bayt.
Por que "isso" deve "se preocupar"
Os dados são armazenados na memória na forma de estruturas de dados, como objetos, listas, matrizes etc. Mas se você deseja enviar dados pela rede ou para um arquivo, é necessário codificá-los como uma sequência de baytov. as representações na memória em uma seqüência de bytes são chamadas de codificação e transformação inversa - dekodirovaniem. eventualmente, o diagrama de dados processado pelo aplicativo ou armazenado na memória pode evoluir, novos campos podem ser adicionados ou removidos temporariamente. Usado,,,,,,,,,,,,,,,,,,,Também edirecionar (código antigo) deve ser armazenado listaablecapaz de ler dados screvernovo código) compatibilidade..
No
presente artigo, vamos discutir uma variedade de formatos de codificação, descobrir por que o binário de codificação é melhor do que JSON, XML, e também como métodos de codificação binários apoiar esquemas de mudanças
dannyh.
Tipos formatos de codificação
Existemdois tipos de formatos de codificação:
- Textos formatos
- Formatos binários
Formatos de texto
Formatos de texto Exemplos de formatos comuns são JSON, CSV e XML. Os formatos de texto são fáceis de usar e entender, mas têm alguns problemas:
- . , XML CSV . JSON , , . . , , 2^53 Twitter, 64- . JSON, API Twitter, ID — JSON- – - , JavaScript- .
- CSV , .
- Os formatos de texto ocupam mais espaço do que a codificação binária. Por exemplo, um dos motivos é que JSON e XML não têm esquema e, portanto, devem conter nomes de campos.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}A codificação JSON deste exemplo leva 82 bytes depois que todo o espaço em branco foi removido.
Codificação binária
Para a análise de dados usada apenas internamente, você pode escolher um formato mais enxuto ou mais rápido. Embora o JSON seja menos detalhado que o XML, os dois ainda ocupam muito espaço quando comparados aos formatos binários. Neste artigo, discutiremos três formatos diferentes de codificação binária:
- Thrift
- Buffers de protocolo
- Avro
Todos eles fornecem serialização eficiente de dados usando esquemas e possuem ferramentas para gerar código, além de suporte para trabalhar com diferentes linguagens de programação. Todos eles suportam a evolução do esquema, fornecendo compatibilidade com versões anteriores e posteriores.
Buffers de Thrift e Protocolo
O Thrift é desenvolvido pelo Facebook e o Protocol Buffers é desenvolvido pelo Google. Nos dois casos, é necessário um esquema para codificar os dados. O Thrift define um esquema usando sua própria linguagem de definição de interface (IDL).
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
Esquema equivalente para buffers de protocolo:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}Como você pode ver, cada campo tem um tipo de dados e número de tag (1, 2 e 3). O Thrift possui dois formatos diferentes de codificação binária: BinaryProtocol e CompactProtocol. O formato binário é simples, como mostrado abaixo, e leva 59 bytes para codificar os dados acima.
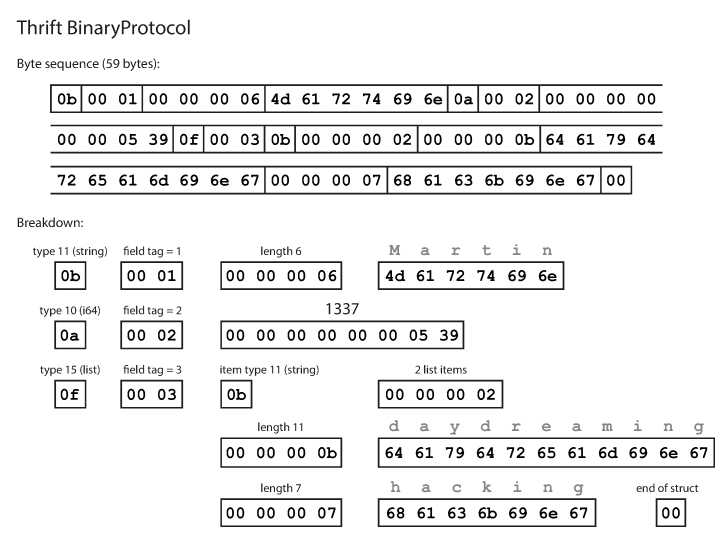
Codificação usando o protocolo binário Thrift O protocolo
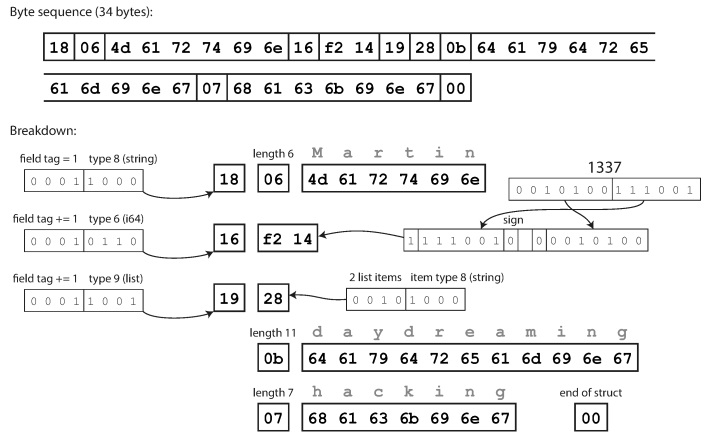
compacto é semanticamente equivalente ao binário, mas compacta as mesmas informações em apenas 34 bytes. A economia é obtida ao empacotar o tipo de campo e o número da etiqueta em um byte.
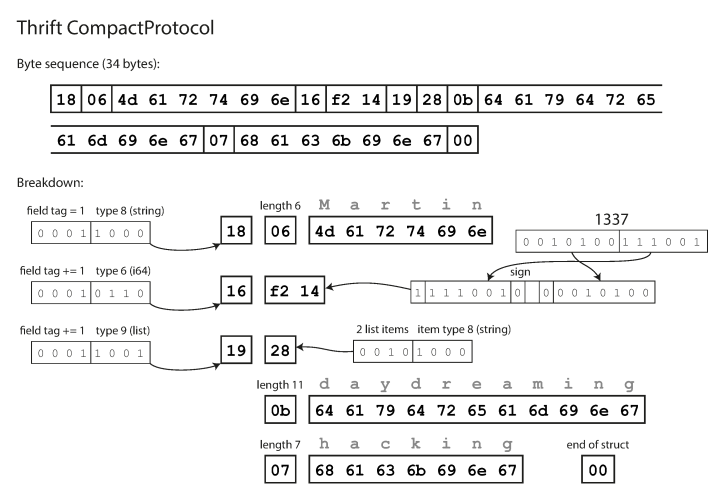
Codificação usando o Thrift Compact
Protocol Buffers codifica os dados de maneira semelhante ao protocolo compacto da Thrift e, após a codificação, os mesmos dados são de 33 bytes.
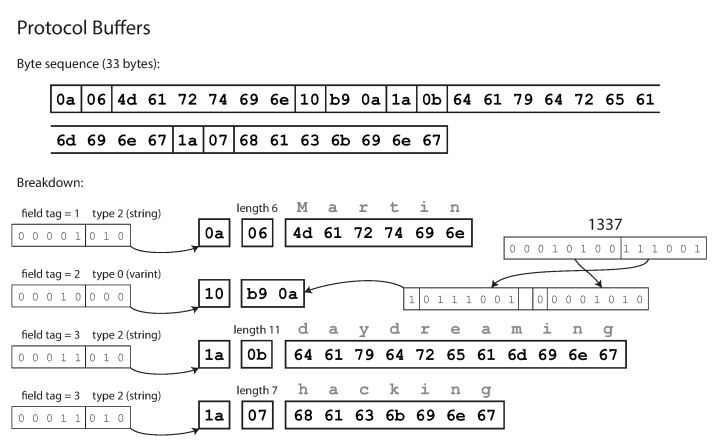
Codificação usando buffers de protocolo
Os números de tag suportam a evolução dos esquemas nos Thrift e Protocol Buffers. Se o código antigo tentar ler os dados gravados com o novo esquema, ele simplesmente ignorará os campos com os novos números de tag. Da mesma forma, o novo código pode ler os dados gravados no esquema antigo, marcando os valores como nulos para os números de tags ausentes.
Avro
O Avro é diferente de Buffers de Protocolo e Thrift. O Avro também usa um esquema para definir dados. O esquema pode ser definido usando o Avro IDL (formato legível por humanos):
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Ou JSON (um formato mais legível por máquina):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
Observe que os campos não têm números de etiqueta. Os mesmos dados codificados com o Avro levam apenas 32 bytes.
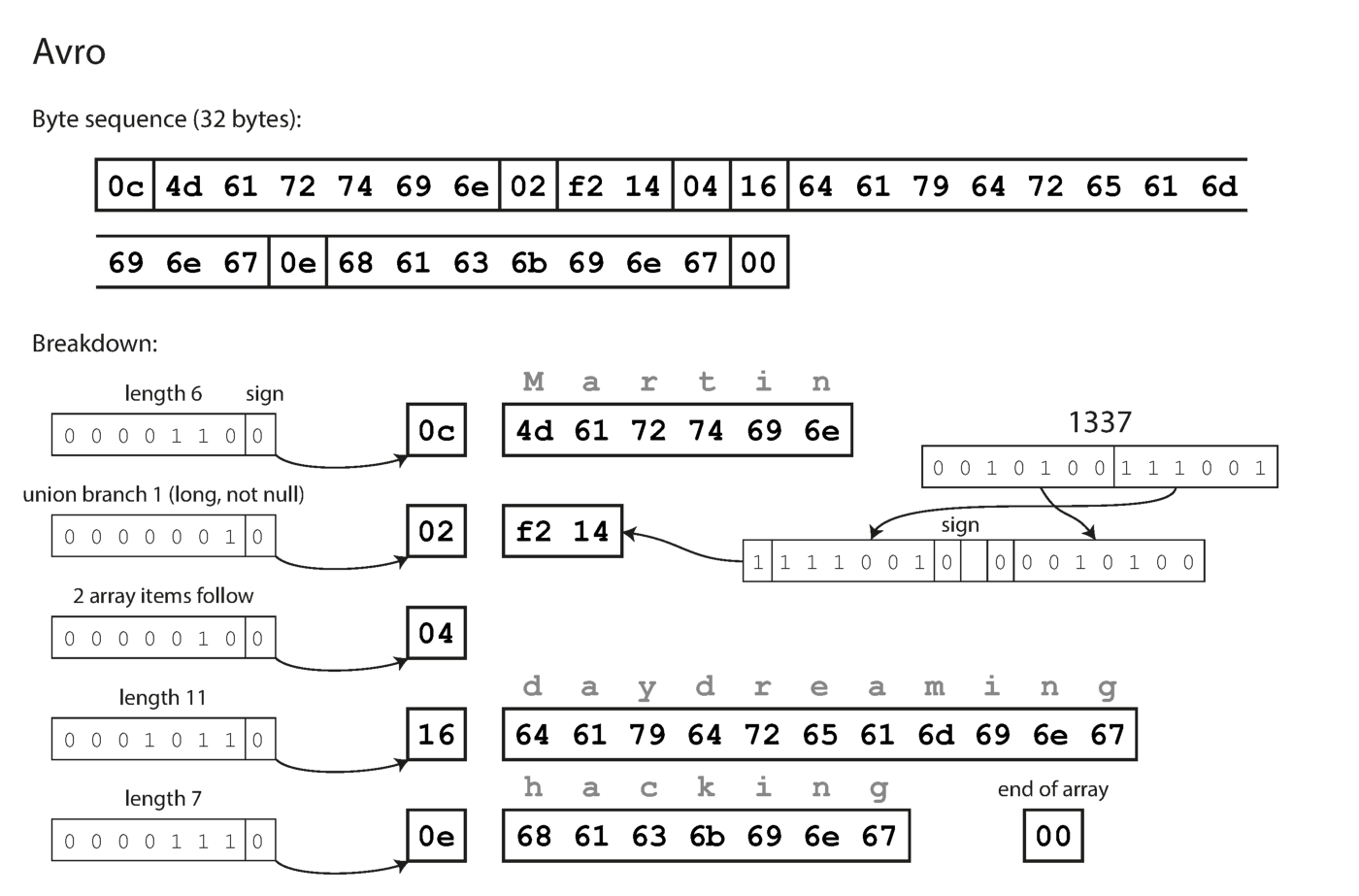
Codificação com Avro.
Como você pode ver na sequência de bytes acima, os campos não podem ser identificados (nos rótulos Thrift e Protocol Buffers com números são usados para isso), também é impossível determinar o tipo de dados do campo. Os valores são simplesmente reunidos. Isso significa que qualquer alteração no circuito durante a decodificação irá gerar dados incorretos? A idéia principal da Avro é que o esquema para escrever e ler não precisa ser o mesmo, mas deve ser compatível. Quando os dados são decodificados, a biblioteca Avro resolve esse problema observando os dois circuitos e traduzindo os dados do circuito do gravador para o circuito do leitor.
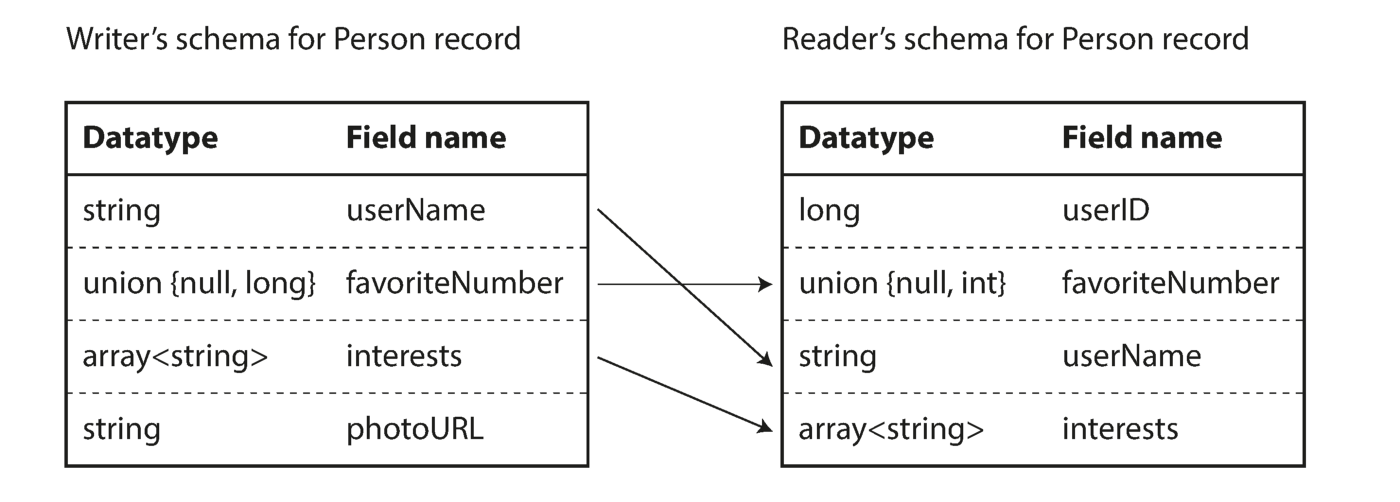
Eliminando a diferença entre o circuito
do leitor e do gravador Você provavelmente está pensando em como o leitor aprende sobre o circuito do gravador. É tudo sobre o cenário de uso da codificação.
- Ao transferir arquivos ou dados grandes, o gravador pode incluir o circuito no início do arquivo uma vez.
- Em um banco de dados com registros individuais, cada linha pode ser gravada com seu próprio esquema. A solução mais simples é incluir um número de versão no início de cada entrada e manter uma lista de esquemas.
- Para enviar um registro pela rede, o leitor e o gravador podem concordar com um esquema quando a conexão é estabelecida.
Uma das principais vantagens do uso do formato Avro é o suporte para esquemas gerados dinamicamente. Como nenhuma tag numerada é gerada, você pode usar um sistema de controle de versão para armazenar entradas diferentes codificadas com esquemas diferentes.
Conclusão
Neste artigo, vimos os formatos de codificação de texto e binário, discutimos como os mesmos dados podem ocupar 82 bytes com JSON codificado, 33 bytes codificados com Thrift e Protocol Buffers e apenas 32 bytes usando a codificação Avro. Os formatos binários oferecem várias vantagens distintas sobre o JSON ao transferir dados pela rede entre serviços de back-end.
Recursos
Para saber mais sobre a codificação e o design de aplicativos com uso intensivo de dados, recomendo a leitura de Designing Intensivo de Dados por Martin Kleppman.

Descubra os detalhes de como obter uma profissão de alto nível do zero ou subir de nível em habilidades e salário fazendo os cursos on-line pagos do SkillFactory:
- Curso de Machine Learning (12 semanas)
- Treinamento da profissão em Data Science (12 meses)
- Profissão analítica com qualquer nível inicial (9 meses)
- Curso Python para Desenvolvimento Web (9 meses)
Consulte Mais informação
- Tendências no cenário de dados 2020
- A ciência de dados está morta. Viva a Ciência dos Negócios
- O melhor cientista de dados não perde tempo com estatísticas
- Como se tornar um cientista de dados sem cursos on-line
- 450 cursos gratuitos da Ivy League
- Data Science : «data»
- Data Sciene : Decision Intelligence