
Artigos anteriores da série
Talvez hoje eu até quebre a tradição e depure o projeto não no complexo Redd, mas em um layout regular. Em primeiro lugar, estou ciente de que a esmagadora maioria dos leitores não tem acesso a um complexo assim, mas eles têm acesso ao Ali Express. Bem, e em segundo lugar, estou com preguiça de cercar um jardim com um par de dispositivos USB e host conectados, e também para lidar com a interferência emergente.
Em 2017, eu estava procurando soluções prontas na rede e encontrei uma coisa tão maravilhosa , ou melhor, seu ancestral. Agora eles têm tudo em uma placa especializada, mas em todos os lugares havia fotos de uma placa de ensaio simples do Xilinx, à qual uma placa do WaveShare estava conectada (você pode aprender sobre isso aqui ). Vamos dar uma olhada na foto deste quadro.

Possui dois conectores USB ao mesmo tempo. Além disso, o diagrama mostra que eles são paralelos. Você pode conectar seus dispositivos USB a um soquete do tipo A e conectar um cabo ao conector mini USB, que iremos conectar ao host. E a descrição do projeto OpenVizsla diz que dessa maneira funciona. A única pena é que o projeto em si seja bastante difícil de ler. Você pode acessá-lo no github, mas darei um link para a conta indicada na página, todos o encontrarão de qualquer maneira, mas foi refeito para o MiGen, mas a versão que encontrei em 2017: http: // github. com / ultraembedded / núcleos, está em um Verilog limpo e existe o ramo usb_sniffer. Lá, tudo não passa diretamente pelo ULPI, mas pelo conversor ULPI para UTMI (essas duas palavras obscenas são microcircuitos de nível físico que correspondem ao canal USB 2.0 de alta velocidade com barramentos compreensíveis para processadores e FPGAs) e só depois trabalham com esse UTMI. Como tudo funciona lá, eu ainda não descobri. Portanto, eu preferi fazer meu desenvolvimento do zero, pois veremos em breve que tudo é assustador e não difícil.
Em que hardware você pode trabalhar
A resposta para a pergunta do título é simples: em qualquer pessoa com um FPGA e memória externa. Obviamente, nesta série, consideraremos apenas os FPGAs da Altera (Intel). No entanto, lembre-se de que os dados do microcircuito ULPI (estão no lenço) são executados a 60 MHz. Fios longos não são aceitáveis aqui. Também é importante conectar a linha CLK à entrada FPGA do grupo GCK, caso contrário, tudo funcionará e falhará. Melhor não arriscar. Não aconselho que você encaminhe programaticamente. Eu tentei. Tudo terminou com um fio na perna do grupo GCK.
Para as experiências de hoje, a meu pedido, um conhecido me soldou um sistema assim:

Micromodule com FPGA e SDRAM (procure-o no ALI expresso pela frase FPGA AC608) e a mesma placa ULPI da WaveShare. É assim que o módulo fica nas fotos de um dos vendedores. Estou com preguiça de soltá-lo do gabinete:

a propósito, os orifícios de ventilação, como na foto do meu gabinete, são muito interessantes. No modelo, desenhe uma camada sólida e, no slicer, defina o preenchimento, digamos, 40% e diga que você precisa criar zero camadas sólidas da parte inferior e superior. Como resultado, a impressora 3D extrai essa ventilação. Muito confortavelmente.
Em geral, a abordagem para encontrar hardware é clara. Agora começamos a projetar o analisador. Em vez disso, já fizemos o próprio analisador nos últimos dois artigos ( aqui nós trabalhamos com hardware , e aqui - com acesso a ele ), agora vamos simplesmente projetar uma cabeça orientada para o problema que os dados de capturas provenientes do microcircuito ULPI.
O que a cabeça deve ser capaz de fazer
No caso do analisador lógico, tudo foi fácil e simples. Existem dados. Nós nos conectamos a eles e começamos a fazer as malas e enviá-los para o barramento AVALON_ST. Tudo é mais complicado aqui. A especificação ULPI pode ser encontrada aqui . Noventa e três folhas de texto chato. Pessoalmente, isso me leva ao desânimo. A descrição do chip USB3300, instalado na placa WaveShare, parece um pouco mais simples. Você pode obtê-lo aqui . Embora eu ainda tenha acumulado coragem desde o mesmo mês de dezembro de 2017, às vezes lendo o documento e fechando-o imediatamente, pois senti a aproximação da depressão.
A partir da descrição, fica claro que o ULPI possui um conjunto de registros que devem ser preenchidos antes de iniciar o trabalho. Isso se deve principalmente a resistências de pull-up e terminação. Aqui está uma imagem para explicar o ponto:

Dependendo da função (host ou dispositivo), bem como da velocidade selecionada, diferentes resistores devem ser incluídos. Mas não somos um host nem um dispositivo! Devemos desconectar todos os resistores para não interferir nos principais dispositivos do barramento! Isso é feito escrevendo para os registros.
Bem, e velocidade. É necessário escolher uma velocidade de trabalho. Para fazer isso, você também precisa escrever nos registros.
Quando temos tudo configurado, você pode começar a buscar dados. Porém, em nome da ULPI, as letras "LP" significam "Pinos baixos". E essa mesma redução no número de pernas levou a um protocolo tão furioso que se mantém! Vamos dar uma olhada no protocolo.
Protocolo ULPI
O protocolo ULPI é um tanto incomum para o homem comum. Mas se você se senta com um documento e medita, alguns recursos mais ou menos compreensíveis começam a aparecer. Está ficando claro que os desenvolvedores fizeram todos os esforços para reduzir realmente o número de contatos usados.
Não digitarei novamente a documentação completa aqui. Vamos nos limitar às coisas mais importantes. O mais importante deles é a direção dos sinais. É impossível lembrar, é melhor olhar sempre a foto: o

ULPI LINK é o nosso FPGA.
Diagrama de tempo da recepção de dados
Em repouso, devemos emitir uma constante 0x00 no barramento de dados, que corresponde ao comando IDLE. Se os dados vierem do barramento USB, o protocolo de troca ficará assim:
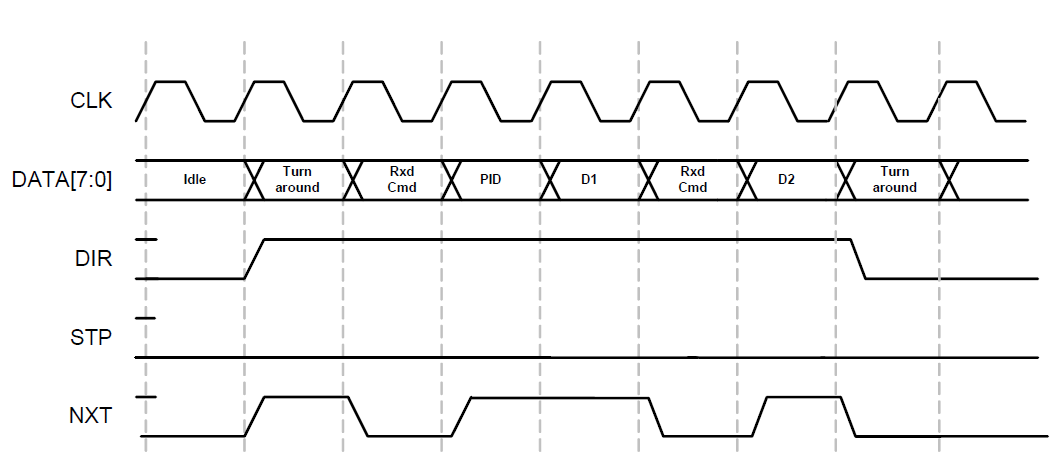
O ciclo começará com o fato de o sinal DIR subir até um. Primeiro, haverá um ciclo de relógio para que o sistema tenha tempo de mudar a direção do barramento de dados. Além disso - milagres da economia começam. Veja o nome do sinal NXT? Significa PRÓXIMO quando transmitido de nós. E aqui está um sinal completamente diferente. Quando DIR é um, eu chamaria NXT C / D. Baixo nível - temos uma equipe. Dados altos.
Ou seja, devemos corrigir 9 bits (o barramento DATA e o sinal NXT) sempre em um DIR alto (depois filtrando o primeiro relógio por software) ou iniciando no segundo relógio após o DIR decolar. Se a linha DIR cair para zero, trocamos o barramento de dados para escrever e novamente começamos a transmitir o comando IDLE.
Com a recepção de dados - é claro. Agora vamos analisar o trabalho com registradores.
Diagrama de tempo de gravação no registro ULPI
Para escrever no registro, a seguinte casa temporária é usada (eu deliberadamente mudei para o jargão, porque sinto que estou tendendo a GOST 2.105, e isso é chato, então vou
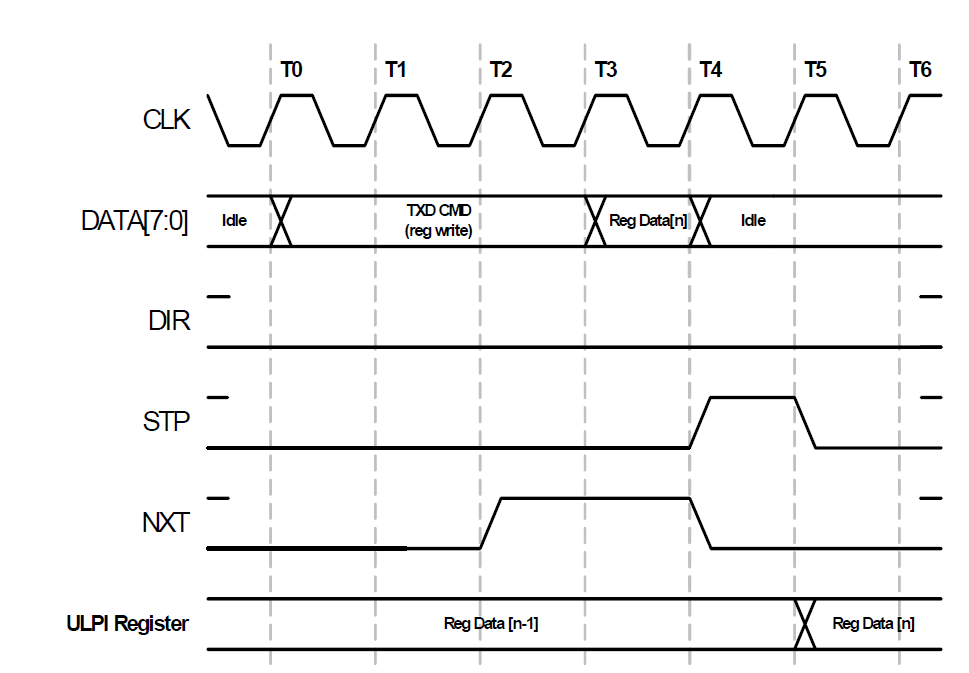
me afastar dele): Antes de tudo, devemos esperar pelo estado DIR = 0. No relógio T0, devemos definir a constante TXD CMD no barramento de dados. O que isso significa? Você não pode descobrir isso imediatamente, mas se você pesquisar um pouco os documentos, o valor desejado pode ser encontrado aqui:

ou seja, os bits de dados altos devem ser configurados para o valor "10" (para todo o byte, a máscara é 0x80) e os inferiores - o número do registro.
Em seguida, você deve esperar o sinal NXT decolar. Com esse sinal, o microcircuito confirma que nos ouviu. Na figura acima, esperamos no relógio T2 e ajustamos os dados no próximo relógio (T3). No relógio T4, o ULPI receberá os dados e removerá o NXT. E marcaremos o final do ciclo de troca de unidades no STP. No T5 também, os dados serão travados no registro interno. O processo terminou. Aqui está um retorno para um pequeno número de conclusões. Mas precisaremos gravar os dados apenas na inicialização, portanto, é claro, teremos que sofrer com o desenvolvimento, mas tudo isso não afetará particularmente o trabalho.
Diagrama de tempo da leitura do registro ULPI
Honestamente, para tarefas práticas, a leitura de registros não é tão importante, mas vamos ver também. A leitura será útil pelo menos para garantir que implementamos o registro corretamente.
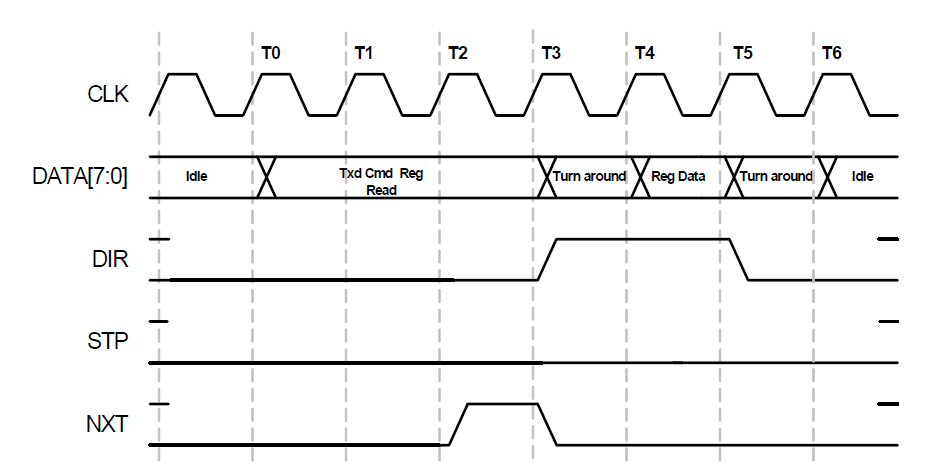
Vemos que diante de nós há uma mistura explosiva das duas casas temporárias anteriores. Definimos o endereço como fizemos para gravar no registro e coletamos os dados de acordo com as regras de leitura de dados.
Bem? Vamos começar a projetar um autômato que moldará tudo isso para nós?
Diagrama estrutural da cabeça
Como você pode ver na descrição acima, o cabeçote deve ser conectado a dois barramentos ao mesmo tempo: AVALON_MM para acessar registros e AVALON_ST para emitir dados a serem armazenados na RAM. A principal coisa na cabeça é o cérebro. E, portanto, deve ser uma máquina de estado que gere os diagramas de tempo que consideramos anteriormente.

Vamos começar seu desenvolvimento com a função de receber dados. Deve-se ter em mente aqui que não podemos influenciar o fluxo do barramento ULPI de nenhuma maneira. Os dados de lá, se começaram a ir, vão. Eles não se importam se o barramento AVALON_ST está pronto ou não. Portanto, simplesmente ignoraremos a indisponibilidade do ônibus. Em um analisador real, será possível adicionar uma indicação de alarme em caso de saída de dados sem prontidão. Tudo deve ser simples dentro da estrutura do artigo, então vamos lembrar disso para o futuro. E para garantir a disponibilidade do barramento, como em um analisador lógico, teremos um bloco FIFO externo. No total, o gráfico de transição do autômato para receber o fluxo de dados é o seguinte:
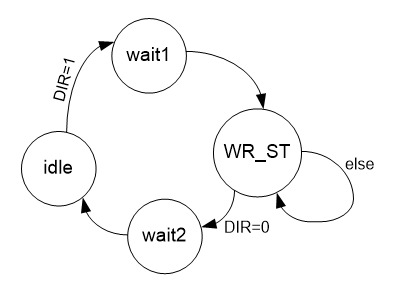
DIR decolou - começou a receber. Penduramos um relógio na espera1, depois o aceitamos enquanto DIR é igual a um. Caiu para zero - depois de um relógio (embora não seja necessário, mas por enquanto vamos definir o estado wait2) voltou ao modo inativo.
Até agora, tudo é simples. Não esqueça que não apenas as linhas D0_D7, mas também a linha NXT devem ir para o barramento AVALON_ST, pois determina o que está sendo transmitido agora: um comando ou dados.
Um ciclo de gravação de registro pode ter um tempo de execução imprevisível. Do ponto de vista do barramento AVALON_MM, isso não é muito bom. Portanto, vamos torná-lo um pouco mais complicado. Vamos criar um registro de buffer. Os dados entrarão nele, após o qual o barramento AVALON_MM será liberado imediatamente. Do ponto de vista do autômato em desenvolvimento, o sinal de entrada have_reg aparece (os dados no registro foram recebidos, os quais devem ser enviados) e o sinal de saída reg_served (o que significa que o processo de emissão do registro está concluído). Adicione a lógica da gravação ao registro no gráfico de transição do autômato.
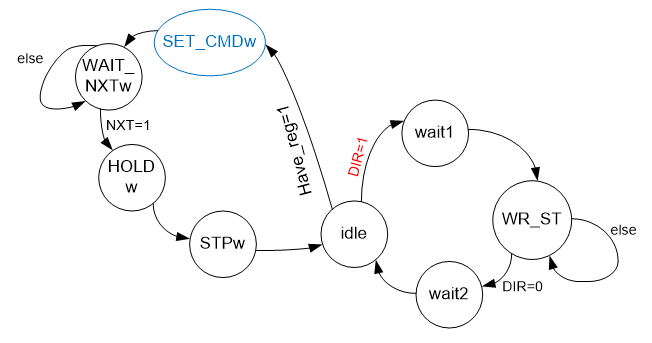
Eu destaquei a condição DIR = 1 em vermelho para deixar claro que ela tem a maior prioridade. Então é possível excluir a expectativa do valor zero do sinal DIR na nova ramificação da máquina. Fazer login em uma ramificação com um valor diferente simplesmente não será possível. O estado SET_CMDw é azul, pois é mais provável que seja puramente virtual. Estas são apenas ações a serem executadas! Ninguém se preocupa em definir a constante correspondente no barramento de dados e apenas durante a transição! No estado STPw, entre outras coisas, o sinal reg_served também pode ser acionado por um ciclo de relógio para limpar o sinal BSY do barramento AVALON_MM, permitindo um novo ciclo de gravação.
Bem, resta adicionar uma ramificação para a leitura do registro ULPI. Aqui, o oposto é verdadeiro. A máquina do serviço de ônibus nos envia uma solicitação e aguarda nossa resposta. Quando os dados são recebidos, ele pode processá-los. E funcionará com suspensão ou sondagem de ônibus, esses já são os problemas dessa máquina. Hoje eu decidi trabalhar em uma pesquisa. Solicitando dados - o BSY apareceu. Como o BSY desapareceu - você pode receber dados de leitura. No total, o gráfico assume a forma:
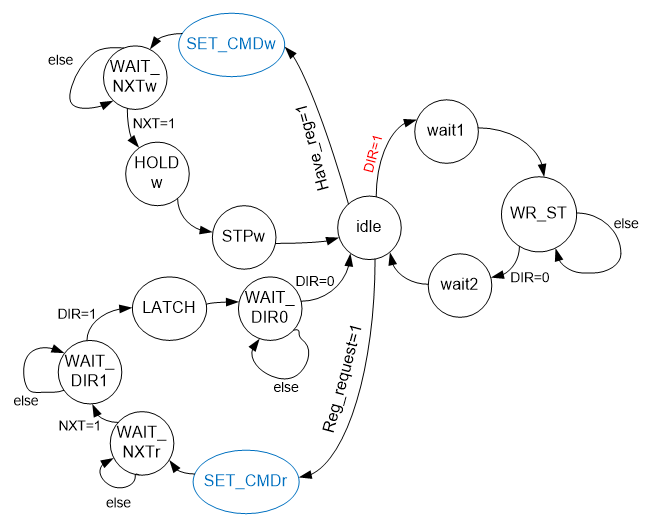
Talvez, no decorrer do desenvolvimento, haja alguns ajustes, mas, por enquanto, aderiremos a esse gráfico. Afinal, este não é um relatório, mas uma instrução sobre a metodologia de desenvolvimento. E a técnica é tal que primeiro você precisa desenhar um gráfico de transição e, em seguida - faça a lógica, de acordo com esta figura, ajustada para obter detalhes pop-up.
Recursos da implementação de autômatos do lado AVALON_MM
Ao trabalhar com o barramento AVALON_MM, você pode seguir de duas maneiras. O primeiro é criar atrasos no acesso ao barramento. Exploramos esse mecanismo em um dos artigos anteriores e avisei que ele está cheio de problemas. A segunda maneira é clássica. Digite o registro de status. No início da transação, defina o sinal BSY, na sua conclusão - redefinir. E atribua a responsabilidade por tudo à lógica principal do barramento (processador Nios II ou ponte JTAG). Cada uma das opções tem suas próprias vantagens e desvantagens. Como já fizemos variantes com atrasos de barramento, vamos fazer tudo hoje, para variar, através do registro de status.
Nós projetamos a máquina principal
A primeira coisa que gostaria de chamar sua atenção são meus gatilhos RS favoritos. Nós temos duas máquinas. O primeiro serve o barramento AVALON_MM, o segundo - a interface ULPI. Descobrimos que a conexão entre eles passa por algumas bandeiras. Somente um processo pode gravar em cada sinalizador. Cada autômato é implementado por seu próprio processo. Como ser? Há algum tempo, comecei a adicionar um gatilho RS. Como temos dois bits, eles devem ser gerados por dois chinelos RS. Aqui estão eles:
//
always_ff @(posedge ulpi_clk)
begin
//
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
//
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
Um processo cocks reg_served, o segundo cocks have_reg. E o RS-flip-flop em seu próprio processo gera o sinal write_busy em sua base. Da mesma forma, read_busy é formado a partir de read_finished e reg_request. Você pode fazer isso de maneira diferente, mas nesta fase do caminho do criativo, eu gosto desse método.
É assim que os sinalizadores BSY são definidos. Amarelo é para o processo de escrita, azul para o processo de leitura. O processo de Verilogov tem uma característica muito interessante. Nele, você pode atribuir valores não uma vez, mas várias vezes. Portanto, se eu quiser que um sinal decole por um ciclo de clock, eu o anulo no início do processo (vemos que os dois sinais são nulos lá) e o defino como um por uma condição que é executada durante um ciclo de clock. A inserção da condição substituirá o padrão. Em todos os outros casos, funcionará. Assim, a gravação na porta de dados inicia a decolagem do sinal have_reg por um ciclo de clock, e a gravação do bit 0 na porta de controle inicia a decolagem do sinal reg_request.

O mesmo texto.
// AVALON_MM
always_ff @(posedge ulpi_clk)
begin
// ,
//
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
//
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
//
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
Como vimos acima, um ciclo de clock é suficiente para o flip-flop RS correspondente ser definido como um. E a partir deste momento, o sinal BSY definido começa a ser lido no registro de status:

O mesmo texto.
// AVALON_MM
always_comb
begin
case (address)
// ( )
0 : readdata <= {26'b0, addr_to_ulpi};
//
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - , -
//
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
Na verdade, tão naturalmente nos familiarizamos com os processos que atendem ao barramento AVALON_MM.
Deixe-me lembrá-lo também dos princípios de trabalho com o barramento ulpi_data. Este barramento é bidirecional. Portanto, você deve usar uma técnica padrão para trabalhar com ela. É assim que a porta correspondente é declarada:
inout [7:0] ulpi_data,
Podemos ler neste barramento, mas não podemos escrever diretamente. Em vez disso, criamos uma cópia para o registro.
logic [7:0] ulpi_d = 0;
E nós conectamos esta cópia ao barramento principal através do seguinte multiplexador:
// inout-
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
Tentei comentar a lógica da máquina principal o máximo possível dentro do código Verilog. Como eu esperava durante o desenvolvimento do gráfico de transição, na implementação real, a lógica mudou um pouco. Alguns dos estados foram jogados fora. No entanto, comparando o gráfico e o texto fonte, espero que você entenda tudo o que é feito lá. Portanto, não vou falar sobre esta máquina. É melhor fornecer como referência o texto completo do módulo, relevante antes da modificação, com base nos resultados de experimentos práticos.
Texto completo do módulo.
module ULPIhead
(
input reset,
output clk66,
// AVALON_MM
input [1:0] address,
input write,
input [31:0] writedata,
input read,
output logic [31:0] readdata = 0,
// AVALON_ST
input logic source_ready,
output logic source_valid = 0,
output logic [15:0] source_data = 0,
// ULPI
inout [7:0] ulpi_data,
output logic ulpi_stp = 0,
input ulpi_nxt,
input ulpi_dir,
input ulpi_clk,
output ulpi_rst
);
logic have_reg = 0;
logic reg_served = 0;
logic reg_request = 0;
logic read_finished = 0;
logic [5:0] addr_to_ulpi;
logic [7:0] data_to_ulpi;
logic [7:0] data_from_ulpi;
logic write_busy = 0;
logic read_busy = 0;
logic [7:0] ulpi_d = 0;
logic force_reset = 0;
//
always_ff @(posedge ulpi_clk)
begin
//
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
//
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
// AVALON_MM
always_comb
begin
case (address)
// ( )
0 : readdata <= {26'b0, addr_to_ulpi};
//
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - , -
//
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
// AVALON_MM
always_ff @(posedge ulpi_clk)
begin
// ,
//
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
//
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
//
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
//
enum {idle,
wait1,wr_st,
wait_nxt_w,hold_w,
wait_nxt_r,wait_dir1,latch,wait_dir0
} state = idle;
always_ff @ (posedge ulpi_clk)
begin
if (reset)
begin
state <= idle;
end else
begin
//
source_valid <= 0;
reg_served <= 0;
ulpi_stp <= 0;
read_finished <= 0;
case (state)
idle: begin
if (ulpi_dir)
state <= wait1;
else if (have_reg)
begin
// ,
// ,
//
ulpi_d [7:6] <= 2'b10;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_w;
end
else if (reg_request)
begin
// -
ulpi_d [7:6] <= 2'b11;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_r;
end
end
// TURN_AROUND
wait1 : begin
state <= wr_st;
// ,
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end
// DIR - AVALON_ST
wr_st : begin
if (ulpi_dir)
begin
// ,
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end else
// wait2,
// , - .
state <= idle;
end
wait_nxt_w : begin
if (ulpi_nxt)
begin
ulpi_d <= data_to_ulpi;
state <= hold_w;
end
end
hold_w: begin
// , ULPI
// . NXT
// ...
if (ulpi_nxt) begin
// , AVALON_MM
reg_served <= 1;
ulpi_d <= 0; // idle
ulpi_stp <= 1; // STP
state <= idle; // - idle
end
end
// STPw ...
// ...
// . , NXT
// ,
wait_nxt_r : begin
if (ulpi_nxt)
begin
ulpi_d <= 0; //
state <= wait_dir1;
end
end
// ,
wait_dir1: begin
if (ulpi_dir)
state <= latch;
end
//
// -
latch: begin
data_from_ulpi <= ulpi_data;
state <= wait_dir0;
end
// ,
wait_dir0: begin
if (!ulpi_dir)
begin
state <= idle;
read_finished <= 1;
end
end
default: begin
state <= idle;
end
endcase
end
end
// inout-
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
// reset ,
assign ulpi_rst = reset | force_reset;
assign clk66 = ulpi_clk;
endmodule
Guia do Programador
Porta do endereço de registro ULPI (+0)
O endereço do registro ULPI do barramento, com o qual o trabalho será realizado, deve ser colocado na porta com deslocamento +0
Porta de dados de registro ULPI (+4)
Ao gravar nesta porta: o processo de gravação no registro ULPI, cujo endereço foi definido na porta do endereço do registro, inicia automaticamente. É proibido gravar nesta porta até que o processo da gravação anterior seja concluído.
Na leitura: Esta porta retornará o valor obtido da última leitura do registro ULPI.
Porta de controle ULPI (+8)
A leitura é sempre zero. A atribuição de bits para gravação é a seguinte:
Bit 0 - Ao escrever um único valor, inicia o processo de leitura do registro ULPI, cujo endereço é definido na porta de endereço do registro ULPI.
Bit 31 - Ao escrever um, envia um sinal de RESET para o chip ULPI.
O restante dos bits está reservado.
Porta de status (+ 0x0C)
Somente leitura.
Bit 0 - WRITE_BUSY. Se for igual a um, o processo de gravação no registro ULPI está em andamento.
Bit 1 - READ_BUSY. Se for igual a um, o processo de leitura do registro ULPI está em andamento.
O restante dos bits está reservado.
Conclusão
Nós nos familiarizamos com o método de organização física da cabeça do analisador USB, projetamos um autômato básico para trabalhar com o microcircuito ULPI e implementamos um esboço do módulo SystemVerilog para essa cabeça. Nos artigos a seguir, examinaremos o processo de modelagem, simularemos este módulo e, em seguida, realizaremos experiências práticas com ele, de acordo com os resultados dos quais concluiremos o código de maneira limpa. Ou seja, até o final, temos pelo menos mais quatro artigos.