
De acordo com uma piada conhecida, todas as memórias nas livrarias deveriam estar localizadas na seção "Ficção Científica". Mas no meu caso, isso é verdade! Há muito tempo,
3D Talking Heads - Este é um busto de bronze de Max Planck de mostrar a língua e piscando; um macaco que copia suas expressões faciais em tempo real; este é um modelo 3D do chefe bastante reconhecível do vice-presidente da Intel, criado de forma totalmente automática a partir de vídeo com sua participação, e muito mais ... Mas primeiro o mais importante.
Vídeo sintético: Talking Heads 3D compatível com MPEG-4 é o nome completo do projeto realizado no Centro de Pesquisa e Desenvolvimento Intel Nizhny Novgorod em 2000-2003. O desenvolvimento foi um conjunto de três tecnologias principais que podem ser usadas juntas e separadamente em muitas aplicações relacionadas à criação e animação de personagens falantes tridimensionais sintéticos.
- Reconhecimento automático e rastreamento de expressões faciais e movimentos da cabeça humana na sequência de vídeo. Ao mesmo tempo, não apenas os ângulos de rotação e inclinação da cabeça em todos os planos são avaliados, mas também os contornos externos e internos dos lábios e dentes durante a conversa, a posição das sobrancelhas, o grau de cobertura dos olhos e até a direção do olhar.
- Animação automática em tempo real de modelos tridimensionais quase arbitrários de cabeças de acordo com os parâmetros de animação obtidos a partir dos algoritmos de reconhecimento e rastreamento do primeiro ponto, bem como de quaisquer outras fontes.
- Criação automática de um modelo 3D fotorrealístico da cabeça de uma pessoa específica usando duas fotos do protótipo (vistas frontal e lateral) ou uma sequência de vídeo em que uma pessoa vira a cabeça de um ombro para outro.
E outro bônus - tecnologia, ou melhor, alguns truques de renderização realista de "cabeças falantes" em tempo real, levando em consideração as limitações de desempenho de hardware e recursos de software que existiam no início dos anos 2000.
E o link entre esses três pontos e meio, assim como o link para a Intel, são quatro letras e um número: MPEG-4.
MPEG-4
Poucas pessoas sabem que o padrão MPEG-4 que surgiu em 1998, além de codificar fluxos de áudio e vídeo reais comuns, fornece informações de codificação sobre objetos sintéticos e sua animação - o chamado vídeo sintético. Um desses objetos é um rosto humano, mais precisamente, uma cabeça definida como uma superfície triangulada - uma malha no espaço 3D. MPEG-4 define 84 pontos especiais no rosto de uma pessoa - Pontos de Característica (FP): cantos e pontos médios dos lábios, olhos, sobrancelhas, ponta do nariz, etc.
Os Parâmetros de Animação Facial (FAP) são aplicados a esses pontos especiais (ou a todo o modelo como um todo no caso de voltas e inclinações), descrevendo a mudança na posição e expressão facial em comparação com o estado neutro.
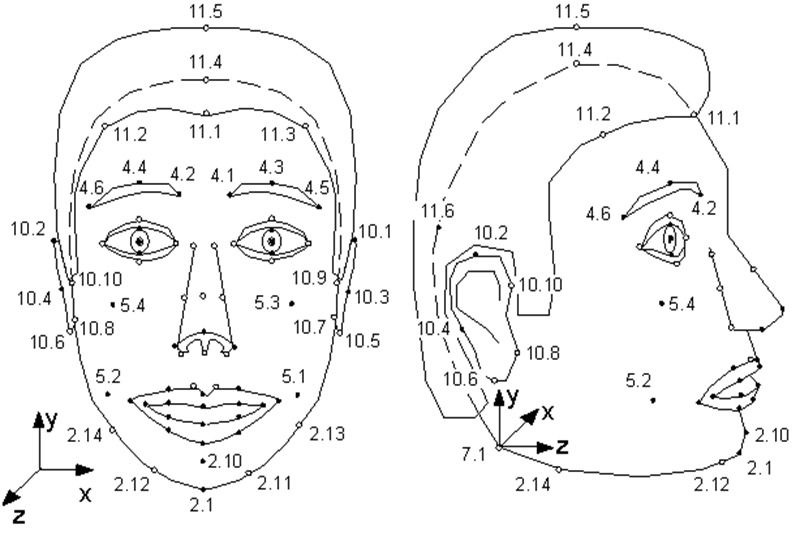
Ilustração da especificação MPEG-4. Pontos singulares do modelo. Como você pode ver, a modelo pode cheirar e mexer as orelhas.
Ou seja, a descrição de cada quadro de vídeo sintético que mostra um personagem falante parece um pequeno conjunto de parâmetros pelos quais o decodificador MPEG-4 deve animar o modelo.
Qual modelo? O MPEG-4 tem duas opções. Ou o modelo é criado pelo codificador e transmitido para o decodificador uma vez no início da sequência, ou o decodificador tem seu próprio modelo proprietário, que é usado na animação.
Ao mesmo tempo, os únicos requisitos MPEG-4 para o modelo: armazenamento em VRML-formato e a presença de pontos especiais. Ou seja, um modelo pode servir como cópia fotorrealística de uma pessoa cujo FAP é usado para animação, bem como um modelo de qualquer outra pessoa, e até mesmo uma chaleira falante - o principal é que ele, além de nariz, tem boca e olhos.

Um dos nossos modelos compatíveis com MPEG-4 é o mais sorridente
Além do objeto principal "rosto", o MPEG-4 descreve objetos independentes "maxilar superior", "maxilar inferior", "língua", "olhos", nos quais também são colocados pontos especiais. Mas se algum modelo não tiver esses objetos, os FAPs correspondentes simplesmente não serão usados pelo decodificador.

- Modelo, modelo, por que você tem olhos e dentes tão grandes? - Para se animar melhor!
De onde vêm os modelos de animação personalizados? Como faço para obter FAP? E, finalmente, como você implementa animação e renderização realistas com base nesses FAPs? O MPEG-4 não dá nenhuma resposta a todas essas perguntas - assim como qualquer padrão de compressão de vídeo, nada diz sobre o processo de filmagem e o conteúdo dos filmes que codifica.
Até onde chegou o progresso? Até milagres sem precedentes!
Claro, tanto o modelo quanto a animação podem ser criados manualmente por artistas profissionais, gastando dezenas de horas e recebendo dezenas de centenas de dólares. Mas isso restringe significativamente o escopo da tecnologia, tornando-a inaplicável em escala industrial. E há muitas aplicações potenciais para a tecnologia, que na verdade comprime quadros de vídeo de alta resolução em vários bytes (ah, é uma pena que não seja nenhum vídeo). Em primeiro lugar, networking - jogos, educação e comunicação (videoconferência) usando personagens sintéticos.
Esses aplicativos eram especialmente relevantes há 20 anos, quando a Internet ainda era acessada por modems, e a Internet ilimitada em gigabit parecia ser algo como teletransporte. Mas, como mostra a vida, em 2020, a largura de banda dos canais de Internet em muitos casos ainda é um problema. E mesmo que não haja esse problema, digamos, estamos falando de uso local, os caracteres sintéticos são capazes de muito. Por exemplo, "ressuscite" um ator famoso do século passado em um filme, ou dê a oportunidade de olhar nos olhos dos agora populares e ainda sem corpo assistentes de voz. Mas primeiro, o processo de transição de um vídeo real de uma pessoa falante para um sintético deve se tornar automático, ou pelo menos, com o mínimo de participação humana.
Isso é exatamente o que foi implementado em Nizhny Novgorod Intel. A ideia surgiu primeiro como parte da implementação da Biblioteca de Processamento MPEG, desenvolvida uma vez pela Intel, e então cresceu não apenas em um spin-off completo, mas em um verdadeiro blockbuster fantástico.
Além disso, completamente "made in Russia" - este projeto parece ser o único para toda a existência da Intel russa, não havia curador na Intel USA. Justin Ratner (chefe da divisão de pesquisa do Intel Labs) gostou da ideia durante sua visita a Nizhny Novgorod e autorizou a

Valery Fedorovich Kuryakin sintético, produtor, diretor, roteirista e, em alguns lugares, o dublê do projeto - na época o chefe do grupo de desenvolvimento da Intel.
Em primeiro lugar, a combinação de tecnologias tão diferentes em um pequeno projeto, no qual apenas três a sete pessoas trabalharam ao mesmo tempo, foi fantástica. Naqueles anos, já existiam pelo menos uma dezena de empresas no mundo que se dedicavam tanto ao reconhecimento e rastreamento facial quanto à criação e animação de "cabeças falantes". Todos eles, é claro, tiveram conquistas em algumas áreas: alguns tiveram excelente qualidade de modelo, alguns mostraram animações muito realistas, alguns tiveram sucesso no reconhecimento e rastreamento. Mas nenhuma empresa conseguiu oferecer todo o conjunto de tecnologias que permite criar de forma totalmente automática um vídeo sintético, no qual um modelo, muito semelhante ao seu protótipo, copie perfeitamente as suas expressões faciais e movimentos.
O projeto Intel 3D Talking Heads foi o primeiro e, na época, a única implementação de um ciclo completo de comunicação por vídeo baseado em todos os elementos do perfil sintético MPEG-4.

Transportadora do projeto de produção de clones sintéticos do modelo 2003.
Em segundo lugar, a combinação do hardware existente na época e as soluções tecnológicas implementadas no projeto, bem como os planos para a sua utilização, foi fantástica. Portanto, no início do projeto, eu tinha um Nokia 3310 no bolso, um Pentium III-500MHz no meu desktop e algoritmos que eram especialmente críticos para o desempenho do trabalho em tempo real foram testados em um servidor Pentium 4-1,7 GHz com 128 Mb de RAM.
Ao mesmo tempo, esperávamos que logo nossos modelos funcionassem em dispositivos móveis, e a qualidade não seria pior do que a dos heróis do filme de animação fotorrealista " Final Fantasy " lançado na época (2001) .

$ 137 milhões foi o custo para um filme criado em um farm de renderização de aproximadamente 1000 computadores Pentium III. Cartaz do site www.thefinalfantasy.com
Mas vamos ver o que aconteceu com a gente.
Reconhecimento e rastreamento de face, aquisição FAP.
Esta tecnologia foi apresentada em duas versões:
- modo em tempo real (25 quadros por segundo no já citado processador Pentium 4-1,7 GHz), quando uma pessoa diretamente em frente a uma câmera de vídeo conectada a um computador é rastreada;
- ( 1 ), .
Ao mesmo tempo, a dinâmica das mudanças na posição / estado do rosto humano foi monitorada em tempo real - podíamos estimar aproximadamente os ângulos de rotação e inclinação da cabeça em todos os planos, o grau aproximado de abertura e alongamento da boca e elevação das sobrancelhas, e reconhecer o piscar. Para alguns aplicativos, essa estimativa aproximada é suficiente, mas se você precisar rastrear com precisão as expressões faciais de uma pessoa, serão necessários algoritmos mais complexos, o que significa outros mais lentos.
No modo offline, nossa tecnologia tornou possível avaliar não apenas a posição da cabeça como um todo, mas reconhecer e rastrear com absoluta precisão os contornos externos e internos dos lábios e dentes durante uma conversa, a posição das sobrancelhas, o grau de cobertura dos olhos e até mesmo o deslocamento das pupilas - a direção do olhar.
Para reconhecimento e rastreamento, uma combinação de algoritmos de visão computacional bem conhecidos foi usada, alguns dos quais já haviam sido implementados na biblioteca OpenCV recém-lançada - por exemplo, Fluxo Óptico, bem como nossos próprios métodos originais baseados em conhecimento a priori da forma dos objetos correspondentes. Em particular - em nossa versão melhorada do método de modelos deformáveis , para o qual os participantes do projeto receberam uma patente .
A tecnologia foi implementada na forma de uma biblioteca de funções que recebia quadros de vídeo com rosto humano como entrada e saída dos FAPs correspondentes.
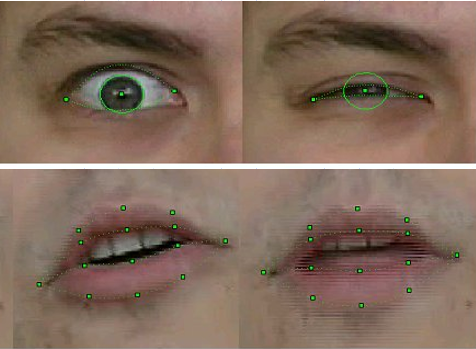
Qualidade de reconhecimento e rastreamento de amostra de FP 2003
Claro, a tecnologia era imperfeita. O reconhecimento e o rastreamento falhavam se a pessoa no quadro tivesse bigode, óculos ou rugas profundas. Mas ao longo de três anos de trabalho, a qualidade melhorou significativamente. Se nas primeiras versões para modelos de reconhecimento de movimento, ao gravar um vídeo, era necessário colocar marcas especiais nos pontos FP correspondentes do rosto - círculos de papel branco obtidos com um soco de escritório, então no final do projeto nada do tipo era necessário, é claro. Além disso, conseguíamos rastrear de forma bastante constante a posição dos dentes e a direção do olhar - e isso na resolução de vídeo de webcams daquela época, onde tais detalhes mal eram distinguíveis!

Isso não é catapora, mas imagens da "infância" da tecnologia de reconhecimento. Intel Principle Engineer, e na época - o novato funcionário da Intel Alexander Bovyrin ensina um modelo sintético para ler poesia
Animação
Como já foi dito várias vezes, a animação do modelo no MPEG-4 é totalmente determinada pelo FAP. E tudo seria simples, se não fosse por alguns problemas.
Primeiro, o fato de que os FAPs das sequências de vídeo são extraídos em 2D, e o modelo é 3D, e é necessário completar de alguma forma a terceira coordenada. Ou seja, um sorriso de boas-vindas no perfil (e os usuários devem ser capazes de ver esse perfil, caso contrário, haverá pouco sentido em 3D) não deve se transformar em um sorriso sinistro.
Em segundo lugar, como também foi dito, FAPs descrevem o movimento de pontos singulares, dos quais existem cerca de oitenta no modelo, enquanto pelo menos um modelo um tanto realista como um todo consiste em vários milhares de vértices (no nosso caso, de quatro a oito mil), e algoritmos são necessários para calcular o deslocamento de todos os outros pontos no modelo com base nos deslocamentos FP.
Ou seja, é claro que quando a cabeça é virada em um ângulo igual, todos os pontos irão virar, mas ao sorrir, mesmo que seja até as orelhas, a "indignação" do deslocamento do canto da boca deve desaparecer gradualmente, mover a bochecha, mas não as orelhas. Além disso, isso deve acontecer de forma automática e realista para qualquer modelo com qualquer largura de boca e geometria de malha ao seu redor. Para resolver esses problemas, algoritmos de animação foram criados no projeto. Eles foram baseados em um modelo pseudomuscular, que simplesmente descreve os músculos que controlam as expressões faciais.
E então, para cada modelo e cada FAP, a "zona de influência" foi determinada preliminarmente de forma automática - os vértices envolvidos na ação correspondente, cujos movimentos foram calculados levando em conta a anatomia e geometria - mantendo a suavidade e conectividade da superfície. Ou seja, a animação consistia em duas partes - preliminar, executada offline, onde certos coeficientes para vértices da malha foram criados e inseridos na tabela, e online, onde, levando em consideração os dados da tabela, a animação em tempo real foi aplicada ao modelo.

Sorrir não é fácil para um modelo 3D e seus criadores
Criação de um modelo 3D de uma pessoa específica.
No caso geral, a tarefa de reconstruir um objeto tridimensional a partir de suas imagens bidimensionais é muito difícil. Ou seja, os algoritmos para sua solução são conhecidos há muito da humanidade, mas na prática, por diversos fatores, o resultado obtido está longe do desejado. E isso é especialmente perceptível no caso da reconstrução do formato do rosto de uma pessoa - aqui você pode se lembrar de nossos primeiros modelos com olhos em forma de oito (a sombra dos cílios nas fotos originais não teve sucesso) ou uma ligeira bifurcação do nariz (o motivo não pode ser restaurado depois de anos).
Mas, no caso de cabeças falantes MPEG-4, a tarefa é muito simplificada, porque o conjunto de características faciais humanas (nariz, boca, olhos, etc.) é o mesmo para todas as pessoas e as diferenças externas pelas quais todos nós (e programas de visão de computador) distinguimos pessoas umas das outras "geométricas" - o tamanho / proporções e localização dessas características e "texturizadas" - cores e relevo. Portanto, um dos perfis de vídeo sintético MPEG-4, calibração, que foi implementado no projeto, pressupõe que o decodificador tenha um modelo generalizado de uma "pessoa abstrata" que é personalizada para uma pessoa específica usando uma foto ou sequência de vídeo.
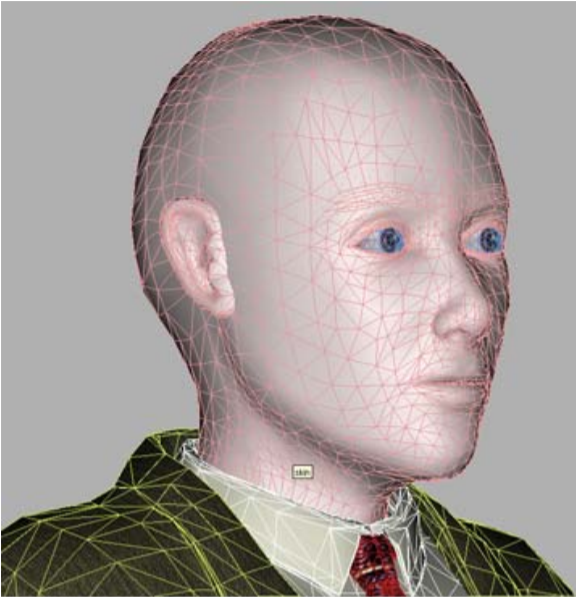
Nosso "homem esférico no vácuo" - um modelo para personalização
Ou seja, as deformações globais e locais da malha 3D ocorrem para coincidir com as proporções das características faciais do protótipo destacadas em sua foto / vídeo, após o que a "textura" do protótipo é aplicada ao modelo - ou seja, uma textura criada a partir das mesmas imagens de entrada. O resultado é um modelo sintético. Isso é feito uma vez para cada modelo, é claro off-line e, claro, não é tão fácil.
Em primeiro lugar, é necessário o registro ou retificação das imagens de entrada - trazendo-as para um sistema de coordenadas que coincide com o sistema de coordenadas do modelo 3D. Além disso, é necessário detectar pontos especiais nas imagens de entrada e, com base em sua localização, deformar o modelo 3D, por exemplo, usando o método de funções de base radiale então, usando algoritmos de costura de panorama , gerar uma textura a partir de duas ou mais imagens de entrada, ou seja, "misturá-las" na proporção correta para obter o máximo de informação visual, além de compensar a diferença de iluminação e tom, que está sempre presente mesmo nas fotos tiradas com as mesmas configurações da câmera (o que nem sempre é o caso), e muito perceptível ao combinar essas fotos.

Este não é um still de filmes de terror, mas a textura de um modelo 3D de Pat Gelsinger , criado com sua permissão quando o projeto foi demonstrado no Intel Developer Forum em 2003
A versão inicial da tecnologia de personalização do modelo com base em duas fotos foi implementada pelos próprios participantes do projeto na Intel. Mas ao atingir um certo nível de qualidade e perceber as limitações de suas capacidades, decidiu-se transferir esta parte do trabalho para o grupo de pesquisa da Universidade Estadual de Moscou, que tinha experiência nesta área. O resultado do trabalho de pesquisadores da Moscow State University sob a liderança de Denis Ivanov foi o aplicativo “Head Calibration Environment”, que realizava todas as operações acima para criar um modelo personalizado de uma pessoa a partir de sua foto de rosto e perfil.
O único ponto sutil é que o aplicativo não estava integrado com a unidade de reconhecimento facial descrita acima, que foi desenvolvida em nosso projeto, então os pontos especiais na foto necessários para o funcionamento dos algoritmos tiveram que ser marcados manualmente. Claro, nem todos os 84, mas apenas os principais, e como o aplicativo tinha uma interface de usuário adequada, essa operação demorou apenas alguns segundos.
Além disso, foi implementada uma versão totalmente automática da reconstrução do modelo a partir de uma sequência de vídeo, na qual uma pessoa vira a cabeça de um ombro para o outro. Mas, como você pode imaginar, a qualidade da textura extraída do vídeo era significativamente pior do que a textura criada a partir de fotografias de câmeras digitais da época com resolução de ~ 4K (3-5 megapixels), o que significa que o modelo resultante parecia menos atraente. Portanto, havia também uma versão intermediária usando várias fotos de diferentes ângulos de rotação da cabeça.

A linha superior é de pessoas virtuais, a linha inferior é real.
Quão bom foi o resultado alcançado? A qualidade do modelo resultante deve ser avaliada não em estática, mas diretamente no vídeo sintético por sua semelhança com o vídeo correspondente do original. Mas os termos "semelhantes e não semelhantes" não são matemáticos, dependem da percepção de uma pessoa em particular, e é difícil entender como nosso modelo sintético e sua animação diferem do protótipo. Algumas pessoas gostam, outras não. Mas o resultado de três anos de trabalho foi que, ao demonstrar os resultados em várias exposições, o público teve que explicar em que janela o vídeo real estava à sua frente e em qual - o sintético.
Visualização.
Para demonstrar os resultados de todas as tecnologias acima, um reprodutor de vídeo sintético MPEG-4 especial foi criado. O player recebeu como entrada um arquivo VRML com um modelo, um stream (ou arquivo) com FAP, bem como streams (arquivos) com vídeo real e áudio para exibição sincronizada com vídeo sintético com suporte para o modo "picture in picture". Ao demonstrar um vídeo sintético, o usuário teve a oportunidade de ampliar o modelo, bem como vê-lo de todos os lados, simplesmente girando o mouse em um ângulo arbitrário.

Embora o player tenha sido escrito para Windows, mas levando em consideração a possível portabilidade no futuro para outros sistemas operacionais, incluindo os móveis. Portanto, o "clássico" OpenGL 1.1 sem quaisquer extensões foi escolhido como a biblioteca 3D.
Ao mesmo tempo, o jogador não só mostrou o modelo, mas também tentou melhorá-lo, mas não retocá-lo, como é costume nos modelos fotográficos, mas, ao contrário, torná-lo o mais realista possível. Ou seja, mantendo-se dentro da estrutura da iluminação Phong mais simples e sem shaders, mas com requisitos de desempenho estritos, a unidade de renderização do jogador criava automaticamente modelos sintéticos: rugas mímicas, cílios, capazes de estreitar e dilatar realisticamente as pupilas; coloque óculos de tamanho adequado no modelo; e também usando o traçado de raios mais simples, ele calculou a iluminação (sombreamento) da língua e dos dentes ao falar.
Claro, agora esses métodos não são mais relevantes, mas lembrá-los é muito interessante. Assim, para a síntese das rugas mímicas, ou seja, pequenas dobras do relevo da pele na face, visíveis durante a contração dos músculos faciais, os tamanhos relativamente grandes dos triângulos da malha do modelo não permitiam a criação de dobras reais. Portanto, um tipo de tecnologia de mapeamento de relevo foi aplicada - mapeamento normal. Em vez de alterar a geometria do modelo, a direção das normais para a superfície nos lugares corretos mudou, e a dependência do componente difuso de iluminação em cada ponto da normal criou o efeito desejado.

Isso é realismo sintético.
Mas o jogador não parou por aí. Para a comodidade de usar tecnologias e transferi-las para o mundo exterior, foi criada a biblioteca de objetos Intel Facial Animation Library, contendo funções de animação (transformação 3D) e visualização do modelo, para que quem quiser (e tiver uma fonte FAP) chame várias funções - "Criar Cena", " CreateActor ”,“ Animate ”poderia animar e mostrar seu modelo em seu aplicativo.
Resultado
O que a participação neste projeto me deu pessoalmente? Claro, a oportunidade de colaborar com pessoas maravilhosas em tecnologias interessantes. Eles me levaram para o projeto devido ao meu conhecimento de métodos e bibliotecas para renderizar modelos 3D e otimizar o desempenho para x86. Mas, naturalmente, não foi possível nos limitarmos ao 3D, então tivemos que ir para outras dimensões. Para escrever um player, era necessário lidar com a análise VRML (não existiam bibliotecas prontas para esse fim), dominar o trabalho nativo com streams no Windows, garantindo o trabalho conjunto de vários threads com sincronização 25 vezes por segundo, não esquecendo da interação do usuário, e até mesmo pensar e implementar interface. Posteriormente, essa lista foi complementada pela participação no aprimoramento dos algoritmos de rastreamento facial. E a necessidade de integrar constantemente e simplesmente combinar componentes escritos por outros membros da equipe com o jogador,e também apresentar o projeto para o mundo externo melhorou muito minhas habilidades de comunicação e coordenação.
O que a participação da Intel neste projeto proporcionou? Como resultado, nossa equipe criou um produto que pode servir como um bom teste e demonstração dos recursos das plataformas e produtos Intel. Além disso, tanto o hardware - CPU e GPU, quanto o software - nossas cabeças (reais e sintéticas) contribuíram para o aprimoramento da biblioteca OpenCV.
Além disso, podemos afirmar com segurança que o projeto deixou uma marca visível na história - como resultado de seu trabalho, seus participantes escreveram artigos e apresentaram relatórios em conferências especializadas em visão computacional e computação gráfica, russa ( GraphiCon ) e internacional.
E os aplicativos de demonstração do 3D Talking Heads foram mostrados pela Intel em dezenas de exposições, fóruns e congressos ao redor do mundo.
Nesse meio tempo, a tecnologia, é claro, avançou muito, tornando mais fácil criar e animar automaticamente personagens sintéticos. Havia a definição de profundidade da câmara Intel Real Sense , e as redes neurais baseadas em grandes dados aprenderam a gerar imagens realistas de pessoas, mesmo inexistentes.
Mas, mesmo assim, os desenvolvimentos do projeto 3D Talking Heads, postados em domínio público, continuam a ser vistos até agora.
Olhe para o nosso jovem alto-falante MPEG-4 sintético de quase 20 anos e você: