
Hoje, sem referência a modelos específicos de equipamento de rede, contaremos como o princípio "da automação à autonomia" está incorporado nas novas capacidades do FabricInsight. Com efeito, nos últimos anos, não só mudou a sua composição, mas surgiram inúmeros novos cenários que permitem determinar o estado atual da rede e prever possíveis problemas nela.
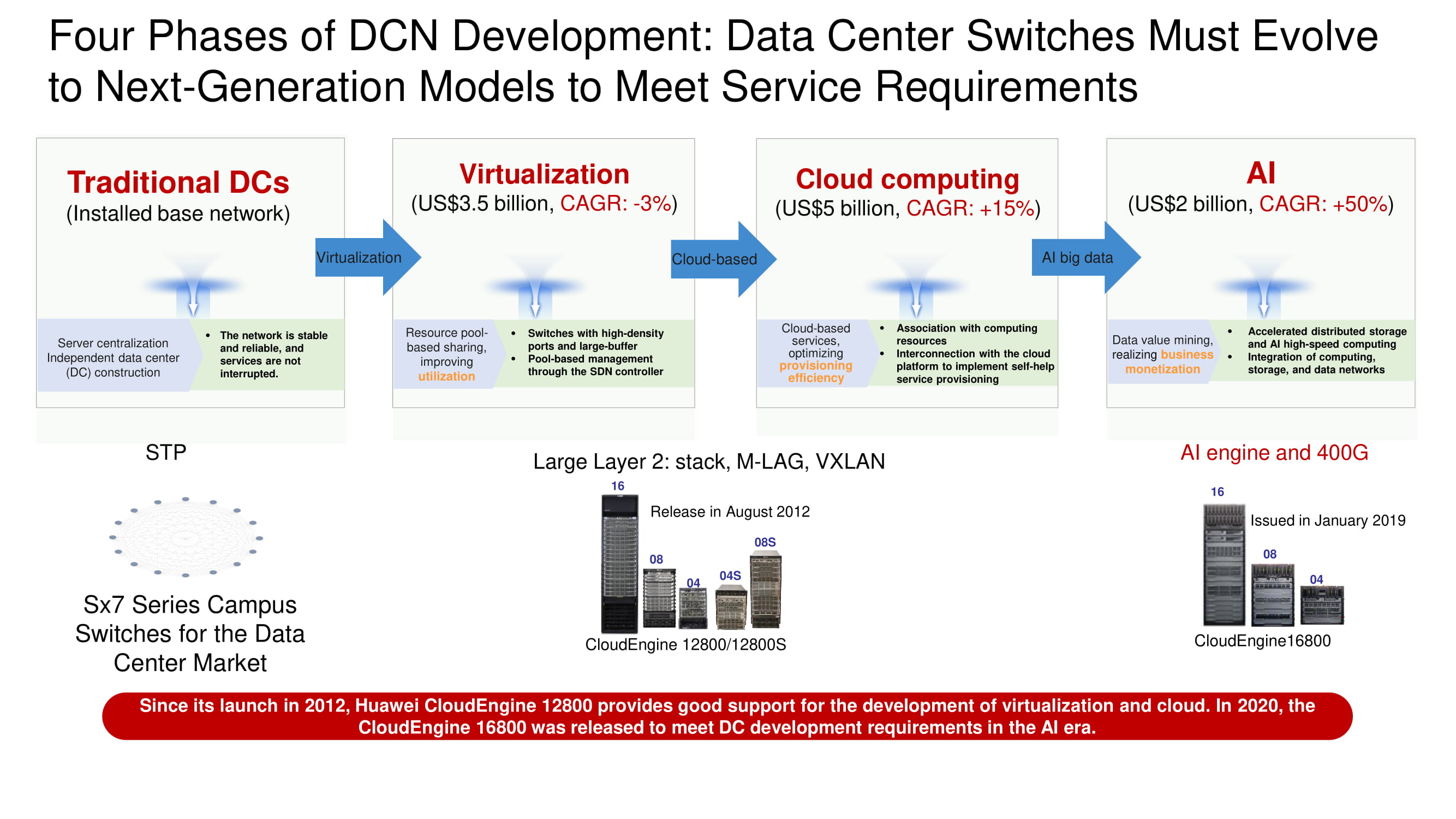
Quatro estágios de desenvolvimento de data center
Determinando o vetor de desenvolvimento de redes de data center, é fácil ver como as arquiteturas tradicionais de data center gradualmente caíram sob o ataque dos sistemas de virtualização, sobreviveram a uma migração massiva de recursos e serviços para as nuvens e agora chegaram perto da introdução generalizada de sistemas de inteligência artificial e interfaces de alta velocidade de 400 Gbps. Os recursos de IA são necessários para construir redes Ethernet sem perdas e criar aplicativos completamente imunes à latência.
Outra área de aplicação de IA é a análise e monitoramento do data center. Temos que passar de uma ideologia que implica monitoramento funcionalmente limitado do estado de algumas "caixas pretas" para o conceito de redes completamente transparentes sobre as quais tudo é conhecido.

Como as principais unidades de rede de infraestrutura para construção de redes de data center, a Huawei agora oferece uma linha de switches CloudEngine 16800 de quatro, oito e dezesseis slots com uplinks de 400 Gbps; seu lançamento está agendado para o ano corrente. Também entre os novos produtos, notamos os switches CloudEngine 6881 e 6863 ToR construídos em nossa própria base de elemento com interfaces de 10 e 25 Gbps, respectivamente.

A ilustração mostra os modelos de switches da linha CloudEngine 16800 com arquitetura ortogonal clássica, equipados com sistema de resfriamento front-to-back, além de placas de linha compatíveis com interfaces de 10, 40 e 100 Gb / s.
Dentre as funções básicas importantes do CloudEngine 16800, destacamos sua capacidade de trabalhar com NSH (Network Service Header), que permite a implementação de microssegmentação distribuída por vários switches no data center (isolamento no nível da máquina virtual), fornecendo amplos recursos de telemetria e analisando o tráfego na borda da rede (inteligência de borda ) usando tecnologias de inteligência artificial baseadas em chips Huawei AI.
O V1R19C10 será verdadeiramente revolucionário. É nele que muitas funções há muito aguardadas devem ser implementadas, incluindo EVPN Multihoming sem um "jumper" na forma de M-LAG (Multi-Switch Link Aggregation) baseado no primeiro e quarto tipos de rotas no roteamento EVPN VXLAN.
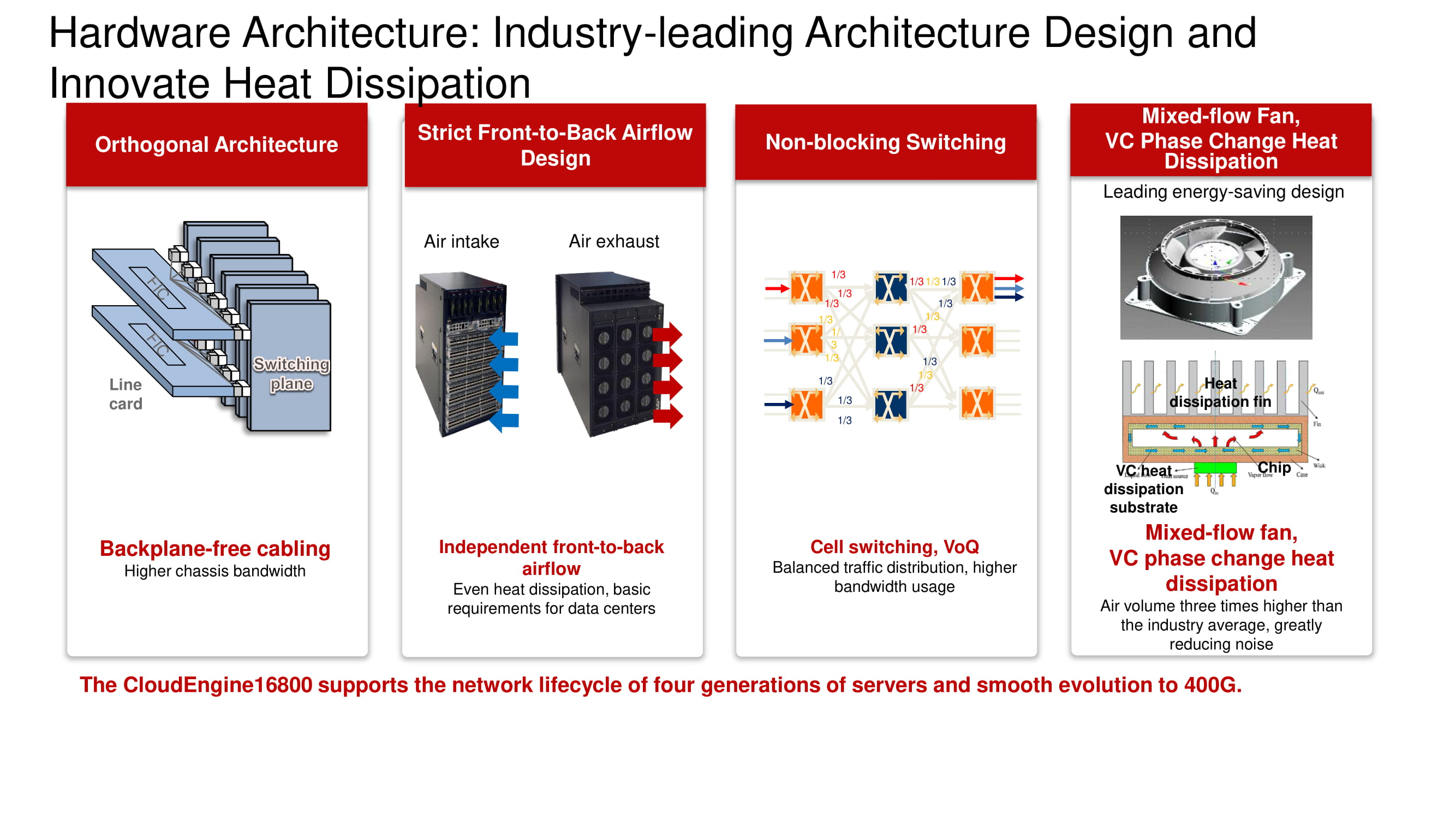
Arquitetura familiar e novas possibilidades
O diagrama mostra a arquitetura ortogonal familiar da Comutação sem bloqueio "de fábrica" de três camadas. Suas principais vantagens incluem o arranjo ideal das placas de "fábrica", placas de linha, conectores e um sistema de sopradores baseado em ventiladores de velocidade variável.
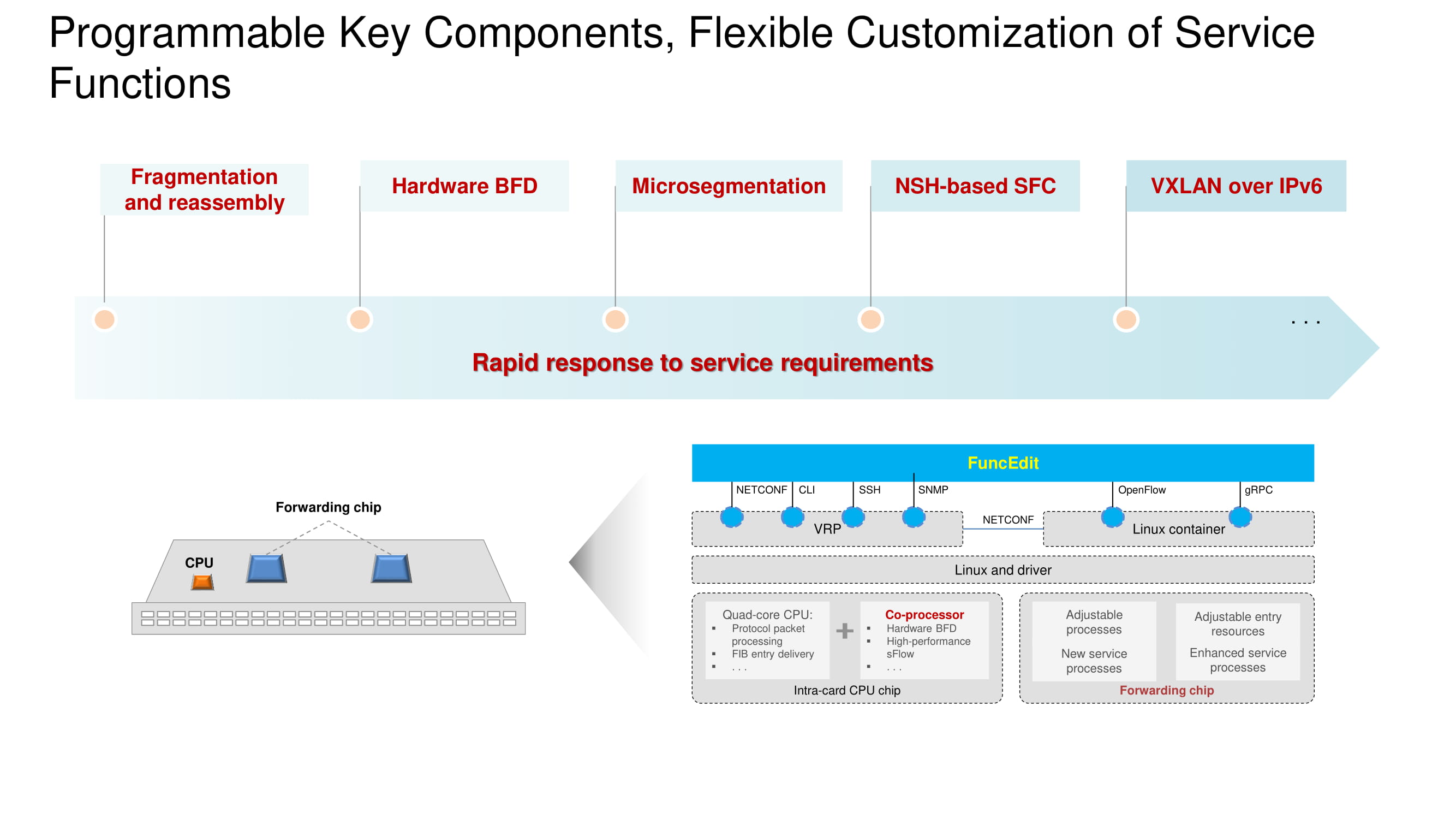
É importante que o protocolo BFD (Bidirectional Forwarding Detection) seja implementado por hardware nos novos modelos de switch e seja possível configurar a VXLAN no espaço de endereço IPv6. A arquitetura básica permanece a mesma e é baseada em um processador, coprocessador e chip de encaminhamento. A funcionalidade de cada um dos nós é mostrada no diagrama. A principal mudança em 2020 é a transição para os próprios chips da Huawei em switches carro-chefe, competindo totalmente com seus equivalentes da Broadcom.
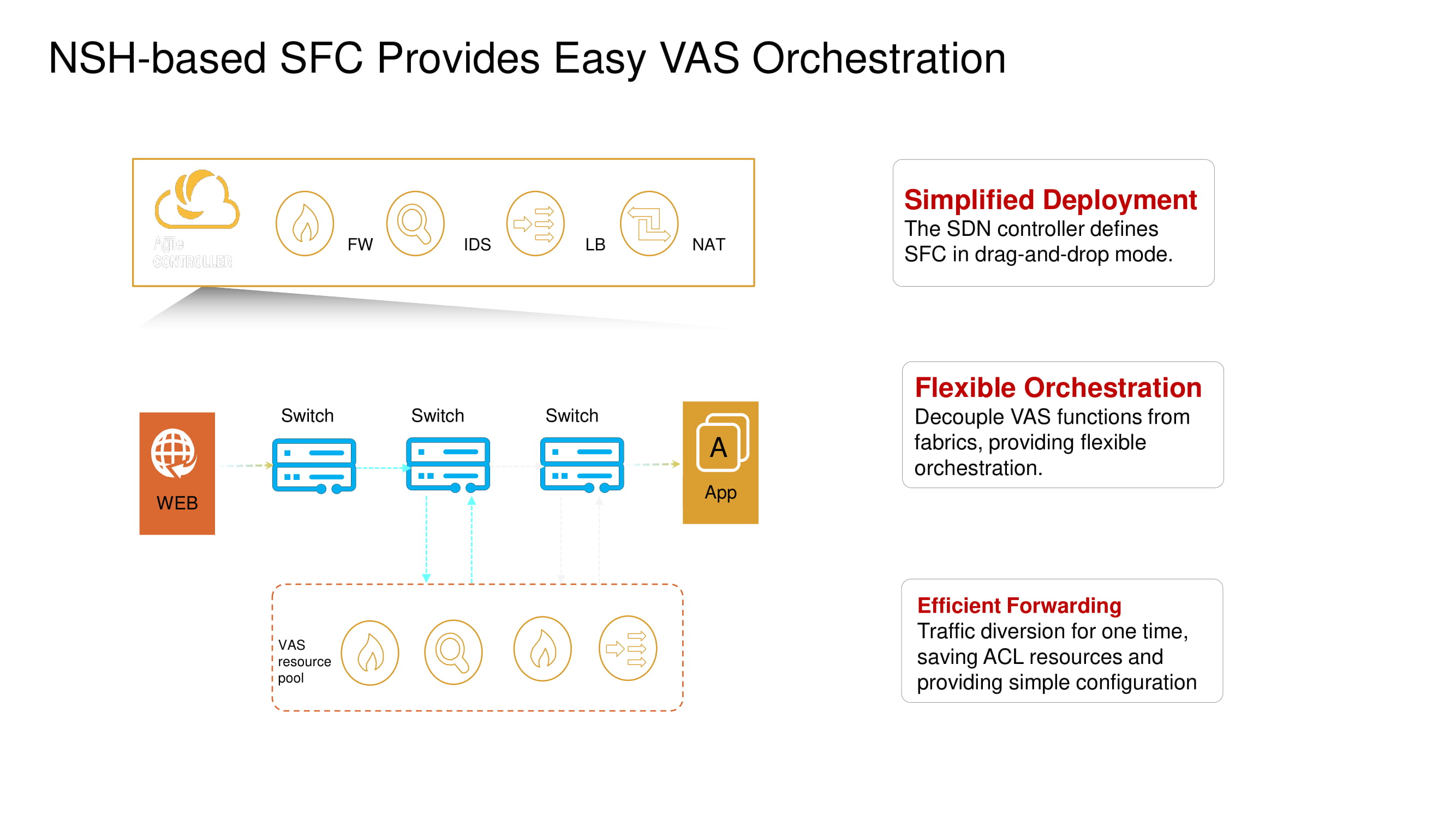
O suporte para operações do Network Service Header permite que novos switches alterem as rotas de pacote VXLAN padrão e habilitem serviços como firewalls (FW), sistemas de detecção de intrusão (IDS), balanceadores de carga (SLB) e NAT.
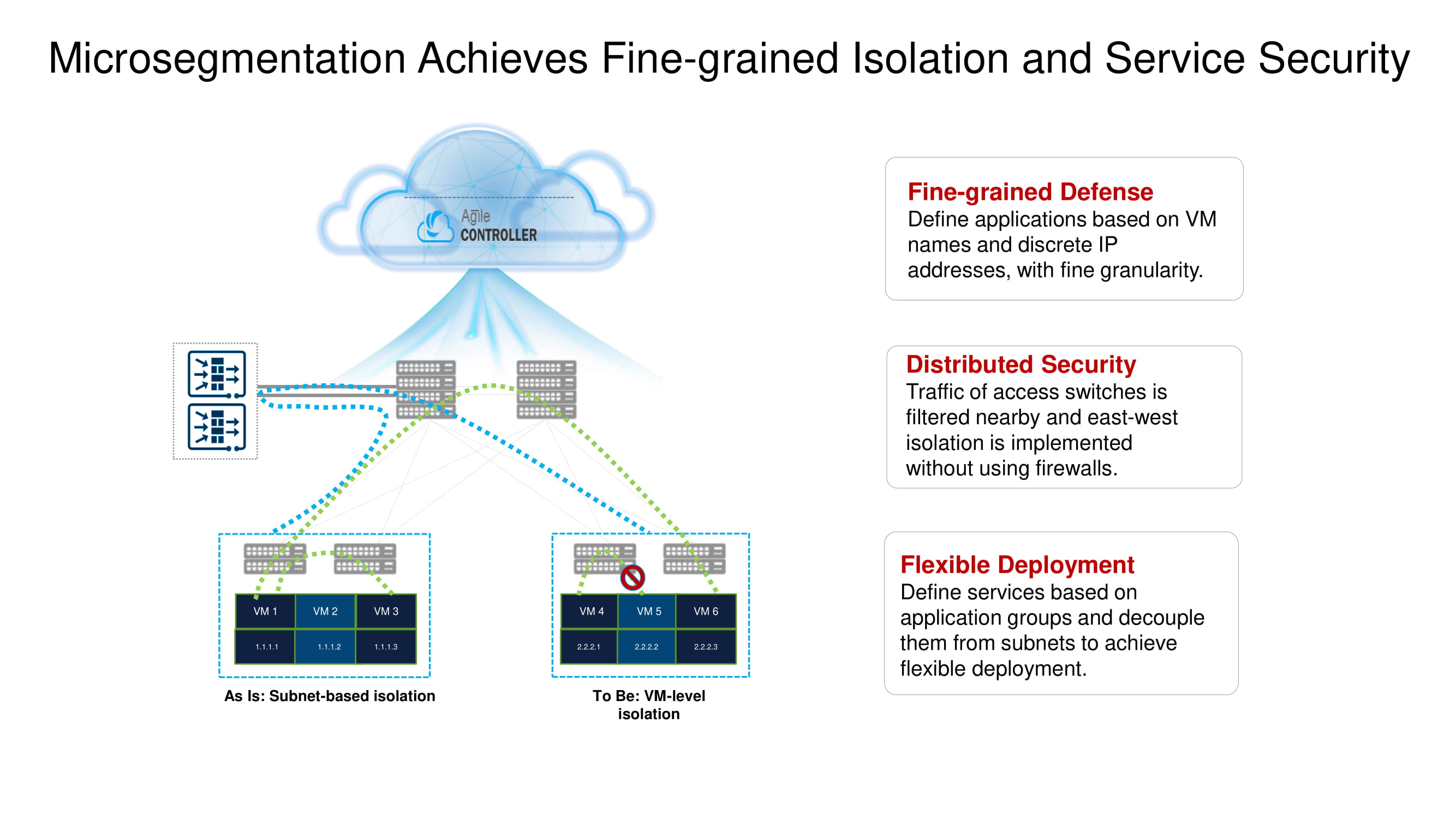
Voltemos brevemente à microssegmentação dividida mencionada anteriormente. Os novos switches Huawei ToR com a ajuda do mesmo NSH permitem isolar cargas de trabalho no nível de nomes de máquinas virtuais. Essas máquinas podem ser agrupadas posteriormente no nível de sub-rede com base nos números de porta, protocolos superiores, etc., formando assim grupos de aplicativos.
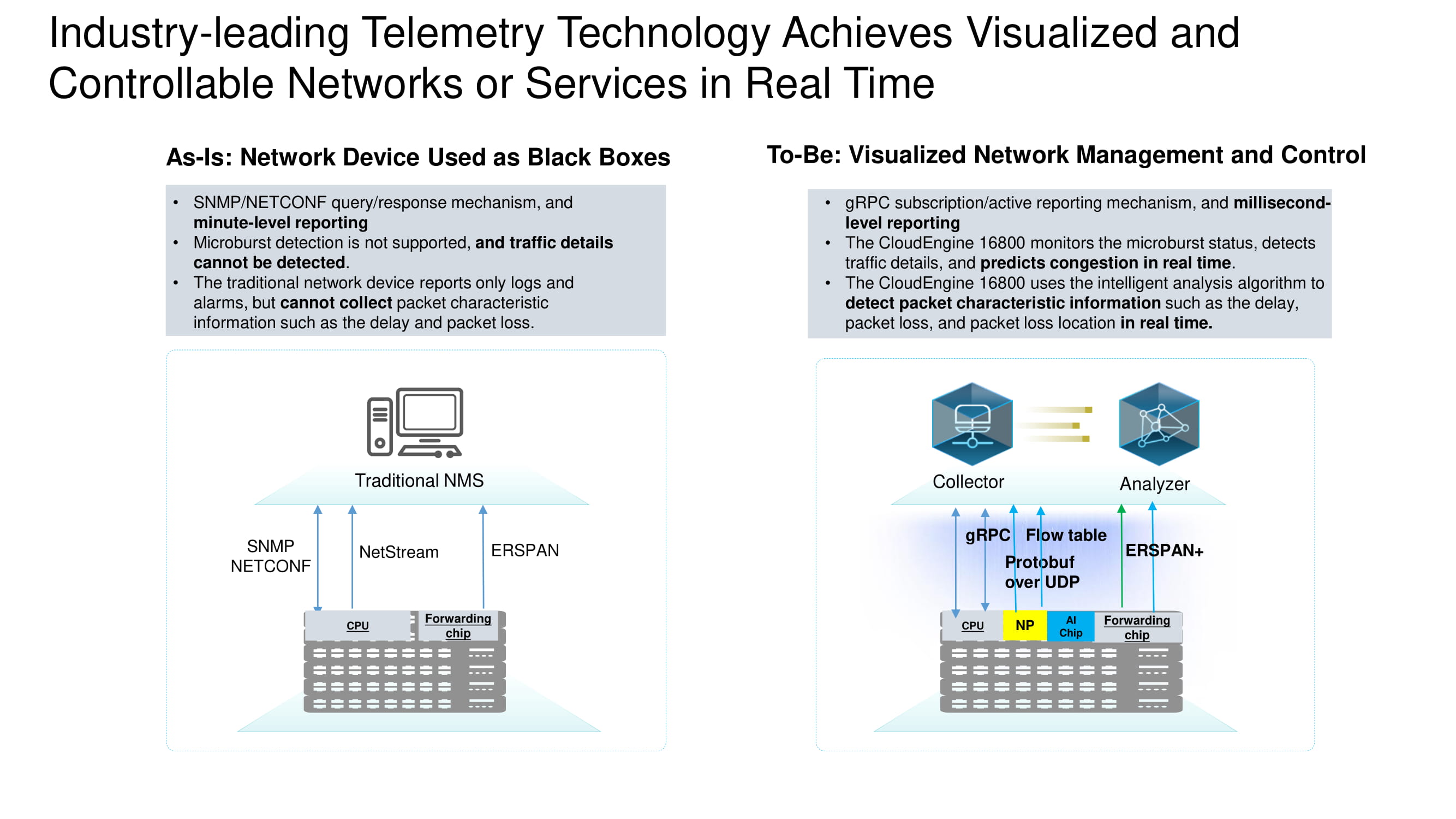
Gama completa de dados de telemetria
As informações dos dispositivos são coletadas em tempo real usando vários protocolos principais. A tarefa do ERSPAN + é coletar cabeçalhos TCP para a análise detalhada subsequente de fluxos TCP no data center. Dados adicionais são extraídos usando o protocolo gRPC e a tabela de fluxo. Tudo isso é coletado com Protobuf sobre UDP.
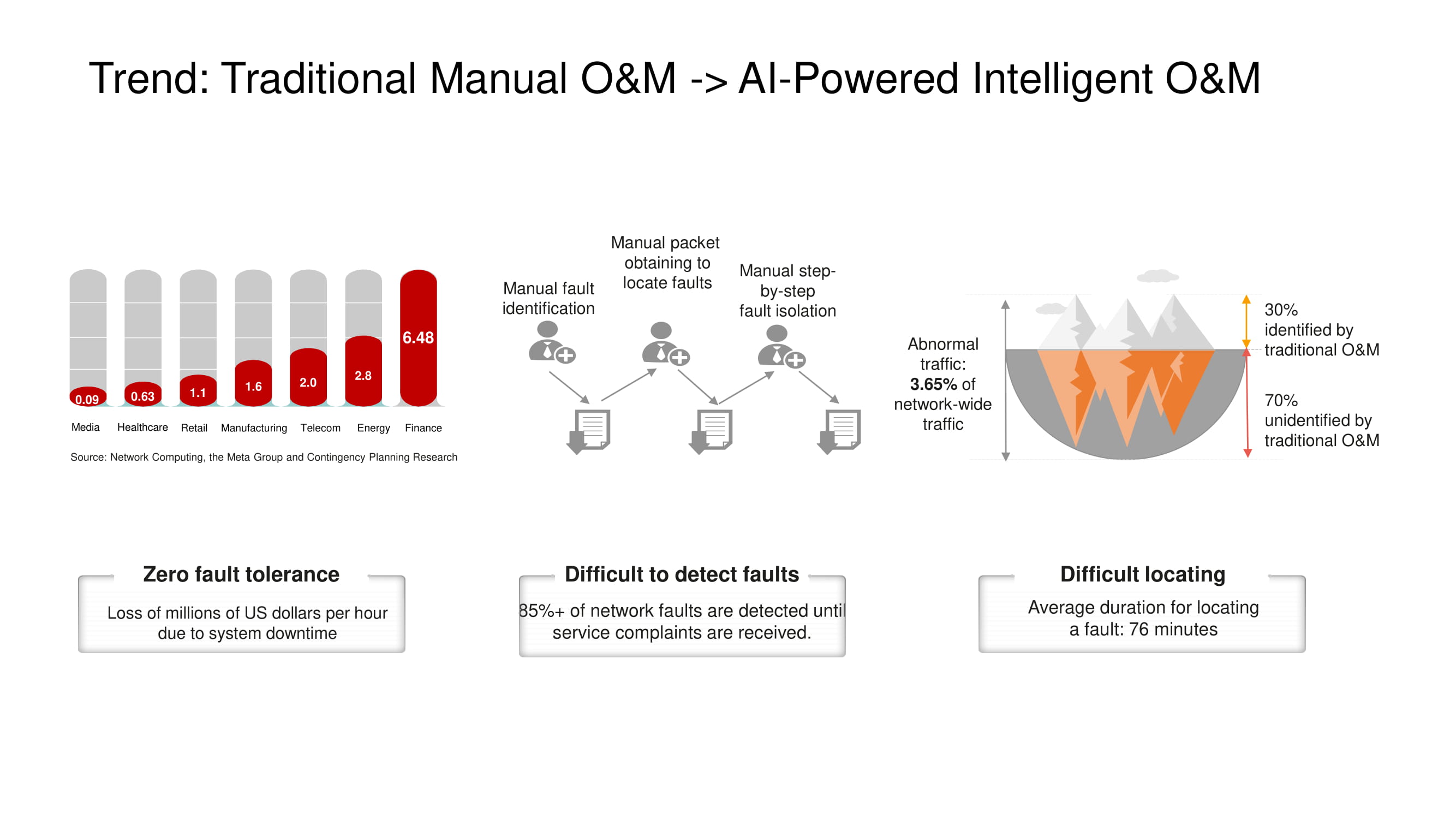
A principal direção do desenvolvimento de ferramentas de O&M na Huawei é a transição do controle de rede manual ou semiautomático para o totalmente automático , baseado em tecnologias de inteligência artificial. Um sistema de telemetria abrangente de um site bastante grande produz enormes quantidades de dados, cuja análise em um curto espaço de tempo só é possível com o uso de IA. Isso é especialmente importante nos data centers, onde falhas e tempo de inatividade são simplesmente inaceitáveis.
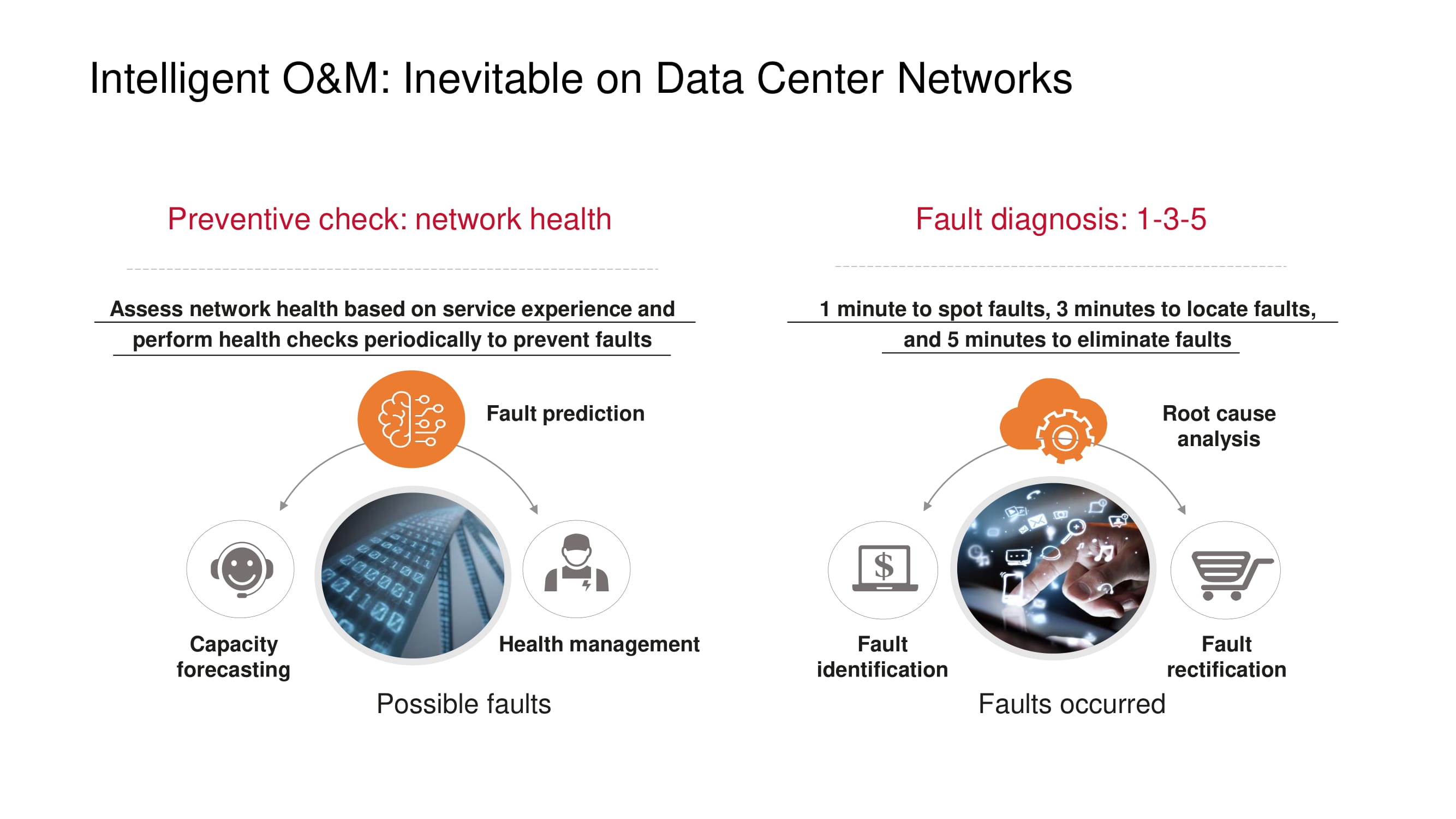
As medidas preventivas destinadas a prevenir problemas com a rede incluem, em primeiro lugar, a monitorização do "estado" da rede: monitorizar a carga do canal, identificar as causas da perda de pacotes (por exemplo, procurar uma correlação com a hora do dia ou períodos de funcionamento de uma aplicação), detectar " gargalos (previsão de capacidade), etc.
Se os problemas ainda forem observados, o princípio 1-3-5 proposto pela Huawei ajuda a minimizar o tempo de diagnóstico e recuperação: um minuto para pesquisar, três minutos para localizar, cinco minutos para eliminar o problema. Para se manter dentro dessa estrutura, os produtos da Huawei oferecem suporte a uma lista cada vez maior de falhas típicas que são detectadas automaticamente.

Modelo V100R019C10 para pequenos data centers
Uma das principais inovações do V100R019C10 é o suporte para visualização baseada em dados de telemetria em todos os tipos de cenários. Na verdade, estamos falando de uma exibição visual de todas as mudanças na rede. Além disso, o dispositivo agora é capaz de determinar mais de 75 causas raiz de certos problemas e ajuda a delinear ações para eliminá-los (scripts de inicialização, etc.).
Uma notícia importante foi o surgimento da versão Standalone, que inclui o iMaster NCE e o FabricInsight e se destina principalmente a pequenos data centers que não requerem vários servidores para gerenciar a rede.
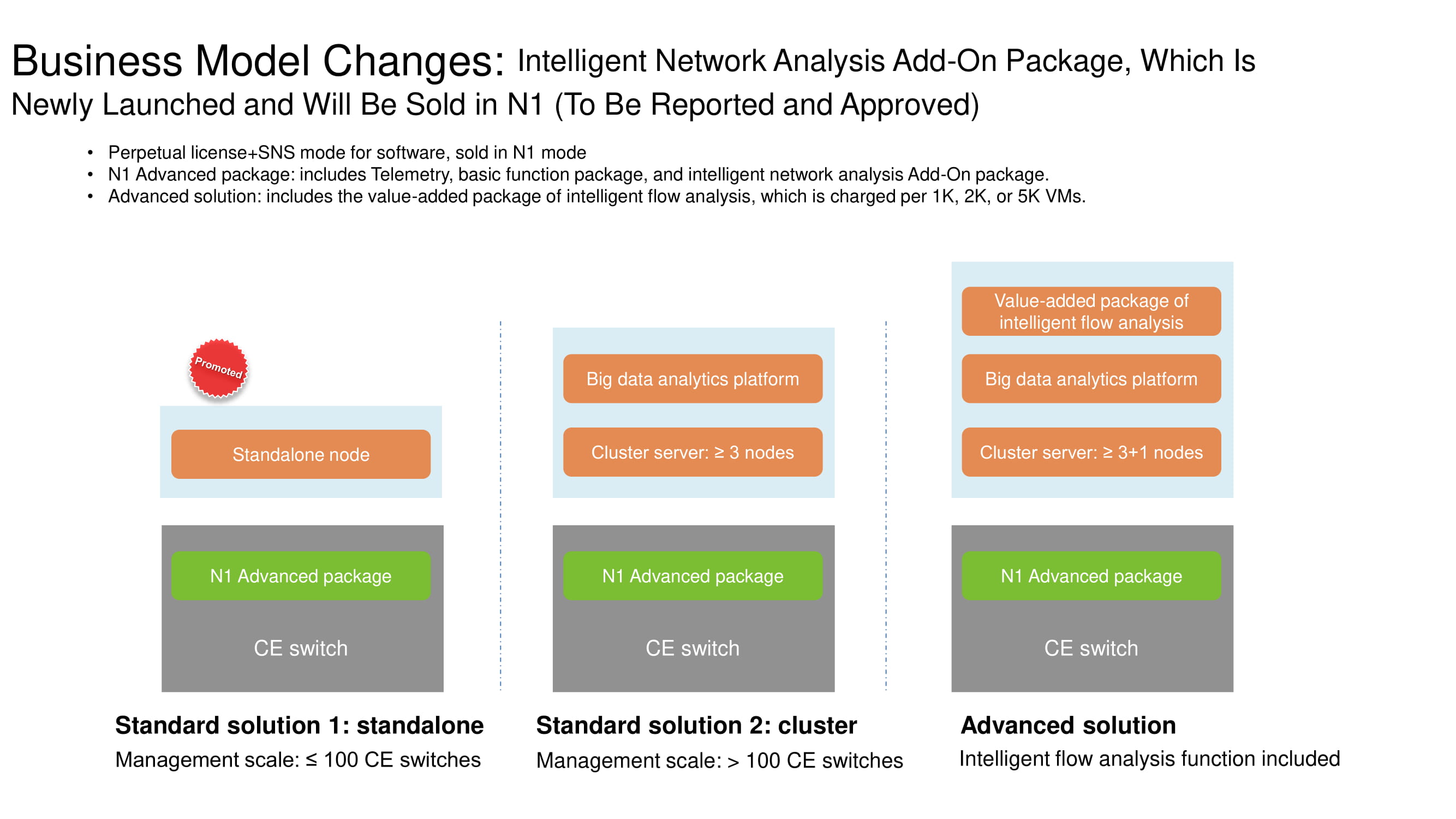
Mudanças no sistema de licenciamento
Para entender melhor os recursos funcionais do FabricInsight, deve ser explicado quais mudanças ocorreram no modelo de negócios para a distribuição de produtos de rede Huawei. Se o número de switches não chegar a cem, esta opção é classificada como edição independente e implica em uma licença N1. Um cluster de três ou mais servidores já está empacotado com uma plataforma de análise de big data. A solução Avançada, que inclui várias centenas de switches, é recomendada para ser usada em conjunto com ferramentas para analisar fluxos de rede. Todas as três opções permitem recursos do FabricInsight com uma licença N1.
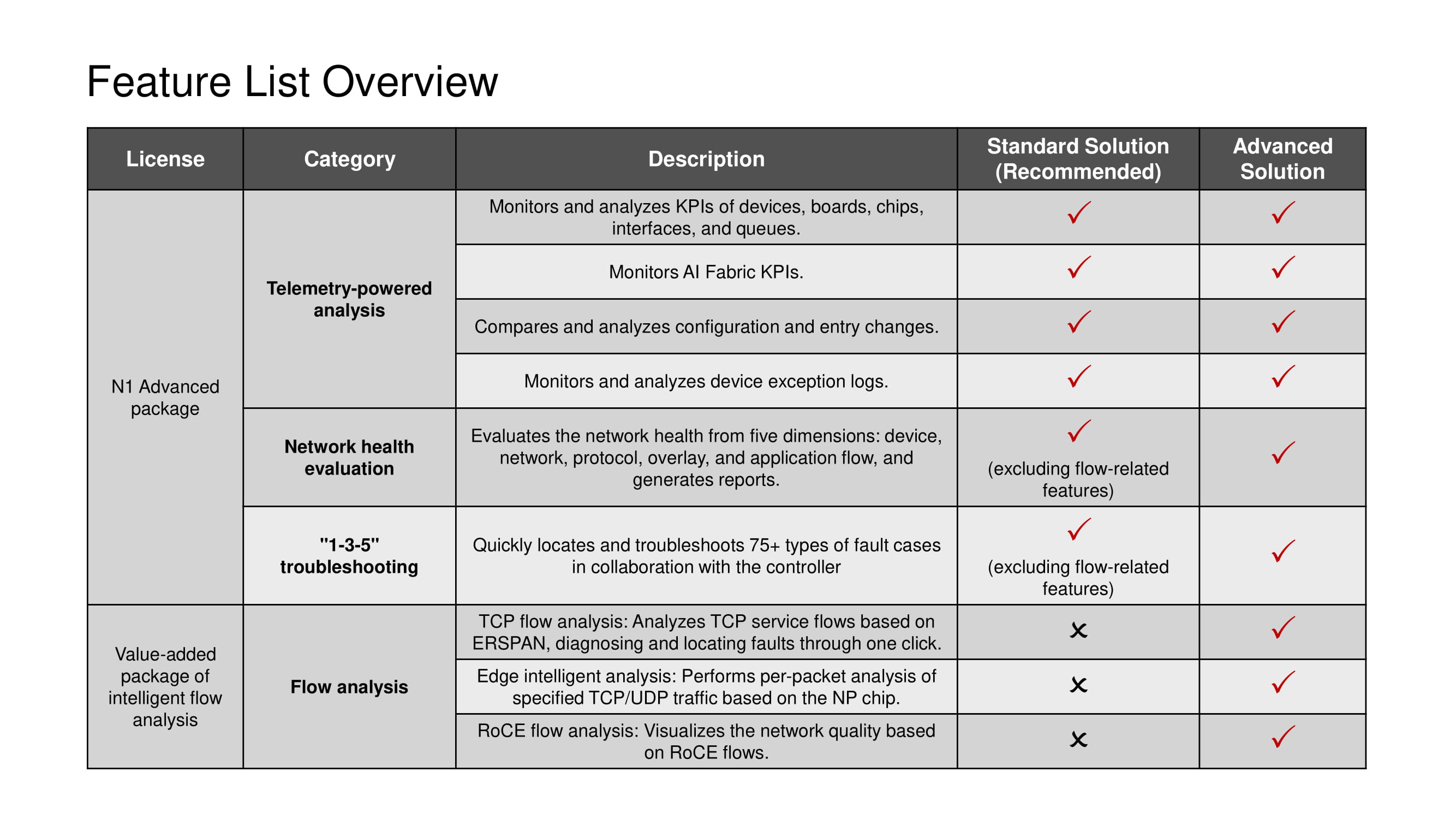
Qualquer licença implica o uso de todo o conjunto de ferramentas de telemetria e cenários 1-3-5, com exceção das ferramentas de análise de fluxo TCP disponíveis apenas na solução Avançada.
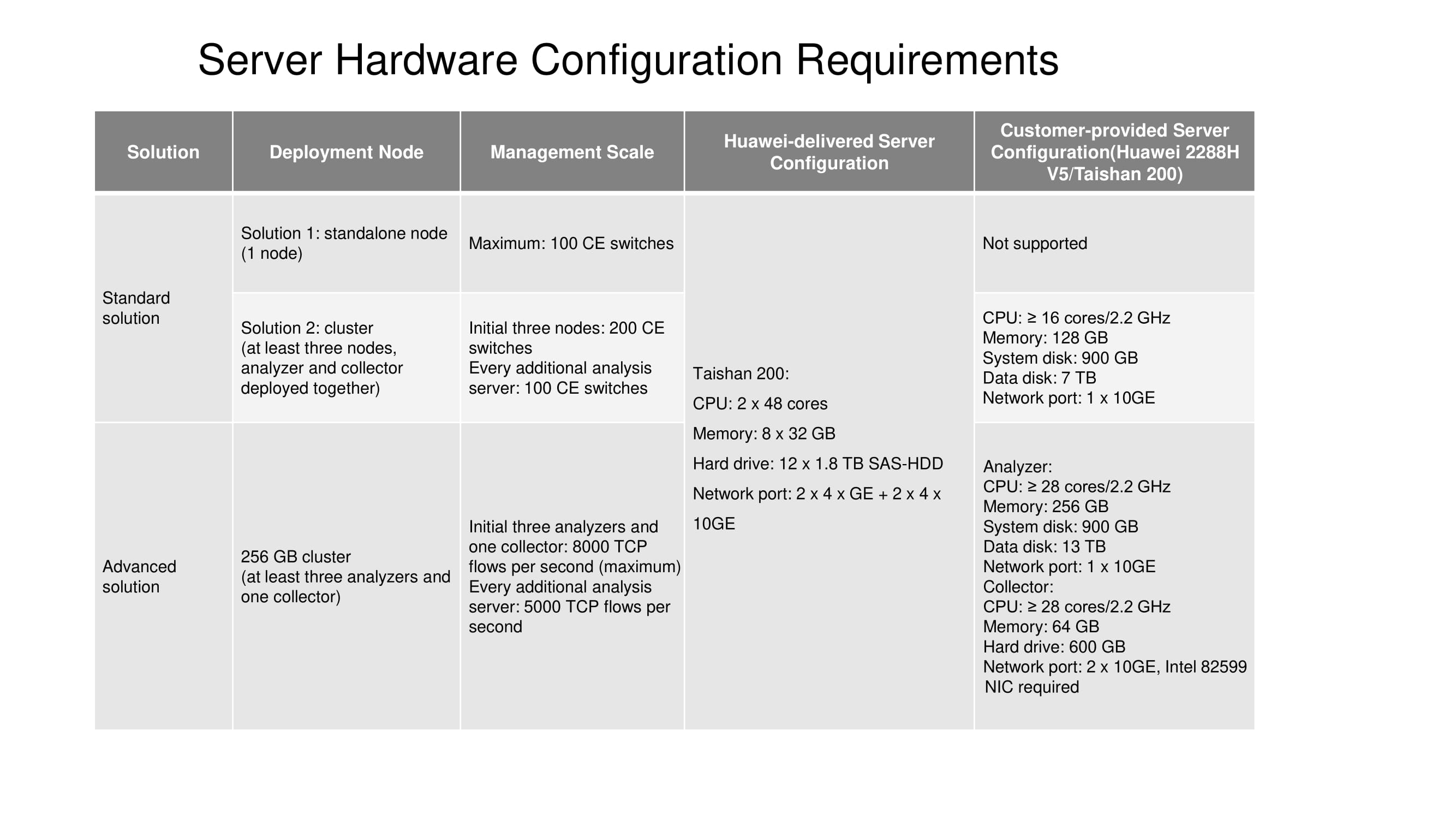
Resta informá-lo sobre as configurações de servidor projetadas para soluções padrão e avançadas. Atualmente, um nó autônomo (um nó) está disponível apenas no servidor Taishan 200. Um cluster de três nós requer 16 ou mais núcleos de computação, 128 GB de RAM, etc. (consulte o diagrama). O tamanho do disco de dados depende diretamente de quanto tempo as estatísticas devem ser armazenadas.

Monitoramento de KPI
Vamos dar uma olhada mais de perto no monitoramento de KPI. Para utilizá-lo, basta definir um intervalo de tempo e valores limites específicos, cujo alcance será verificado com base nos dados de telemetria recebidos. Existem muitos tipos de métricas disponíveis, incluindo:
- CPU e uso de memória;
- uso de FIB / MAC;
- uso da memória associativa ternária (TCAM) do chip;
- parâmetros de porta;
- o tamanho do buffer da fila;
- diferentes métricas de AI Fabric;
- nível de sinal, temperatura e outros parâmetros do módulo óptico;
- perda de pacotes.
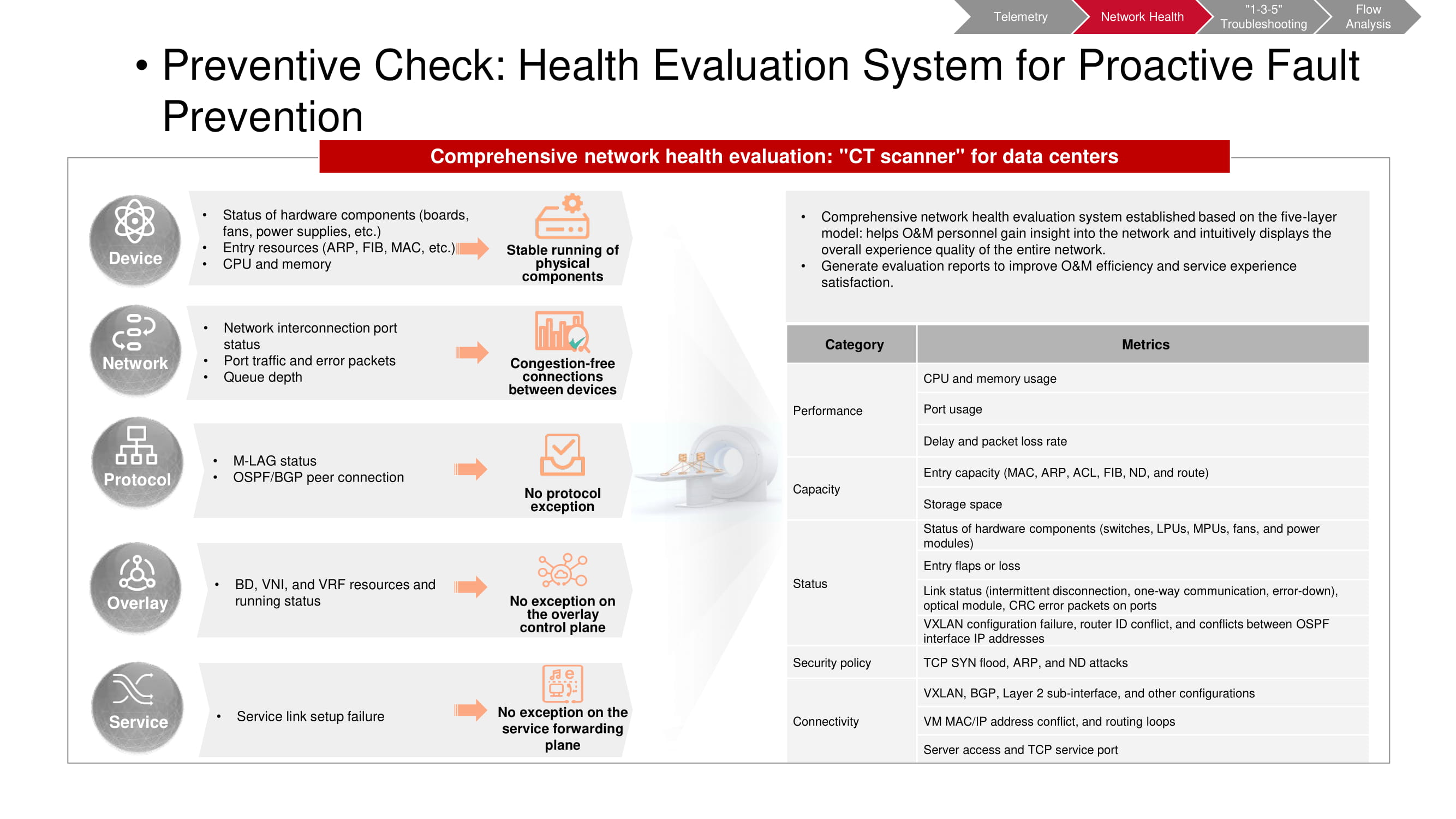
Verificação preliminar
A ferramenta de pré-verificação também opera em dados de telemetria. O tomógrafo permite que você entenda se certos eventos indesejados ocorreram na rede. Algumas das métricas coincidem com as métricas de monitoramento de KPI da "fábrica" (principalmente relacionadas à capacidade e desempenho). O resto é baseado nos resultados da análise de nível superior (VXLAN, BGP, etc.) e análise de configuração. Após iniciar o tomógrafo, ele coleta as informações necessárias e gera um relatório abrangente sobre o estado da rede.
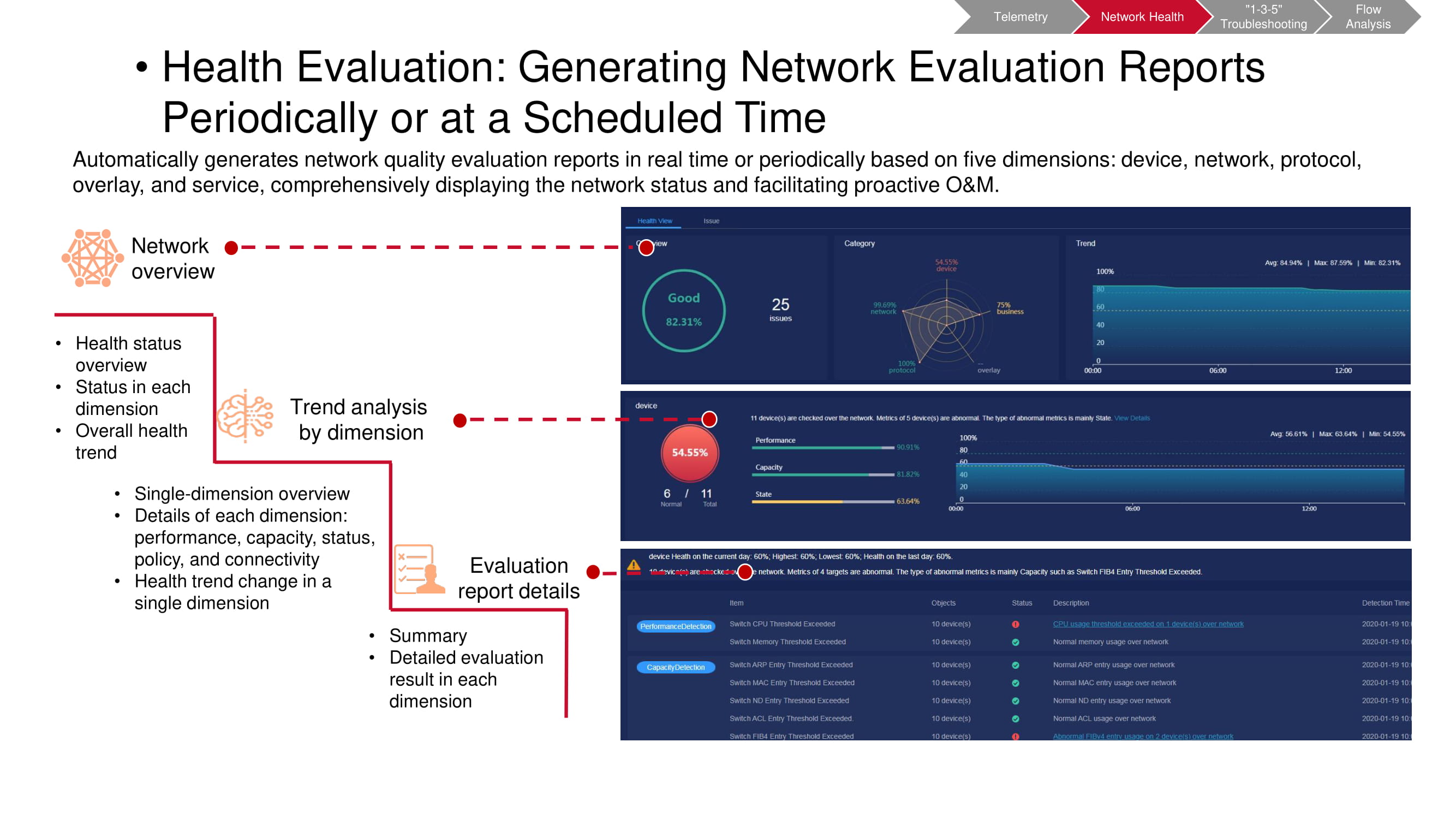
É necessário realizar tais verificações regularmente, tendo predeterminado os intervalos de tempo entre elas. Isso torna mais fácil identificar as tendências emergentes na rede no tempo, incluindo mudanças periódicas e não periódicas. Isso permite que você entenda de maneira muito mais completa e rápida o que exatamente está acontecendo. Além disso, qualquer parâmetro de interesse particular pode ser selecionado para monitoramento mais detalhado.
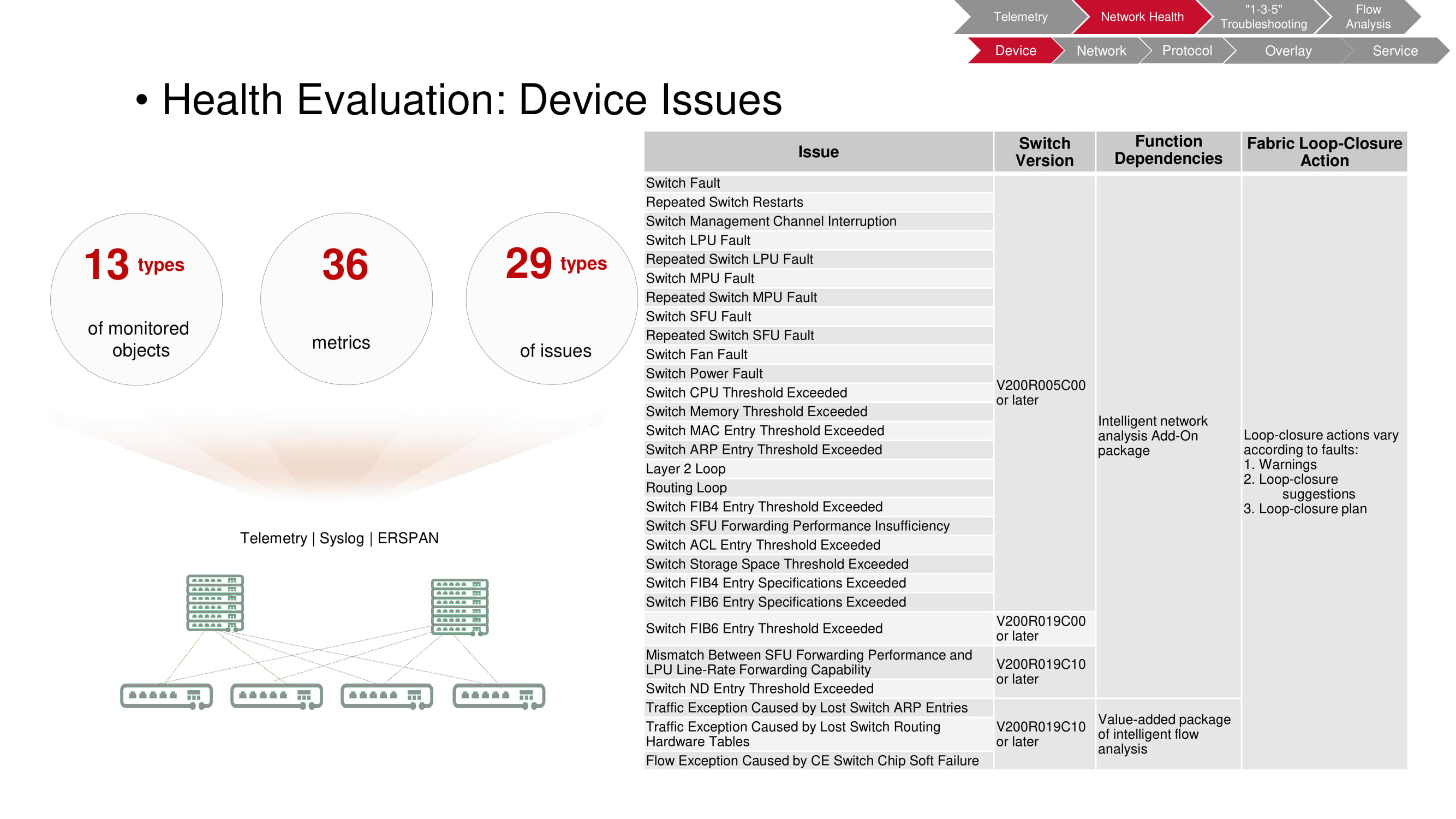
Problemas de dispositivo
O monitoramento permite que você identifique uma ampla variedade de problemas que surgem no nível do dispositivo. Neste caso, o objeto de verificação é uma chave, dos quais 36 dos parâmetros de operação registrados permitem detectar 29 tipos de falhas.
A tabela no diagrama lista os tipos de falhas; modelos de switch que permitem ao FabricInsight detectar o problema; funções usadas pelo FabricInsight; ações automáticas tomadas quando os problemas são detectados (avisos, recomendações, lançamento de script).
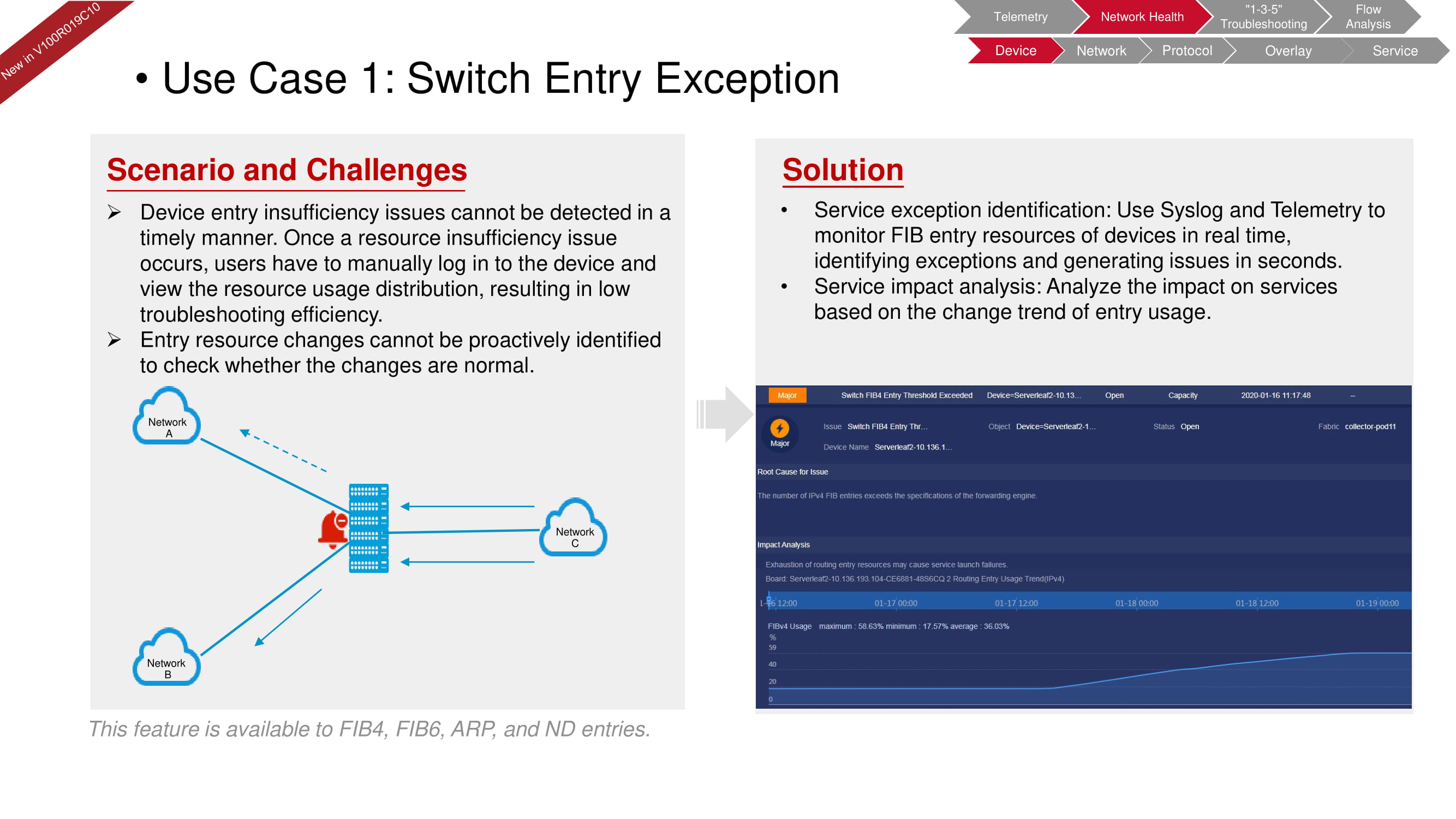
Digamos que o dispositivo tenha uma escassez de recursos levando a uma queda no nível de serviço. Os dados do log do sistema, combinados com os dados de telemetria dos recursos FIB, permitem avaliar rapidamente a situação no modo de verificação manual.
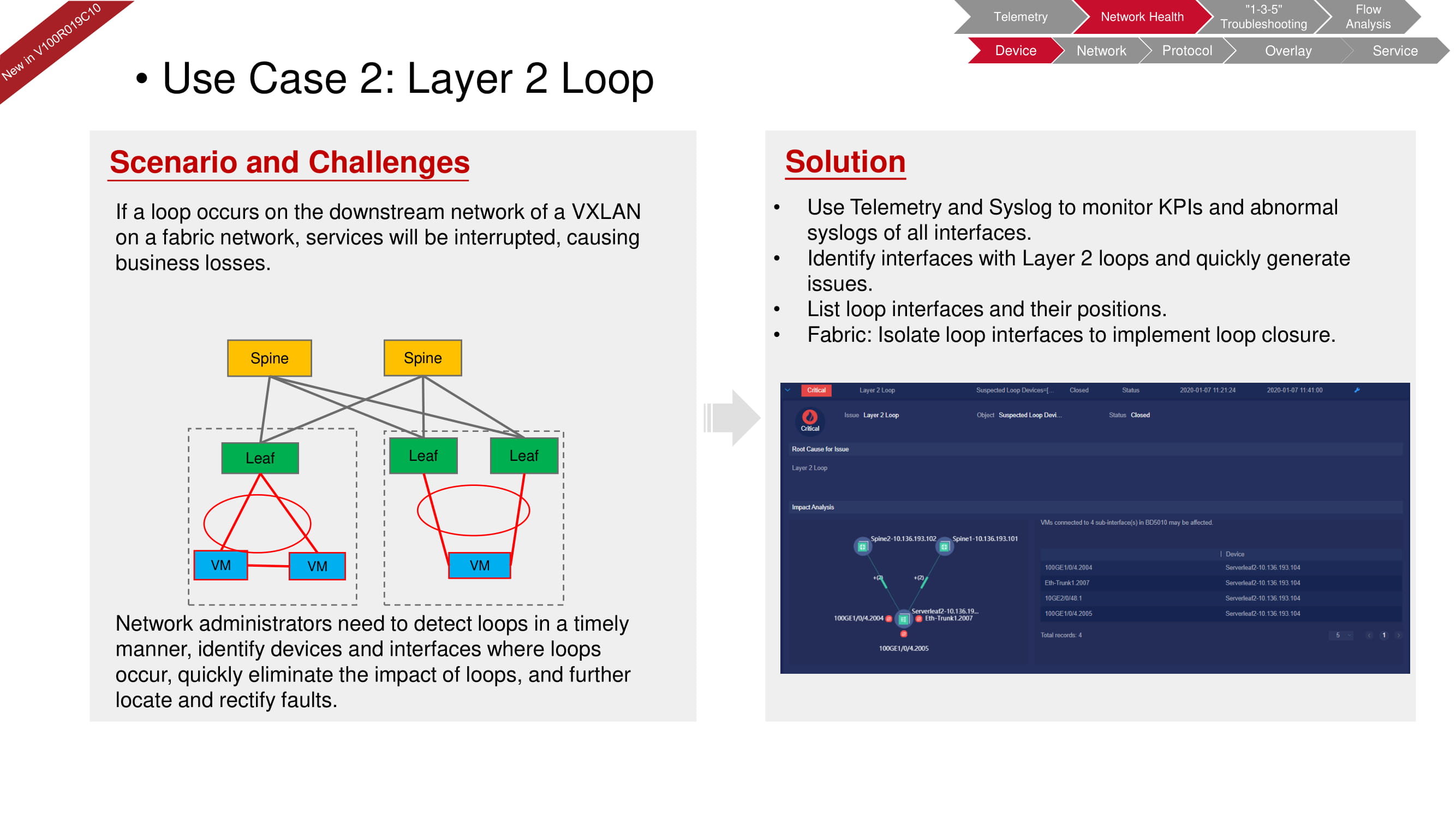
Simplesmente não é possível que ocorra um loop no nível do hardware, uma vez que o dispositivo não permitirá que tal erro seja introduzido na configuração. No entanto, um loop pode ocorrer, por exemplo, no segundo nível (no nível da máquina virtual) devido a um switch de software configurado incorretamente, como no diagrama acima. Com o FabricInsight, você pode não apenas detectar um problema, mas também isolar a seção desejada da rede para eliminar seu impacto no funcionamento de toda a "malha".

Problemas de rede
Com base em 18 métricas disponíveis para análise, o FabricInsight identifica 10 tipos de problemas de rede. O diagrama fornece uma lista completa deles, bem como - como no caso de problemas de dispositivo - os modelos de switch que permitem ao FabricInsight detectar o problema, as funções usadas e as ações automáticas disponíveis.

Suponha que a degradação ou mau funcionamento de um módulo óptico leve a uma deterioração em seu desempenho: o link se torna instável. Essas situações ocorrem de forma irregular e são difíceis de reproduzir. A localização do problema pode demorar muito. Com o FabricInsight, você pode notar imediatamente uma queda no nível do sinal ou uma mudança na tensão em um módulo.
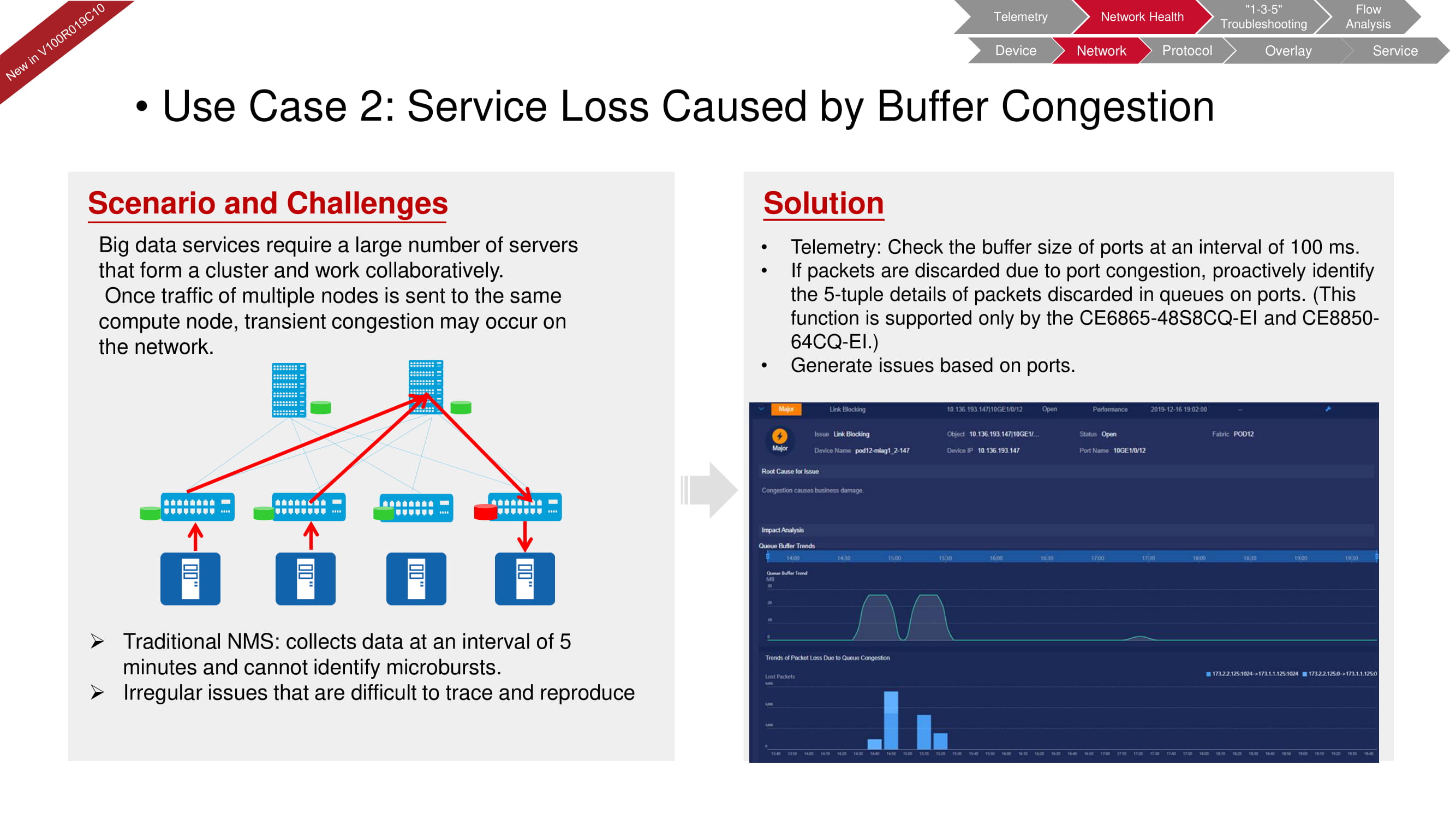
O diagnóstico de rede fabricInsight também pode identificar prontamente problemas de buffer que geralmente ocorrem em sistemas com um grande número de servidores que são dedicados ao processamento de big data. O NMS (Network Management System) tradicional verifica os parâmetros relacionados ao buffer a cada cinco minutos. Os recursos de telemetria do FabricInsight podem reduzir esses intervalos para 100 ms e detectar até mesmo os microincidentes mais curtos.

Problemas no nível do protocolo
Aqui, o FabricInsight é capaz de identificar seis tipos de problemas, incluindo um conflito entre duas chaves mestras no M-LAG; problemas com a interação de switches vizinhos, etc. Esta funcionalidade está disponível ao usar switches V200R005C00 e mais recentes.

Considere o conflito de interruptores principais. Com todas as vantagens da tecnologia M-LAG, em caso de quebra de link e falha de rede ponto a ponto, aparecem dois interruptores mestres no sistema. O FabricInsight é capaz de reagir proativamente a tal situação monitorando constantemente o estado do link de mesmo nível e DFS.

Problemas de rede de sobreposição
Sete tipos de problemas de rede de sobreposição podem ser identificados monitorando dez métricas diferentes. O FabricInsight pode verificar o status da licença VXLAN, localizar erros de configuração, detectar travamentos de subinterface etc. As opções de resposta são semelhantes às descritas anteriormente.

Problemas de serviço
Sete métricas são monitoradas para identificar seis tipos de problemas de nível de serviço. Podem ser detectados conflitos de endereços IP, problemas de conexão, ataques de inundação TCP SYN, etc. Observe que, para oferecer suporte a esses recursos do FabricInsight, pode ser necessário um analisador de fluxo TCP.
Com uma visão mais ampla da solução de problemas, o FabricInsight é mais do que apenas um coletor de dispositivos, mas uma biblioteca extensível de scripts que aborda uma ampla variedade de tipos de problemas.

Da automação à autonomia
Em resumo, digamos que a ideologia da Rede Orientada a Intenções se baseie em um modelo de resposta em três estágios, que inclui a coleta de informações, sua análise por meio de IA e propostas de mudança de estado da rede, inclusive em modo automático.
***
Lembramos que nossos especialistas realizam webinars regularmente sobre os produtos Huawei e as tecnologias que eles usam. Uma lista de webinars para as próximas semanas está disponível aqui .