
Aqui você encontrará uma lista de materiais lançados em junho em inglês. Todos eles são escritos sem acadêmico excessivo, contêm exemplos de código e links para repositórios não vazios. A maioria das tecnologias mencionadas é de domínio público e não requer hardware pesado para testes.
GPT de imagem
A IA aberta decidiu que, como um modelo de transformador treinado em texto pode gerar frases completas coerentes, se o modelo for treinado em sequências de pixels, poderá gerar imagens aumentadas. A IA aberta demonstra como a amostragem de alta qualidade e a classificação precisa das imagens permitem que o modelo gerado concorra com os melhores modelos convolucionais em ambientes de aprendizado não supervisionado.

Depixelizer de rosto Há
um mês, tivemos a oportunidade de brincar com a ferramenta, que usa um modelo de aprendizado de máquina para transformar retratos em belas pixel art. É divertido, mas ainda é difícil imaginar o amplo uso dessa tecnologia. Mas a ferramenta que produz o efeito oposto imediatamente se interessou muito pelo público. Com a ajuda de um despixelizer de rosto, em teoria, será possível estabelecer a identidade de uma pessoa gravando vídeos de câmeras de vigilância externas.

DeepFaceDrawing
Se trabalhar com imagens em pixel não for suficiente e você precisar compor uma fotografia com o retrato de uma pessoa a partir de um esboço primitivo, uma ferramenta baseada em DNN já apareceu para isso. Conforme concebido pelos criadores, são necessários apenas esboços gerais, e não esboços profissionais - o modelo restaurará o rosto da pessoa, o que coincidirá com o esboço. O sistema foi criado usando a estrutura Jittor, como prometem os criadores, o código fonte do Pytorch será adicionado em breve ao repositório do projeto.
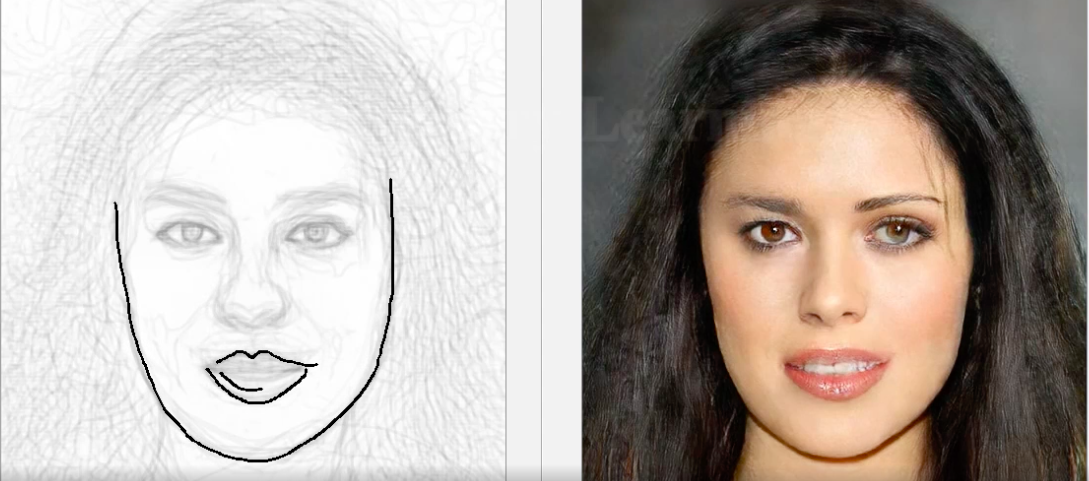
PIFuHD
Com as reconstruções faciais resolvidas, e o resto do corpo? Graças ao desenvolvimento do DNN, tornou-se possível modelar em 3D uma figura humana com base em uma foto bidimensional. A principal limitação se deve ao fato de que previsões precisas requerem análise de um contexto mais amplo e dados de origem em alta resolução. A arquitetura em camadas do modelo e os recursos de aprendizado de ponta a ponta ajudarão a resolver esse problema. No primeiro nível, para economizar recursos, toda a imagem é analisada em baixa resolução. O contexto é formado e, em um nível mais detalhado, o modelo avalia a geometria analisando a imagem de alta resolução.

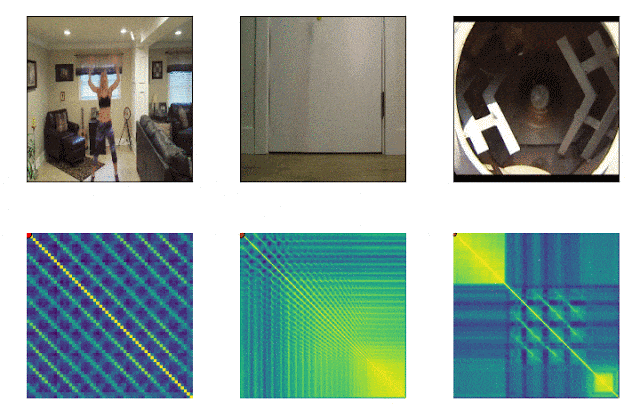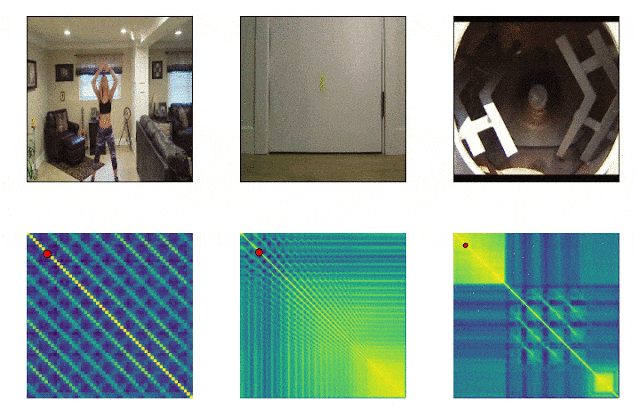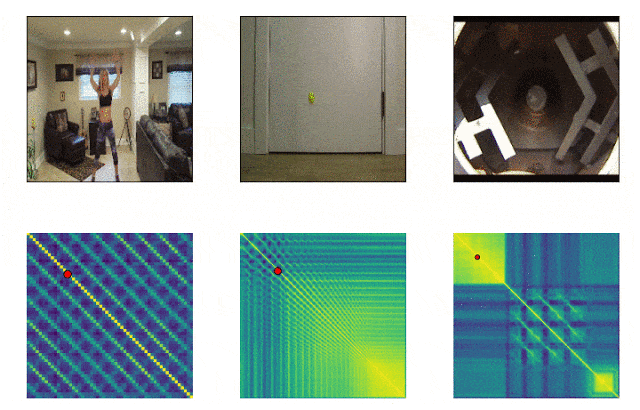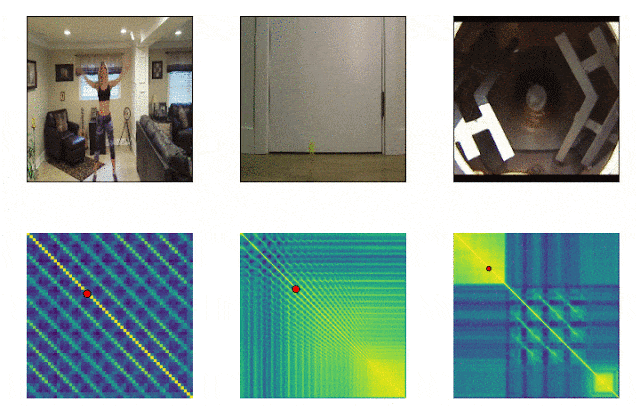
RepNet
Muitas coisas que nos cercam consistem em ciclos de diferentes frequências. Freqüentemente, para entender a essência de um fenômeno, é necessário analisar informações sobre suas manifestações recorrentes. Levando em conta as possibilidades de gravação de vídeo, não é mais difícil corrigir as repetições, o problema era contá-las. O método de comparação quadro a quadro da densidade de pixels no quadro muitas vezes não era adequado devido à trepidação da câmera ou obstrução por objetos, além de uma grande diferença na escala e na forma ao aumentar e diminuir o zoom. Um modelo desenvolvido pelo Google agora resolve esse problema. Ele identifica ações repetitivas no vídeo, incluindo aquelas que não foram usadas no treinamento. Como resultado, o modelo retorna dados sobre a frequência de ações repetidas reconhecidas no vídeo. O Colab já está disponível .
Modelo SPICE
Anteriormente, era necessário confiar em algoritmos sofisticados de processamento de sinal para determinar o tom. O maior desafio foi separar o som em estudo do ruído de fundo ou o som dos instrumentos que o acompanham. Um modelo pré-treinado está agora disponível para esta tarefa que detecta frequências altas e baixas. O modelo está disponível para uso na Web e em dispositivos móveis.
Detector de distanciamento social
O caso de criar um programa com o qual você possa acompanhar se as pessoas observam o distanciamento social. O autor conta em detalhes como ele escolheu um modelo pré-treinado, como lidou com a tarefa de reconhecer pessoas e como, usando o OpenCV, ele transformou a imagem em uma projeção ortográfica para calcular a distância entre as pessoas. Você também pode se familiarizar com o código-fonte do projeto.

Reconhecimento de documentos típicos
Hoje, existem milhares de variações dos documentos modelo mais comuns, como recibos, faturas e cheques. Sistemas automatizados existentes projetados para trabalhar com um tipo muito limitado de modelo. O Google sugere o uso de aprendizado de máquina para isso. O artigo discute a arquitetura do modelo e os resultados dos dados obtidos. Em breve, a ferramenta fará parte do serviço de AI do documento .
Como criar um pipeline escalável para o desenvolvimento e implantação de algoritmos de aprendizado de máquina para o varejo sem contato
A startup israelense Trigo compartilha sua experiência no uso de aprendizado de máquina e visão computacional no varejo take-and-go. A empresa é fornecedora de um sistema que permite que as lojas operem sem uma caixa registradora. Os autores contam quais tarefas eles enfrentaram e explicam por que escolheram o PyTorch como uma estrutura para aprendizado de máquina e o Allegro AI Trains para infraestrutura e como eles conseguiram estabelecer o processo de desenvolvimento.
Só isso, obrigado pela atenção!