
Devo dizer imediatamente: não sou especialista em TI, mas entusiasta no campo da estatística. Além disso, participei de várias competições de previsão da Fórmula 1 ao longo dos anos. Daí as tarefas que meu modelo enfrentou: emitir previsões que não seriam piores do que aquelas criadas "a olho nu". E, idealmente, o modelo, é claro, deve derrotar oponentes humanos.
Esse modelo se concentra apenas na previsão do resultado das qualificações, pois as qualificações são mais previsíveis que as corridas e mais fáceis de modelar. No entanto, é claro, no futuro planejo criar um modelo que permita prever os resultados das corridas com uma precisão suficientemente boa.
Para criar um modelo, resumi todos os resultados de práticas e qualificações para as temporadas 2018 e 2019 em uma tabela: 2018 serviu como amostra de treinamento e 2019 como amostra de teste. Com base nesses dados, construímos uma regressão linear . Para simplificar a regressão, nossos dados são uma coleção de pontos em um plano de coordenadas. Traçamos uma linha reta que se desvia menos da totalidade desses pontos. E a função, cujo gráfico é essa linha - esta é a nossa regressão linear.
A partir da fórmula conhecida no currículo escolarnossa função é diferenciada apenas pelo fato de termos duas variáveis. A primeira variável (X1) é o atraso na terceira prática e a segunda variável (X2) é o atraso médio nas qualificações anteriores. Essas variáveis não são equivalentes e um de nossos objetivos é determinar o peso de cada variável no intervalo de 0 a 1. Quanto mais uma variável for de zero, mais importante será a explicação da variável dependente. No nosso caso, a variável dependente é o tempo da volta, expresso no atraso por trás do líder (ou, mais precisamente, de um certo “círculo ideal”, pois esse valor foi positivo para todos os pilotos).
Os fãs do livro Moneyball (que não são explicados no filme) podem se lembrar de que, usando regressão linear, eles determinaram que a porcentagem base, também conhecida como OBP (porcentagem na base), está mais intimamente relacionada às feridas obtidas do que outras estatísticas. Nosso objetivo é aproximadamente o mesmo: entender quais fatores estão mais relacionados aos resultados das qualificações. Uma das grandes vantagens da regressão é que ela não requer conhecimentos avançados de matemática: apenas inserimos os dados e, em seguida, o Excel ou outro editor de planilha nos fornece coeficientes prontos.
Basicamente, queremos saber duas coisas com regressão linear. Primeiro, até que ponto nossas variáveis independentes escolhidas explicam a mudança na função. E segundo, quão importante é cada uma dessas variáveis independentes. Em outras palavras, o que melhor explica os resultados da qualificação: os resultados das corridas nas pistas anteriores ou os resultados das sessões de treinamento na mesma pista.
Um ponto importante deve ser observado aqui. O resultado final foi a soma de dois parâmetros independentes, cada um deles resultante de duas regressões independentes. O primeiro parâmetro é a força da equipe nesta fase, mais precisamente, o atraso do melhor piloto da equipe em relação ao líder. O segundo parâmetro é a distribuição de forças dentro da equipe.
O que isso significa por exemplo? Digamos que participemos do Grande Prêmio da Hungria de 2019. O modelo mostra que a Ferrari estará 0,218 segundos atrás do líder. Mas esse é o atraso do primeiro piloto, e quem eles serão - Vettel ou Leclair - e qual será a diferença entre eles é determinada por outro parâmetro. Neste exemplo, o modelo mostrou que Vettel estará à frente e Leclair perderá 0,096 segundos para ele.
Por que essas dificuldades? Não é mais fácil considerar cada piloto separadamente, em vez dessa repartição entre o atraso da equipe e o atraso do primeiro piloto do segundo da equipe? Talvez seja assim, mas minhas observações pessoais mostram que é muito mais confiável olhar para os resultados da equipe do que para os resultados de cada piloto. Um piloto pode cometer um erro ou sair da pista ou ele terá problemas técnicos - tudo isso trará caos ao modelo, a menos que você rastreie manualmente cada situação de força maior, o que leva muito tempo. A influência da força maior nos resultados da equipe é muito menor.
Mas voltando ao ponto em que queríamos avaliar quão bem nossas variáveis explicativas escolhidas explicam a mudança na função. Isso pode ser feito usando o coeficiente de determinação. Demonstrará até que ponto os resultados da qualificação são explicados pelos resultados de estágios e qualificações anteriores.
Como construímos duas regressões, também temos dois coeficientes de determinação. A primeira regressão é responsável pelo nível da equipe no estágio, a segunda pelo confronto entre os pilotos da mesma equipe. No primeiro caso, o coeficiente de determinação é 0,82, ou seja, 82% dos resultados das qualificações são explicados pelos fatores que escolhemos e outros 18% - por alguns outros fatores que não levamos em consideração. Este é um bom resultado. No segundo caso, o coeficiente de determinação foi de 0,13.
Essas métricas, em essência, significam que o modelo prevê o nível da equipe razoavelmente bem, mas tem problemas para determinar a diferença entre os colegas de equipe. No entanto, para o objetivo final, não precisamos conhecer a diferença, precisamos apenas saber qual dos dois pilotos será maior e o modelo basicamente lida com isso. Em 62% dos casos, o modelo obteve uma classificação mais alta do que o piloto que realmente foi mais alto na qualificação.
Ao mesmo tempo, ao avaliar a força da equipe, os resultados do último treinamento foram uma vez e meia mais importantes que os resultados das qualificações anteriores, mas nos duelos entre equipes, foi o contrário. A tendência se manifestou nos dados de 2018 e 2019.
A fórmula final é assim:
Primeiro piloto:
Segundo piloto:
Deixe-me lembrá-lo de que X1 é o atraso na terceira prática e X2 é o atraso médio nas qualificações anteriores.
O que estes números significam. Eles significam que o nível da equipe na qualificação é 60% determinado pelos resultados do terceiro treino e 40% - pelos resultados das qualificações nas etapas anteriores. Consequentemente, os resultados da terceira prática são fator uma vez e meia mais significativo do que os resultados das qualificações anteriores.
Os fãs da Fórmula 1 provavelmente sabem a resposta para essa pergunta, mas, para o resto, você deve comentar por que eu peguei os resultados do terceiro treino. Existem três práticas na Fórmula 1. No entanto, é no último deles que as equipes tradicionalmente treinam qualificações. No entanto, nos casos em que o terceiro treino falhou devido a chuva ou outra força maior, peguei os resultados do segundo treino. Tanto quanto me lembro, em 2019, houve apenas um desses casos - no Grande Prêmio do Japão, quando, devido a um tufão, o palco foi realizado em um formato reduzido.
Além disso, alguém provavelmente percebeu que o modelo usa o atraso médio nas qualificações anteriores. Mas e a primeira etapa da temporada? Usei as defasagens do ano anterior, mas não as deixei como estão, mas as ajustei manualmente com base no senso comum. Por exemplo, em 2019, a Ferrari foi em média 0,3 segundos mais rápida que a Red Bull. No entanto, parece que a equipe italiana não terá essa vantagem este ano, ou talvez esteja completamente atrasada. Portanto, para a primeira etapa da temporada 2020, o Grande Prêmio da Áustria, aproximei manualmente o Red Bull da Ferrari.
Dessa forma, obtive o atraso de cada piloto, classifiquei os pilotos pelo atraso e obtive a previsão final para a qualificação. É importante entender, no entanto, que o primeiro e o segundo pilotos são convenções puras. Voltando ao exemplo com Vettel e Leclair, no Grande Prêmio da Hungria, a modelo considerou Sebastian o primeiro piloto, mas em muitos outros estágios ela preferiu Leclair.
resultados
Como eu disse, a tarefa era criar um modelo que possibilitasse prever tanto quanto as pessoas. Como base, tomei minhas previsões e as de meus colegas de equipe, que foram criadas "a olho nu", mas com um estudo cuidadoso dos resultados das práticas e discussão conjunta.
O sistema de classificação foi o seguinte. Apenas os dez melhores pilotos foram levados em consideração. Para um acerto preciso, a previsão recebeu 9 pontos, uma falta na posição 1, 6 pontos, uma falta na posição 2, 4 pontos, uma falta na posição 3, 2 pontos e uma falta na posição 4, 1 ponto. Ou seja, se na previsão o piloto estiver em 3º lugar e, como resultado, ele conquistou a pole position, a previsão recebeu 4 pontos.
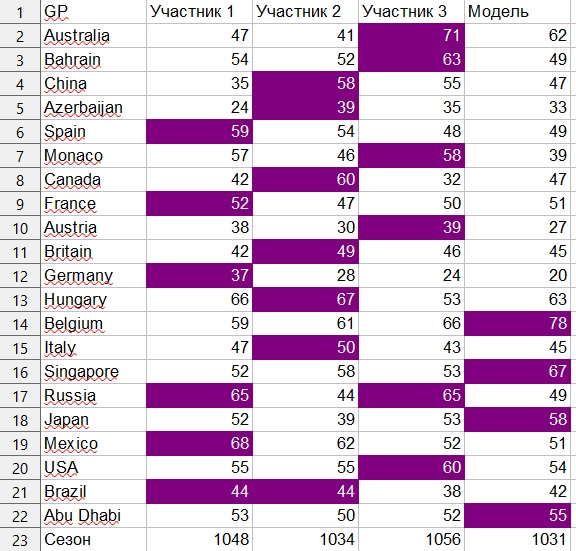
Com esse sistema, o número máximo de pontos para o Grande Prêmio de 21 é 1890.
Os participantes humanos obtiveram 1056, 1048 e 1034 pontos, respectivamente.
O modelo marcou 1031 pontos, embora com a manipulação leve dos coeficientes, também recebi 1045 e 1053 pontos.
Pessoalmente, estou satisfeito com os resultados, pois esta é minha primeira experiência na construção de regressões e levou a resultados bastante aceitáveis. Obviamente, eu gostaria de melhorá-los, porque tenho certeza de que, com a ajuda da construção de modelos, mesmo que simples como este, você pode obter melhores resultados do que apenas avaliar os dados "a olho". Dentro da estrutura desse modelo, seria possível, por exemplo, levar em consideração o fator de que algumas equipes são fracas na prática, mas “disparam” nas qualificações. Por exemplo, há uma observação de que a Mercedes muitas vezes não era a melhor equipe durante o treinamento, mas teve um desempenho muito melhor nas qualificações. No entanto, essas observações humanas não foram refletidas no modelo. Portanto, na temporada 2020, que começa em julho (se nada de inesperado acontecer), quero testar esse modelo em uma competição contra meteorologistas ao vivo e também descobrir,como isso pode ser melhorado.
Além disso, espero ter uma repercussão na comunidade de fãs da Fórmula 1 e acreditar que, através da troca de idéias, possamos entender melhor o que constitui os resultados de qualificações e corridas, e esse é o objetivo de qualquer pessoa que faça previsões.