Parte 2
Neste artigo, você aprenderá:
- Sobre o ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
- Sobre quais arquiteturas CNN existem:
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- Sobre quais problemas surgiram com as novas arquiteturas de rede, como eles foram resolvidos pelas subsequentes:
- problema de gradiente de desaparecimento
- problema de gradiente explodindo
ILSVRC
O Desafio de Reconhecimento Visual em Grande Escala da ImageNet é uma competição anual em que os pesquisadores comparam suas grades para detecção e classificação de objetos em fotografias.
Esta competição foi o ímpeto para o desenvolvimento de:
- Arquiteturas de rede neural
- métodos e práticas pessoais que são usados até hoje.
Este gráfico mostra como os algoritmos de classificação evoluíram ao longo do tempo:
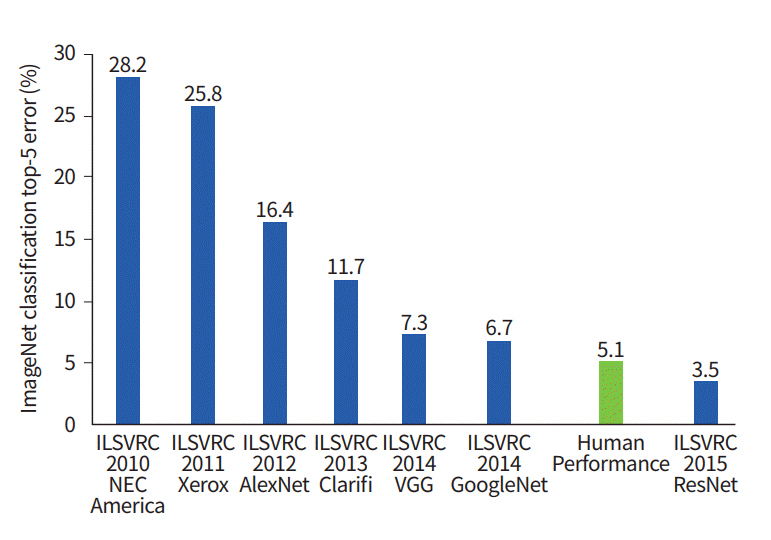
No eixo x - anos e algoritmos (desde 2012 - neural convolucional rede).
O eixo y é a porcentagem de erros na amostra dos 5 primeiros erros.
O erro 5 principais é uma forma de avaliar o modelo: o modelo retorna uma certa distribuição de probabilidade e se entre as 5 probabilidades principais houver um valor verdadeiro (rótulo de classe) da classe, então a resposta do modelo é considerada correta. Consequentemente, (1 - erro principal-1) é a precisão familiar.
Arquiteturas CNN
LeNet-5
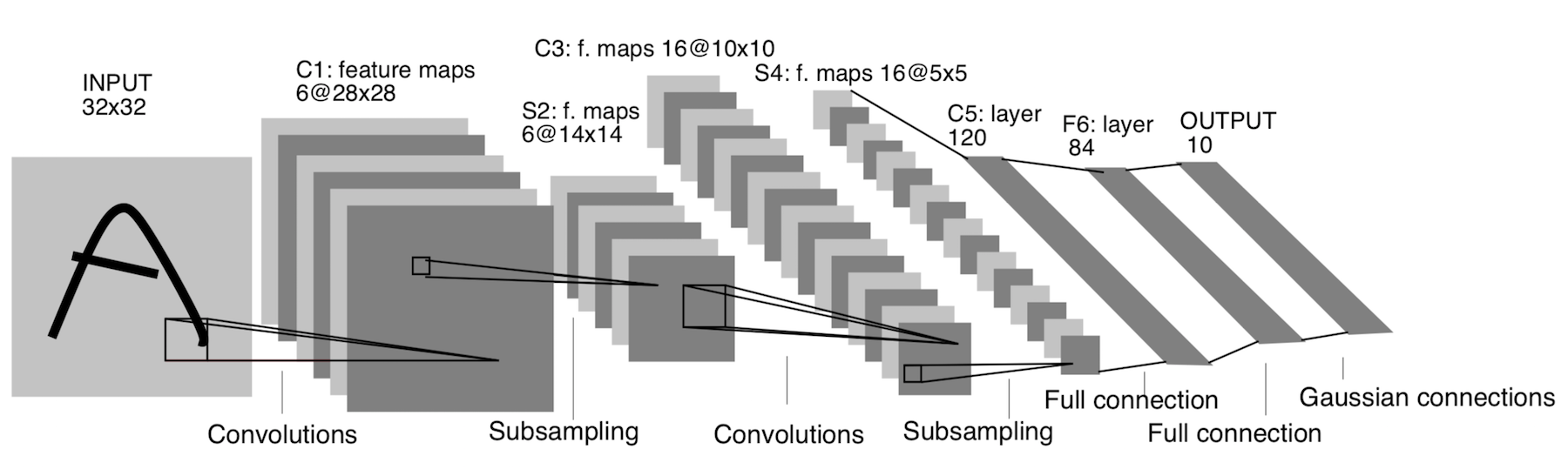
Já apareceu em 1998! Ele foi projetado para reconhecer letras e números escritos à mão. A subamostragem aqui se refere à camada de agrupamento.
Arquitetura:
CONV 5x5, passada = 1
POOL 2x2, passada = 2
CONV 5x5, passada = 1
POOL 5x5, passada = 2
FC (120, 84)
FC (84, 10)
Agora, esta arquitetura tem apenas significado histórico. Essa arquitetura é fácil de implementar manualmente em qualquer estrutura moderna de aprendizado profundo.
AlexNet

A imagem não está duplicada. É assim que a arquitetura é representada, porque a arquitetura AlexNet não cabia em um dispositivo de GPU naquela época, então "metade" da rede funcionava em uma GPU e a outra na outra.
Surgiu em 2012. Um avanço nesse mesmo ILSVRC começou com ela - ela derrotou todos os modelos de arte da época. Depois disso, as pessoas perceberam que as redes neurais realmente funcionam :)
Arquitetura mais especificamente:

Se você olhar atentamente para a arquitetura do AlexNet, verá que por 14 anos (desde o surgimento do LeNet-5) quase não houve mudanças, exceto pelo número de camadas.
Importante:
- Pegamos nossa imagem original de 227 x 227 x 3 e diminuímos sua dimensão (em altura e largura), mas aumentamos o número de canais. Esta parte da arquitetura "codifica" a representação original do objeto (codificador).
- ReLU. ReLu .
- 60 .
- .
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- Um registro como Conv 11x11s4, 96 significa que a camada de convolução tem um filtro 11x11xNc, passo = 4, o número de tais filtros é 96. Agora, o número de tais filtros é o número de canais para a próxima camada (o mesmo Nc). Assumimos que a imagem inicial possui três canais (R, G e B).
VGGNet
Arquitetura:
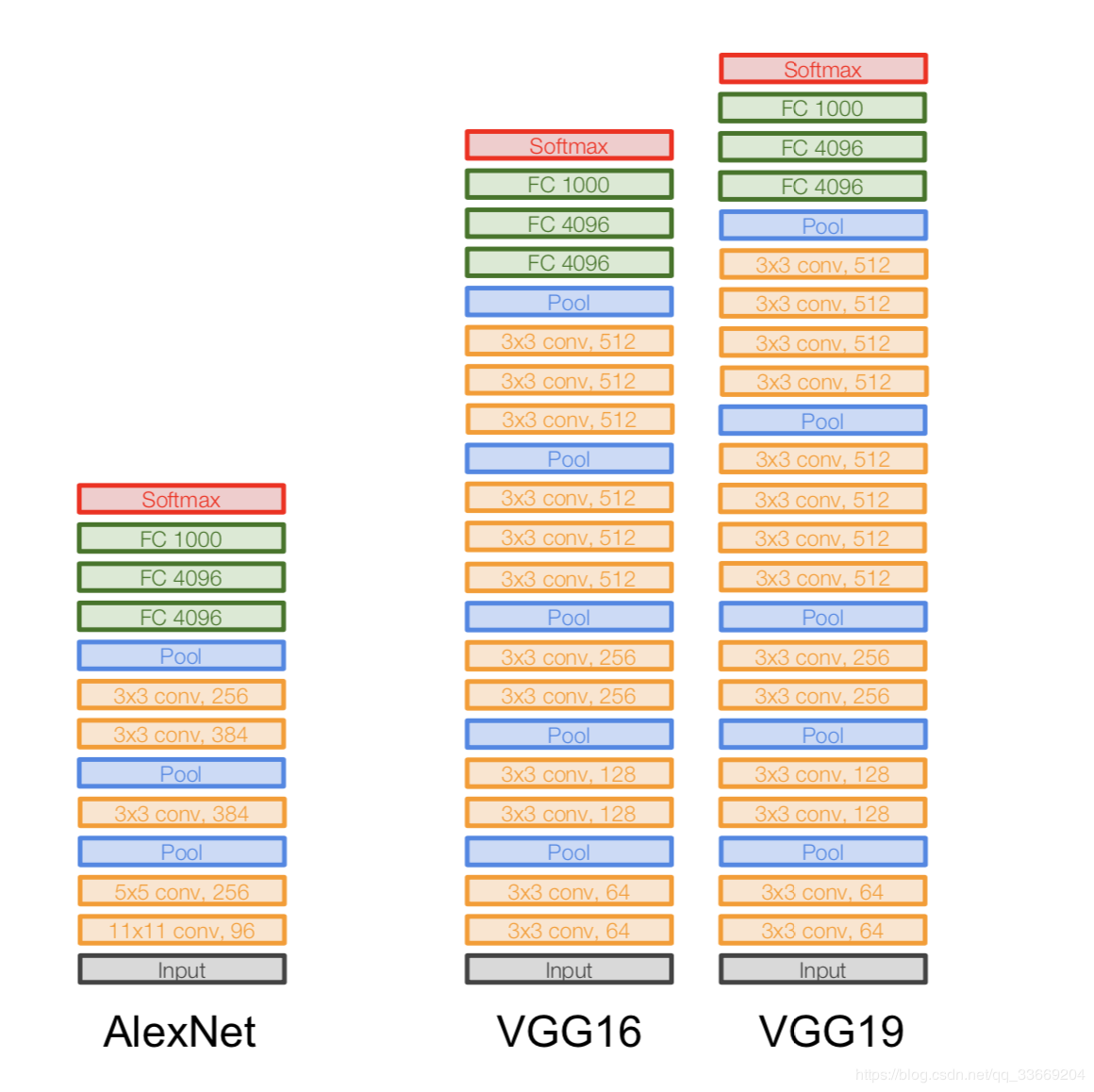
introduzida em 2014.
Duas versões - VGG16 e VGG19. A ideia principal é usar pequenos (3x3) em vez de grandes (11x11 e 5x5). A intuição para usar grandes convoluções é simples - queremos obter mais informações dos pixels vizinhos, mas é muito melhor usar filtros pequenos com mais frequência .
E é por causa disso:
- . , . .. , , .
- => .
- — , — , — , .
Importante:
- Ao treinar uma rede neural para um algoritmo de retropropagação de erro, é importante preservar as representações do objeto (para nós, a imagem original) em todos os estágios (convoluções, pools) de propagação direta (passagem para frente é quando alimentamos a imagem para a entrada e passamos para a saída ao resultado). Essa representação de um objeto pode ser cara em termos de memória. Dê uma olhada:
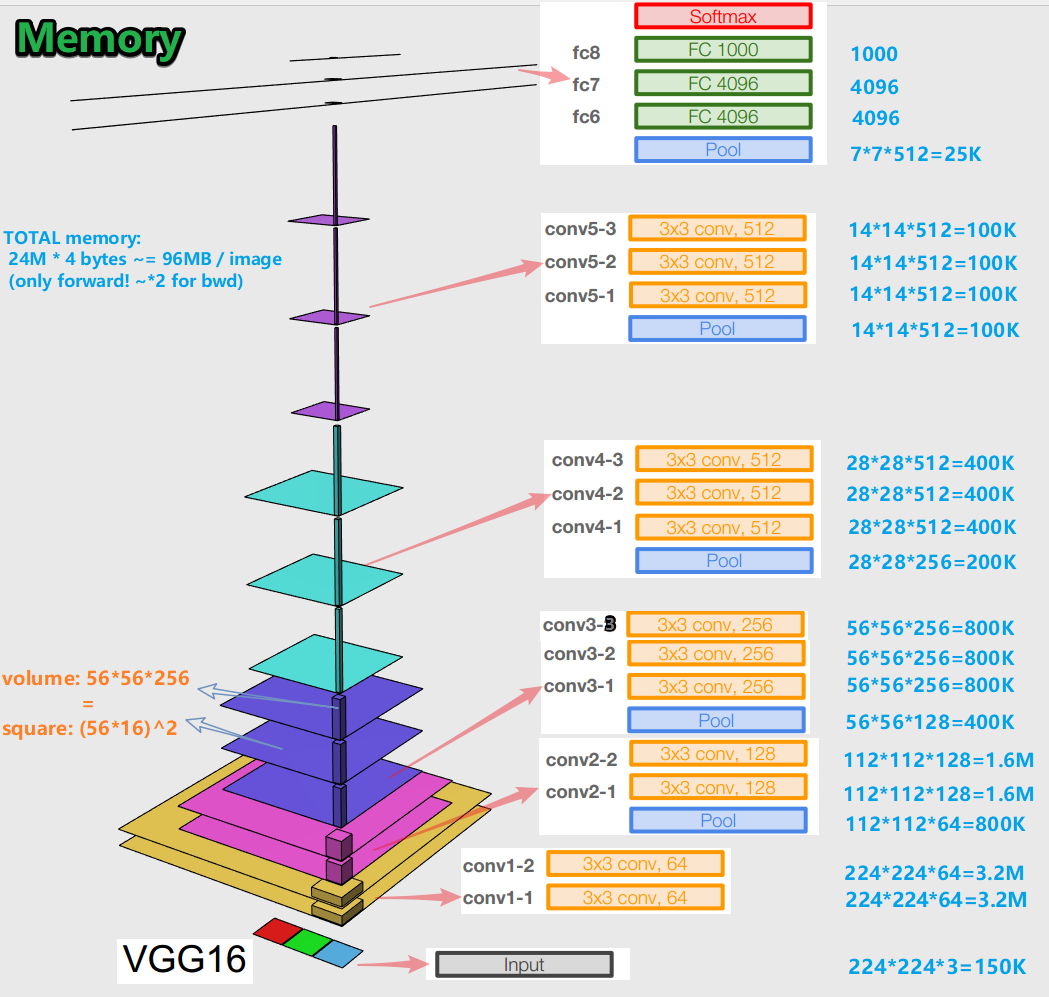
Acontece cerca de 96 MB por imagem - e isso é apenas para a passagem para frente. Para a passagem para trás (bwd na imagem) - enquanto calcula gradientes - cerca de duas vezes mais. Surge uma imagem interessante: o maior número de parâmetros treinados está localizado em camadas totalmente conectadas, e a maior memória é ocupada por representações de objetos após camadas convolucionais e agrupadas . C - sinergia.
- A rede tem 138 milhões de parâmetros de aprendizagem em variação de 16 camadas e 143 milhões de parâmetros em variação de 19 camadas.
GoogLeNet
Arquitetura:
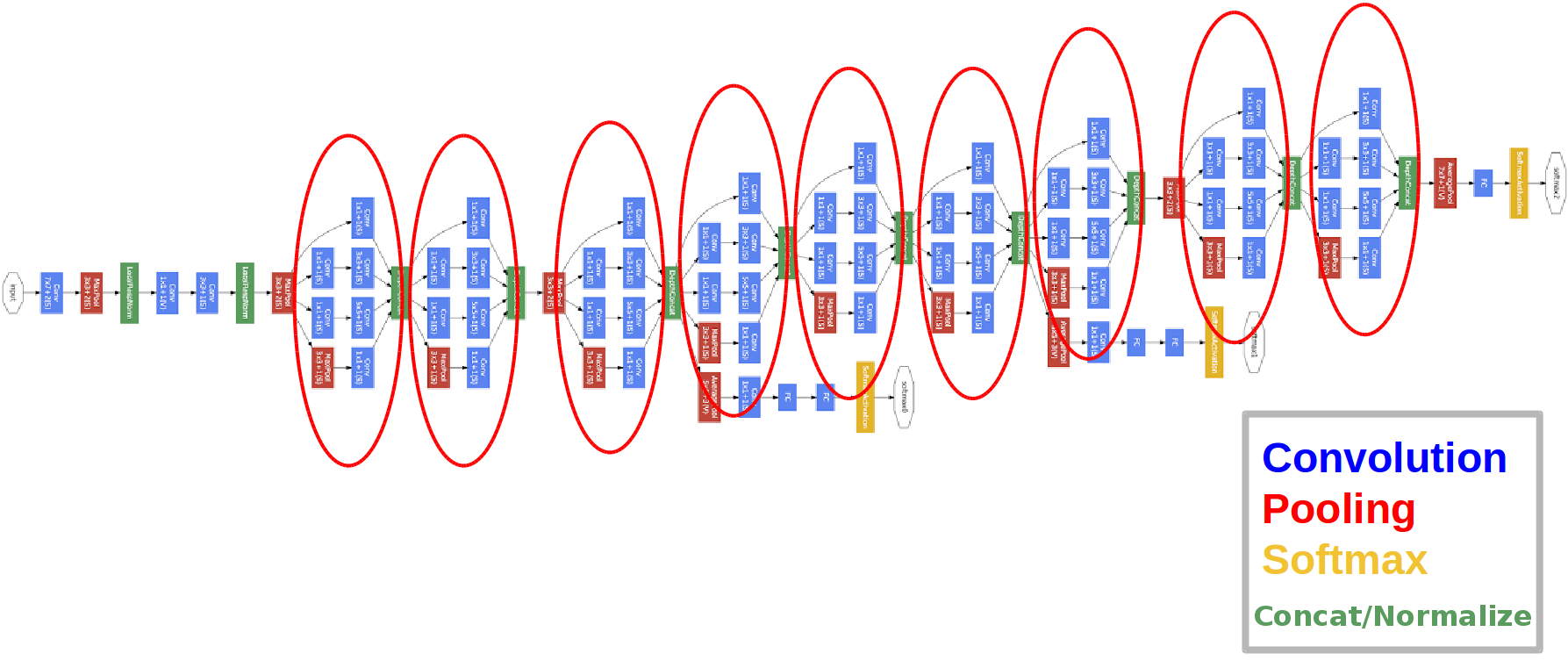
introduzida em 2014.
Os círculos vermelhos são os chamados módulo de Iniciação.
Vamos examiná-lo mais de perto:
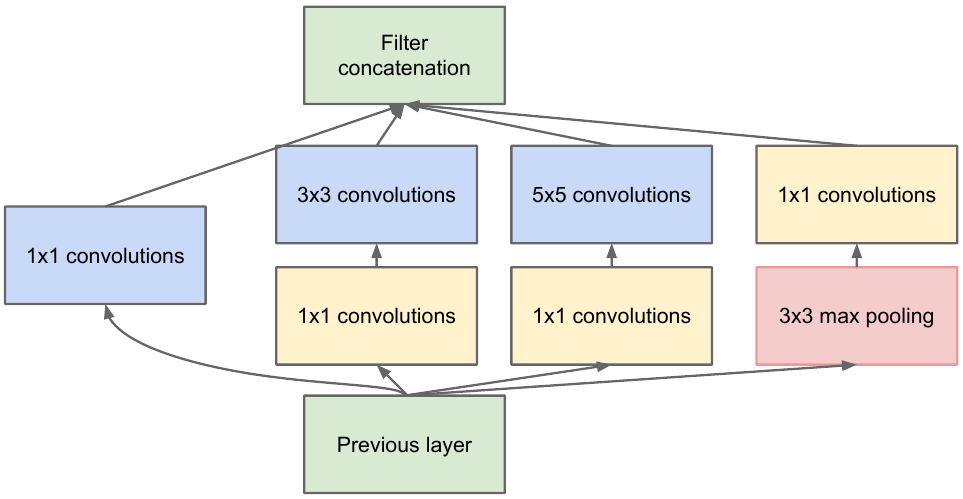
pegamos um mapa de características da camada anterior, aplicamos várias convoluções com diferentes filtros a ele e, em seguida, concatenamos o resultante. A intuição é simples: queremos obter diferentes representações de nosso mapa de características usando filtros de tamanhos diferentes. As convoluções 1x1 são usadas para não aumentar tanto o número de canais após cada bloco inicial. Essa. quando o mapa de feições tem um grande número de canais, e eles querem reduzir este número sem alterar a altura e largura do mapa de feições, use a convolução 1x1.
Existem também três blocos classificadores na rede, é assim que um deles se parece (o da direita para nós):

Com essa construção, o gradiente "melhor" alcança das camadas de saída às camadas de entrada durante a retropropagação do erro.
Por que precisamos de duas saídas de rede extras? É tudo sobre o chamado problema do gradiente de desaparecimento :
o resultado final é que, ao retropropagar um erro, o gradiente tende a zero trivialmente. Quanto mais profunda a rede, mais suscetível a esse fenômeno. Por que isso acontece? Quando passamos para trás, vamos da saída para a entrada, calculando os gradientes de funções complexas. Derivada de uma função complexa ( regra da cadeia) É essencialmente multiplicação. E assim, multiplicando alguns valores no caminho da saída para a entrada, encontramos números próximos de zero e, com isso, os pesos da rede neural praticamente não são atualizados. Isso é parcialmente um problema com as funções de ativação sigmóide que têm sua saída em algum intervalo fixo. Bem, este problema é parcialmente resolvido usando a função de ativação ReLu. Por que parcialmente? Porque ninguém dá garantias para os valores dos parâmetros treinados e a representação do objeto de entrada em todos os mapas de recursos.
Importante:
- A rede tem 22 camadas (um pouco mais do que a rede anterior).
- O número de parâmetros treinados é igual a cinco milhões, várias vezes menor que nas duas redes anteriores.
- A aparência das convoluções 1x1.
- Blocos de iniciação são usados.
- Em vez de camadas totalmente conectadas, agora convoluções 1x1, que diminuem a profundidade e, como resultado, diminuem a dimensão das camadas totalmente conectadas e o chamado conjunto avegare global (você pode ler mais aqui ).
- A arquitetura tem 3 saídas (a resposta final é ponderada).
ResNet
Arquitetura (variante ResNet-34): introduzida
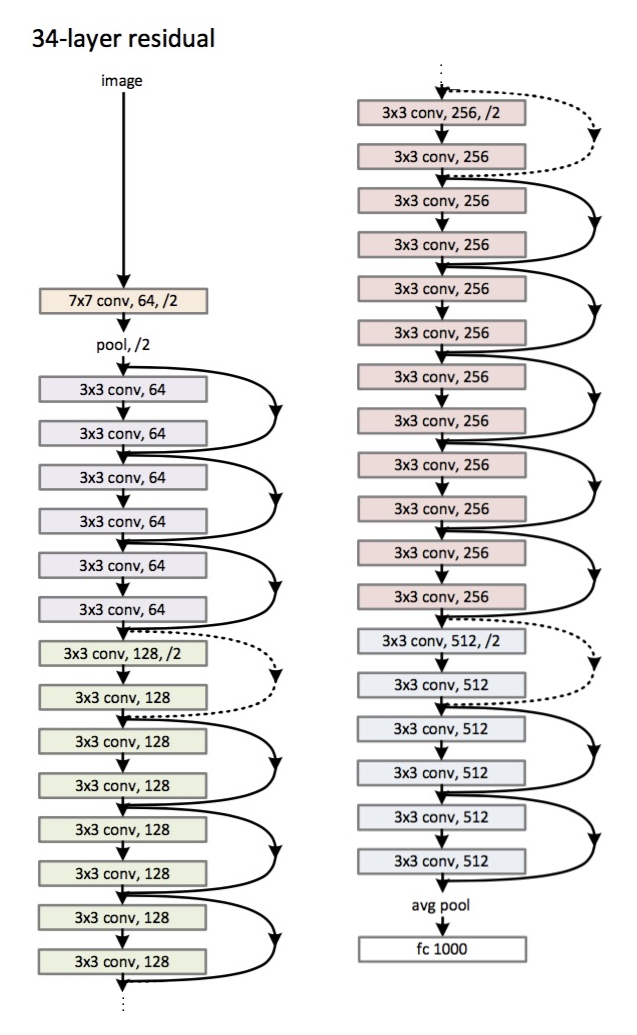
em 2015.
A principal inovação é um grande número de camadas e os chamados blocos residuais. Esses blocos são usados para combater o problema do gradiente de desbotamento. A conexão entre esses blocos residuais é chamada de atalho (setas na imagem). Agora, com esses atalhos, o gradiente alcançará todos os parâmetros necessários, treinando assim a rede :)
Importante:
- Em vez de camadas totalmente conectadas - pool global médio.
- Blocos residuais.
- A rede ultrapassou os humanos no reconhecimento de imagens no conjunto de dados ImageNet (erro dos 5 primeiros).
- A normalização em lote foi usada pela primeira vez.
- É utilizada a técnica de inicialização de pesos (intuição: a partir de uma certa inicialização de pesos, a rede converge (aprende) mais rápido e melhor).
- A profundidade máxima é de 152 camadas!
Uma pequena digressão
O problema do gradiente de desvanecimento é relevante para todas as redes neurais profundas.
Há também seu antagonista - o problema do gradiente explosivo, que também é relevante para todas as redes neurais profundas. A linha inferior é clara a partir do nome - o gradiente se torna muito grande, o que causa NaN (não um número, infinito). A solução é óbvia - limitar o valor do gradiente, caso contrário - reduzir seu valor (normalizar). Essa técnica é chamada de "recorte".
Conclusão
Em 2019, apareceu um artigo sobre uma nova família de arquiteturas - EfficientNet.
Eu recomendo seguir as últimas tendências em várias tarefas e áreas relacionadas ao Aprendizado de Máquina aqui . Neste recurso, você pode selecionar uma tarefa (por exemplo, classificação de imagem) e um conjunto de dados (por exemplo, ImageNet) e observar a qualidade de certas arquiteturas, informações adicionais sobre elas. Por exemplo, a grade FixEfficientNet-L2 leva o honroso primeiro lugar na classificação de imagens no conjunto de dados ImageNet (primeira precisão).
Nos próximos artigos, falaremos sobre aprendizagem por transferência, detecção de objetos, segmentação.