bytecode. O primeiro é CodeObject, você pode ver seu resumo. Na verdade, a estrutura é maior. Este é um código sem contexto. Isso significa que essa estrutura contém, na verdade, o bytecode que acabamos de ver. Ele contém os nomes das variáveis usadas nesta função, se a função contém referências a constantes, nomes de constantes, algo mais.

A próxima estrutura é FrameObject. Este já é o contexto de execução, a estrutura que já contém o valor das variáveis; referências a variáveis globais; a pilha de execução, sobre a qual falaremos um pouco mais tarde, e muitas outras informações. Digamos o número da execução da instrução.
Por exemplo: se você deseja chamar uma função várias vezes, você terá o mesmo CodeObject, e um novo FrameObject será criado para cada chamada. Ele terá seus próprios argumentos, sua própria pilha. Portanto, eles estão interligados.

Qual é o loop do interpretador principal, como o bytecode é executado? Você viu que tínhamos uma lista desses opcode com oparg. Como tudo isso é feito? Python, como qualquer interpretador, tem um loop que executa esse bytecode. Ou seja, um quadro entra nele e o Python apenas passa pelo bytecode em ordem, verifica que tipo de oparg ele é e vai para seu manipulador usando um switch enorme. Apenas um opcode é mostrado aqui, por exemplo. Por exemplo, temos uma subtração binária aqui, uma subtração binária, digamos que “AB” será realizada neste local.
Vamos explicar como funciona a subtração binária. Muito simples, este é um dos códigos mais simples. A função TOP pega o valor mais alto da pilha, pega do mais alto, não apenas o retira da pilha e, em seguida, a função PyNumber_Subtract é chamada. Resultado: a função de barra SET_TOP é empurrada de volta para a pilha. Se não estiver claro sobre a pilha, um exemplo se seguirá.

Muito brevemente sobre o GIL. O GIL é um mutex de nível de processo em Python que leva esse mutex no loop do interpretador principal. E só depois disso o bytecode começa a ser executado. Isso é feito para que apenas um thread esteja executando o bytecode por vez, a fim de proteger a estrutura interna do interpretador.
Digamos, indo um pouco além, que todos os objetos em Python têm várias referências a eles. E se dois threads alterarem esse número de links, o interpretador será interrompido. Portanto, existe um GIL.
Você será informado sobre isso na aula sobre programação assíncrona. Como isso pode ser importante para você? Multithreading não é usado, porque mesmo que você faça várias threads, geralmente você terá apenas uma delas executada, o bytecode será executado em uma das threads. Portanto, use multiprocessamento ou extensão sish ou outra coisa.

Um pequeno exemplo. Você pode explorar este quadro com segurança em Python. Existe um módulo sys que possui uma função de sublinhado get_frame. Você pode obter um quadro e ver quais variáveis existem. Existe uma instrução. Isso é mais para ensinar, na vida real eu não usei.
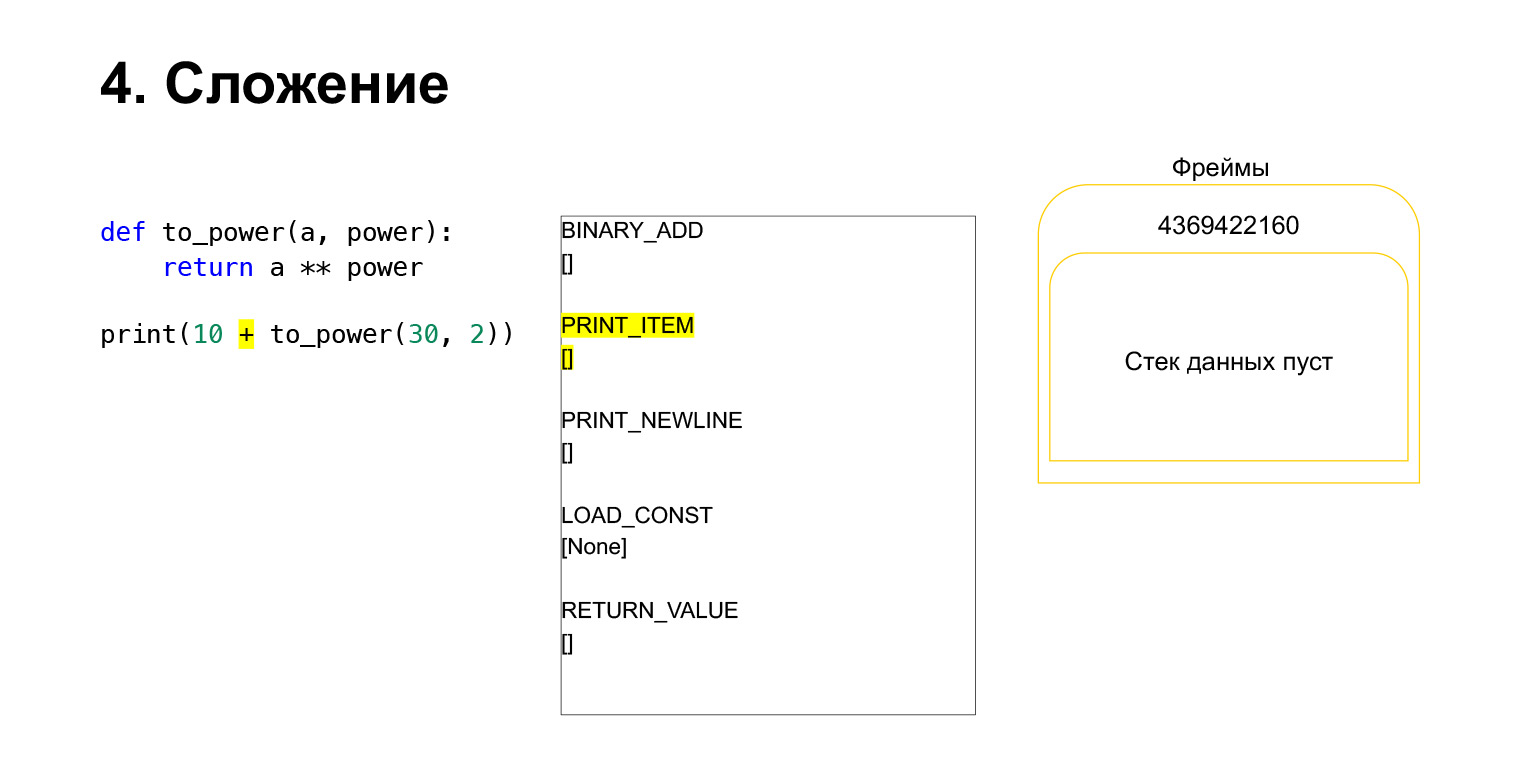
Vamos tentar ver como a pilha da máquina virtual Python funciona para entender. Temos um código, bem simples, que não entende o que faz.
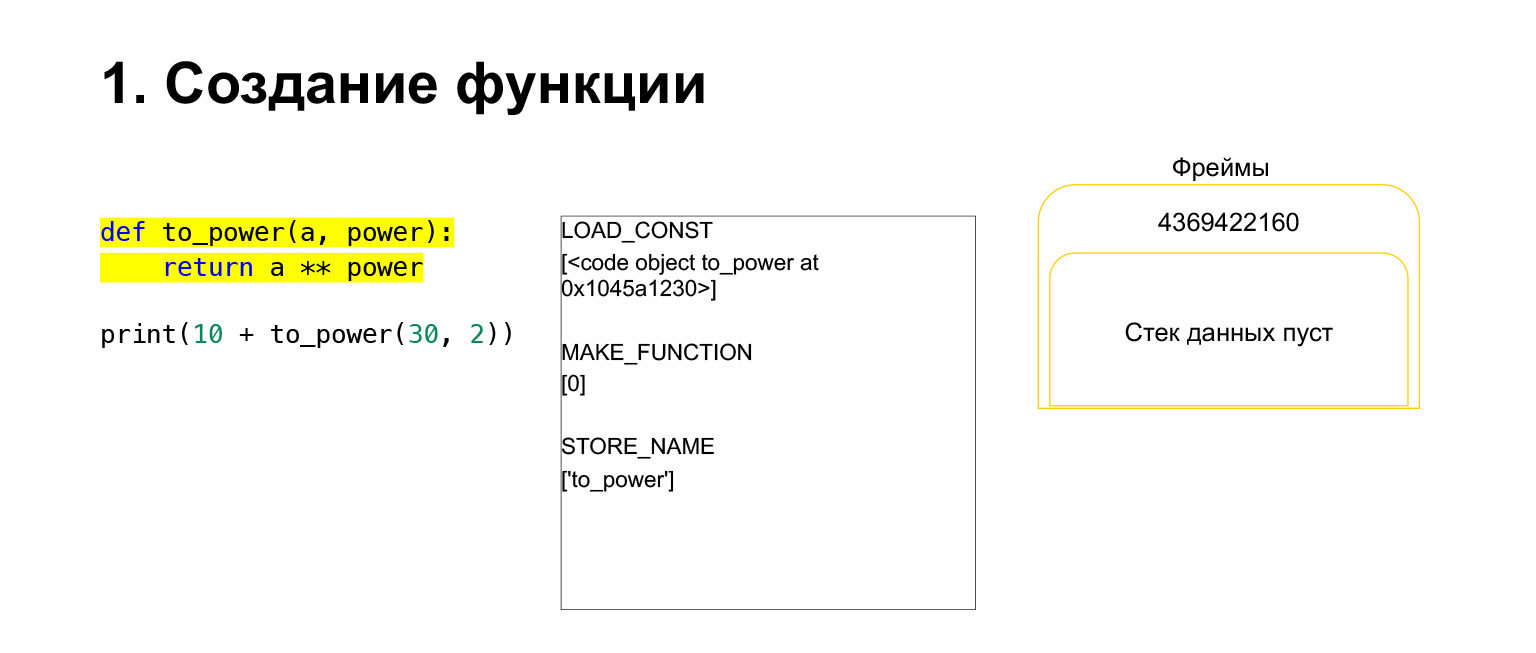
À esquerda está o código. A parte que estamos examinando agora está destacada em amarelo. Na segunda coluna, temos o bytecode desta peça. A terceira coluna contém quadros com pilhas. Ou seja, cada FrameObject tem sua própria pilha de execução.
O que o Python faz? Ele simplesmente segue em ordem, bytecode, na coluna do meio, executa e funciona com a pilha.
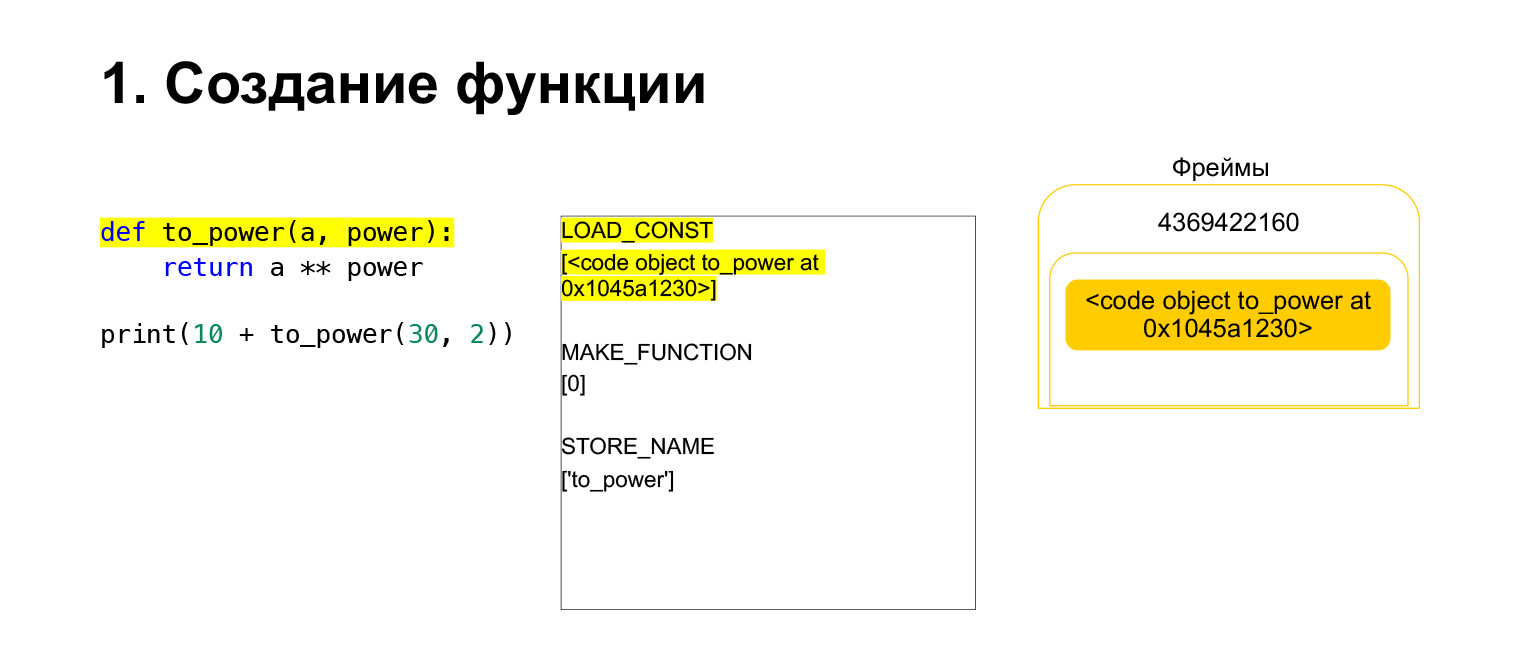
Executamos o primeiro opcode chamado LOAD_CONST. Ele carrega uma constante. Pulamos a parte, um CodeObject é criado lá e tínhamos um CodeObject em algum lugar das constantes. Python o carregou na pilha usando LOAD_CONST. Agora temos um CodeObject na pilha neste quadro. Podemos seguir em frente.
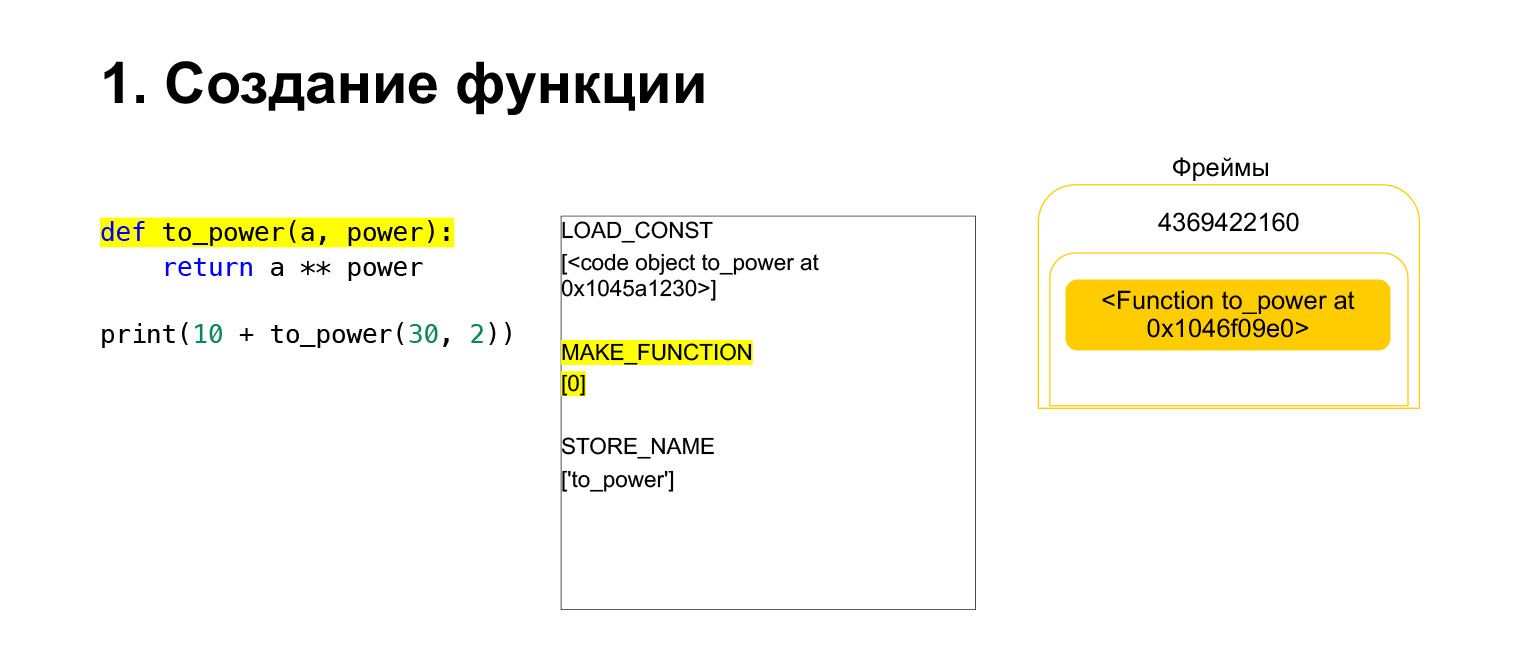
Então o Python executa opcode MAKE_FUNCTION. MAKE_FUNCTION obviamente faz uma função. Ele espera que você tenha um CodeObject na pilha. Ele executa alguma ação, cria uma função e coloca a função de volta na pilha. Agora você tem FUNCTION em vez de CodeObject que estava na pilha de quadros. E agora essa função precisa ser colocada na variável to_power para que você possa se referir a ela.
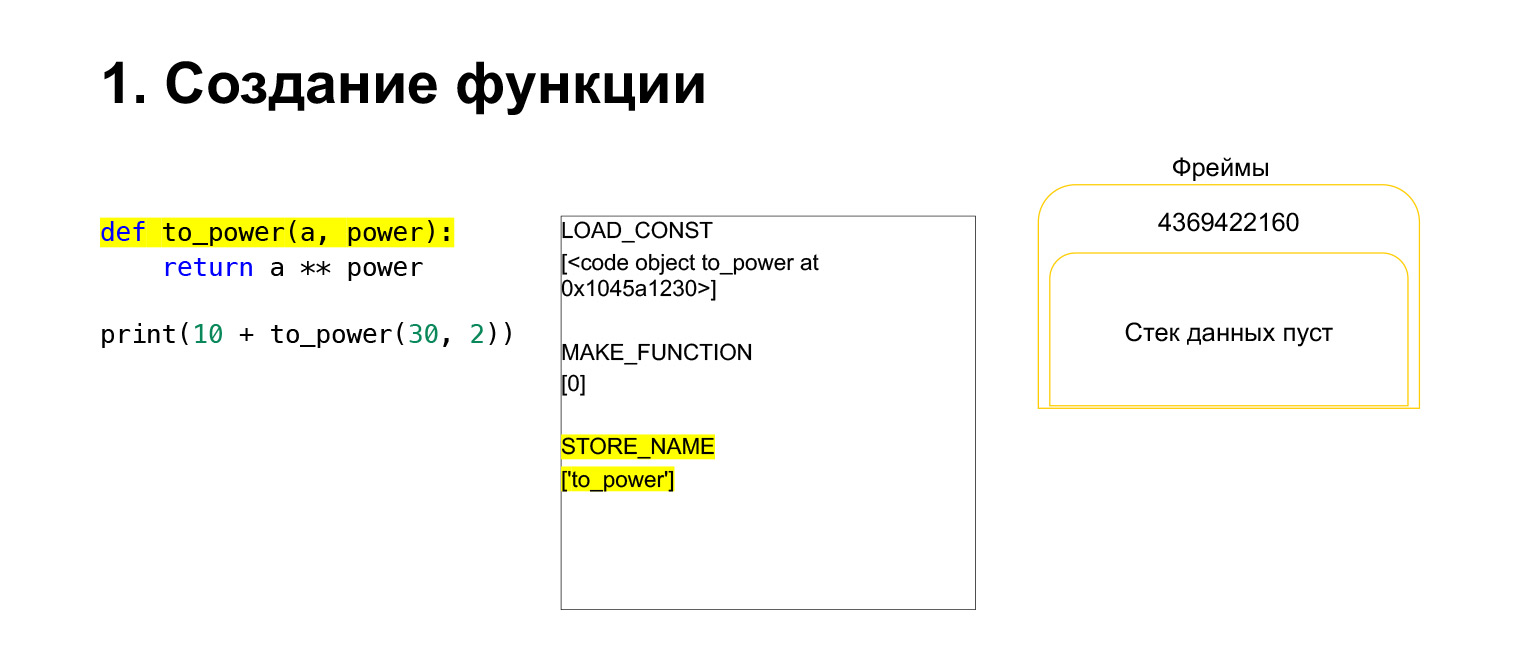
Opcode STORE_NAME é executado, ele é colocado na variável to_power. Tínhamos uma função na pilha, agora é a variável to_power, você pode se referir a ela.
A seguir, queremos imprimir 10 + o valor desta função.
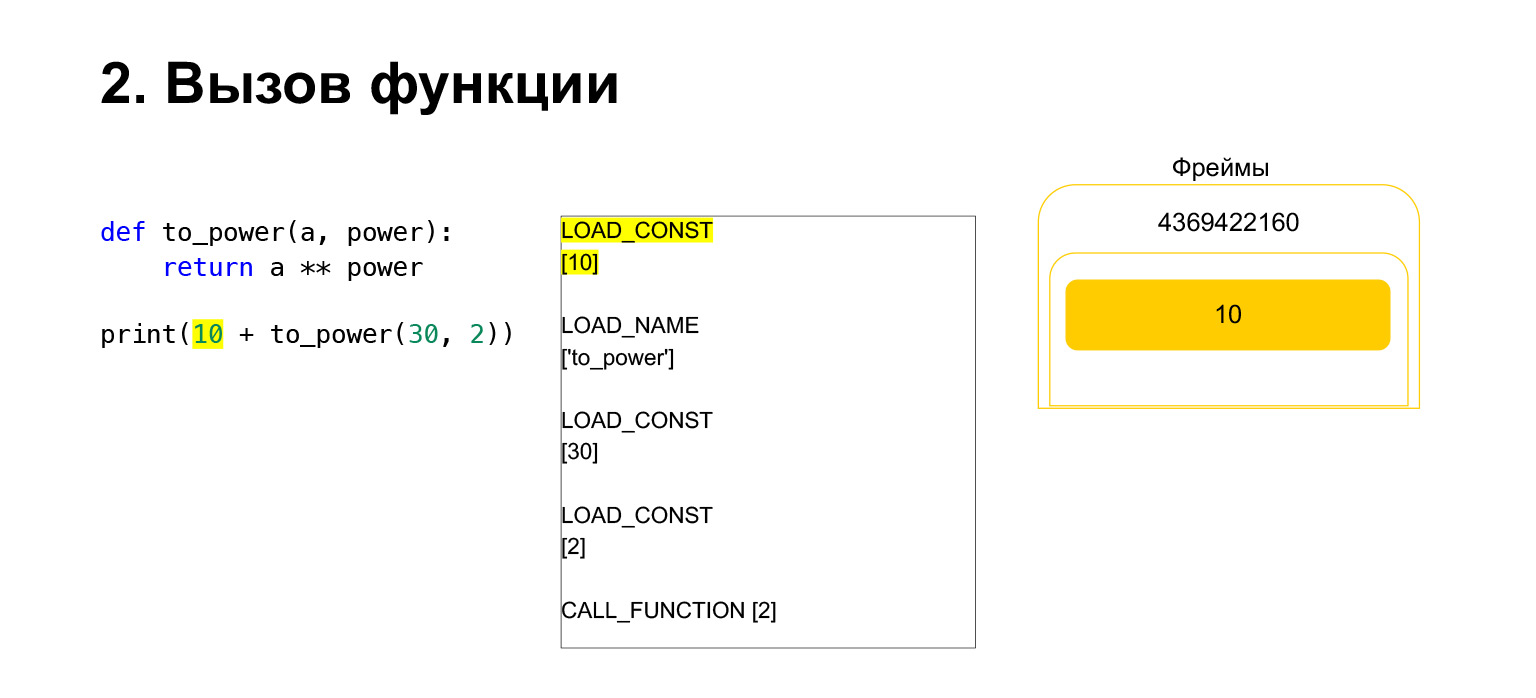
O que o Python faz? Isso foi convertido para bytecode. O primeiro opcode que temos é LOAD_CONST. Colocamos os dez primeiros na pilha. Uma dúzia apareceu na pilha. Agora precisamos executar to_power.

A função é executada da seguinte maneira. Se ela tiver argumentos posicionais - não examinaremos o resto por enquanto - primeiro o Python coloca a própria função na pilha. Em seguida, ele insere todos os argumentos e chama CALL_FUNCTION com o número do argumento dos argumentos da função.
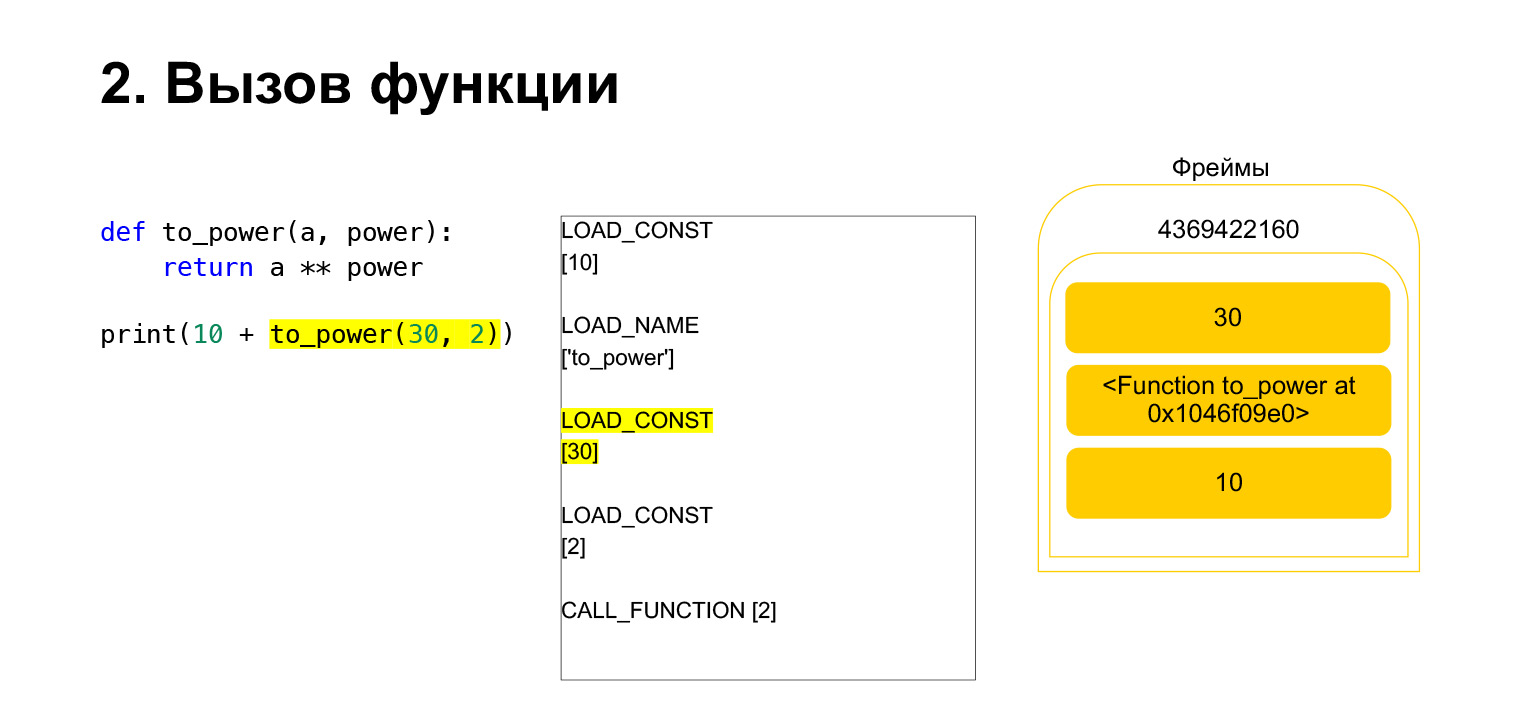
Carregamos o primeiro argumento na pilha, esta é uma função.
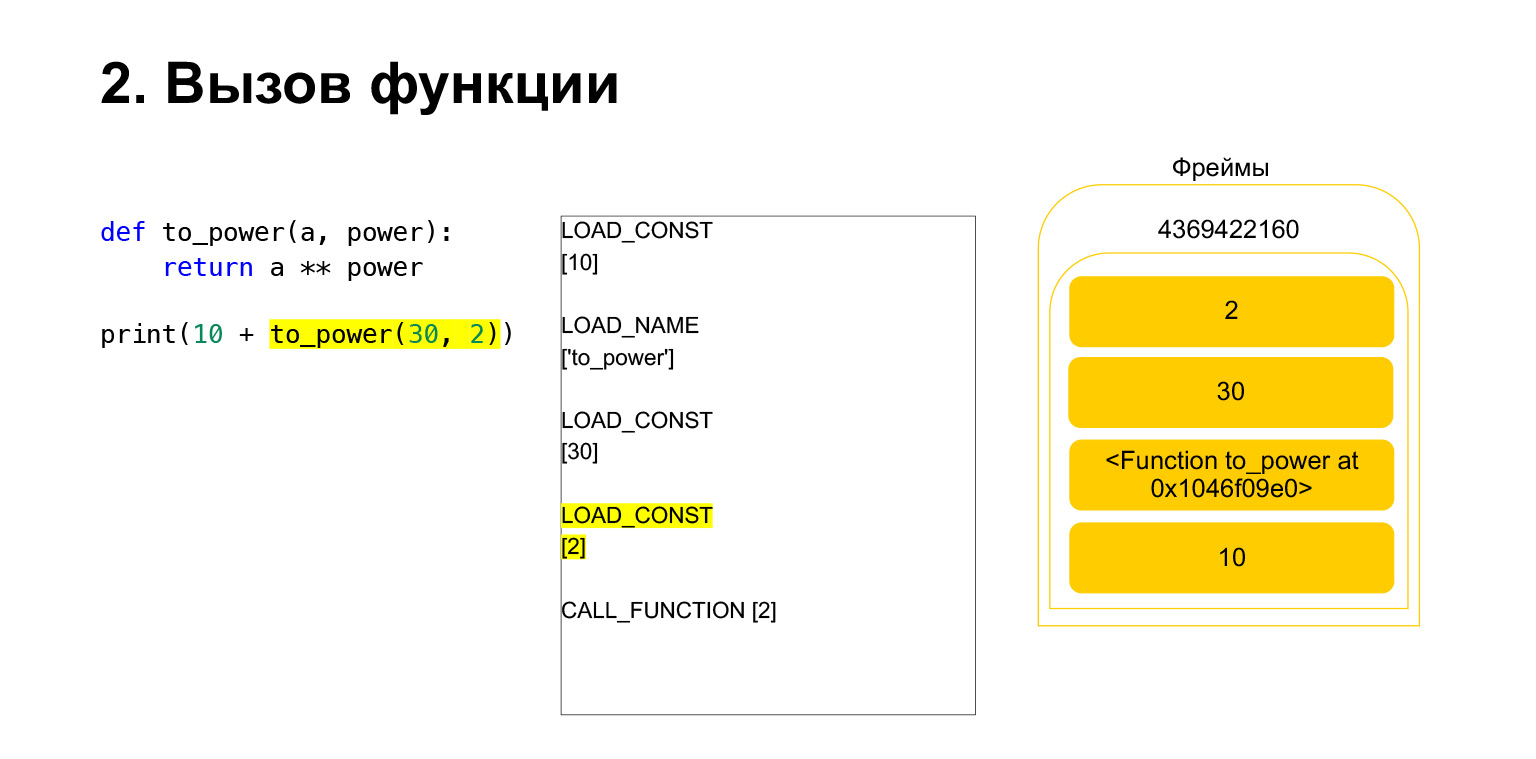
Carregamos mais dois argumentos na pilha - 30 e 2. Agora temos uma função e dois argumentos na pilha. O topo da pilha está no topo. CALL_FUNCTION está esperando por nós. Dizemos: CALL_FUNCTION (2), ou seja, temos uma função com dois argumentos. CALL_FUNCTION espera ter dois argumentos na pilha, seguidos por uma função. Temos: 2, 30 e FUNÇÃO.
Opcode em andamento.
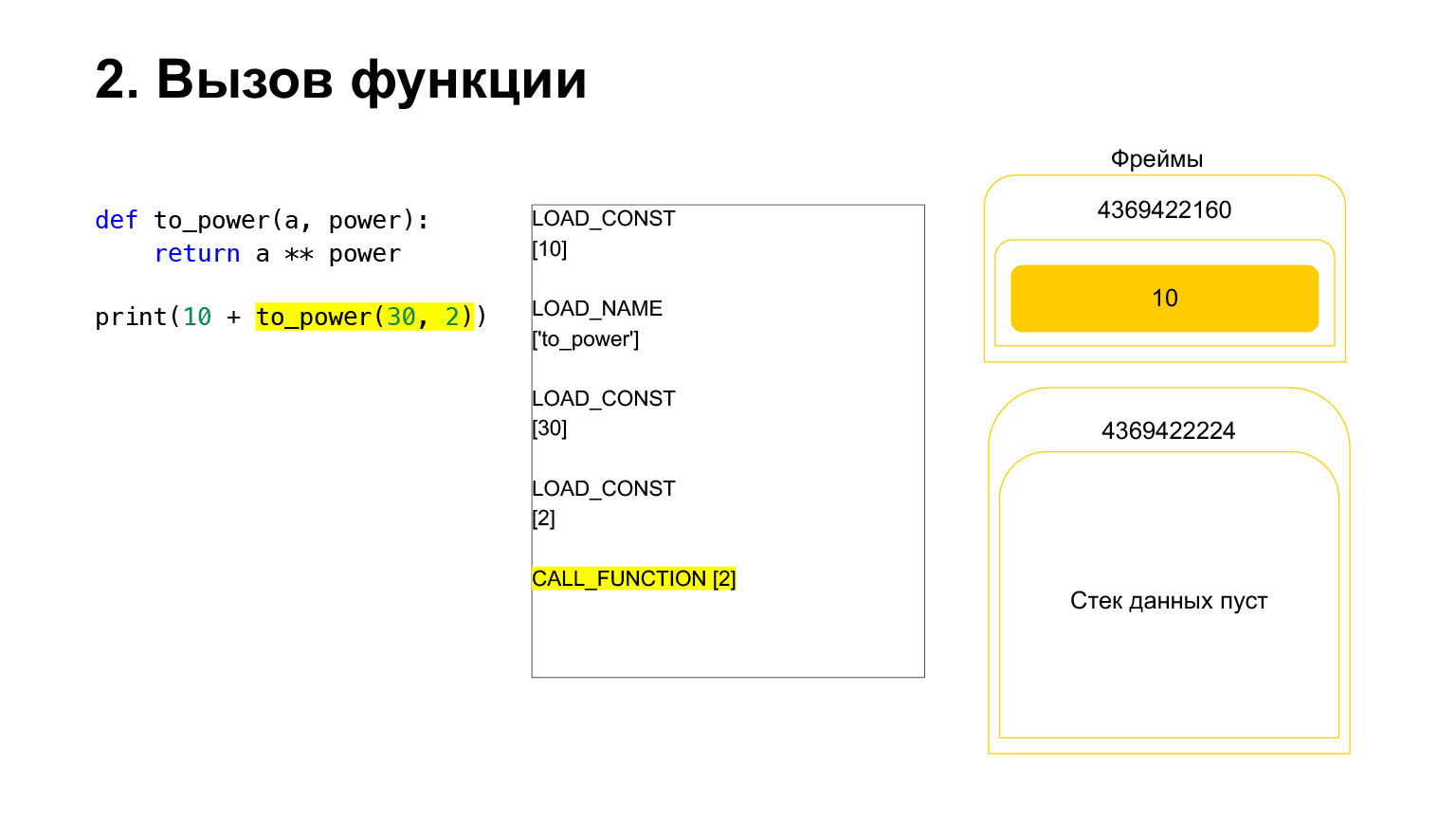
Para nós, consequentemente, essa pilha sai, uma nova função é criada, na qual a execução ocorrerá agora.
O quadro tem sua própria pilha. Um novo quadro foi criado para sua função. Ainda está vazio.
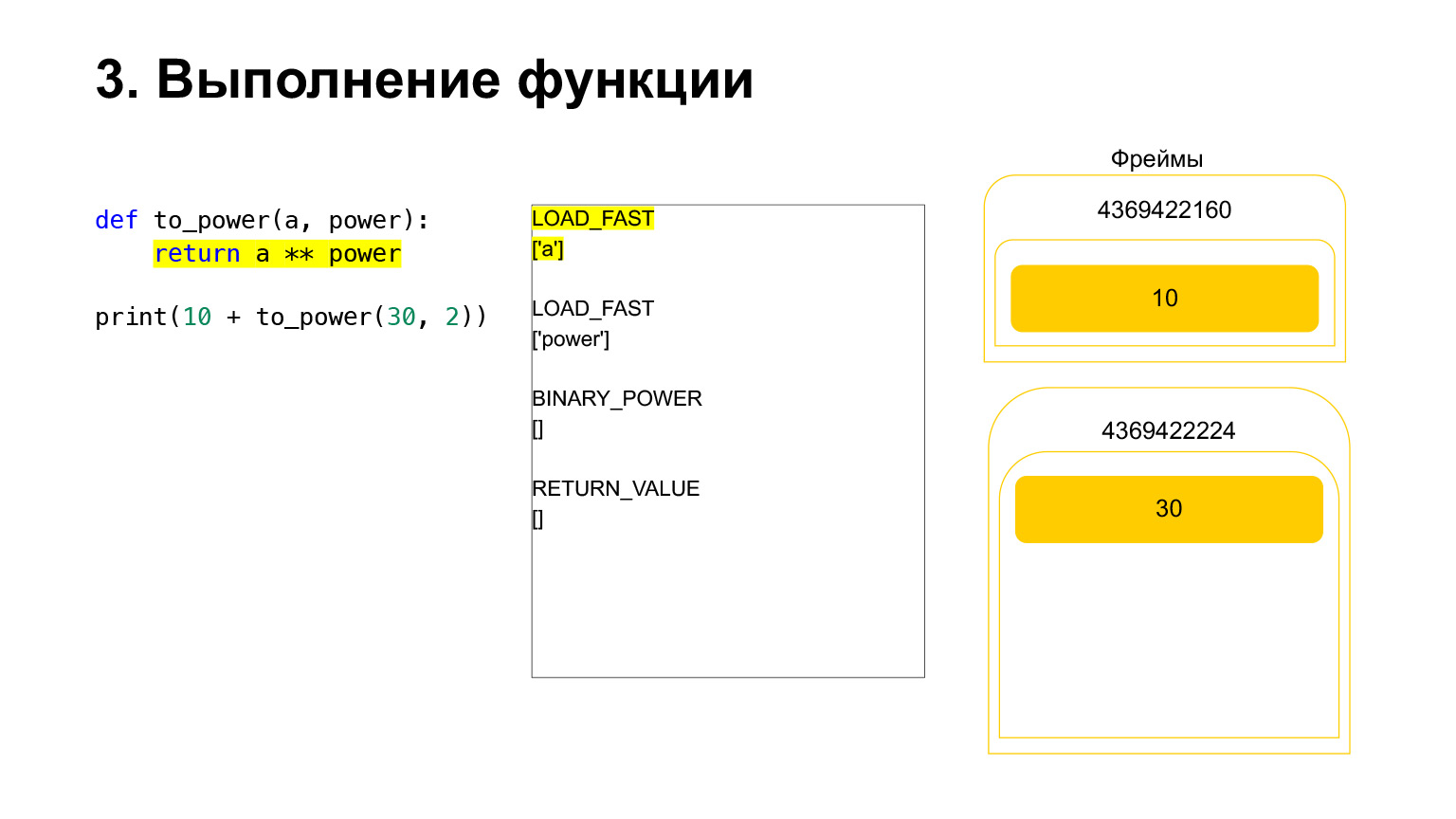
A execução posterior ocorre. Já é mais fácil aqui. Precisamos elevar A à potência. Carregamos na pilha o valor da variável A - 30. O valor da variável power - 2.
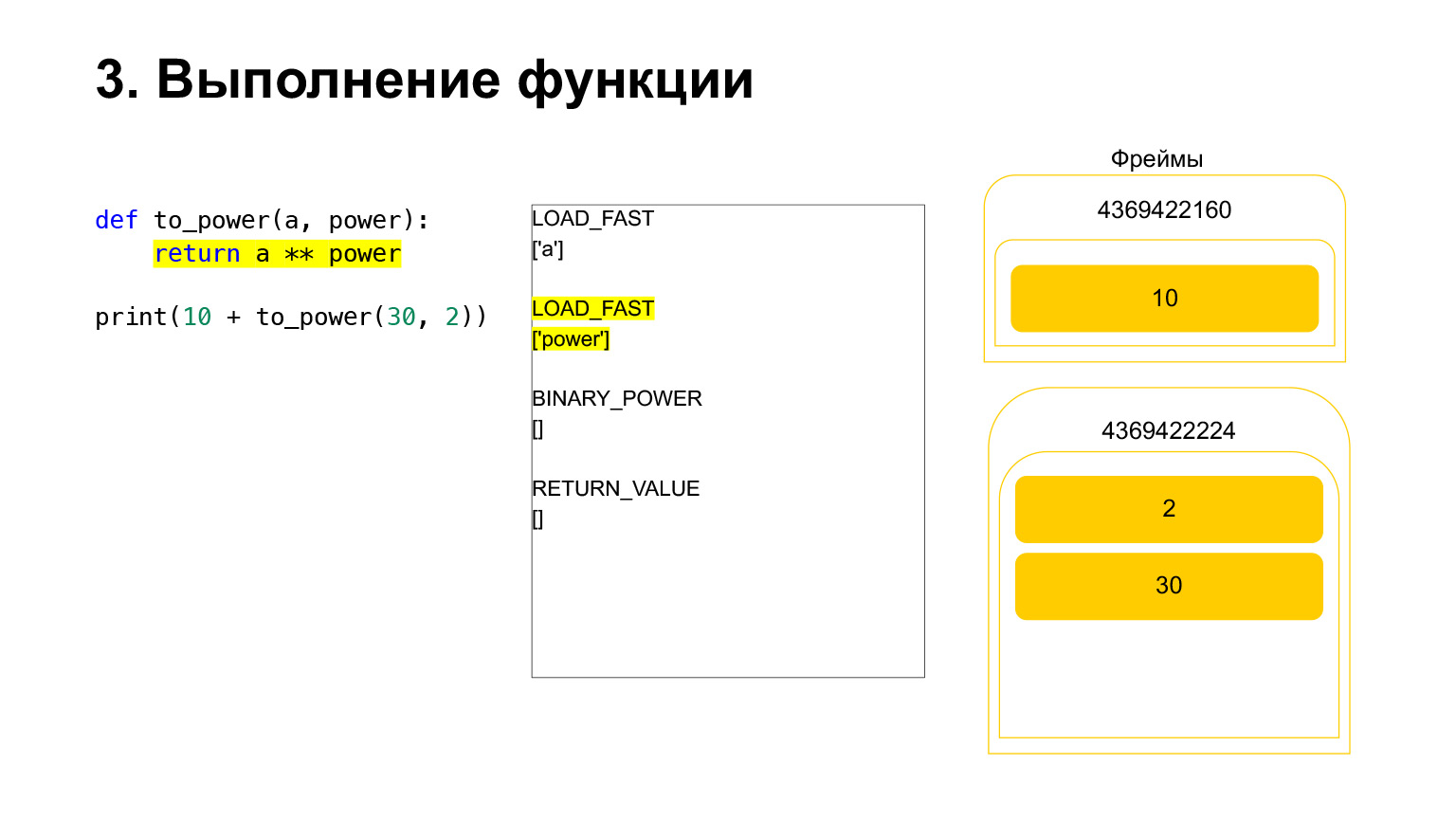
E o opcode BINARY_POWER é executado.
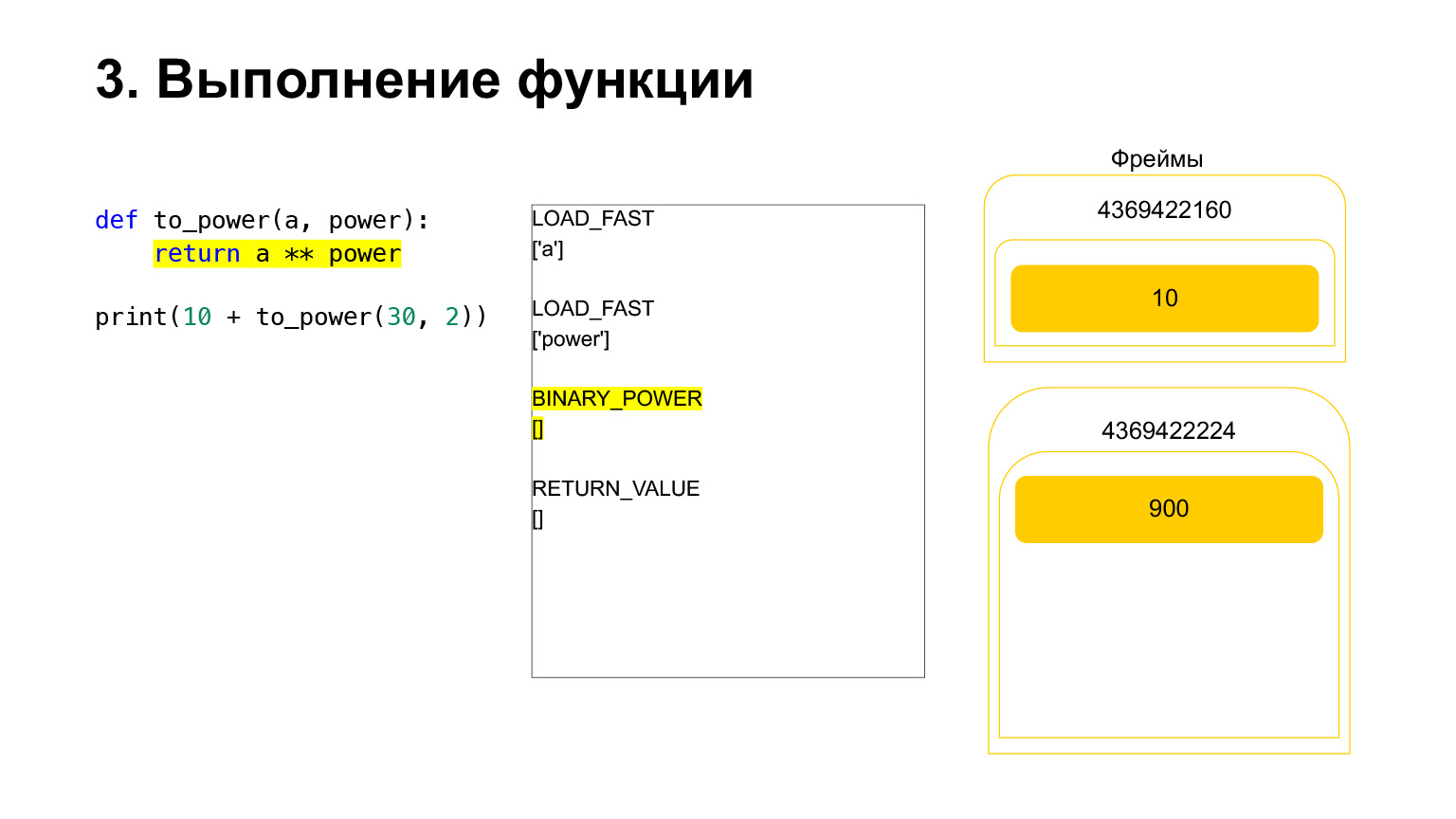
Elevamos um número à potência de outro e o colocamos de volta na pilha. Descobriu-se 900 na pilha de funções.
O próximo opcode RETURN_VALUE retornará o valor da pilha para o quadro anterior.

É assim que ocorre a execução. A função foi concluída, o quadro provavelmente será limpo se não tiver referências e haverá dois números no quadro da função anterior.

Então tudo é quase o mesmo. A adição ocorre.
(...) Vamos falar sobre tipos e PyObject.
Digitando

Um objeto é uma estrutura sish, na qual existem dois campos principais: o primeiro é o número de referências a esse objeto, o segundo é o tipo do objeto, é claro, uma referência ao tipo do objeto.
Outros objetos herdam de PyObject, incluindo-o. Ou seja, se olharmos para um float, um número de ponto flutuante, a estrutura lá é PyFloatObject, então ele tem um HEAD, que é uma estrutura PyObject, e, além disso, dados, ou seja, double ob_fval, onde o valor deste float em si é armazenado.

E esse é o tipo de objeto. Acabamos de ver o tipo em PyObject, é uma estrutura que denota um tipo. Na verdade, essa também é uma estrutura C que contém ponteiros para funções que implementam o comportamento desse objeto. Ou seja, existe uma estrutura muito grande lá. Possui funções especificadas que são chamadas se, por exemplo, você deseja adicionar dois objetos deste tipo. Ou você deseja subtrair, chamar esse objeto ou criá-lo. Tudo o que você pode fazer com os tipos deve ser especificado nesta estrutura.

Por exemplo, vamos examinar int, inteiros em Python. Também uma versão muito abreviada. Em que podemos estar interessados? Int tem tp_name. Você pode ver que existe tp_hash, podemos obter o hash int. Se chamarmos o hash em int, esta função será chamada. tp_call temos zero, não definido, isso significa que não podemos chamar int. tp_str - conversão de string não definida. Python tem uma função str que pode ser convertida em uma string.
Não entrou no slide, mas vocês já sabem que o int ainda pode ser impresso. Por que é zero aqui? Como também há tp_repr, Python tem duas funções de passagem de string: str e repr. Fundição mais detalhada para string. Na verdade, está definido, apenas não entrou no slide e será chamado se você realmente levar a uma string.
Bem no final, vemos tp_new - uma função que é chamada quando este objeto é criado. tp_init temos zero. Todos nós sabemos que int não é um tipo mutável, imutável. Depois de criá-lo, não adianta alterá-lo, inicializá-lo, então é zero.

Vejamos também Bool, por exemplo. Como alguns de vocês devem saber, Bool em Python na verdade herda de int. Ou seja, você pode adicionar Bool, compartilhar uns com os outros. Isso, é claro, não pode ser feito, mas é possível.
Vemos que existe um tp_base - um ponteiro para o objeto base. Tudo além de tp_base são as únicas coisas que foram substituídas. Ou seja, ele tem seu próprio nome, sua própria função de apresentação, onde não é um número que está escrito, mas verdadeiro ou falso. Representação como número, algumas funções lógicas são substituídas lá. Docstring é próprio e de sua criação. Todo o resto vem de int.

Vou falar brevemente sobre listas. Em Python, uma lista é um array dinâmico. Um array dinâmico é um array que funciona assim: você inicializa uma área de memória com antecedência com alguma dimensão. Adicione elementos lá. Assim que o número de elementos ultrapassar esse tamanho, você o expande com uma certa margem, ou seja, não por um, mas por algum valor a mais de um, para que haja um bom ponto de asin.
Em Python, o tamanho cresce em 0, 4, 8, 16, 25, ou seja, de acordo com algum tipo de fórmula que nos permite fazer a inserção assintoticamente para uma constante. E você pode ver que há um trecho da função de inserção na lista. Ou seja, estamos fazendo redimensionamento. Se não tivermos resize, geramos um erro e atribuímos o elemento. Em Python, este é um array dinâmico normal implementado em C.
(...) Vamos falar sobre dicionários brevemente. Eles estão por toda parte em Python.
Dicionários
Todos nós sabemos que nos objetos toda a composição das classes está contida nos dicionários. Muitas coisas são baseadas neles. Dicionários em Python em uma tabela hash.
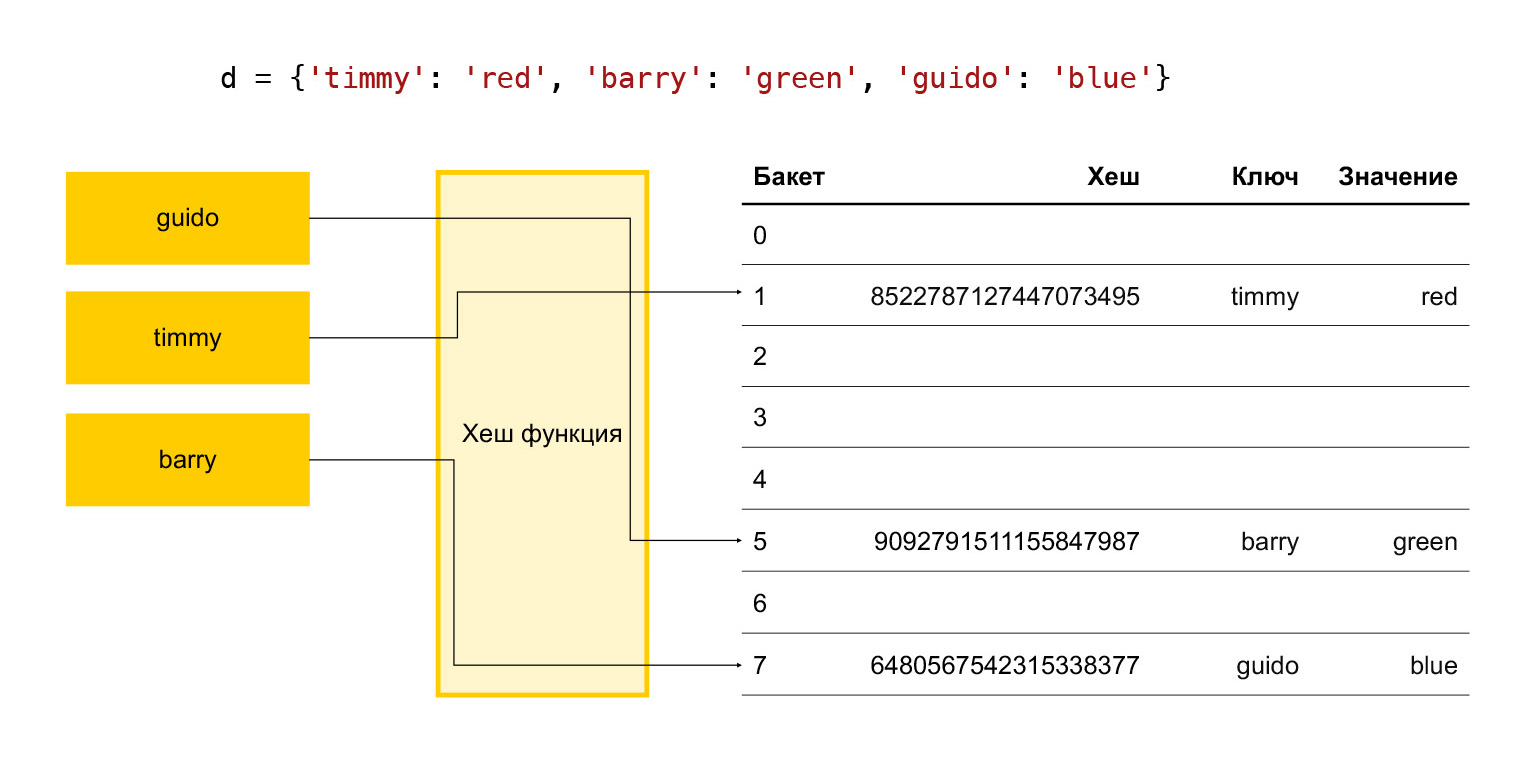
Resumindo, como funciona uma tabela hash? Existem algumas chaves: timmy, barry, guido. Queremos colocá-los em um dicionário, executamos cada chave por meio de uma função hash. Acontece um hash. Usamos esse hash para encontrar o balde. Um balde é simplesmente um número em uma matriz de elementos. Ocorre a divisão final do módulo. Se o balde estiver vazio, basta colocar o item desejado nele. Se não estiver vazio e já houver um determinado elemento aí, então é uma colisão e escolhemos o próximo balde, ver se está livre ou não. E assim por diante até encontrarmos um balde grátis.
Portanto, para que a operação de adição ocorra em um tempo adequado, precisamos manter constantemente um determinado número de baldes livres. Caso contrário, ao nos aproximarmos do tamanho deste array, vamos procurar por um balde livre por muito tempo, e tudo ficará mais lento.
Portanto, é empiricamente aceito no Python que um terço dos elementos do array são sempre gratuitos. Se o número for maior que dois terços, a matriz se expande. Isso não é bom, porque um terço dos elementos é desperdiçado, nada de útil é armazenado.

Link do slide
Portanto, desde a versão 3.6, o Python fez isso. À esquerda você pode ver como era antes. Temos uma matriz esparsa onde esses três elementos são armazenados. Desde 3.6, eles decidiram fazer de tal array esparso um array regular, mas ao mesmo tempo armazenar os índices dos elementos de bucket em índices de array separados.
Se olharmos para a matriz de índices, então no primeiro intervalo temos Nenhum, no segundo há um elemento com índice 1 dessa matriz, etc.
Isso permitiu, em primeiro lugar, reduzir o uso de memória e, em segundo lugar, também o tiramos da caixa de graça matriz ordenada. Ou seja, adicionamos elementos a este array, condicionalmente, com o acréscimo sish usual, e o array é ordenado automaticamente.
Existem algumas otimizações interessantes que o Python usa. Para que essas tabelas de hash funcionem, precisamos ter uma operação de comparação de elementos. Imagine que colocamos um elemento em uma tabela hash e, em seguida, queremos pegar um elemento. Pegamos o haxixe, vamos para o balde. Vemos: o balde está cheio, tem alguma coisa lá. Mas é esse o elemento de que precisamos? Talvez tenha havido uma colisão quando ele foi colocado e o item realmente coube em outro balde. Portanto, devemos comparar as chaves. Se a chave estiver errada, usamos o mesmo mecanismo de busca do próximo balde que é usado para resolução de colisão. E vamos mais longe.

Link do slide
Portanto, precisamos ter uma função de comparação de chave. Em geral, o recurso de comparação de objetos pode ser muito caro. Portanto, essa otimização é usada. Primeiro, comparamos os IDs dos itens. ID em CPython é, como você sabe, uma posição na memória.
Se os IDs forem iguais, eles são os mesmos objetos e, claro, são iguais. Em seguida, retornamos True. Caso contrário, observe os hashes. O hash deve ser uma operação muito rápida se não tivermos substituído de alguma forma. Pegamos hashes desses dois objetos e comparamos. Se seus hashes não forem iguais, então os objetos definitivamente não são iguais, então retornamos False.
E apenas em um caso muito improvável - se nossos hashes são iguais, mas não sabemos se é o mesmo objeto - só então comparamos os próprios objetos.
Uma coisa interessante: você não pode inserir nada nas chaves durante a iteração. Isso é um engano.

Por dentro, o dicionário tem uma variável chamada versão, que armazena a versão do dicionário. Quando você altera o dicionário, a versão muda, o Python entende isso e emite um erro.

Para que os dicionários podem ser usados em um exemplo mais prático? No Taxi temos pedidos, e os pedidos têm status que podem mudar. Ao alterar o status, você deve realizar algumas ações: enviar SMS, registrar pedidos.
Essa lógica é escrita em Python. Para não escrever um enorme if do formulário "se o status do pedido é tal e tal, faça isso", existe um dict em que a chave é o status do pedido. E para VALUE existe uma tupla, que contém todos os manipuladores que devem ser executados na transição para este status. Esta é uma prática comum, na verdade, é uma substituição para o switch.

Mais algumas coisas por tipo. Vou te falar sobre imutável. Esses são tipos de dados imutáveis e mutáveis são, respectivamente, tipos mutáveis: ditames, classes, instâncias de classe, planilhas e talvez algo mais. Quase todo o resto são strings, números comuns - eles são imutáveis. Para que servem os tipos mutáveis? Primeiro, eles tornam o código mais fácil de entender. Ou seja, se você vir no código que algo é uma tupla, você entende que isso não muda mais e isso torna mais fácil para você ler o código? entenda o que vai acontecer a seguir. Em tupla ds, você não pode digitar itens. Você entenderá isso e ajudará na leitura de você e de todas as pessoas que lerão o código para você.
Portanto, há uma regra: se você não mudar algo, é melhor usar tipos imutáveis. Também leva a um trabalho mais rápido. Existem duas constantes que a tupla usa: pit_tuple, tap_tuple, max e CC. Qual é o ponto? Para todas as tuplas de tamanho até 20, um método de alocação específico é usado, o que torna essa alocação mais rápida. E pode haver até dois mil desses objetos de cada tipo, muito. Isso é muito mais rápido do que planilhas, portanto, se você usar tupla, será mais rápido.
Existem também verificações de tempo de execução. Obviamente, se você estiver tentando conectar algo em um objeto e ele não suportar essa função, haverá um erro, uma certa compreensão de que você fez algo errado. As chaves em um dicionário só podem ser objetos que possuem um hash que não muda durante sua vida útil. Apenas objetos imutáveis satisfazem esta definição. Só eles podem ser chaves de ditado.

Como fica em C? Exemplo. À esquerda está uma tupla e à direita uma lista regular. Aqui, é claro, nem todas as diferenças são visíveis, mas apenas aquelas que eu queria mostrar. Na lista do campo tp_hash temos NotImplemented, ou seja, a lista não tem hash. Na tupla, há alguma função que realmente retornará um hash para você. É exatamente por isso que tupla, entre outras coisas, pode ser uma chave de dicionário, e a lista não.
A próxima coisa destacada é a função de atribuição de item, sq_ass_item. Na lista é, na tupla é zero, ou seja, você naturalmente não pode atribuir nada à tupla.

Mais uma coisa. Python não copia nada até que pedimos. Isso também deve ser lembrado. Se você quiser copiar algo, use, digamos, o módulo de cópia, que tem uma função copy.deepcopy. Qual é a diferença? copy copia o objeto, se for um objeto recipiente, como uma lista de irmãos. Todas as referências que estavam neste objeto são inseridas no novo objeto. E a deepcopy copia recursivamente todos os objetos dentro desse contêiner e além.
Ou, se quiser copiar uma lista rapidamente, você pode usar uma única fatia de dois pontos. Você receberá uma cópia, esse atalho é simples.
(...) A seguir, vamos falar sobre gerenciamento de memória.
Gerenciamento de memória

Vamos pegar nosso módulo sys. Tem uma função que permite ver se está usando alguma memória. Se você iniciar o interpretador e observar as estatísticas de mudanças de memória, verá que criou muitos objetos, incluindo pequenos. E esses são apenas os objetos que são criados atualmente.
Na verdade, o Python cria muitos pequenos objetos em tempo de execução. E se usássemos a função malloc padrão para alocá-los, rapidamente nos veríamos no fato de que nossa memória está fragmentada e, conseqüentemente, a alocação de memória é lenta.

Isso implica a necessidade de usar seu próprio gerenciador de memória. Resumindo, como funciona? Python aloca para si blocos de memória, chamados de arena, 256 kilobytes cada. Por dentro, ele se divide em grupos de quatro kilobytes, este é o tamanho de uma página de memória. Dentro dos pools, temos blocos de tamanhos diferentes, de 16 a 512 bytes.
Quando tentamos alocar menos de 512 bytes para um objeto, o Python seleciona à sua maneira um bloco adequado para esse objeto e coloca o objeto nesse bloco.
Se o objeto for desalocado, excluído, este bloco será marcado como livre. Mas não é fornecido ao sistema operacional e, na próxima localização, podemos escrever este objeto no mesmo bloco. Isso acelera muito a alocação de memória.

Liberando memória. Anteriormente, vimos a estrutura PyObject. Ela tem este refcnt - contagem de referência. Funciona de forma muito simples. Quando você faz referência a esse objeto, o Python incrementa a contagem de referência. Assim que você tiver um objeto, a referência desaparece para ele, você desaloca a contagem de referência.
O que está destacado em amarelo. Se refcnt não for zero, então estamos fazendo algo lá. Se refcnt for zero, desalocamos imediatamente o objeto. Não estamos esperando nenhum catador de lixo, nada, mas neste momento limpamos a memória.
Se você se deparar com o método del, ele simplesmente remove a vinculação da variável ao objeto. E o método __del__, que você pode definir na classe, é chamado quando o objeto é realmente removido da memória. Você chamará del no objeto, mas se ele ainda tiver referências, o objeto não será excluído em nenhum lugar. E seu Finalizador, __del__, não será chamado. Embora sejam chamados muito semelhantes.
Uma breve demonstração de como você pode ver o número de links. Há nosso módulo sys favorito, que tem uma função getrefcount. Você pode ver o número de links para um objeto.

Eu vou te contar mais. Um objeto é feito. O número de links é obtido dele. Detalhe interessante: a variável A aponta para TaxiOrder. Você pega o número de links e "2" é impresso. Parece por quê? Temos uma referência de objeto. Mas quando você chama getrefcount, esse objeto é envolvido em torno do argumento dentro da função. Portanto, você já tem duas referências a este objeto: a primeira é a variável, a segunda é o argumento da função. Portanto, "2" é impresso.
O resto é trivial. Atribuímos outra variável ao objeto, obtemos 3. Em seguida, removemos esse vínculo, obtemos 2. Em seguida, removemos todas as referências a este objeto, e ao mesmo tempo o finalizador é chamado, que imprimirá nossa linha.

(...) Há outro recurso interessante do CPython, que não pode ser construído, e parece que não é dito sobre isso em nenhum lugar dos documentos. Inteiros são freqüentemente usados. Seria um desperdício recriá-los todas as vezes. Portanto, os números mais comumente usados, os desenvolvedores Python escolheram o intervalo de –5 a 255, eles são Singleton. Ou seja, eles são criados uma vez, ficam em algum lugar do interpretador e, quando você tenta obtê-los, obtém uma referência para o mesmo objeto. Pegamos A e B, uns, imprimimos, comparamos seus endereços. Got True. E temos, digamos, 105 referências a este objeto, simplesmente porque agora existem tantas.
Se tomarmos algum número maior - por exemplo, 1408 - esses objetos não são iguais para nós e há, respectivamente, duas referências a eles. Na verdade, um.
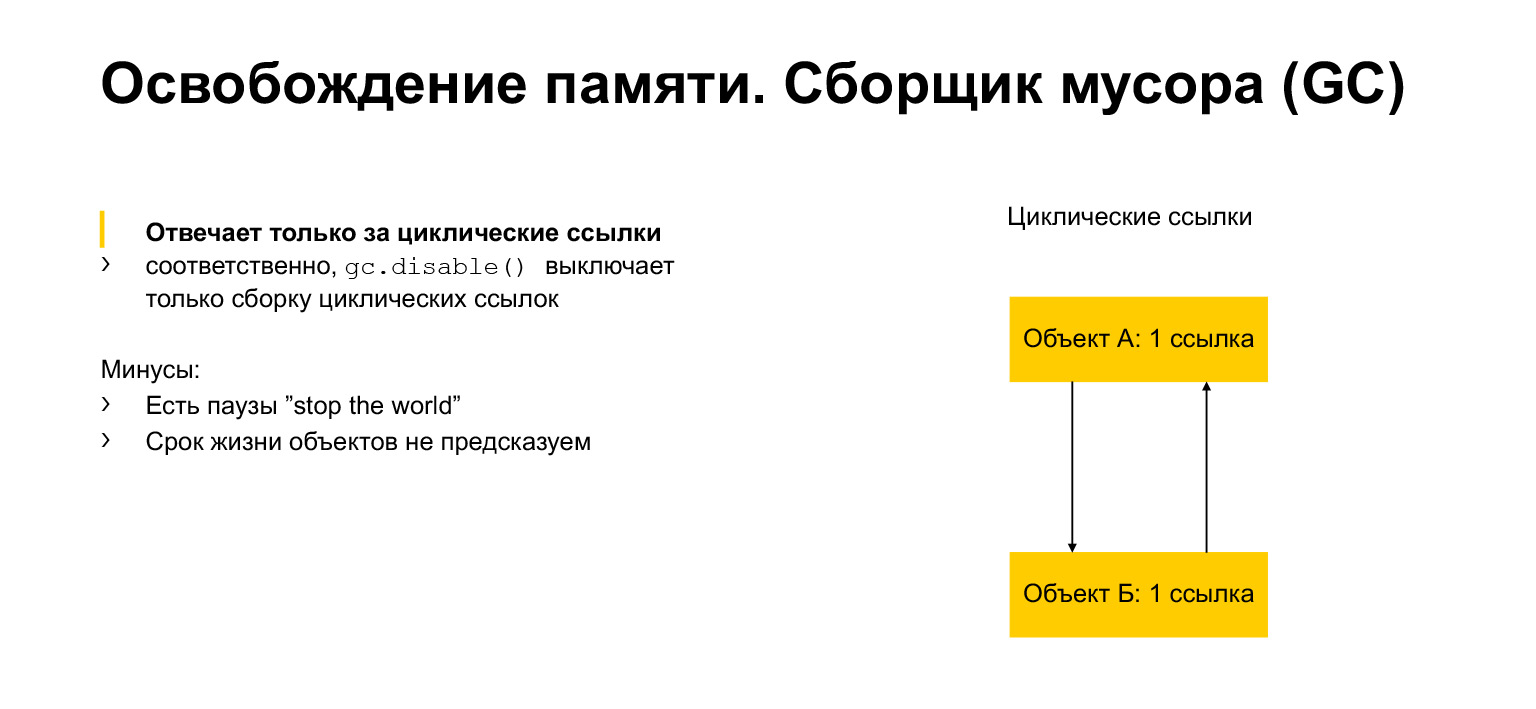
Conversamos um pouco sobre alocação e liberação de memória. Agora vamos falar sobre o coletor de lixo. Para que serve? Parece que temos vários links. Uma vez que ninguém fez referência ao objeto, podemos excluí-lo. Mas podemos ter links circulares. Um objeto pode se referir a si mesmo, por exemplo. Ou, como no exemplo, pode haver dois objetos, cada um referindo-se a um vizinho. Isso é chamado de ciclo. E então esses objetos nunca podem dar uma referência a outro objeto. Mas, ao mesmo tempo, por exemplo, eles são inatingíveis de outra parte do programa. Precisamos excluí-los porque são inacessíveis, inúteis, mas possuem links. É exatamente para isso que serve o módulo coletor de lixo. Ele detecta ciclos e remove esses objetos.
Como ele trabalha? Primeiro, vou falar brevemente sobre gerações e, em seguida, sobre o algoritmo.
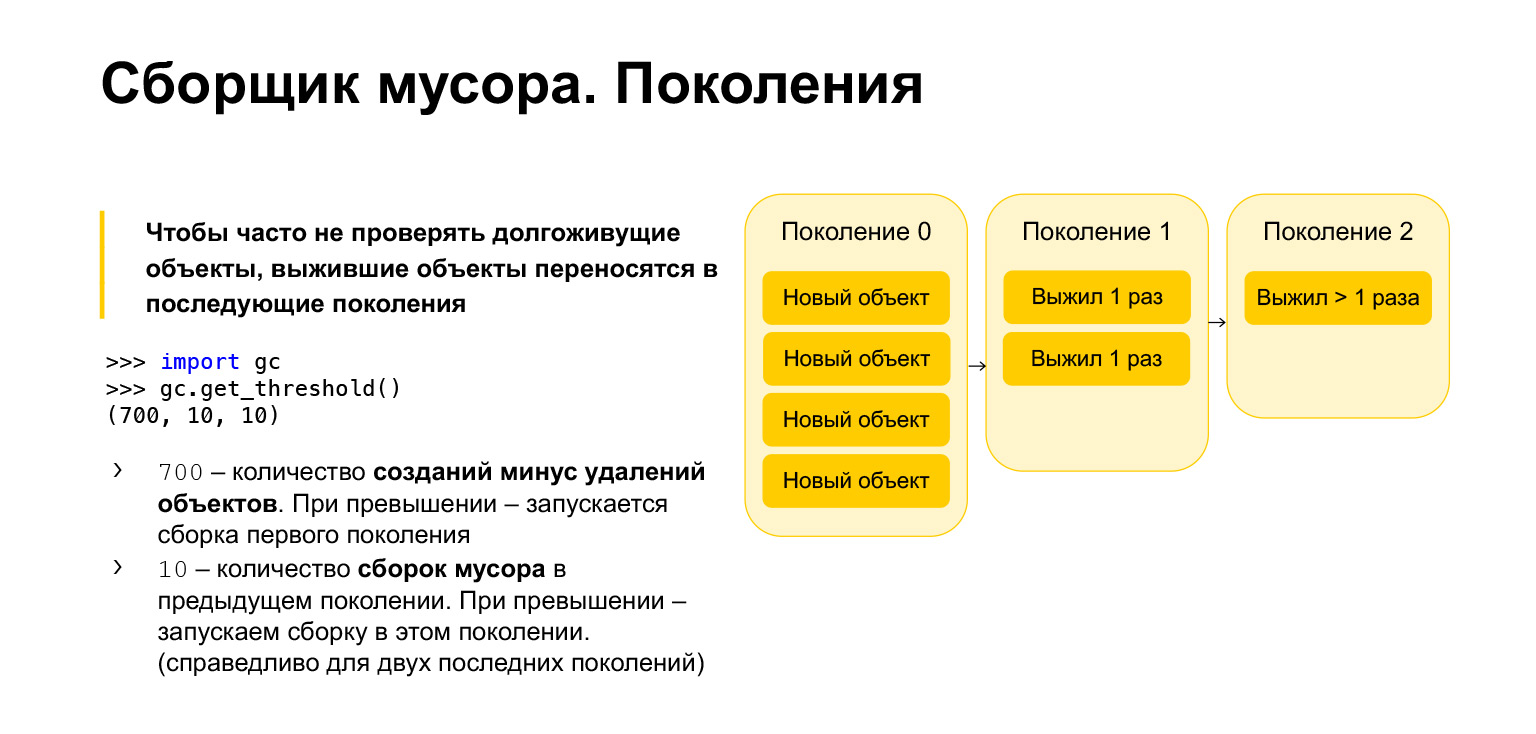
Para otimizar a velocidade do coletor de lixo em Python, ele é geracional, ou seja, funciona usando gerações. Existem três gerações. Para que eles são necessários? É claro que aqueles objetos que foram criados recentemente são mais prováveis de serem desnecessários do que objetos de vida longa. Digamos que você crie algo no decorrer das funções. Provavelmente, não será necessário ao sair da função. É o mesmo com loops, com variáveis temporárias. Todos esses objetos precisam ser limpos com mais frequência do que aqueles que já existem há muito tempo.
Portanto, todos os novos objetos são colocados na geração zero. Esta geração é limpa periodicamente. Python possui três parâmetros. Cada geração tem seu próprio parâmetro. Você pode obtê-los, importar o coletor de lixo, chamar a função get_threshold e obter esses limites.
Por padrão, são 700, 10, 10. O que é 700? Este é o número de criação de objetos menos o número de exclusões. Assim que ultrapassar 700, uma coleta de lixo de nova geração é iniciada. E 10, 10 é o número de coletas de lixo na geração anterior, após o qual precisamos iniciar a coleta de lixo na geração atual.
Ou seja, quando limparmos a geração zero 10 vezes, iniciaremos a construção na primeira geração. Depois de limpar a primeira geração 10 vezes, iniciaremos a construção na segunda geração. Conseqüentemente, os objetos se movem de geração em geração. Se eles sobreviverem, eles passarão para a primeira geração. Se eles sobreviveram a uma coleta de lixo na primeira geração, eles serão movidos para a segunda. A partir da segunda geração, eles não se mudam mais para lugar nenhum, permanecem lá para sempre.
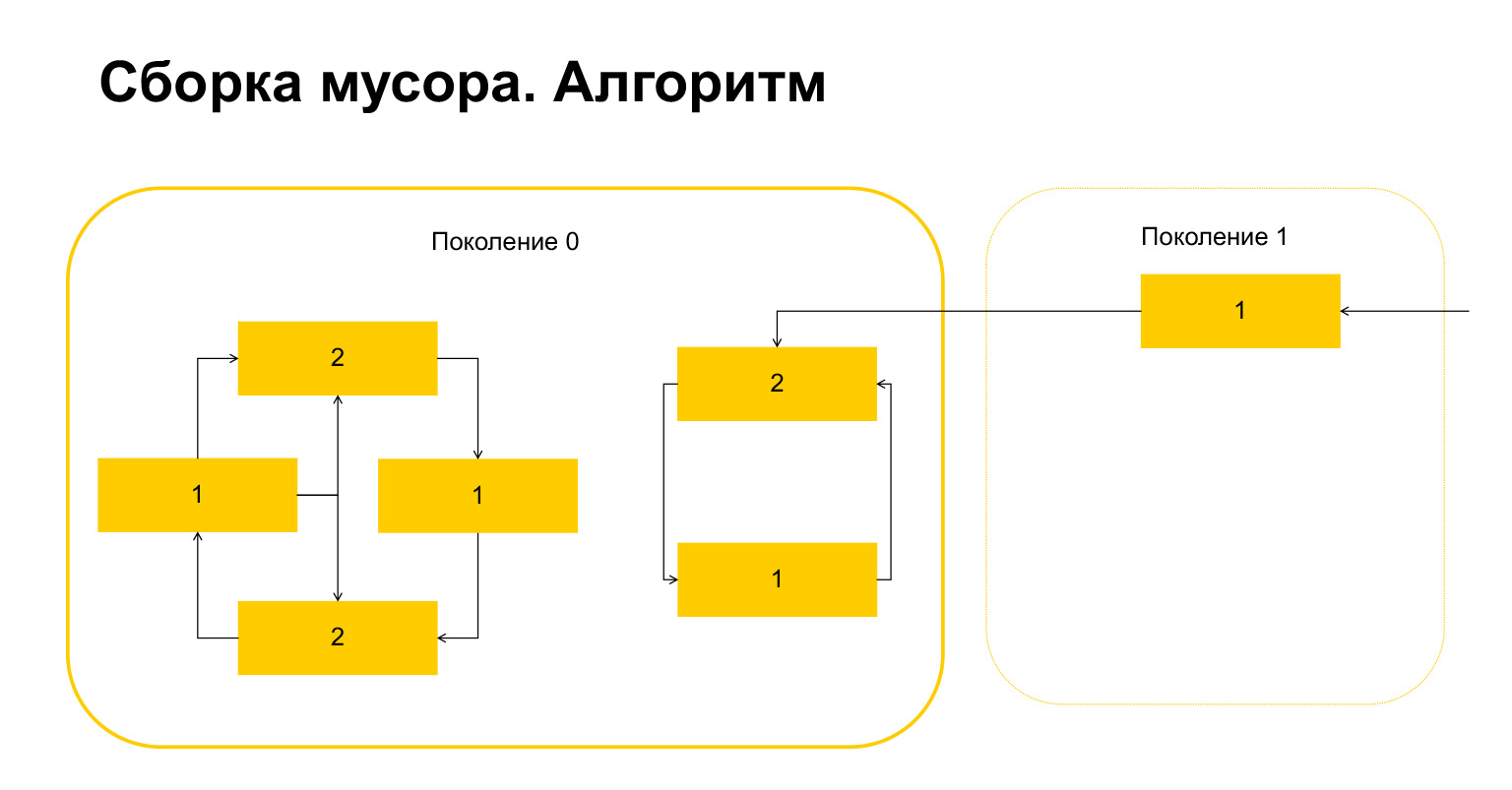
Como funciona a coleta de lixo em Python? Digamos que começamos a coleta de lixo na geração 0. Temos alguns objetos, eles têm ciclos. Há um grupo de objetos à esquerda que se referem um ao outro e o grupo à direita também se refere um ao outro. Um detalhe importante - eles também são referenciados na geração 1. Como o Python detecta loops? Primeiro, uma variável temporária é criada para cada objeto e o número de referências a este objeto é escrito nela. Isso se reflete no slide. Temos dois links para o objeto no topo. Um objeto da geração 1, no entanto, está sendo referenciado de fora. Python se lembra disso. Então (importante!) Ele passa por cada objeto dentro da geração e exclui, diminui o contador pelo número de referências dentro desta geração.
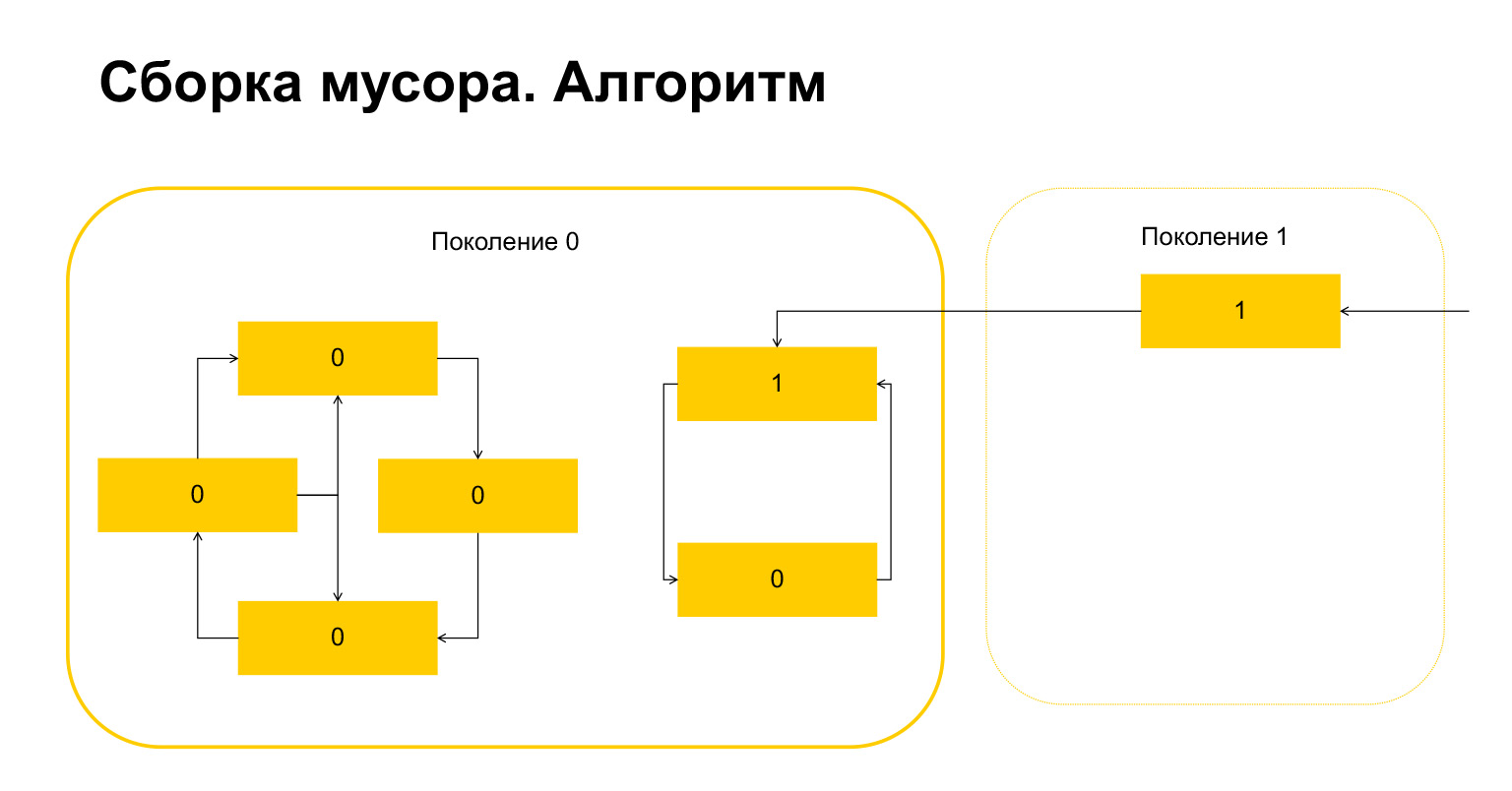
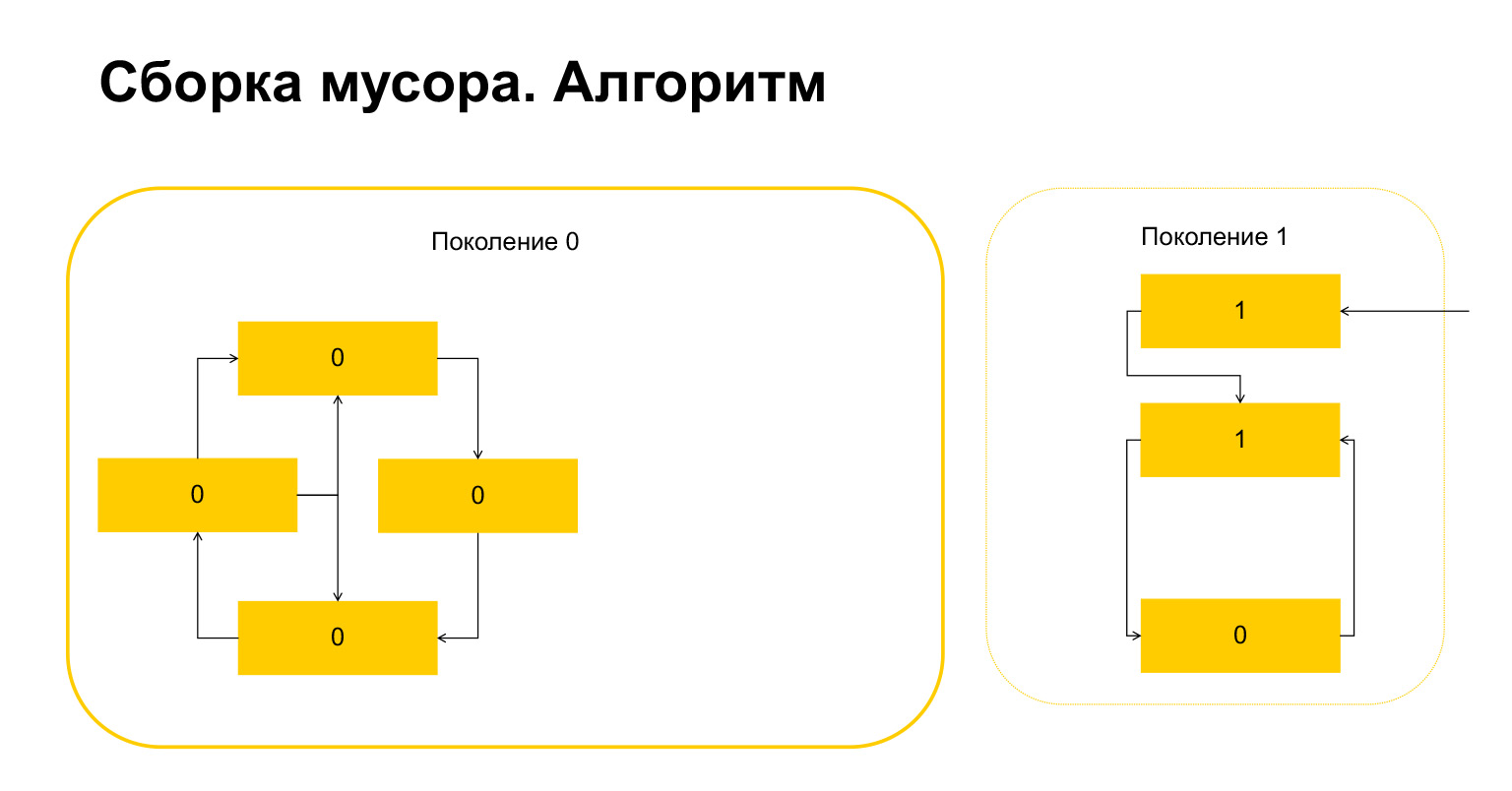
Aqui está o que aconteceu. Para objetos que se referem apenas uns aos outros dentro de uma geração, esta variável tornou-se automaticamente igual a zero por construção. Apenas os objetos referenciados de fora têm uma unidade.
O que o Python faz a seguir? Ele, por haver um aqui, entende que esses objetos são referenciados de fora. E não podemos deletar nem este objeto nem este, senão acabaremos com uma situação inválida. Portanto, Python transfere esses objetos para a geração 1, e tudo o que resta na geração 0, ele apaga, limpa. Tudo sobre o coletor de lixo.
(...) Ir em frente. Vou falar brevemente sobre geradores.
Geradores

Infelizmente, não haverá introdução aos geradores aqui, mas vamos tentar dizer o que é um gerador. Este é um tipo de função, relativamente falando, que lembra o contexto de sua execução usando a palavra yield. Nesse ponto, ele retorna um valor e lembra do contexto. Você pode então consultá-lo novamente e obter o valor que ele fornece.
O que você pode fazer com geradores? Você pode produzir um gerador, ele retornará valores para você, lembre-se do contexto. Você pode voltar para o gerador. Neste caso, será lançada a execução de StopIteration, o valor dentro do qual conterá o valor, neste caso Y.
Fato menos conhecido: Você pode enviar alguns valores para o gerador. Ou seja, você chama o método send no gerador e Z - veja o exemplo - será o valor da expressão de rendimento que o gerador invocará. Se você quiser controlar o gerador, pode passar valores para lá.
Você também pode lançar exceções lá. A mesma coisa: pegue um objeto gerador e jogue-o. Você joga um erro aí. Você terá um erro no lugar do último rendimento. E fechar - você pode fechar o gerador. Em seguida, a execução do GeneratorExit é gerada e o gerador não deve produzir mais nada.

Aqui, eu só queria falar sobre como funciona no CPython. Na verdade, você tem um quadro de execução em seu gerador. E, como lembramos, FrameObject contém todo o contexto. A partir disso, parece claro como o contexto é preservado. Ou seja, você só tem um quadro no gerador.

Quando você executa uma função de gerador, como Python sabe que você não precisa executá-la, mas criar um gerador? O CodeObject que examinamos tem sinalizadores. E quando você chama uma função, o Python verifica seus sinalizadores. Se o flag CO_GENERATOR estiver presente, ele entende que a função não precisa ser executada, mas apenas criar um gerador. E ele o cria. Função PyGen_NewWithQualName.

Como está indo a execução? De GENERATOR_FUNCTION, o gerador primeiro chama GENERATOR_Object. Então você pode chamar GENERATOR_Object usando next para obter o próximo valor. Como acontece a próxima ligação? Seu frame é retirado do gerador, é armazenado na variável F. E enviado ao loop principal do interpretador EvalFrameEx. Você é executado como no caso de uma função normal. O mapcode YIELD_VALUE é usado para retornar, pausar a execução do gerador. Ele se lembra de todo o contexto no quadro e para de executar. Este foi o penúltimo tópico.
(...) Uma rápida recapitulação do que são exceções e como são usadas em Python.
Exceções

As exceções são uma forma de lidar com situações de erro. Temos um bloco de teste. Podemos escrever em try aquelas coisas que podem lançar exceções. Digamos que possamos gerar um erro usando a palavra raise. Com a ajuda de except podemos capturar certos tipos de exceções, neste caso SomeError. Com exceto, capturamos todas as exceções sem expressão. O bloco else é usado com menos frequência, mas existe e só será executado se nenhuma exceção for lançada. O bloco finally será executado de qualquer maneira.
Como as exceções funcionam no CPython? Além da pilha de execução, cada quadro também possui uma pilha de blocos. É melhor usar um exemplo.


Uma pilha de blocos é uma pilha na qual os blocos são gravados. Cada bloco possui um tipo, Handler, um manipulador. Handler é o endereço de bytecode para o qual saltar para processar este bloco. Como funciona? Digamos que temos algum código. Fizemos um bloco try, temos um bloco except no qual capturamos exceções RuntimeError, e um bloco finally, que deve ser em qualquer caso.
Tudo isso degenera neste bytecode. Bem no início do bytecode no bloco try, vemos dois opcode SETUP_FINALLY com argumentos para 40 e para 12. Esses são os endereços dos manipuladores. Quando SETUP_FINALLY é executado, um bloco é colocado na pilha de blocos, que diz: para me processar, vá em um caso para o 40º endereço, no outro para o 12º.
12 abaixo da pilha está except, a linha que contém o else RuntimeError. Isso significa que quando tivermos uma exceção, vamos olhar a pilha de blocos em busca de um bloco do tipo SETUP_FINALLY. Encontre o bloco em que há uma transição para o endereço 12, vá lá. E aí temos uma comparação da exceção com o tipo: verificamos se o tipo da exceção é RuntimeError ou não. Se for igual, nós o executamos, se não, saltamos para outro lugar.
FINALMENTE é o próximo bloco na pilha de blocos. Ele será executado para nós se houver alguma outra exceção. Em seguida, a pesquisa continuará nesta pilha de blocos, e chegaremos ao próximo bloco SETUP_FINALLY. Haverá um manipulador que nos informará, por exemplo, o endereço 40. Pulamos para o endereço 40 - você pode ver no código que este é um bloco finally.

Funciona de forma muito simples em CPython. Temos todas as funções que podem gerar exceções para retornar um código de valor. Se tudo correr bem, retorna 0. Se for um erro, -1 ou NULL é retornado, dependendo do tipo de função.
Considere uma barra lateral em C. Vemos como ocorre a divisão. E há uma verificação de que se B é igual a zero e não queremos dividir por zero, então lembramos da exceção e retornamos NULL. Isso significa que houve um erro. Portanto, todas as outras funções superiores na pilha de chamadas também devem gerar NULL. Veremos isso no loop principal do interpretador e pularemos aqui.

Isso é desenrolar da pilha. Está tudo como eu disse: percorremos toda a pilha de blocos e verificamos se seu tipo é SETUP_FINALLY. Em caso afirmativo, pule em Handler, muito simples. Isso, na verdade, é tudo.
Links
Intérprete geral:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
Memory Management:
arctrix.com/nas/python/gc
rushter.com/blog/python -memory-managment
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
Exceções:
bugs.python.org/issue17611