
Os custos de armazenamento de dados freqüentemente se tornam o principal item de custo ao criar um sistema de vigilância por vídeo. No entanto, eles seriam incomparavelmente maiores se não houvesse algoritmos no mundo capazes de comprimir um sinal de vídeo. No artigo de hoje, falaremos sobre a eficácia dos codecs modernos e quais princípios fundamentam seu trabalho.
Vamos começar com números para maior clareza. Deixe o vídeo ser gravado continuamente, em resolução Full HD (agora esse é o mínimo necessário, pelo menos se você quiser usar totalmente as funções de análise de vídeo) e em tempo real (ou seja, com uma taxa de quadros de 25 quadros por segundo). Vamos supor também que o hardware de nossa escolha suporte a codificação de hardware H.265. Neste caso, com diferentes configurações de qualidade de imagem (alta, média e baixa), obteremos aproximadamente os seguintes resultados.
Codec |
Intensidade de movimento no quadro |
Uso de espaço em disco por dia, GB |
H.265 (alta qualidade) |
Alto |
138 |
H.265 (alta qualidade) |
Média |
67 |
H.265 (alta qualidade) |
Baixo |
41 |
H.265 (qualidade média) |
Alto |
86 |
H.265 (qualidade média) |
Média |
42 |
H.265 (qualidade média) |
Baixo |
26 |
H.265 (baixa qualidade) |
Alto |
81 |
H.265 (baixa qualidade) |
Média |
39 |
H.265 (baixa qualidade) |
Baixo |
24 |
Mas se a compressão de vídeo não existisse em princípio, veríamos números completamente diferentes. Vamos tentar descobrir o porquê. Um fluxo de vídeo nada mais é do que uma sequência de imagens estáticas (quadros) em uma determinada resolução. Tecnicamente, cada quadro é uma matriz bidimensional contendo informações sobre as unidades elementares (pixels) que formam a imagem. TrueColor requer 3 bytes para codificar cada pixel. Assim, no exemplo dado, teríamos uma taxa de bits:
1920 × 1080 × 25 × 3/1048576 = ~ 148 Mb / s
Considerando que há 86400 segundos em um dia, os números saem verdadeiramente astronômicos:
148 × 86400/1024 = 12487 GB
Portanto, se gravássemos um vídeo sem compressão com qualidade máxima nas condições dadas, precisaríamos de 12 terabytes de espaço em disco para armazenar os dados recebidos de uma única câmera de vídeo durante o dia. Mas mesmo o sistema de segurança de um apartamento ou pequeno escritório pressupõe a presença de pelo menos dois dispositivos de gravação de vídeo, enquanto o próprio arquivo deve ser mantido por várias semanas ou até meses, se exigido por lei. Ou seja, para atender a qualquer objeto, mesmo de tamanho muito modesto, seria necessário um data center inteiro!
Felizmente, os algoritmos modernos de compressão de vídeo podem economizar significativamente o espaço em disco: por exemplo, usar o codec H.265 pode reduzir o tamanho do vídeo em 90 (!) Vezes. Resultados tão impressionantes foram alcançados graças a um conjunto de várias tecnologias que têm sido usadas com sucesso não só no campo da vigilância por vídeo, mas também no setor "civil": em sistemas de televisão analógica e digital, em filmagens amadoras e profissionais e muitas outras situações.
O exemplo mais simples e óbvio é a subamostragem de cores. Este é o nome de um método de codificação de vídeo em que a resolução de cor dos quadros é deliberadamente reduzida e a taxa de amostragem dos sinais de diferença de cor torna-se menor do que a frequência de amostragem do sinal de luminância. Este método de compressão de dados de vídeo é totalmente justificado do ponto de vista da fisiologia humana e do ponto de vista da aplicação prática no campo da gravação de vídeo. Nossos olhos são bons em perceber a diferença no brilho, mas são muito menos sensíveis às mudanças de cor, e é por isso que a amostragem dos sinais de diferença de cor pode ser sacrificada, porque a maioria das pessoas simplesmente não notará isso. Ao mesmo tempo, é difícil imaginar como um carro da cor de uma "aranha tramando um crime" é anunciado na lista de procurados: a orientação dirá "cinza escuro", e isso é correto, porque caso contrário a pessoa que leu a descrição do carro nem mesmo entenderá.de que tonalidade estamos falando.
Mas com uma diminuição nos detalhes, tudo acaba sendo completamente diferente. Tecnicamente, a quantização (ou seja, dividir a faixa do sinal em vários níveis e, em seguida, trazê-los para os valores especificados) funciona muito bem: usando este método, o tamanho do vídeo pode ser reduzido muitas vezes. Mas assim podemos perder detalhes importantes (por exemplo, o número de um carro que passa ao longe ou as características faciais de um intruso): eles ficarão borrados e tal registro será inútil para nós. Como proceder nesta situação? A resposta é simples, como tudo que é engenhoso: uma vez que você toma os objetos dinâmicos como ponto de partida, tudo imediatamente se ajusta. Este princípio tem sido usado com sucesso desde o surgimento do codec H.264 e provou ser excelente, abrindo uma série de possibilidades adicionais para compressão de dados.
Era previsível: descobrir como o H.264 compacta o vídeo
Voltemos à mesa com a qual começamos. Como você pode ver, além de parâmetros como resolução, taxa de quadros e qualidade da imagem, o fator decisivo que determina o tamanho final do vídeo é o nível de dinamismo da cena sendo filmada. Isso se deve às peculiaridades do trabalho dos codecs de vídeo modernos em geral, e do H.264 em particular: o mecanismo de previsão de quadros usado nele permite compactar vídeo adicionalmente, sem praticamente sacrificar a qualidade da imagem. Vamos ver como isso funciona.
O codec H.264 usa vários tipos de quadros:
- I-frames (do inglês Intra-coded frames, eles também são chamados de chave ou chave) - contêm informações sobre objetos estáticos que não mudam por um longo tempo.
- P- (Predicted frames, , ) — , , I-.
- B- (Bi-predicted frames, ) — P-, I-, P- B-, , .
O que isto significa? No codec H.264, a construção da imagem de vídeo é a seguinte: a câmera faz um quadro de referência (I-frame) e com base (por isso é chamado de quadro de referência) subtrai as partes fixas da imagem do quadro. Isso cria um P-frame. Em seguida, o terceiro é subtraído deste segundo quadro e um quadro P modificado também é criado. Isso cria uma série de quadros diferenciais que contêm apenas alterações entre dois quadros sucessivos. Como resultado, obtemos a seguinte cadeia:
[INÍCIO DA CAPTURA] IPPPPPPPPPPPPP- ...
Visto que no processo de subtração, erros são possíveis que levam ao aparecimento de artefatos gráficos, então após um certo número de quadros o esquema é repetido: um quadro-chave é formado novamente, seguido por uma série quadros com mudanças.
… -PPPPPPPIPPPPPPP ... A
imagem completa é formada pela "sobreposição" de quadros P no quadro de referência. Ao mesmo tempo, torna-se possível processar de forma independente o fundo e os objetos em movimento, o que permite ainda economizar espaço em disco sem o risco de perder detalhes importantes (características faciais, placas de carro, etc.). No caso de objetos que executam movimentos monótonos (por exemplo, rodas giratórias de carros), os mesmos quadros de diferença podem ser usados repetidamente.
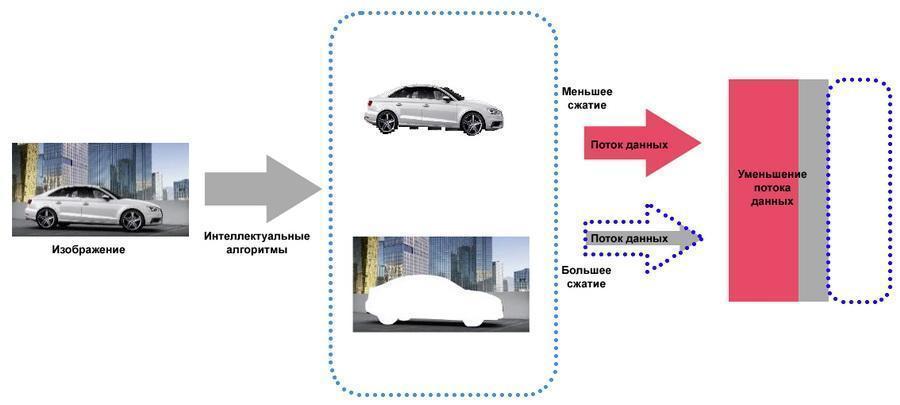
O processamento independente de objetos estáticos e dinâmicos economiza espaço em disco.
Esse mecanismo é chamado de compactação entre quadros. Os quadros previstos são formados com base na análise de uma ampla amostra de estados de cena fixos: o algoritmo prevê onde este ou aquele objeto se moverá no campo de visão da câmera, o que pode reduzir significativamente a quantidade de dados gravados ao observar, por exemplo, a estrada.
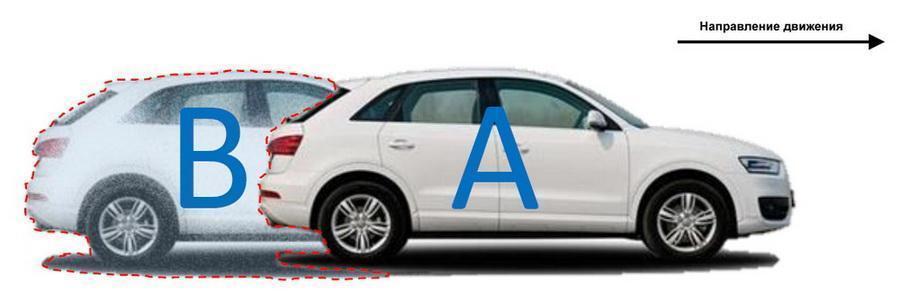
O codec forma frames, prevendo para onde o objeto se moverá. Por
sua vez, o uso de frames preditos bidirecionais permite várias vezes reduzir o tempo de acesso a cada frame do stream, já que bastará descompactar apenas três frames para recebê-lo: B contendo links, e I e o P a que se refere. Neste caso, a sequência de quadros pode ser representada como segue.
[INICIAR CAPTURA] IBPBPBPBPBPBPBPBP-…
Esta abordagem pode aumentar significativamente a velocidade de avanço rápido e mostrar e simplificar o trabalho com o arquivo de vídeo.
Qual é a diferença entre H.264 e H.265?

O H.265 usa todos os mesmos princípios de compressão do H.264: a imagem de fundo é salva uma vez e, então, apenas as alterações originadas dos objetos em movimento são gravadas, o que reduz significativamente os requisitos não apenas de armazenamento, mas também de largura de banda recursos de rede. No entanto, no H.265, muitos algoritmos e métodos de previsão de movimento passaram por mudanças qualitativas significativas.
Assim, a versão atualizada do codec passou a utilizar macroblocos de uma árvore de codificação (Coding Tree Unit, CTU) de tamanho variável com resolução de até 64 × 64 pixels, enquanto anteriormente o tamanho máximo desse bloco era de apenas 16 × 16 pixels. Isso tornou possível melhorar significativamente a precisão da extração de blocos dinâmicos, bem como a eficiência do processamento de quadros em resolução 4K e superior.
Além disso, o H.265 possui um filtro de desbloqueio aprimorado - filtro responsável por suavizar as bordas dos blocos, necessário para eliminar artefatos ao longo da linha de sua união. Finalmente, o algoritmo Motion Vector Predictor (MVP) aprimorado ajudou a reduzir significativamente o volume do vídeo devido a um aumento radical na precisão das previsões ao codificar objetos em movimento, que foi alcançado aumentando o número de direções rastreadas: se anteriormente apenas 8 vetores fossem levados em consideração, agora - 36
Além de todos os itens acima, o H.265 melhorou o suporte para multithreading: as áreas quadradas nas quais cada quadro é dividido durante a codificação agora podem ser processadas independentemente umas das outras. Também há suporte para Wavefront Parallelel Processing (WPP), que também melhora o desempenho da compressão. Quando o modo WPP é ativado, o processamento da CTU é realizado linha por linha, da esquerda para a direita, porém, a codificação de cada linha subsequente pode começar antes mesmo da finalização da anterior, se os dados recebidos das CTUs previamente processadas forem suficientes para isso. Codificação de atraso de tempo de mudança de várias strings CTU,Junto com o suporte para o conjunto estendido de instruções AVX / AVX2, ele pode aumentar ainda mais a velocidade de processamento de fluxos de vídeo em sistemas multi-core e multi-processador.
Cartões flash de vigilância: quando o tamanho não é a única coisa
E novamente, vamos voltar ao prato com o qual começamos nossa conversa hoje. Vamos calcular quanto espaço em disco precisamos se quisermos armazenar um arquivo de vídeo nos últimos 30 dias com qualidade máxima de vídeo:
138 × 30/1024 = 4
Pelos padrões de hoje, 4 terabytes para um disco rígido de nível industrial é praticamente nada: discos rígidos modernos são para a vigilância por vídeo tem capacidade de até 14 terabytes e possui um recurso de trabalho de até 360 TB por ano com MTBF de até 1,5 milhão de horas. Quanto aos cartões de memória, nem tudo é tão simples aqui.
Em câmeras IP, os cartões flash desempenham o papel de armazenamentos de backup: os dados neles são constantemente sobrescritos para que, em caso de perda de conexão com o servidor de vídeo, o fragmento de vídeo ausente possa ser restaurado de uma cópia local. Essa abordagem pode aumentar significativamente a tolerância a falhas de todo o sistema de segurança, mas, ao mesmo tempo, os próprios cartões de memória estão sob grande pressão.
Como você pode ver em nossa tabela, mesmo com baixa qualidade de imagem e com atividade mínima no quadro, cerca de 24 GB de vídeo serão gravados em apenas um dia. Isso significa que um cartão de 128 GB será completamente substituído em menos de uma semana. Se precisarmos obter imagens da mais alta qualidade, todos os dados nesse meio serão totalmente atualizados uma vez por dia! E isso é apenas em resolução Full HD. E se precisarmos de uma imagem em 4K? Nesse caso, a carga quase dobrará (nas condições fornecidas, o vídeo em qualidade máxima exigirá 250 GB).
No uso diário, isso é simplesmente impossível, então mesmo o cartão de memória mais econômico pode atendê-lo por vários anos consecutivos sem uma única falha. E tudo graças aos algoritmos de nivelamento de desgaste. Seu trabalho pode ser descrito esquematicamente da seguinte maneira. Vamos ter um cartão de memória novo, recém-saído da loja. Gravamos vários vídeos nele, usando 7 de 16 gigabytes. Depois de um tempo, excluímos alguns dos vídeos desnecessários, liberando 3 gigabytes, e gravamos novos, cujo volume era de 2 GB. Parece que você pode usar o espaço que acabou de ser liberado, mas o mecanismo de nivelamento de desgaste alocará para novos dados aquela parte da memória que nunca foi usada antes. Embora os controladores modernos "embaralhem" bits e bytes de uma maneira muito mais sofisticada, o princípio geral permanece o mesmo.
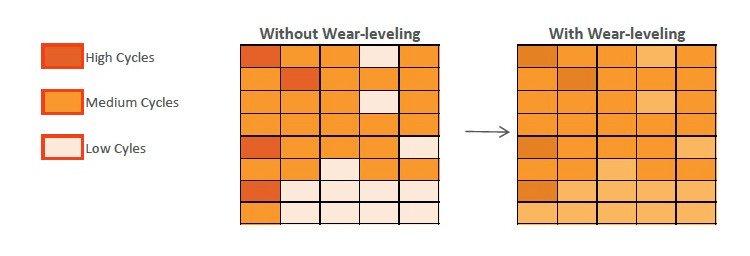
Lembre-se de que a codificação de bits de informação ocorre pela mudança da carga nas células de memória devido ao tunelamento quântico de elétrons através da camada dielétrica, que causa desgaste gradual das camadas dielétricas com subsequente vazamento de carga. E quanto mais frequentemente a carga muda em uma célula particular, mais cedo ela irá falhar. O nível de desgaste visa precisamente garantir que cada uma das células disponíveis seja sobrescrita aproximadamente o mesmo número de vezes e, assim, ajuda a aumentar a vida útil do cartão de memória.
É fácil adivinhar que o nivelamento de desgaste deixa de desempenhar qualquer papel significativo no caso de o cartão flash ser constantemente reescrito inteiramente: aqui, a resistência dos próprios chips vem à tona. O critério mais objetivo para avaliar este último é o número máximo de ciclos de programar / apagar, ou, em resumo, ciclos de P / E, que a memória flash pode suportar. Além disso, o coeficiente TBW (Terabytes Gravados) é bastante preciso e, neste caso, ilustrativo (já que podemos calcular os volumes de reescrita com antecedência). Se apenas um dos indicadores listados for indicado nas características técnicas, então não será difícil calcular o outro. É suficiente usar a seguinte fórmula:
TBW = (Capacidade × Número de ciclos P / E) / 1000
Assim, por exemplo, TBW de um cartão flash com capacidade de 128 gigabytes, cujo recurso é 200 P / E, será: (128 × 200) / 1000 = 25,6 TBW.
Vamos contar. A durabilidade dos cartões de memória de consumo é de 100-300 P / E e 300 está no seu melhor. Com base nesses números, podemos estimar sua vida útil com uma precisão bastante alta. Vamos usar a fórmula e preencher uma nova tabela para um cartão de memória de 128 GB. Vamos pegar a qualidade máxima da imagem em Full HD como diretriz, ou seja, a câmera vai gravar 138 GB de vídeo por dia, como descobrimos antes.
Recurso do cartão de memória, ciclos P / E |
TBW |
MTBF |
100 |
12,8 |
3 meses |
200 |
25,6 |
6 meses |
300 |
38,4 |
1 ano |
Quer usar cartões de 64 GB ou gravar vídeos em 4K? Sinta-se à vontade para dividir o tempo calculado por dois: em média, os cartões de memória do consumidor terão que ser trocados a cada seis meses e em cada câmera. Ou seja, a cada 6 meses você terá que adquirir um novo lote de cartões flash, incorrer em custos adicionais de manutenção e, claro, colocar em risco o objeto protegido, uma vez que as câmeras terão que ser retiradas de serviço durante a substituição.
Finalmente, mais um ponto ao qual você deve prestar atenção ao escolher um cartão de memória são as características de velocidade. Na descrição de quase todos os cartões flash modernos, você pode encontrar uma entrada do formulário: “Desempenho: até 100 MB / s na leitura, até 90 MB / s na escrita; gravação de vídeo: C10, U1, V10 ". Aqui, C10 e U1 significam nada mais do que uma classe de velocidade de gravação de vídeo, e se você olhar os materiais de referência, então as classes C10, U1 e V10 correspondem a 10 MB / s. De onde vem a diferença de 9 vezes e por que a marcação é tripla? Na verdade, tudo é muito simples.
No exemplo considerado, 100 e 90 MB / s são as velocidades nominais, ou seja, o desempenho máximo alcançável do cartão em operações sequenciais de leitura e escrita, desde que seja utilizado com hardware compatível, que por sua vez tenha desempenho suficiente. C10, U1 e V1 (10 MB / s) são as taxas mínimas de transferência de dados sustentadas nas piores condições de teste. Este parâmetro deve ser levado em consideração na escolha de cartões para câmeras de CFTV pela simples razão de que se for menor que a taxa de bits do stream de vídeo, é carregado com o aparecimento de artefatos gráficos na gravação e até mesmo a perda de frames inteiros. Obviamente, no caso de sistemas de segurança, isso é inaceitável: quaisquer defeitos na imagem são carregados com a perda de dados críticos - por exemplo, evidências que poderiam ajudar a capturar um intruso.
Quanto à presença de três marcações ao mesmo tempo, as razões para isso são puramente históricas. C10 pertence às primeiras classificações criadas pela SD Card Association, que foi compilada em 2006, tendo recebido o nome simples e descomplicado de Speed Class. O surgimento da classificação UHS Speed Class, indicada pela marcação U1, está associada à criação da interface Ultra High Speed, que hoje é usada na grande maioria dos cartões flash. Por fim, a última classificação, Video Speed Class (V1), foi desenvolvida pela SD Card Association em 2016 em conexão com a proliferação de dispositivos que suportam gravação de vídeo de ultra-alta definição (4K, 8K e 3D).
Como as classificações listadas se sobrepõem parcialmente, preparamos uma tabela comparativa para você, na qual as características de velocidade dos cartões de memória flash são comparadas entre si e correlacionadas com vídeos de diferentes resoluções.
Classe de velocidade |
Classe de velocidade UHS |
Aula de velocidade de vídeo |
Velocidade mínima de gravação sustentada |
Resolução de vídeo |
C2 |
- |
- |
2 MB / s |
Gravação de vídeo de definição padrão (SD, 720 por 576 pixels) |
C4 |
- |
- |
4 MB / s |
Gravação de vídeo em alta definição (HD) incluindo Full HD (720p a 1080p / 1080i) |
C6 |
- |
V6 |
6 MB / s |
|
C10 |
U1 |
V10 |
10 MB / s |
Gravação de vídeo Full HD (1080p) a 60 quadros por segundo |
- |
U3 |
V30 |
30 MB / s |
Gravação de vídeo com resolução de até 4K e 60/120 fps |
- |
- |
V60 |
60 MB / s |
Grave arquivos de vídeo com resolução de 8K e taxa de quadros de 60/120 quadros por segundo |
- |
- |
V90 |
90 MB / s |
Deve-se ter em mente que as correspondências indicadas na tabela são relevantes para câmeras de vídeo amadoras, semi-profissionais e profissionais. Na indústria de vigilância por vídeo, onde a gravação em tempo real é realizada a uma taxa máxima de 25 quadros por segundo, e codecs H.264 e H.265 de alto desempenho são usados para compactar o stream de vídeo, usando codificação preditiva, na grande maioria dos casos, os cartões de memória correspondentes à classe U1 serão suficientes / V10, uma vez que a taxa de bits em tais condições quase nunca excede o limite de 10 MB / s.
Cartões microSD WD Purple para sistemas de vigilância

Levando em consideração todos os recursos acima, a Western Digital desenvolveu uma série especializada de cartões de memória microSD WD Purple, que atualmente inclui duas linhas de produtos: WD Purple QD102 e WD Purple SC QD312 Extreme Endurance. O primeiro incluiu quatro unidades que variam de 32 a 512 GB, o segundo - três modelos, para 64, 128 e 256 GB. Em comparação com as soluções para o consumidor, o WD Purple foi feito sob medida para os sistemas de vigilância por vídeo digital de hoje com vários aprimoramentos importantes.
A principal vantagem da série roxa é uma vida útil significativamente maior em comparação com os dispositivos domésticos: os cartões da linha QD102 podem suportar 1000 ciclos de programação / apagamento, enquanto o QD312 - já 3000 ciclos P / E, o que lhes permite estender sua vida útil muitas vezes, mesmo no modo de gravação 24 horas. e torna esses cartões ideais para uso em instalações especialmente protegidas, onde a gravação é realizada 24 horas por dia, 7 dias por semana. Por outro lado, a conformidade com UHS Speed Class 1 e Video Speed Class 10 permite que os cartões WD Purple sejam usados em câmeras de alta definição, inclusive para gravação em tempo real.
Além disso, os cartões de memória WD Purple têm vários outros recursos importantes que vale a pena mencionar:
- ( 1 ) ( -25°C +85°C) WD Purple , ;
- 5000 500 g ;
- , , .
Para maior clareza, preparamos uma tabela de comparação para você, que mostra as principais características dos cartões de memória WD Purple.
Series |
WD Purple QD102 |
WD Purple QD312 |
||||||
Volume, GB |
32 |
64 |
128 |
256 |
512 |
64 |
128 |
256 |
Formato- fator |
microSDHC |
microSDXC |
||||||
atuação |
Até 100 MB / s em operações de leitura sequencial, até 65 MB / s em operações de gravação sequencial |
|||||||
Classe de velocidade |
U1 / V10 |
|||||||
Recurso de registro (P / E) |
1000 |
3000 |
||||||
Recurso de gravação (TBW) |
32 |
64 |
128 |
256 |
512 |
192 |
384 |
768 |
Faixa de temperatura operacional |
-25 ° C a 85 ° C |
|||||||
garantia |
3 anos |
|||||||