Mas o trabalho do Data Scientist está vinculado aos dados, e um dos momentos mais importantes e demorados é processar os dados antes de enviá-los a uma rede neural ou analisá-los de uma determinada maneira.
Neste artigo, nossa equipe descreverá como você pode processar dados de forma rápida e fácil com instruções e códigos passo a passo. Tentamos tornar o código flexível o suficiente para ser aplicado em diferentes conjuntos de dados.
Muitos profissionais podem não encontrar nada de extraordinário neste artigo, mas os iniciantes serão capazes de aprender algo novo, e qualquer pessoa que há muito sonha em fazer um bloco de anotações separado para processamento rápido e estruturado de dados pode copiar o código e formatá-lo ou fazer o download de um já pronto. caderno do Github.
Temos conjunto de dados. o que fazer a seguir?
Portanto, o padrão: você precisa entender com o que estamos lidando, o quadro geral. Usaremos o pandas para fazer isso simplesmente para definir diferentes tipos de dados.
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 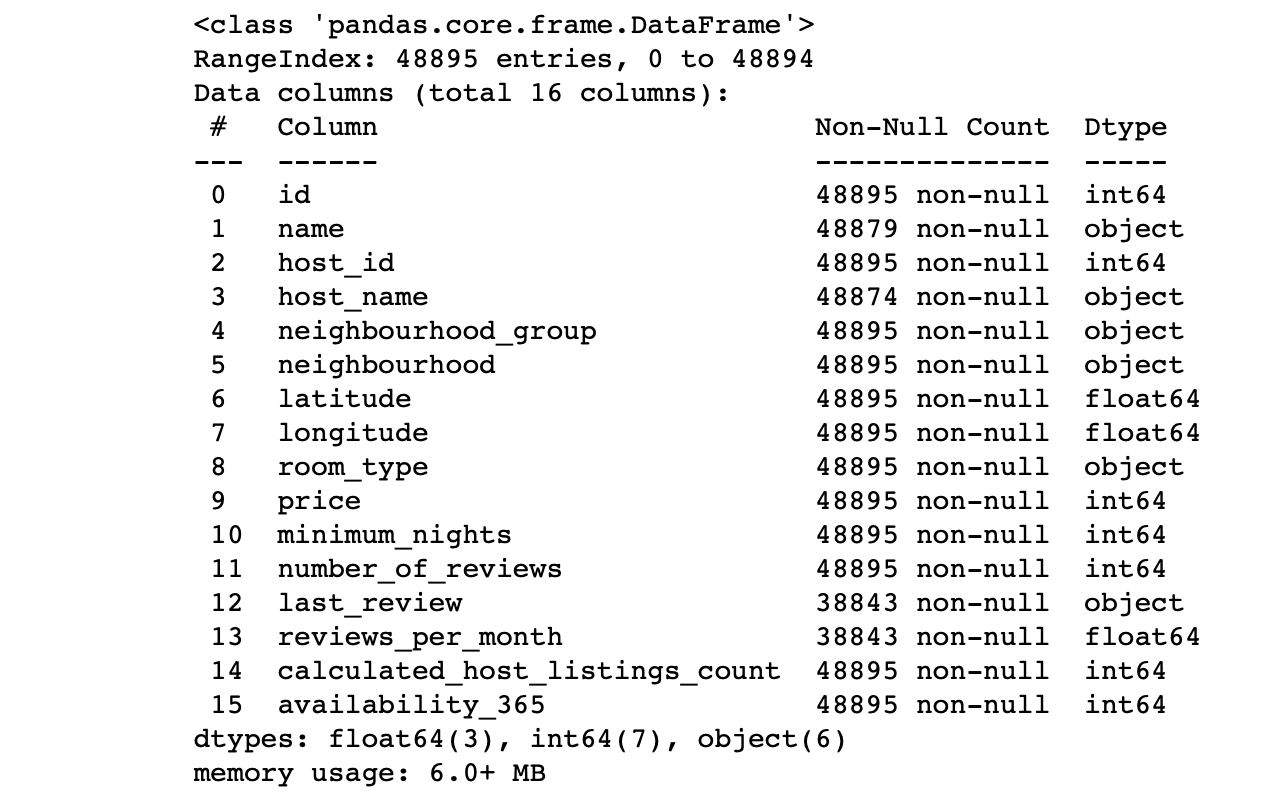
Vemos os valores das colunas:
- O número de linhas em cada coluna corresponde ao número total de linhas?
- Qual é a essência dos dados em cada coluna?
- Para qual coluna queremos fazer previsões?
As respostas a essas perguntas permitirão que você analise o conjunto de dados e desenhe um plano para as próximas etapas.
Além disso, para uma visão mais aprofundada dos valores em cada coluna, podemos usar a função describe () do pandas. No entanto, a desvantagem dessa função é que ela não fornece informações sobre colunas com valores de string. Trataremos deles mais tarde.
df.describe()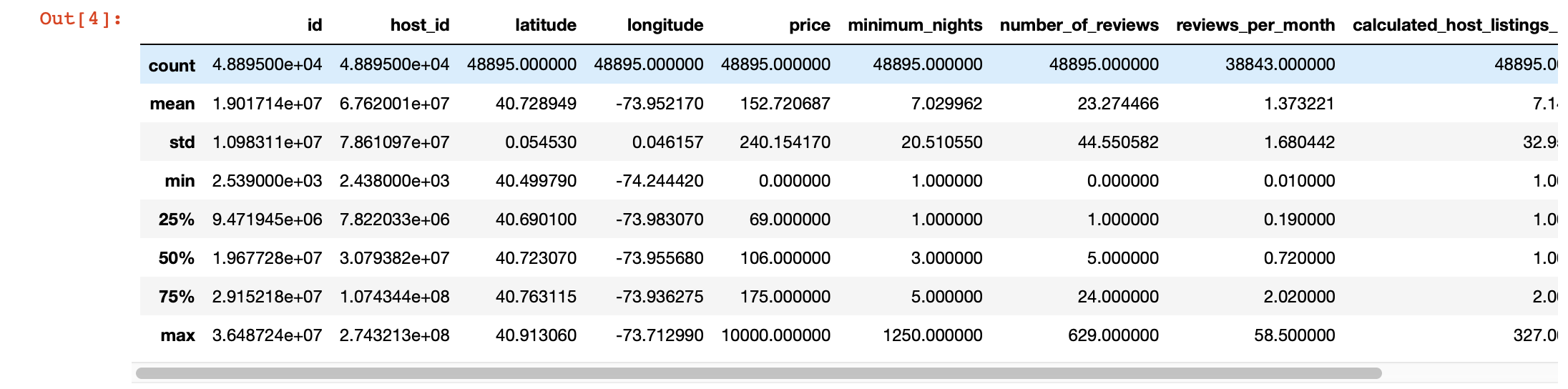
Visualização mágica
Vejamos onde não temos nenhum valor:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')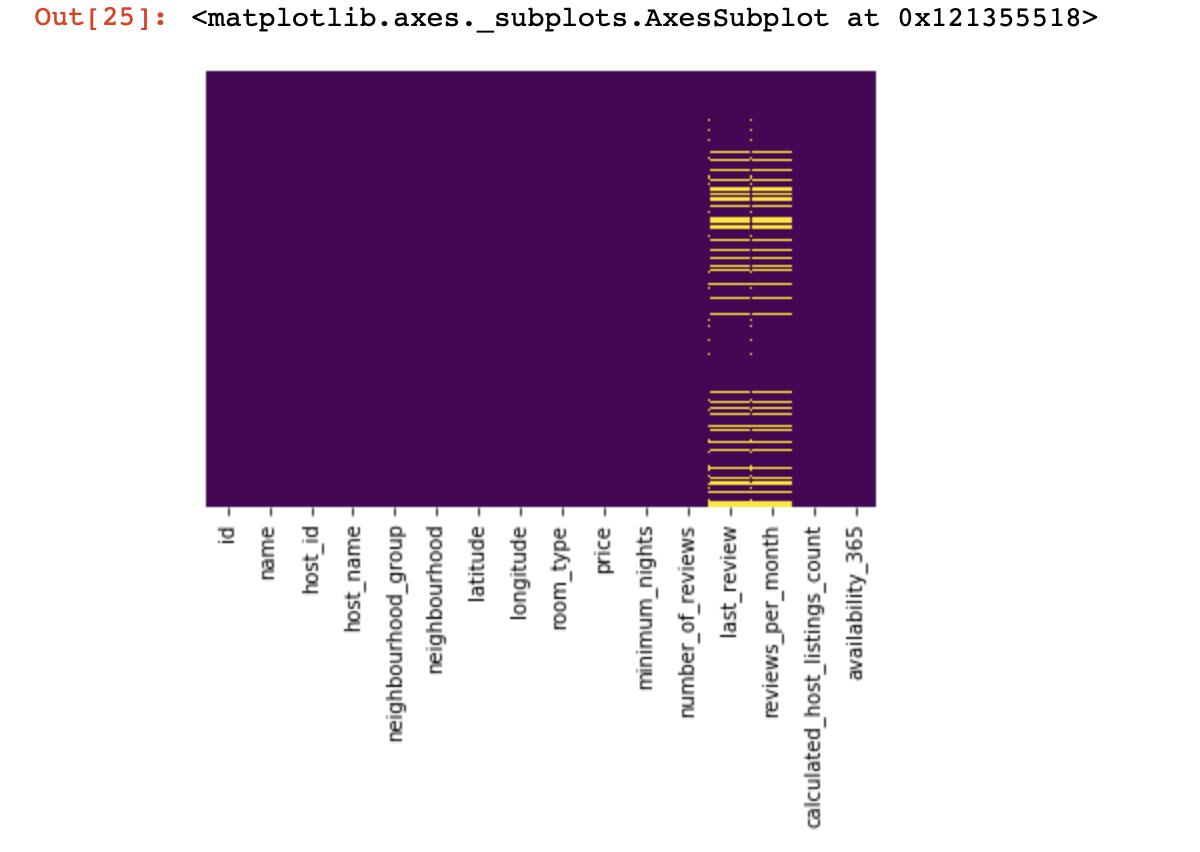
Foi uma pequena olhada de cima, agora vamos descer para coisas mais interessantes. Vamos
tentar encontrar e, se possível, deletar colunas que possuem apenas um valor em todas as linhas (elas não afetarão o resultado de forma alguma):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , Agora, protegemos a nós mesmos e ao sucesso do nosso projeto de linhas duplicadas (linhas que contêm as mesmas informações na mesma ordem que uma das linhas existentes):
df.drop_duplicates(inplace=True) # , .
# .Dividimos o conjunto de dados em dois: um com valores qualitativos e outro com valores quantitativos
Aqui, precisamos fazer um pequeno esclarecimento: se as linhas com dados ausentes em dados qualitativos e quantitativos não se correlacionam fortemente entre si, então será necessário tomar uma decisão sobre o que sacrificamos - todas as linhas com dados ausentes, apenas parte delas ou certas colunas. Se as linhas estiverem relacionadas, temos todo o direito de dividir o conjunto de dados em dois. Caso contrário, primeiro você precisará lidar com as linhas que não correlacionam os dados ausentes em termos qualitativos e quantitativos, e só então dividir o conjunto de dados em dois.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Fazemos isso para facilitar o processamento desses dois tipos diferentes de dados - mais tarde, entenderemos o quanto isso simplifica nossa vida.
Trabalhamos com dados quantitativos
A primeira coisa que devemos fazer é determinar se existem "colunas de espionagem" nos dados quantitativos. Chamamos essas colunas assim porque fingem ser dados quantitativos e funcionam como dados qualitativos.
Como os definimos? Claro, tudo depende da natureza dos dados que você está analisando, mas, em geral, essas colunas podem ter poucos dados exclusivos (na região de 3-10 valores exclusivos).
print(df_numerical.nunique())Depois de definir as colunas de espionagem, vamos movê-los de dados quantitativos para qualitativos:
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - Por fim, separamos completamente os dados quantitativos dos qualitativos e agora você pode trabalhar com eles de maneira adequada. A primeira é entender onde temos valores vazios (NaN e, em alguns casos, 0 será considerado como valores vazios).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())Nesta fase, é importante entender em quais colunas os zeros podem significar valores ausentes: isso está relacionado a como os dados foram coletados? Ou poderia estar relacionado aos valores dos dados? Essas perguntas precisam ser respondidas caso a caso.
Portanto, se ainda assim decidimos que não podemos ter dados onde há zeros, devemos substituir os zeros por NaN, para que seja mais fácil trabalhar com esses dados perdidos mais tarde:
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)Agora vamos ver onde temos dados ausentes:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()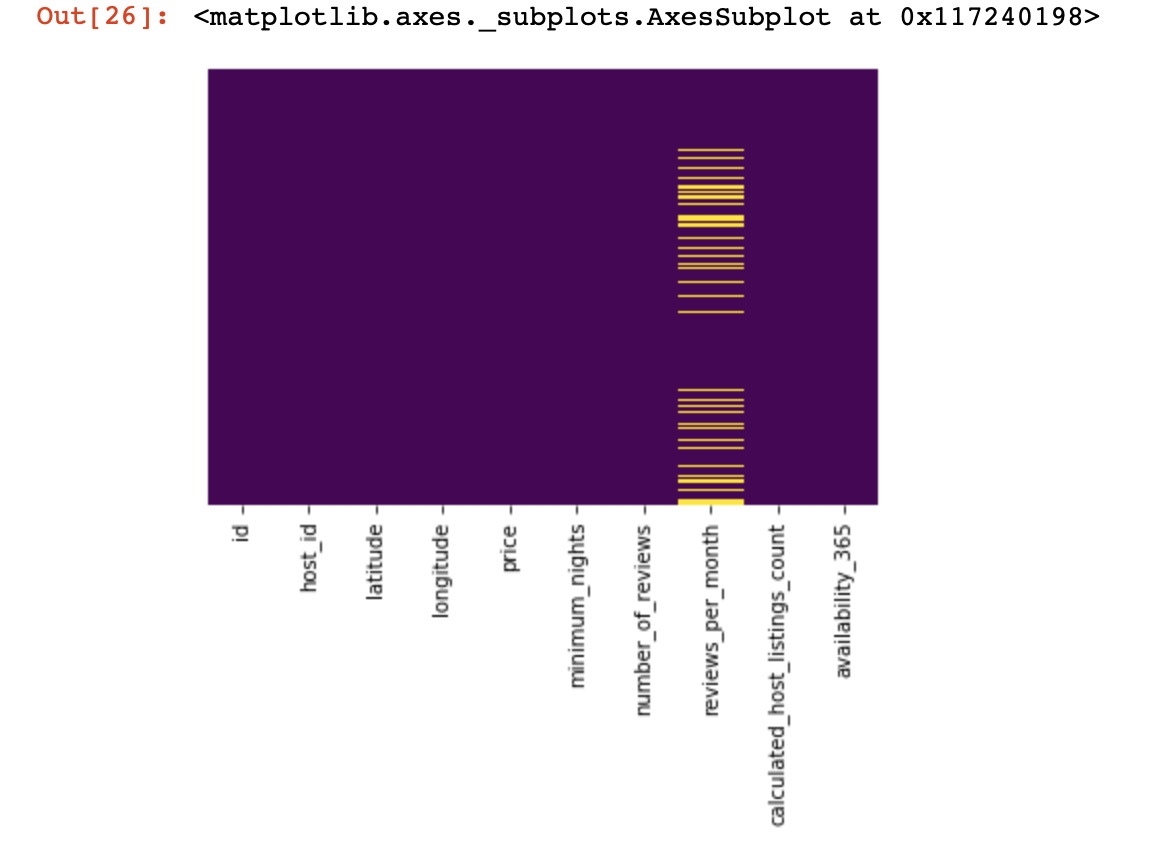
Aqui, os valores dentro das colunas que estão faltando devem ser marcados em amarelo. E a diversão começa agora - como se comportar com esses valores? Excluir linhas com esses valores ou colunas? Ou preencher esses valores vazios com algum outro?
Aqui está um diagrama aproximado que pode ajudá-lo a decidir o que você pode fazer basicamente com valores vazios:
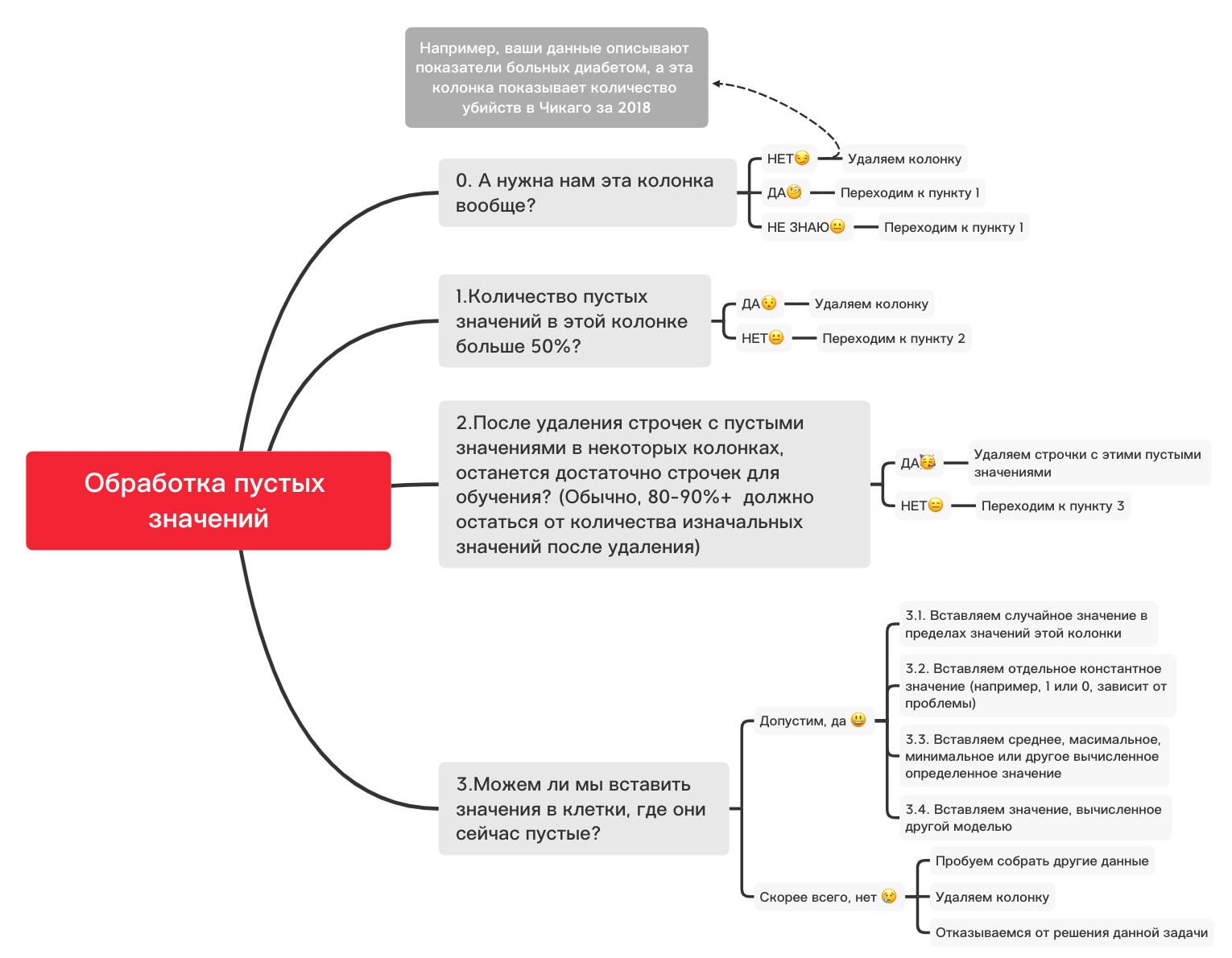
0. Remova colunas desnecessárias
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1. Existem mais de 50% dos valores em branco nesta coluna?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2. Exclua linhas com valores vazios
df_numerical.dropna(inplace=True)# , 3.1. Insira um valor aleatório
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2. Inserir valor constante
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3. Insira a média ou o valor mais frequente
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4. Inserindo um valor calculado por outro modelo
Às vezes, os valores podem ser calculados usando modelos de regressão usando modelos da biblioteca sklearn ou outras bibliotecas semelhantes. Nossa equipe dedicará um artigo separado sobre como isso pode ser feito em um futuro próximo.
Portanto, embora a narrativa sobre dados quantitativos seja interrompida, porque há muitas outras nuances sobre como fazer a preparação e o pré-processamento de dados melhor para diferentes tarefas, e as coisas básicas para dados quantitativos foram levadas em consideração neste artigo, e agora é a hora de retornar aos dados qualitativos. que separamos alguns passos do quantitativo. Você pode mudar este notebook como quiser, ajustando-o para diferentes tarefas, de forma que o pré-processamento de dados seja muito rápido!
Dados qualitativos
Basicamente, para dados de qualidade, o método One-hot-encoding é usado para formatá-los de uma string (ou objeto) para um número. Antes de prosseguirmos para este ponto, vamos usar o diagrama e o código acima para lidar com valores vazios.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')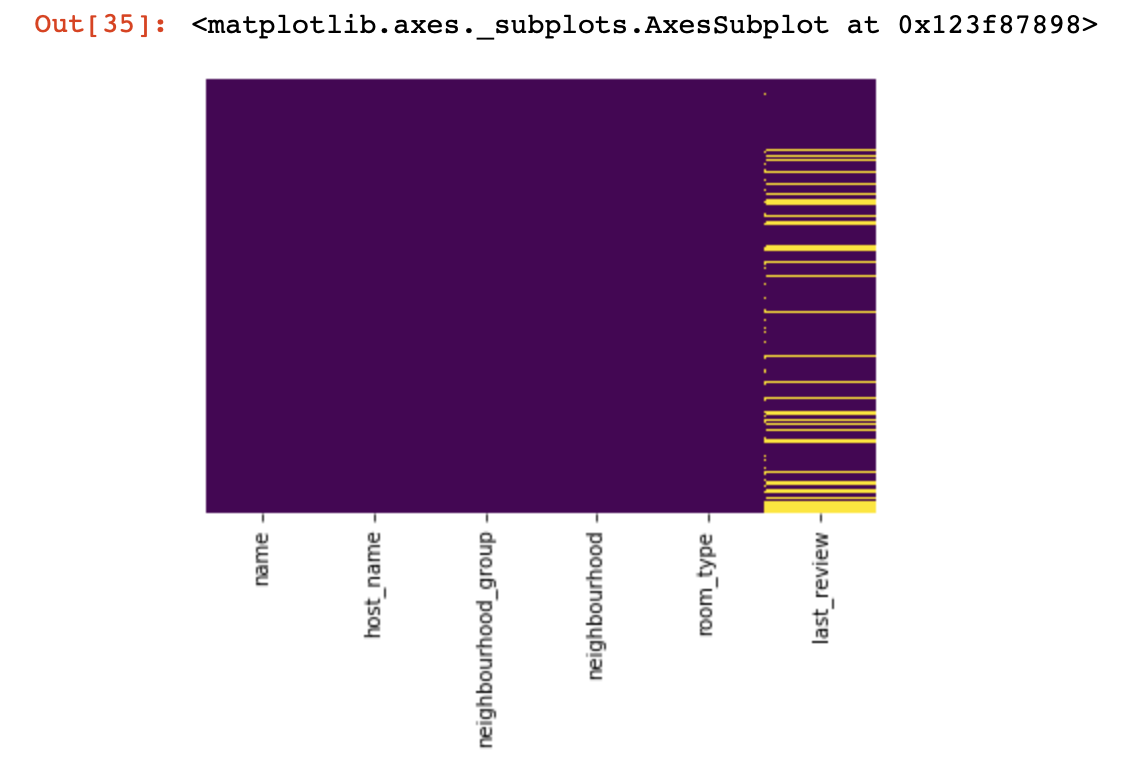
0. Removendo colunas desnecessárias
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1. Existem mais de 50% dos valores em branco nesta coluna?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2. Exclua linhas com valores vazios
df_categorical.dropna(inplace=True)# ,
# 3.1. Insira um valor aleatório
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2. Inserir valor constante
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)Então, finalmente, lidamos com valores vazios em dados de qualidade. Agora é a hora de codificar os valores que estão em seu banco de dados. Este método é frequentemente usado para garantir que seu algoritmo possa treinar com dados de qualidade.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Então, finalmente terminamos o processamento de dados qualitativos e quantitativos separadamente - é hora de combiná-los de volta
new_df = pd.concat([df_numerical,df_categorical], axis=1)Depois de mesclar os conjuntos de dados em um, no final podemos usar a transformação de dados usando MinMaxScaler da biblioteca sklearn. Isso fará com que nossos valores variem de 0 a 1, o que ajudará no treinamento do modelo no futuro.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Esses dados agora estão prontos para qualquer coisa - para redes neurais, algoritmos de ML padrão e assim por diante!
Neste artigo, não levamos em consideração o trabalho com dados relacionados a séries temporais, pois para tais dados você deve usar técnicas de processamento ligeiramente diferentes, dependendo da sua tarefa. No futuro, nossa equipe dedicará um artigo à parte a este tema, e esperamos que seja capaz de trazer algo interessante, novo e útil para sua vida, como este.