
Introdução
Google Dorks ou Google Hacking é uma técnica usada pela mídia, investigadores, engenheiros de segurança e qualquer outra pessoa para consultar vários mecanismos de pesquisa para descobrir informações ocultas e vulnerabilidades que podem ser encontradas em servidores públicos. É uma técnica em que as consultas regulares de pesquisa do site são usadas em toda a sua extensão para determinar as informações ocultas na superfície.
Como funciona o Google Dorking?
Este exemplo de coleta e análise de informações, agindo como uma ferramenta OSINT, não é uma vulnerabilidade do Google ou um dispositivo para hackear a hospedagem de sites. Pelo contrário, atua como um processo convencional de recuperação de dados com recursos avançados. Isso não é novo, pois há um grande número de sites que têm mais de uma década e servem como repositórios para explorar e usar o Google Hacking.
Enquanto os mecanismos de pesquisa indexam, armazenam cabeçalhos e conteúdo da página e os vinculam para consultas de pesquisa ideais. Mas, infelizmente, os web spiders de qualquer mecanismo de pesquisa são configurados para indexar absolutamente todas as informações encontradas. Mesmo que os administradores dos recursos da web não tivessem intenção de publicar este material.
No entanto, o mais interessante sobre o Google Dorking é a enorme quantidade de informações que podem ajudar a todos no processo de aprendizado do processo de pesquisa do Google. Pode ajudar os recém-chegados a encontrar parentes desaparecidos ou pode ensinar como extrair informações para seu próprio benefício. Em geral, cada recurso é interessante e surpreendente à sua maneira e pode ajudar a todos exatamente no que procuram.
Que informações posso encontrar no Dorks?
Variando de controladores de acesso remoto de várias máquinas de fábrica a interfaces de configuração de sistemas críticos. Presume-se que ninguém jamais encontrará uma grande quantidade de informações postadas na rede.
No entanto, vamos ver em ordem. Imagine uma nova câmera CCTV que permite assistir ao vivo no seu telefone sempre que quiser. Você o configura e se conecta via Wi-Fi e baixa o aplicativo para autenticar o login da câmera de segurança. Depois disso, você pode acessar a mesma câmera de qualquer lugar do mundo.
No fundo, nem tudo parece tão simples. A câmera envia uma solicitação ao servidor chinês e reproduz o vídeo em tempo real, permitindo que você faça login e abra o feed de vídeo hospedado no servidor na China a partir de seu telefone. Este servidor pode não exigir uma senha para acessar o feed de sua webcam, tornando-o publicamente disponível para quem procura o texto contido na página de visualização da câmera.
E, infelizmente, o Google é implacavelmente eficiente para localizar qualquer dispositivo na Internet rodando em servidores HTTP e HTTPS. E como a maioria desses dispositivos contém algum tipo de plataforma web para personalizá-los, isso significa que muitas coisas que não deveriam estar no Google vão parar lá.
De longe, o tipo de arquivo mais sério é aquele que carrega as credenciais dos usuários ou de toda a empresa. Isso geralmente acontece de duas maneiras. No primeiro, o servidor é configurado incorretamente e expõe seus logs administrativos ou logs ao público na Internet. Quando as senhas são alteradas ou o usuário não consegue fazer login, esses arquivos podem vazar junto com as credenciais.
A segunda opção ocorre quando os arquivos de configuração contendo as mesmas informações (logins, senhas, nomes de banco de dados, etc.) tornam-se publicamente disponíveis. Esses arquivos devem ser ocultados de qualquer acesso público, pois geralmente deixam informações importantes. Qualquer um desses erros pode levar ao fato de um invasor encontrar essas lacunas e obter todas as informações necessárias.
Este artigo ilustra o uso do Google Dorks para mostrar não apenas como encontrar todos esses arquivos, mas também como as plataformas vulneráveis podem ser que contêm informações na forma de uma lista de endereços, e-mail, fotos e até mesmo uma lista de webcams disponíveis publicamente.
Analisando operadores de pesquisa
O Dorking pode ser usado em vários mecanismos de pesquisa, não apenas no Google. No uso diário, os mecanismos de pesquisa como Google, Bing, Yahoo e DuckDuckGo fazem uma consulta de pesquisa ou string de consulta de pesquisa e retornam resultados relevantes. Além disso, esses mesmos sistemas são programados para aceitar operadores mais avançados e complexos que restringem muito esses termos de pesquisa. Um operador é uma palavra-chave ou frase que tem um significado especial para um mecanismo de pesquisa. Exemplos de operadores comumente usados são: "inurl", "intext", "site", "feed", "idioma". Cada operador é seguido por dois pontos, seguido pela frase ou frases-chave correspondentes.
Esses operadores permitem que você pesquise informações mais específicas, como linhas específicas de texto nas páginas de um site da Web ou arquivos hospedados em um URL específico. Entre outras coisas, o Google Dorking também pode encontrar páginas de login ocultas, mensagens de erro mostrando informações sobre vulnerabilidades disponíveis e arquivos compartilhados. O principal motivo é que o administrador do site pode simplesmente ter esquecido de excluir do acesso público.
O serviço Google mais prático e ao mesmo tempo interessante é a capacidade de pesquisar páginas excluídas ou arquivadas. Isso pode ser feito usando o operador "cache:". O operador trabalha de forma a mostrar a versão salva (excluída) da página da web armazenada no cache do Google. A sintaxe para este operador é mostrada aqui:
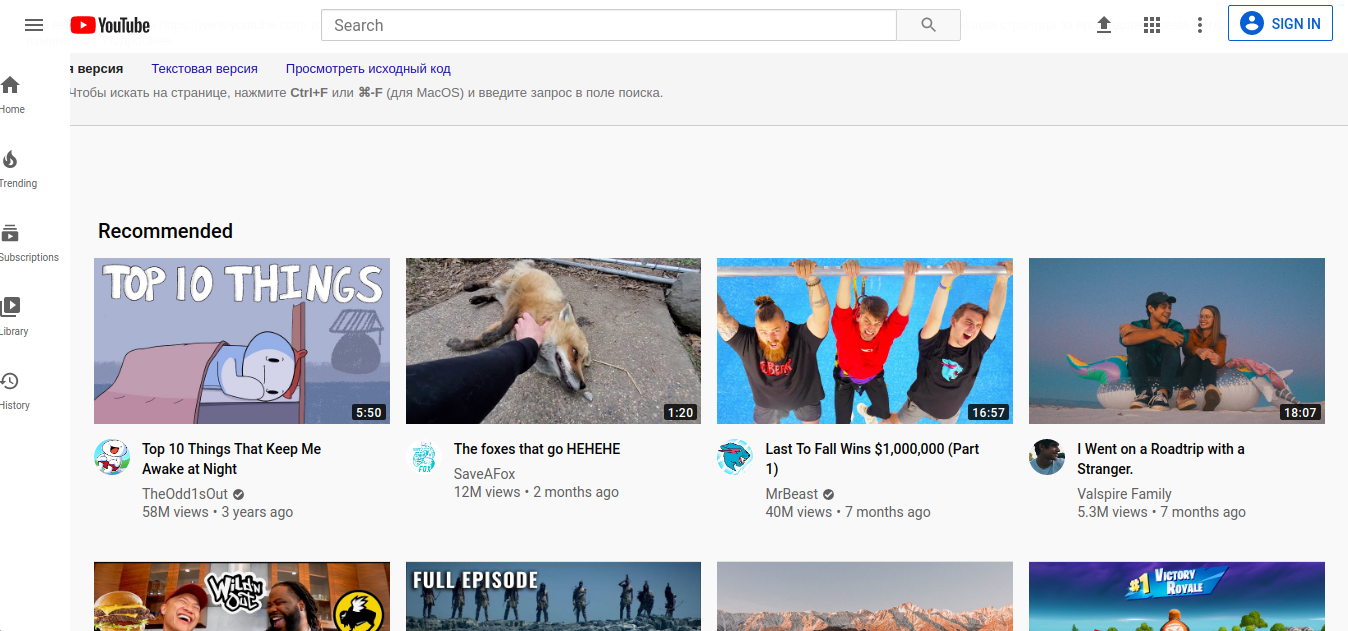
cache: www.youtube.com
Após fazer a solicitação acima ao Google, é fornecido acesso à versão anterior ou desatualizada da página da web do Youtube. O comando permite que você chame a versão completa da página, a versão em texto ou a própria fonte da página (código completo) A hora exata (data, hora, minuto, segundo) da indexação feita pelo Google spider também é indicada. A página é exibida como um arquivo gráfico, embora a pesquisa na própria página seja realizada da mesma forma que em uma página HTML normal (o atalho de teclado é CTRL + F). Os resultados do comando "cache:" dependem da freqüência com que a página da web foi indexada pelo Google. Se o próprio desenvolvedor definir o indicador com uma certa frequência de visitas no cabeçalho do documento HTML, o Google reconhece a página como secundária e geralmente a ignora em favor da proporção do PageRank.que é o principal fator na frequência de indexação de páginas. Portanto, se uma determinada página da web foi alterada entre as visitas do rastreador do Google, ela não será indexada ou lida usando o comando "cache:". Os exemplos que funcionam especialmente bem ao testar esse recurso são blogs, contas de mídia social e portais online atualizados com frequência.
As informações excluídas ou dados que foram colocados por engano ou precisam ser excluídos em algum ponto podem ser recuperados com muita facilidade. A negligência do administrador da plataforma web pode colocá-lo em risco de espalhar informações indesejadas.
Informação do usuário
A pesquisa de informações do usuário é usada por meio de operadores avançados, que tornam os resultados da pesquisa precisos e detalhados. O operador "@" é utilizado para pesquisar usuários de indexação nas redes sociais: Twitter, Facebook, Instagram. Usando o exemplo da mesma universidade polonesa, você pode encontrar seu representante oficial, em uma das plataformas sociais, usando este operador da seguinte forma:
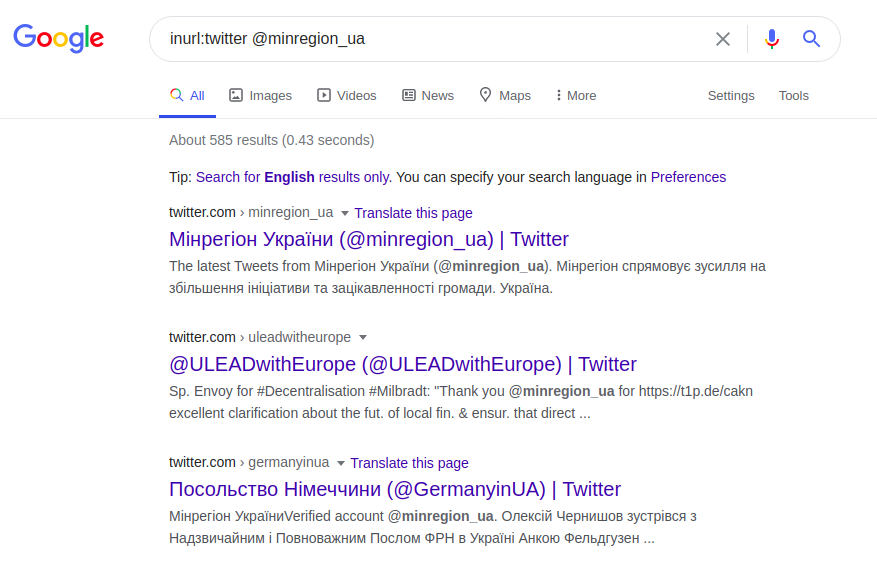
inurl: twitter @minregion_ua
Esta solicitação do Twitter encontra o usuário "minregion_ua". Supondo que o local ou nome da obra do utilizador que procuramos (Ministério para o Desenvolvimento das Comunidades e Territórios da Ucrânia) e o seu nome sejam conhecidos, pode fazer um pedido mais específico. E em vez de ter que pesquisar tediosamente a página web da instituição inteira, você pode fazer a consulta correta com base no endereço de e-mail e assumir que o nome do endereço deve incluir pelo menos o nome do usuário ou instituição solicitada. Por exemplo:
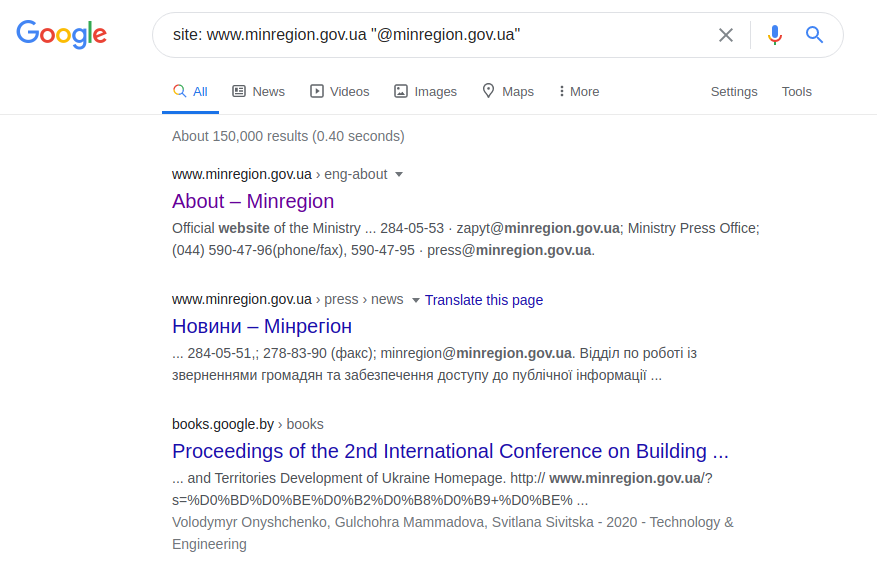
site: www.minregion.gov.ua "@ minregion.ua"
Você também pode usar um método menos complicado e enviar uma solicitação apenas para endereços de e-mail, conforme mostrado abaixo, na esperança de sorte e falta de profissionalismo do administrador de recursos da web.
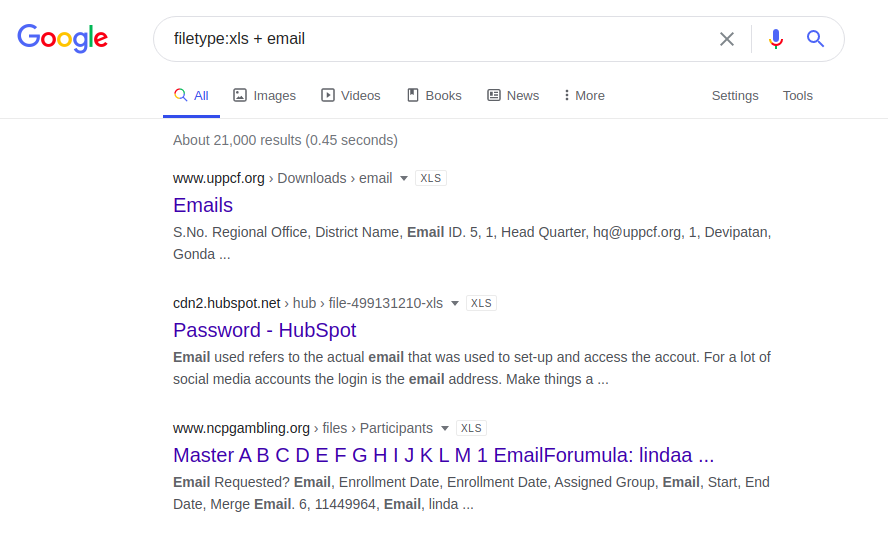
email.xlsx
filetype: xls + email
Além disso, você pode tentar obter endereços de e-mail de uma página da web com a seguinte solicitação:

site: www.minregion.gov.ua intext: e-mail
A consulta acima irá buscar a palavra-chave "e-mail" na página web do Ministério para o Desenvolvimento das Comunidades e Territórios da Ucrânia. Encontrar endereços de e-mail é de uso limitado e geralmente requer pouca preparação e coleta de informações do usuário com antecedência.
Infelizmente, a busca por números de telefone indexados na agenda telefônica do Google está limitada apenas aos Estados Unidos. Por exemplo:
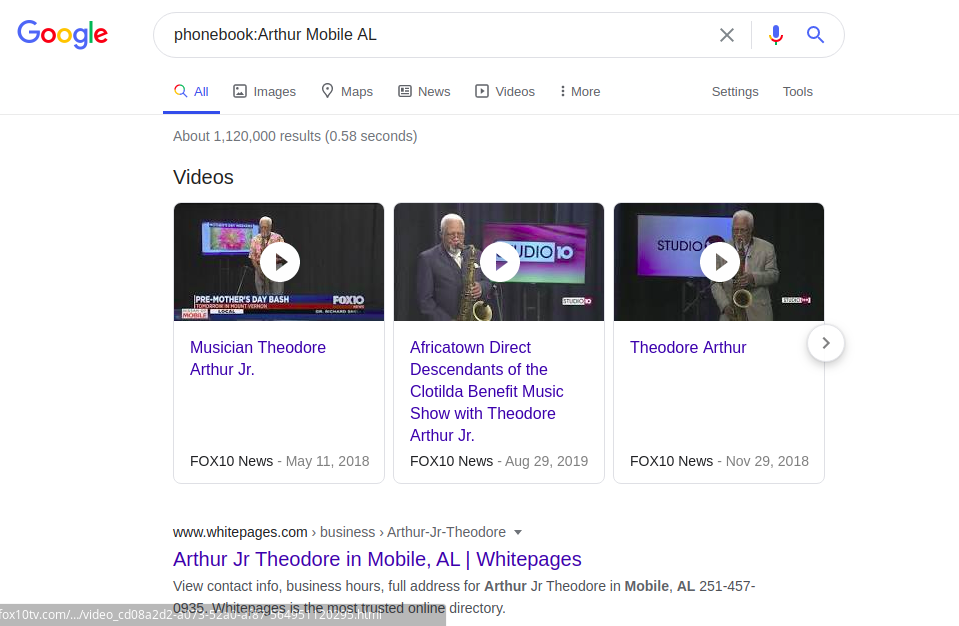
lista telefônica: Arthur Mobile AL A
busca por informações do usuário também é possível através da "busca de imagens" do Google ou busca reversa de imagens. Isso permite que você encontre fotos idênticas ou semelhantes em sites indexados pelo Google.
Informação de recursos da web
O Google possui vários operadores úteis, em particular "related:", que exibe uma lista de sites "semelhantes" ao desejado. A semelhança é baseada em links funcionais, não links lógicos ou significativos.
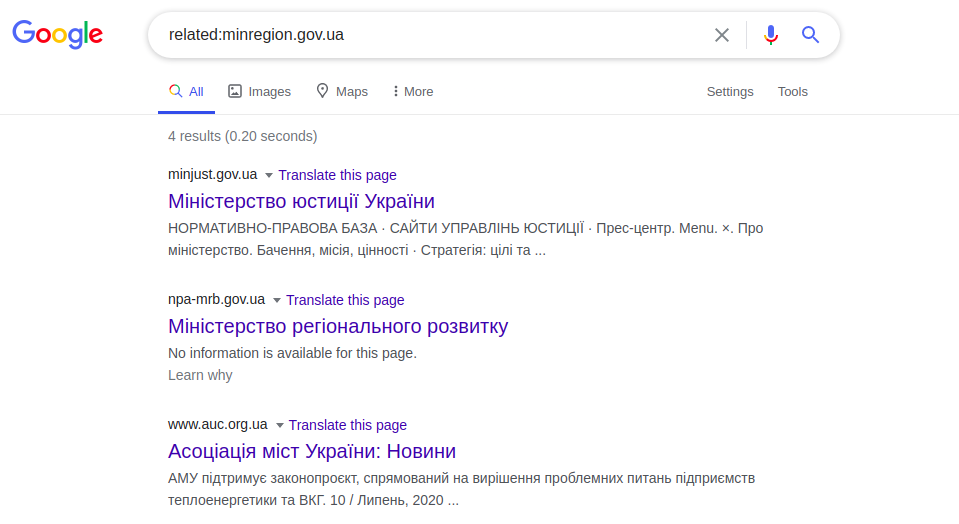
related: minregion.gov.ua
Este exemplo exibe páginas de outros Ministérios da Ucrânia. Este operador funciona como o botão "Páginas relacionadas" nas pesquisas avançadas do Google. Da mesma forma, funciona a solicitação “info:”, que exibe informações em uma determinada página da web. Esta é a informação específica de uma página web apresentada no título do site (), nomeadamente nas tags de meta descrição (<meta name = “Descrição”). Exemplo:

info: minregion.gov.ua
Outra consulta, "define:", é muito útil para encontrar artigos de pesquisa. Ele permite que você obtenha definições de palavras de fontes como enciclopédias e dicionários online. Um exemplo de sua aplicação:
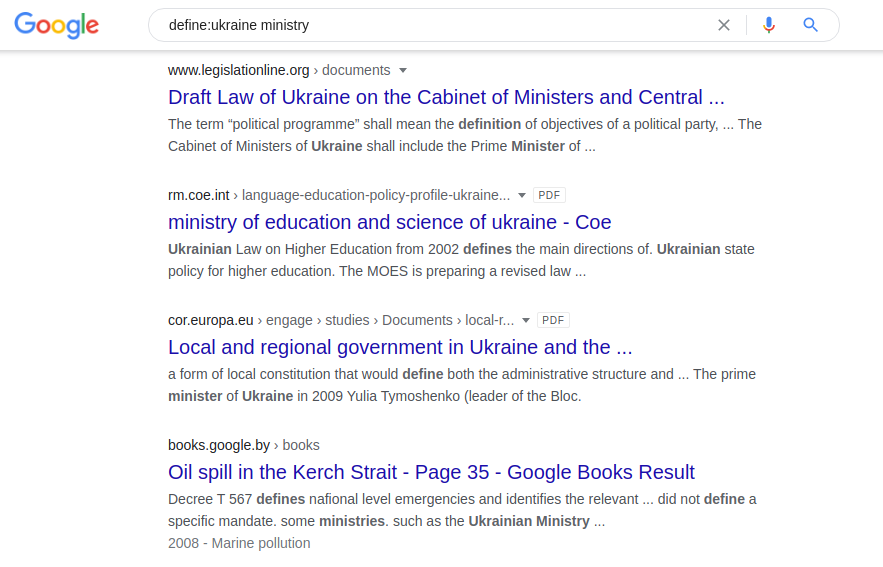
definir: territórios ucranianos O
operador universal - til ("~"), permite que você pesquise por palavras semelhantes ou sinônimos:
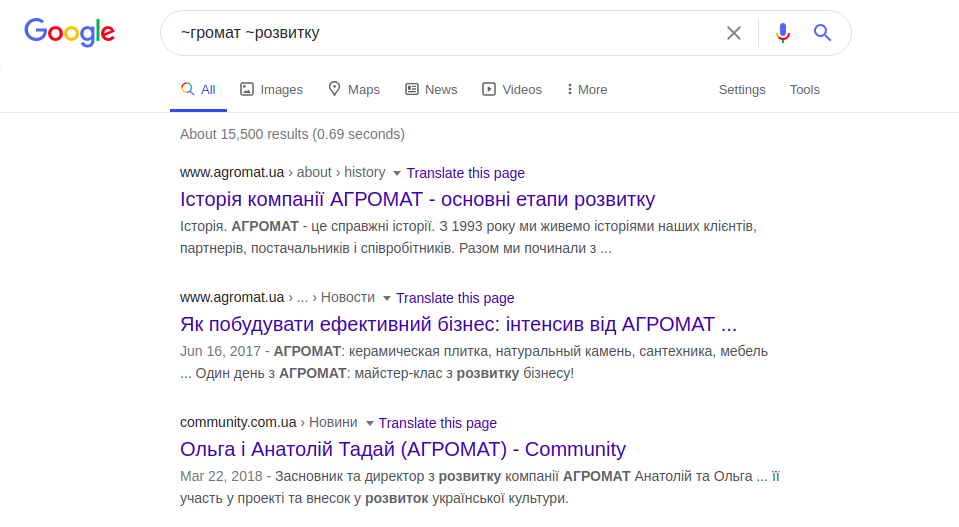
~ comunidades ~ desenvolvimento
A consulta acima exibe sites com as palavras “comunidades” (territórios) e “desenvolvimento” (desenvolvimento) e sites com o sinônimo “comunidades”. O operador "link:", que modifica a consulta, limita o intervalo de pesquisa aos links especificados para uma página específica.
link: www.minregion.gov.ua
No entanto, este operador não exibe todos os resultados e não expande os critérios de pesquisa.
Hashtags são um tipo de número de identificação que permite agrupar informações. Eles são usados atualmente no Instagram, VK, Facebook, Tumblr e TikTok. O Google permite que você pesquise várias redes sociais ao mesmo tempo ou apenas as recomendadas. Um exemplo de consulta típica para qualquer mecanismo de pesquisa é:
# polyticavukrainі O
operador "AROUND (n)" permite que você pesquise duas palavras localizadas a uma distância de um determinado número de palavras uma da outra. Exemplo:

Ministério de AROUND (4) da Ucrânia
O resultado da consulta acima é exibir sites que contenham essas duas palavras ("ministério" e "Ucrânia"), mas eles estão separados um do outro por quatro outras palavras.
A pesquisa por tipo de arquivo também é extremamente útil, pois o Google indexa o conteúdo de acordo com o formato em que foi gravado. O operador "filetype:" é usado para isso. Existe uma grande variedade de pesquisas de arquivos atualmente em uso. De todos os mecanismos de pesquisa disponíveis, o Google fornece o conjunto mais sofisticado de operadores para pesquisa de código aberto.
Como alternativa aos operadores acima, ferramentas como Maltego e Oryon OSINT Browser são recomendadas. Eles fornecem recuperação automática de dados e não requerem o conhecimento de operadores especiais. O mecanismo dos programas é muito simples: a partir da consulta correta enviada ao Google ou Bing, são encontrados documentos publicados pela instituição de seu interesse e analisados os metadados desses documentos. Um recurso potencial de informação para tais programas é cada arquivo com qualquer extensão, por exemplo: ".doc", ".pdf", ".ppt", ".odt", ".xls" ou ".jpg".
Além disso, deve-se dizer como cuidar adequadamente de "limpar seus metadados" antes de tornar os arquivos públicos. Alguns guias da web fornecem pelo menos várias maneiras de se livrar das metainformações. Porém, é impossível deduzir a melhor maneira, pois tudo depende das preferências individuais do próprio administrador. Em geral, é recomendável gravar os arquivos em um formato que não armazene metadados inicialmente e, em seguida, disponibilize os arquivos. Existem inúmeros programas gratuitos de limpeza de metadados na Internet, principalmente para imagens. O ExifCleaner pode ser considerado um dos mais desejáveis. No caso de arquivos de texto, é altamente recomendável que você limpe manualmente.
Informações deixadas sem saber pelos proprietários do site
Os recursos indexados pelo Google permanecem públicos (por exemplo, documentos internos e materiais da empresa deixados no servidor) ou são mantidos por conveniência pelas mesmas pessoas (por exemplo, arquivos de música ou arquivos de filme). A busca por esse tipo de conteúdo pode ser feita usando o Google de muitas maneiras diferentes e a mais fácil delas é adivinhar. Se, por exemplo, existem arquivos 5.jpg, 8.jpg e 9.jpg em um determinado diretório, você pode prever que existem arquivos de 1 a 4, de 6 a 7 e até mais 9. Portanto, você pode ter acesso a materiais que não deveriam deviam estar em público. Outra forma é pesquisar tipos específicos de conteúdo em sites. Você pode pesquisar arquivos de música, fotos, filmes e livros (e-books, audiolivros).
Em outro caso, podem ser arquivos que o usuário deixou inadvertidamente em domínio público (por exemplo, música em um servidor FTP para seu próprio uso). Essas informações podem ser obtidas de duas maneiras: usando o operador "filetype:" ou o operador "inurl:". Por exemplo:
filetype: doc site: gov.ua
site: www.minregion.gov.ua filetype: pdf
site: www.minregion.gov.ua inurl: doc
Você também pode pesquisar arquivos de programa usando uma consulta de pesquisa e filtrando o arquivo desejado por sua extensão:
filetype: iso
Informações sobre a estrutura das páginas da web
Para visualizar a estrutura de uma determinada página da web e revelar toda a sua estrutura, o que ajudará o servidor e suas vulnerabilidades no futuro, você pode fazer isso usando apenas o operador "site:". Vamos analisar a seguinte frase:
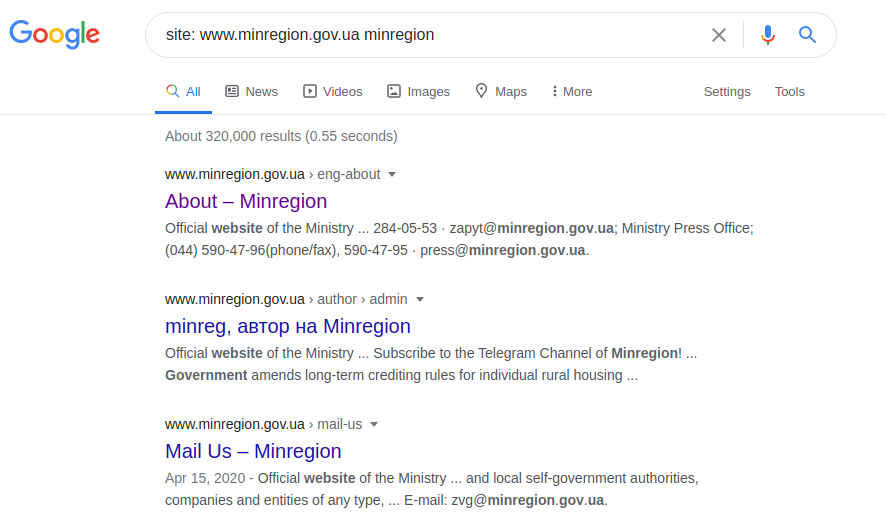
site: www.minregion.gov.ua minregion
Começamos a pesquisar a palavra “minregion” no domínio “www.minregion.gov.ua”. Todos os sites deste domínio (pesquisas do Google tanto no texto, nos cabeçalhos e no título do site) contêm esta palavra. Assim, obtendo a estrutura completa de todos os sites daquele domínio particular. Assim que a estrutura do diretório estiver disponível, um resultado mais preciso (embora isso nem sempre aconteça) pode ser obtido com a seguinte consulta:
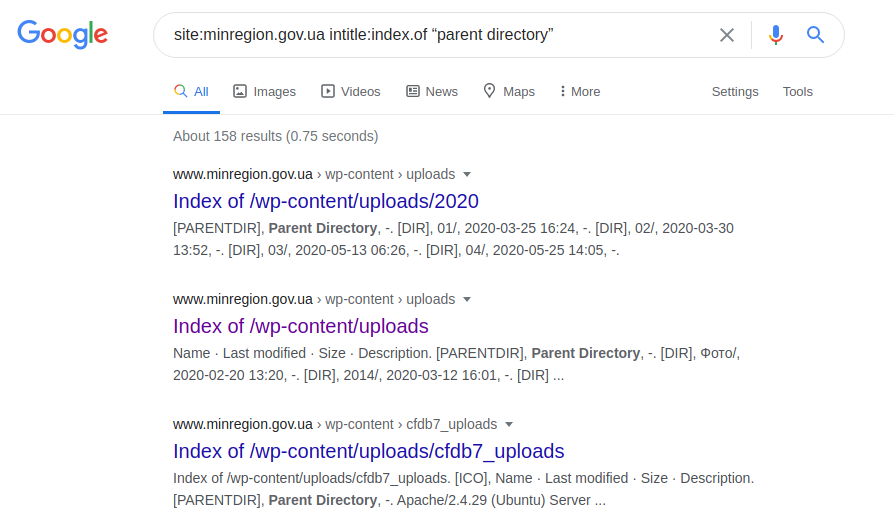
site: minregion.gov.ua intitle: index.of "diretório pai"
Mostra os subdomínios menos protegidos de "minregion.gov.ua", às vezes com a capacidade de pesquisar o diretório inteiro, junto com o possível download de arquivos. Portanto, naturalmente, tal solicitação não é aplicável a todos os domínios, uma vez que podem ser protegidos ou executados sob o controle de algum outro servidor.
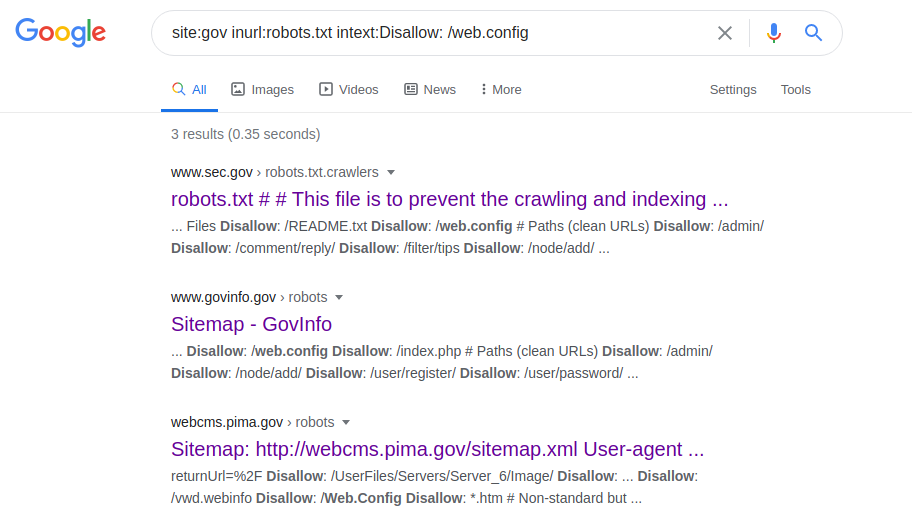
site: gov inurl: robots.txt intext: Disallow: /web.config
Esta declaração permite que você acesse os parâmetros de configuração de vários servidores. Após fazer a solicitação, vá até o arquivo robots.txt, procure o caminho para "web.config" e vá para o caminho do arquivo especificado. Para obter o nome do servidor, sua versão e outros parâmetros (por exemplo, portas), a seguinte solicitação é feita:
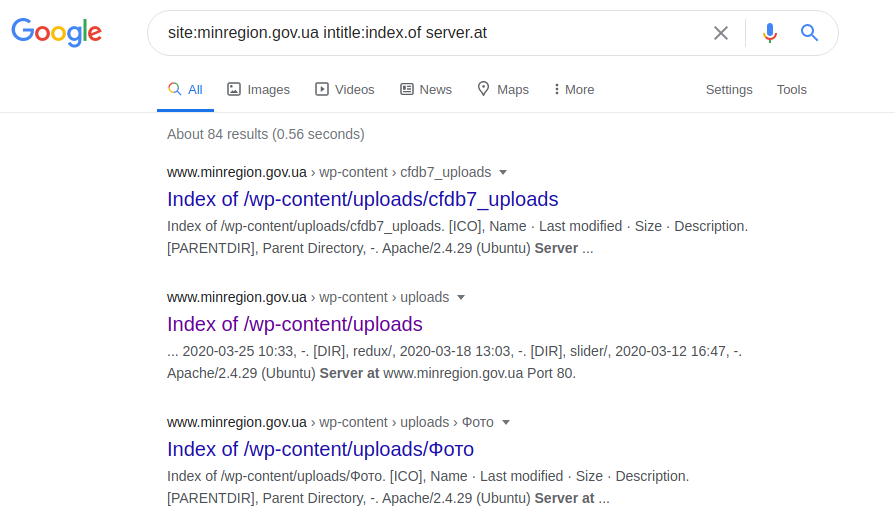
site: gosstandart.gov.by intitle: index.of server.at
Cada servidor tem algumas frases exclusivas em suas páginas iniciais , por exemplo, Internet Information Service (IIS):
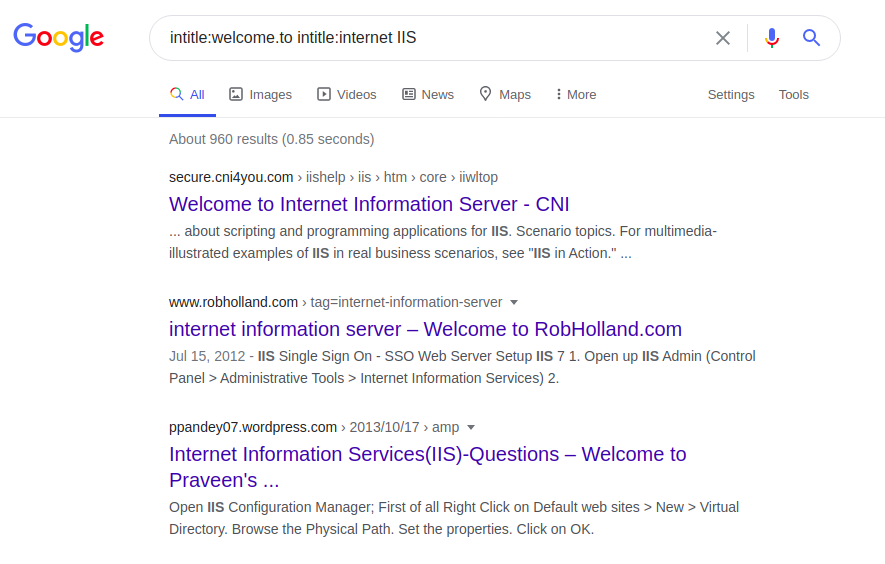
intitle: welcome.to intitle: internet IIS
A definição do próprio servidor e das tecnologias nele utilizadas depende apenas da engenhosidade da consulta solicitada. Você pode, por exemplo, tentar fazer isso esclarecendo uma especificação técnica, manual ou as chamadas páginas de ajuda. Para demonstrar esse recurso, você pode usar a seguinte consulta:
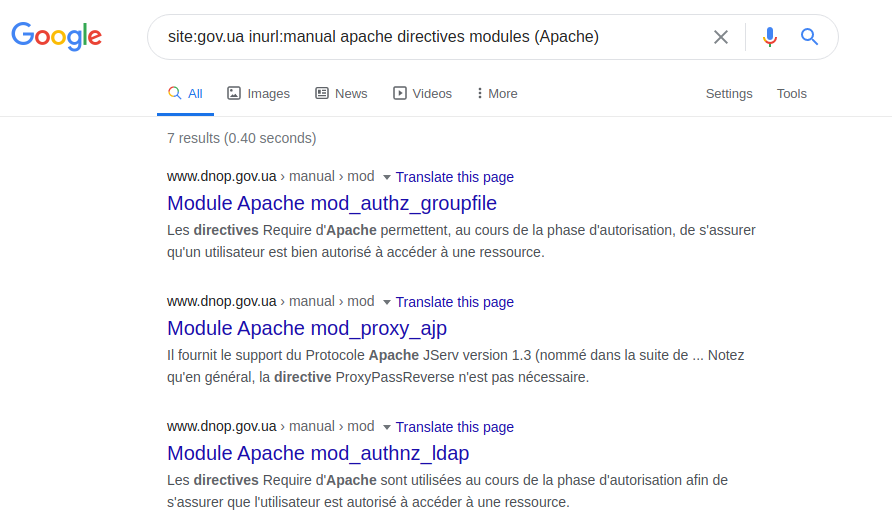
site: gov.ua inurl: manual apache directives modules (Apache) O
acesso pode ser estendido, por exemplo, graças ao arquivo com erros SQL:
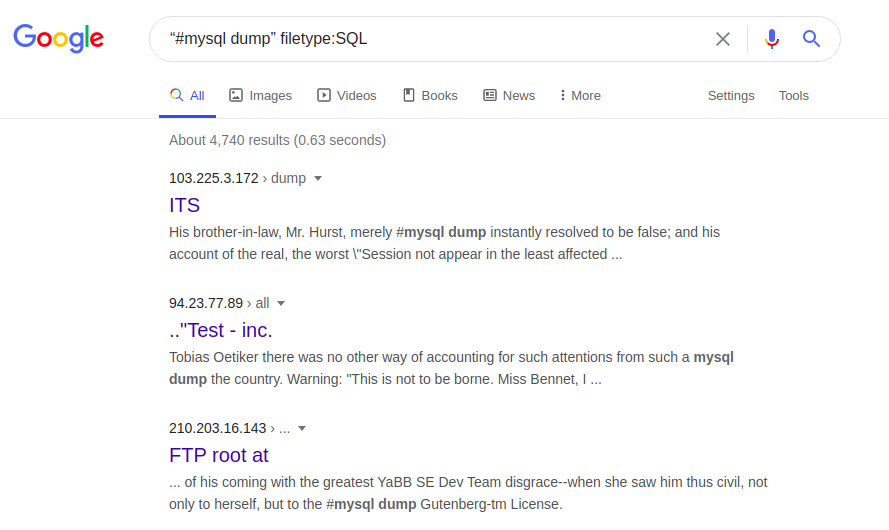
Tipo de arquivo "#Mysql dump":
Erros de SQL em um banco de dados SQL podem, em particular, fornecer informações sobre a estrutura e o conteúdo dos bancos de dados. Por sua vez, toda a página web, suas versões originais e / ou atualizadas podem ser acessadas por meio da seguinte solicitação:
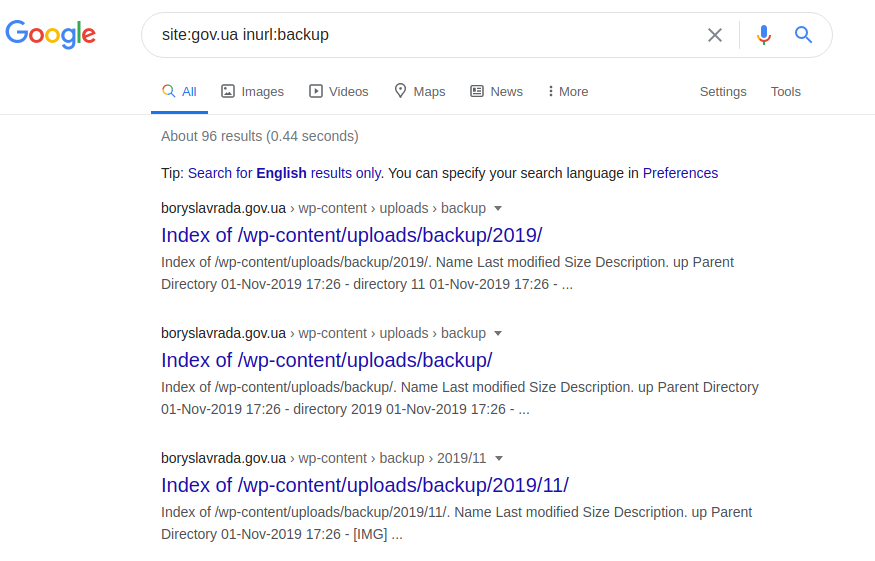
site: gov.ua inurl: backup
site: gov.ua inurl: backup intitle: index.of inurl: admin
Atualmente, usar os operadores acima raramente dá os resultados esperados, uma vez que podem ser bloqueados antecipadamente por usuários experientes.
Além disso, usando o programa FOCA, você pode encontrar o mesmo conteúdo que ao pesquisar os operadores acima. Para começar, o programa precisa do nome do domínio, após o qual analisará a estrutura de todo o domínio e todos os demais subdomínios conectados aos servidores de uma determinada instituição. Essas informações podem ser encontradas na caixa de diálogo na guia Rede:
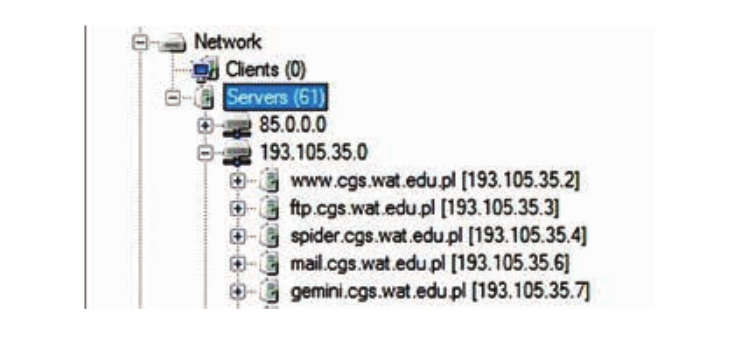
Assim, um invasor potencial pode interceptar dados deixados por administradores da web, documentos internos e materiais da empresa deixados até mesmo em um servidor oculto.
Se quiser saber ainda mais informações sobre todos os operadores de indexação possíveis, você pode verificar o banco de dados de destino de todos os operadores do Google Dorking aqui . Você também pode se familiarizar com um projeto interessante no GitHub, que coletou todos os links de URL mais comuns e vulneráveis e tentar procurar algo interessante para você, você pode ver aqui neste link .
Combinando e obtendo resultados
Para exemplos mais específicos, abaixo está uma pequena coleção de operadores do Google comumente usados. Em uma combinação de várias informações adicionais e os mesmos comandos, os resultados da pesquisa mostram uma visão mais detalhada do processo de obtenção de informações confidenciais. Afinal, para um mecanismo de busca regular do Google, esse processo de coleta de informações pode ser bastante interessante.
Pesquise orçamentos no site do Departamento de Segurança Interna e Cibersegurança dos EUA.
A seguinte combinação fornece todas as planilhas do Excel publicamente indexadas que contêm a palavra "orçamento":
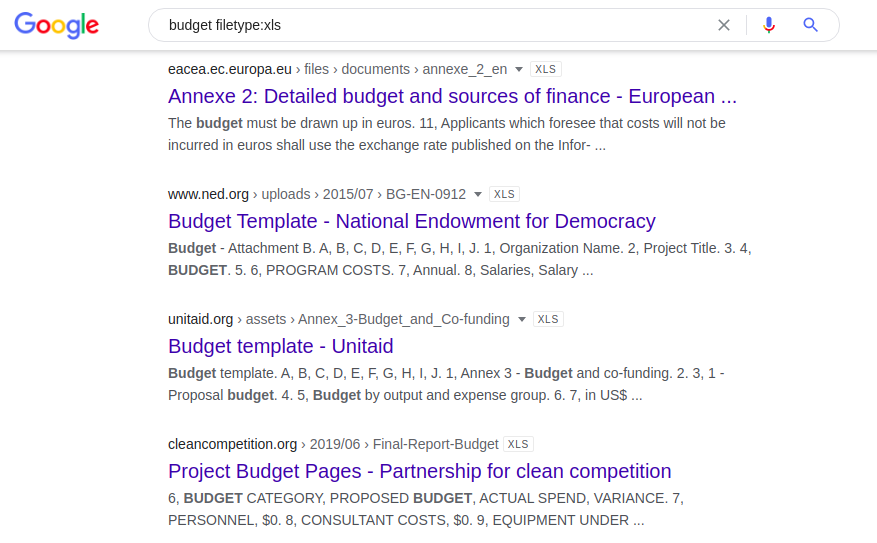
budget filetype: xls
Como o operador "filetype:" não reconhece automaticamente versões diferentes do mesmo formato de arquivo (por exemplo, doc versus odt ou xlsx versus csv), cada um desses formatos deve ser dividido separadamente:
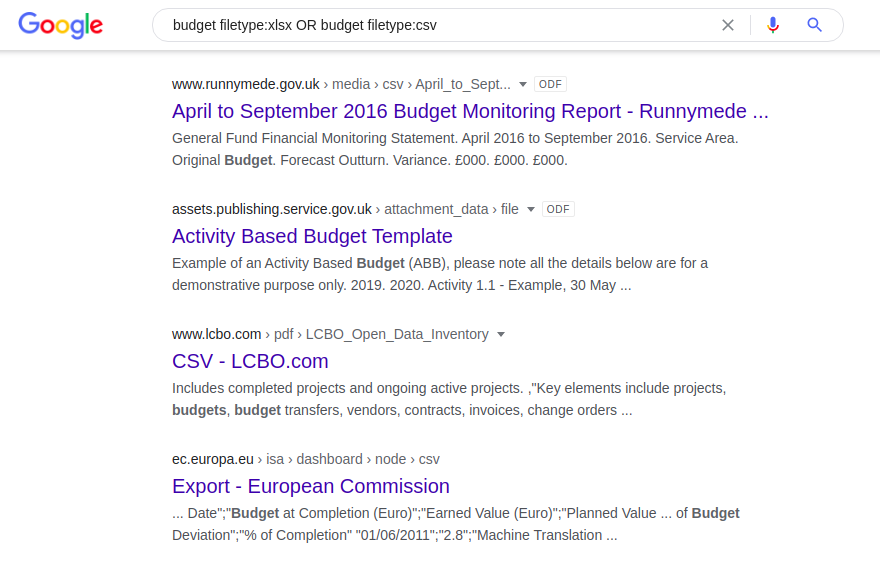
tipo de arquivo de orçamento: xlsx OU tipo de arquivo de orçamento: csv
O dork subsequente retornará arquivos PDF no site da NASA:
site: nasa.gov filetype: pdf
Outro exemplo interessante de uso de um idiota com a palavra-chave “orçamento” é pesquisar documentos de segurança cibernética dos EUA em formato “pdf” no site oficial do Departamento de Defesa Nacional.
budget cybersecurity site: dhs.gov filetype: pdf
Mesmo aplicativo idiota, mas desta vez o mecanismo de pesquisa retornará planilhas .xlsx contendo a palavra "budget" no site do Departamento de Segurança Interna dos EUA:
site de orçamento: dhs.gov filetype: xls
Procure por senhas
A busca de informações por login e senha pode ser útil como uma busca por vulnerabilidades em seu próprio recurso. Caso contrário, as senhas são armazenadas em documentos compartilhados em servidores da web. Você pode tentar as seguintes combinações em diferentes mecanismos de pesquisa:
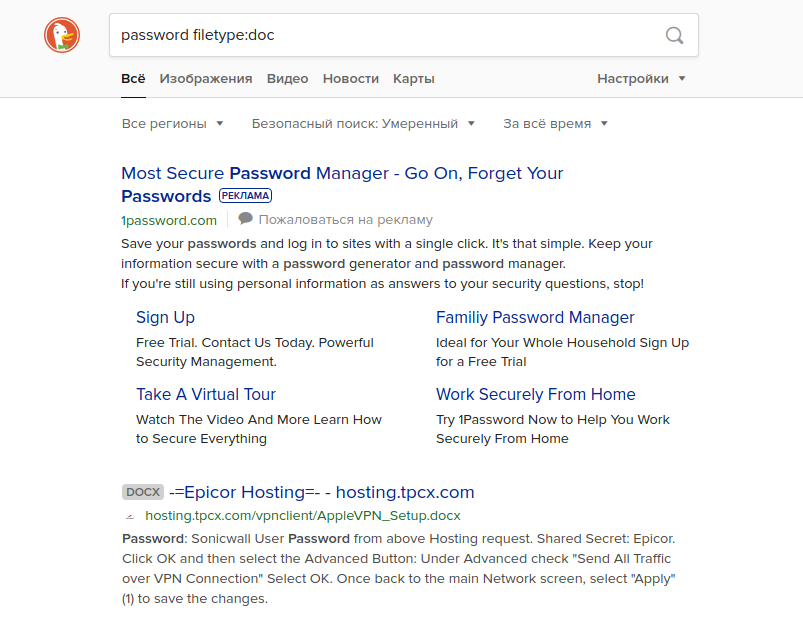
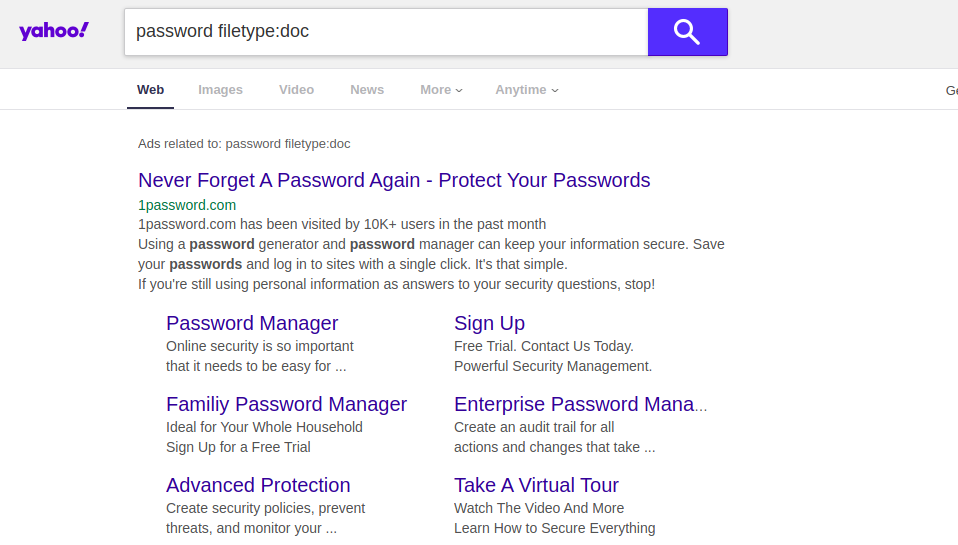
tipo de arquivo de senha: doc / docx / pdf / xls
tipo de arquivo de senha: doc / docx / pdf / xls site: [Nome do site]
Se você tentar inserir essa consulta em outro mecanismo de pesquisa, poderá obter resultados completamente diferentes. Por exemplo, se você executar esta consulta sem o termo "site: [Nome do site] ", o Google retornará resultados de documentos contendo os nomes de usuário e senhas reais de algumas escolas americanas. Outros motores de busca não mostram esta informação nas primeiras páginas de resultados. Como você pode ver abaixo, Yahoo e DuckDuckGo são exemplos.
Preços da habitação em Londres
Outro exemplo interessante diz respeito às informações sobre o preço da habitação em Londres. Abaixo estão os resultados de uma consulta que foi inserida em quatro mecanismos de pesquisa diferentes:
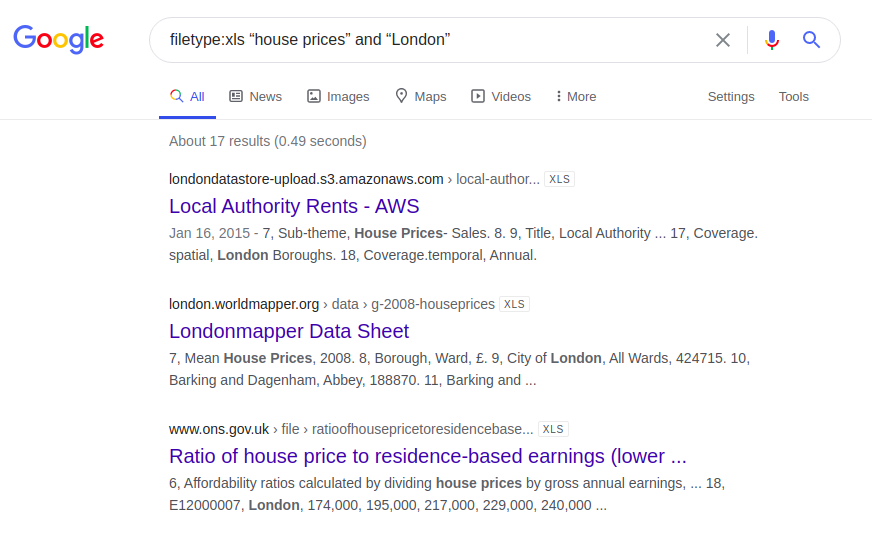
filetype: xls "preços de casas" e "Londres"
Talvez agora você tenha suas próprias ideias e ideias sobre quais sites gostaria de focar em sua própria busca de informações ou como verificar adequadamente seu próprio recurso para possíveis vulnerabilidades ...
Ferramentas alternativas de indexação de pesquisa
Existem também outros métodos de coleta de informações usando o Google Dorking. Todos eles são alternativas e atuam como automação de busca. Abaixo, propomos dar uma olhada em alguns dos projetos mais populares que não são pecado compartilhar.
Google Hacking Online
O Google Hacking Online é uma integração online da pesquisa do Google Dorking de vários dados por meio de uma página da web usando operadores estabelecidos, que você pode encontrar aqui . A ferramenta é um campo de entrada simples para encontrar o endereço IP ou URL desejado de um link para um recurso de interesse, junto com opções de pesquisa sugeridas.
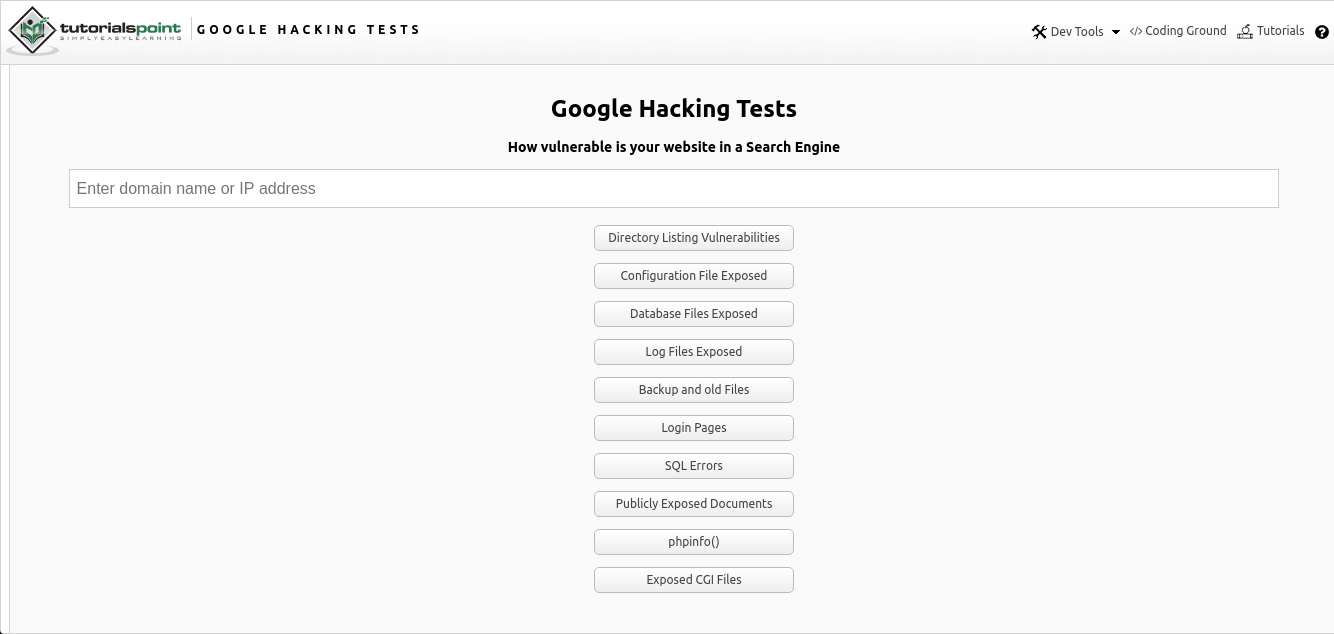
Como você pode ver na imagem acima, a pesquisa por vários parâmetros é fornecida na forma de várias opções:
- Pesquise por diretórios públicos e vulneráveis
- Arquivos de configuração
- Arquivos de banco de dados
- Histórico
- Dados antigos e dados de backup
- Páginas de autenticação
- Erros de SQL
- Documentos publicamente disponíveis
- Informações de configuração do servidor php ("phpinfo")
- Arquivos de interface comum de gateway (CGI)
Tudo funciona no vanilla JS, que é escrito no próprio arquivo da página da web. No início, as informações do usuário inseridas são obtidas, ou seja, o nome do host ou o endereço IP da página da web. Em seguida, é feita uma solicitação aos operadores das informações inseridas. Um link para pesquisar um recurso específico é aberto em uma nova janela pop-up com os resultados fornecidos.
BinGoo
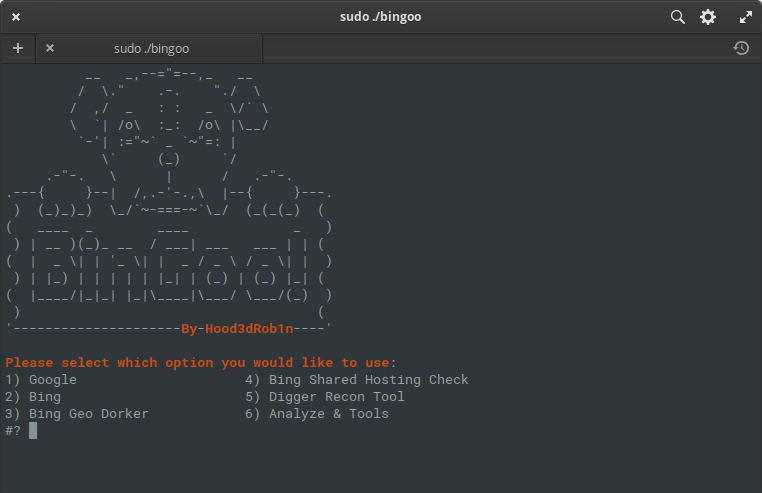
BinGoo é uma ferramenta versátil escrita em bash puro. Ele usa os operadores de pesquisa Google e Bing para filtrar um grande número de links com base nos termos de pesquisa fornecidos. Você pode escolher pesquisar um operador por vez ou listar um operador por linha e realizar uma varredura em massa. Assim que o processo de coleta inicial for concluído, ou você tiver links coletados de outras maneiras, pode passar para as ferramentas de análise para verificar se há sinais comuns de vulnerabilidades.
Os resultados são ordenadamente classificados em arquivos apropriados com base nos resultados obtidos. Mas a análise também não pára por aqui, você pode ir ainda mais longe e executá-los usando a funcionalidade SQL ou LFI adicional, ou você pode usar as ferramentas de wrapper SQLMAP e FIMAP, que funcionam muito melhor, com resultados precisos.
Também estão incluídos vários recursos úteis para tornar a vida mais fácil, como geodorking com base no tipo de domínio, códigos de país no domínio e verificador de hospedagem compartilhada que usa busca Bing pré-configurada e listas de idiotas para procurar possíveis vulnerabilidades em outros sites. Também está incluída uma pesquisa simples por páginas admin com base na lista fornecida e nos códigos de resposta do servidor para confirmação. Em geral, este é um pacote de ferramentas muito interessante e compacto que realiza a coleta principal e a análise da informação fornecida! Você pode se familiarizar com ele aqui .
Pagodo
O objetivo da ferramenta Pagodo é a indexação passiva pelos operadores do Google Dorking para coletar páginas da web e aplicativos potencialmente vulneráveis na Internet. O programa consiste em duas partes. O primeiro é ghdb_scraper.py, que consulta e coleta os operadores Google Dorks, e o segundo, pagodo.py, usa os operadores e as informações coletadas por meio de ghdb_scraper.py e as analisa por meio de consultas do Google.
O arquivo pagodo.py requer uma lista de operadores do Google Dorks para começar. Um arquivo semelhante é fornecido no repositório do próprio projeto ou você pode simplesmente consultar todo o banco de dados por meio de uma única solicitação GET usando ghdb_scraper.py. E então apenas copie as declarações individuais do dorks para um arquivo de texto ou coloque-as em json se dados de contexto adicionais forem necessários.
Para realizar esta operação, você precisa inserir o seguinte comando:
python3 ghdb_scraper.py -j -sAgora que existe um arquivo com todos os operadores necessários, ele pode ser redirecionado para pagodo.py usando a opção "-g" para começar a coletar aplicativos públicos e potencialmente vulneráveis. O arquivo pagodo.py usa a biblioteca "google" para pesquisar esses sites usando operadores como este:
intitle: "ListMail Login" admin -demo
site: example.com
Infelizmente, o processo de tantos pedidos (nomeadamente ~ 4600) através do Google é simples não funciona. O Google irá identificá-lo imediatamente como um bot e bloquear o endereço IP por um determinado período. Várias melhorias foram adicionadas para tornar as consultas de pesquisa mais orgânicas.
O módulo Google Python foi especialmente ajustado para permitir a randomização do agente do usuário nas pesquisas do Google. Este recurso está disponível na versão 1.9.3 do módulo e permite que você randomize os diferentes agentes de usuário usados para cada consulta de pesquisa. Este recurso permite emular diferentes navegadores usados em um grande ambiente corporativo.
O segundo aprimoramento enfoca a randomização do tempo entre as pesquisas. O atraso mínimo é especificado usando o parâmetro -e, e o fator de jitter é usado para adicionar tempo ao número mínimo de atrasos. Uma lista de 50 tremores é gerada e um deles é adicionado aleatoriamente à latência mínima para cada pesquisa do Google.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))Mais adiante no script, um tempo aleatório é selecionado da matriz de jitter e adicionado ao atraso na criação de solicitações:
pause_time = self.delay + random.choice (self.jitter)Você mesmo pode experimentar os valores, mas as configurações padrão funcionam perfeitamente. Observe que o processo da ferramenta pode levar vários dias (em média 3; dependendo do número de operadores especificados e do intervalo de solicitação), portanto, certifique-se de ter tempo para isso.
Para executar a ferramenta em si, basta o seguinte comando, onde "example.com" é o link para o site de interesse e "dorks.txt" é o arquivo de texto que ghdb_scraper.py criou:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1E você pode tocar e se familiarizar com a ferramenta clicando neste link .
Métodos de proteção do Google Dorking
Recomendações principais
O Google Dorking, como qualquer outra ferramenta de código aberto, tem suas próprias técnicas para proteger e impedir que invasores coletem informações confidenciais. As seguintes recomendações dos cinco protocolos devem ser seguidas por administradores de quaisquer plataformas e servidores da web para evitar ameaças do "Google Dorking":
- Atualização sistemática de sistemas operacionais, serviços e aplicativos.
- Implementação e manutenção de sistemas anti-hacker.
- Conhecimento dos robôs do Google e dos vários procedimentos do mecanismo de pesquisa e como validar esses processos.
- Remover conteúdo sensível de fontes públicas.
- Separando conteúdo público, conteúdo privado e bloqueando o acesso ao conteúdo para usuários públicos.
.Htaccess e configuração do arquivo robots.txt
Basicamente, todas as vulnerabilidades e ameaças associadas ao "Dorking" são geradas devido ao descuido ou negligência dos usuários de vários programas, servidores ou outros dispositivos da web. Portanto, as regras de autoproteção e proteção de dados não causam quaisquer dificuldades ou complicações.
Para abordar cuidadosamente a prevenção da indexação de qualquer mecanismo de busca, você deve prestar atenção a dois arquivos de configuração principais de qualquer recurso de rede: ".htaccess" e "robots.txt". O primeiro protege os caminhos e diretórios designados com senhas. O segundo exclui diretórios da indexação pelos motores de busca.
Se o seu próprio recurso contém certos tipos de dados ou diretórios que não devem ser indexados no Google, então, em primeiro lugar, você deve configurar o acesso às pastas por meio de senhas. No exemplo abaixo, você pode ver claramente como e o que exatamente deve ser escrito no arquivo ".htaccess" localizado no diretório raiz de qualquer site.
Primeiro, adicione algumas linhas como mostrado abaixo:
AuthUserFile /your/directory/here/.htpasswd
AuthGroupFile / dev / null
AuthName "seguro Documento"
AuthType Basic
exigem username1 usuário
requerem username2 usuário
requerem USERNAME3 usuário
Na linha AuthUserFile, especifique o caminho para a localização do arquivo .htaccess, que está localizado em seu diretório. E nas últimas três linhas, você precisa especificar o nome de usuário correspondente ao qual o acesso será fornecido. Então você precisa criar ".htpasswd" na mesma pasta que ".htaccess" e executar o seguinte comando:
htpasswd -c .htpasswd username1
Digite a senha para username1 duas vezes e depois disso, um arquivo completamente limpo ".htpasswd" será criado em diretório atual e conterá a versão criptografada da senha.
Se houver vários usuários, você deve atribuir uma senha a cada um deles. Para adicionar usuários adicionais, você não precisa criar um novo arquivo, você pode simplesmente adicioná-los ao arquivo existente sem usar a opção -c usando este comando:
htpasswd .htpasswd username2
Em outros casos, é recomendado configurar um arquivo robots.txt, que é responsável por indexar as páginas de qualquer recurso da web. Ele serve como um guia para qualquer mecanismo de pesquisa com links para endereços de páginas específicos. E antes de ir diretamente para a fonte que você está procurando, o robots.txt bloqueará essas solicitações ou as ignorará.
O próprio arquivo está localizado no diretório raiz de qualquer plataforma da Web em execução na Internet. A configuração é realizada apenas alterando dois parâmetros principais: "User-agent" e "Disallow". O primeiro seleciona e marca todos ou alguns mecanismos de pesquisa específicos. Enquanto o segundo indica o que exatamente precisa ser bloqueado (arquivos, diretórios, arquivos com certas extensões, etc.). Abaixo estão alguns exemplos: diretórios, arquivos e exclusões de mecanismos de pesquisa específicos excluídos do processo de indexação.
User-agent: *
Disallow: / cgi-bin /
User-agent: *
Disallow: /~joe/junk.html
User-agent: Bing
Disallow: /
Usando metatags
Além disso, restrições para web spiders podem ser introduzidas em páginas da web individuais. Eles podem estar localizados em sites, blogs e páginas de configuração típicos. No cabeçalho HTML, eles devem ser acompanhados por uma das seguintes frases:
<meta name = “Robots” content = “none” \>
<meta name = “Robots” content = “noindex, nofollow” \>
Quando você adiciona tal entrada no cabeçalho da página, os robôs do Google não indexam nenhuma página secundária ou principal. Essa string pode ser inserida em páginas que não devem ser indexadas. No entanto, essa decisão é baseada em um acordo mútuo entre os motores de busca e o próprio usuário. Embora o Google e outros web spiders cumpram as restrições mencionadas acima, existem certos robôs da web que “procuram” essas frases para recuperar dados que são configurados inicialmente sem indexação.
Das opções mais avançadas de segurança de indexação, você pode usar o sistema CAPTCHA. Este é um teste de computador que permite que apenas humanos acessem o conteúdo de uma página, não bots automatizados. No entanto, essa opção tem uma pequena desvantagem. Não é muito amigável para os próprios usuários.
Outra técnica defensiva simples do Google Dorks poderia ser, por exemplo, codificar caracteres em arquivos administrativos com ASCII, dificultando o uso do Google Dorking.
Prática Pentesting
As práticas de pentesting são testes para identificar vulnerabilidades na rede e em plataformas web. Eles são importantes em sua própria maneira, porque tais testes determinam exclusivamente o nível de vulnerabilidade de páginas da web ou servidores, incluindo o Google Dorking. Existem ferramentas de pentesting dedicadas que podem ser encontradas na Internet. Um deles é o Site Digger, um site que permite que você verifique automaticamente o banco de dados do Google Hacking em qualquer página da web selecionada. Além disso, também existem ferramentas como o scanner Wikto, SUCURI e vários outros scanners online. Eles funcionam de maneira semelhante.
Existem ferramentas mais sofisticadas que imitam o ambiente da página da web, junto com bugs e vulnerabilidades, para atrair um invasor e, em seguida, recuperar informações confidenciais sobre ele, como o Google Hack Honeypot. Um usuário padrão que tem pouco conhecimento e experiência insuficiente em proteção contra o Google Dorking deve primeiro verificar seus recursos de rede para identificar vulnerabilidades do Google Dorking e verificar quais dados confidenciais estão disponíveis publicamente. Vale a pena verificar esses bancos de dados regularmente, haveibeenpwned.com e dehashed.com , para ver se a segurança de suas contas online foi comprometida e publicada.
https://haveibeenpwned.com/ refere-se a páginas da web mal protegidas onde os dados da conta (endereços de e-mail, logins, senhas e outros dados) foram coletados. O banco de dados contém atualmente mais de 5 bilhões de contas. Uma ferramenta mais avançada está disponível em https://dehashed.com , que permite pesquisar informações por nomes de usuário, endereços de e-mail, senhas e seus hashes, endereços IP, nomes e números de telefone. Além disso, contas vazadas podem ser compradas online. O acesso de um dia custa apenas $ 2.
Conclusão
O Google Dorking é parte integrante da coleta de informações confidenciais e do processo de sua análise. Ele pode ser considerado uma das ferramentas OSINT mais raiz e principais. Os operadores do Google Dorking ajudam a testar seu próprio servidor e a encontrar todas as informações possíveis sobre uma vítima potencial. Este é, de fato, um exemplo muito marcante do uso correto dos motores de busca com o propósito de explorar informações específicas. No entanto, se as intenções de usar essa tecnologia são boas (verificar as vulnerabilidades de seu próprio recurso na Internet) ou ruins (pesquisar e coletar informações de vários recursos e usá-las para fins ilegais), resta apenas aos usuários decidir.
Métodos alternativos e ferramentas de automação fornecem ainda mais oportunidades e conveniência para a análise de recursos da web. Alguns deles, como o BinGoo, estendem a busca regular indexada no Bing e analisam todas as informações recebidas por meio de ferramentas adicionais (SqlMap, Fimap). Eles, por sua vez, apresentam informações mais precisas e específicas sobre a segurança do recurso da web selecionado.
Ao mesmo tempo, é importante saber e lembrar como proteger adequadamente e evitar que suas plataformas online sejam indexadas onde não deveriam. E também aderir às disposições básicas fornecidas para cada administrador da web. Afinal, o desconhecimento e o desconhecimento de que, por engano próprio, outras pessoas obtiveram suas informações, não significa que tudo possa ser devolvido como antes.