Neste artigo, falarei sobre as principais funções do BigQuery e mostrarei seus recursos com exemplos específicos. Você pode escrever consultas básicas e testá-las em dados de demonstração.
O que é SQL e quais dialetos ele possui
SQL (Structured Query Language) é uma linguagem de consulta estruturada para trabalhar com bancos de dados. Com sua ajuda, você pode receber, adicionar ao banco de dados e modificar grandes quantidades de dados. O Google BigQuery oferece suporte a dois dialetos: SQL padrão e SQL legado.
O dialeto a ser escolhido depende da sua preferência, mas o Google recomenda o uso do SQL padrão devido a uma série de vantagens:
- Flexibilidade e funcionalidade ao trabalhar com campos aninhados e repetidos.
- Suporte para linguagens DML e DDL , que permitem alterar dados em tabelas, bem como manipular tabelas e visualizações em GBQ.
- O processamento de grandes quantidades de dados é mais rápido do que o Legasy SQL.
- Suporte para todas as atualizações atuais e futuras do BigQuery.
Você pode descobrir mais sobre a diferença entre os dialetos na ajuda .
Por padrão, as consultas do Google BigQuery são executadas em SQL legado.
Existem várias maneiras de mudar para o SQL padrão:
- Na interface do BigQuery, na janela de edição da consulta, selecione "Mostrar opções" e desmarque a caixa ao lado da opção "Usar SQL legado"

- Adicione a linha #standardSQL antes da consulta e inicie a consulta em uma nova linha

Por onde começar
Para que você possa praticar a execução de consultas paralelamente à leitura do artigo, preparei para você uma tabela com dados de demonstração . Carregue os dados da planilha em seu projeto do Google BigQuery.
Se você ainda não tem um projeto GBQ, crie um. Para fazer isso, você precisa de uma conta de faturamento ativa no Google Cloud Platform . Você precisará vincular o cartão, mas sem seu conhecimento não haverá débito em dinheiro, além disso, no ato do cadastro, você receberá $ 300 por 12 meses , que poderá gastar no armazenamento e processamento dos dados.
Recursos do Google BigQuery
Os grupos de funções mais comumente usados ao construir consultas são função Aggregate, função Date, função String e função Window. Agora mais sobre cada um deles.
Função agregada
As funções de agregação permitem obter valores de resumo em toda a tabela. Por exemplo, calcule o cheque médio, a renda mensal total ou destaque o segmento de usuários que fizeram o número máximo de compras.
Aqui estão os recursos mais populares desta seção:
| SQL legado | SQL padrão | O que a função faz |
|---|---|---|
| AVG (campo) | AVG ([DISTINCT] (campo)) | Retorna a média da coluna do campo. No SQL padrão, ao adicionar uma cláusula DISTINCT, a média é calculada apenas para linhas com valores únicos (não duplicados) da coluna do campo |
| MAX (campo) | MAX (campo) | Retorna o valor máximo da coluna do campo |
| MIN (campo) | MIN (campo) | Retorna o valor mínimo da coluna do campo |
| SUM (campo) | SUM (campo) | Retorna a soma dos valores da coluna do campo |
| COUNT (campo) | COUNT (campo) | Retorna o número de linhas no campo da coluna |
| EXACT_COUNT_DISTINCT (campo) | COUNT ([DISTINCT] (campo)) | Retorna o número de linhas únicas na coluna do campo |
Para obter uma lista de todas as funções, consulte a Ajuda: SQL legado e SQL padrão .
Vamos ver como as funções listadas funcionam com um exemplo de demonstração de dados. Vamos calcular a receita média de transações, compras com maior e menor valor, receita total e o número de todas as transações. Para verificar se as compras estão duplicadas, também calcularemos o número de transações exclusivas. Para fazer isso, escrevemos uma consulta na qual indicamos o nome de nosso projeto, conjunto de dados e tabela do Google BigQuery.
#legasy SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
EXACT_COUNT_DISTINCT(transactionId) as unique_transactions
FROM
[owox-analytics:t_kravchenko.Demo_data]#standard SQL
SELECT
AVG(revenue) as average_revenue,
MAX(revenue) as max_revenue,
MIN(revenue) as min_revenue,
SUM(revenue) as whole_revenue,
COUNT(transactionId) as transactions,
COUNT(DISTINCT(transactionId)) as unique_transactions
FROM
`owox-analytics.t_kravchenko.Demo_data`Como resultado, obtemos os seguintes resultados:
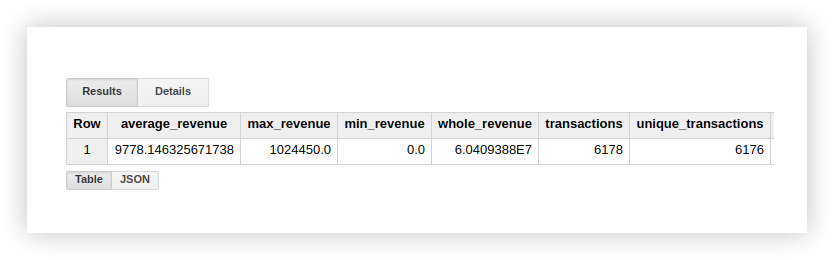
Você pode verificar os resultados do cálculo na tabela original com dados de demonstração usando as funções padrão do Planilhas Google (SUM, AVG e outras) ou tabelas dinâmicas.
Como você pode ver na imagem acima, o número de transações e as transações únicas são diferentes.
Isso sugere que há 2 transações em nossa tabela com transactionId duplicada:
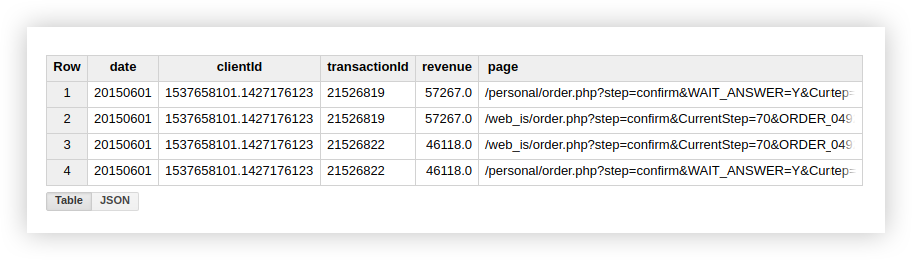
Portanto, se você estiver interessado em transações exclusivas, use a função que conta linhas exclusivas. Como alternativa, você pode agrupar os dados usando uma cláusula GROUP BY para se livrar das duplicatas antes de usar a função de agregação.
Funções para trabalhar com datas (função de data)
Essas funções permitem que você processe datas: altere seu formato, selecione a parte necessária (dia, mês ou ano), altere a data em um determinado intervalo.
Eles podem ser úteis para você nos seguintes casos:
- Ao configurar análises de ponta a ponta - para trazer datas e horas de diferentes fontes para um único formato.
- Ao criar relatórios atualizados automaticamente ou correspondências acionadas. Por exemplo, quando você precisa de dados das últimas 2 horas, uma semana ou um mês.
- Ao criar relatórios de coorte, nos quais é necessário obter dados no contexto de dias, semanas, meses.
Funções de data mais comumente usadas:
| SQL legado | SQL padrão | O que a função faz |
|---|---|---|
| DATA ATUAL () | DATA ATUAL () | Retorna a data atual no formato% AAAA-% MM-% DD |
| DATE (timestamp) | DATE (timestamp) | Converte uma data do formato% AAAA-% MM-% DD% H:% M:% S. no formato% AAAA-% MM-% DD |
| DATE_ADD (carimbo de data / hora, intervalo, intervalo_unidades) | DATE_ADD(timestamp, INTERVAL interval interval_units) | timestamp, interval.interval_units.
Legacy SQL YEAR, MONTH, DAY, HOUR, MINUTE SECOND, Standard SQL — YEAR, QUARTER, MONTH, WEEK, DAY |
| DATE_ADD(timestamp, — interval, interval_units) | DATE_SUB(timestamp, INTERVAL interval interval_units) | timestamp, interval |
| DATEDIFF(timestamp1, timestamp2) | DATE_DIFF(timestamp1, timestamp2, date_part) | timestamp1 timestamp2.
Legacy SQL , Standard SQL — date_part (, , , , ) |
| DAY(timestamp) | EXTRACT(DAY FROM timestamp) | timestamp. 1 31 |
| MONTH(timestamp) | EXTRACT(MONTH FROM timestamp) | timestamp. 1 12 |
| YEAR(timestamp) | EXTRACT(YEAR FROM timestamp) | timestamp |
Para obter uma lista de todos os recursos, consulte a Ajuda do SQL legado e do SQL padrão .
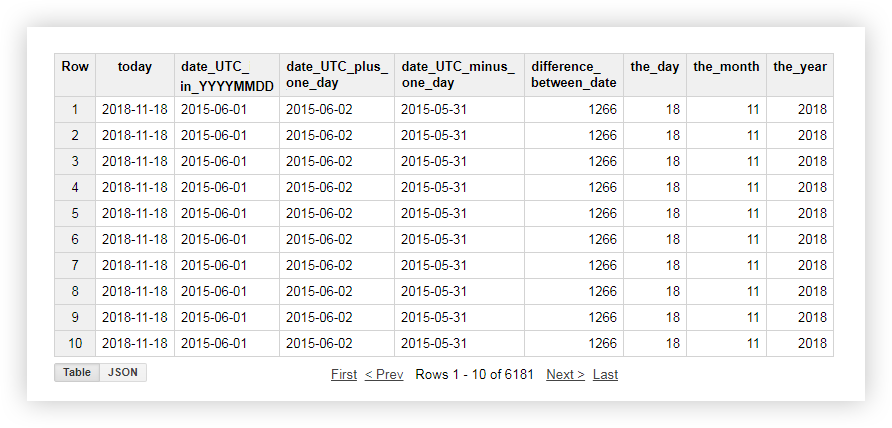
Vejamos uma demonstração dos dados, como cada uma das funções acima funciona. Por exemplo, obtemos a data atual, trazemos a data da tabela original para o formato% AAAA-% MM-% DD, subtraímos e adicionamos um dia a ela. Em seguida, calculamos a diferença entre a data atual e a data da tabela original e dividimos a data atual separadamente em ano, mês e dia. Para fazer isso, você pode copiar as consultas de exemplo abaixo e substituir o nome do projeto, conjunto de dados e tabela de dados pelos seus.
#legasy SQL
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day,
DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day,
DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date,
DAY( CURRENT_DATE() ) AS the_day,
MONTH( CURRENT_DATE()) AS the_month,
YEAR( CURRENT_DATE()) AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data]
#standard SQL
SELECT
today,
date_UTC_in_YYYYMMDD,
DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day,
DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day,
DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date,
EXTRACT(DAY FROM today ) AS the_day,
EXTRACT(MONTH FROM today ) AS the_month,
EXTRACT(YEAR FROM today ) AS the_year
FROM (
SELECT
CURRENT_DATE() AS today,
DATE( date_UTC ) AS date_UTC_in_YYYYMMDD
FROM
`owox-analytics.t_kravchenko.Demo_data`)
Após aplicar a solicitação, você receberá o seguinte relatório:
Funções para trabalhar com strings (função String)
As funções de string permitem formar uma string, selecionar e substituir substrings, calcular o comprimento da string e o índice ordinal da substring na string original.
Por exemplo, com a ajuda deles, você pode:
- Faça filtros no relatório por tags UTM que são passadas para o URL da página.
- Traga os dados para um formato uniforme se os nomes das fontes e campanhas forem escritos em registros diferentes.
- Substitua os dados incorretos no relatório, por exemplo, se o nome da campanha foi enviado com um erro de digitação.
As funções mais populares para trabalhar com strings:
| SQL legado | SQL padrão | O que a função faz |
|---|---|---|
| CONCAT ('str1', 'str2') ou 'str1' + 'str2' | CONCAT ('str1', 'str2') | Concatena várias strings 'str1' e 'str2' em uma |
| 'str1' CONTÉM 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| LENGTH('str' ) | CHAR_LENGTH('str' )
CHARACTER_LENGTH('str' ) |
'str' ( ) |
| SUBSTR('str', index [, max_len]) | SUBSTR('str', index [, max_len]) | max_len, index 'str' |
| LOWER('str') | LOWER('str') | 'str' |
| UPPER(str) | UPPER(str) | 'str' |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Retorna o índice da primeira ocorrência da string 'str2' na string 'str1', caso contrário - 0 |
| REPLACE ('str1', 'str2', 'str3') | REPLACE ('str1', 'str2', 'str3') | Substitui na string 'str1' substring 'str2' pela substring 'str3' |
Mais detalhes - na ajuda: Legacy SQL e Standard SQL .
Vejamos o exemplo de dados de demonstração de como usar as funções descritas. Suponha que temos 3 colunas separadas que contêm os valores do dia, mês e ano:
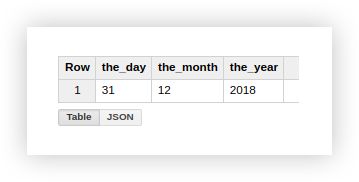
Trabalhar com uma data neste formato não é muito conveniente, por isso vamos combiná-la em uma coluna. Para fazer isso, use as consultas SQL abaixo e não se esqueça de incluir o nome do seu projeto, conjunto de dados e tabela do Google BigQuery.
#legasy SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1,
the_day+'-'+the_month+'-'+the_year AS mix_string2
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
mix_string1,
mix_string2
#standard SQL
SELECT
CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1
FROM (
SELECT
'31' AS the_day,
'12' AS the_month,
'2018' AS the_year
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
mix_string1
Após a execução da solicitação, receberemos a data em uma coluna:

Muitas vezes, ao carregar uma determinada página no site, os valores das variáveis que o usuário selecionou são escritos na URL. Pode ser um método de pagamento ou entrega, um número de transação, um índice de uma loja física onde um cliente deseja retirar um item, etc. Usando uma consulta SQL, você pode extrair esses parâmetros do endereço da página.
Vejamos dois exemplos de como e por que fazer isso.
Exemplo 1 . Digamos que queremos saber o número de compras em que os usuários retiram itens em lojas físicas. Para fazer isso, você precisa contar o número de transações enviadas de páginas cujo URL contém a substring shop_id (índice da loja física). Fazemos isso usando as seguintes consultas:
#legasy SQL
SELECT
COUNT(transactionId) AS transactions,
check
FROM (
SELECT
transactionId,
page CONTAINS 'shop_id' AS check
FROM
[owox-analytics:t_kravchenko.Demo_data])
GROUP BY
check
#standard SQL
SELECT
COUNT(transactionId) AS transactions,
check1,
check2
FROM (
SELECT
transactionId,
REGEXP_CONTAINS( page, 'shop_id') AS check1,
page LIKE '%shop_id%' AS check2
FROM
`owox-analytics.t_kravchenko.Demo_data`)
GROUP BY
check1,
check2
Na tabela resultante, vemos que 5502 transações foram enviadas das páginas que contêm shop_id (verificação = verdadeiro):
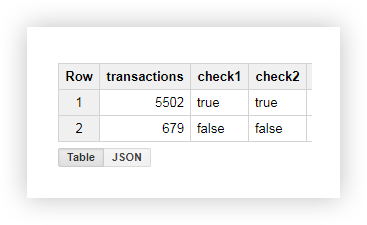
Exemplo 2 . Suponha que você atribuiu seu delivery_id a cada método de entrega e escreve o valor desse parâmetro no URL da página. Para descobrir qual método de entrega o usuário escolheu, selecione delivery_id em uma coluna separada.
Usamos as seguintes consultas para isso:
#legasy SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
LENGTH(page_lower_case) AS page_length,
INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
[owox-analytics:t_kravchenko.Demo_data])))
ORDER BY
page_lower_case ASC
#standard SQL
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
selected_delivery_id,
REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id
FROM (
SELECT
page_lower_case,
page_length,
index_of_delivery_id,
SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id
FROM (
SELECT
page_lower_case,
CHAR_LENGTH(page_lower_case) AS page_length,
STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id
FROM (
SELECT
LOWER( page) AS page_lower_case,
UPPER( page) AS page_upper_case
FROM
`owox-analytics.t_kravchenko.Demo_data`)))
ORDER BY
page_lower_case ASC
Como resultado, obtemos a seguinte tabela no Google BigQuery:

Funções para trabalhar com subconjuntos de dados ou funções de janela (função de janela)
Essas funções são semelhantes às funções de agregação que discutimos acima. Sua principal diferença é que os cálculos não são executados em todo o conjunto de dados selecionado usando uma consulta, mas em uma parte dele - um subconjunto ou janela.
Usando funções de janela, você pode agregar dados por grupos sem usar o operador JOIN para combinar várias consultas. Por exemplo, calcule a receita média por campanhas publicitárias, o número de transações por dispositivo. Ao adicionar outro campo ao relatório, você pode descobrir facilmente, por exemplo, a participação na receita de uma campanha publicitária na Black Friday ou a participação nas transações feitas em um aplicativo móvel.
Junto com cada função, uma expressão OVER deve ser escrita na solicitação, que define os limites da janela. OVER contém 3 componentes com os quais você pode trabalhar:
- PARTITION BY - define o atributo pelo qual você dividirá os dados de origem em subconjuntos, por exemplo PARTITION BY clientId, DayTime.
- ORDER BY - define a ordem das linhas no subconjunto, por exemplo ORDER BY hora DESC.
- WINDOW FRAME - permite processar linhas dentro de um subconjunto de acordo com uma característica específica. Por exemplo, você pode calcular a soma de nem todas as linhas na janela, mas apenas as cinco primeiras antes da linha atual.
Esta tabela resume as funções de janela mais comumente usadas:
| SQL legado | SQL padrão | O que a função faz |
|---|---|---|
| AVG (campo)
COUNT (campo) COUNT (campo DISTINCT) MAX () MIN () SUM () |
AVG ([DISTINCT] (campo))
COUNT (campo) COUNT ([DISTINCT] (campo)) MAX (campo) MIN (campo) SUM (campo) |
, , , field .
DISTINCT , () |
| 'str1' CONTAINS 'str2' | REGEXP_CONTAINS('str1', 'str2') 'str1' LIKE ‘%str2%’ | true 'str1' ‘str2’.
Standard SQL ‘str2’ re2 |
| DENSE_RANK() | DENSE_RANK() | |
| FIRST_VALUE(field) | FIRST_VALUE (field[{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAST_VALUE(field) | LAST_VALUE (field [{RESPECT | IGNORE} NULLS]) | field .
field . RESPECT IGNORE NULLS , NULL |
| LAG(field) | LAG (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
| LEAD(field) | LEAD (field[, offset [, default_expression]]) | field .
Offset , . . Default_expression — , , |
Você pode ver uma lista de todas as funções na ajuda do SQL legado e do SQL padrão: funções analíticas agregadas , funções de navegação .
Exemplo 1. Digamos que desejamos analisar a atividade dos compradores durante o horário comercial e não comercial. Para fazer isso, é necessário dividir as transações em 2 grupos e calcular as métricas de nosso interesse:
- Grupo 1 - compras em horário comercial das 9h00 às 18h00.
- Grupo 2 - compras fora do horário de expediente das 0h00 às 9h00 e das 18h00 às 24h00.
Além do horário laboral e não laboral, outro sinal para formação de janela será o clientId, ou seja, para cada utilizador teremos duas janelas:
| Subconjunto (janela) | ID do Cliente | Dia |
|---|---|---|
| 1 janela | clientId 1 | Tempo de trabalho |
| 2 janelas | clientId 2 | Horário não comercial |
| 3 janelas | clientId 3 | Tempo de trabalho |
| 4 janelas | clientId 4 | Horário não comercial |
| Janela N | clientId N | Tempo de trabalho |
| Janela N + 1 | clientId N + 1 | Horário não comercial |
Vamos calcular a renda média, máxima, mínima e total, o número de transações e o número de transações exclusivas para cada usuário durante o horário comercial e não comercial nos dados de demonstração. As perguntas abaixo nos ajudarão a fazer isso.
#legasy SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
#standard SQL
SELECT
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
FROM (
SELECT
date,
clientId,
DayTime,
AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue,
MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue,
MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue,
SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue,
COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions,
COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
avg_revenue,
max_revenue,
min_revenue,
sum_revenue,
transactions,
unique_transactions
ORDER BY
transactions DESC
Vamos ver o que aconteceu como resultado, usando o exemplo de um dos usuários com clientId = '102041117.1428132012 ′. Na tabela inicial para este usuário, tínhamos os seguintes dados:
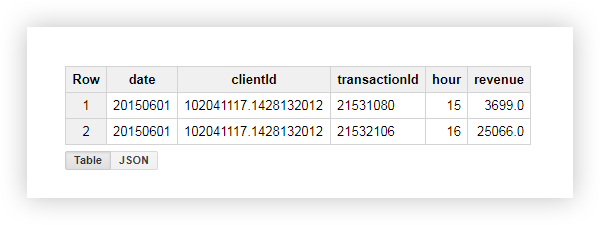
Ao aplicar a consulta, recebemos um relatório que contém a receita média, mínima, máxima e total deste usuário, bem como o número de transações. Como você pode ver na captura de tela abaixo, o usuário fez as duas transações durante o horário comercial:

Exemplo 2 . Agora vamos complicar um pouco a tarefa:
- Vamos colocar os números de sequência de todas as transações na janela, dependendo do tempo de execução. Lembre-se de que definimos a janela por usuário e tempo útil / não útil.
- Vamos exibir a receita da transação seguinte / anterior (em relação à atual) na janela.
- Vamos exibir a receita da primeira e da última transação na janela.
Para isso, usamos as seguintes consultas:
#legasy SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
[owox-analytics:t_kravchenko.Demo_data]))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
#standard SQL
SELECT
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
FROM (
SELECT
date,
clientId,
DayTime,
hour,
DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank,
revenue,
LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue,
LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue,
FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour,
LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour
FROM (
SELECT
date,
date_UTC,
clientId,
transactionId,
revenue,
page,
hour,
CASE
WHEN hour>=9 AND hour<=18 THEN ' '
ELSE ' '
END AS DayTime
FROM
`owox-analytics.t_kravchenko.Demo_data`))
GROUP BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
ORDER BY
date,
clientId,
DayTime,
hour,
rank,
revenue,
lead_revenue,
lag_revenue,
first_revenue_by_hour,
last_revenue_by_hour
Vamos verificar os resultados do cálculo usando o exemplo de um usuário já familiarizado com clientId = '102041117.1428132012 ′:

Na captura de tela acima, vemos que:
- A primeira transação foi às 15h e a segunda às 16h.
- Após a transação atual às 15:00, houve uma transação às 16:00, cuja receita é 25066 (coluna lead_revenue).
- Antes da transação atual às 16h, havia uma transação às 15h com uma receita de 3699 (coluna lag_revenue).
- A primeira transação na janela foi uma transação às 15:00, cuja receita é de 3699 (coluna first_revenue_by_hour).
- A solicitação processa os dados linha a linha, portanto, para a transação em questão, será a última da janela e os valores nas colunas last_revenue_by_hour e receita serão os mesmos.
conclusões
Neste artigo, cobrimos as funções mais populares das seções Função agregada, função Data, função String, Função janela. No entanto, o Google BigQuery tem muitos outros recursos úteis, por exemplo:
- Funções de transmissão - permitem que você transmita dados para um formato específico.
- Funções de curinga de tabela - permitem que você acesse várias tabelas de um conjunto de dados.
- Funções de expressão regular - permitem que você descreva o modelo de uma consulta de pesquisa, e não seu valor exato.
Escreva nos comentários se fizer sentido escrever com os mesmos detalhes sobre eles.