
Por que os petroleiros precisam da PNL? Como você faz um computador entender o jargão profissional? É possível explicar para a máquina o que é "pressão", "resposta do acelerador", "anular"? Como os novos contratados e o assistente de voz são conectados? Tentaremos responder a essas questões no artigo sobre a introdução do assistente digital no software de apoio à produção de petróleo, que facilita o trabalho rotineiro de um geólogo-desenvolvedor.
Nós do instituto estamos desenvolvendo nosso próprio software ( https://rn.digital/ ) para a indústria do petróleo, e para que seus usuários se apaixonem, você precisa não apenas implementar funções úteis nele, mas também pensar na conveniência da interface o tempo todo. Uma das tendências em UI / UX hoje é a transição para interfaces de voz. Afinal, digam o que se diga, a forma mais natural e conveniente de interação para uma pessoa é a fala. Assim, foi decidido desenvolver e implementar um assistente de voz em nossos produtos de software.
Além de melhorar o componente UI / UX, a introdução do assistente também permite reduzir o "limite" para novos funcionários trabalharem com software. A funcionalidade de nossos programas é extensa e pode levar mais de um dia para descobri-la. A capacidade de "pedir" ao assistente para executar o comando necessário reduzirá o tempo gasto na resolução da tarefa, bem como reduzirá o estresse de um novo trabalho.
Como o serviço de segurança corporativa é muito sensível à transferência de dados para serviços externos, pensamos em desenvolver um assistente baseado em soluções de código aberto que permitem o processamento de informações localmente.
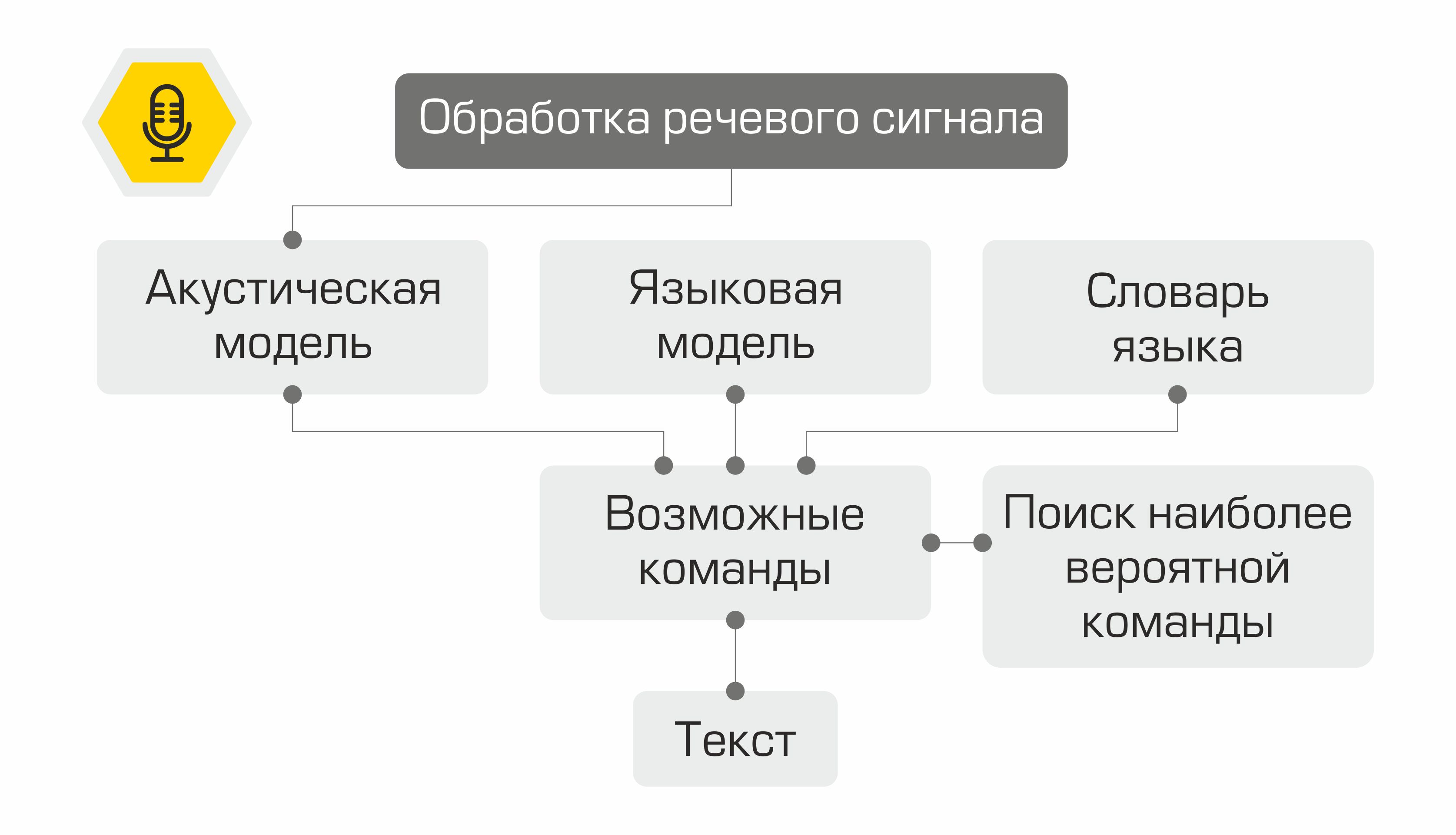
Estruturalmente, nosso assistente consiste nos seguintes módulos:
- Reconhecimento de fala (ASR)
- Alocação de objetos semânticos (Natural Language Understanding, NLU)
- Execução de comando
- Síntese de fala (Text-to-Speech, TTS)
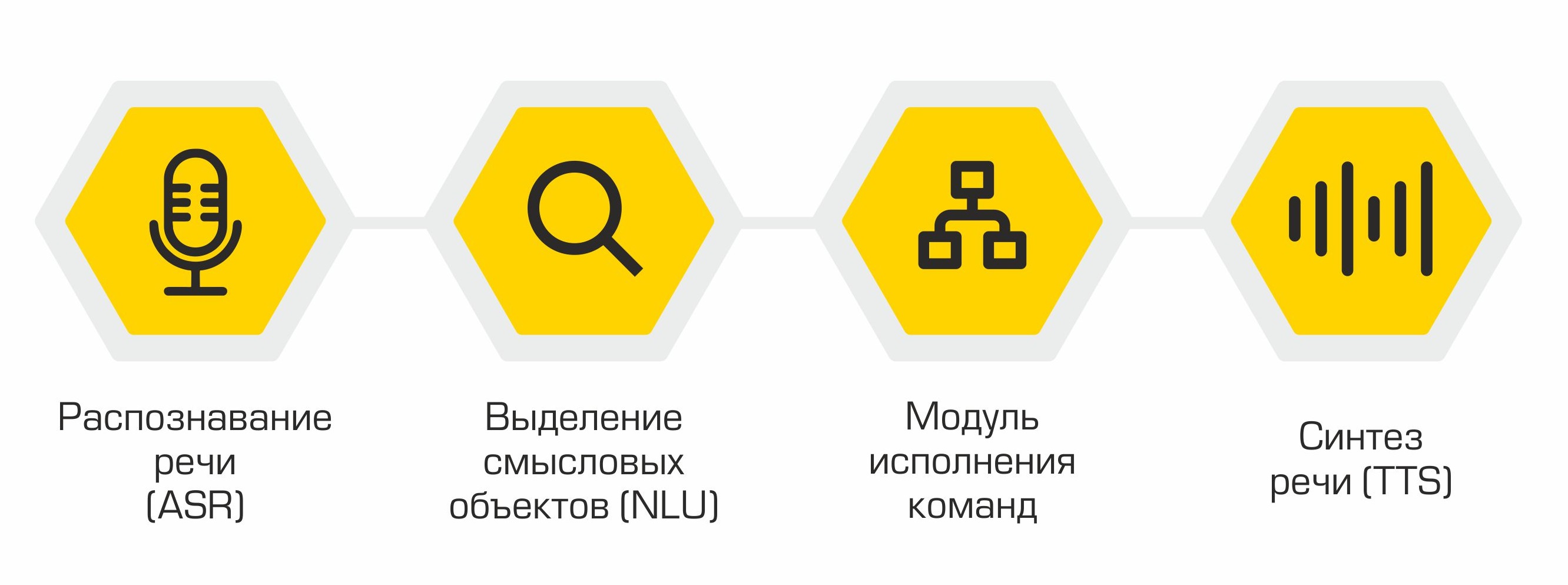
O princípio do assistente: das palavras (usuário) às ações (no software)!
A saída de cada módulo serve como ponto de entrada para o próximo componente do sistema. Assim, a fala do usuário é convertida em texto e enviada para processamento em algoritmos de aprendizado de máquina para determinar a intenção do usuário. A depender dessa intenção, a classe requerida é ativada no módulo de execução de comandos, que atende a solicitação do usuário. Após a conclusão da operação, o módulo de execução de comando transmite informações sobre o status de execução do comando para o módulo de síntese de voz, que, por sua vez, notifica o usuário.
Cada módulo auxiliar é um microsserviço. Assim, se desejar, o usuário pode prescindir das tecnologias de fala e consultar diretamente o "cérebro" do assistente - o módulo de destaque de objetos semânticos - por meio de um bot de bate-papo.
Reconhecimento de fala
O primeiro estágio do reconhecimento de voz é o processamento de sinais de voz e extração de recursos. A representação mais simples de um sinal de áudio é um oscilograma. Ele reflete a quantidade de energia em um determinado momento. No entanto, essa informação não é suficiente para determinar o som falado. É importante para nós saber quanta energia está contida em diferentes faixas de frequência. Para fazer isso, usando a transformada de Fourier, é feita uma transição do oscilograma para o espectro.
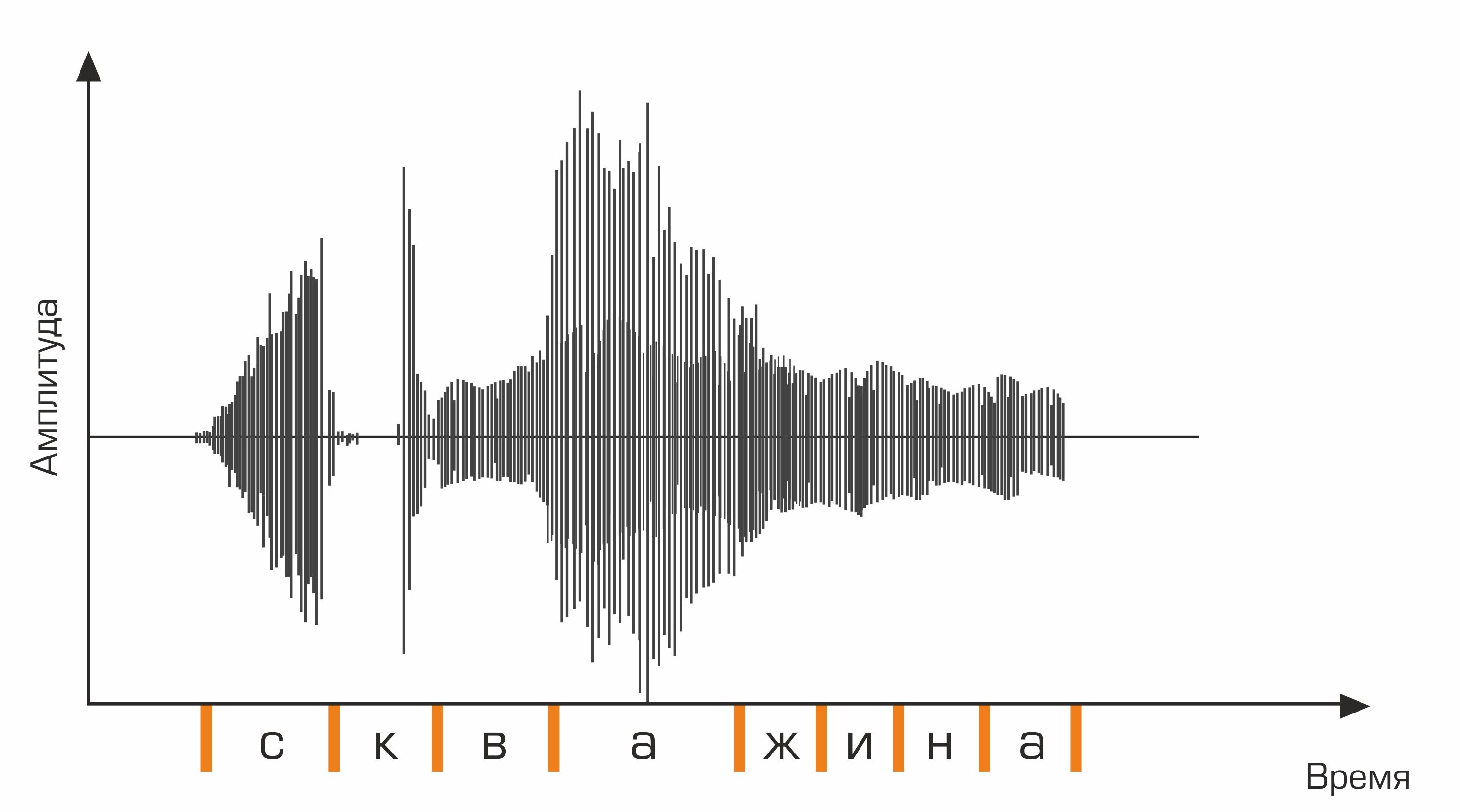
Este é um oscilograma.
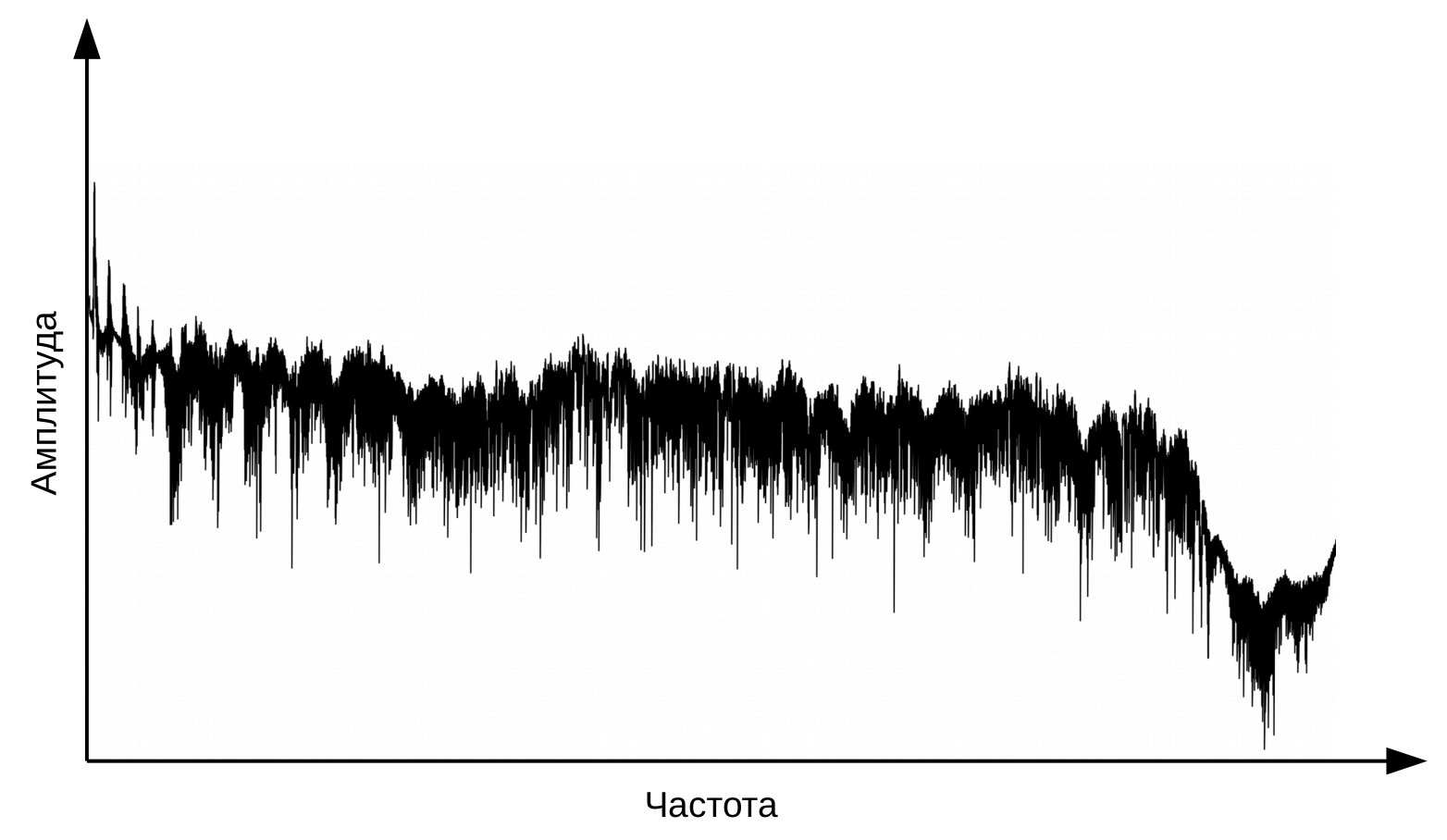
E este é o espectro para cada momento no tempo.
Aqui é necessário esclarecer que a fala se forma quando um fluxo de ar vibrante passa pela laringe (fonte) e pelo trato vocal (filtro). Para a classificação dos fonemas, precisamos apenas de informações sobre a configuração do filtro, ou seja, sobre a posição dos lábios e da língua. Esta informação pode ser distinguida pela transição do espectro para o cepstrum (cepstrum é um anagrama da palavra espectro), realizada usando a transformada inversa de Fourier do logaritmo do espectro. Novamente, o eixo x não é a frequência, mas o tempo. O termo “frequência” é usado para distinguir entre os domínios de tempo do cepstrum e o sinal de áudio original (Oppenheim, Schafer. Digital Signal Processing, 2018).
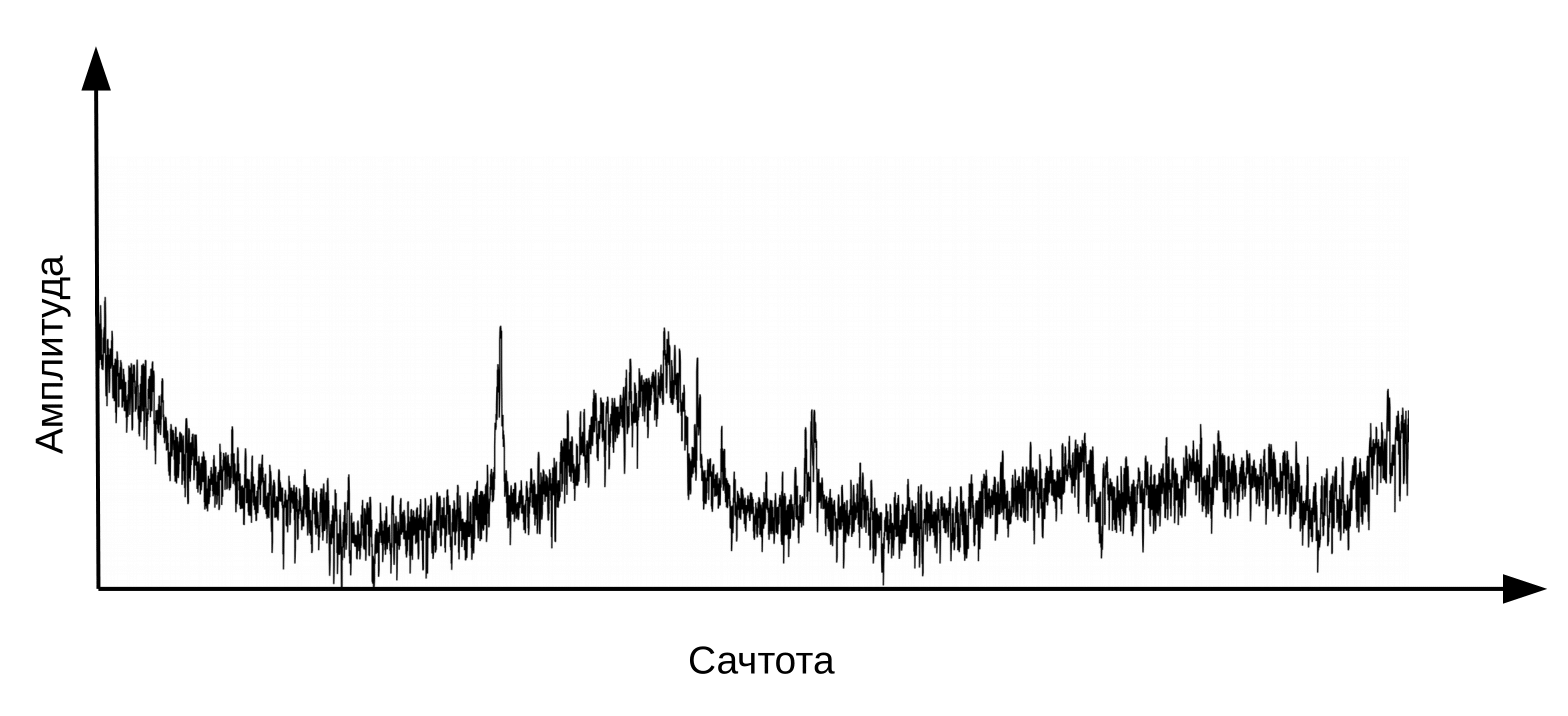
Cepstrum, ou simplesmente “espectro do logaritmo do espectro”. Sim, sim, comum é um termo , não um erro de digitação
Informações sobre a posição do trato vocal são encontradas nos primeiros 12 coeficientes do cepstro. Esses 12 coeficientes cepstrais são complementados por recursos dinâmicos (delta e delta-delta) que descrevem alterações no sinal de áudio. (Jurafsky, Martin. Speech and Language Processing, 2008). O vetor de valores resultante é chamado de vetor MFCC (coeficientes cepstrais de Mel-freqüência) e é o recurso acústico mais comum usado no reconhecimento de voz.
O que acontece a seguir com os sinais? Eles são usados como entrada para o modelo acústico. Mostra qual unidade linguística tem mais probabilidade de "gerar" esse vetor MFCC. Em diferentes sistemas, essas unidades linguísticas podem ser partes de fonemas, fonemas ou mesmo palavras. Assim, o modelo acústico transforma uma sequência de vetores MFCC em uma sequência de fonemas mais prováveis.
Além disso, para a sequência de fonemas, é necessário selecionar a sequência apropriada de palavras. É aqui que entra em jogo o dicionário da língua, contendo a transcrição de todas as palavras reconhecidas pelo sistema. Compilar esses dicionários é um processo trabalhoso que requer conhecimento especializado da fonética e da fonologia de uma determinada língua. Um exemplo de linha de um dicionário de transcrições:
bem skv aa zh yn ay
Na próxima etapa, o modelo de linguagem determina a probabilidade anterior da frase na linguagem. Em outras palavras, o modelo fornece uma estimativa da probabilidade de tal frase aparecer em um idioma. Um bom modelo de linguagem determinará que a frase "Faça um gráfico da taxa do petróleo" é mais provável do que a frase "Faça um gráfico do petróleo nove".
A combinação de um modelo acústico, um modelo de linguagem e um dicionário de pronúncia cria uma “grade” de hipóteses - todas as sequências de palavras possíveis a partir das quais a mais provável pode ser encontrada usando o algoritmo de programação dinâmica. Seu sistema o oferecerá como um texto reconhecido.
Representação esquemática do funcionamento do sistema de reconhecimento de voz
Seria impraticável reinventar a roda e escrever uma biblioteca de reconhecimento de fala do zero, então nossa escolha recaiu sobre a estrutura kaldi . A vantagem indiscutível da biblioteca é sua flexibilidade, permitindo, se necessário, criar e modificar todos os componentes do sistema. Além disso, a Licença Apache 2.0 permite que você use livremente a biblioteca no desenvolvimento comercial.
Como dados de treinamento, um modelo acústico utilizou o conjunto de dados de áudio freeware VoxForge . Para converter uma sequência de fonemas em palavras, usamos o dicionário da língua russa fornecido pela biblioteca CMU Sphinx . Uma vez que o dicionário não continha a pronúncia de termos específicos da indústria do petróleo, a partir dele, utilizando o utilitáriog2p-seq2seq treinou um modelo grafema para fonema para criar rapidamente transcrições para novas palavras. O modelo de linguagem foi treinado em transcrições de áudio do VoxForge e em um conjunto de dados que criamos, contendo os termos da indústria de petróleo e gás, os nomes dos campos e empresas de mineração.
Seleção de objetos semânticos
Então, reconhecemos a fala do usuário, mas isso é apenas uma linha de texto. Como você diz ao computador o que fazer? Os primeiros sistemas de controle de voz usavam um conjunto de comandos bastante limitado. Tendo reconhecido uma dessas frases, foi possível chamar a operação correspondente. Desde então, as tecnologias de processamento e compreensão de linguagem natural (PNL e PNL, respectivamente) deram um salto. Já hoje, os modelos treinados em grandes quantidades de dados são capazes de entender bem o significado de uma declaração.
Para extrair significado do texto de uma frase reconhecida, é necessário resolver dois problemas de aprendizado de máquina:
- Classificação da equipe do usuário (Intent Classification).
- Alocação de entidades nomeadas (Named Entity Recognition).
No desenvolvimento dos modelos, usamos a biblioteca Rasa de código aberto , distribuída sob a licença Apache 2.0.
Para resolver o primeiro problema, é necessário representar o texto como um vetor numérico que pode ser processado por uma máquina. Para tal transformação, o modelo neural StarSpace é usado , o que permite " aninhar " o texto da solicitação e a classe da solicitação em um espaço comum.

Modelo Neural StarSpace
Durante o treinamento, a rede neural aprende a comparar entidades, de modo a minimizar a distância entre o vetor de consulta e o vetor da classe correta e maximizar a distância aos vetores de diferentes classes. Durante o teste, a classe y é selecionada para a consulta x para que:
A distância do cosseno é usada como uma medida da similaridade dos vetores :,
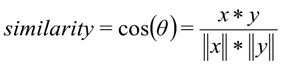
onde
x é a solicitação do usuário, y é a categoria da solicitação.
3.000 consultas foram marcadas para treinar o classificador de intenção do usuário. No total, nos formamos em 8 turmas. Dividimos a amostra em amostras de treinamento e teste em uma proporção de 70/30 usando o método de estratificação para a variável alvo. A estratificação nos permitiu preservar a distribuição original das classes no trem e na prova. A qualidade do modelo treinado foi avaliada por vários critérios ao mesmo tempo:
- Recall - a proporção de solicitações classificadas corretamente para todas as solicitações desta classe.
- A parcela de solicitações classificadas corretamente (precisão).
- Precisão - a proporção de solicitações classificadas corretamente em relação a todas as solicitações que o sistema atribuiu a esta classe.
- F1 – .
Além disso, a matriz de erro do sistema é usada para avaliar a qualidade do modelo de classificação. O eixo y é a verdadeira classe da afirmação, o eixo x é a classe prevista pelo algoritmo.
Na amostra de controle, o modelo apresentou os seguintes resultados:
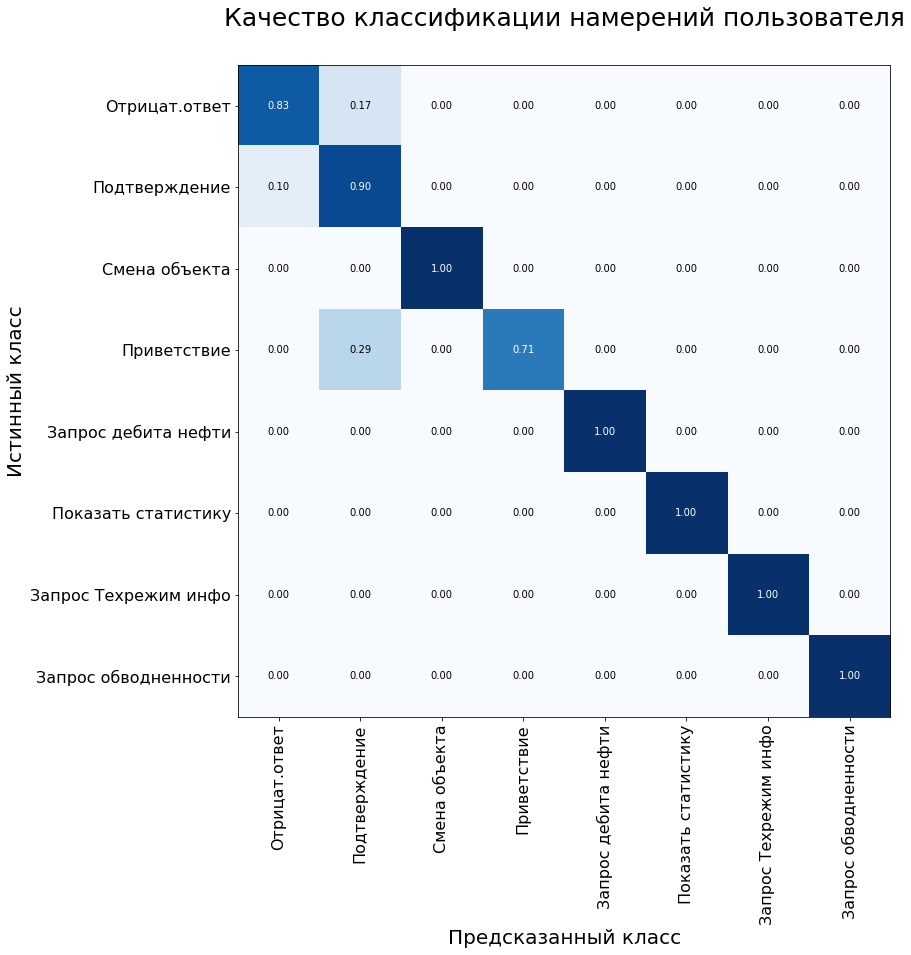
Métricas do modelo no conjunto de dados de teste: Precisão - 92%, F1 - 90%.
A segunda tarefa - a seleção de entidades nomeadas - é identificar palavras e frases que denotam um objeto ou fenômeno específico. Essas entidades podem ser, por exemplo, o nome de um depósito ou de uma empresa de mineração.
Para resolver o problema, foi utilizado o algoritmo de Campos Aleatórios Condicionais, que são uma espécie de campos de Markov. O CRF é um modelo discriminativo, ou seja, modela a probabilidade condicional P(Y | X) estado latente Y (classe de palavras) da observação X (palavra).
Para atender às solicitações do usuário, nosso assistente precisa destacar três tipos de entidades nomeadas: nome do campo, nome do poço e nome do objeto de desenvolvimento. Para treinar o modelo, preparamos um conjunto de dados e produzimos uma anotação: cada palavra da amostra foi atribuída a uma classe correspondente.

Um exemplo do conjunto de treinamento para o problema de reconhecimento de entidade nomeada.
No entanto, nem tudo foi tão simples. O jargão profissional é bastante comum entre desenvolvedores de campo e geólogos. Não é difícil para as pessoas entenderem que o "injetor" é um poço de injeção e que "Samotlor", muito provavelmente, significa o campo Samotlor. Para um modelo treinado com uma quantidade limitada de dados, ainda é difícil traçar esse paralelo. Para lidar com essa limitação, um recurso tão maravilhoso da biblioteca Rasa ajuda a criar um dicionário de sinônimos.
## sinônimo: Samotlor
- Samotlor
- Samotlor
- o maior campo de petróleo da Rússia
A adição de sinônimos também nos permitiu expandir um pouco a amostra. O volume de todo o conjunto de dados foi de 2.000 solicitações, que dividimos em treinamento e teste em uma proporção de 70/30. A qualidade do modelo foi avaliada usando a métrica F1 e foi de 98% quando testado em uma amostra de controle.
Execução de comando
Dependendo da classe de solicitação do usuário definida na etapa anterior, o sistema ativa a classe correspondente no kernel do software. Cada classe possui pelo menos dois métodos: um método que realiza diretamente a solicitação e um método para gerar uma resposta para o usuário.
Por exemplo, quando um comando é atribuído à classe "request_production_schedule", é criado um objeto da classe RequestOilChart, que descarrega informações sobre a produção de petróleo do banco de dados. Entidades nomeadas dedicadas (por exemplo, nomes de poço e campo) são usadas para preencher slots em consultas para acessar o banco de dados ou o kernel do software. O assistente responde com a ajuda de modelos preparados, os espaços nos quais são preenchidos com os valores dos dados carregados.

Um exemplo de um protótipo assistente funcionando.
Síntese de fala

Como funciona a síntese de fala concatenativa.
O texto de notificação do usuário gerado na etapa anterior é exibido na tela e também é usado como entrada para o módulo de síntese de fala oral. A geração de voz é realizada usando a biblioteca RHVoice... A licença GNU LGPL v2.1 permite que a estrutura seja usada como um componente de software comercial. Os principais componentes do sistema de síntese de voz são o processador linguístico, que processa o texto de entrada. O texto é normalizado: os números são reduzidos a representação escrita, abreviaturas são decifradas, etc. Em seguida, usando o dicionário de pronúncia, é criada uma transcrição para o texto, que é então transmitida para a entrada do processador acústico. Este componente é responsável por selecionar os elementos sonoros do banco de dados de voz, concatenar os elementos selecionados e processar o sinal sonoro.
Juntando tudo
Assim, todos os componentes do assistente de voz estão prontos. Resta apenas "coletá-los" na sequência correta e testá-los. Como mencionamos anteriormente, cada módulo é um microsserviço. A estrutura RabbitMQ é usada como um barramento para conectar todos os módulos. A ilustração demonstra claramente o trabalho interno do assistente a partir do exemplo de uma solicitação típica do usuário:
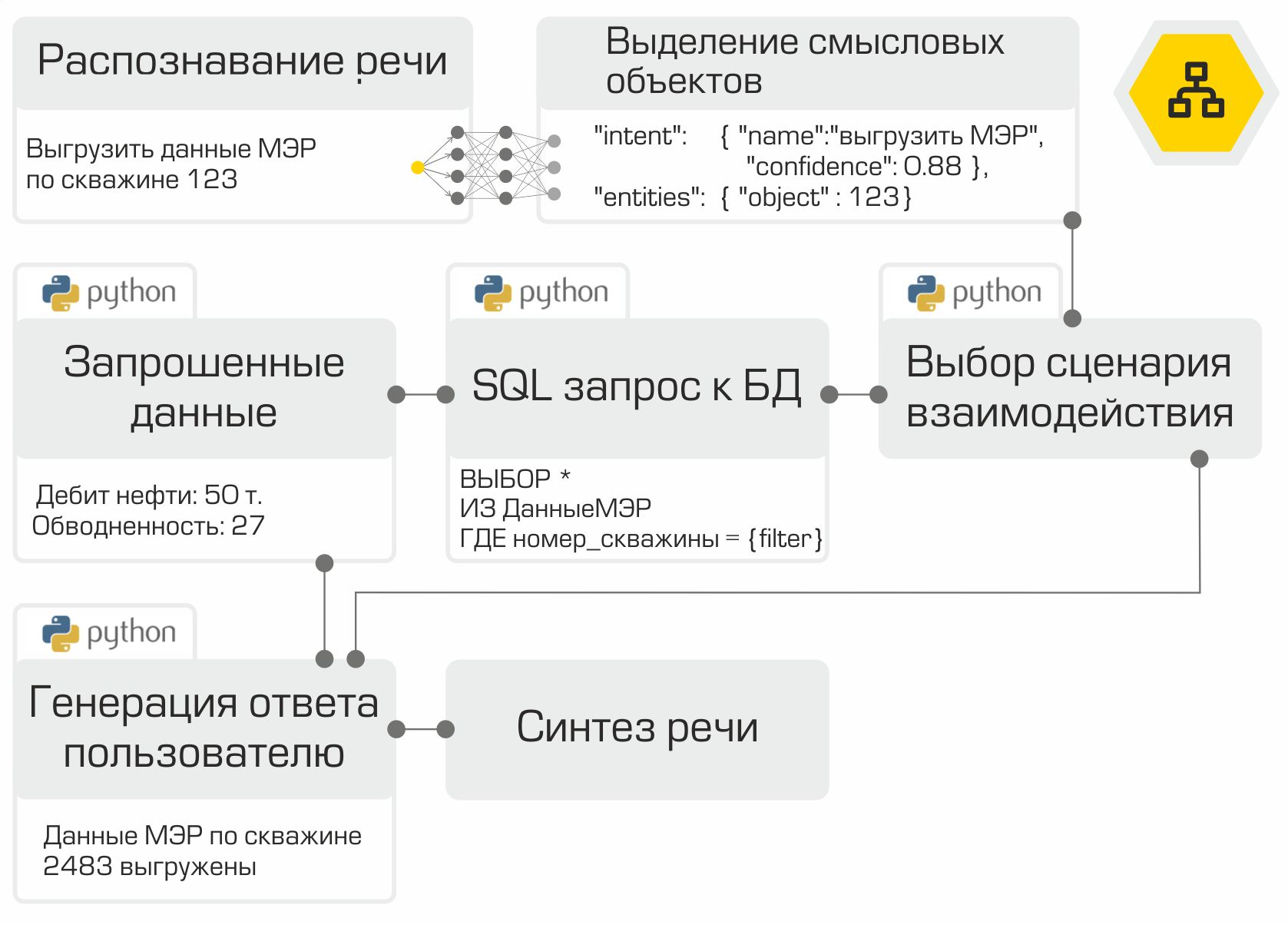
A solução criada permite colocar toda a infraestrutura na rede da Empresa. O processamento local de informações é a principal vantagem do sistema. No entanto, você tem que pagar pela autonomia porque tem que coletar dados, treinar e testar modelos por conta própria, em vez de usar o poder dos principais fornecedores no mercado de assistente digital.
No momento, estamos integrando o assistente em um de nossos produtos.
Como será conveniente procurar seu poço ou seu arbusto favorito com apenas uma frase!
Na próxima etapa, pretende-se coletar e analisar o feedback dos usuários. Também há planos para expandir os comandos reconhecidos e executados pelo assistente.
O projeto descrito no artigo está longe de ser o único exemplo de uso de métodos de aprendizado de máquina em nossa empresa. Assim, por exemplo, a análise de dados é usada para selecionar automaticamente poços candidatos para medidas geológicas e técnicas, cujo objetivo é estimular a produção de petróleo. Em um dos próximos artigos, contaremos como resolvemos esse problema legal. Assine nosso blog para não perder!